每个数据团队都有这样的经历:业务提了个新需求,产品写 PRD,数据写埋点文档,研发排期实现,测试验证上线------一套流程走完,2 周过去了。业务等不起,研发累得够呛,最后埋点还埋错了。
为此,ThinkingAI 正式发布数据采集 Agent,基于企业级 AI Agent 平台 Agentic Engine,数据采集 Agent 让数据埋点从"多团队协作的工程任务"变成"业务人员自助启动、研发一键生成代码"的标准化流程。
【为什么强调"工程化"?】
产品打磨过程中,团队观察到一个现象:聊 Agent 的人很多,但能让 Agent 在生产环境稳定干活的没几个。究其原因,大部分 Agent 还是"聊天框玩具",不是"工程工具"。
因此,企业级 Agent 必须跨过三道门槛:
第一,可装可跑的工具链形态。不是网页聊天框里输提示词,而是能被工程师 npm install、CLI 调用的标准工具,有版本号、有 changelog、有完整的 API 文档。
第二,可被工程消费的产物结构。Agent 输出的不是 Word 文档或 PPT,而是标准化的 JSON/YAML 配置文件。这个文件能被现有研发流程直接消费,也能被 Claude Code、Codex、Cursor 等本地 coding agent 直接接入,自动生成代码。
第三,可与现有研发流程连通。Agent 不能要求企业重建工作流,而要嵌入企业已有的 IDE(VS Code/IntelliJ 插件)、代码仓库(Git)、CI/CD 流水线(Jenkins/GitHub Actions)。
【数据采集 Agent 的完整 工作流 】
基于上述三大标准,数据采集 Agent 实现了一条完整的自动化流水线,具体分为四个步骤:
Step 1:自助启动 埋点 设计(5 分钟)
业务人员把产品需求(PRD 或口头描述)输入后,Agent 通过自然语言理解自动生成完整的埋点方案,包括:
-
业务事件定义(Event)
-
属性结构(Properties)
-
数据口径说明(如 DAU 的统计口径)
-
字段命名规范(如 event_id、user_id 的命名规则)
原本需要 3-5 天的埋点方案,现在 5 分钟就能输出。方案确认后,Agent 自动把事件和属性写入数据分析后台,无需人工录入。
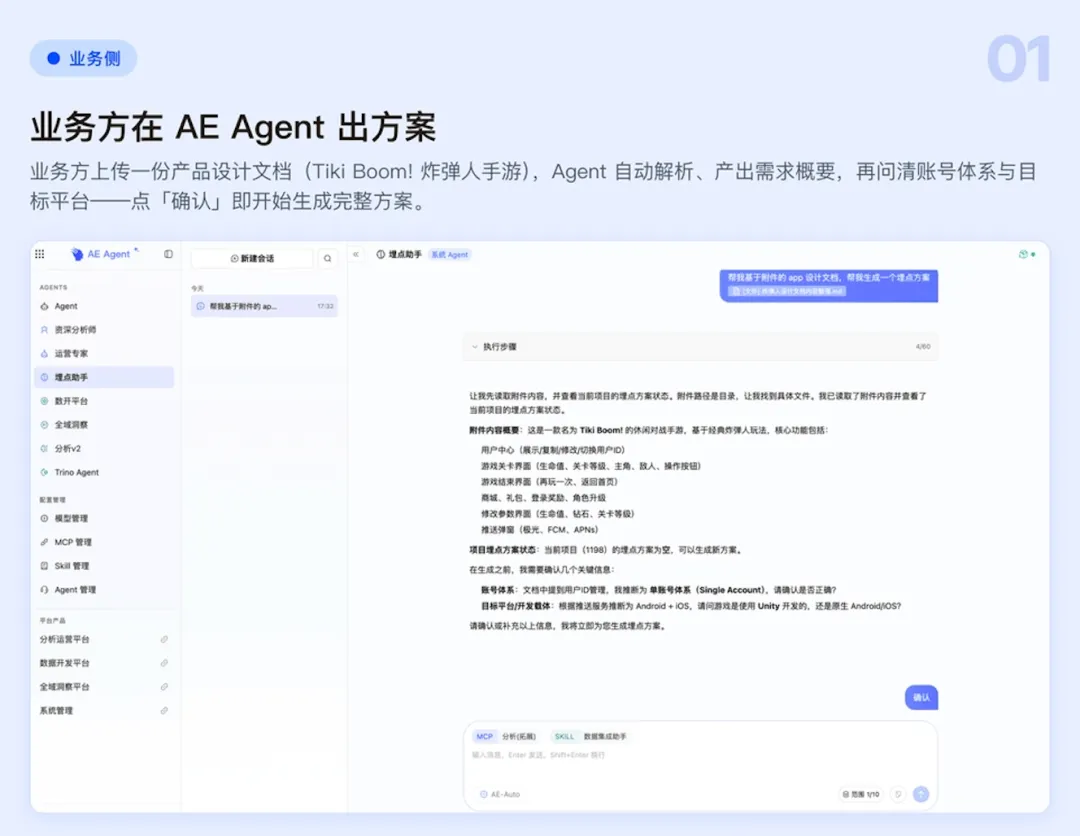
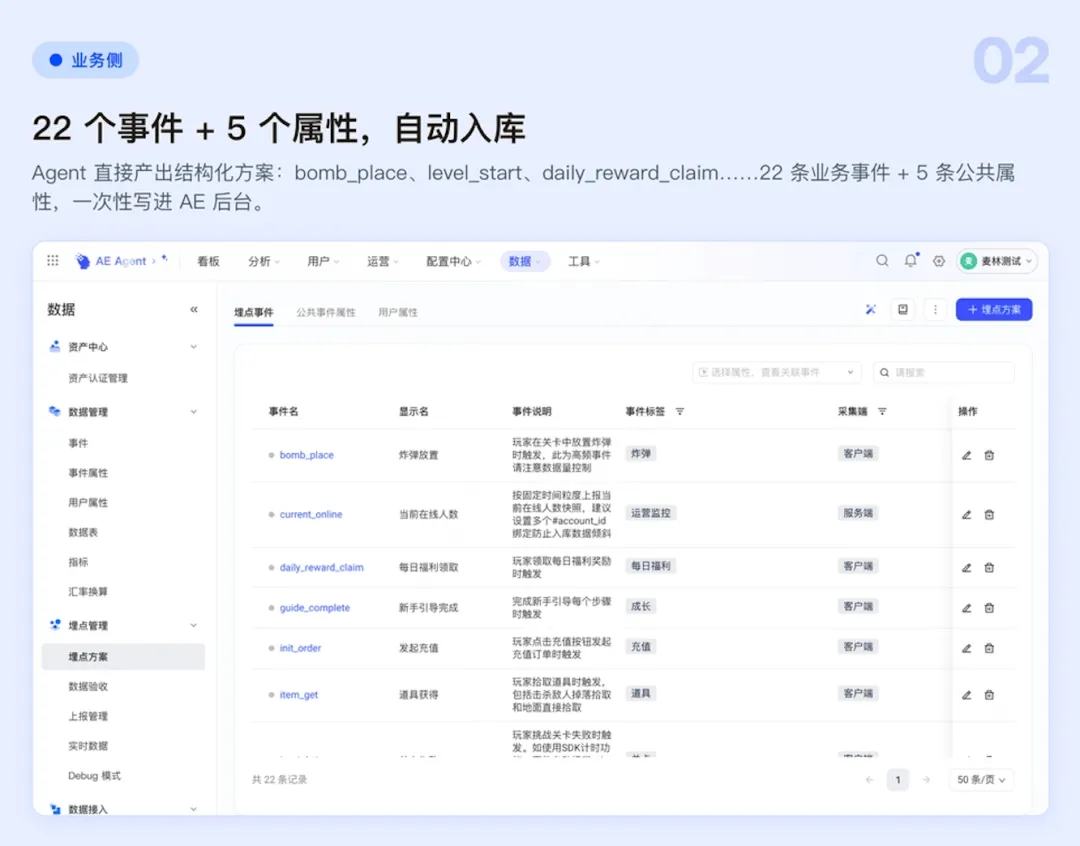
Step 2:标准化产物输出( JSON /YAML)
有了方案之后,Agent 输出的不是 Word 文档,而是一份标准化的埋点规范文件(JSON/YAML 格式)。这个文件包含:
-
事件 Schema 定义
-
属性类型约束(string/number/boolean)
-
必填字段标识
-
枚举值约束
-
跨事件关联关系
Step 3:多端代码一键生成
这份 JSON/YAML 文件可以被 Claude Code、Codex、Cursor 等本地 AI 编程工具直接读取,自动生成多端埋点代码:
-
Android(Java/Kotlin,支持主流 SDK)
-
iOS(Swift/ObjC,支持 CocoaPods)
-
Web(JavaScript/TypeScript,支持 npm 包)
-
小程序(微信/支付宝/字节)
-
Unity(C#,支持游戏埋点场景)
-
服务端上报代码(Node.js/Python/Go/Java)
-
LogBus2 配置文件(用于日志采集)

所有代码均符合各平台 SDK 规范,事件名、属性名、上报时机都和埋点方案严格一致。至此,研发同学的工作从"理解需求 + 写埋点代码",简化为"接入产物 + 验证联调"。
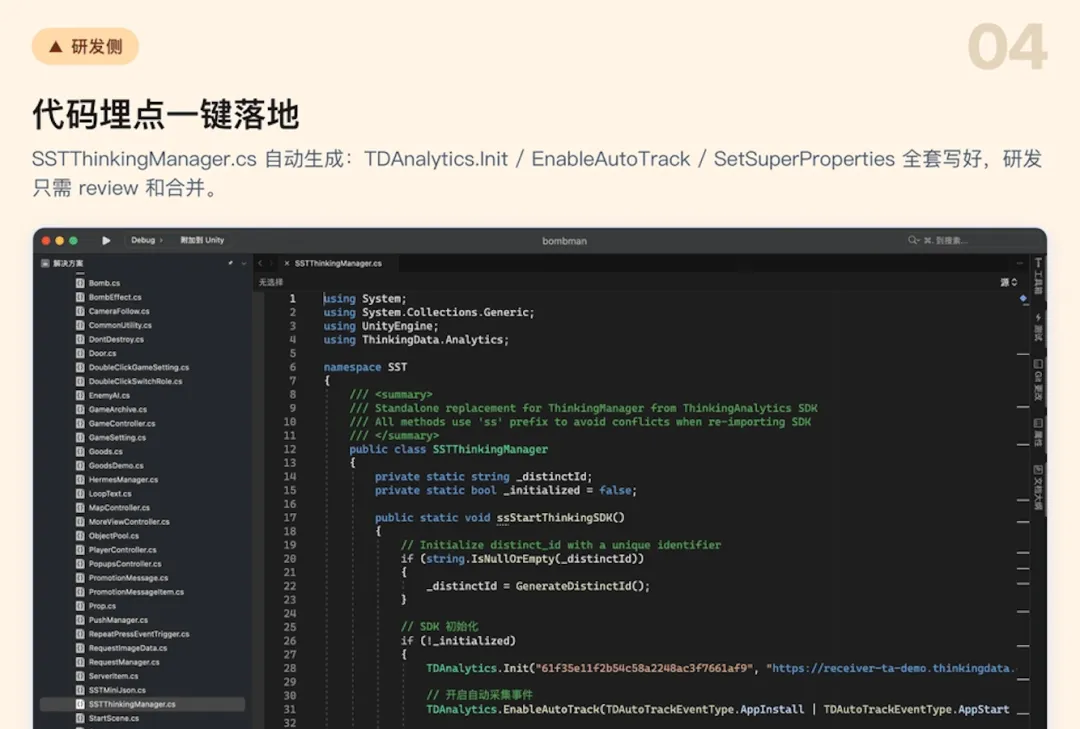
Step 4:自动校验,埋了不错
代码上线后,数据上报时后台会自动比对方案进行校验:
-
事件命名一致性检查
-
属性类型匹配度检查
-
必填字段完整性检查
-
数据格式合规性检查
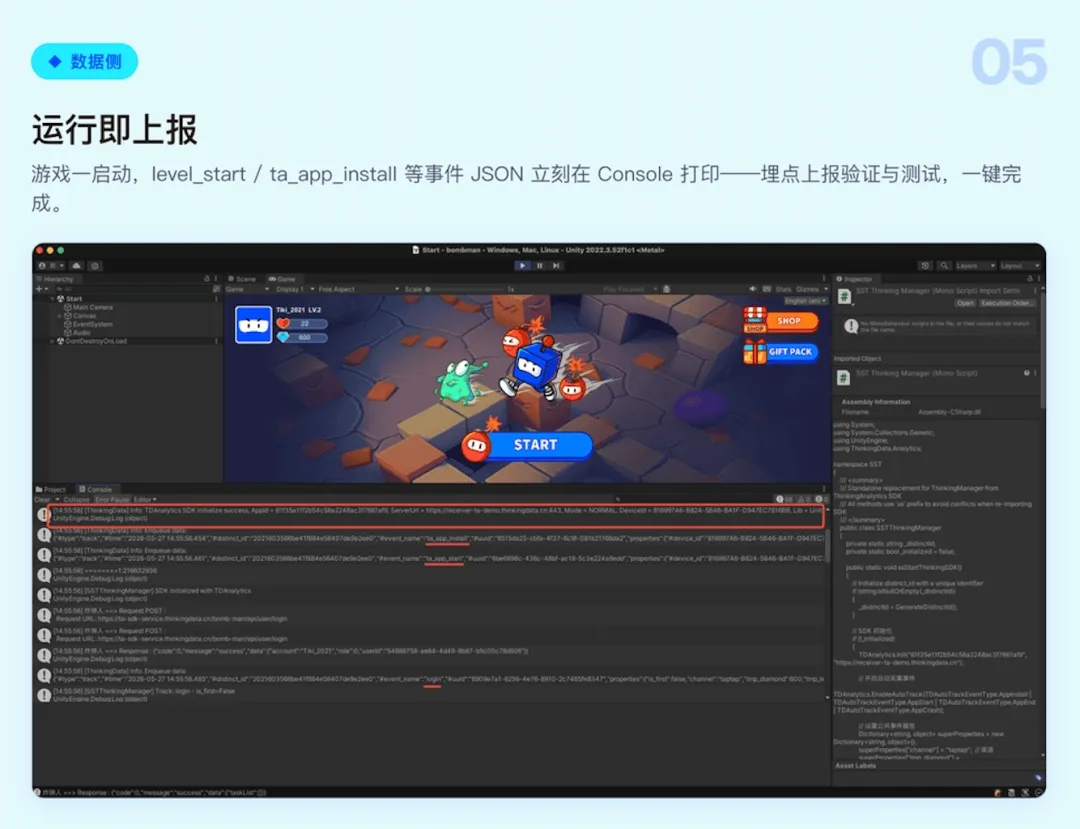
发现不一致时即时报警,避免传统埋点最常见的"埋了但埋错"问题。此外,Agent 还会根据上报的问题提供对应的配置步骤、示例代码和排查方法。
埋点产生的数据秒级传输,确保入库数据与预设方案一致的同时,实现"即采即入、即入即用",让数据能第一时间推动业务决策。
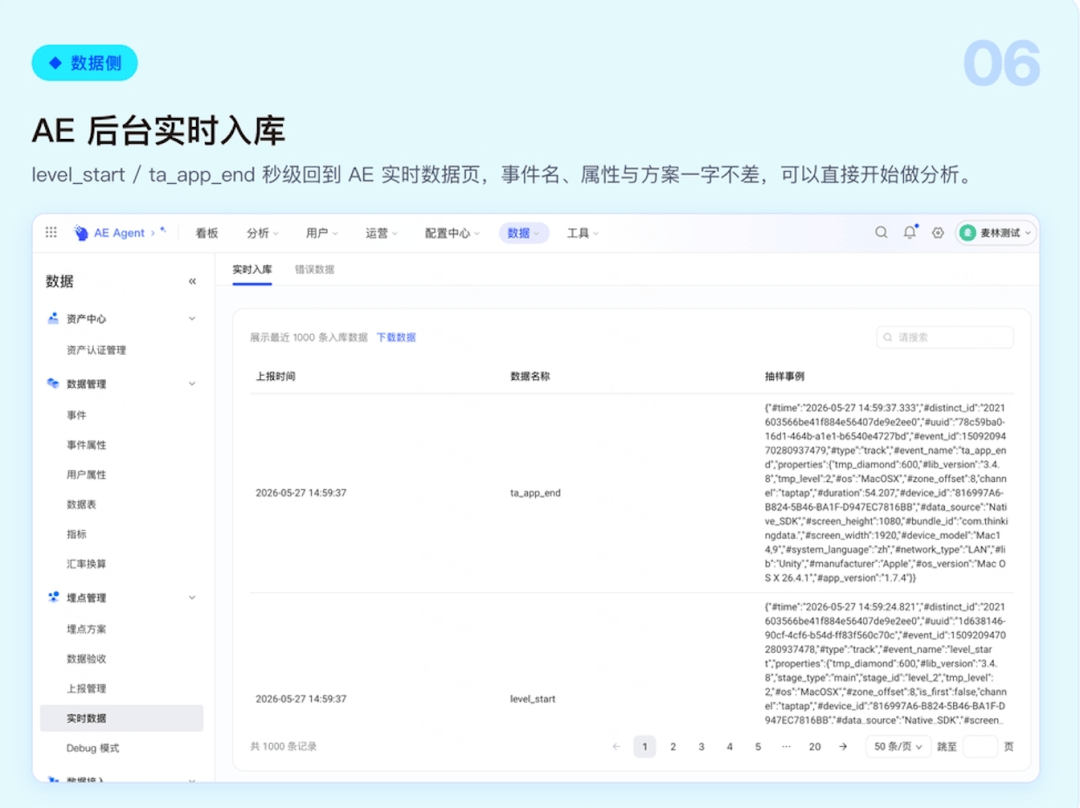
至此,三个能力形成完整的闭环:方案设计→代码生成→验证上线。原本需要 2 周才能完成的埋点上线流程,如今一步到位。埋点产生的数据秒级传输,实现"即采即入、即入即用"。
【从单点工具,到平台协作】
但这只是第一步。数据采集 Agent 不是孤立工具,而是企业级 AI Agent平台 Agentic Engine 的一部分。当它与其他 Agent 协同工作时,才能发挥更大的价值。
Agentic Engine 上的每一个 Agent 都遵循"产物可被消费"的设计原则------上游 Agent 输出的标准化产物,可以被下游 Agent、也可以被研发本地的 AI 工具直接接入。
ThinkingAI 相信,AI 时代的企业内部不再应该被"用数据的能力"和"造数据的能力"割裂。团队应当在同一条 Agent 工具链上协同工作,把精力放在真正创造价值的事情上。
6 月 5 号,视频号和小红书将直播实机演示数据采集 Agent,让大家真正看到埋点方案一键生成、一键上线是怎么做到的,期待与大家到时见面!