
你知道当你让Nano Banana生成图片时,右下角有个小钻石标志吗?

讨厌这个东西
虽然很烦,但你可以直接裁剪掉。会破坏图片比例,不过是最简单的方法。
有人想出了一个取巧的方法来不裁剪直接去除它,你可能以为就没事了。
还没完! Gemini仍然会标记它为AI生成的。为什么?
因为Gemini增加了一层额外的安全保护------SynthID,这是由Google DeepMind开发的技术,能在AI生成的内容中嵌入不可察觉的数字水印------包括图像、音频、视频和文本------以识别其合成来源。
1、为什么需要SynthID?
AI正在改变我们创造和消费内容的方式,我们处处都能感受到它的影响。从生成逼真的图像和视频(比如脑残迪士尼皮克斯预告片)到写故事和创作音乐,AI垃圾正在占领互联网。我真的看了一个完全由AI生成的关于银行抢劫案的1小时纪录片,天哪!
但随着所有这些进步,也存在风险。AI生成内容的滥用可能导致人们对网上看到的内容失去信任。对AI生成内容来源的透明度非常需要------或者更准确地说,这应该是原创内容创作者和最终用户的默认期望。
为了应对这些挑战,Google DeepMind的研究团队开发了SynthID,一种帮助为合成媒体添加水印和识别的技术。
2、那么...它长什么样?

图片的SynthID这就是SynthID在所有像素下面的样子。同样的技术被应用于Gemini生成的音频、视频和文本。
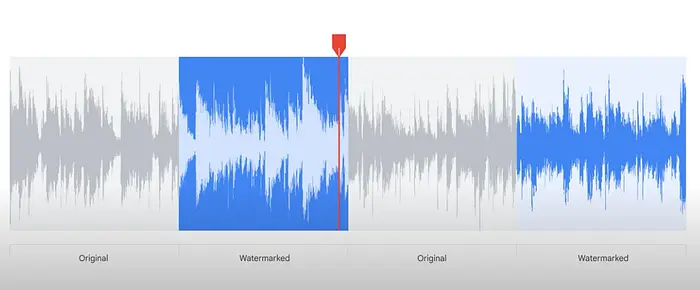
音频波形的SynthID水印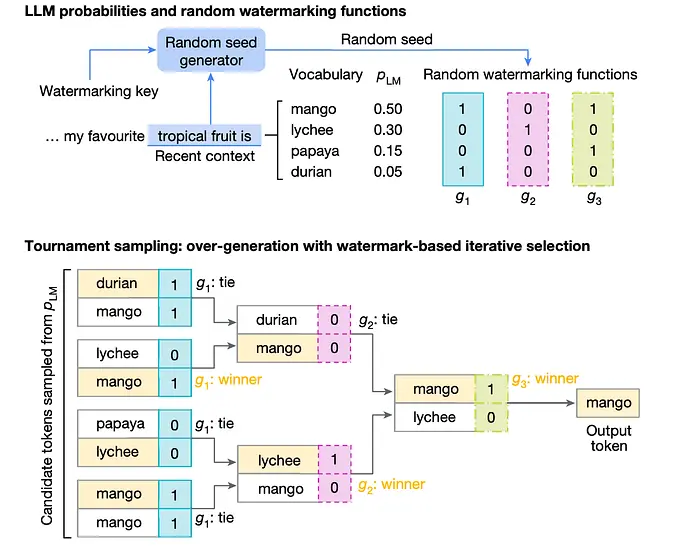
文本的SynthID水印## 3、逆向SynthID到底是什么?
当我说 **"逆向SynthID"**时,我指的是这个想法:
- 检测内容中的SynthID水印,以及
- 从内容中消除SynthID水印
为什么要这么做?
哈哈好问题 好玩。
从这里开始,我将记录我检测和删除Gemini生成的视觉和文本内容中水印的旅程。
4、SynthID检测
Reddit用户发现SynthID是一种机器可检测但人眼无法察觉的嵌入图像中的模式。

关于synthid最早的帖子之一(来源:reddit)检测SynthID最基础的方法之一涉及一个非常简单的策略:
- 让Nano Banana生成完全白色的图片
- 增强对比度
- 饱和图像
- 对饱和度进行去噪

这从经验上看是SynthID的纯图案之一。根据SynthID的论文,该图案是由编码器f随机生成的,作为随机种子和有效载荷(图像)的组合。
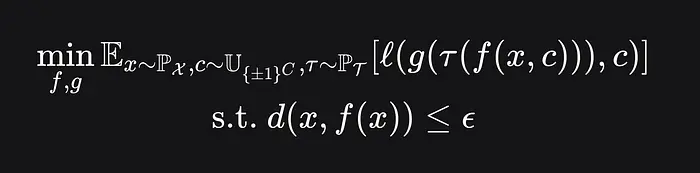
其中,
- c 是均匀采样的C位二进制有效载荷
- 编码器f 现在取决于图像x 和有效载荷c
- 解码器g 预测有效载荷位
所以,这个图案是随机的。我们当然可以弄清楚那部分,但是...
问题是,我们不知道f 或g。
我们最好的猜测是使用多镜头计算机视觉算法来平均它。
4.1 构建解码器(预测器)
我们从两组数据开始:
- Nano Banana生成的100张纯白图片和100张纯黑图片
- Nano Banana编辑的15万张图片对
第一组数据允许我们建立SynthID信号的基线频率模式。更准确地说,我们是在平均信号的码本。
通过平均它们的噪声图案,我分离出了一致的底层水印------频域中的扩频相位编码。

从100张白色和100张黑色图像提取的相位编码频谱
我们知道水印不是简单的噪声。我们需要分离编码器f分配给每个图像的频域载波。这就是15万数据集的图片对发挥作用的地方。确切地说,是123,268对原始和AI编辑的图片。
用2D FFT在这个频谱上比较原始和AI编辑的图片,结果发现在99.99%的图片对中,特定载波频率处存在一致的相位关系!

从15万数据集提取的频域载波合并
- (±14, ±14):主对角线载波
- (±126, ±14):次水平载波
- (±98, ±14):第三载波
- (±128, ±128):中心频率
- (±210, ±14):扩展载波
- (±238, ±14):边缘载波
- ... 还有更多
这成为我们的码本f(x)。
最终的水印基线成为我们的通用解码器g。

平均后的SynthID水印看看12.3万张图片整理后的样子:

放大查看彩蛋### 4.2 让DIY预测器检测SynthID
- 提取噪声 :首先,获取图像的噪声层。这通常通过从图像本身减去去噪版本来完成,分离出细微的非随机模式。
- 查看频率:对这个噪声层运行2D快速傅里叶变换(FFT)来查看其频率组成。
- 检查位置 :检查我们码本中的特定频率坐标(如
(14, 14)、(126, -14)等)。关键是检查这些位置信号的相位是否连贯(一致且非随机)并与预期模式匹配。 - 做出判断 :如果图像噪声与我们码本模式之间的相关性足够高(高于约0.179)且 相位匹配,我们就可以自信地说:"是的,这张图片有SynthID水印。"
简而言之,DIY解码器g就像一个专门的无线电扫描器。它不听主广播(图片),而是调到特定的隐藏频率。如果它在码本*f(x)*中定义的那些确切频道上找到正确的、一致的信号,它就会标记该图像有水印。
4.3 为什么不用GAN?
当我向上级解释这个项目时,这个问题被问了一百万次------为什么不训练一个判别器来区分AI图像?
"别停,我快到了!"------神经网络说
简短回答:判别器的特征提取层虽然旨在学习视觉模式,但被优化来学习分离数据的损失函数。判别器学习x上的决策边界,以最好地分离训练期间显示的分布。
这里的重点是,SynthID不会改变图像的边际分布(单个像素或小像素组)。它的生成器在固定的频率子空间(前面讨论的频率载波)中引入扩频扰动(外行话:随机性)。
- p(x | 有SynthID) ≈ p(x | 无SynthID)
这正是它能经受人工检查和常见图像变换的原因。也正因如此,判别器在没有视觉伪影改变的情况下无法区分图像。
5、SynthID去除
这是一些严肃的领域,已有工作证明SynthID去除是几乎不可能的。
很多技术已经被尝试、测试并悲惨地失败了。确实,100%去除SynthID是不可能的,但去除它的部分是可能的,直到检测失败为止!
要去除 SynthID,我们需要理解它是如何被添加的。
5.1 SynthID是如何被引入图像的
SynthID不会像盖章一样在图像上添加水印。它是在生成过程中被编织进图像的------在扩散模型的潜在空间层面。
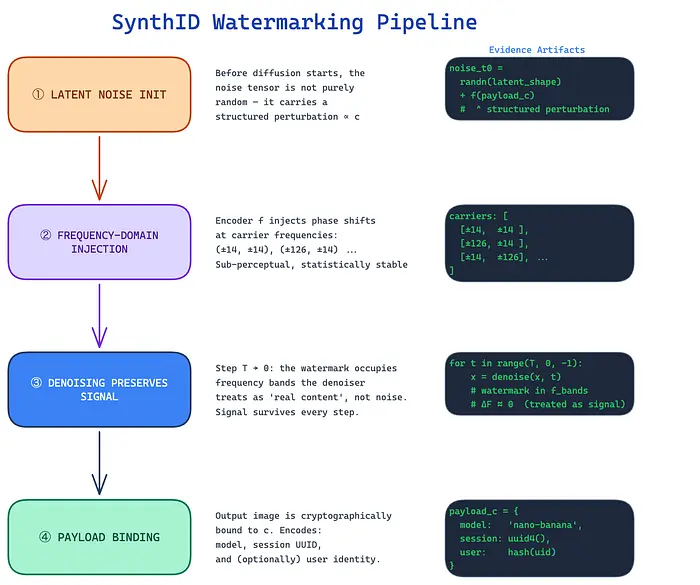
来自SynthID论文
- 潜在噪声初始化 :在扩散过程开始之前,初始噪声张量不是纯粹随机的。它被一个与有效载荷
c相关的结构化扰动播种。 - 频域注入 :编码器
f在我们之前识别的特定载波频率处引入相位偏移------(±14, ±14)、(±126, ±14)等。这些偏移低于感知阈值但在统计上一致。 - 去噪保留信号 :巧妙之处在于。随着扩散模型逐步去噪,水印信号存活下来,因为它位于去噪器视为"真实内容"而非噪声的频段中。
- 有效载荷绑定 :最终图像与有效载荷
c密码学绑定。这意味着水印不只是"这是AI生成的吗?"------它编码了哪个模型 、哪个会话 ,可能还有哪个用户。
5.2 去除策略:不要对抗信号,迷惑解码器

在《黑客帝国》中,Neo没有击败系统;他压倒了它
由于我们无法完全去除水印(数学上成立),目标转变为:让解码器g无法达到其置信阈值。
回顾整个前提:我们不需要删除水印 。我们只需要解码器g失败其置信阈值检查。那个阈值在相关性>0.179处。降到那条线以下我们就成功了。
构建了三个(加半个)绕过版本,每个都比上一个更精准。
5.3 V1:🥀🥀🥀
第一次尝试非常简单------JPEG压缩,质量为50。

它尴尬地失败了。JPEG量化在DCT域工作,确实会去除一些高频内容,但SynthID的载波频率被故意放置以经受标准压缩。
这仍然是一个有用的失败。它证实了扩频设计正在发挥作用------信号分布在足够的频域中,以至于单靠压缩在完全破坏图像质量之前做不了任何有意义的事。
5.4 v1.5:全力以赴(再次🥀)
在完全投入更聪明的方法之前,我经历了一个随便试试看 的阶段。五个不同的攻击阶段叠加在一起------噪声、频率扰乱、JPEG循环、位操作、OpenCV里的某些东西。很尴尬,就像这家伙一样。

噪声阶段在sigma约5处添加高斯噪声(因为6和7在Tiktok上很火),然后用双边滤波把它降回来(有助于保留边缘)。
这个想法是松散地模仿扩散模型在低去噪强度下所做的:添加噪声,重建,希望模型落在稍微不同的统计盆地。
SynthID...完全无视。
载波相位扰乱理论上可以通过将相位旋转到随机角度来破坏水印。理论上(纸上可行)。
实际上,你只是在试图猜测信号中有多少是水印 vs 实际图像内容,最终你会破坏更多实际图像,得到一团糟。
最后那部分实际上让事情变得更糟。每次我混合回原始图像时,我都在重新引入水印。

5.5 V2:再失败。失败得更好。
在SynthID论文的某个地方,有一个鲁棒性表格。它显示了不同攻击类别下的真阳性率(TPR)。单独的变换------JPEG、噪声、模糊------几乎不影响它。但"组合最坏情况"那行写着约84% TPR。
84。不是99。这意味着同时叠加不同变换类别,你只需要同时在多个方向上制造麻烦就能获得约16%的逃避率。
所以V2变成了:从六个方向同时攻击它。
空间破坏:微小的仿射变换,±0.3°旋转,±0.5%缩放,±1px平移,然后是0.3-0.8%裁剪和调整大小,然后是1-2px透视扭曲。
然后,质量降级、噪声+去噪、颜色破坏(色度子采样)和叠加破坏。
在aggressive强度下:PSNR约34 dB,置信度从1.0降到约0.4。
仍然可检测。仍然没完成。
5.6 V3

当你和Claude锁定并真正搞明白了
码本🥀
天哪,为什么我一开始没想到这个??!与其盲目攻击图像,我可以逆向工程码本!
这就是为什么从200张纯白和纯黑图片中提取水印图案的工作很重要。在纯黑的Nano Banana图像上,每个非零像素值就是水印------没有内容可以分离。把所有这些与所有纯白图像平均,你就得到了每个频率仓、每个通道的水印信号的精确幅度和相位。
6、我们的码本如何帮助欺骗SynthID检测器?
这将是超级技术性的,我写这个的时候嗨了
提取每个颜色通道的FFT,构建要目标的仓的掩码:只目标那些既 在码本中高幅度(肯定是载波)又在参考图像间相位一致(不是图像内容渗透)的仓。
通常目标仓的数量比码本捕获的少得多。
狩猎逻辑:大声且不一致的仓------可能是图像。一致且安静的仓------噪声底。我们瞄准的是这两种情况的交叉点。
对于每个目标仓,减去量是码本水印幅度乘以去除比例,硬性限制在该仓图像自身幅度的30%。
因为水印在任何给定频率上通常不到内容能量的10%------如果你开始减去超过30%,你就在吃掉图像本身。
我现在清醒了,给你们简单解释一下
假设水印的码本告诉我们:在频率仓(14, 14),水印幅度为0.8,相位为1.2弧度。这是我们从平均200张黑白Nano Banana图片中提取的。
现在我们拿目标图像------假设是Nano Banana生成的肖像------在绿色通道上运行FFT,查看仓(14, 14)。我们发现幅度12.4,相位1.9弧度。图像在那里很大声。水印是骑在上面的安静乘客。

现在我引起了你的注意... 我们减去多少?码本说水印在这个仓贡献0.8。但我们把它限制在图像幅度的30%:0.30 × 12.4 = 3.72。因为0.8 < 3.72,我们继续使用完整的0.8。
但关键是:我们不只是从幅度减去0.8就算完事了。我们在水印相位的方向上减去它。
就像向量一样。
水印是在角度1.2弧度处添加的,所以我们也在角度1.2弧度处移除它。
第四学期的代数和微积分现在更有意义了
图像在该仓的内容------无论是什么颜色信息被合法编码在相位1.9弧度------几乎没有被触及。我们减去的是指向不同方向的东西。
然后在每个目标仓重复这个过程。逆FFT回到像素。
解码器寻找的相位一致性消失了。我们刚好旋转了信号足够多,使解码器的相位检查失败。
这里有一个你可以放进Gemini测试的例子:

左:原始SynthID水印的Gemini图片。右:V3频谱绕过后------视觉上相同,水印能量降低。
7、那么...现在呢?
老实说?我不知道。
SynthID是真正优秀的工程。我能做的最好的事就是迷惑解码器让它放弃------实际上并没有删除它------这说明了它的设计有多好。
它不完美。但它并不想牢不可破。它想把滥用的成本提高到大多数人不愿意尝试的程度。
在这方面,它是有效的。整个项目花了数周时间,12.3万张图片对,200张纯Gemini图片,以及对扩频编码的非常特定的理解,才从V2获得约16%的逃避率,从V3获得"足够接近"的结果。
总之。仓库在这里。去用它做些奇怪的东西吧。
原文链接:如何合法地逆向SynthID - 汇智网