OpenDataLoader PDF:自动化PDF可访问性与AI数据提取的开源解决方案
在数字化时代,PDF作为重要的文档格式,无处不在。然而,PDF文件的可访问性和数据提取一直是技术挑战,尤其是在复杂的文档结构和多样的内容类型面前。OpenDataLoader PDF项目,致力于解决这些问题,成为一种强大的工具,能够自动化PDF文件的可访问性,提取为AI准备的数据。本文将详细介绍OpenDataLoader PDF的核心功能、应用场景及具体使用方法。
1. 项目概述
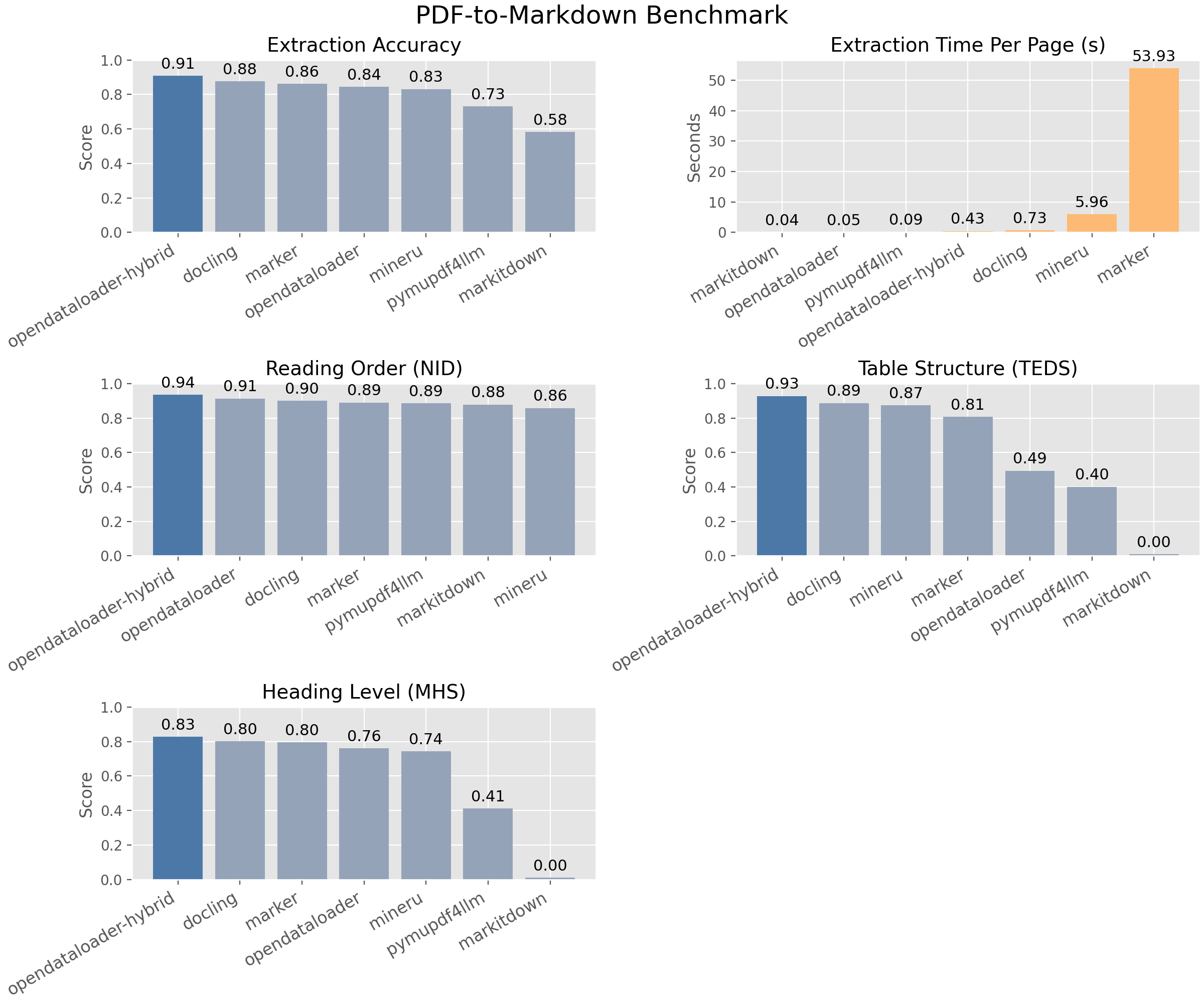
OpenDataLoader PDF是一个强大的PDF解析器,能够从各种PDF文件中提取结构化数据,包括Markdown、JSON和HTML格式。该项目在多个基准测试中表现优异,实现了0.90的总体准确率和0.93的表格准确率,特别适合需要进行大规模数据提取的场景。
核心功能特性:
- 丰富的输出格式:支持Markdown、JSON、HTML等多种格式,便于不同应用场景的需求。
- 强大的光学字符识别(OCR):内置80多种语言OCR功能,能够处理低质量扫描文档,确保数据的准确提取。
- 复杂内容处理:包括复杂表格、LaTeX公式和图表图片描述的提取,提供多种模式以适应不同文档类型。
2. 应用场景
OpenDataLoader PDF的设计理念是帮助用户更轻松地提取和处理PDF文件内容,尤其是在以下场景中表现出色:
- 学术研究:科研人员可以轻松提取期刊文章中的数据,避免手工录入的繁琐过程。
- 数据分析:数据科学家可以从商业报告中快速获取结构化数据,为后续分析提供基础。
- 法律文档处理:法律专业人士能够自动生成可访问的法律文档,确保合规性。
- 教育领域:教师和学生可以从教材中提取必要的信息,提升学习效率。
3. 使用方法
3.1 初始设置
在开始使用OpenDataLoader PDF之前,请确保已安装Java 11或更高版本,以及Python 3.10或更高版本。
bash
pip install -U opendataloader-pdf3.2 批量转换示例
以下是一个简单的Python示例,演示如何批量转换PDF文件为结构化格式:
python
import opendataloader_pdf
# 批量转换文件
opendataloader_pdf.convert(
input_path=["file1.pdf", "file2.pdf", "folder/"],
output_dir="output/",
format="markdown,json"
)3.3 高级特性使用
OpenDataLoader PDF支持多种功能,包括混合模式处理复杂PDF。您可以使用以下命令来启动处理:
bash
# 启动服务器
opendataloader-pdf-hybrid --port 5002
# 处理PDF
opendataloader-pdf --hybrid docling-fast file1.pdf file2.pdf folder/在混合模式下,OpenDataLoader将简单页面保留在本地处理,而复杂页面将路由到AI后端,以获取更高的准确率。
4. PDF可访问性自动化
OpenDataLoader PDF项目还关注PDF文件的可访问性问题,计划在2026年推出自动标记功能,将未标记的PDF文件转化为符合可访问性标准的标记PDF。这一过程将大大简化PDF的合规要求,避免高额的人工修复费用。该项目的合作伙伴包括PDF协会和Dual Lab,确保其技术的准确性与可靠性。
5. 先进功能
5.1 信息提取基准
OpenDataLoader PDF在多个标准中的表现优异,例如:
| 引擎 | 整体准确率 | 阅读顺序 | 表格 | 标题 |
|---|---|---|---|---|
| opendataloader hybrid | 0.90 | 0.94 | 0.93 | 0.83 |
| opendataloader | 0.72 | 0.91 | 0.49 | 0.76 |
| 其他 | ... | ... | ... | ... |
这些数字表明OpenDataLoader PDF具有行业领先的提取能力。
5.2 JSON输出示例
以下是用OpenDataLoader PDF提取的JSON格式输出示例,包含每个元素的详细信息:
json
{
"type": "heading",
"id": 42,
"level": "Title",
"page number": 1,
"bounding box": [72.0, 700.0, 540.0, 730.0],
"content": "Introduction"
}每个元素都带有唯一标识符、页码和边界框信息,便于后续的数据处理与引用。
6. 同类项目对比
与OpenDataLoader PDF类似的开源项目还包括:
- Docling:专注于Markdown、JSON格式输出,处理速度较快,但不支持元素的边界框输出。
- Marker:提供基础的PDF解析功能,但需要GPU支持,处理速度较慢。
- PymuPDF4llm:速度快,但在表格和标题的准确性上表现一般,而OpenDataLoader PDF在这些方面具有明显优势。
OpenDataLoader PDF以其全面的功能和优异的性能成为PDF数据提取领域的重要工具,尤其适用于需要高精准度和复杂处理的场景。
总结
OpenDataLoader PDF通过强大的功能和灵活的应用场景,充分满足用户在PDF数据提取、可访问性和自动化处理等方面的需求。无论是学术研究、法律文件还是教育资料,这一工具都能提供可靠的支持与帮助。预计在未来的自动标记功能上线后,更将推动PDF可访问性的进一步发展。