大家好,我是孟健。
我用 OpenClaw 搭了一套全自动需求挖掘系统,每天早上醒来,手机上已经躺着一份机会清单。
今天把整套系统的搭建思路、每一步怎么做、用什么工具、看什么指标,全部拆开讲。你看完之后可以直接照着搭一套。
先说结论:这套系统一共 11 步,两个发现入口(搜索 + 社区),一条统一判断链。跑在 OpenClaw 上,一个 cron job 每天自动执行。
种子词
→ ① 新词发现(Google Trends)
→ ② 老词筛选(关键词数据库)
→ ③ 第一次合并
→ ④ Hacker News 信号扫描
→ ⑤ GitHub 信号扫描
→ ⑥ Tavily 社区验证
→ ⑦ 社区词 → Trends 桥接
→ ⑧ 社区词趋势验证
→ ⑨ 第二次合并
→ ⑩ SERP 竞争分析
→ ⑪ 最终分级 shortlist下面一步一步拆。
01 第一步:准备种子词
所有需求挖掘的起点都是种子词。种子词不是"你觉得什么好",而是你要研究的品类表达。
怎么选种子词:
- 你正在做的领域的核心词(比如做 AI 工具站,种子词就是 ai generator、ai detector、ai editor 这一类)
- 竞品的核心关键词(去 Ahrefs/Semrush 看竞品排名靠前的词)
- 用户在搜索框里实际打出来的表达(Google Suggest、Answer the Public)
我的做法 :维护一个 seed_roots.json 文件,里面放了 127 个根词。每天 pipeline 跑的时候自动从这里面取。
种子词不需要很多,但要覆盖你关心的品类。后面的 pipeline 会自动帮你扩展。
02 新词发现:用 Google Trends 找正在起势的表达
这一步的目标是:从海量候选词里,找到搜索热度正在上升的新表达。
具体操作:
- 用 Google Trends API(pytrends 库)批量查询候选词
- 每个词跟一个基准词(我用的是 "gpts")做趋势对比
- 算三个核心指标:
- avg_ratio:过去 12 个月平均搜索量 / 基准词平均搜索量
- last_ratio:最近一个月的比值(判断当前势头)
- slope:趋势斜率(正=在涨,负=在跌)
判断标准:
- last_ratio > 6 且 slope > 0:🔥 强上升信号
- avg_ratio > 3 且 last_ratio > avg_ratio:📈 稳步上升
- slope < 0 且 last_ratio < avg_ratio:📉 在衰退,跳过
自动过滤三类噪音:
- 品牌词(DeepSeek、ChatGPT、Midjourney)→ 这是别人的流量,不是你的机会
- 娱乐词(taylor swift、minecraft)→ 跟你的业务无关
- 成熟大词(free vpn、pdf converter)→ 已经卷到极致
我的参数:每轮查询 54 组 Trends 数据,取 top 80 个候选词进入下一步。
03 老词筛选:从关键词数据库里找被低估的成熟词
新词线找的是"正在涨的",老词线找的是"已经有量但竞争没那么激烈的"。
数据源:关键词数据库(我用的是 DataForSEO 的 Keywords Data API,你也可以用 Ahrefs API 或 Semrush API)。
怎么筛:
- 从 127 个种子根词出发,每个根词取 20 个相关词
- 按以下条件过滤:
- 月搜索量 > 1000(太小的不值得做)
- KD(关键词难度)< 30(太难的打不过)
- 不是品牌词
- 不是纯导航词(比如"gmail login")
- 按 search_volume / KD 的比值排序------搜索量越高、难度越低的词,机会越大
我的参数:127 个根词 × 20 个/根 = 最多 2540 个候选,过滤后通常剩 200-400 个。
04 第一次合并:新词 + 老词去重
两条线的候选词合并到一个池子里,自动去重。
这一步很简单但很必要。因为同一个词可能同时被新词线和老词线发现,合并后保留两边的证据,不重复计算。
05 社区信号层:HN、GitHub、Reddit
这是整套系统最有差异化的部分。技术社区的讨论往往比搜索趋势早 3-6 个月。
Hacker News 扫描:
- 工具:Algolia HN Search API(免费,不需要 key)
- 方法:用候选词搜索最近 30 天的帖子和评论
- 看什么:提及次数、讨论深度(评论数)、情绪(正面讨论 vs 吐槽)
- 真实例子:我在 HN 上发现 "ai humanizer" 这个词被高频提到之前,Google Trends 上它还只是一条微弱的上升线
GitHub 扫描:
- 工具:GitHub Search API
- 方法:扫最近新增 star 快的 repo,提取命名、topic、description
- 价值:一个 repo 的名字就是一个需求的产品化表达。比如一个 repo 叫 "ai-tattoo-generator",那 "ai tattoo generator" 就是一个候选关键词
Tavily 社区验证:
- 工具:Tavily Search API($1 可以搜 1000 次)
- 方法:对候选词搜 Reddit、Product Hunt 的讨论
- 看什么:用户在讨论什么痛点?在比较什么工具?在抱怨什么?
- 为什么不直接用 Reddit API:Reddit API 限制多且不稳定,Tavily 做间接抓取更省事
🔴 关键设计:社区词不直接进 shortlist。
这是很多人会犯的错。Reddit 上热议不代表有搜索量,GitHub 上火不代表 SERP 可切入。
所以我设计了一个"回流"机制------
06 社区词回流验证:补词可以,但必须走验证
社区发现的候选词,会被重新送回 Google Trends 做趋势验证。
具体流程:
build_trend_candidates_from_community.py:从 HN/GitHub/Tavily 的结果中提取候选关键词run_community_trend_validation.py:跟新词线用同一套 Trends 逻辑验证(avg_ratio、last_ratio、slope)- 验证通过的词并入主候选池(第二次 merge)
为什么要这么设计:
来源可以很多,但判断标准必须统一。不管词是从 Trends 发现的还是从 Reddit 捞到的,最后都要过同一条验证链。
这步的意义:社区层既能补词,也必须把补出来的词回流到统一判断链路。
07 SERP 主判断:谁在前排决定一切
到这一步,候选词已经经过了趋势验证 + 社区验证。但还差最关键的一刀:SERP 竞争格局分析。
工具:DataForSEO SERP API($0.002/次查询,很便宜)
怎么判断:
- 拉前 10 的搜索结果
- 把每个域名分类成"大站"或"niche 站"
- 算比例
大站列表(我维护了 30+ 个):
Wikipedia、Amazon、YouTube、Reddit、Forbes、PCMag、CNET、G2、Capterra、OpenAI、Anthropic、Figma、Canva、Adobe、Grammarly、Turnitin......
判断标准:
| SERP 格局 | 判断 | 动作 |
|---|---|---|
| niche ≥ 7 : big ≤ 3 | 🟢 SERP 对小站友好 | 值得继续 |
| niche 5-6 : big 4-5 | 🟡 有一定空间 | 可观察 |
| niche ≤ 4 : big ≥ 6 | 🔴 大站锁死 | 不值得做 |
今天墨探(我的市场 Agent)跑出来的真实结果:
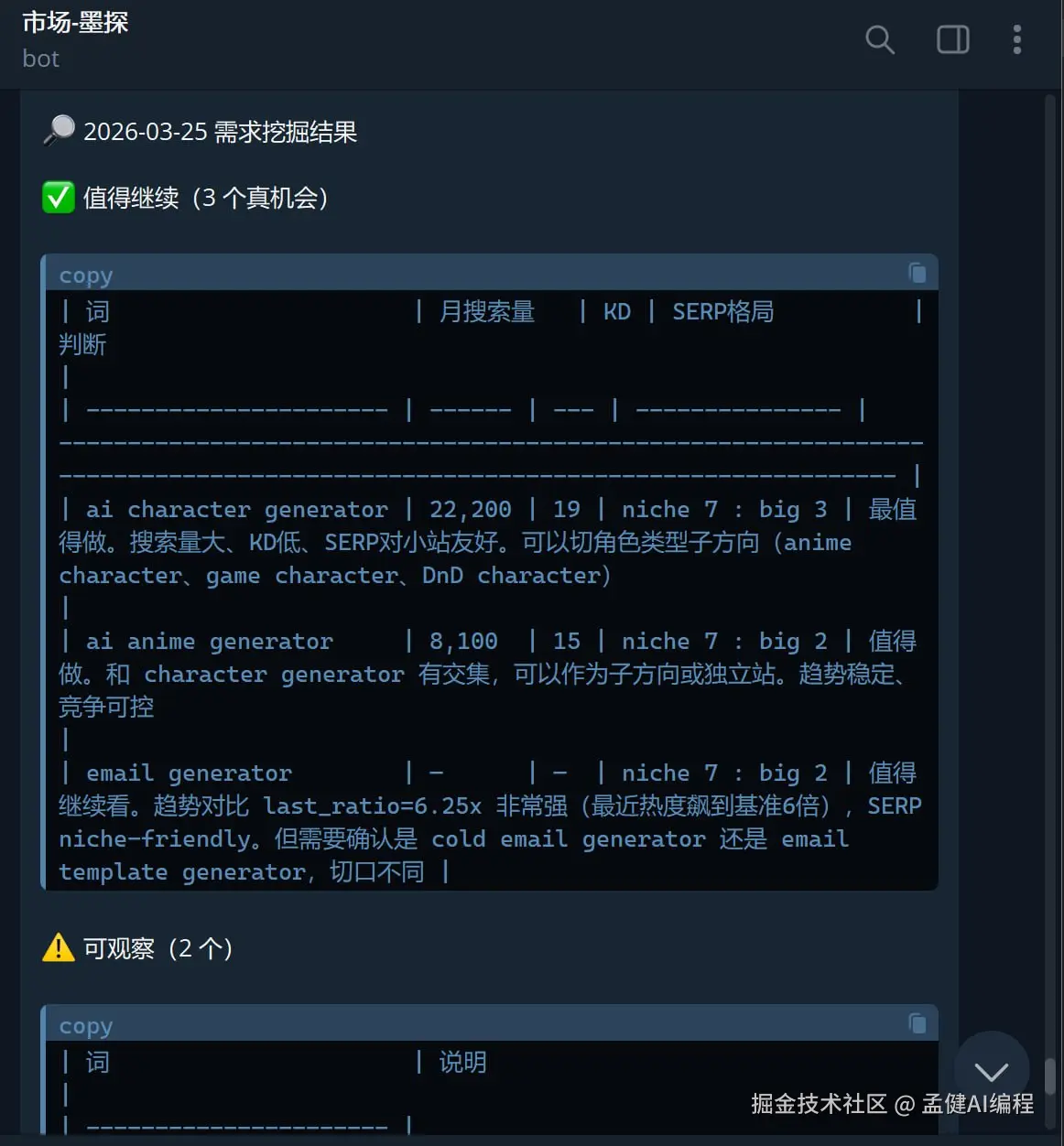
- ai character generator:月搜 22,200,KD 19,niche 7 : big 3 → ✅ 最值得做,可以切角色类型子方向
- ai anime generator:月搜 8,100,KD 15,niche 7 : big 2 → ✅ 值得做,趋势稳定、竞争可控
- email generator:last_ratio 6.25x(最近热度飙到基准 6 倍),niche 7 : big 2 → ✅ 值得继续看
- ai detector:niche 3 : big 7 → ❌ 大站锁死
- free ai checker:niche 2 : big 8 → ❌ 大站锁死
08 最终分级:三个桶
所有词过完整条链路后,被分成三类:
✅ 值得继续:SERP 可切入 + 趋势/数据/社区至少有两个维度的证据。可以开始做产品规划。
⚠️ 可观察:有一定信号但证据不够硬,或者 SERP 竞争不确定。放进观察池,下周再跑一次看变化。
❌ 不值得做:大站锁死、品牌词、娱乐噪音、或者趋势在下降。直接排除。
这轮从几百个种子词最后产出:13 个值得继续,3 个可观察,其余全部淘汰。
09 在 OpenClaw 上怎么跑
脚本结构:
bash
scripts/
├── run_full_keyword_research_pipeline.py # 主编排脚本
├── run_new_word_pipeline.py # 新词发现
├── run_old_word_pipeline.py # 老词筛选
├── merge_keyword_candidates.py # 候选词合并
├── run_hn_signal_scan.py # HN 扫描
├── run_github_signal_scan.py # GitHub 扫描
├── run_tavily_community_scan.py # Tavily 社区验证
├── build_trend_candidates_from_community.py # 社区→Trends 桥接
├── run_community_trend_validation.py # 社区词趋势验证
├── run_keyword_research_review.py # SERP 分析
├── build_final_keyword_shortlist.py # 最终分级
└── keyword_pipeline_common.py # 公共函数主脚本 run_full_keyword_research_pipeline.py 按顺序调用 11 个子脚本,每一步的输出存到 data/pipeline_results/,最终 shortlist 存到 reports/。
OpenClaw cron 配置:
我给市场 Agent(墨探)配了一个 daily cron job。每天早上自动跑完整条链路,跑完后自动把结果发到 Telegram 群里。
每一步用的外部 API 和实际费用:
| 步骤 | API | 单价 | 实际费用 |
|---|---|---|---|
| 新词 Trends | pytrends(免费) | $0 | $0 |
| 老词数据 | DataForSEO Keywords Data | $0.009/查询 | ~$1.65 |
| HN 扫描 | Algolia HN API | $0 | $0 |
| GitHub 扫描 | GitHub Search API | $0 | $0 |
| 社区验证 | Tavily Search | $0.001/次 | ~$0.05 |
| SERP 分析 | DataForSEO SERP | $0.002/查询 | ~$0.03 |
| Trends 验证 | pytrends(免费) | $0 | ~$0.69 |
**整套 pipeline 跑一次的实际成本大约 2−3。∗∗每天跑一次,一个月也就60-90------比一个 Ahrefs 标准订阅($99/月)还便宜,但你拿到的是每天更新的、经过完整验证的机会清单。
DataForSEO 注册送 $50 免费额度,够你免费跑半个多月。
10 你自己搭需要什么
如果你想照着搭一套,需要准备的东西:
- OpenClaw 部署好(一台 VPS 即可)
- DataForSEO 账号(注册送 $50 额度,够用很久)
- Tavily API Key($1 = 1000 次搜索)
- Google 账号(pytrends 免费用)
- 一份种子词列表(你的业务领域的核心关键词,20-50 个起步)
- Python 环境(脚本都是 Python 写的)
不需要 Ahrefs 或 Semrush 的高价订阅(那两个分别是 99/月和129/月起步)。整套系统的数据源成本每月不到 12。DataForSEO注册就送50 额度,够你跑大半年。
最后
2026 年,独立开发者的核心瓶颈正在从"不会做"转向"不知道做什么"。
AI 让写代码变容易了,让做设计变容易了。但"找到一个值得做的方向"这件事,还是要靠判断力。而判断力需要数据支撑。
这套系统做的事情就是:让 AI 帮你跑完判断之前的所有脏活------收集、清洗、验证、分级------你只需要看结论、做决策。
Agent 跑数据,人做判断。这才是正确的分工。
AI 最值钱的用法,不是替你思考,是替你跑完思考之前的那些脏活。
你现在是怎么找需求的?评论区聊,我每条都看。
👋 我是孟健,前腾讯 T11 / 前字节技术 Leader,现在全职做 AI 编程。
🔥 更多 AI 编程实战:
- GitHub:@mengjian-github
- 专栏:AI编程实战
觉得有用?点赞+收藏 就是最大支持 🙏