音频识别入门内容
文章目录
- 音频识别入门内容
- 前言
- 一、声学领域主要分类
- 二、自动语音识别(ASR)基本原理
-
- [2.1 什么是自动语音识别](#2.1 什么是自动语音识别)
- [2.2 自动语音识别简史](#2.2 自动语音识别简史)
- [2.3 语音识别处理 Pipeline 综述](#2.3 语音识别处理 Pipeline 综述)
- [2.4 语音识别的类型](#2.4 语音识别的类型)
- [2.5 语音单位与言语的基本组成部分](#2.5 语音单位与言语的基本组成部分)
- 三、处理音频信号
-
- [3.1 采样与量化](#3.1 采样与量化)
- [3.2 音频格式(WAV、MP3、FLAC)](#3.2 音频格式(WAV、MP3、FLAC))
- [3.3 波形图、频谱图与时频图](#3.3 波形图、频谱图与时频图)
- [3.4 预加重与分帧](#3.4 预加重与分帧)
- [3.5 窗函数](#3.5 窗函数)
- [3.6 特征提取](#3.6 特征提取)
- [3.7 生成梅尔频率倒谱系数(MFCC)](#3.7 生成梅尔频率倒谱系数(MFCC))
- 四、声学模型
-
- [4.1 什么是声学模型](#4.1 什么是声学模型)
- [4.2 声学模型的作用](#4.2 声学模型的作用)
- [4.3 将声音映射到音素](#4.3 将声音映射到音素)
-
- [4.3.1 早期方法:高斯混合模型(GMMs)](#4.3.1 早期方法:高斯混合模型(GMMs))
- [4.3.2 隐马尔可夫模型(HMM)在序列数据中的应用](#4.3.2 隐马尔可夫模型(HMM)在序列数据中的应用)
- [4.3.3 HMM 在语音识别中的应用](#4.3.3 HMM 在语音识别中的应用)
- [4.3.4 GMM 与 HMM 的结合(GMM-HMM)](#4.3.4 GMM 与 HMM 的结合(GMM-HMM))
- [4.3.5 基于神经网络的声学模型](#4.3.5 基于神经网络的声学模型)
- 现代端到端架构
- [4.3.6 声学模型在 ASR 系统中的定位](#4.3.6 声学模型在 ASR 系统中的定位)
- 五、语言模型
-
- [5.1 什么是语言模型](#5.1 什么是语言模型)
- [5.2 语音中的歧义问题](#5.2 语音中的歧义问题)
- [5.3 N-gram 语言模型](#5.3 N-gram 语言模型)
- [5.4 困惑度(Perplexity)](#5.4 困惑度(Perplexity))
- [5.5 语言模型如何提高准确性](#5.5 语言模型如何提高准确性)
- [5.6 神经网络语言模型简介](#5.6 神经网络语言模型简介)
- 六、解码与系统集成
-
- [6.1 解码器的作用](#6.1 解码器的作用)
- [6.2 确定最可能的词语序列](#6.2 确定最可能的词语序列)
- [6.3 搜索算法概览](#6.3 搜索算法概览)
- [6.4 理解维特比算法](#6.4 理解维特比算法)
- [6.5 完整的 ASR 流程回顾](#6.5 完整的 ASR 流程回顾)
- 七、评估与性能指标
-
- [7.1 词错误率(WER)](#7.1 词错误率(WER))
- [7.2 影响 ASR 准确性的常见因素](#7.2 影响 ASR 准确性的常见因素)
前言
本文是一份系统性的语音识别(ASR)入门介绍,面向希望了解语音识别原理与工程实践的读者。
主要参考资料:
- 趋近智
- Hugging Face Transformers 文档
- 相关学术论文及工程实践经验
阅读建议:本文从声学领域分类出发,依次介绍 ASR 的发展简史、音频信号处理、声学模型、语言模型,最终到解码与系统集成,层层递进,建议按章节顺序阅读。
一、声学领域主要分类
语音/声学相关的 AI 任务大体可分为以下几类:
1. 自动语音识别(ASR,Automatic Speech Recognition)
将语音信号转换为文本,即"语音转文本"(Speech-to-Text)。
2. 语音合成(TTS,Text-to-Speech)
将文本转换为语音,即"文本转语音"。
3. 自然语言理解(NLU,Natural Language Understanding)
主要面向意图识别与语义理解。可以直接采用面向语音的模型处理,也可以先通过 ASR 将语音转为文本,再进行文本级的语义理解与意图识别。
4. 说话人识别(Speaker Recognition)
也称声纹识别,主要用于声纹鉴权与身份校验。
5. 情感识别(Emotion Recognition)
识别说话人的情绪状态,通常用于为 TTS 赋能,使合成语音更自然、更具情感表达力,从而在对话中更接近真人。
二、自动语音识别(ASR)基本原理
2.1 什么是自动语音识别
自动语音识别(ASR)是将人类口语自动转换为文字的技术。其核心要解决两大问题:
- 声学问题:如何将连续的音频信号准确映射到语音的基本单元(音素)?
- 语言问题:如何在多个声学上相似的候选结果中,选择语言上最合理的词语序列?
ASR 的典型应用场景
| 场景类型 | 典型应用 |
|---|---|
| 实时场景 | 会议纪要、语音助手、语音纠错、视频实时字幕、车载系统 |
| 离线场景 | 听写转录、呼叫中心自动化、语音数据标注 |
2.2 自动语音识别简史
早期阶段:声学模式匹配
20 世纪 50 年代,贝尔实验室开发了"Audrey"系统,这是最早的 ASR 尝试之一。这些早期系统基于声学模式匹配,只能识别特定说话人的小词汇量语音,但证明了机器识别语音在原理上的可行性。
统计方法阶段:隐马尔可夫模型(HMM)
20 世纪 70 年代是 ASR 发展的重要转折点。研究人员放弃了整体声音模式匹配,转而引入统计方法。在美国国防部高级研究计划局(DARPA)的大力资助下,隐马尔可夫模型(HMM) 得到广泛采用。
HMM 将语音视为一系列声音状态的随机过程,不再匹配整个单词,而是计算特定音频特征序列对应于音素序列的概率。这种概率化、序列化的建模方式更能应对人类语音的自然变异性,能够对声音之间的转变过渡进行建模,是识别连续流畅语音的重要突破。
近代:GMM-HMM 系统
20 世纪 90 年代至 21 世纪初,ASR 的主流方案是将 HMM 与高斯混合模型(GMM) 结合使用,即 GMM-HMM 系统:
- HMM 负责建模语音的时序结构,模拟音素如何按顺序组合成单词。
- GMM 负责在每个 HMM 状态下对音频特征(如 MFCC)的概率分布进行建模。
GMM-HMM 系统成为该时代的工业标准,在大词汇量连续语音识别任务上取得了显著进展。
现代:深度学习端到端模型
2010 年前后,深度学习技术的兴起再次变革了 ASR 领域。研究人员发现,深度神经网络(DNN)在学习音频特征与语音单元之间的复杂非线性关系方面远优于 GMM,于是 DNN-HMM 混合系统 应运而生,词错误率(WER)显著下降。
此后,研究重心逐渐转向端到端(End-to-End)模型。这类系统用单一的大型神经网络直接从音频特征学习到文本的映射,无需独立的声学模型、发音词典和语言模型组件。当前主流方案包括基于 CTC(Connectionist Temporal Classification)和基于 Attention 的 Encoder-Decoder 架构,以及两者结合的混合方案。智能手机语音助手、智能音箱等产品均由这类现代深度学习系统提供支持。
2.3 语音识别处理 Pipeline 综述
工程实践中,一个完整的 ASR 系统通常以 pipeline 的形式串联多个子模块:
VAD → ASR(CTC/Attention)→ PUNC → ITN- VAD(Voice Activity Detection,语音活动检测):检测音频中的人声片段,剔除静音与噪声段,减少无效计算。
- ASR 主模型:将语音特征转换为文本,通常基于 CTC 或 Attention 机制。
- PUNC(标点预测):为转写文本自动添加标点符号。
- ITN(Inverse Text Normalization,逆文本正则化):将"三千五百元"转换为"3500 元"等标准化表示。
代表性开源方案:
| 框架 | 来源 | 特点 |
|---|---|---|
| FunASR | 阿里达摩院 | 完整串联 VAD→ASR→PUNC→ITN,工业级应用广泛;部分组件较老旧,迭代相对滞后 |
| FireRedASR | 小红书 | 较新方案,综合性能优秀,中文识别效果突出 |
| sherpa-onnx | k2-fsa(Next-gen Kaldi) | 跨平台部署导向,支持 Android / iOS / 嵌入式 / 服务端;以 ONNX 格式封装模型,推理无需 Python 环境;同时支持 VAD、ASR、TTS、说话人识别等完整 pipeline;绑定覆盖 C/C++、Python、Java、Swift、Kotlin 等多语言;适合对推理性能和部署环境有严格要求的工程场景 |
Pipeline 与端到端模型的互补关系
部分文献认为,随着 Seq2Seq 端到端模型(如 Qwen3-ASR)能力增强,传统 pipeline 将被取代。然而,在实际工程中,两者目前仍是互补关系,不可偏废。
具体而言,端到端模型内部通常嵌入一个相对轻量的语言模型(LLM),以平衡推理速度与精度。在以下场景中,单纯依靠端到端模型难以保证质量,仍需 pipeline 辅助:
- 长音频处理(如 1 小时以上):较长的提示词或热词列表会在长序列推理中压缩语言建模能力,导致转写质量下滑。
- 存在较长非人声片段(静音、背景噪声等):模型可能产生"幻觉"(无中生有地脑补内容),在长音频中此问题被放大,可引发后续转写的连锁崩溃或提前中断。
- 复杂声学环境:强噪声、多人同时说话等场景中,VAD 等预处理步骤仍不可缺少。
2.4 语音识别的类型
根据对说话人依赖程度和语音形式的不同,ASR 系统可分为以下几类:
- 说话人相关(Speaker-Dependent):针对特定说话人进行训练或适配,识别率高但泛化能力弱,多用于个人化设备。
- 说话人无关(Speaker-Independent):可识别任意说话人的语音,通用性强,是现代 ASR 的主流形式。
- 孤立词识别(Isolated Word):识别单个命令词,对计算资源要求低,常用于关键词唤醒(如"小爱同学")。
- 连续语音识别(Continuous Speech):识别自然连续的句子,是日常使用场景的核心需求,技术难度更高。
2.5 语音单位与言语的基本组成部分
音素(Phoneme) 是语言中最小的具有区别意义功能的语音单位。不同语言的音素系统有所差异:
- 英语等字母语言:以音素或词素(Morpheme)为基本单位进行建模。
- 中文、日文、韩文:通常以字符(Character)为建模单位,因为字符与语音的对应关系相对固定。
为使模型具备跨语言处理能力,同时保证语义无关性,领域内发展了两种主要方案:
- IPA(国际音标,International Phonetic Alphabet):用统一的音标体系描述所有语言的发音,消除语言间的拼写差异。
- 基于 Unicode 字符编码的训练:直接以 Unicode 子词(Subword,如 BPE)为单位,无需语言特定的发音词典,Whisper 等现代端到端模型广泛采用此方案。
三、处理音频信号
3.1 采样与量化
(1)采样(Sampling)
现实世界中的声音以连续的模拟波形在介质中传播。为了让计算机能够存储和处理音频信号,必须将连续的模拟信号转换为离散的数字信号,这一过程称为模数转换(A/D 转换) ,其中的关键步骤之一就是采样。
采样是指以固定的时间间隔对连续信号的瞬时幅度进行测量并记录。单位时间内的采样次数称为采样率(Sampling Rate),单位为赫兹(Hz)。
奈奎斯特-香农采样定理 :为了不失真地重构原始信号,采样率必须至少是信号中最高频率成分的 2 倍。
由于人类语音的频率范围通常低于 8 kHz,因此 16 kHz 的采样率在语音识别中是标准配置------它满足奈奎斯特定理,且能充分捕获口语的关键声学特征。对于音乐等包含更高频率成分的信号,CD 标准采用 44.1 kHz 的采样率。
(2)量化(Quantization)
采样后,我们得到一系列离散时间点的幅度测量值,但每个测量值的精度仍然是连续的(理论上可以有无限位小数)。量化是将这些连续的幅度值映射到有限个离散级别的过程。
量化精度由**位深度(Bit Depth)**决定:
- 16 位:可表示 2¹⁶ = 65,536 个量化级别,是大多数 ASR 应用的标准配置,在音质与文件大小之间取得良好平衡。
- 位深度越低,文件越小,但同时引入的**量化误差(量化噪声)**也越大------量化噪声是实际采样幅度与其量化近似值之间的差值。
采样和量化共同将连续的模拟波转换为计算机可存储、处理和分析的数字序列,即音频的数字表示形式。
3.2 音频格式(WAV、MP3、FLAC)
WAV、MP3 和 FLAC 都是对采样量化后数字音频的封装格式,区别在于是否进行了压缩及压缩方式。
未压缩音频:WAV
波形音频文件格式(Waveform Audio File Format,.wav)直接存储原始的 PCM 数字音频数据,不进行任何压缩,因此文件体积最大,但音质最高、信息最完整,是 ASR 系统处理的首选格式。
有损压缩:MP3
MP3 编码器借助心理声学原理,丢弃人耳难以感知的音频成分(如极高频率、被响亮声音掩蔽的微弱声音),以此实现约 10:1 的压缩比,但会不可逆地损失部分音频信息,整体音质低于 WAV。
无损压缩:FLAC
自由无损音频编解码器(Free Lossless Audio Codec,.flac)类似于针对音频的 ZIP 压缩。解压后可完整还原原始 PCM 数据,无任何信息损失,是兼顾存储效率与音质保真的优选方案。
对 ASR 系统的影响
所有音频在输入 ASR 系统进行处理前,无论原始格式是 WAV、MP3 还是FLAC,均需先解码还原为原始的未压缩 PCM 波形数据。文件格式本身仅代表音频的存储方式,而非 ASR 模型实际处理的内容。
需要注意的是,经过有损压缩(如 MP3)的音频在解码后,其中已丢失的信息无法恢复,可能对特征提取的质量产生一定影响。
3.3 波形图、频谱图与时频图
从原始数字音频到语音识别模型的输入,通常需要借助多种可视化与分析工具来理解信号的特性。
(1)波形图(Waveform)
波形图以时间为横轴、振幅为纵轴,直观展示音频信号随时间变化的幅度。它是音频最基础的表示形式,能清晰反映音量的强弱变化和语音段/静音段的分布,但无法直接看出频率成分的变化,因而不适合作为 ASR 模型的输入特征。
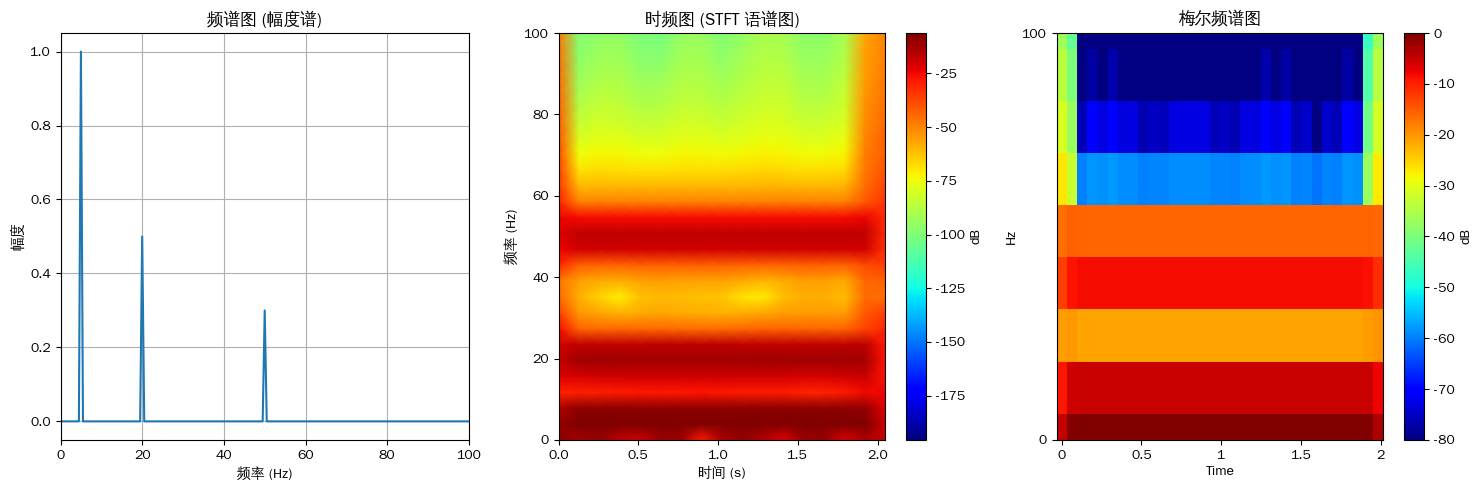
(2)频谱图(Spectrum)
对某一时刻的音频帧进行快速傅里叶变换(FFT) ,可得到该帧信号在各频率成分上的能量分布,即频谱。频谱图以频率为横轴、能量(幅度或功率)为纵轴,揭示了单帧音频的频率组成。
然而,单帧频谱只反映某一静止时刻的频率信息,无法体现语音随时间的动态变化。
(3)时频图(Spectrogram,语谱图)
时频图(又称语谱图或声谱图)通过对连续音频进行短时傅里叶变换(STFT),在每个时间帧上计算频谱,然后将所有帧的频谱沿时间轴拼接,形成以时间为横轴、频率为纵轴、颜色(或亮度)表示能量强度的二维图像。
时频图综合了时域与频域的信息,使得语音信号中音素的动态声学特征清晰可见,是语音分析和特征提取的核心工具。
(4)梅尔频谱图(Mel Spectrogram)
普通时频图采用线性频率轴,而梅尔频谱图是在梅尔尺度(见 3.6、3.7 节)上重新映射频率轴的时频图,更符合人耳对频率的感知规律。梅尔频谱图是 MFCC 特征提取的中间步骤,也是许多现代端到端 ASR 模型(如 Whisper)的直接输入。
三种表示的关系总结
| 表示形式 | 横轴 | 纵轴 | 特点 |
|---|---|---|---|
| 波形图 | 时间 | 振幅 | 直观,但无频率信息 |
| 频谱图 | 频率 | 能量 | 单帧静态频率分布 |
| 时频图(语谱图) | 时间 | 频率(颜色=能量) | 动态时频联合分析,ASR 特征提取基础 |
| 梅尔频谱图 | 时间 | 梅尔频率(颜色=能量) | 符合人耳感知,现代 ASR 常用输入 |
3.4 预加重与分帧
(1)预加重(Pre-emphasis)
典型语音信号的能量分布极不均匀:大部分能量集中在低频段。
| 频段 | 声学内容 | 能量占比(典型) |
|---|---|---|
| 0--1 kHz | 基频(F0)与共振峰(F1/F2) | 60%--80% |
| 1--4 kHz | 语音清晰度区域 | 15%--35% |
| >4 kHz | 辅音细节、噪声 | 5%--20% |
尽管高频分量(如辅音"s"与"f"中的摩擦音)在区分音素方面至关重要,其能量却远低于低频分量。这种能量不平衡会干扰后续特征提取算法的稳定性,并降低信噪比(SNR)。
预加重通过一个高通滤波器来提升高频分量的相对能量,从而:
- 平衡全频段的能量分布,使频谱更均匀;
- 提高信噪比(SNR),有助于降低噪声影响。
预加重滤波公式如下(其中 α 通常取 0.97):
y ( t ) = x ( t ) − α ⋅ x ( t − 1 ) y(t) = x(t) - \alpha \cdot x(t-1) y(t)=x(t)−α⋅x(t−1)
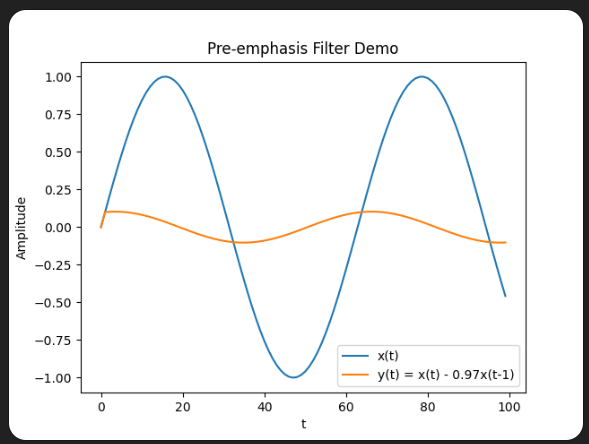
(2)分帧(Framing)
语音信号具有非平稳性:不同音素在不同时刻具有截然不同的频率特性。如果对整段语音一次性进行频率分析,则会将所有音素的特征混叠平均,丢失关键的局部声学细节。
然而,在极短的时间窗口内(通常 20--30 ms),语音信号可视为准平稳(quasi-stationary)------其统计特性相对稳定。这是分帧的理论基础。
分帧将预加重后的信号切分为一系列短小的、相互重叠的片段(帧),两个关键参数为:
- 帧长(Frame Length) :每帧持续时间,标准值为 25 ms。足够长以包含充分的声学信息,又足够短以维持准平稳假设。
- 帧移(Frame Shift / Hop Length) :相邻两帧起始点的间隔,常用值为 10 ms。
由于帧移(10 ms)小于帧长(25 ms),相邻帧之间存在 15 ms 的重叠区域。重叠的目的在于:
- 确保帧与帧之间平滑过渡,避免在帧边缘"截断"某个音素;
- 防止因分帧位置不当而导致关键声学信息丢失。
注 :对于长音频,可采用动态分帧策略,结合 VAD 信息在音频的自然停顿处分帧,以避免固定分帧带来的"强制截断"问题和非人声片段引发的"幻觉"转写。
3.5 窗函数
经过分帧处理后,每一帧在起始和结束处往往存在突变边缘 。如果直接对这样的帧进行频率分析(如 FFT),尖锐的边缘会在原始信号中不存在的频率上引入虚假能量,这种现象称为频谱泄漏(Spectral Leakage)------能量从其真实频率"泄漏"到邻近频率,扭曲信号的真实频率成分。
为避免频谱泄漏,在进行 FFT 之前需要对每一帧施加窗函数(Window Function),即将帧内每个采样点乘以对应的窗函数系数,使帧的两端平滑地趋近于零。
汉明窗(Hamming Window)
在语音识别中,汉明窗是最常用的窗函数,其形状为中间接近 1、两端平滑趋近一个小的非零值的钟形曲线:
w ( n ) = 0.54 − 0.46 cos ( 2 π n N − 1 ) w(n) = 0.54 - 0.46 \cos\left(\frac{2\pi n}{N-1}\right) w(n)=0.54−0.46cos(N−12πn)
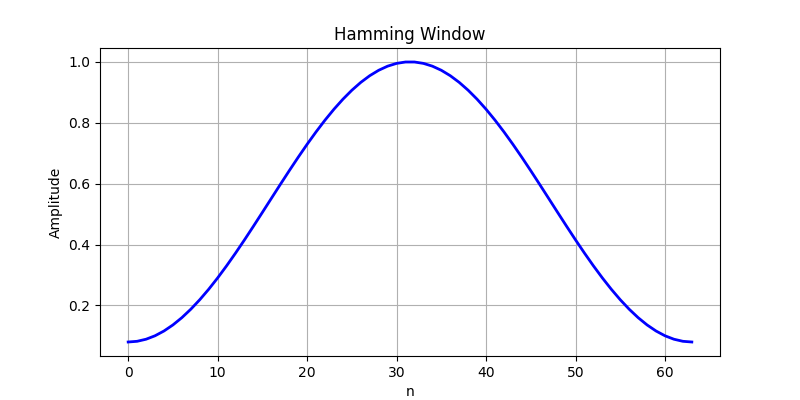
与完全归零的**汉宁窗(Hanning Window)**相比,汉明窗两端保留小的非零值,能更好地保留帧端的微弱声学信息,同时有效抑制频谱泄漏。
其他常用窗函数:汉宁窗(Hanning)、布莱克曼窗(Blackman)等,在不同场景下有各自的适用优势,但汉明窗是语音识别领域的经典默认选择。
窗函数处理后,每一帧信号两端的能量被平滑压缩,整帧信号过渡自然,可以安全地进行 FFT 分析,进入下一阶段------特征提取。
3.6 特征提取
将模拟声波转换为数字样本序列后,理论上可以直接将这些原始样本输入机器学习模型,但这样做存在几个关键问题:
高维度:16 kHz 采样下,1 秒音频产生 16,000 个数据点,5 秒则高达 80,000 个。在如此长的序列上训练模型计算代价极大,且难以学到有效规律。
冗余信息:原始音频中包含大量与识别语音内容无关的信息,例如背景噪声、说话人的音高变化、录音环境噪声等。
一致性差:同一个词在不同说话人、不同音量或不同情绪下发音时,原始波形差异极大,模型很难从原始幅度值中泛化学习。
特征提取 的目标,是将高维、嘈杂的原始音频信号转换为更紧凑、稳定且对语音识别有效 的低维表示,即一组特征向量(Feature Vector)。
转换为符合人耳感知的特征
频谱图(时频图)是对原始波形的重要改进,但其采用线性频率尺度:从 100 Hz 到 200 Hz 与从 4000 Hz 到 4100 Hz 被视为等距的变化。然而,人耳的频率感知并非线性的------我们对低频变化的感知远比对高频变化敏感,且区分语音音素所需的关键信息大多集中在较低频段。
为了构建更符合人类听觉感知的特征表示,引入了梅尔尺度(Mel Scale) ------一种感知音高尺度,在该尺度上间隔相等的声音,人耳听起来感觉也间隔相等。基于梅尔尺度的梅尔频率倒谱系数(MFCC) 是语音识别系统中最经典、最广泛使用的特征之一。
3.7 生成梅尔频率倒谱系数(MFCC)
MFCC(Mel-Frequency Cepstral Coefficients)是语音识别领域使用最广泛的传统声学特征,其核心思想是以更符合人类听觉感知的方式来表示音频信号。
梅尔尺度:模拟人类听觉
人耳对低频音高变化更敏感,100 Hz 与 200 Hz 之间的音高差,感觉上远大于 10,000 Hz 与 10,100 Hz 之间的差------尽管绝对频率差相同。梅尔尺度通过非线性映射重新表达频率轴,对低频给予更高分辨率,对高频给予较低分辨率。
将频率 f f f(Hz)转换为梅尔值的公式为:
m = 2595 ⋅ log 10 ( 1 + f 700 ) m = 2595 \cdot \log_{10}\left(1 + \frac{f}{700}\right) m=2595⋅log10(1+700f)
MFCC 提取流程
对每个加窗后的音频帧,依次执行以下变换:
音频帧 → STFT/FFT 功率谱 → 梅尔滤波器组 梅尔频谱 → log 对数梅尔频谱 → DCT MFCC \text{音频帧} \xrightarrow{\text{STFT/FFT}} \text{功率谱} \xrightarrow{\text{梅尔滤波器组}} \text{梅尔频谱} \xrightarrow{\log} \text{对数梅尔频谱} \xrightarrow{\text{DCT}} \text{MFCC} 音频帧STFT/FFT 功率谱梅尔滤波器组 梅尔频谱log 对数梅尔频谱DCT MFCC
各步骤说明:
- 短时傅里叶变换(STFT/FFT):将时域帧转换为频域功率谱,获取各频率的能量分布。
- 梅尔滤波器组:用一组在梅尔尺度上均匀分布的三角形滤波器对功率谱进行滤波,将线性频率轴映射到梅尔频率轴,同时实现频率维度的降维。
- 取对数(Log):对滤波后的能量取对数,模拟人耳对响度的对数感知特性,同时压缩动态范围。
- 离散余弦变换(DCT):对对数梅尔频谱施加 DCT,将相关性较高的梅尔谱系数去相关,转化为紧凑的倒谱系数。
最终特征向量
通常只保留 DCT 输出的前 12--13 个系数(较高阶系数表示能量的快速变化,对语音语义贡献较少,且对噪声更敏感)。第 0 个系数代表帧的平均能量,有时单独处理或丢弃。
经过完整处理后,一帧 25 ms 的音频从数千个原始采样点被压缩为仅包含 12--13 个数字的特征向量。将音频片段中所有帧的特征向量按时间顺序堆叠,得到一个特征矩阵(行=时间帧,列=MFCC 系数),这就是传统声学模型的标准输入。
四、声学模型
4.1 什么是声学模型
ASR 系统通过特征提取,将原始音频转换为特征向量序列(如 MFCC)。这些数值虽能紧凑表示声音的声学属性,但本身不具备语言意义。
声学模型(Acoustic Model,AM) 的作用,正是充当声音与语言基本单元之间的"翻译器"。对于输入的每个特征向量(代表约 10--25 ms 的音频),声学模型计算该段声音对应语言中每个可能音素的概率。
例如,对于某一帧音频,模型可能输出:
- P(/t/ | 特征) = 0.70
- P(/d/ | 特征) = 0.10
- P(/s/ | 特征) = 0.05
- 其他音素 ...
声学模型本身是一个专门的模式识别器,通过在大量有标注的语音数据(音频与对应文本的时间对齐数据)上训练,学习每个音素在特征空间中的统计分布特征。
4.2 声学模型的作用
声学模型回答的核心问题是:"给定这段音频特征,它对应某个特定音素的可能性有多大?"
形式上,这一概率通常写作条件概率 P ( 音频特征 ∣ 音素 ) P(\text{音频特征} \mid \text{音素}) P(音频特征∣音素),即"在某个音素被说出的前提下,观察到这组特征的概率"。
声学模型对输入音频中的每个时间帧重复执行此计算,输出一个逐帧的音素概率序列。这个输出是概率性的而非确定性的,这一点非常重要------人类语音的自然变异性(口音、语速、前后音的协同发音效应等)使得确定性判断难以实现,概率化输出为后续解码步骤提供了灵活性。
这些概率分数随后被传递给 ASR 流程的下一阶段------解码器,后者结合语言模型信息,从候选音素/词序列中找出最终的最优转录结果。
4.3 将声音映射到音素
声学模型作为一座桥梁,将连续的音频特征向量序列映射到语言的基本单元------音素。
由于语音的可变性(同一音素在不同语境、说话人、语速下声学表现不同),声学模型不做出确定性决定,而是为所有可能的音素计算似然分数(Likelihood Score):
P ( 特征 ∣ 音素 i ) , i = 1 , 2 , ... , N P(\text{特征} \mid \text{音素}_i), \quad i = 1, 2, \ldots, N P(特征∣音素i),i=1,2,...,N
声学模型本身不负责最终决策,它只提供这些概率证据。当两个音素在声学上非常相似时(如 /p/ 与 /b/),两者都可能获得较高的概率分数,真正的最终决策由解码器完成。
4.3.1 早期方法:高斯混合模型(GMMs)
在传统系统中,对于每个音素,声学模型需要描述其特征向量的统计分布。由于同一音素在不同发音条件下的特征向量存在多种变体,高斯混合模型(GMM) 被用来对每个音素的特征分布进行建模。
GMM 由多个高斯分量(正态分布)加权叠加而成:
- 每个分量可以捕捉音素的一种典型发音变体(如"top"中的 /t/ 与"stop"中的 /t/ 具有不同的声学特性);
- 多个分量的组合使 GMM 能灵活描述复杂的多峰分布。
训练完成后,对于新输入的特征向量,每个音素的 GMM 分别计算生成该向量的概率,从而输出所需的 P ( 特征 ∣ 音素 ) P(\text{特征} \mid \text{音素}) P(特征∣音素)。
GMM 的局限性:GMM 孤立地对每一帧特征建模,没有时序感知能力。语音本质上是声音的有序序列,需要另一个组件来处理时序结构,这正是 HMM 的用武之地。
4.3.2 隐马尔可夫模型(HMM)在序列数据中的应用
语音本质上是序列化的,单词"cat"中 /k/、/æ/、/t/ 的顺序定义了这个词的身份。一个只处理单帧特征的模型(如 GMM)无法捕捉这种时序结构。
隐马尔可夫模型(HMM) 是专为序列数据建模而设计的统计工具,其中"隐藏"的含义在于:生成观测数据的底层状态序列无法被直接观测。
经典类比:设想你身处一个无窗的房间,想推断外面的天气(晴天/雨天)。天气是隐藏状态 ,你看不见;进入房间的同事是否持有湿雨伞是观测值。通过随时间积累的观测,你可以推断最可能的天气状态序列。HMM 将这一思路形式化。
4.3.3 HMM 在语音识别中的应用
HMM 直接映射到语音识别的两层结构:
- 隐藏状态:音素(我们无法直接从原始波形中"看到"一个完美的 /k/ 或 /æ/)。
- 观测值:从音频帧提取的特征向量(如 MFCC)------我们手中实际拥有的声学证据。
HMM 由三个核心组件构成:
- 状态集(S):每个音素通常用一条由 3 个状态构成的链建模(起始、中间、结束),以捕捉音素内部的动态变化。
- 转移概率(A):定义从一个状态转移到另一个状态的概率,强制约束合法的音素内部转移(音素可在自身状态上停留,以处理发音快慢的变化)和音素间转移。
- 发射概率(B) :在特定状态下产生特定观测值(音频特征向量)的概率,即 P ( 音频特征 ∣ 状态 ) P(\text{音频特征} \mid \text{状态}) P(音频特征∣状态)。
HMM 的局限性:HMM 本身没有规定如何计算发射概率,需要与 GMM 结合才能对声学特征建模。
4.3.4 GMM 与 HMM 的结合(GMM-HMM)
GMM 和 HMM 各有优势,也各有局限:
- GMM 擅长描述单帧特征的统计分布,但无时序感知。
- HMM 擅长序列建模,但本身无法直接处理连续的声学特征数据。
GMM-HMM 混合架构 将两者优势结合:
- GMM 承担 HMM 中发射概率的计算,即 P ( 特征向量 ∣ HMM状态 ) P(\text{特征向量} \mid \text{HMM状态}) P(特征向量∣HMM状态),描述每个音素状态的声学分布。
- HMM 提供时序"脚手架",通过转移概率建模音素的持续时长与合法转移顺序。
这一混合架构在深度学习兴起之前,长达数十年是 ASR 领域的工业标准。
4.3.5 基于神经网络的声学模型
GMM-HMM 存在内在局限:GMM 难以对高度复杂的非线性声学模式建模;HMM 的状态独立性假设对流畅人类语音而言过于严格。
DNN-HMM 混合架构
第一个重大突破是以深度神经网络(DNN) 替代 GMM,保留 HMM 的序列建模框架,形成 DNN-HMM 混合系统。
其工作流程如下:
- 输入:音频特征向量序列(如 MFCC)。
- DNN 处理:DNN 通过多层非线性变换,学习特征与 HMM 状态之间的复杂映射。
- 输出 :DNN 的输出层为每个 HMM 状态(或音素)生成后验概率,即 P ( 音素 ∣ 特征 ) P(\text{音素} \mid \text{特征}) P(音素∣特征)。
- HMM 序列化:DNN 输出的概率序列传入 HMM,由维特比算法找到最可能的音素状态路径。
仅将 GMM 替换为 DNN 这一项改进,就使词错误率(WER)大幅下降,成为 2010 年代初 ASR 领域的里程碑进展。
现代端到端架构
混合 DNN-HMM 的成功只是深度学习革命的开端。现代 ASR 已转向端到端(End-to-End)模型,将声学建模、发音词典查找和语言建模整合进单一神经网络,直接从音频特征学习文本输出。
当前主流的两类端到端方案:
① 连接时序分类(CTC,Connectionist Temporal Classification)
CTC 模型直接从输入音频特征输出字符或子词序列,巧妙地通过引入空白符(blank)和折叠规则处理语音与文本之间无清晰边界的对齐问题,无需预先的帧级标注对齐。典型代表:Wav2Vec2系列。
② Attention-based Encoder-Decoder(注意力机制编解码器)
编码器对整段音频进行编码,形成高层语义表示;解码器逐步生成词或字符,同时通过注意力机制动态聚焦于音频编码的相关区域。典型代表:Paraformer 、Whisper、Conformer 。
现代主流系统(如 Whisper)通常采用 CTC 与 Attention 联合训练 的混合策略,兼顾两者优势:CTC 提供帧级对齐约束,Attention 提供全局上下文理解能力。
4.3.6 声学模型在 ASR 系统中的定位
无论采用何种技术(GMM-HMM、DNN-HMM 或端到端),声学模型始终扮演同一核心角色:
- 输入:从短音频帧提取的特征向量序列。
- 输出:对应每个基本语音单元(音素或子词)的概率分布序列。
- 核心职责:将抽象的数值特征转换为语言层面可解释的概率信息,为解码器提供声学证据。
声学模型本身不做最终的词语决策------它只提供"这段声音听起来像哪个音素"的概率性证据。最终决策由解码器结合语言模型共同完成。
五、语言模型
声学模型提供的是声学证据,但仅凭声学证据无法保证转录准确性。例如,"recognize speech"(识别语音)与"wreck a nice beach"(破坏一片漂亮的海滩)这两个短语在音素层面几乎完全相同,声学模型会为两者分配接近的概率分数。要消除这类歧义,需要引入对语言本身规律性的理解------这正是语言模型的职责。
5.1 什么是语言模型
语言模型(Language Model,LM) 是一种统计工具,用于计算词语序列 W W W 出现的概率 P ( W ) P(W) P(W)。它不感知任何音频信息,唯一的职责是评估"一个给定的词语序列在目标语言中出现的可能性有多大",充当语法与用语习惯的判断者。
语言模型通过在大规模文本语料库(书籍、新闻、网页、对话转录等)上训练,习得语言的统计规律:哪些词语常见、哪些词语倾向于相互搭配、哪些语法结构频繁出现。
在 ASR 流程中的作用
语言模型与声学模型协同工作,由解码器将两者的信息整合:
- 声学得分 P ( O ∣ W ) P(O \mid W) P(O∣W):音频与候选词序列的匹配程度(由声学模型提供)。
- 语言得分 P ( W ) P(W) P(W):候选词序列在语言中出现的概率(由语言模型提供)。
解码器寻找使两者乘积最大化的词序列作为最终输出,从而在声学上相似的候选结果中,选取语言上更合理的那一个。
5.2 语音中的歧义问题
口语中存在多种类型的歧义,是 ASR 系统面临的核心挑战:
同音词(Homophones)
发音相同但拼写和含义不同的词,如:
- to / too / two
- their / there / they're
- ate / eight
- weather / whether
声学模型无法区分这些词,需要语言模型提供上下文信息("I ate dinner"远比"I eight dinner"更常见)。
词语边界歧义
口语是连续的声音流,词间停顿通常不明显,可能导致多种合理的词语切分方式。经典示例:
- "I scream" vs. "ice cream"
语法与语义合理性
语言模型为每个候选句子分配概率得分,偏好语法正确、语义合理的词语序列,从而引导系统做出更准确的判断:
P ( "recognize speech" ) ≫ P ( "wreck a nice beach" ) P(\text{"recognize speech"}) \gg P(\text{"wreck a nice beach"}) P("recognize speech")≫P("wreck a nice beach")
5.3 N-gram 语言模型
N-gram 模型 通过马尔可夫假设 简化了计算整个句子概率的问题:一个词的概率仅取决于其前面 N − 1 N-1 N−1 个词,而非整个历史序列。
二元语法(Bigram,N=2)
P ( w i ∣ w i − 1 ) = Count ( w i − 1 , w i ) Count ( w i − 1 ) P(w_i \mid w_{i-1}) = \frac{\text{Count}(w_{i-1}, w_i)}{\text{Count}(w_{i-1})} P(wi∣wi−1)=Count(wi−1)Count(wi−1,wi)
三元语法(Trigram,N=3)
P ( w i ∣ w i − 2 , w i − 1 ) = Count ( w i − 2 , w i − 1 , w i ) Count ( w i − 2 , w i − 1 ) P(w_i \mid w_{i-2}, w_{i-1}) = \frac{\text{Count}(w_{i-2}, w_{i-1}, w_i)}{\text{Count}(w_{i-2}, w_{i-1})} P(wi∣wi−2,wi−1)=Count(wi−2,wi−1)Count(wi−2,wi−1,wi)
更高阶的 N-gram(N=4、5)提供更长的上下文,但随之带来数据稀疏性问题------N-gram 阶数越高,训练数据中缺失该序列的可能性越大,估计的概率越不可靠。二元语法和三元语法在上下文覆盖和数据可靠性之间取得了良好的平衡,是传统 ASR 系统的常见配置。
句子开始标记 :为处理句子首词无前驱词的边界情况,通常在每个训练句子开头添加特殊标记 <s>,使首词概率也可以用 N-gram 公式统一计算。
5.4 困惑度(Perplexity)
困惑度(Perplexity,PPL) 是评估语言模型质量的标准指标,直观含义是"模型在预测下一个词时平均面临多少个等可能的选择"。
对于测试集中的词序列 W = ( w 1 , w 2 , ... , w N ) W = (w_1, w_2, \ldots, w_N) W=(w1,w2,...,wN),困惑度定义为:
PPL ( W ) = P ( w 1 , w 2 , ... , w N ) − 1 N = 1 P ( w 1 , w 2 , ... , w N ) N \text{PPL}(W) = P(w_1, w_2, \ldots, w_N)^{-\frac{1}{N}} = \sqrtN{\frac{1}{P(w_1, w_2, \ldots, w_N)}} PPL(W)=P(w1,w2,...,wN)−N1=NP(w1,w2,...,wN)1
等价地,可以用交叉熵(Cross-Entropy, H H H)表达:
PPL ( W ) = 2 H ( W ) , H ( W ) = − 1 N ∑ i = 1 N log 2 P ( w i ∣ w 1 , ... , w i − 1 ) \text{PPL}(W) = 2^{H(W)}, \quad H(W) = -\frac{1}{N} \sum_{i=1}^{N} \log_2 P(w_i \mid w_1, \ldots, w_{i-1}) PPL(W)=2H(W),H(W)=−N1i=1∑Nlog2P(wi∣w1,...,wi−1)
理解困惑度
| 场景 | 困惑度 | 含义 |
|---|---|---|
| 完美预测 | 1 | 模型对每个词都确定无疑地预测正确 |
| 均匀随机猜测(词汇量 V) | V | 模型完全不能利用上下文信息 |
| 实际语言模型 | 50--200(典型) | 困惑度越低,语言模型质量越高 |
困惑度的局限性
困惑度是基于对数概率计算的,对罕见词和未见 N-gram 的赋概方式非常敏感。两个模型在困惑度上的微小差距,有时在实际 ASR 的词错误率(WER)上可能并无显著差异,因此在工程实践中,困惑度通常与 WER 一起综合评估语言模型的实际效果。
N-gram 模型的零频率问题与平滑
当某个 N-gram 在训练数据中未出现(计数为 0)时,基于最大似然估计(MLE)的概率也为 0。将零概率乘入句子概率链,会导致整个句子概率为 0,过于极端。
解决方案是平滑(Smoothing):为未见 N-gram 分配一个小的非零概率,同时从已见 N-gram 中"借"部分概率质量。常用方法包括:
- 拉普拉斯(加一)平滑 :对每个 N-gram 计数加 1,分母加词汇量 V V V:
P ( w n ∣ w n − 1 ) = Count ( w n − 1 , w n ) + 1 Count ( w n − 1 ) + V P(w_n \mid w_{n-1}) = \frac{\text{Count}(w_{n-1}, w_n) + 1}{\text{Count}(w_{n-1}) + V} P(wn∣wn−1)=Count(wn−1)+VCount(wn−1,wn)+1
- Kneser-Ney 平滑:更精细地处理低频词,在实践中效果更优,是传统语言模型中的工业标准平滑方法。
5.5 语言模型如何提高准确性
语言模型通过以下机制改善 ASR 系统的转录准确性:
结合两种证据
解码器在生成转录时,综合声学证据与语言证据:
最终得分 ∝ P ( O ∣ W ) × P ( W ) \text{最终得分} \propto P(O \mid W) \times P(W) 最终得分∝P(O∣W)×P(W)
以"recognize speech" vs. "wreck a nice beach"为例:
| 候选 | 声学得分 | 语言模型概率 | 综合得分 |
|---|---|---|---|
| "recognize speech" | 0.85 | 0.70 | 0.595 |
| "wreck a nice beach" | 0.88 | 0.001 | 0.00088 |
即使声学得分稍低,语言模型对"recognize speech"的强烈偏好使其综合得分远高于声学上略占优势的错误候选。
领域适配
针对特定领域(医疗、法律、金融等)的 ASR 应用,可以用该领域的文本数据训练或微调语言模型,以提升专业术语和行业用语的识别准确率。
5.6 神经网络语言模型简介
传统 N-gram 模型存在两个核心局限:
- 数据稀疏性:无法有效处理训练中未见的词语序列。
- 固定上下文窗口:N-gram 只能利用固定数量的前驱词(通常 2--4 个),无法捕捉长距离依赖。
神经网络语言模型(NNLM) 通过以下机制克服了这些局限:
词嵌入(Word Embedding)
每个词被映射为稠密的实值向量(词向量),语义相近的词在向量空间中距离更近。例如,"nice"、"good"、"lovely"的词向量彼此接近。
这意味着:模型学会了"a good day"是常见表达后,即使从未见过"a nice day",也能根据"nice"与"good"的向量相似性,为"a nice day"分配合理的概率------泛化能力大幅提升。
序列记忆:RNN 与 LSTM
循环神经网络(RNN) 在处理序列时维护一个隐藏状态,该状态随每个新词更新,理论上能记住任意长度历史的信息。
长短期记忆网络(LSTM) 通过门控机制(输入门、遗忘门、输出门)解决了标准 RNN 的梯度消失问题,能够有效捕捉句子乃至段落级别的长距离依赖。
Transformer 与大语言模型(LLM)
近年来,基于自注意力机制(Self-Attention)的 Transformer 架构彻底改变了语言建模领域。以 GPT、BERT 为代表的大型预训练语言模型,在 N-gram 和 RNN 所有能力之上实现了质的飞跃,并逐渐被集成到现代端到端 ASR 系统中(如 Whisper 内部使用 Transformer 解码器作为语言建模组件)。
六、解码与系统集成
在前面的章节中,我们分别了解了声学模型(将音频特征映射到音素概率)和语言模型(评估词语序列的概率)。本章介绍最后一个关键环节:如何将两者的输出结合起来,高效地生成最终的文本转录。
语音识别的核心目标可以用一个公式表达:在给定观测音频特征 O O O 的前提下,找到使后验概率最大的词语序列 W ^ \hat{W} W^:
W ^ = arg max W P ( W ∣ O ) = arg max W P ( O ∣ W ) × P ( W ) \hat{W} = \underset{W}{\arg\max} \; P(W \mid O) = \underset{W}{\arg\max} \; P(O \mid W) \times P(W) W^=WargmaxP(W∣O)=WargmaxP(O∣W)×P(W)
其中 P ( O ∣ W ) P(O \mid W) P(O∣W) 由声学模型提供, P ( W ) P(W) P(W) 由语言模型提供,负责执行这一搜索的组件即为解码器。
6.1 解码器的作用
解码器是 ASR 系统的"决策引擎",扮演项目总指挥的角色:它不自行生成声学或语言信息,而是智能地整合来自声学模型和语言模型的所有可能性,寻找最优的词语序列。
可以将解码器类比为人脑的语言理解机制:听到一个模糊的短语时,大脑会即时考量不同词语的可能性,结合语法和语境做出判断------"ice cream"和"I scream"在声学上几乎无法区分,但大脑根据上下文几乎无需思考就能做出正确判断。
6.2 确定最可能的词语序列
解码器的任务是找出与输入音频 O O O 最匹配的单个词语序列 W W W------不仅声音上要匹配,语言上也要合理。
结合两种得分
对每个候选词序列(假设),解码器将声学模型得分与语言模型得分相乘,取综合得分最高者:
| 假设 | 声学得分 | 语言模型得分 | 综合得分 |
|---|---|---|---|
| "wreck a nice beach" | 0.90 | 0.0001 | 0.00009 |
| "recognize speech" | 0.88 | 0.10 | 0.088 |
即使声学得分非常接近,语言模型在综合得分中扮演了强大的"决胜者"角色。
使用对数概率
将多个概率(均介于 0 和 1 之间)连乘,容易产生**数值下溢(Numerical Underflow)**问题------结果小到计算机将其视为零。实际系统中通过取对数将乘法转化为加法,计算更稳定:
W ^ = arg max W log P ( O ∣ W ) + log P ( W ) \hat{W} = \underset{W}{\arg\max} \left \\log P(O \\mid W) + \\log P(W) \\right W^=WargmaxlogP(O∣W)+logP(W)
由于概率的对数是负数,这等价于寻找对数概率之和最接近零(即最大)的候选序列。
6.3 搜索算法概览
可能的词语序列数量是天文数字------一个包含 20,000 词的词汇表,五词句子的组合数量为 20000 5 20000^5 200005,穷举搜索根本不可行。
将搜索转化为路径寻优问题
将解码过程看作在一张有向图(篱笆图/格子图,Lattice)上寻找最优路径:
- 图中的每个节点代表某个时间步上的某个词或音素;
- 每条边关联一个基于声学和语言概率计算的"代价";
- 声学匹配差或语言上不太可能的路径代价高,会被优先放弃。
束搜索(Beam Search)与剪枝
束搜索 是一种高效的启发式搜索策略:在每个时间步,解码器只保留当前得分最高的前 B B B 个假设("束宽"),丢弃其余。 B B B 越大,搜索越全面但计算越慢; B B B 越小,速度越快但可能错过最优解。实际系统通常在精度与效率之间选取合适的束宽。
6.4 理解维特比算法
维特比算法(Viterbi Algorithm) 是一种基于动态规划(Dynamic Programming) 的经典最优路径搜索算法,保证在时间高效的前提下找到通过格子图的全局最优路径。
动态规划的核心思想:将复杂问题分解为子问题,每个子问题只求解一次并缓存结果。维特比算法利用这一思想,每次只需知道到达上一时间步各状态的最优路径,即可推导当前时间步的最优路径,无需保留所有历史。
算法流程(以"recognize speech" vs. "wreck a nice beach"为例)
- 时间步 1:分析第一段音频,两个候选序列得分相近,均保留。
- 时间步 2:分析后续音频,计算 4 条可能路径(各词×各后续词)的综合得分。语言概率极低的路径(如 "recognize" → "beach")被标记为低分。
- 剪枝:在每步保留到达每个节点的最高概率路径,丢弃次优路径。
- 回溯(Backtracking):算法到达音频终点后,确定总体最优路径的最后一个词,然后沿保存的回溯指针逆向追溯,重建完整的最优词语序列。
维特比算法的保证:在不穷举所有可能组合的前提下,找到全局最优的词语序列,是经典 HMM 解码的标准算法。
6.5 完整的 ASR 流程回顾
将各章节内容贯通,完整的 ASR 流程如下:
原始音频
│
▼
【特征提取】
预加重 → 分帧 → 窗函数 → FFT → 梅尔滤波器 → 取对数 → DCT → MFCC 特征矩阵
│
▼
【声学模型(AM)】
输入:MFCC 特征向量序列
输出:逐帧音素概率分布 P(O | W)
│
├──────────────────────┐
│ ▼
│ 【语言模型(LM)】
│ 输入:候选词序列
│ 输出:词序列概率 P(W)
│ │
▼ │
【解码器(Decoder)】
整合声学概率 + 语言概率 + 发音词典
W_hat = argmax P(O|W) × P(W)
使用维特比算法 / 束搜索高效寻优
│
▼
【最终文本输出】
最优词语序列(转录结果)
│
▼
【后处理(Pipeline)】
标点预测(PUNC)→ 逆文本正则化(ITN)→ 最终可读文本每个阶段的职责总结
| 阶段 | 输入 | 输出 | 核心问题 |
|---|---|---|---|
| 特征提取 | 原始音频 | MFCC 特征矩阵 | 如何将音频压缩为有效特征? |
| 声学模型 | 特征向量序列 | 音素概率分布序列 | 这段声音听起来像哪个音素? |
| 语言模型 | 候选词序列 | 词序列概率 | 这些词在语言中合理吗? |
| 解码器 | AM + LM 输出 | 最优词序列 | 综合两种证据,最可能的句子是什么? |
| 后处理 | 原始转录文本 | 规范化文本 | 标点、数字、专有名词如何规范? |
七、评估与性能指标
7.1 词错误率(WER)
词错误率(Word Error Rate,WER) 是 ASR 系统最核心的评估指标,定义为:
WER = S + D + I N × 100 % \text{WER} = \frac{S + D + I}{N} \times 100\% WER=NS+D+I×100%
其中:
- S S S:替换错误数(Substitutions,一个词被错误地识别为另一个词)
- D D D:删除错误数(Deletions,漏识别某个词)
- I I I:插入错误数(Insertions,识别出了原文中没有的词)
- N N N:参考文本中的词语总数
WER 越低,系统性能越好;WER = 0 表示完美识别。现代端到端 ASR 系统在标准英语测试集(如 LibriSpeech clean)上可以达到 2%--4% 的 WER。
7.2 影响 ASR 准确性的常见因素
| 因素 | 说明 |
|---|---|
| 背景噪声 | 餐厅、街道等嘈杂环境大幅降低识别率 |
| 口音与方言 | 训练数据未覆盖的口音会导致泛化能力下降 |
| 说话风格 | 自发语音(包含停顿、重复、不完整句子)比朗读语音更难识别 |
| 专业词汇 | 医疗、法律等领域的专业术语在通用模型中识别率较低 |
| 采样率与音质 | 低采样率(如 8 kHz 电话信道)信息损失较大 |
| 语速 | 极快语速下语音模糊,极慢语速下停顿切分困难 |
本文持续更新,如有错误或补充建议,欢迎反馈。