往期回顾
如何速成LLM以伪装成一个AI研究者(1)------循环,卷积,编解码器,注意力,Transformer
如何速成LLM以伪装成一个AI研究者(2)------Pre-LN,KV-Cache优化,MoE
如何速成LLM以伪装成一个AI研究者(3)------预训练,监督微调,强化学习RLHF/DPO
如何速成LLM以伪装成一个AI研究者(4)------PPO,GRPO,DAPO,GSPO
如何速成LLM以伪装成一个AI研究者(5)------显存估算,显卡选择
免责声明:作者也是伪装的,有错漏属于正常现象,欢迎评论指正。
参数高效微调PEFT
如果你不够富有,动辄几十上百B的模型是肯定没有显存来训的。此时就需要更有性价比的选择------参数高效微调(Parameter efficient fine-tuning,PEFT)。通过减少进入训练的参数量,可以显著减少训练中梯度参数+优化器状态占用的显存,并且也能达到和全量微调相近的性能效果。
主流的参数高效微调方法有三种:LoRA,Adapter和prompt-tuning。其中,LoRA是被使用最多的方法------性能最接近全量微调,训练参数量极低,不引入推理延迟,都是它的优势所在。
LoRA
LoRA: Low-Rank Adaptation of Large Language Models
LoRA(Low-rank Adaption) 的原理一张图就可以概括:
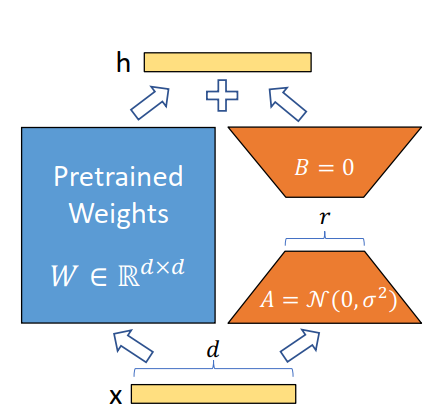
假设原始的权重矩阵为 W W W,对 W W W进行更新,就相当于将 W W W变为 W ′ = W + Δ W W'=W+\Delta W W′=W+ΔW。而LoRA的核心思想基于一个观察:在针对特定下游任务进行微调时,模型权重的更新矩阵 Δ W \Delta W ΔW 往往具有 低秩(low-rank) 特性。这意味着,尽管原始权重矩阵 W ∈ R d × k W \in \mathbb{R}^{d \times k} W∈Rd×k 可能很大( d d d 和 k k k 可达数千甚至数万),但有效的任务适配信息可以压缩到一个低维子空间中。
具体而言,LoRA 不直接微调原始权重 W W W,而是冻结 W W W,并引入一对可训练的低秩矩阵 A ∈ R d × r A \in \mathbb{R}^{d \times r} A∈Rd×r 和 B ∈ R r × k B \in \mathbb{R}^{r \times k} B∈Rr×k,其中秩 r ≪ min ( d , k ) r \ll \min(d, k) r≪min(d,k)(通常 r r r 取 4、8、16 等)。前向传播时,将低秩更新加到原始权重上:
h = W x + Δ W x = W x + ( B A ) x h = Wx + \Delta W x = Wx + (BA)x h=Wx+ΔWx=Wx+(BA)x
其中 B B B 和 A A A 分别用随机高斯初始化和零初始化,确保训练开始时 Δ W = 0 \Delta W = 0 ΔW=0,模型输出与原始预训练模型一致。训练过程中,只更新 A A A 和 B B B 的参数,而 W W W 保持不变。
为什么有效?
- 参数高效 :可训练参数从 d × k d \times k d×k 降至 r × ( d + k ) r \times (d + k) r×(d+k),通常减少 2~3 个数量级,极大节省显存。
- 无推理延迟 :训练完成后,可将 B A BA BA 与 W W W 合并( W ′ = W + B A W' = W + BA W′=W+BA),得到一个与原始模型结构、计算量完全相同的模型,无需额外计算。
- 模块化与组合性 :不同的 LoRA 适配器(即不同的 A , B A, B A,B 对)可针对不同任务训练,并灵活加载、合并或加权组合,实现多任务适配。
神奇的LoRA融合
听到LoRA这个词最多的应用领域,应该就是Stable Diffusion图像生成了。多个LoRA的融合能够兼顾多种微调的效果------例如,一个LoRA微调了"水手服"这个服装的图片,另一个LoRA则正对某种角色形象进行微调。当两者融合时,就可以获得"特定角色穿水手服"的图片!(图源:Multi-LoRA Composition for Image Generation)
好吧,实际上全量微调的模型权重融合也可以有这个效果------可是,组合LoRA可"轻量"太多了!

使用LoRA的时候,一般微调哪些参数?
在 多头自注意力机制 中,会把输入 X X X通过投影矩阵 W Q , W V W_Q, W_V WQ,WV和 W K W_K WK投影成 Q = W Q X Q=W_QX Q=WQX, V = W V X V=W_VX V=WVX和 K = W K X K=W_KX K=WKX。最后多头拼接后,还会再乘以一个 W O W_O WO得到输出结果。这些参数中:
通用起点:可以先只微调 W Q , W V W_Q, W_V WQ,WV
进阶1:如果觉得起点效果还不够,可以微调 W Q , W V , W K , W O W_Q, W_V, W_K, W_O WQ,WV,WK,WO
进阶2:可以不止微调Attention模块,把FFN的MLP一起微调了
根据预期效果和资源,实验性地权衡即可。
如何将多个LoRA进行融合?
如果秩相同,直接将参数简单加权平均就行。通过LoRA融合,可以使模型兼顾多个不同的微调效果。
此外还有一些 模型融合 相关的算法,可以自行查阅。例如:Merging LoRAs like Playing LEGO: Pushing the Modularity of LoRA to Extremes Through Rank-Wise Clustering
如果秩不同,也需要使用一些算法来进行合并,会略麻烦。
Adapter和Prompt-tuning
然后我们再提一嘴Adapter和Prompt-tuning。
Adapter
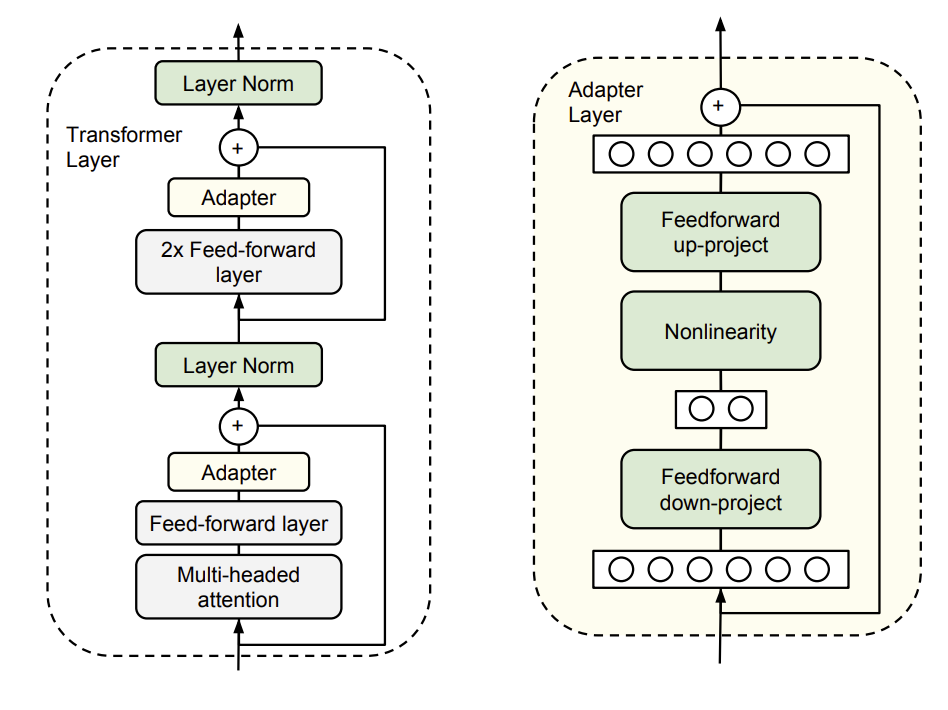
Adapter(适配器)的思路非常直观:在预训练模型的某些层(通常是Transformer的FFN层之后)插入一个轻量的、可训练的"插件"模块,而冻结原始模型的所有参数。训练时,只更新这些Adapter模块的参数。
典型结构:一个Adapter通常由两个前馈层(feed-forward)和一个非线性激活函数(如ReLU)组成,中间有一个瓶颈(bottleneck)维度,以控制参数量。其数学形式可以表示为:
Adapter ( x ) = x + W down ⋅ ReLU ( W up ⋅ x ) \text{Adapter}(x) = x + W_{\text{down}} \cdot \text{ReLU}(W_{\text{up}} \cdot x) Adapter(x)=x+Wdown⋅ReLU(Wup⋅x)
其中 W down ∈ R d × r W_{\text{down}} \in \mathbb{R}^{d \times r} Wdown∈Rd×r 和 W up ∈ R r × d W_{\text{up}} \in \mathbb{R}^{r \times d} Wup∈Rr×d, r ≪ d r \ll d r≪d 是瓶颈维度。输入 x x x 先经过一个降维投影 W up W_{\text{up}} Wup,再经过ReLU激活,最后通过升维投影 W down W_{\text{down}} Wdown 恢复到原始维度,并与原始输入 x x x 相加(残差连接)。
由于增加了额外的计算层(即使很小),Adapter微调后的模型会带来一定的推理延迟。各种意义上它都不如LoRA常用,但是在一些模块化任务上可能会有奇效 (指你总是微调不出效果,病急乱投医的时候也可以试试)。
Prompt-tuning
Prompt-tuning(提示调优)的思想是,学习一个prompt来教模型更好地理解任务------而不是修改模型的内部权重。具体地,它在在输入文本前拼接若干个可学习的向量(即软提示),然后在微调任务上训练这些软提示向量,并期待它们能"编码"到让模型完成任务的特定知识。
例如,对于情感分类任务,原始输入可能是"这部电影真好看。",经过Prompt-tuning后,输入可能变为:
[可学习向量1] [可学习向量2] ... [可学习向量k] 这部电影真好看。我们期待最终可学习向量能够帮助模型更好地理解"情感分类"任务。比如,它或许是一份任务说明书("情感分类就是识别情感的正负向......")或者一个任务指南("抓住评价性词汇......"),但实际上它的可解释性没有这么好,生成的是一份AI特供而不是给人看的任务说明书。
模型在训练过程中学会将这些软提示向量与"情感分类"这个任务关联起来。
优点:
- 参数极少:通常只增加几千到几万个参数(即软提示向量的数量 × 隐藏维度)。
- 完全无推理延迟:软提示只是额外的输入token,不增加模型计算量。
- 高度任务特定:可以为每个任务训练一套独立的软提示。
缺点:
- 效果依赖模型规模:在较小模型(<10B参数)上效果往往不如全量微调或LoRA,但在超大模型(>100B)上可以接近全量微调。
- 提示长度敏感:软提示的长度(即token数量)是一个需要调优的超参数。
- 可解释性差:这些软提示向量是连续空间中的点,人类难以理解其具体含义。
对比
| 方法 | 可训练参数占比 | 推理延迟 | 训练速度 | 典型效果 | 适用场景 |
|---|---|---|---|---|---|
| LoRA | 0.01%~1% | 无 | 快 | 接近全量微调 | 绝大多数下游任务,尤其是资源受限场景 |
| Adapter | 0.5%~5% | 有(轻微) | 中等 | 略低于LoRA | 需要模块化、多任务切换的场景 |
| Prompt-tuning | <0.01% | 无 | 很快 | 依赖模型规模(大模型效果好) | 超大模型(>100B)的轻量级适配,多任务学习 |
至于微调的时候怎么选......无脑先选LoRA就可以了,没效果再考虑其他的。
量化
精度
在存储中,浮点数数据类型通常有FP32,FP16或者BF16。其中,FP32(Float 32)是标准的IEEE 32-bit浮点数表示,其中8 bits被用于"指数",23 bits被用于"尾数", 1 bit则用于符号位。而FP16(Float 16)中,指数为5 bits,尾数是10 bits,这导致FP16的数值范围明显小于FP32。而BF16为8 bits指数,7 bits尾数的格式,它的大致数值范围和FP32相当,但是精度更差。
指数和尾数
浮点数使用科学计数法来表示,数值=尾数*10^指数
实验表明,在推理 过程中降低精度(例如将FP32的模型转化为FP16/BF16)往往没有明显的性能下降,还能做到大幅度的显存节约(从4bytes到2bytes,节省了一半)。而通过量化技术,可以做到进一步的节约,譬如说,8-bit量化,指的就是将模型数值量化到INT8,从而将显存占用减少到1/4。
一次量化是对一个张量 (譬如一个权重矩阵)单独进行的,不同张量间量化后的整数大小 无法 直接比较原始数值的相对大小。一般来说,量化后存储在显存的参数,还需要进行反量化回浮点数,才能再做矩阵乘法、激活之类的操作。量化和反量化都需要计算时间,因此量化会放慢推理速度,属于一种时间换空间的做法。而一些高性能推理引擎(如 TensorRT、高通 SNPE、TFLite、ONNX Runtime)则会用一些方式尽量减少运算中反量化的次数。
量化一般用于推理
zero-point量化
zero-point量化 是一种比较常见的量化方式,它的原理也非常地简单:假如原始的高精度浮点数范围在 m i n , m a x min, max min,max,量化后的数值范围为 q m i n , q m a x q_{min}, q_{max} qmin,qmax(8bit的话,一般是 0 , 255 0, 255 0,255)
首先计算出:
s c a l e = m a x − m i n q m a x − q m i n scale = \frac{max-min}{q_{max}-q_{min}} scale=qmax−qminmax−min
z e r o _ p o i n t = q m i n − r o u n d ( m i n s c a l e ) zero\point=q{min}-round(\frac{min}{scale}) zero_point=qmin−round(scalemin)
其中 s c a l e scale scale是缩放因子, z e r o _ p o i n t zero\_point zero_point则是原始张量中零点被映射到的位置。
然后对于每个高精度数值 x x x,做如下量化(round代表四舍五入):
Q ( x ) = r o u n d ( x s c a l e + z e r o _ p o i n t ) Q(x)=round(\frac{x}{scale}+zero\_point) Q(x)=round(scalex+zero_point)
譬如,原始向量为 ( 2.4 , − 1 , 0.6 , 1.1 ) (2.4, -1, 0.6, 1.1) (2.4,−1,0.6,1.1),需要量化到 0 , 255 , 0,255, 0,255,则 s c a l e = 3.4 255 = 1 / 75 , z e r o _ p o i n t = 75 scale=\frac{3.4}{255}=1/75, zero\_point=75 scale=2553.4=1/75,zero_point=75。 Q ( 2.4 ) = 255 , Q ( − 1 ) = 0 , Q ( 0.6 ) = 120 , Q ( 1.1 ) = r o u n d ( 157.5 ) = 158 Q(2.4)=255, Q(-1)=0, Q(0.6)=120, Q(1.1)=round(157.5)=158 Q(2.4)=255,Q(−1)=0,Q(0.6)=120,Q(1.1)=round(157.5)=158
反量化也同样比较简单, Q − 1 ( x i n t ) = ( x i n t − z e r o _ p o i n t ) ∗ s c a l e Q^{-1}(x_{int}) = (x_{int} - zero\_point) * scale Q−1(xint)=(xint−zero_point)∗scale。例如上式中, Q − 1 ( 158 ) = ( 158 − 75 ) / 75 ≈ 1.1067 Q^{-1}(158)=(158-75)/75\approx 1.1067 Q−1(158)=(158−75)/75≈1.1067,和原始的1.1就出现了一些精度误差。
更多量化算法,推荐阅读这篇博客。
QLoRA
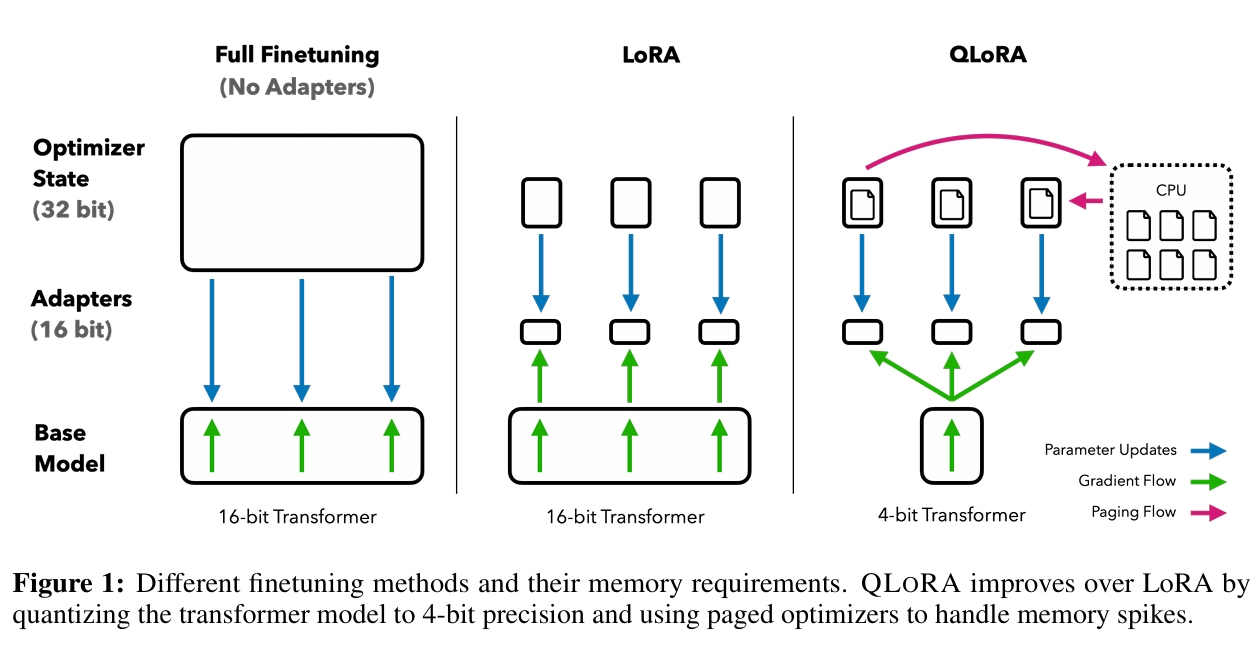
最后,我们来介绍一下QLoRA:QLORA:Efficient Finetuning of Quantized LLMs
QLoRA的目标是在LoRA微调中使用量化技术,进一步降低微调成本。具体地,QLoRA将预训练模型权重用 4-bit NF4 存储,同时附加 全精度(通常FP16/BF16)的LoRA参数 ,只更新LoRA部分。通过三种核心创新的trick,使得4-bit微调的性能接近全精度微调。
论文里的图理解起来有一点抽象,具体的,中图(LoRA)和右图(QLoRA)的区别在于base model从16-bit变成了4-bit量化,并且右边用红色箭头标注了 Paged Optimizer 在 GPU 和 CPU 之间分页流动,避免显存峰值溢出的过程。
不过,需要明确的一点是,QLoRA的核心创新trick,本身和LoRA都没有直接关系,可以通用地使用在量化推理/量化微调情景。
技巧1:4-bit NormalFloat (NF4) 量化
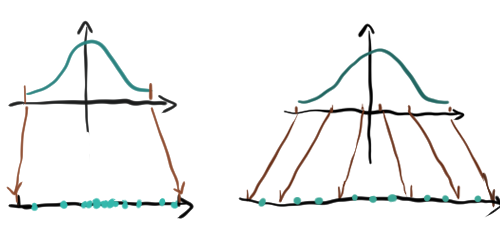
预训练大模型的权重 近似服从均值为0的正态分布,这就意味着,如果使用上文提到的线性的缩放方式来量化,可能导致大量数值被挤压在0附近,整个量化桶非常稀疏(如下图左所示)。
而NF4量化将正态分布的累积概率函数均分为16个等概率区间,并为每个区间选取一个中位数作为量化代表值,使得权重信息保留得更好(如图右所示,不等长的区间被映射到等长的量化区间,量化后的稀疏度保持一致)。
此外,对于个别过大过小异常值,会拉大 min , max \\min,\\max min,max区间的异常值,NF4还进行了额外的分块量化,给异常值单独的量化区间。
技巧2:双重量化 (Double Quantization)
将每256个块的缩放因子(上文的 s c a l e scale scale)为一组,再次进行8-bit量化,进一步节省空间。
技巧3:分页优化器 (Paged Optimizers)
使用NVIDIA统一内存技术,在GPU显存即将溢出时,将部分优化器状态(如Adam的一阶/二阶矩)自动转移到CPU内存中,并在需要时再取回。
加上这些技巧后,4-bit量化模型+LoRA就能达到极具性价比的微调效果,并且性能损失很小。