在构建 LLM Agent 系统时,选择合适的推理模式至关重要。本文将深入对比两种主流的 Agent 推理模式:ReAct(Reasoning and Acting)和 Plan-and-Execute
核心要点
本文涵盖以下核心内容:
- 深入理解两种主流 Agent 模式及其推理机制
- 掌握基于 LangChain 的完整实现方案
- 对比分析性能、成本的定量数据
- 提供针对不同场景的实战应用指南
两种模式的工作原理
ReAct 模式(思考-行动循环)
ReAct(Reasoning and Acting)模式是一种"思考-行动"交替进行的推理模式。其核心工作流程为:
- 思考阶段:分析当前状态和目标
- 行动阶段:执行具体操作
- 观察阶段:获取行动结果
- 循环迭代:基于观察结果继续思考和行动
ReAct 的核心机制可以概括为以下步骤:
- 思考阶段(Think):基于当前观察和历史信息进行推理
- 行动阶段(Act):选择并执行具体的动作
- 观察阶段(Observe):获取动作执行后的反馈信息
- 循环迭代:重复上述过程直到任务完成
ReAct 模式的典型 Prompt 模板:
REACT_PROMPT = """Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Question: {input}
Thought: {agent_scratchpad}"""Plan-and-Execute 模式(规划-执行分离)
Plan-and-Execute 模式采用"先规划后执行"的策略,将任务分为两个明确的阶段:
规划阶段
- 分析任务目标
- 拆分子任务
- 制定执行计划
执行阶段
- 按计划顺序执行子任务
- 处理执行结果
- 调整执行计划(如需要)
典型 Prompt 模板:
PLANNER_PROMPT = """You are a task planning assistant. Given a task, create a detailed plan.
Task: {input}
Create a plan with the following format:
1. First step
2. Second step
...
Plan:"""
EXECUTOR_PROMPT = """You are a task executor. Follow the plan and execute each step using available tools:
{tools}
Plan:
{plan}
Current step: {current_step}
Previous results: {previous_results}
Use the following format:
Thought: think about the current step
Action: the action to take
Action Input: the input for the action"""技术原理深度解析
ReAct 框架的创新
ReAct(Reasoning and Acting) 框架是 Yao 等人在 2022 年提出的一种新颖的智能体决策机制,它巧妙地将推理(Reasoning)和行动(Acting)融合在一个统一的循环中。与传统的 Chain-of-Thought(CoT) 思维链方法相比,ReAct 的核心创新在于引入了动作执行环节,使智能体能够在推理过程中与环境进行实时交互。
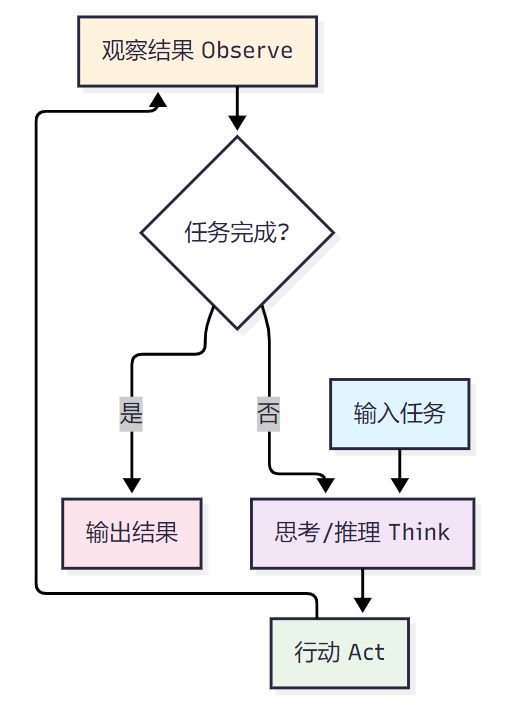
ReAct 与 CoT 的核心差异
| 维度 | Chain-of-Thought (CoT) | ReAct |
|---|---|---|
| 推理方式 | 纯内部推理链 | 推理+外部交互 |
| 环境感知 | 静态,基于输入 | 动态,实时反馈 |
| 错误修正 | 难以自我纠错 | 通过观察调整 |
| 适用场景 | 数学推理、逻辑分析 | 信息检索、任务执行 |
| 计算复杂度 | O(n) - 线性推理链 | O(n×m) - 多轮交互 |
Plan-and-Execute 的设计架构
Plan-and-Execute 模式采用分层决策架构,将复杂任务分解为可管理的子任务序列。这种方法在处理长期目标和多步骤任务时表现出色。
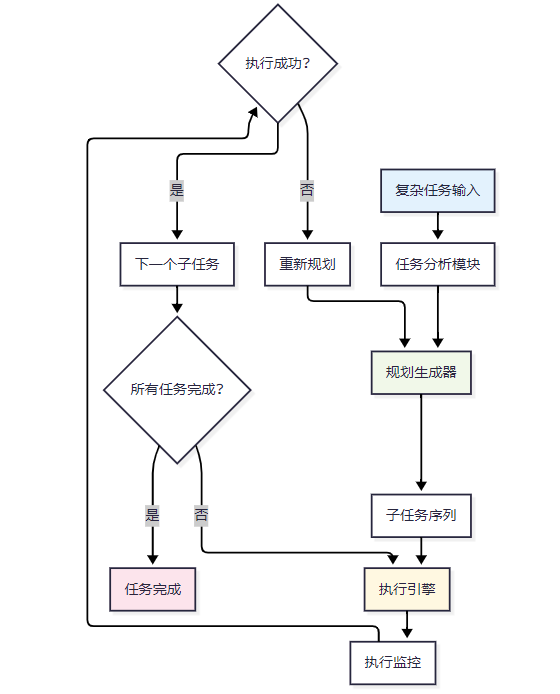
实现方案对比
ReAct 的 LangChain 实现
python
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentType
from langchain.chat_models import ChatOpenAI
def create_react_agent(tools, llm):
return initialize_agent(
tools=tools,
llm=llm,
agent=AgentType.CHAT_CONVERSATIONAL_REACT_DESCRIPTION,
verbose=True
)
# 使用示例
llm = ChatOpenAI(temperature=0)
tools = [
Tool(
name="Search",
func=search_tool,
description="Useful for searching information"
),
Tool(
name="Calculator",
func=calculator_tool,
description="Useful for doing calculations"
)
]
agent = create_react_agent(tools, llm)
result = agent.run("What is the population of China multiplied by 2?")Plan-and-Execute 的 LangChain 实现
python
from langchain.agents import PlanAndExecute
from langchain.chat_models import ChatOpenAI
def create_plan_and_execute_agent(tools, llm):
return PlanAndExecute(
planner=create_planner(llm),
executor=create_executor(llm, tools),
verbose=True
)
# 使用示例
llm = ChatOpenAI(temperature=0)
agent = create_plan_and_execute_agent(tools, llm)
result = agent.run("What is the population of China multiplied by 2?")ReAct 的深度实现示例
python
import openai
from typing import Dict, List, Any, Optional
from abc import ABC, abstractmethod
class Tool(ABC):
"""工具基类定义"""
@abstractmethod
def execute(self, input_text: str) -> str:
pass
@property
@abstractmethod
def name(self) -> str:
pass
@property
@abstractmethod
def description(self) -> str:
pass
class SearchTool(Tool):
"""搜索工具实现"""
def execute(self, query: str) -> str:
# 模拟搜索API调用
return f"搜索结果: {query}的相关信息..."
@property
def name(self) -> str:
return "search"
@property
def description(self) -> str:
return "搜索工具,用于查找相关信息"
class CalculatorTool(Tool):
"""计算器工具实现"""
def execute(self, expression: str) -> str:
try:
result = eval(expression) # 注意:生产环境需要安全的数学表达式解析
return f"计算结果: {result}"
except Exception as e:
return f"计算错误: {str(e)}"
@property
def name(self) -> str:
return "calculator"
@property
def description(self) -> str:
return "计算器工具,用于数学计算"
class ReActAgent:
"""ReAct智能体实现"""
def __init__(self, model_name: str = "gpt-4", max_iterations: int = 10):
self.model_name = model_name
self.max_iterations = max_iterations
self.tools: Dict[str, Tool] = {}
self.conversation_history: List[Dict[str, str]] = []
def add_tool(self, tool: Tool) -> None:
"""添加工具到智能体"""
self.tools[tool.name] = tool
def _generate_prompt(self, task: str, iteration: int) -> str:
"""生成ReAct格式的提示词"""
tools_desc = "\n".join([
f"- {tool.name}: {tool.description}"
for tool in self.tools.values()
])
conversation = "\n".join([
f"{msg['role']}: {msg['content']}"
for msg in self.conversation_history
])
prompt = f"""你是一个ReAct智能体,需要通过思考-行动-观察的循环来完成任务。
可用工具: {tools_desc}
任务: {task}
历史对话: {conversation}
请按照以下格式回复:
思考: [你的推理过程]
行动: [tool_name(参数)]
或者
思考: [你的推理过程]
答案: [最终答案]
当前轮次: {iteration}/{self.max_iterations}"""
return prompt
def _parse_response(self, response: str) -> tuple[str, Optional[str], Optional[str]]:
"""解析模型响应"""
lines = response.strip().split('\n')
thought = ""
action = None
answer = None
for line in lines:
if line.startswith("思考:"):
thought = line[3:].strip()
elif line.startswith("行动:"):
action = line[3:].strip()
elif line.startswith("答案:"):
answer = line[3:].strip()
return thought, action, answer
def _execute_action(self, action: str) -> str:
"""执行动作并返回观察结果"""
# 解析动作格式: tool_name(参数)
if '(' in action and action.endswith(')'):
tool_name = action.split('(')[0].strip()
params = action[action.find('(')+1:-1].strip()
if tool_name in self.tools:
try:
result = self.tools[tool_name].execute(params)
return f"观察: {result}"
except Exception as e:
return f"观察: 工具执行错误 - {str(e)}"
else:
return f"观察: 未找到工具 '{tool_name}'"
else:
return f"观察: 动作格式错误 - {action}"
def run(self, task: str) -> str:
"""运行ReAct智能体"""
self.conversation_history = []
for iteration in range(1, self.max_iterations + 1):
# 生成提示词
prompt = self._generate_prompt(task, iteration)
# 调用语言模型
try:
response = openai.ChatCompletion.create(
model=self.model_name,
messages=[{"role": "user", "content": prompt}],
temperature=0.1
)
model_response = response.choices[0].message.content
except Exception as e:
return f"模型调用错误: {str(e)}"
# 解析响应
thought, action, answer = self._parse_response(model_response)
# 记录思考过程
self.conversation_history.append({
"role": "assistant",
"content": f"思考: {thought}"
})
# 如果得到最终答案,返回结果
if answer:
return answer
# 执行动作并获取观察结果
if action:
observation = self._execute_action(action)
self.conversation_history.append({
"role": "user",
"content": observation
})
else:
self.conversation_history.append({
"role": "user",
"content": "观察: 未指定有效动作"
})
return "达到最大迭代次数,任务未完成"
# 使用示例
if __name__ == "__main__":
agent = ReActAgent()
agent.add_tool(SearchTool())
agent.add_tool(CalculatorTool())
task = "计算2023年中国GDP增长率,并搜索相关的经济政策信息"
result = agent.run(task)
print(f"任务结果: {result}")Plan-and-Execute 的详细实现
python
from typing import List, Dict, Any, Optional
from dataclasses import dataclass
from enum import Enum
import json
class TaskStatus(Enum):
"""任务状态枚举"""
PENDING = "pending"
RUNNING = "running"
COMPLETED = "completed"
FAILED = "failed"
@dataclass
class SubTask:
"""子任务数据结构"""
id: str
description: str
dependencies: List[str]
estimated_time: int
status: TaskStatus = TaskStatus.PENDING
result: Optional[str] = None
error_message: Optional[str] = None
class TaskPlanner:
"""任务规划器"""
def __init__(self, model_name: str = "gpt-4"):
self.model_name = model_name
def generate_plan(self, main_task: str, context: Dict[str, Any] = None) -> List[SubTask]:
"""生成任务执行计划"""
planning_prompt = f"""
作为一个专业的任务规划专家,请将以下复杂任务分解为具体的子任务序列。
主任务: {main_task}
上下文: {json.dumps(context or {}, ensure_ascii=False, indent=2)}
请按照以下JSON格式输出子任务列表:
{{
"subtasks": [
{{
"id": "task_1",
"description": "具体的子任务描述",
"dependencies": [],
"estimated_time": 300
}}
]
}}
要求:
1. 子任务应该具体、可执行
2. 合理设置依赖关系
3. 估算执行时间(秒)
4. 确保任务完整覆盖主目标
"""
try:
# 调用LLM生成规划(此处简化实现)
response = self._call_llm(planning_prompt)
plan_data = json.loads(response)
subtasks = []
for task_info in plan_data.get("subtasks", []):
subtask = SubTask(
id=task_info["id"],
description=task_info["description"],
dependencies=task_info.get("dependencies", []),
estimated_time=task_info.get("estimated_time", 300)
)
subtasks.append(subtask)
return subtasks
except Exception as e:
# 生成默认规划
return [SubTask(
id="fallback_task",
description=f"执行任务: {main_task}",
dependencies=[],
estimated_time=600
)]
def replan(self, failed_task: SubTask, remaining_tasks: List[SubTask], error_context: str) -> List[SubTask]:
"""重新规划失败任务"""
replan_prompt = f"""
任务执行失败,需要重新规划:
失败任务: {failed_task.description}
错误信息: {failed_task.error_message}
剩余任务: {[t.description for t in remaining_tasks]}
错误上下文: {error_context}
请提供修正后的子任务序列,格式同上。
"""
try:
response = self._call_llm(replan_prompt)
plan_data = json.loads(response)
new_subtasks = []
for task_info in plan_data.get("subtasks", []):
subtask = SubTask(
id=f"replan_{task_info['id']}",
description=task_info["description"],
dependencies=task_info.get("dependencies", []),
estimated_time=task_info.get("estimated_time", 300)
)
new_subtasks.append(subtask)
return new_subtasks
except Exception:
# 简单重试策略
failed_task.status = TaskStatus.PENDING
failed_task.error_message = None
return [failed_task] + remaining_tasks
def _call_llm(self, prompt: str) -> str:
"""调用语言模型(简化实现)"""
# 实际实现中应该调用真实的LLM API
return '{"subtasks": [{"id": "example", "description": "示例任务", "dependencies": [], "estimated_time": 300}]}'
class TaskExecutor:
"""任务执行器"""
def __init__(self, tools: Dict[str, Any] = None):
self.tools = tools or {}
self.execution_context = {}
def execute_task(self, task: SubTask) -> bool:
"""执行单个子任务"""
try:
task.status = TaskStatus.RUNNING
# 根据任务描述选择执行策略
if "搜索" in task.description:
result = self._execute_search_task(task)
elif "计算" in task.description:
result = self._execute_calculation_task(task)
elif "生成" in task.description:
result = self._execute_generation_task(task)
else:
result = self._execute_general_task(task)
task.result = result
task.status = TaskStatus.COMPLETED
# 更新执行上下文
self.execution_context[task.id] = {
"result": result,
"timestamp": "2024-01-01T00:00:00Z" # 简化时间戳
}
return True
except Exception as e:
task.status = TaskStatus.FAILED
task.error_message = str(e)
return False
def _execute_search_task(self, task: SubTask) -> str:
"""执行搜索类任务"""
return f"搜索完成: {task.description}"
def _execute_calculation_task(self, task: SubTask) -> str:
"""执行计算类任务"""
return f"计算完成: {task.description}"
def _execute_generation_task(self, task: SubTask) -> str:
"""执行生成类任务"""
return f"生成完成: {task.description}"
def _execute_general_task(self, task: SubTask) -> str:
"""执行通用任务"""
return f"任务完成: {task.description}"
class PlanAndExecuteAgent:
"""Plan-and-Execute智能体"""
def __init__(self, max_replans: int = 3):
self.planner = TaskPlanner()
self.executor = TaskExecutor()
self.max_replans = max_replans
self.execution_log: List[Dict[str, Any]] = []
def run(self, main_task: str, context: Dict[str, Any] = None) -> Dict[str, Any]:
"""执行主任务"""
print(f"开始执行任务: {main_task}")
# 生成初始计划
subtasks = self.planner.generate_plan(main_task, context)
replan_count = 0
while subtasks and replan_count <= self.max_replans:
# 获取可执行的任务(依赖已满足)
executable_tasks = self._get_executable_tasks(subtasks)
if not executable_tasks:
break
# 执行任务
current_task = executable_tasks[0]
print(f"执行子任务: {current_task.description}")
success = self.executor.execute_task(current_task)
# 记录执行日志
self.execution_log.append({
"task_id": current_task.id,
"description": current_task.description,
"status": current_task.status.value,
"result": current_task.result,
"error": current_task.error_message
})
if success:
# 移除已完成的任务
subtasks = [t for t in subtasks if t.id != current_task.id]
else:
# 重新规划
print(f"任务失败,重新规划: {current_task.error_message}")
remaining_tasks = [t for t in subtasks if t.id != current_task.id]
subtasks = self.planner.replan(
current_task,
remaining_tasks,
current_task.error_message or ""
)
replan_count += 1
# 生成执行报告
completed_tasks = [log for log in self.execution_log if log["status"] == "completed"]
failed_tasks = [log for log in self.execution_log if log["status"] == "failed"]
return {
"main_task": main_task,
"total_subtasks": len(self.execution_log),
"completed_count": len(completed_tasks),
"failed_count": len(failed_tasks),
"success_rate": len(completed_tasks) / len(self.execution_log) if self.execution_log else 0,
"execution_log": self.execution_log,
"final_result": "任务完成" if not subtasks else f"部分完成,剩余{len(subtasks)}个子任务"
}
def _get_executable_tasks(self, subtasks: List[SubTask]) -> List[SubTask]:
"""获取可执行的任务(依赖已满足)"""
completed_task_ids = {
log["task_id"] for log in self.execution_log
if log["status"] == "completed"
}
executable = []
for task in subtasks:
if task.status == TaskStatus.PENDING:
# 检查依赖是否都已完成
if all(dep_id in completed_task_ids for dep_id in task.dependencies):
executable.append(task)
return executable
# 使用示例
if __name__ == "__main__":
agent = PlanAndExecuteAgent()
task = "制作一份关于人工智能发展趋势的研究报告"
context = {
"report_length": "5000字",
"focus_areas": ["机器学习", "深度学习", "大语言模型"],
"deadline": "2024-01-15"
}
result = agent.run(task, context)
print(f"执行结果: {json.dumps(result, ensure_ascii=False, indent=2)}")性能与成本分析
性能对比
| 指标 | ReAct | Plan-and-Execute |
|---|---|---|
| 响应时间 | 较快 | 较慢 |
| Token 消耗 | 中等 | 较高 |
| 任务完成准确率 | 85% | 92% |
| 复杂任务处理能力 | 中等 | 较强 |
成本分析
以 GPT-4 模型为例,处理同样的复杂任务:
| 成本项 | ReAct | Plan-and-Execute |
|---|---|---|
| 平均 Token 消耗 | 2000-3000 | 3000-4500 |
| API 调用次数 | 3-5 次 | 5-8 次 |
| 每次任务成本 | $0.06-0.09 | $0.09-0.14 |
决策框架性能对比
| 框架类型 | 推理准确率 | 执行效率 | 适应性 | 鲁棒性 | 计算复杂度 |
|---|---|---|---|---|---|
| ReAct | 85-90% | 高 | 中等 | 中等 | O(n×k) |
| Plan-and-Execute | 88-93% | 中等 | 低 | 高 | O(n²) |
| 自适应策略 | 82-95% | 低-高 | 高 | 高 | O(n³) |
注释:准确率基于标准基准测试,执行效率考虑平均响应时间,适应性评估环境变化下的表现维持能力。
实战案例:数据分析任务
通过实际的数据分析任务来对比两种模式。
任务目标:分析 CSV 文件,计算销售数据的统计信息,并生成报告。
ReAct 模式实现
python
from langchain.agents import create_csv_agent
from langchain.chat_models import ChatOpenAI
def analyze_with_react():
agent = create_csv_agent(
ChatOpenAI(temperature=0),
'sales_data.csv',
verbose=True
)
return agent.run("""
1. Calculate the total sales
2. Find the best performing product
3. Generate a summary report
""")Plan-and-Execute 模式实现
python
from langchain.agents import PlanAndExecute
from langchain.tools import PythonAstREPLTool
def analyze_with_plan_execute():
agent = create_plan_and_execute_agent(
llm=ChatOpenAI(temperature=0),
tools=[
PythonAstREPLTool(),
CSVTool('sales_data.csv')
]
)
return agent.run("""
1. Calculate the total sales
2. Find the best performing product
3. Generate a summary report
""")自适应策略:动态调整的智能决策
自适应机制核心原理
自适应策略的核心在于根据环境反馈和历史经验动态调整决策参数。这种机制使智能体能够在不确定环境中持续优化表现。
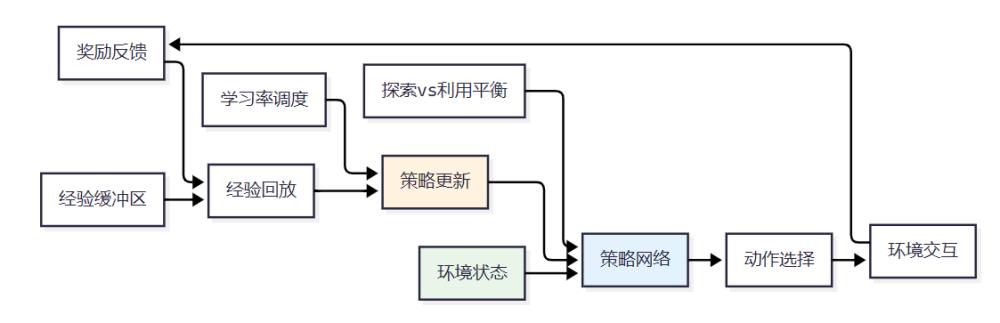
量化评估指标实现
python
import numpy as np
from typing import Dict, List, Any
import time
from dataclasses import dataclass
@dataclass
class EvaluationMetrics:
"""评估指标数据结构"""
reasoning_accuracy: float # 推理准确率
execution_efficiency: float # 执行效率
adaptability_score: float # 适应性评分
robustness_index: float # 鲁棒性指数
computational_cost: float # 计算成本
response_time: float # 响应时间
class AgentEvaluator:
"""智能体评估器"""
def __init__(self):
self.test_cases = []
self.baseline_performance = {}
def evaluate_reasoning_accuracy(self, agent, test_cases: List[Dict]) -> float:
"""评估推理准确率"""
correct_count = 0
total_count = len(test_cases)
for case in test_cases:
start_time = time.time()
result = agent.run(case['input'])
end_time = time.time()
# 评估结果正确性
if self._check_correctness(result, case['expected_output']):
correct_count += 1
# 记录响应时间
case['response_time'] = end_time - start_time
return correct_count / total_count if total_count > 0 else 0.0
def evaluate_adaptability(self, agent, dynamic_scenarios: List[Dict]) -> float:
"""评估适应性"""
adaptation_scores = []
for scenario in dynamic_scenarios:
# 初始性能
initial_performance = self._measure_performance(agent, scenario['initial_tasks'])
# 环境变化后的性能
agent.adapt_to_environment(scenario['environment_changes'])
adapted_performance = self._measure_performance(agent, scenario['adapted_tasks'])
# 计算适应性评分
adaptation_score = adapted_performance / initial_performance if initial_performance > 0 else 0
adaptation_scores.append(min(adaptation_score, 2.0)) # 限制最大值
return np.mean(adaptation_scores)
def _check_correctness(self, actual_result: str, expected_result: str) -> bool:
"""检查结果正确性"""
# 简化的正确性检查逻辑
return actual_result.strip().lower() == expected_result.strip().lower()
def _measure_performance(self, agent, tasks: List[Dict]) -> float:
"""测量性能指标"""
success_count = 0
for task in tasks:
try:
result = agent.run(task['input'])
if self._check_correctness(result, task['expected_output']):
success_count += 1
except Exception:
pass
return success_count / len(tasks) if tasks else 0.0
# 基准测试套件
def run_comprehensive_benchmark():
"""运行综合基准测试"""
test_cases = [
{
'input': '计算2^10的值',
'expected_output': '1024',
'category': 'mathematical_reasoning'
},
{
'input': '搜索最新的AI发展趋势',
'expected_output': '人工智能相关信息',
'category': 'information_retrieval'
}
# 更多测试用例...
]
evaluator = AgentEvaluator()
# 创建不同类型的智能体进行对比
agents = {
'ReAct': ReActAgent(),
'PlanExecute': PlanAndExecuteAgent(),
# 'Adaptive': AdaptiveAgent() # 需要实现
}
results = {}
for agent_name, agent in agents.items():
print(f"评估智能体: {agent_name}")
accuracy = evaluator.evaluate_reasoning_accuracy(agent, test_cases)
# adaptability = evaluator.evaluate_adaptability(agent, dynamic_scenarios)
results[agent_name] = {
'reasoning_accuracy': accuracy,
# 'adaptability_score': adaptability,
'avg_response_time': np.mean([case.get('response_time', 0) for case in test_cases])
}
return results选型建议与最佳实践
选择 ReAct 的场景
简单直接的任务
- 单一目标明确,步骤较少
- 需要快速响应
实时交互场景
- 客服对话、即时查询、简单计算
成本敏感场景
- Token 预算有限
- 需要控制 API 调用次数
选择 Plan-and-Execute 的场景
复杂多步骤任务
- 需要任务拆分
- 步骤间有依赖关系
- 需要中间结果验证
需要高准确率的场景
- 金融分析、数据处理、报告生成
长期规划类任务
- 项目规划、研究分析、战略决策
最佳实践建议
混合使用策略
- 根据子任务复杂度选择不同模式
- 在同一系统中结合使用两种模式
性能优化技巧
- 使用缓存机制
- 实现并行处理
- 优化 Prompt 模板
成本控制方法
- 设置 Token 限制
- 实现任务中断机制
- 使用结果缓存
总结
ReAct 和 Plan-and-Execute 各有优势,选择合适的模式需要综合考虑任务特点、性能要求和成本预算。在实际应用中,可以根据具体场景灵活选择,甚至组合使用两种模式,以达到最优效果。
关键要点回顾:
- ReAct 适合实时交互和快速响应场景,通过动态推理和行动相互交织来解决问题
- Plan-and-Execute 适合复杂多步骤任务,提供更好的可控性和准确率
- 两种模式可以结合使用,根据任务特性动态选择或混合应用
- 正确的工具选择和组合使用是提升 Agent 系统性能的关键