大家好,我是二哥呀。
用 AI 写代码、跑 Agent 这大半年,最大的感受就是------模型能力确实越来越强了。
但确实也是真的贵,Claude Code+Codex 我每个月要 400 多刀。
对于普通人来说,这是一笔不菲的开销啊,苍天可见,我也是真舍不得,但也是真离不开。😄
索性,兄弟们,总有雷哥想办法。上周在 GitHub 上刷到一个项目,README 第一行写着"每月 13 亿免费 Token"。
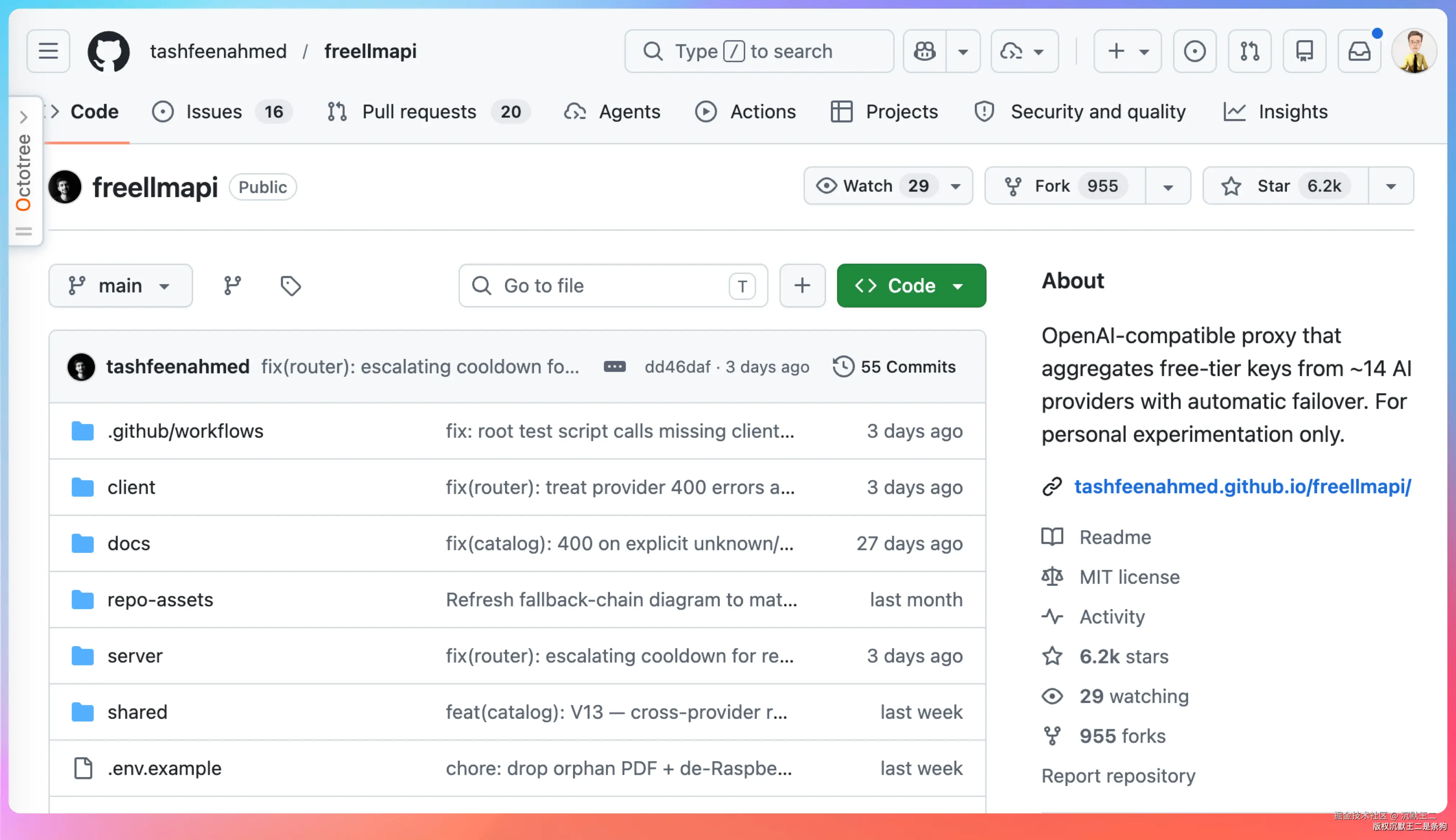
已经 6.2k star了。
01、FreeLLMAPI 是什么
先说清楚这东西干了什么。
FreeLLMAPI 是一个自托管的 API 网关,把 Google Gemini、Groq、Mistral、Cerebras、SambaNova、OpenRouter、GitHub Models、Cloudflare Workers AI、Cohere 等 14 家 AI 厂商的免费额度聚合到一个端点上,对外暴露标准的 OpenAI 兼容接口。
你只要注册各家平台的免费 API Key(都不需要绑卡),配进 FreeLLMAPI 的后台,它就会给你生成一个统一的 Bearer Token。之后所有请求都打到 http://localhost:3001/v1/chat/completions,由路由器自动选择当前可用的最优模型。

其他还有 Cohere、Z.ai(智谱)、HuggingFace、NVIDIA NIM 等平台。
02、前置环境准备
Node.js 20 以上
macOS 用 Homebrew 直接安装:
bash
brew install node@22Windows 建议用 WSL2 或者去 Node.js 官网下载安装包。装完验证一下:
bash
node -v
Git
需要用 Git 克隆仓库。macOS 自带,Windows 用户可以装 Git for Windows。
bash
git --version注册各家免费 API Key
这一步是整个流程里最花时间的部分,但只需要做一次。
我建议第一次先注册三家:Groq、Mistral、OpenRouter。
三家配好基本就够日常使用了。
注册流程都差不多:进官网、创建账号、在后台找到 API Keys 页面、创建一个新的 Key、复制保存。
GitHub Models 稍微不一样,需要在 GitHub 的 Settings → Developer settings → Personal access tokens 里创建一个带 Models 权限的 Token。
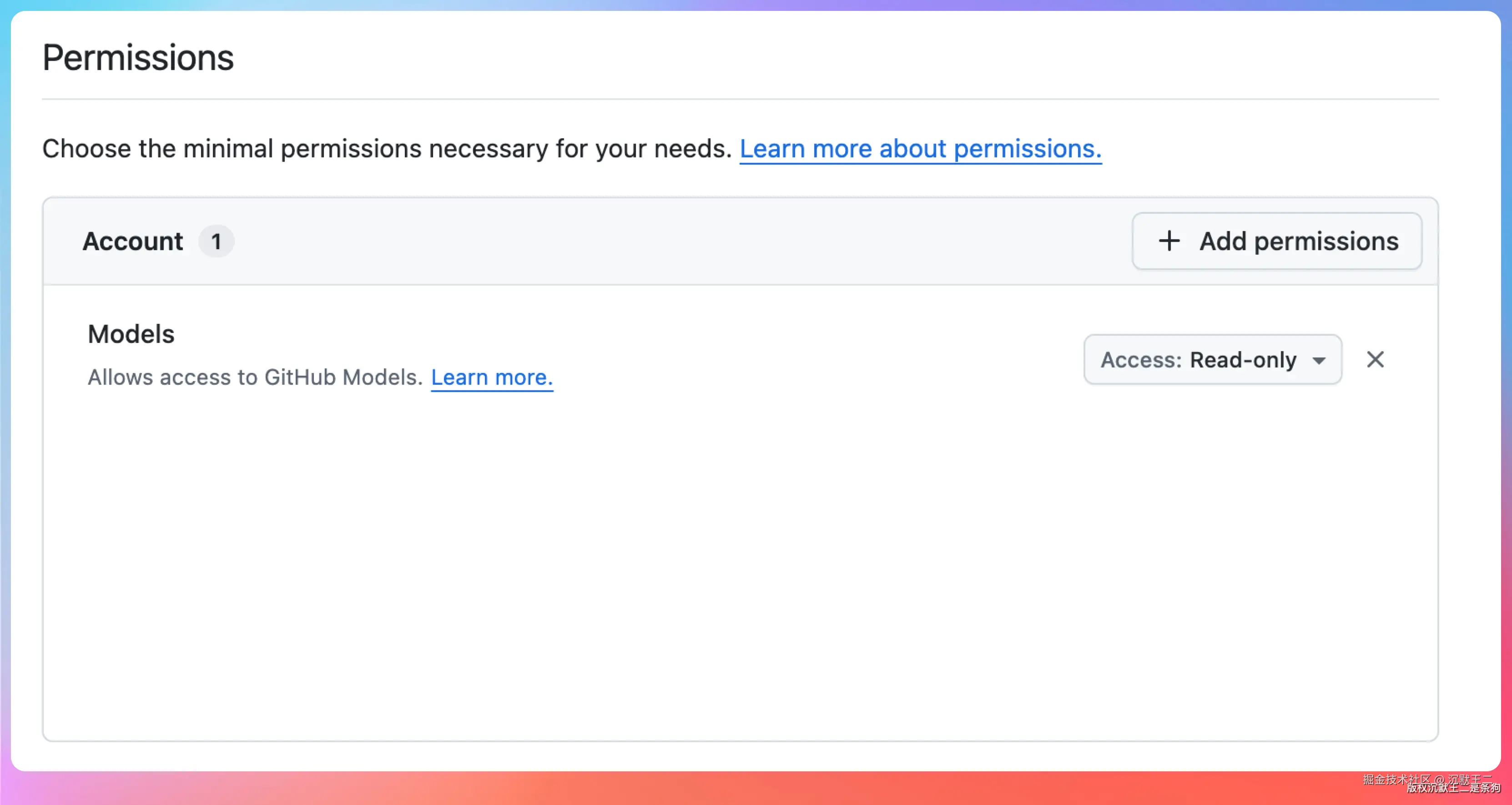
把创建好的 Key 先存到一个文本文件里,后面配置的时候要用。
03、克隆和启动
环境准备好后,正式开始安装。
克隆仓库
bash
git clone https://github.com/tashfeenahmed/freellmapi.git
cd freellmapi
安装依赖
bash
npm install这一步会同时安装前端和后端的依赖。
生成加密密钥
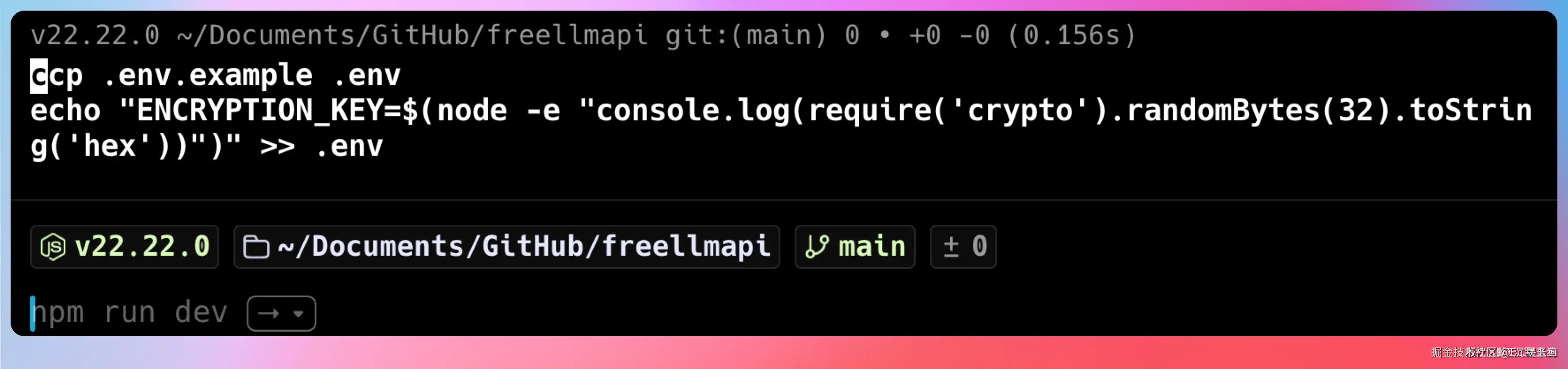
FreeLLMAPI 会用 AES-256-GCM 加密存储你的 API Key,所以需要一个加密密钥。
bash
cp .env.example .env
echo "ENCRYPTION_KEY=$(node -e "console.log(require('crypto').randomBytes(32).toString('hex'))")" >> .env这条命令会生成一个 64 位的十六进制密钥,写入 .env 文件。
启动开发服务器
bash
npm run dev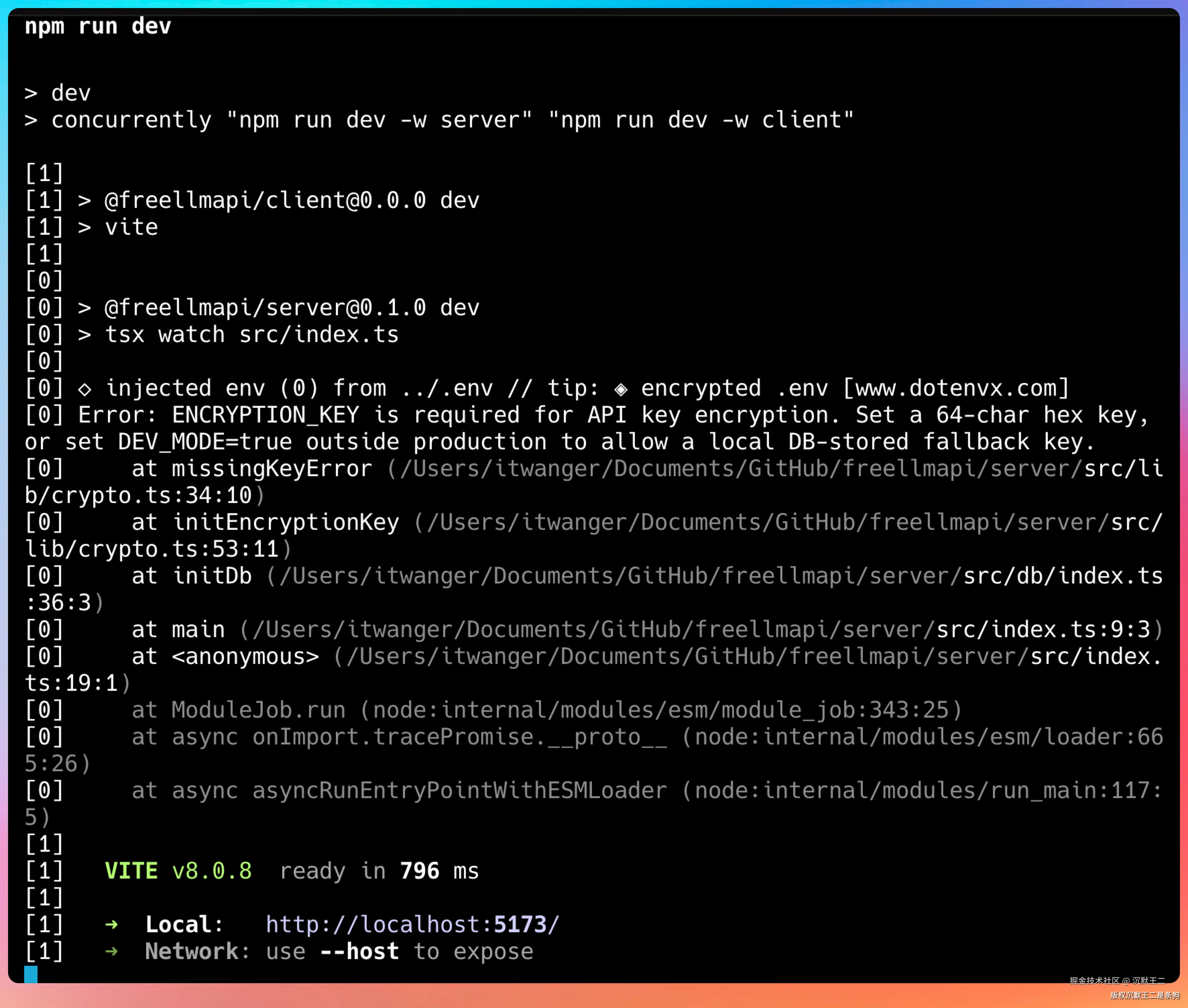
启动后会看到两个地址:
- 前端 Dashboard:
http://localhost:5173 - 后端 API:
http://localhost:3001
浏览器打开 http://localhost:5173,能看到 FreeLLMAPI 的管理后台,说明安装成功了。
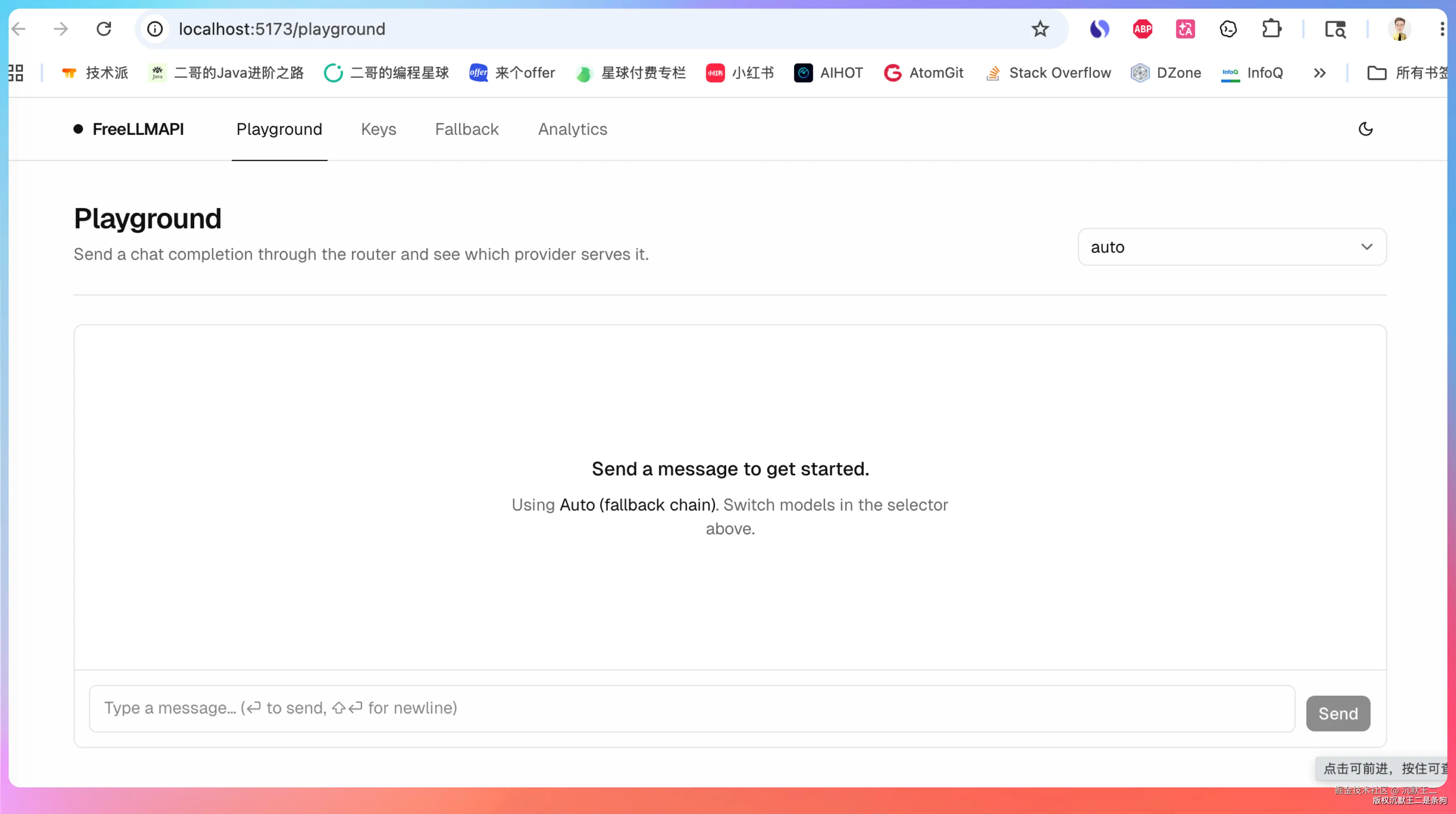
如果要生产环境部署,用 npm run build && node server/dist/index.js,前后端都跑在 3001 端口上。
04、配置 Provider 和 API Key
Dashboard 打开后,第一件事是把各家平台的 API Key 配进去。
在 Dashboard 左侧找到 Provider 管理页面,点击添加 Provider,选择平台(比如 Groq),粘贴你的 API Key。
可以用 FreeLLMAPI 检查这个 Key 的健康状态,绿色表示可用,红色表示无效或已达限额。
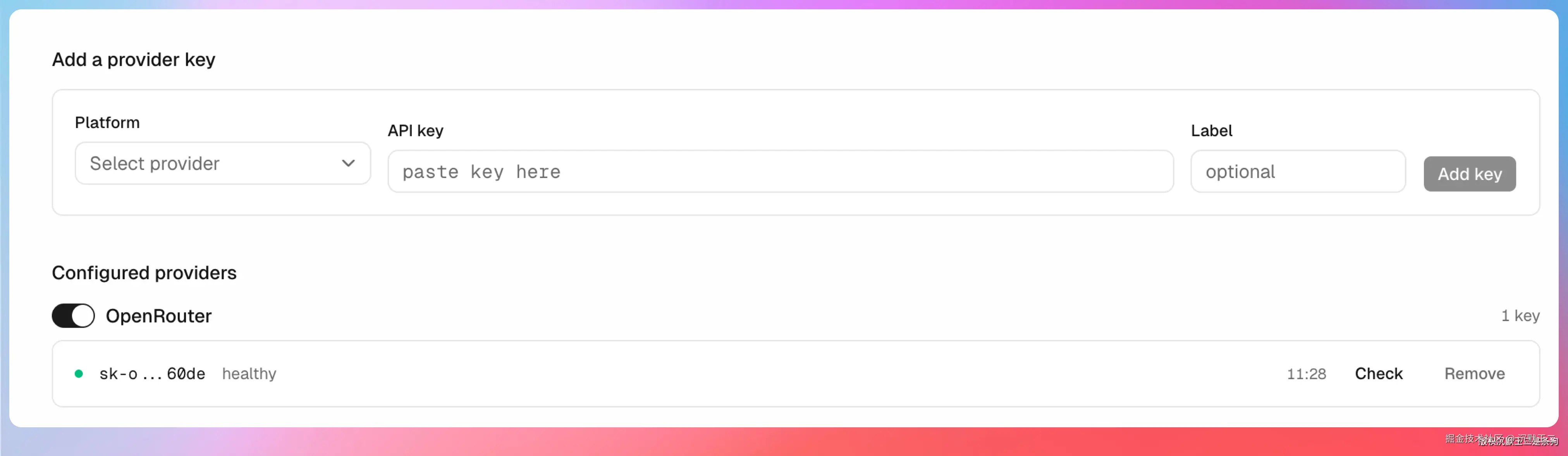
每个 Provider 配好之后,FreeLLMAPI 会自动把该平台支持的模型注册到路由表里。
你不需要手动指定用哪个模型,路由器会根据可用性自动选。
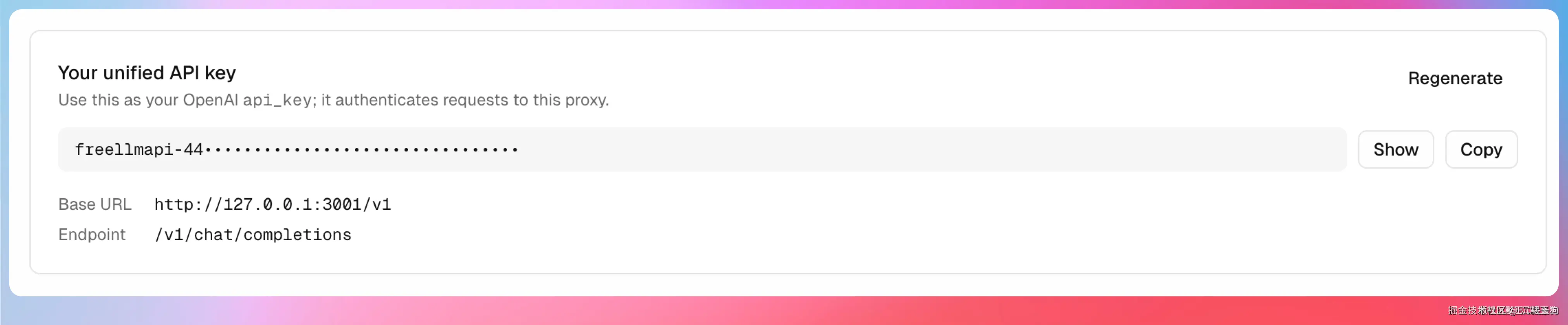
配完所有 Provider 之后,在 Dashboard 的 API Key 页面,你会看到系统生成的统一 API Key,格式是 freellmapi-xxxx。复制这个 Key,后面所有客户端都用它来认证。
05、快速验证
配好之后先用 curl 测一下,确保端到端能跑通。
bash
curl http://localhost:3001/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer freellmapi-你的Key" \
-d '{
"model": "auto",
"messages": [{"role": "user", "content": "用一句话介绍你自己"}]
}'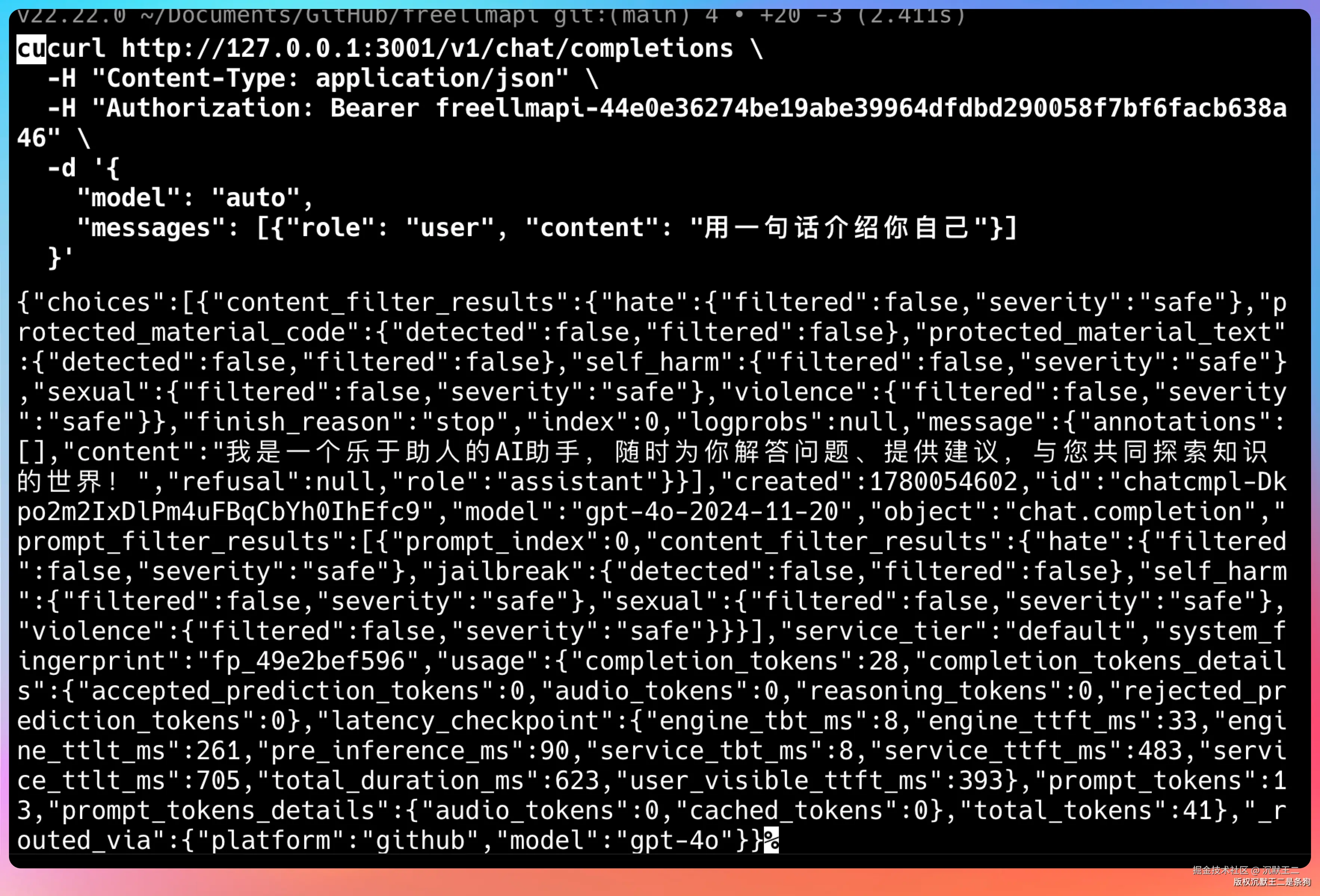
注意 model 字段写 auto,让路由器自动选择当前最优的可用模型。返回的响应头里有一个 x-routed-via 字段,告诉你这次请求实际由哪个 Provider 处理。
如果返回了正常的 JSON 响应,就说明从客户端到路由器到 Provider 的整个流程跑通了。
06、接入 PaiCLI
PaiCLI 是我们做的一个开源 Agent CLI 工具,类似 Claude Code。
它底层用了模板方法模式来管理 LLM Provider,把 HTTP 请求、流式解析、Tool Calling、Token 计数这些通用逻辑抽到一个基类里,每个具体的 Provider 只需要继承基类、填上 API 地址和 Key 就行了。
目前 PaiCLI 内置了 GLM、DeepSeek、StepFun、Kimi 四个 Provider。
配置方式
打开 PaiCLI。
json
/config provider freellmapi --base-url http://127.0.0.1:5173/v1 --api-key <FreeLLMAPI unified API key> --model auto 配置好后,用 /model freellmapi 切换到 FreeLLMAPI,就能开始用了。
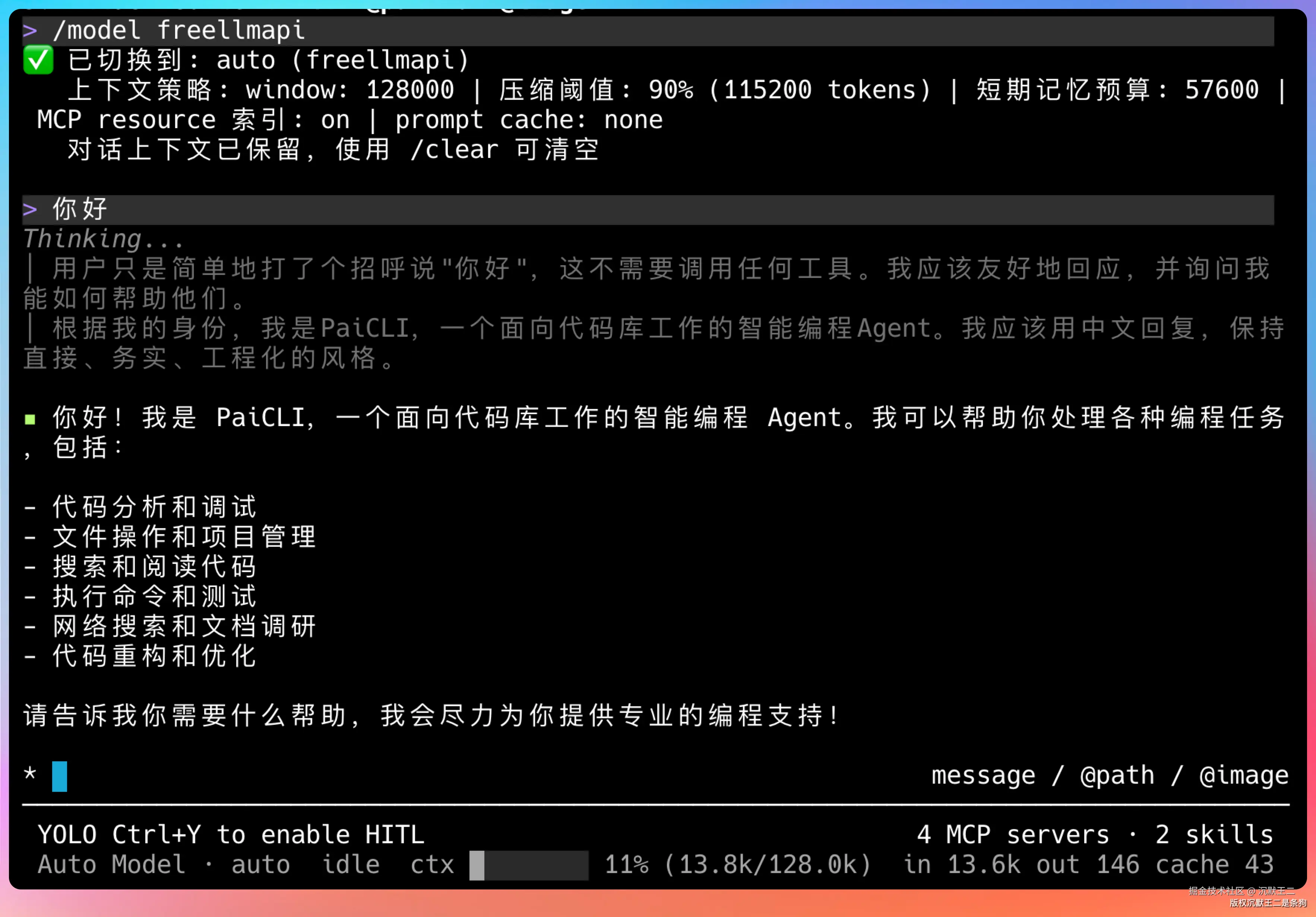
实测效果
切换完成后,可以直接在 PaiCLI 里试几个提示词,验证 FreeLLMAPI 是否正常工作。
Case 1:代码解释
css
帮我读一下 src/main/java/com/paicli/llm 目录下的代码,整理出所有 Provider 的接入方式和核心差异,输出一份对比表格。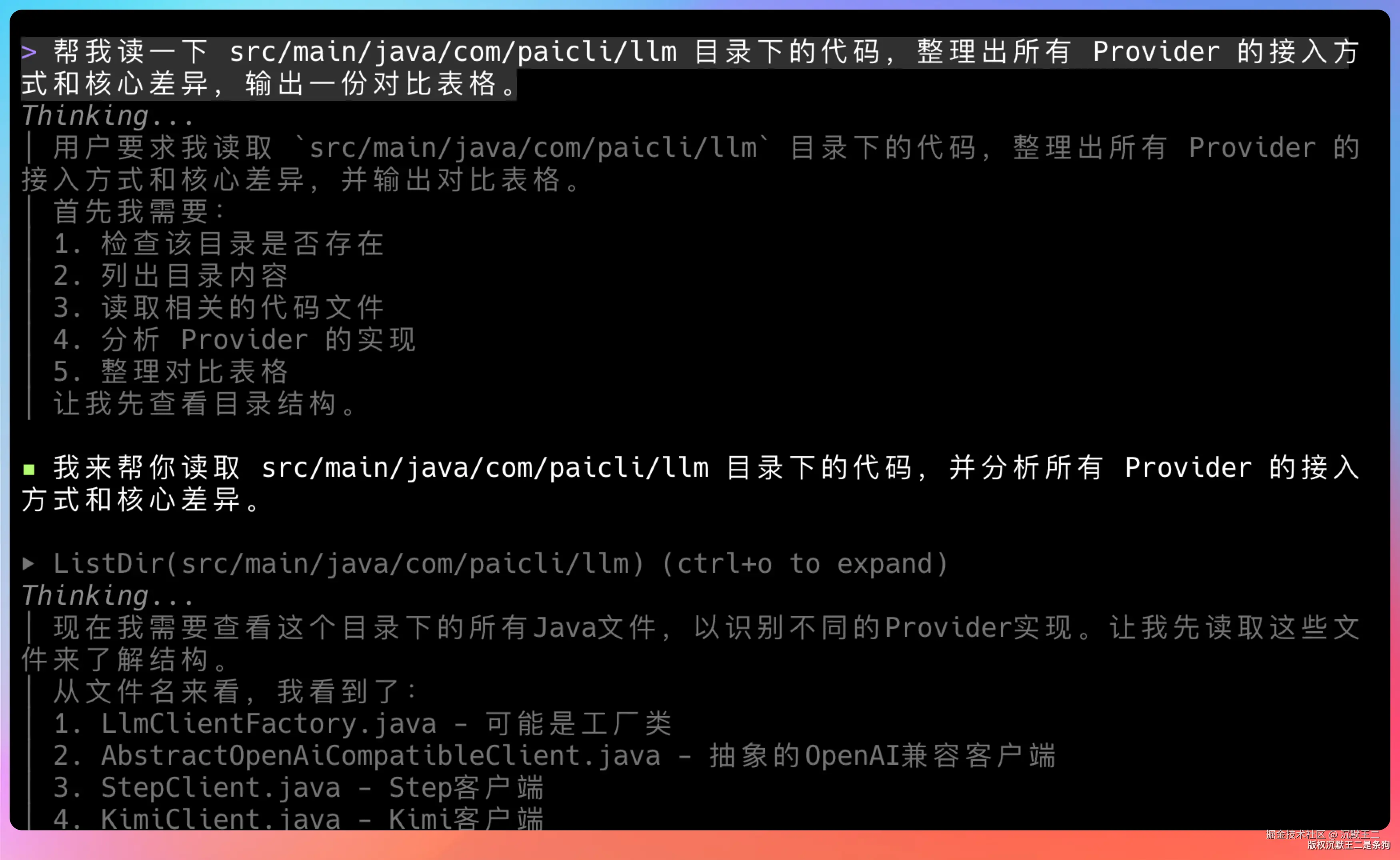
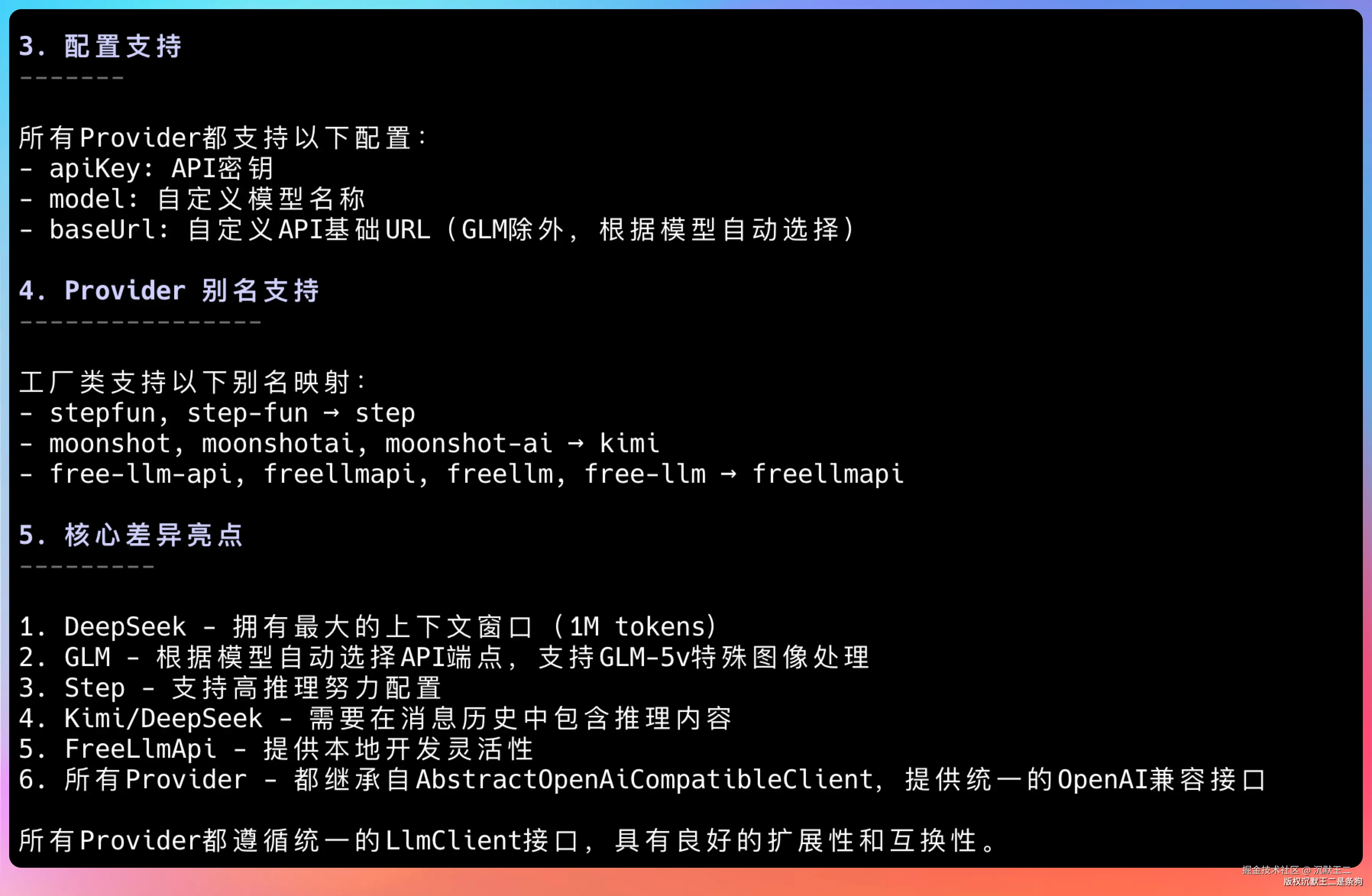
这个任务会触发 PaiCLI 的文件读取和代码搜索工具,模型需要理解 Java 代码结构。可以直观感受到 FreeLLMAPI 路由到的模型在代码理解上的表现。
Case 2:批量文件处理
扫描当前项目中所有的 TODO 和 FIXME 注释,按优先级分类整理成一份清单,输出到 todo-report.md。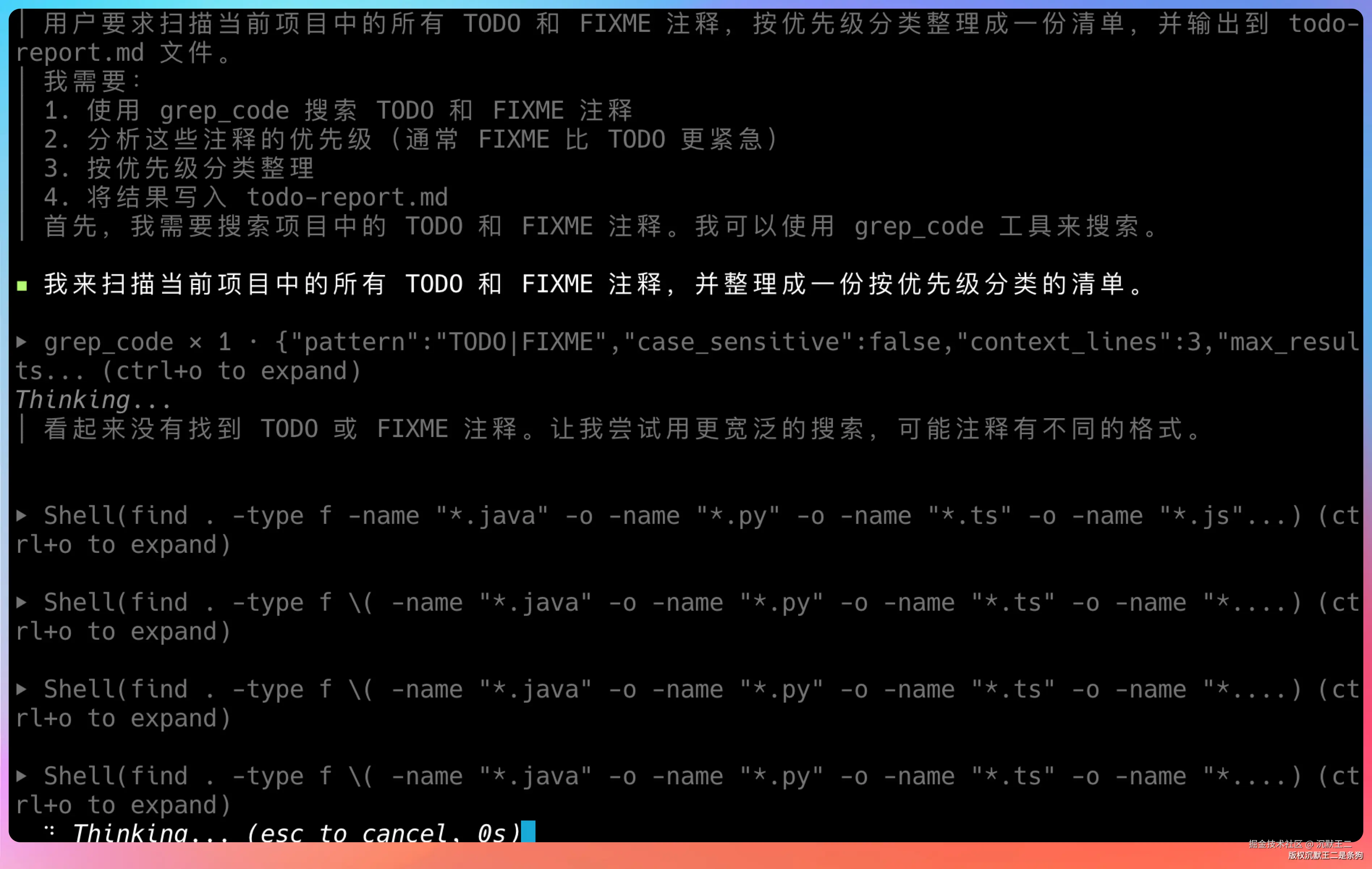
这个任务会大量调用 grep 工具,多轮对话下可以观察 FreeLLMAPI 的 Sticky Session 机制是否生效------30 分钟内的连续请求会路由到同一个模型,保持上下文连贯。
简历怎么写
如果你在 PaiCLI 的基础上做了 FreeLLMAPI 的集成开发,简历里可以这样包装:
项目名称:PaiCLI --- 开源 Agent CLI 框架
项目简介:类 Claude Code 的终端 AI 助手,支持 ReAct 循环、Plan-and-Execute、多 Agent 协作
技术栈:Java、OpenAI Compatible API、模板方法模式、流式 SSE 解析、SQLite
核心职责:
- 基于模板方法模式实现 LLM Provider 抽象层,新增 Provider 只需约 30 行代码,支持 GLM、DeepSeek、StepFun、Kimi 等 6 家模型厂商的快速接入
- 集成 FreeLLMAPI 网关,通过 OpenAI 兼容协议聚合 14 家免费 API
- 封装 OpenAI 兼容协议基类,统一处理流式响应解析、Tool Calling 参数转换和 Token 计数,覆盖 4 种主流 API 协议差异
07、路由机制和限流策略
FreeLLMAPI 的路由器是整个项目最有意思的部分,我花了一晚上读了它的源码,发现设计比我预期的精细很多。
动态惩罚路由
路由器不是简单地按固定优先级排序。
它维护了一套动态惩罚机制------每个模型有一个基础优先级,但实际排序用的是"基础优先级 + 惩罚分"。
惩罚分怎么来的?
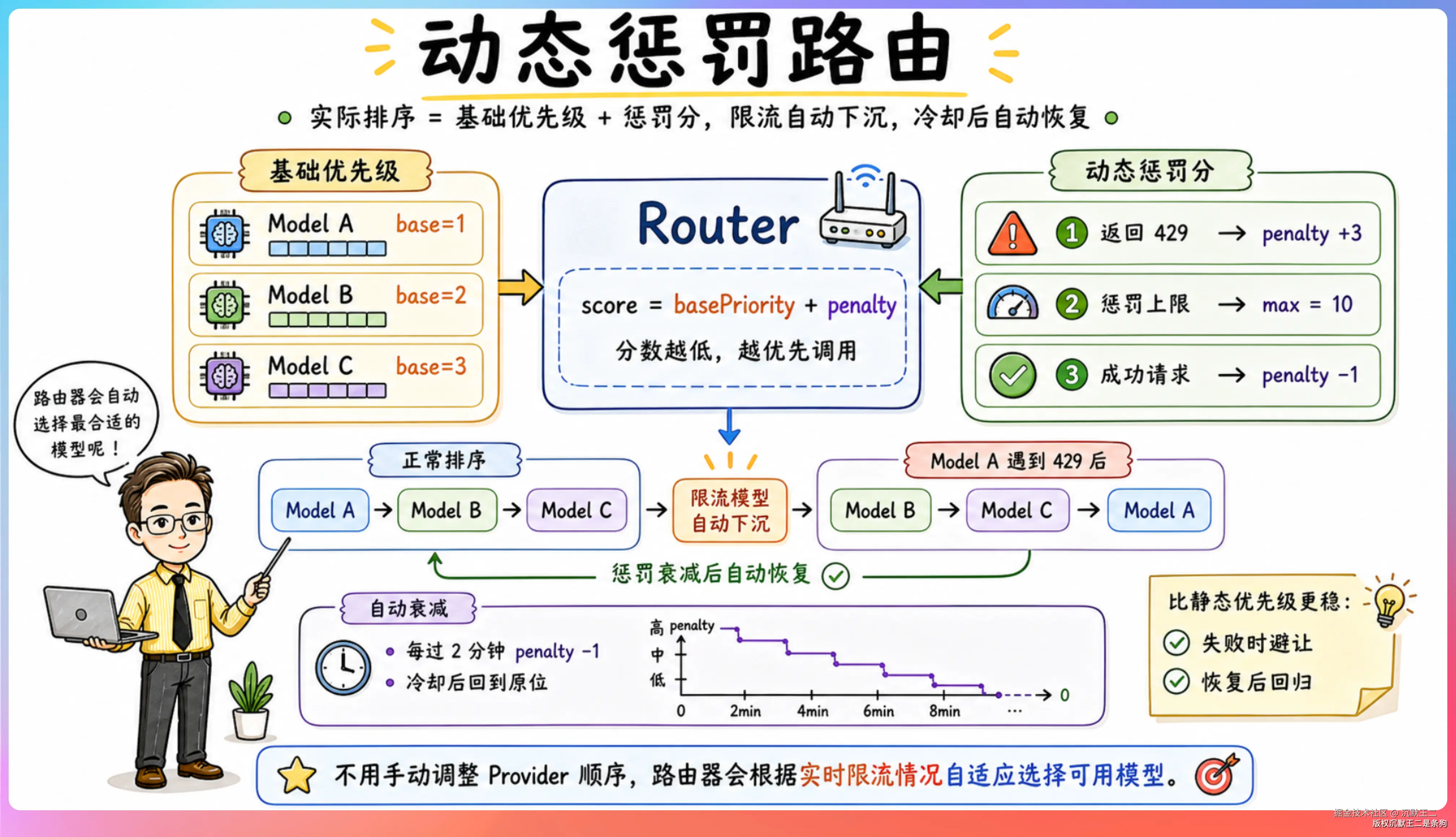
每次某个模型返回 429(限流),惩罚分加 3,上限 10。
每过 2 分钟自动衰减 1,每次成功请求也减 1。这意味着一个模型被限流后,会在优先级队列里自动下沉,让其他模型先顶上来。等冷却期过了,惩罚分衰减到 0,它又回到原来的位置。
这个设计比静态优先级高明的地方在于,它能自适应。你不需要手动调整各家 Provider 的顺序,路由器会根据实时的限流情况自动找到最优解。
滑动窗口限流
限流检查用的是滑动窗口算法,不是固定窗口。
区别在哪里?
固定窗口是"每分钟 100 次",到点重置计数器。滑动窗口是"过去 60 秒内 100 次",每一秒都在滑动。
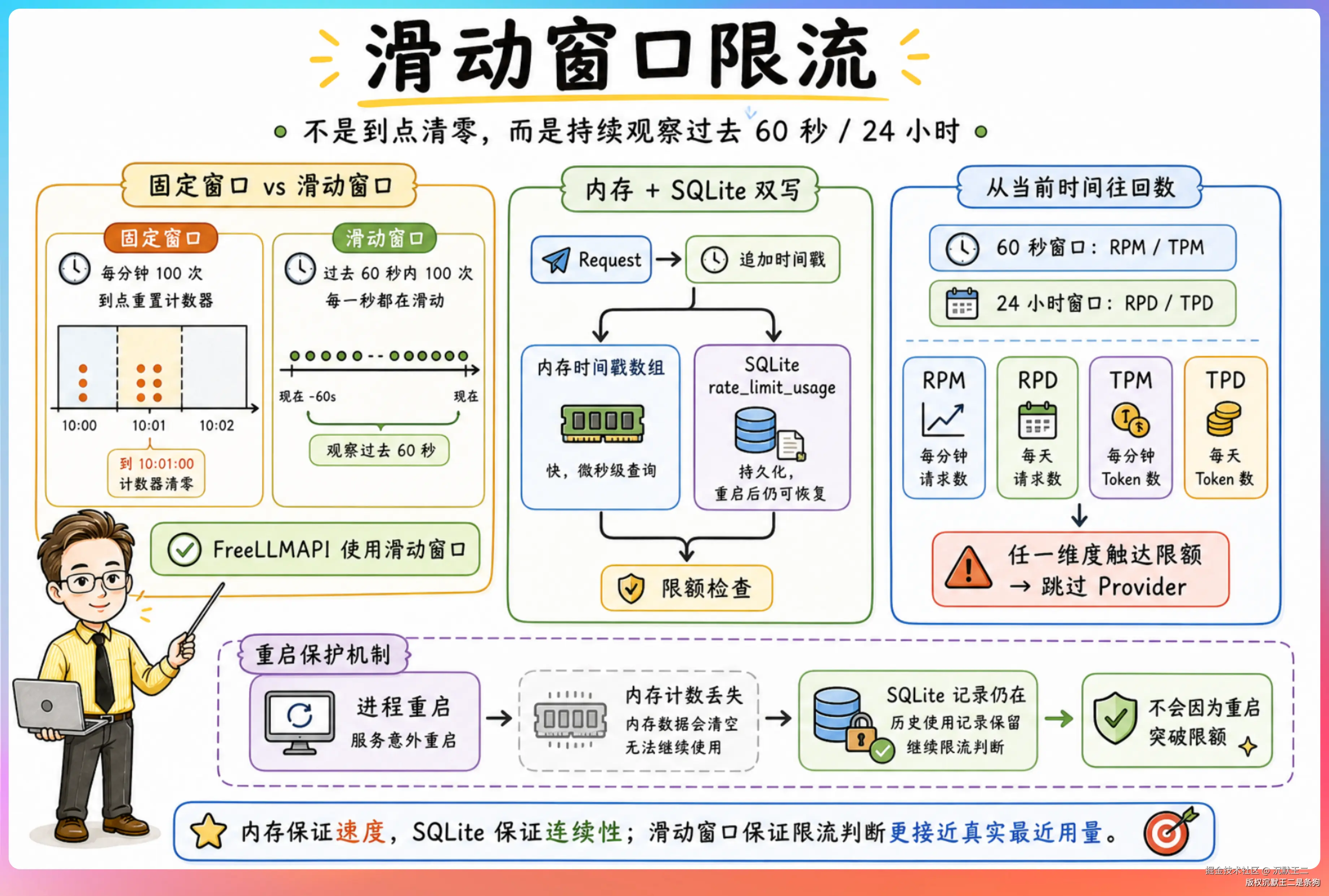
FreeLLMAPI 的实现是内存和 SQLite 双写。
每次请求都会往内存的时间戳数组里追加一条,同时写一条记录到 SQLite 的 rate_limit_usage 表。检查限额的时候,从当前时间往回看 60 秒(RPM)或 24 小时(RPD),数一下有多少条请求记录。
为什么要双写?
内存快,查询响应时间在微秒级。SQLite 慢一点,但重启后数据还在。
如果 FreeLLMAPI 进程挂了重启,内存里的计数全丢了,但 SQLite 里的记录还在,不会出现重启后突破限额的情况。
检查维度一共四个:RPM(每分钟请求数)、RPD(每天请求数)、TPM(每分钟 Token 数)、TPD(每天 Token 数)。任何一个维度触达限额,这个 Provider 就会被跳过。
冷却升级
更有意思的是冷却时间的升级策略。同一个模型在 24 小时内第一次触发 429,冷却 2 分钟。第二次 10 分钟。第三次 1 小时。第四次直接冷却 24 小时。
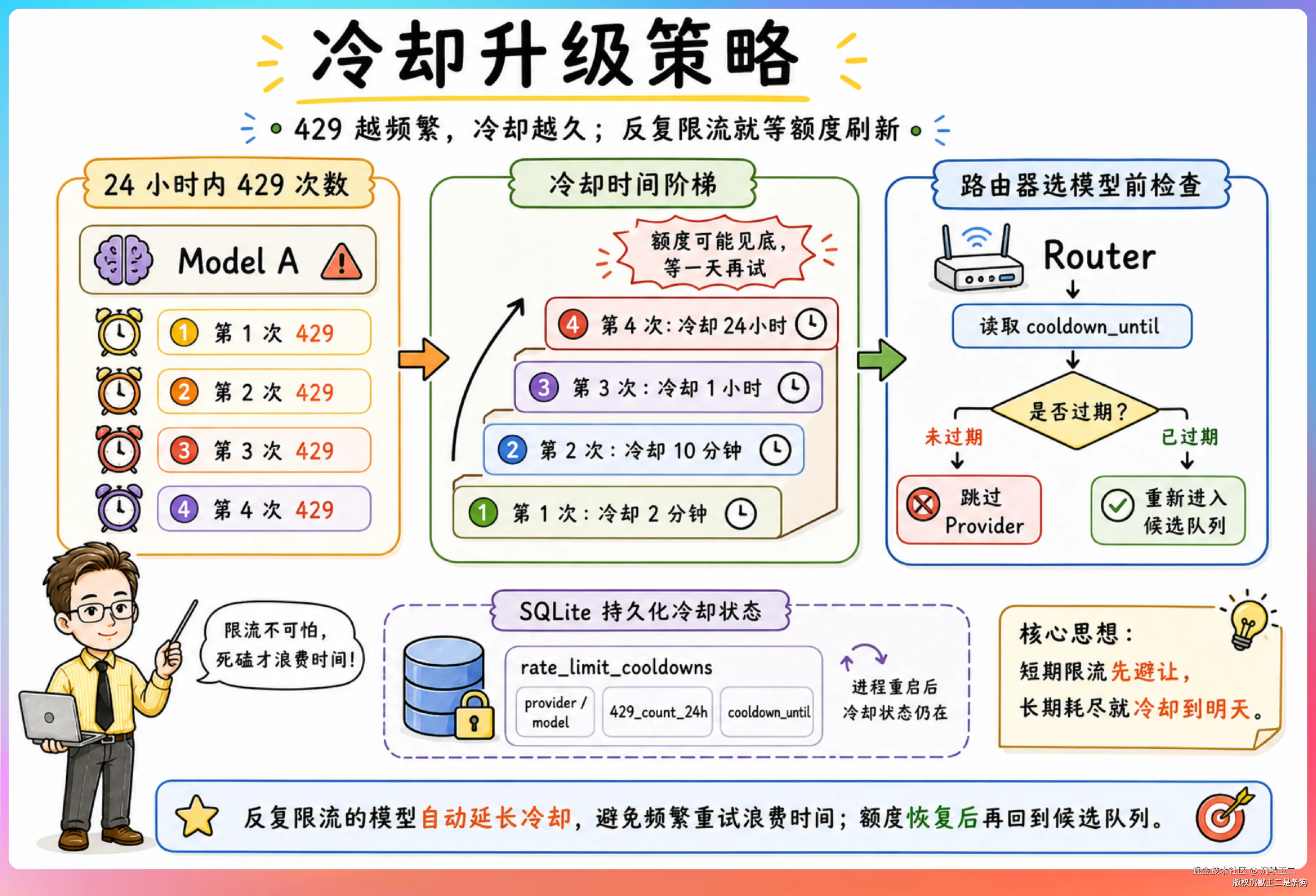
这个设计的思路是:如果一个模型反复被限流,说明它的免费额度可能已经见底了,与其每隔几秒钟去试一次浪费时间,不如直接让它冷却一整天,等额度刷新了再说。
冷却状态存在 SQLite 的 rate_limit_cooldowns 表里,路由器每次选模型之前都会先检查冷却时间,没过期的直接跳过。
Sticky Session
多轮对话场景下有一个问题:如果第一轮路由到了 Groq 的 Llama,第二轮突然切到了 Google 的 Gemini,前面传的上下文对 Gemini 来说可能格式不兼容,或者模型对上下文的理解方式不同,回答质量会下降。
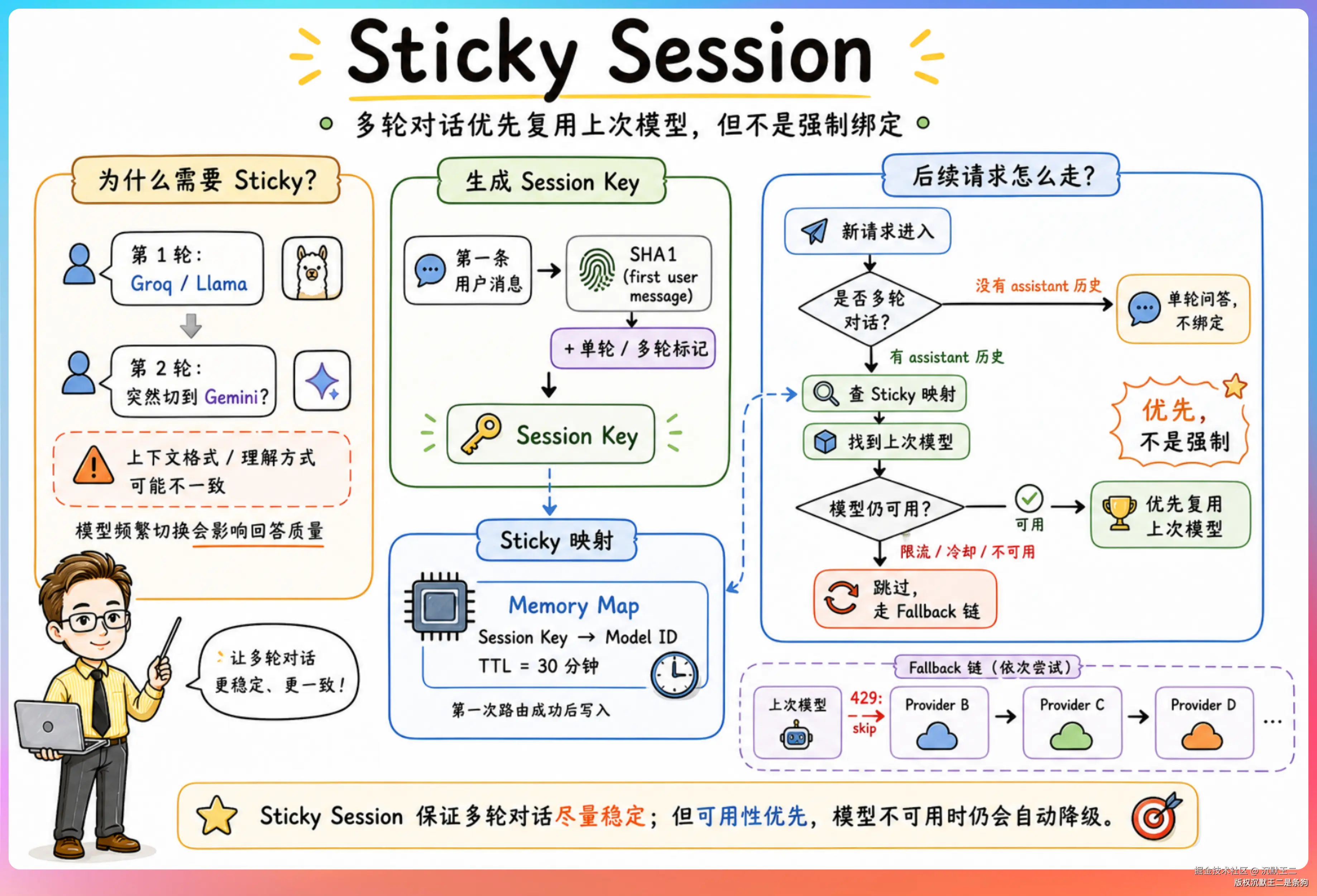
FreeLLMAPI 的解决方案是 Sticky Session。
它用第一条用户消息的 SHA1 哈希值作为 Session Key,加上一个单轮/多轮的标记。
第一次路由成功后,把 Session Key 和模型 ID 的映射存到内存里,30 分钟有效。
后续同一个对话的请求进来,路由器会先查 Sticky 映射,如果找到了就优先用上次的模型。
注意是"优先"不是"强制"。如果上次的模型已经被限流了,路由器会跳过它,按正常的 Fallback 链继续找下一个。只有在上次的模型还可用的情况下,才会复用。
另外 Sticky Session 只对多轮对话生效。如果消息列表里没有 assistant 角色的历史消息,说明是单轮问答,不需要绑定模型。
Fallback 和重试
整个请求链路最多重试 20 次。
每次重试时,上一次失败的模型和 Key 的组合会被加入跳过集合,路由器选下一个的时候直接绕过。加上冷却机制和动态惩罚,20 次重试基本能覆盖所有可用的 Provider。
如果 20 次全部失败,返回 429 错误,错误信息里会带上最后一次失败的原因。
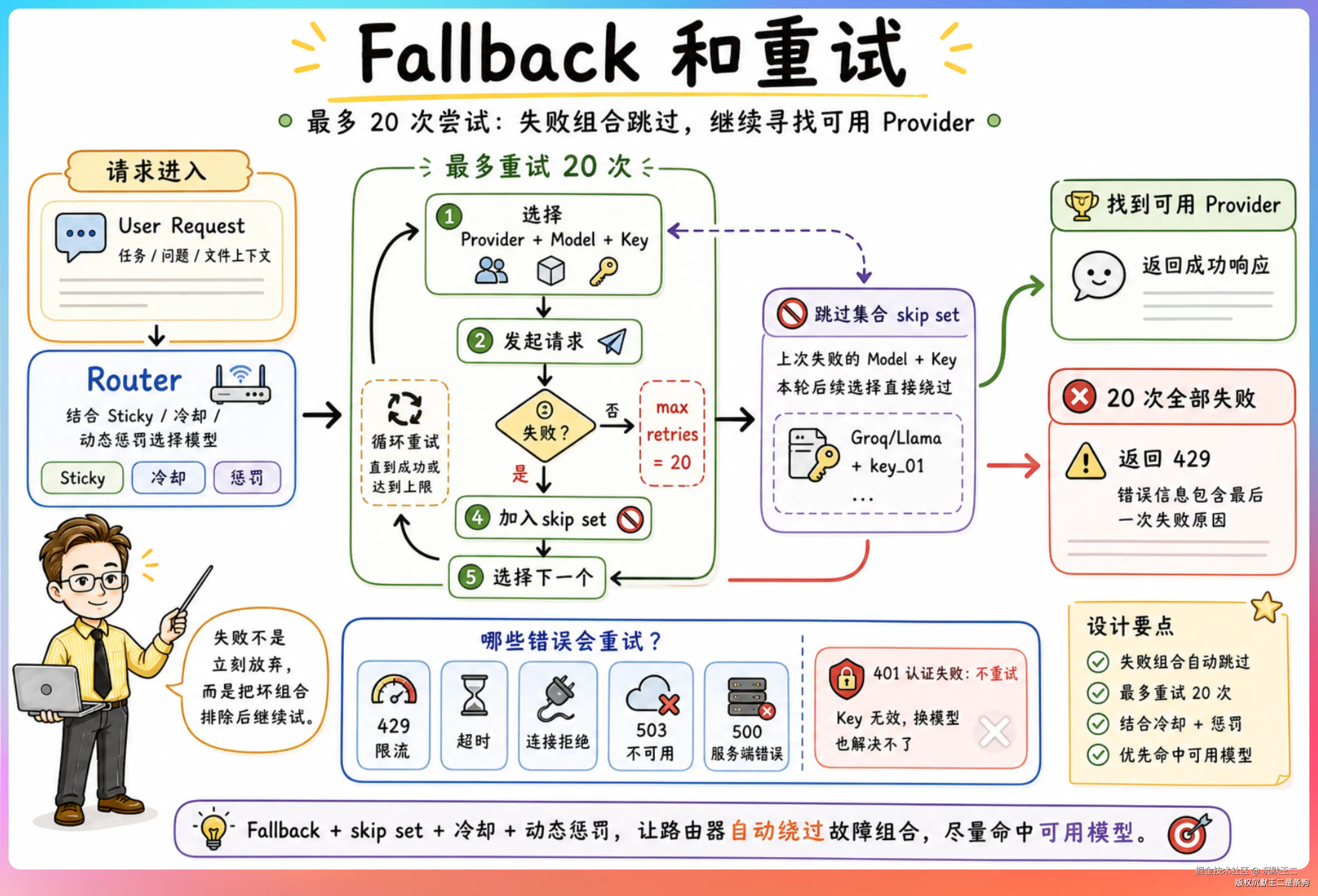
哪些错误会触发重试?
429 限流、超时、连接拒绝、503 不可用、500 服务端错误,这些都会。
401 认证失败不会重试,因为换一个模型也解决不了 Key 无效的问题。