Kubernetes基础入门教程
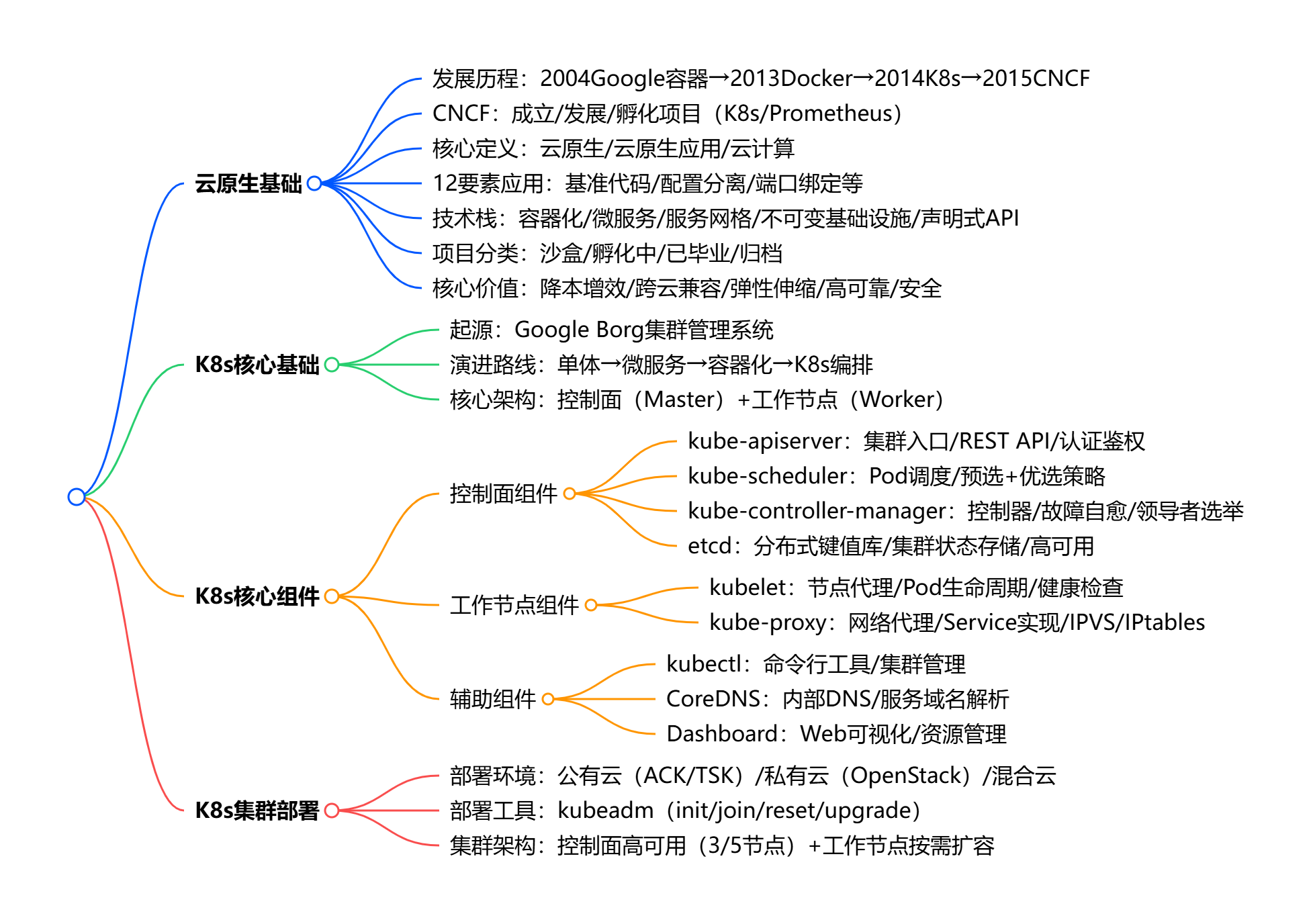
目录
第1章 云原生基础认知
1.1 云原生发展历程
1.2 CNCF云原生计算基金会
1.3 云原生核心定义与概念
1.4 云原生12要素应用
1.5 云原生技术栈与项目分类
1.6 云原生的核心价值
第2章 Kubernetes核心基础
2.1 Kubernetes起源与发展
2.2 容器化到K8s的演进路线
2.3 Kubernetes核心架构(控制面+工作节点)
第3章 Kubernetes核心组件详解
3.1 控制面组件(kube-apiserver/kube-scheduler/kube-controller-manager/etcd)
3.2 工作节点组件(kubelet/kube-proxy)
3.3 辅助组件(DNS/Dashboard/kubectl)
第4章 Kubernetes集群基础部署
4.1 K8s集群部署环境(公有云/私有云)
4.2 K8s集群部署工具(kubeadm)
第1章 云原生基础认知
知识图
云原生基础认知
├─ 发展历程(2004-2022关键节点)
├─ CNCF(成立/成员/使命)
├─ 核心定义(概念/应用/云计算区别)
├─ 12要素应用(核心原则)
├─ 技术栈+项目分类(技术栈组成/CNCF项目四阶段)
└─ 核心价值(降本增效/兼容/弹性/可靠/安全)1.1 云原生发展历程
知识点
云原生技术的发展依托容器、集群管理技术的迭代,核心企业(Google/Redhat等)和开源社区推动了整个生态的成熟,关键时间节点奠定了云原生的技术基础。
实例
Google从2004年开始内部大规模使用容器技术,为后续K8s诞生积累了大量实践经验;2013年Docker发布让容器技术普及,2014年K8s发布实现容器的规模化管理。
表格
|------|---------------------------|------------------|
| 年份 | 关键事件 | 行业影响 |
| 2004 | Google内部大规模使用容器技术 | 容器技术实践落地,积累核心经验 |
| 2008 | Google将Cgroups合并入Linux内核 | 为容器资源隔离提供内核级支持 |
| 2013 | Docker项目正式发布 | 容器技术平民化,推动行业普及 |
| 2014 | Kubernetes项目正式发布 | 容器编排技术诞生,实现规模化管理 |
| 2015 | CNCF云原生计算基金会成立 | 云原生生态标准化、开源化发展 |
| 2022 | CNCF覆盖187国/820+企业/16万+开发者 | 云原生成为全球主流技术体系 |
1.2 CNCF云原生计算基金会
知识点
CNCF由Google牵头,联合Redhat、微软等厂商2015年成立,是云原生领域的核心开源基金会,核心使命是支持开源社区开发云原生组件,孵化并推广云原生项目。
实例
CNCF孵化出Kubernetes、Prometheus、Harbor、etcd等核心云原生项目,成为企业构建云原生架构的标配工具。
表格
|----------|-------|----------------------------|-----------------|
| CNCF发展阶段 | 时间 | 核心数据 | 生态特征 |
| 初期 | 2015年 | 由Google等牵头成立 | 聚焦核心容器编排项目孵化 |
| 成长 | 2017年 | 170个成员/14个基金项目 | 项目数量快速增长,生态初步成型 |
| 成熟 | 2018年 | 195个成员/19基金+11孵化项目 | 项目分层,孵化/毕业体系完善 |
| 全球化 | 2022年 | 187国/820+企业/130+项目/16万+开发者 | 全球覆盖,成为云原生行业标准 |
1.3 云原生核心定义与概念
知识点
- 云原生:2013年诞生于技术社区,是一套先进架构理念的集合,也是可落地的生产环境方法论,核心是在云环境构建、部署、管理现代应用,让企业聚焦业务开发,而非底层环境。
- 云原生应用:由独立的微服务组成,可独立部署、运行,相比单体应用更敏捷。
- 云计算:按需付费的基础设施服务,为云原生提供运行环境,企业无需自建硬件集群。
- 核心区别:云计算是运行环境 ,云原生是应用的构建/交付方法,而非简单的"云部署"。
实例
某电商企业将单体电商系统拆分为用户、订单、支付、商品4个微服务(云原生应用),部署在阿里云的ECS/RDS等云计算资源上,通过K8s管理,实现各微服务独立迭代、弹性伸缩。
表格
|-------|--------------------------|----------------------|
| 概念 | 核心内涵 | 核心目标 |
| 云原生 | 微服务/DevOps/容器等架构理念+落地方法论 | 快速交付、迭代应用,降低成本,提高稳定性 |
| 云原生应用 | 由独立微服务组成的业务程序 | 敏捷开发、独立部署、资源轻量化 |
| 云计算 | 按需付费的托管式基础设施服务 | 减少企业硬件投入,降低运维成本 |
1.4 云原生12要素应用
知识点
12要素应用是Pivotal2015年提出的云原生应用构建标准,是云原生应用的核心设计原则,确保应用可移植、可伸缩、易维护,适配云环境的动态特性。
实例
某微服务项目通过Nacos做配置中心(要素3:配置与代码分离),通过Docker打包(要素5:构建/发布/运行分离),通过多副本部署实现弹性扩展(要素8:并发)。
表格
|----|-----------|-------------------|----------------------------------|
| 序号 | 要素名称 | 核心要求 | 落地实例 |
| 1 | 基准代码 | 一份代码库,多份部署,版本控制 | Git管理代码,开发/测试/生产环境用同一代码库 |
| 2 | 依赖 | 显式声明、隔离微服务依赖 | Maven/Gradle声明依赖,Docker容器隔离依赖环境 |
| 3 | 配置 | 配置在代码之外,动态注入 | 配置中心(Nacos/Apollo)、K8s ConfigMap |
| 4 | 后端服务 | 把后端服务当作附加资源,API调用 | 数据库/缓存/消息队列通过API访问,可灵活替换 |
| 5 | 构建/发布/运行 | 严格分离三个阶段 | 构建(打包镜像)→发布(镜像打标签)→运行(启动容器) |
| 6 | 进程 | 无状态进程,独立运行环境 | 微服务以无状态部署,会话存在Redis等中间件 |
| 7 | 端口绑定 | 服务通过端口绑定对外提供访问 | 微服务监听8080端口,K8s通过Service暴露端口 |
| 8 | 并发 | 多副本横向扩展,应对高并发 | K8s Deployment设置副本数,根据负载自动扩缩容 |
| 9 | 易处理 | 快速启动、优雅终止,保证可用性 | 容器秒级启动,K8s优雅停止Pod,等待请求处理完成 |
| 10 | 开发/线上环境等价 | 环境尽可能一致 | 开发/测试/生产均使用Docker容器,统一依赖版本 |
| 11 | 日志 | 日志作为事件流,统一收集存储 | 容器输出日志到标准输出,Fluentd收集到ELK |
| 12 | 管理进程 | 一次性进程完成管理任务,与业务隔离 | K8s CronJob做数据备份,Init容器做初始化操作 |
1.5 云原生技术栈与项目分类
知识点
- 云原生技术栈核心组成:容器化、微服务、服务网格、不可变基础设施、声明式API,是构建云原生应用的技术底座。
- CNCF项目分四个阶段:沙盒(Sandbox)、孵化中(Incubating)、已毕业(Graduated)、归档(Archived),按成熟度和生产可用性划分。
实例
企业构建云原生架构时,用Docker做容器化(容器化技术)、Spring Cloud做微服务(微服务技术)、Istio做服务网格(服务网格技术)、K8s镜像做不可变基础设施,通过K8s YAML做声明式API定义应用状态。
表格
云原生核心技术栈
|---------|------------------|----------------------------|
| 技术模块 | 核心概念 | 代表工具 |
| 容器化 | 应用打包与运行环境隔离 | Docker、containerd |
| 微服务 | 业务拆分为松耦合、独立部署的服务 | Spring Cloud、Apache Dubbo |
| 服务网格 | 微服务间的流量管理、监控、治理 | Service Mesh、Istio、Linkerd |
| 不可变基础设施 | 部署后不修改,通过镜像更新 | K8s镜像、容器镜像 |
| 声明式API | 描述应用状态,系统自动实现 | K8s YAML配置、CRD |
CNCF项目分类
|-----------------|-----|------------------|------------------------------------|
| 项目阶段 | 成熟度 | 生产可用性 | 代表项目 |
| Sandbox(沙盒) | 最低 | 未经过生产广泛测试,实验性 | 各类新兴实验项目 |
| Incubating(孵化中) | 中等 | 少数用户生产成功使用,贡献者活跃 | Harbor、Rook |
| Graduated(已毕业) | 最高 | 稳定、广泛生产采用,贡献者众多 | Kubernetes、Prometheus、etcd、CoreDNS |
| Archived(归档) | - | 生命周期结束,不再维护 | 不再活跃的老旧项目 |
1.6 云原生的核心价值
知识点
云原生为企业带来全链路的价值提升,核心体现在降本增效、跨云兼容、弹性伸缩、高可靠高可用、安全防护五大维度,是企业数字化转型的核心技术支撑。
实例
某互联网企业采用云原生架构后,业务迭代周期从1个月缩短为1周(降本增效);同时部署在阿里云和私有云,实现多云兼容;双十一期间通过K8s弹性伸缩,Pod副本数从10个扩到100个,应对高并发(弹性伸缩)。
表格
|--------|--------------------------|--------------------------------------|
| 核心价值 | 具体体现 | 落地方式 |
| 降本增效 | 降低前期落地/后期运营成本,业务快速迭代 | 微服务独立开发、容器化部署、CI/CD自动化 |
| 跨云兼容 | 多环境部署/运维成本降低,适配公有/私有/混合云 | 基于CNCF标准工具,避免云厂商锁定 |
| 弹性伸缩 | 应对高并发,资源按需分配 | K8s HPA(水平Pod自动扩缩容)、弹性容器实例 |
| 高可靠高可用 | 节点故障自动恢复,Pod副本始终符合预期 | K8s控制器管理、节点容灾、异地多活 |
| 安全性 | 全链路访问控制、加密、资源防护 | K8s Ingress/SLB、RBAC鉴权、Secret加密、镜像扫描 |
第2章 Kubernetes核心基础
K8S中文网:
知识图
Kubernetes核心基础
├─ 起源(Google Borg集群管理系统)
├─ 演进路线(单体应用→微服务→容器化→K8s编排)
└─ 核心架构
├─ 控制面(Master Node):核心管理节点
└─ 工作节点(Worker Node):应用运行节点2.1 Kubernetes起源与发展
知识点
- Kubernetes(简称K8s)源于Google内部的Borg集群管理系统,Borg是Google核心的大规模集群管理工具,实现跨数据中心资源利用率最大化,让用户聚焦业务。
- K8s2014年正式发布,基于Borg的实践经验,开源后成为CNCF核心项目,目前是云原生领域事实标准的容器编排工具。
- Borg核心组成:BorgMaster(主节点)、Borglet(节点代理)、borgcfg(配置文件)、Scheduler(调度器),对应K8s的核心组件设计。
实例
Google通过Borg管理数万台服务器,支撑搜索、YouTube等核心业务的运行,K8s继承了Borg的核心设计思想,如容器编排、资源调度、故障自愈,让中小企业也能使用Google级别的集群管理技术。
表格
|------------|-----------------|-----------|--------------------------------------|--------------------------|
| 项目 | 开发主体 | 核心定位 | 核心组成 | 应用场景 |
| Borg | Google内部 | 大规模集群管理系统 | BorgMaster、Borglet、borgcfg、Scheduler | Google内部核心服务(搜索/YouTube) |
| Kubernetes | Google开源+CNCF维护 | 开源容器编排工具 | 控制面组件+工作节点组件+etcd | 企业公有/私有/混合云的容器集群管理 |
2.2 容器化到K8s的演进路线
知识点
企业应用架构从单体应用向云原生演进的核心路线:单体应用拆分为微服务→微服务容器化(Docker)→K8s实现容器的编排与管理,解决容器的规模化部署、调度、监控、故障恢复问题。
实例
某招聘网站最初是单体应用,包含求职者、职位、招聘者所有功能,迭代慢、扩容难;拆分为求职者、职位、招聘者3个微服务后,各自独立开发;再用Docker为每个微服务制作镜像,实现环境一致;最后部署到K8s,由K8s管理容器的启动、调度、扩缩容。
表格
|-------|---------------|--------------------|------------------|-----------------|
| 演进阶段 | 架构特点 | 技术工具 | 核心问题 | 解决思路 |
| 单体应用 | 所有功能耦合,单一部署包 | 传统开发框架(SSM/SSH) | 迭代慢、扩容难、故障影响全局 | 按业务功能拆分为微服务 |
| 微服务 | 业务解耦,独立部署/运行 | Spring Cloud/Dubbo | 服务数量多,环境不一致,部署复杂 | 微服务容器化,统一运行环境 |
| 容器化 | 微服务打包为镜像,环境隔离 | Docker/containerd | 容器数量多,调度/监控/自愈难 | 用K8s做容器编排管理 |
| K8s编排 | 容器规模化管理,自动化运维 | Kubernetes | - | 实现云原生应用的全生命周期管理 |
2.3 Kubernetes核心架构
知识点
K8s集群采用主从架构 ,分为控制面(Master Node) 和工作节点(Worker Node) 两部分,控制面负责集群的管理和调度,工作节点负责运行实际的应用容器(以Pod为单位),所有组件通过kube-apiserver交互,集群状态存储在etcd中。
实例
一个典型的K8s集群包含3个控制面节点(高可用)和5个工作节点,控制面的kube-apiserver接收kubectl的指令,kube-scheduler将Pod调度到空闲的工作节点,kubelet在工作节点上启动Pod,kube-proxy实现Pod的网络访问。
表格
|--------------|------------|------------------------------------------------------------|------------------------|
| 集群节点 | 核心角色 | 核心组件 | 核心功能 |
| 控制面(Master) | 集群管理、调度、决策 | kube-apiserver、kube-scheduler、kube-controller-manager、etcd | 接收指令、调度Pod、故障自愈、存储集群状态 |
| 工作节点(Worker) | 应用运行、容器管理 | kubelet、kube-proxy、容器运行时(Docker/containerd)、Pod | 启动/监控Pod、实现网络转发、运行应用容器 |
第3章 Kubernetes核心组件详解
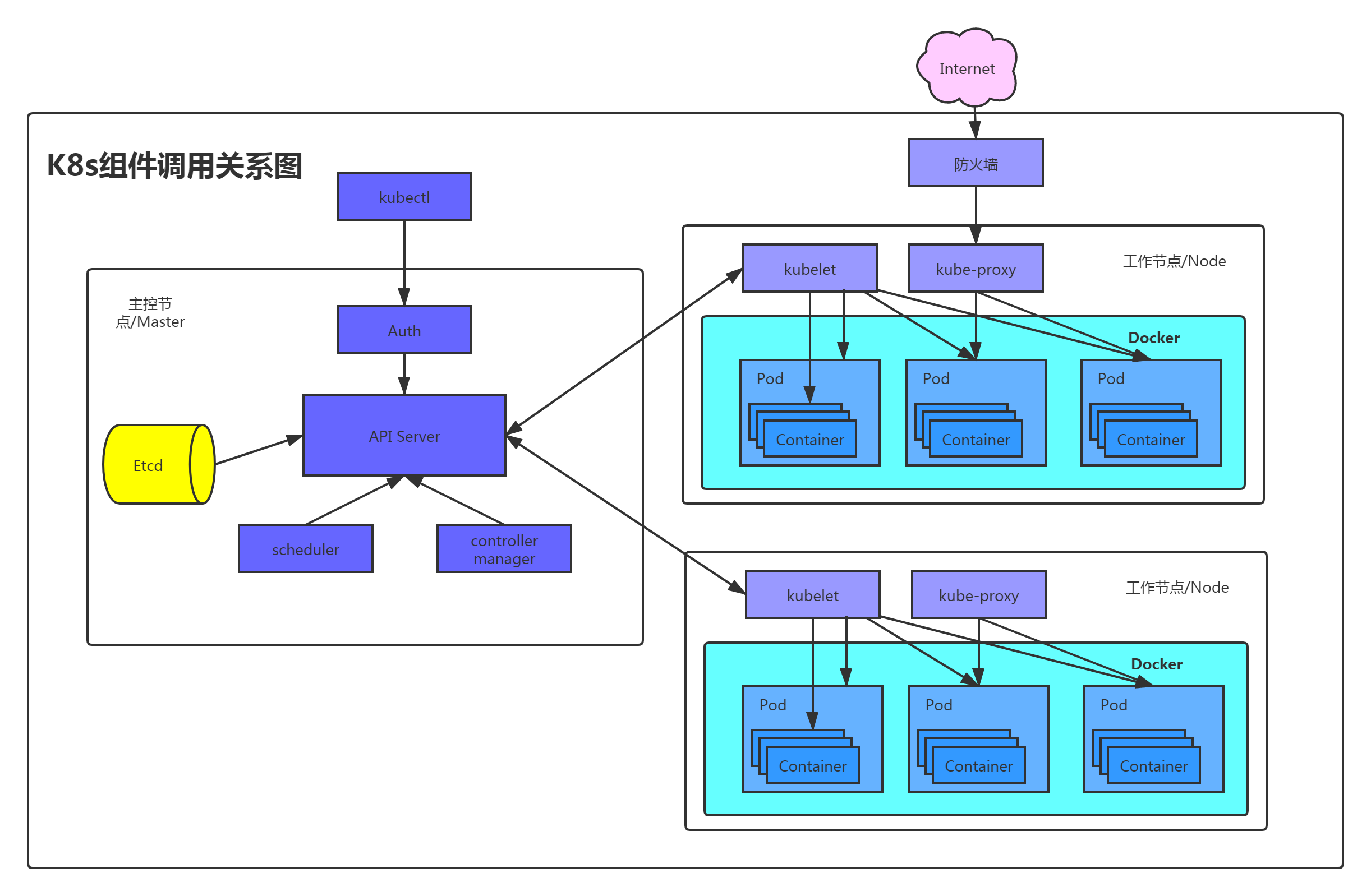
知识图
Kubernetes核心组件详解
├─ 控制面组件
│ ├─ kube-apiserver:集群入口,REST API服务
│ ├─ kube-scheduler:Pod调度器,节点选择
│ ├─ kube-controller-manager:控制器,故障自愈/副本管理
│ └─ etcd:集群数据库,存储所有状态数据
├─ 工作节点组件
│ ├─ kubelet:节点代理,Pod生命周期管理
│ └─ kube-proxy:网络代理,服务访问/负载均衡
└─ 辅助组件
├─ kubectl:命令行客户端,集群管理工具
├─ DNS(CoreDNS):集群内部DNS解析
└─ Dashboard:Web可视化管理界面3.1 控制面组件
3.1.1 kube-apiserver
知识点
- K8s的唯一入口,提供HTTPS RESTful API,实现集群所有资源的增删改查/监控,所有组件(scheduler/controller-manager/kubelet)都通过它交互。
- 核心特性:认证(Token/证书/HTTP Base)、鉴权(RBAC)、准入控制,默认监听6443端口,0.0.0.0地址,可通过启动参数修改。
- API版本分为:Alpha(预览版,不稳定)、Beta(测试版,不建议生产)、v1/v2(稳定版,生产可用)。
实例
通过kubectl get nodes查询节点状态,kubectl将请求发送到kube-apiserver,apiserver认证后从etcd获取数据并返回;通过curl命令直接调用apiserver的API查询集群信息:
# 查看集群API版本信息
curl --cacert /etc/kubernetes/ssl/ca.pem -H "Authorization: Bearer ${TOKEN}" https://172.31.7.101:6443/version表格
|-------|--------------------------------|----------------------------------------|-----------------------|
| 核心特性 | 具体实现 | 配置方式 | 生产建议 |
| 网络监听 | 默认6443端口/0.0.0.0 | --secure-port修改端口,--bind-address修改监听IP | 监听内网IP,禁止公网直接访问6443端口 |
| 认证鉴权 | Token/客户端证书/HTTP Base认证,RBAC鉴权 | 配置认证策略、RBAC规则 | 启用客户端证书认证,严格配置RBAC权限 |
| API版本 | Alpha/Beta/稳定版(v1) | 调用API时指定版本(如/api/v1) | 生产环境仅使用稳定版API |
| 集群交互 | 所有组件的统一交互入口 | 组件通过apiserver访问etcd/同步状态 | 部署多apiserver实现高可用 |
3.1.2 kube-scheduler
https://kubernetes.io/zh-cn/docs/concepts/architecture/#kube-controller-manager
知识点
- 负责Pod调度 ,将待调度的Pod分配到合适的Worker Node,调度分为预选策略 和优选策略两步,最终将调度结果写入etcd。
- 预选策略:过滤掉不满足Pod需求的节点(如资源不足、卷冲突、污点不匹配)。
- 优选策略:对预选后的节点评分,选择分数最高的节点(如资源消耗最小、资源使用率最均衡)。
- 调度完成后,kubelet通过apiserver监听到Pod绑定信息,启动容器。
实例
一个需要4核CPU的Pod,scheduler先预选过滤掉2核、3核的节点,剩下4核、8核的节点;
再通过LeastRequestedPriority优选策略,为资源消耗小的节点打分,最终将Pod调度到8核节点(资源更充足)。
表格
|--------------|----------------------------|-------------------------|-------------|
| 调度阶段 | 核心策略 | 策略说明 | 作用 |
| 预选策略(Filter) | NoDiskConflict | 检查Pod卷与节点卷是否冲突 | 过滤卷冲突的节点 |
| | PodFitsResources | 检查节点资源(CPU/内存)是否满足Pod需求 | 过滤资源不足的节点 |
| | PodSelectorMatches | 检查节点是否包含Pod的标签选择器 | 过滤标签不匹配的节点 |
| | PodToleratesNodeTaints | 检查Pod是否容忍节点的污点 | 过滤污点不匹配的节点 |
| 优选策略(Rank) | LeastRequestedPriority | 资源消耗最小的节点评分高 | 优先选择资源充足的节点 |
| | BalancedResourceAllocation | 资源使用率最均衡的节点评分高 | 优化节点资源利用率 |
| | CalculateNodeLabelPriority | 含指定Label的节点评分高 | 按业务需求指定节点调度 |
| | TaintTolerationPriority | 按污点容忍匹配度评分 | 适配节点污点策略 |
3.1.3 kube-controller-manager
https://kubernetes.io/zh-cn/docs/concepts/architecture/#kube-controller-manager
知识点
- 集群的控制中心 ,包含多个子控制器(副本控制器、节点控制器、命名空间控制器等),实现故障自愈、副本管理、节点管理等核心功能。
- 核心特性:基于领导者选举实现高可用(--leader-elect=true),通过分布式锁抢占leader,leader超时未更新则重新选举。
- 节点故障处理机制:5秒检查一次节点状态→40秒未收到心跳标记为不可达→5分钟未恢复则驱逐节点上的Pod并在其他节点重建。
实例
某Worker Node宕机,kube-controller-manager的节点控制器5秒后发现节点无心跳,40秒后将节点标记为NotReady,5分钟后删除该节点上的所有Pod,并通过副本控制器在其他正常节点重建Pod,保证应用副本数符合预期。
表格
|---------|--------------------------|---------------------------------------------------------------------------------------|----------------------------|
| 核心子控制器 | 功能 | 配置参数 | 生产参数 |
| 节点控制器 | 节点状态监控、故障处理 | node-monitor-period(节点检查周期) node-monitor-grace-period(宽限期) pod-eviction-timeout(驱逐超时) | 5s/40s/5m |
| 副本控制器 | 保证Pod副本数始终符合预期 | 副本数(replicas) | 根据业务需求设置,建议≥2 |
| 命名空间控制器 | 管理命名空间的创建/删除/状态 | - | 按业务划分命名空间(如生产/测试/开发) |
| 服务账号控制器 | 管理集群服务账号(ServiceAccount) | - | 为不同应用分配独立服务账号,最小权限原则 |
| 高可用配置 | 领导者选举,避免单点故障 | --leader-elect=true | 必开,部署多controller-manager节点 |
3.1.4 etcd
https://kubernetes.io/zh-cn/docs/concepts/architecture/#kube-controller-manager
知识点
- CoreOS开发的分布式键值数据库 ,是K8s的唯一数据存储,保存集群所有资源状态(Pod/Service/Node等),是集群的"大脑"。
- 核心特性:分布式、强一致性、高可用,生产环境需部署3/5节点集群,并定期备份数据。
- 所有组件仅通过kube-apiserver访问etcd,不直接操作,保证数据一致性。
实例
K8s集群中创建一个Pod,kube-apiserver将Pod的配置和状态写入etcd;
kube-scheduler调度Pod后,将调度结果更新到etcd;
kubelet从etcd获取Pod信息并启动容器,容器状态变化后再通过apiserver更新到etcd。
表格
|--------|-------------------------------|----------------------------|----------------------|
| etcd特性 | 实现方式 | 生产部署建议 | 运维建议 |
| 数据存储 | 键值对形式,存储K8s所有资源状态 | 独立部署,不与其他组件混部 | 定期备份(如每天),备份文件异地存储 |
| 高可用 | 部署3/5节点集群,基于Raft协议选主 | 至少3节点,节点分布在不同机房 | 监控etcd节点状态,避免集群脑裂 |
| 访问方式 | 仅通过kube-apiserver访问,提供HTTPS接口 | 禁止公网访问etcd,配置访问证书 | 限制apiserver的etcd操作权限 |
| 性能 | 内存数据库,读写性能高 | 为etcd节点分配独立CPU/内存(建议≥2核4G) | 避免大体积资源存储,定期清理无用资源 |
3.2 工作节点组件
3.2.1 kubelet
https://kubernetes.io/zh-cn/docs/concepts/architecture/#kube-controller-manager
知识点
- 运行在每个Worker Node 上的代理组件,是Master与Worker的通信桥梁,负责Pod的全生命周期管理。
- 核心功能:向Master汇报节点状态、接收apiserver指令启动/停止Pod、准备Pod数据卷、执行容器健康检查、返回Pod运行状态。
- 与容器运行时(Docker/containerd)交互,实现容器的实际启动和管理。
实例
1.kube-scheduler将Pod调度到Node1后kubelet(Node1上)通过apiserver获取Pod的YAML配置;
2.拉取容器镜像,创建数据卷,启动容器;
3.并每隔10秒执行一次容器健康检查(如HTTP检查),若容器故障则重启容器。
表格
|-------------|------------------------------------------|-----------------|--------------------------------|
| kubelet核心功能 | 实现方式 | 监控指标 | 故障处理 |
| 节点状态汇报 | 定期向apiserver上报节点CPU/内存/磁盘状态 | 节点使用率、节点就绪状态 | 节点状态异常时,apiserver标记为NotReady |
| Pod生命周期管理 | 接收apiserver指令,调用容器运行时管理容器 | Pod就绪状态、Pod运行状态 | Pod故障时,根据重启策略重启容器 |
| 数据卷准备 | 挂载ConfigMap/Secret/PV到Pod | 数据卷挂载状态 | 挂载失败则Pod启动失败,kubelet上报事件 |
| 容器健康检查 | 存活探针(livenessProbe)、就绪探针(readinessProbe) | 探针检查结果、容器重启次数 | 存活探针失败→重启容器;就绪探针失败→移除Service端点 |
3.2.2 kube-proxy
https://kubernetes.io/zh-cn/docs/concepts/architecture/#kube-controller-manager
知识点
- 运行在每个Worker Node 上的网络代理,负责K8sService的实现,通过管理节点的网络规则实现Pod的网络访问和负载均衡。
- 三种工作模式:UserSpace(废弃)、IPtables(传统模式)、IPVS(高性能模式,K8s v1.11后默认)。
- IPVS相比IPtables效率更高,支持更多负载均衡算法(rr/LC/dh/sh等),未安装IPVS模块则自动回退到IPtables。
- 支持会话保持,通过ClientIP实现同一客户端的请求转发到同一个Pod。
实例
创建一个Nginx Service(ClusterIP),kube-proxy在每个节点上创建IPVS规则,将Service的ClusterIP映射到后端的Nginx Pod;当客户端访问ClusterIP时,kube-proxy通过rr(轮询)算法将请求转发到不同的Pod,实现负载均衡。
表格
|----------------|----------------|----|--------------------|-----------------------------|
| kube-proxy工作模式 | 适用版本 | 性能 | 负载均衡算法 | 部署要求 |
| UserSpace | K8s v1.1之前 | 低 | 简单轮询 | 已废弃,不建议使用 |
| IPtables | K8s v1.2+ | 中 | 轮询 | 无需额外安装组件,默认支持 |
| IPVS | K8s v1.11+(默认) | 高 | rr/LC/dh/sh/sed/nq | 安装ipvsadm/ipset,加载ip_vs内核模块 |
扩展:IPVS负载均衡算法
|--------|------|--------------------------|-------------------|
| 算法名称 | 英文缩写 | 核心逻辑 | 适用场景 |
| 轮询 | rr | 请求依次转发到后端Pod | 后端Pod性能一致的场景 |
| 最小连接数 | lc | 请求转发到当前连接数最少的Pod | 后端Pod处理请求耗时不一致的场景 |
| 目标哈希 | dh | 根据目标IP哈希转发 | 基于目标IP的会话保持 |
| 源哈希 | sh | 根据源IP哈希转发 | 基于客户端IP的会话保持 |
| 最短期望延迟 | sed | 结合连接数和响应时间,转发到期望延迟最小的Pod | 高并发、对延迟敏感的场景 |
| 不排队调度 | nq | 无连接的Pod优先接收请求,避免排队 | 高并发、短连接场景 |
3.3 辅助组件
3.3.1 kubectl
https://kubernetes.io/zh-cn/docs/reference/kubectl/
知识点
- K8s的命令行客户端工具,用于与kube-apiserver交互,实现集群的所有管理操作(创建/删除/查询资源)。
- 配置文件:默认读取
$HOME/.kube/config,可通过KUBECONFIG环境变量或--kubeconfig参数指定其他配置文件。 - 核心操作:资源的增删改查(create/delete/get/update)、集群状态查看、资源编辑(edit)、日志查看(logs)等。
实例
# 查看集群节点状态
kubectl get nodes
# 创建Pod(通过YAML文件)
kubectl apply -f pod-nginx.yaml
# 查看Pod日志
kubectl logs nginx-pod
# 进入Pod内部
kubectl exec -it nginx-pod -- /bin/bash表格
|------|---------------------------------------------------|---------------|------------------------------------------|
| 核心操作 | 命令示例 | 功能说明 | 常用参数 |
| 资源查询 | kubectl get pods/nodes/services | 查看资源状态 | -n(指定命名空间)、-o wide(详细信息)、-o yaml(YAML格式) |
| 资源创建 | kubectl apply -f xxx.yaml | 通过YAML创建/更新资源 | -f(指定文件/目录)、-n(指定命名空间) |
| 资源删除 | kubectl delete -f xxx.yaml/kubectl delete pod xxx | 删除资源 | --force(强制删除) |
| 日志查看 | kubectl logs xxx-pod | 查看Pod容器日志 | -f(实时日志)、--tail=100(最后100行) |
| 容器进入 | kubectl exec -it xxx-pod -- /bin/bash | 进入Pod的容器 | -it(交互式终端) |
| 资源编辑 | kubectl edit pod xxx-pod | 在线编辑资源配置 | -o yaml(指定编辑格式) |
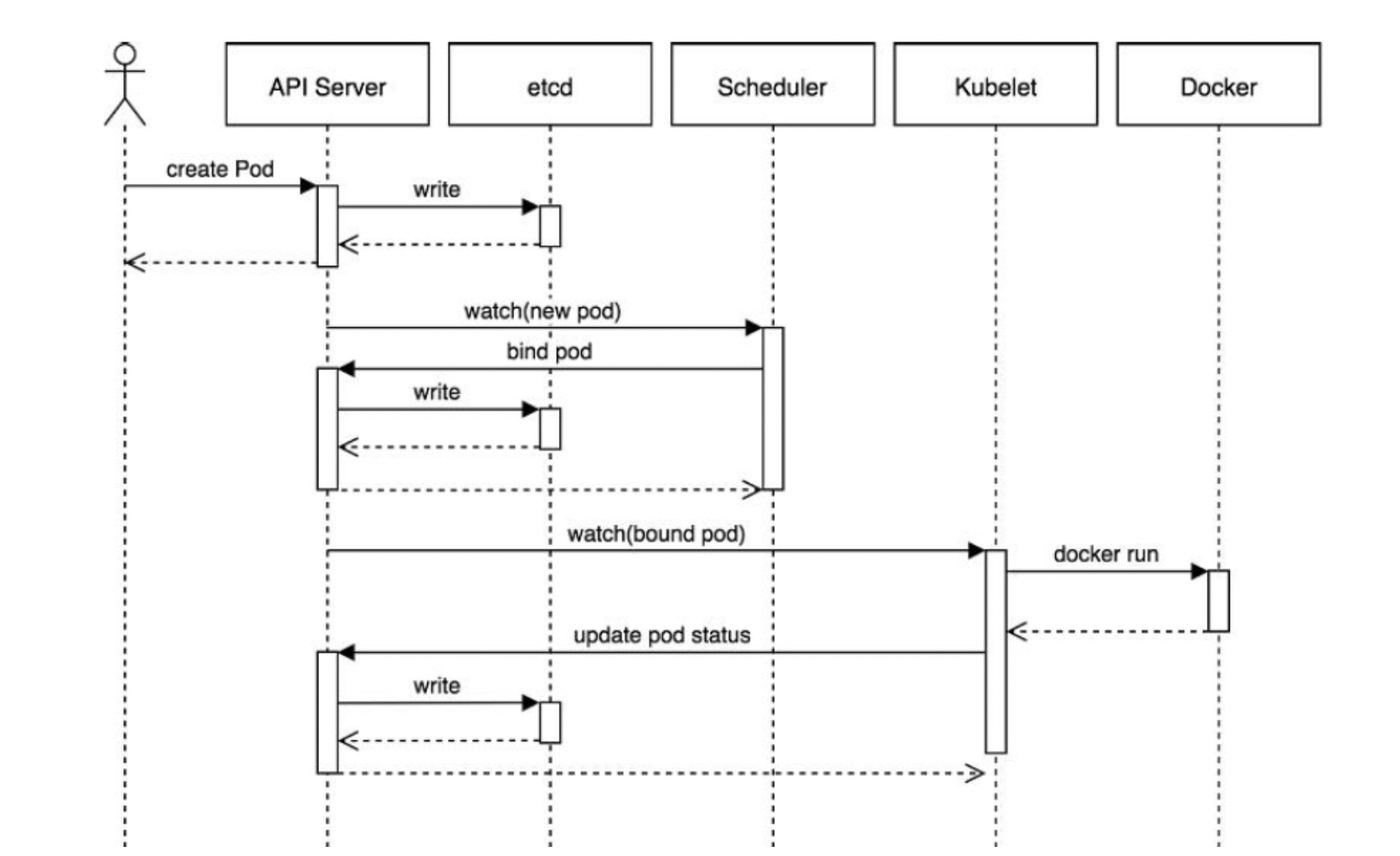
POD创建流程:
2.1: 执行 kubectl create -f nginx-deploy.yaml → kubectl 向 kube-apiserver 发起创建请求; 2.2:kube-apiserver 完成「认证 / 授权」后,将 Deployment 的「期望状态」(比如 3 个副本)写入 etcd,并返回创建成功;
2.3:kube-controller-manager 中的 Deployment 控制器,通过 apiserver 发现新的 Deployment,自动创建对应的 ReplicaSet;
2.4:replicaSet 控制器发现「期望 3 个 Pod,实际 0 个」,通过 apiserver 创建 3 个 Pod 的资源对象,写入 etcd;
2.5:kube-scheduler 监听 apiserver,发现 3 个「待调度的 Pod」,为每个 Pod 筛选并打分,选出最合适的 Node 节点,将调度结果(Pod 绑定到哪个 Node)更新到 etcd;
2.6:对应 Node 节点上的 kubelet,通过 apiserver 发现「自己被分配了 Pod」,调用容器运行时(Docker/containerd)创建 Pod,Pod 启动成功后,kubelet 将 Pod 的「实际运行状态」上报给 apiserver,apiserver 更新到 etcd;
2.7: kube-proxy 监控到 Pod 创建后,更新本地的 iptables/ipvs 规则,让 Service 可以转发流量到新 Pod;
2.8:后续如果某个 Pod 宕机 → ReplicaSet 控制器发现「实际 2 个 Pod≠期望 3 个」→ 自动创建新 Pod → scheduler 重新调度 → kubelet 创建 Pod,完成自愈。
3.3.2 DNS(CoreDNS)
知识点
- K8s集群的内部DNS服务,替代早期的kube-dns,实现集群内资源的域名解析(如Service名称解析为ClusterIP),让微服务通过域名相互访问。
- 核心功能:Service域名解析、Pod域名解析、自定义DNS配置,默认部署在kube-system命名空间。
- 解析规则:
服务名.命名空间.svc.cluster.local,如nginxservice.magedu.svc.cluster.local。
实例
在magedu命名空间创建Nginx Service(名称为nginx-service),集群内的其他Pod可通过nginx-service.magedu.svc.cluster.local访问该Service,CoreDNS将域名解析为Service的ClusterIP,实现微服务间的无感知访问。
表格
|----------|----------------|-------------|------------------|----------------------------|
| DNS组件 | 适用版本 | 核心优势 | 部署方式 | 解析规则 |
| kube-dns | K8s v1.18之前 | 轻量、简单 | 静态部署 | 服务名.命名空间.svc.cluster.local |
| CoreDNS | K8s v1.18+(默认) | 可扩展、插件化、性能高 | K8s Deployment部署 | 服务名.命名空间.svc.cluster.local |
3.3.3 Dashboard
知识点
- K8s的Web可视化管理界面,替代部分kubectl命令,实现资源的可视化查看、创建、修改、删除,支持Pod监控、弹性伸缩、滚动升级等操作。
- 核心功能:集群/节点/Pod/Service等资源的可视化展示、资源的增删改查、Pod日志查看、容器终端操作、Deployment弹性伸缩。
- 访问方式:通过NodePort/Ingress暴露服务,需通过Token认证登录。
实例
部署K8s Dashboard后,通过https://172.31.7.111:30002访问Web界面,输入管理员Token登录,可在界面上直接查看所有Pod的运行状态,对Nginx的Deployment实现副本数从2个扩到5个,无需执行kubectl命令。
表格
|---------------|-------------------------|----------------|------------------------------|
| Dashboard核心功能 | 操作方式 | 优势 | 生产建议 |
| 资源可视化展示 | 网页端查看集群/节点/Pod/Service等 | 直观、便捷,快速掌握集群状态 | 仅用于监控,不建议生产环境通过网页修改资源 |
| 资源增删改查 | 网页端表单/上传YAML创建资源 | 无需记忆kubectl命令 | 测试环境可用,生产环境建议用kubectl+GitOps |
| Pod日志/终端 | 网页端直接查看日志、进入容器终端 | 快速排查Pod故障 | 临时故障排查使用 |
| 应用运维 | 弹性伸缩、滚动升级、重启Pod | 可视化操作,降低运维门槛 | 生产环境操作前做好备份 |
第4章 Kubernetes集群基础部署
知识图
Kubernetes集群基础部署
├─ 部署环境
│ ├─ 公有云:阿里云/腾讯云/AWS,自带K8s服务(ACK/TSK/EKS)
│ └─ 私有云:基于OpenStack/VMware,自建K8s集群
├─ 部署工具
│ └─ kubeadm:K8s官方推荐,快速部署高可用集群
└─ 集群架构:控制面高可用(3/5节点)+工作节点(按需扩容)4.1 K8s集群部署环境
知识点
K8s集群可部署在公有云、私有云、混合云 环境,公有云提供托管式K8s服务,降低部署和运维成本;私有云需自建集群,适合对数据隐私要求高的企业;核心架构均为控制面高可用+工作节点按需扩容。
实例
- 公有云:某企业使用阿里云ACK(容器服务Kubernetes版),直接创建3个控制面节点和5个工作节点,阿里云负责控制面的运维和升级,企业仅需管理工作节点和应用。
- 私有云:某金融企业基于OpenStack搭建私有云,通过kubeadm部署3个控制面节点和10个工作节点,所有节点由企业自主运维,保证数据不出内网。
表格
|------|------------------------|--------------------|---------------|------|------------|
| 部署环境 | 代表产品 | 部署方式 | 运维成本 | 数据隐私 | 适用企业 |
| 公有云 | 阿里云ACK、腾讯云TSK、AWS EKS | 托管式部署,控制台/API创建集群 | 低(云厂商负责控制面运维) | 一般 | 中小企业、互联网企业 |
| 私有云 | OpenStack/VMware+自建K8s | 手动部署(kubeadm),自主运维 | 高(全集群自主运维) | 高 | 金融、政府、大型企业 |
| 混合云 | 公有云K8s+私有云K8s | 跨云部署,通过云原生工具实现互通 | 中 | 中等 | 有跨云业务需求的企业 |
4.2 K8s集群部署工具(kubeadm)
知识点
- kubeadm是K8s官方推荐的集群部署工具 ,轻量、便捷,支持快速部署单节点/高可用K8s集群,自动处理组件配置、证书生成、集群初始化等步骤。
- 核心命令:
kubeadm init(初始化控制面)、kubeadm join(工作节点加入集群)、kubeadm reset(重置集群)、kubeadm upgrade(升级集群)。 - 高可用部署:需部署3/5个控制面节点,配合负载均衡器(SLB/HAProxy)暴露apiserver,etcd可选择内置或外部集群。
实例
初始化控制面节点(指定Pod网段、服务网段、负载均衡器IP):
kubeadm init --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12 --control-plane-endpoint=172.31.7.100:6443工作节点加入集群(执行init后输出的join命令):
kubeadm join 172.31.7.100:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx表格
|-----------------|----------------|---------------------------------------------------------------------------------|--------------------|
| kubeadm核心命令 | 功能 | 常用参数 | 适用场景 |
| kubeadm init | 初始化K8s控制面节点 | --pod-network-cidr(Pod网段) --service-cidr(服务网段) --control-plane-endpoint(高可用VIP) | 控制面节点初始化,单节点/高可用集群 |
| kubeadm join | 节点加入集群 | --token(集群令牌) --discovery-token-ca-cert-hash(CA证书哈希) | 工作节点/新增控制面节点加入集群 |
| kubeadm reset | 重置节点,清除K8s相关配置 | -f(强制重置) | 节点退出集群、集群重新部署 |
| kubeadm upgrade | 升级K8s集群版本 | upgrade plan(查看可升级版本) upgrade apply(执行升级) | 集群版本升级,支持平滑升级 |
| kubeadm token | 管理集群令牌 | create(创建新令牌) list(查看令牌) | 令牌过期后创建新令牌,让节点加入集群 |
整体核心思维导图
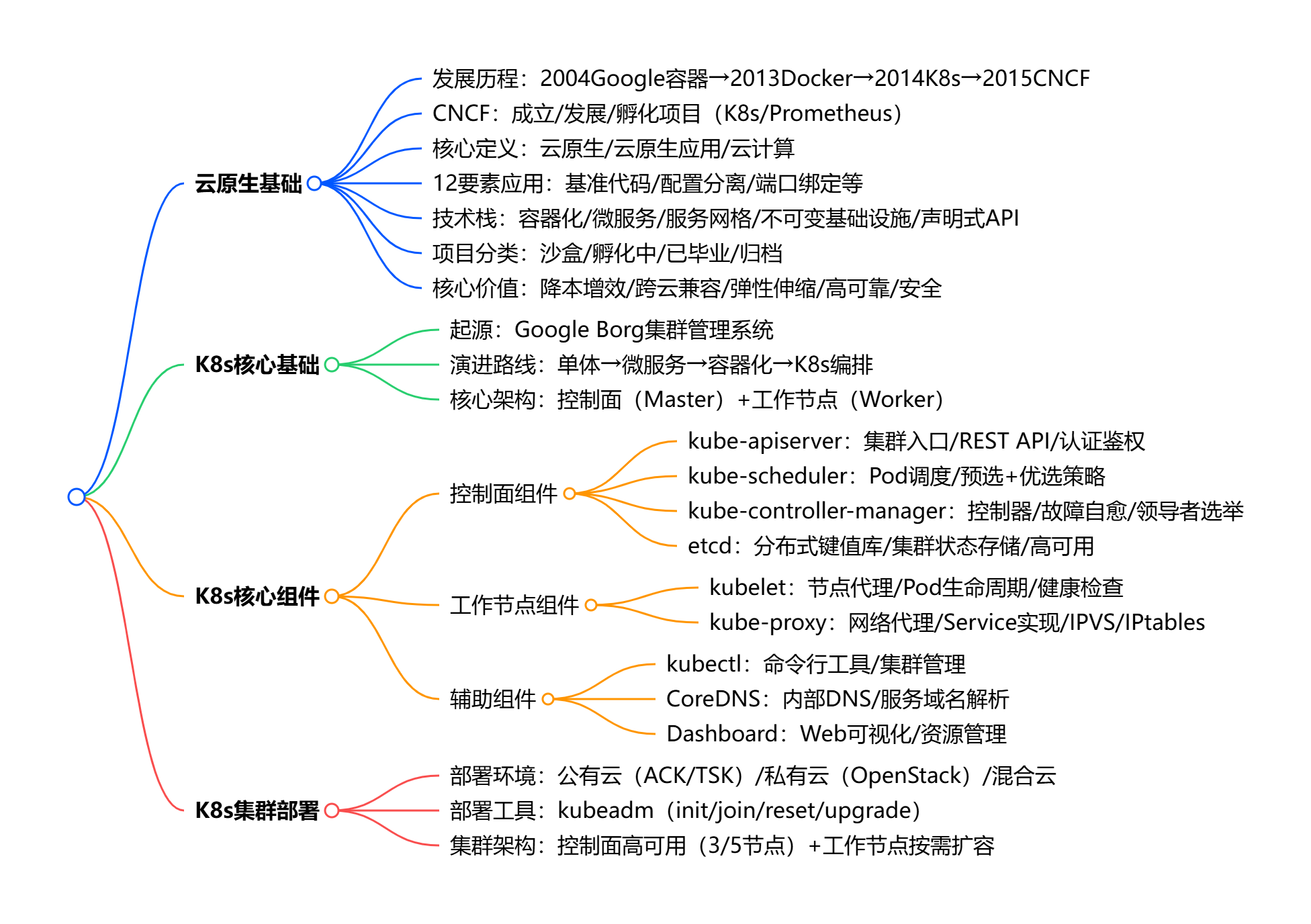
## **云原生基础**
- 发展历程:2004Google容器→2013Docker→2014K8s→2015CNCF
- CNCF:成立/发展/孵化项目(K8s/Prometheus)
- 核心定义:云原生/云原生应用/云计算
- 12要素应用:基准代码/配置分离/端口绑定等
- 技术栈:容器化/微服务/服务网格/不可变基础设施/声明式API
- 项目分类:沙盒/孵化中/已毕业/归档
- 核心价值:降本增效/跨云兼容/弹性伸缩/高可靠/安全
## **K8s核心基础**
- 起源:Google Borg集群管理系统
- 演进路线:单体→微服务→容器化→K8s编排
- 核心架构:控制面(Master)+工作节点(Worker)
## **K8s核心组件**
- 控制面组件
- kube-apiserver:集群入口/REST API/认证鉴权
- kube-scheduler:Pod调度/预选+优选策略
- kube-controller-manager:控制器/故障自愈/领导者选举
- etcd:分布式键值库/集群状态存储/高可用
- 工作节点组件
- kubelet:节点代理/Pod生命周期/健康检查
- kube-proxy:网络代理/Service实现/IPVS/IPtables
- 辅助组件
- kubectl:命令行工具/集群管理
- CoreDNS:内部DNS/服务域名解析
- Dashboard:Web可视化/资源管理
## **K8s集群部署**
- 部署环境:公有云(ACK/TSK)/私有云(OpenStack)/混合云
- 部署工具:kubeadm(init/join/reset/upgrade)
- 集群架构:控制面高可用(3/5节点)+工作节点按需扩容