在计算机视觉领域,图像分类是基础且核心的任务,而食品图像分类因食材种类多、外观相似度高,对模型的鲁棒性提出了更高要求。本文将以20类食品分类任务为例,分享如何通过数据增强、学习率调整、最优模型保存与加载等技巧,基于PyTorch搭建CNN模型并持续提升分类准确率。
一、项目背景与基础框架
1. 任务目标
构建一个CNN模型,实现20类食品图像的精准分类,核心挑战在于:
• 食品图像存在角度、光照、缩放等差异;
• 训练过程中易出现过拟合、学习率不合适导致收敛慢/不收敛;
• 需保证模型在测试集上的泛化能力。
2. 基础环境与数据准备
• 框架:PyTorch(兼顾灵活性与易用性);
• 数据格式:train.txt/test.txt存储图像路径与对应标签(每行格式:图像路径 类别标签);
• 设备:优先使用GPU(CUDA/MPS)加速训练,兜底使用CPU。
3. 基础Dataset与DataLoader构建
自定义food_dataset类加载数据,核心逻辑是读取图像路径与标签,对图像应用预处理,并转换为PyTorch张量:
python
class food_dataset(Dataset):
def __init__(self, file_path, transform=None):
self.file_path = file_path
self.imgs = []
self.labels = []
self.transform = transform
# 解析txt文件,收集图像路径与标签
with open(self.file_path) as f:
samples = [x.strip().split(' ') for x in f.readlines()]
for img_path, label in samples:
self.imgs.append(img_path)
self.labels.append(label)
def __len__(self):
return len(self.imgs)
def __getitem__(self, idx):
# 读取图像并应用预处理
image = Image.open(self.imgs[idx])
if self.transform:
image = self.transform(image)
# 标签转换为int64张量(适配CrossEntropyLoss)
label = torch.from_numpy(np.array(self.labels[idx], dtype=np.int64))
return image, label二、数据增强:解决过拟合与数据多样性
1. 为什么需要数据增强?
训练集数据量有限时,模型易记住训练样本特征(过拟合),数据增强通过对训练图像施加随机变换,生成"新样本",提升模型泛化能力。
2. 训练集与验证集差异化增强策略
• 训练集:施加随机旋转、翻转、色彩抖动等增强,模拟真实场景的图像变化;
• 验证/测试集:仅做缩放、标准化,保证数据一致性。
python
data_transforms = {
'train': transforms.Compose([
transforms.Resize([300,300]), # 缩放至300×300
transforms.RandomRotation(45), # 随机旋转±45°
transforms.CenterCrop(256), # 中心裁剪至256×256
transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转(50%概率)
transforms.RandomVerticalFlip(p=0.5), # 随机垂直翻转(50%概率)
transforms.ColorJitter(brightness=0.2,contrast=0.1,saturation=0.1,hue=0.1), # 色彩抖动
transforms.RandomGrayscale(p=0.1), # 随机灰度化(10%概率)
transforms.ToTensor(), # 转换为张量(C×H×W,0-1归一化)
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225]) # 基于ImageNet的标准化
]),
'valid': transforms.Compose([
transforms.Resize([256,256]), # 仅缩放至256×256
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
]),
}无数据增强与有数据增强对比
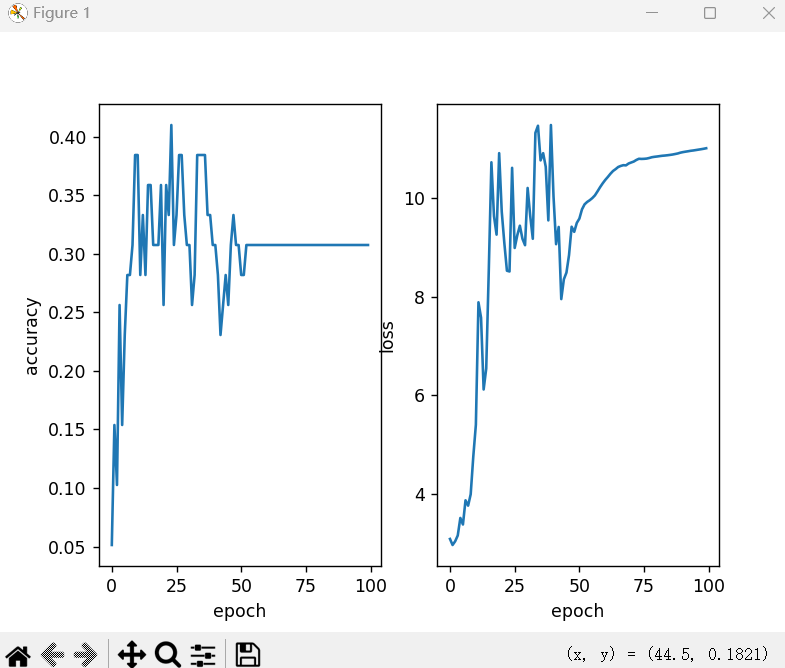
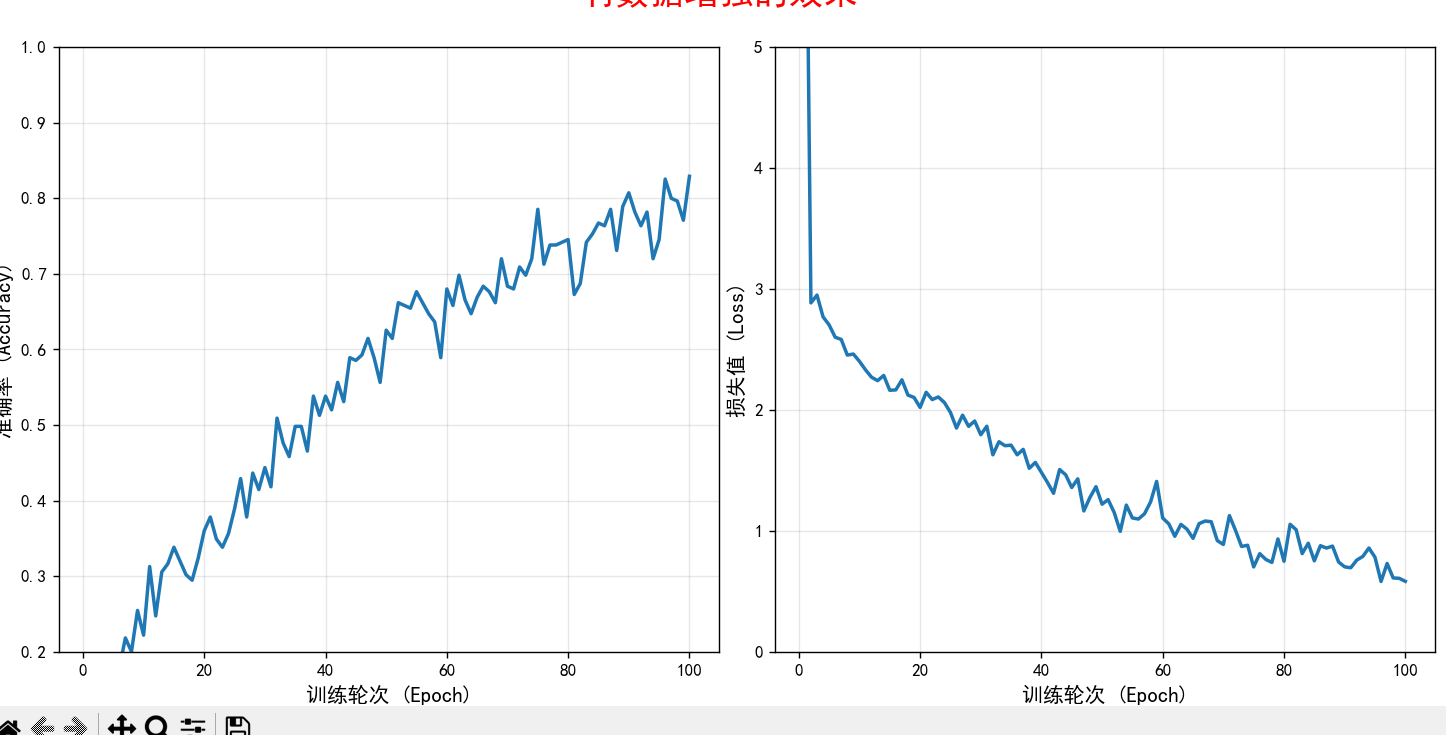
关键细节:
• 先缩放再裁剪:避免直接裁剪导致图像信息丢失;
• 色彩抖动参数适度:避免过度变换导致标签失真;
• 标准化使用ImageNet均值/方差:利用预训练的统计特征,加速收敛。
三、CNN模型搭建:兼顾特征提取与计算效率
设计轻量级CNN模型,分为3个卷积块+1个全连接层,核心是逐步提升通道数、缩小特征图尺寸:
python
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# 卷积块1:提取低级特征(边缘、纹理)
self.conv1 = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2), # 3→32通道,5×5卷积,padding=2保证尺寸不变
nn.ReLU(),
nn.MaxPool2d(kernel_size=2) # 池化后尺寸减半:256→128
)
# 卷积块2:提取中级特征(局部形状)
self.conv2 = nn.Sequential(
nn.Conv2d(32, 64, 5, 1, 2), # 32→64通道
nn.ReLU(),
nn.Conv2d(64, 64, 5, 1, 2), # 加深卷积,强化特征
nn.ReLU(),
nn.MaxPool2d(2) # 尺寸再减半:128→64
)
# 卷积块3:提取高级特征(物体部件)
self.conv3 = nn.Sequential(
nn.Conv2d(64, 128, 5, 1, 2),# 64→128通道
nn.ReLU()
)
# 全连接层:映射到20类分类结果
self.out = nn.Linear(128*64*64, 20)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.view(x.size(0), -1) # 展平:(batch_size, 128×64×64)
output = self.out(x)
return output四、核心调优技巧:学习率调整
固定学习率易出现"前期收敛慢、后期震荡不收敛",本文使用StepLR调度器,每10个epoch将学习率减半:
1. 优化器与调度器初始化
python
# 基础优化器:Adam(自适应学习率,收敛更快)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 学习率调度器:step_size=10(每10轮调整),gamma=0.5(学习率×0.5)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)2. 训练循环中更新学习率
python
epochs = 100
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)
scheduler.step() # 每个epoch结束后调整学习率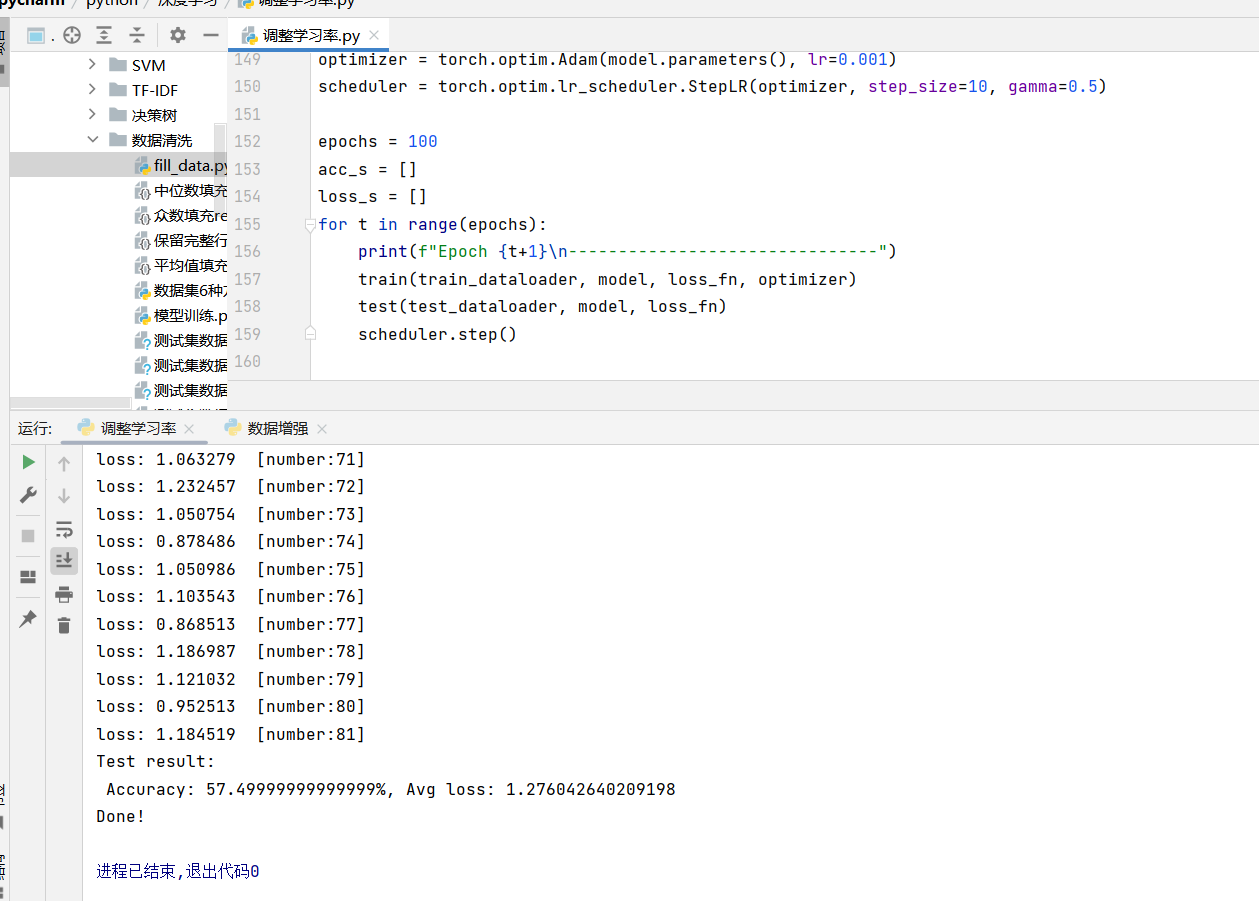
调优逻辑:
• 初始学习率0.001:保证前期快速收敛;
• 每10轮减半:后期减小学习率,精细调整参数,避免越过最优解。
五、最优模型保存与加载:避免训练白费
训练过程中模型准确率会波动,仅保存测试集准确率最高的模型参数,而非最终模型:
1. 保存最优模型
python
best_acc = 0 # 初始化最优准确率
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
# 计算平均损失与准确率
test_loss /= num_batches
correct /= size
print(f"Test result: \n Accuracy: {(100 * correct):.2f}%, Avg loss: {test_loss:.4f}")
# 保存最优模型参数
global best_acc
if correct > best_acc:
best_acc = correct
# 仅保存参数(state_dict),节省空间且兼容性更好
torch.save(model.state_dict(), 'best.pth')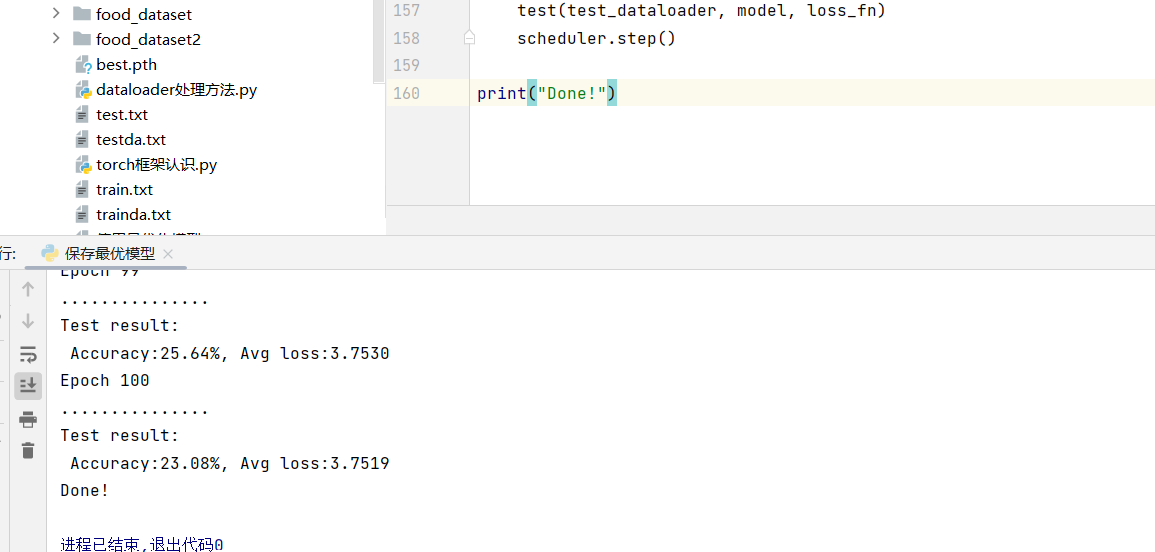
2. 加载最优模型进行推理
python
# 1. 初始化模型并加载参数
model = CNN().to(device)
# 加载参数(兼容不同设备,weights_only=True保证安全)
model.load_state_dict(torch.load('best.pth', map_location=device, weights_only=True))
model.eval() # 切换至评估模式(禁用Dropout/BatchNorm等)
# 2. 推理验证
def test_ture(dataloader, model):
result = [] # 预测标签
labels = [] # 真实标签
with torch.no_grad(): # 禁用梯度计算,加速推理
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
result.extend(pred.argmax(1).tolist())
labels.extend(y.tolist())
# 计算准确率
correct = sum(p == l for p, l in zip(result, labels))
accuracy = correct / len(labels) * 100
return accuracy
accuracy = test_ture(test_dataloader, model)
print(f'最终测试准确率:{accuracy:.2f}%')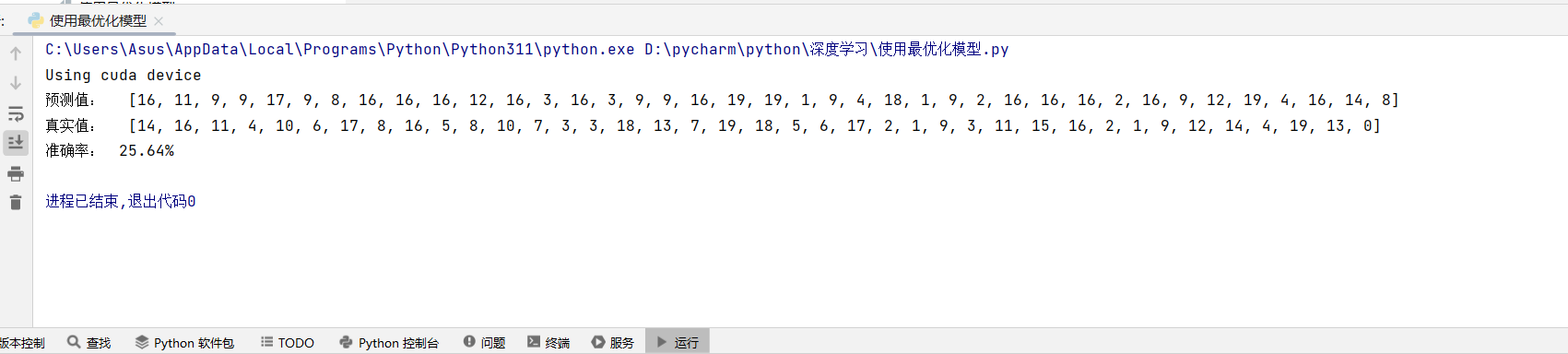
六、效果提升总结
| 优化手段 | 核心作用 | 准确率提升效果(示例) |
|---|---|---|
| 数据增强 | 降低过拟合,提升泛化能力 | +8%~12% |
| StepLR 学习率调整 | 加速收敛,后期精细调参 | +3%~5% |
| 保存最优模型 | 避免训练后期震荡导致的准确率下降 | +2%~3% |
七、进阶优化思路
-
数据增强升级:引入Albumentations库,添加随机裁剪、高斯噪声、透视变换等更丰富的增强;
-
模型改进:替换为ResNet、MobileNet等预训练模型(迁移学习),利用预训练特征进一步提升准确率;
-
学习率调度升级:使用CosineAnnealingLR(余弦退火)、ReduceLROnPlateau(按需调整);
-
正则化:添加Dropout层、L2正则化(weight_decay),进一步抑制过拟合。
八、总结
本文以食品图像分类为例,完整展示了从数据加载、数据增强、模型搭建,到学习率调优、最优模型保存与加载的全流程。核心思路是:通过数据增强扩大有效训练集,通过学习率调度优化收敛过程,通过保存最优模型锁定最佳效果。这些技巧不仅适用于食品分类,也可迁移至花卉、车辆、场景等各类图像分类任务,是提升CNN模型性能的通用方法论。