提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
SpringAI的学习笔记
一、非重点前置
embedding:将一长串文本转换成多维向量,比如1024维,然后通过余弦不等式计算相似度,可以用于做推荐系统。相关不重要的资料,是将演员简介全部转换为向量,然后新用户点击后,寻找和他加权平均向量链值最接近的用户,推荐新用户没看过的,即用embedding实现协同过滤。
RAG:将知识库前篇后匹配用户问题,并返回
二、重点
1.手写RAG
1.chunk划分适中,设置为200-500,过大导致内容都在一个chunk,回答也集中在某个chunk,丢失细节;过小导致可能会丢失上下文信息

2.减小相似度,将更多的chunk返回给模型,或者topN多拿一些
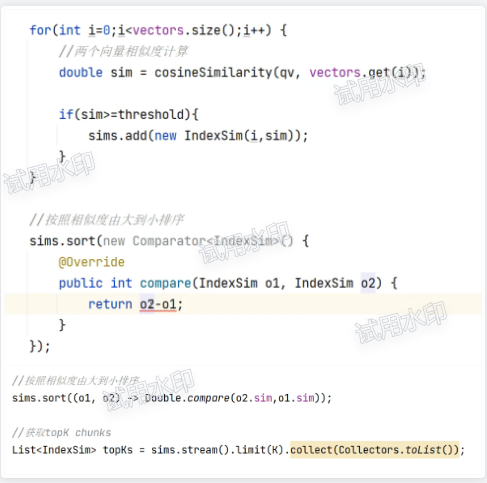
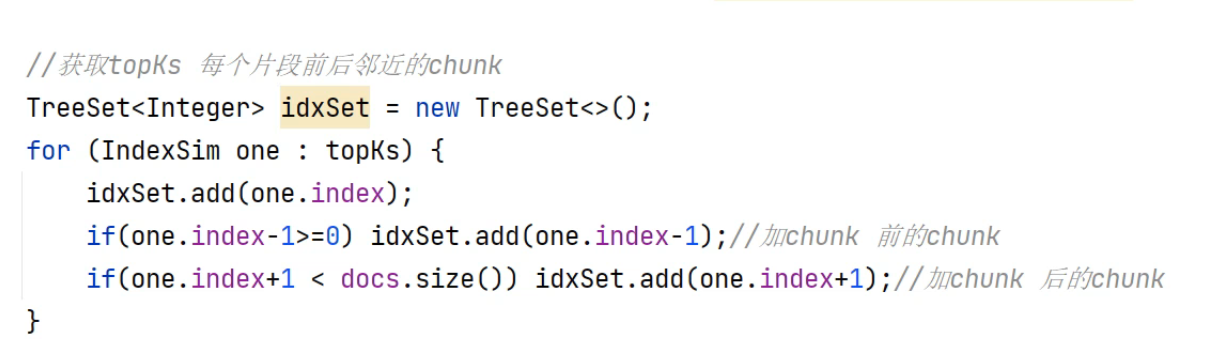
3.手动获取相邻片段
2.RAG的API使用
分两种,一种就是questionAndAnswer,另一种可以带上下文RetrivalArgument
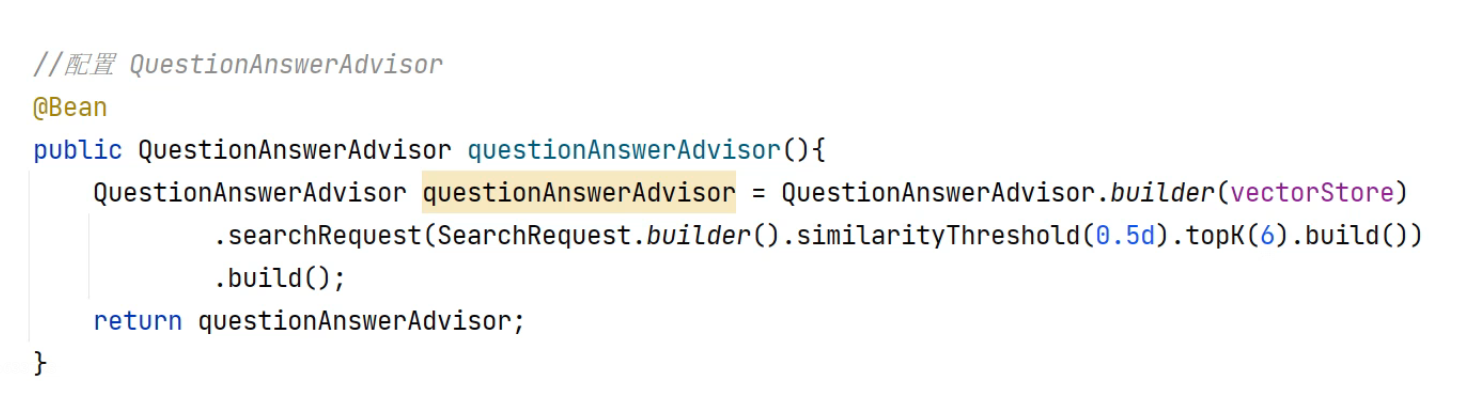
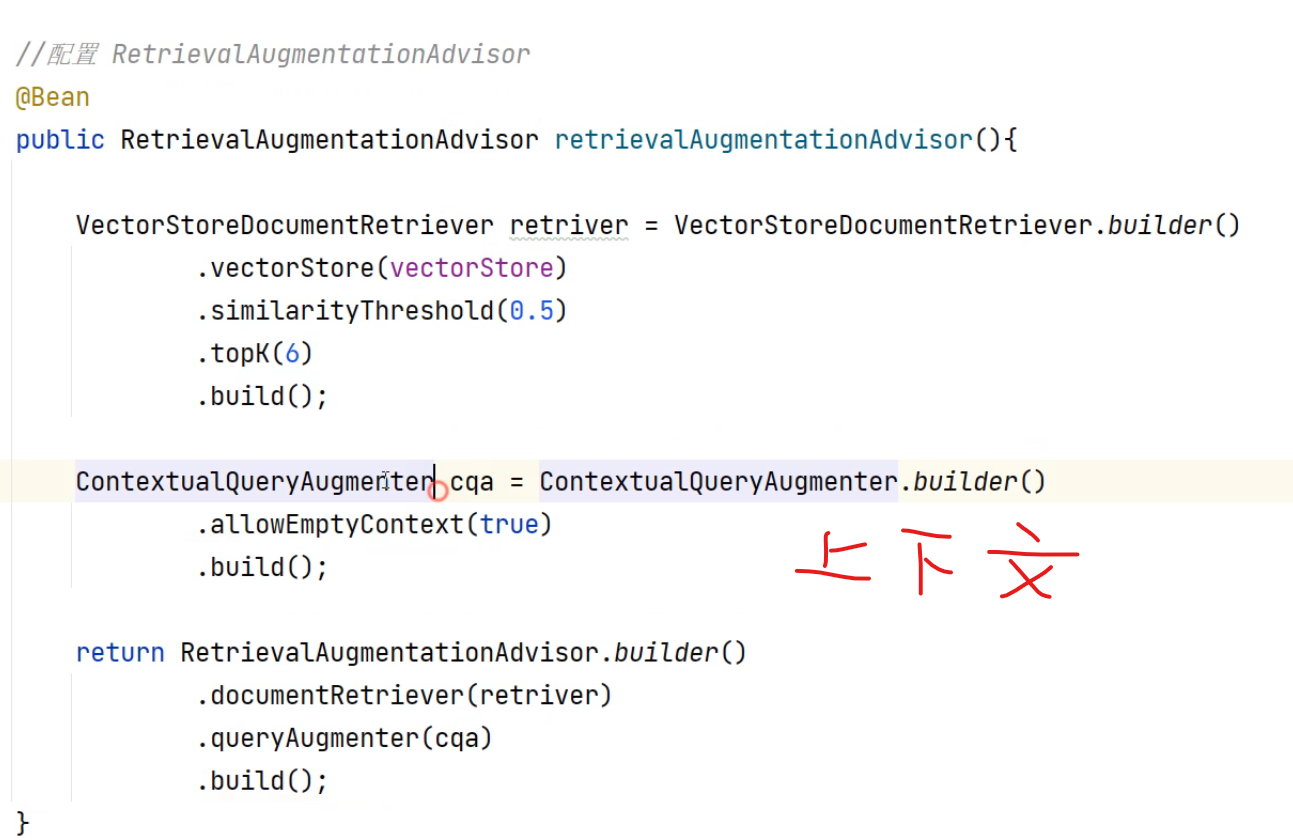
实际使用如果需要AI严格按照知识库来回答,还是要调小相似度,让尽可能多的chunk返回给模型,回答效果才能比较好。
3.MCP协议
如果有更换模型的考虑,可能在编写开始就要考虑遵循MCP协议。MCP协议是大模型和调用工具间的规范。
- 单机
注:client端执行server端指定目录下的jar包,来实现调用
server端

client端
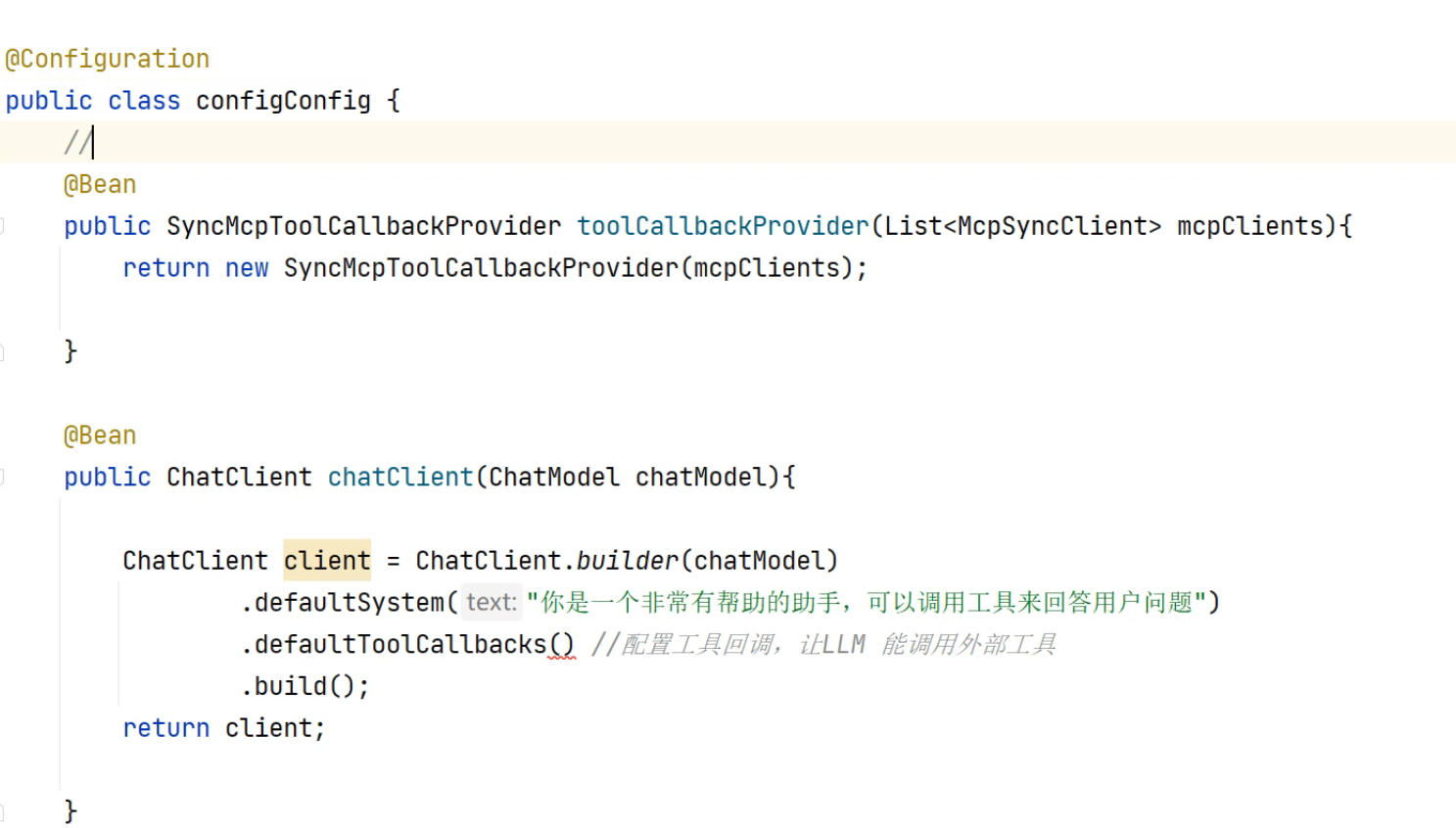
- 远程
代码层几乎一样,只是修改了pom文件
总结
如果是刚开始,注意应该放在embedding和RAG,然后如果想要手写的工具能够被多个模型复用,就注意一下MCP,就这些。