一、概念定义
RocksDB 状态后端(RocksDB State Backend) 的本质是:一种基于 LSM-Tree 结构的嵌入式 KV 存储引擎,作为 Apache Flink 的堆外状态后端,将算子状态持久化到本地磁盘并以增量快照方式同步到远程存储系统。
在整个 Apache Flink 体系中,RocksDB State Backend 处于 状态管理层 的核心位置------它是 Flink 突破 JVM 堆内存限制、支撑 TB 级超大状态(Large State) 流计算任务的关键基础设施,直接决定了流处理任务的吞吐、延迟与故障恢复能力。
直观类比: 可以将 RocksDB State Backend 类比为一个高速邮件分拣中心的 本地货架仓储系统------工人(算子)在本地货架(RocksDB)上快速存取包裹(状态),同时定期将货架快照(Checkpoint)同步到异地总仓(HDFS/S3),一旦仓库发生火灾(节点故障),可以从总仓快速恢复货架内容。
二、整体架构全景图
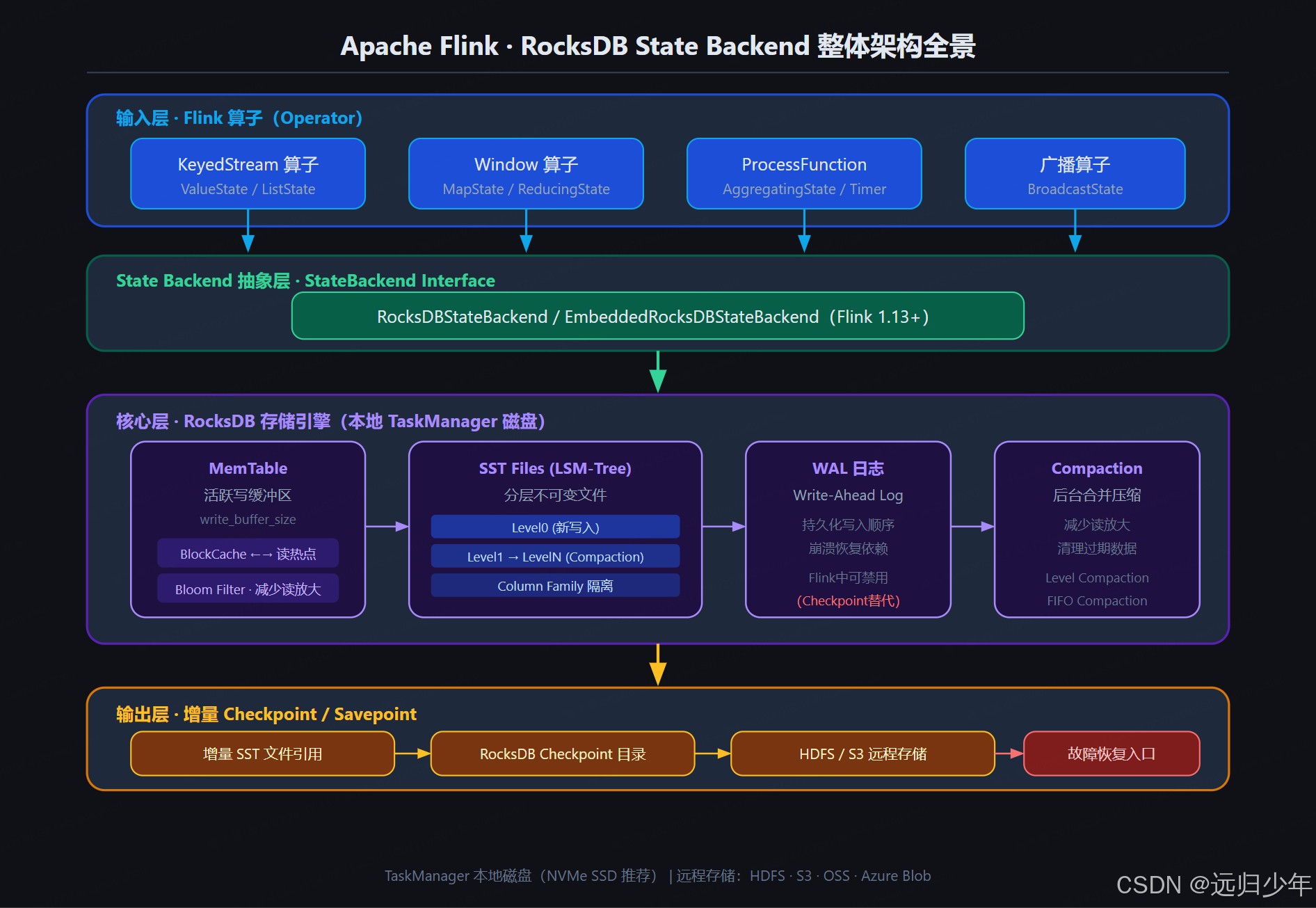
三、核心子概念逐一详解
3.1 MemTable(内存写缓冲区)
定义: MemTable 是 RocksDB 的内存写缓冲区,所有写操作首先进入 MemTable,采用跳表(SkipList)或 HashSkipList 数据结构实现,写满后自动转为 Immutable MemTable 并刷写至磁盘 SST 文件。
关键特性:
- 默认大小由
write_buffer_size控制(Flink 默认 64MB) - 同时允许多个 MemTable 并存(
max_write_buffer_number) - 写操作完全在内存中,延迟极低(微秒级)
java
// Flink 中配置 RocksDB MemTable 参数
EmbeddedRocksDBStateBackend backend = new EmbeddedRocksDBStateBackend(true);
// 通过 RocksDBOptionsFactory 自定义底层参数
backend.setRocksDBOptions(new RocksDBOptionsFactory() {
@Override
public DBOptions createDBOptions(DBOptions currentOptions,
Collection<AutoCloseable> handlesToClose) {
return currentOptions
.setMaxBackgroundJobs(4) // 后台 Compaction 线程数
.setInfoLogLevel(InfoLogLevel.WARN_LEVEL);
}
@Override
public ColumnFamilyOptions createColumnOptions(ColumnFamilyOptions currentOptions,
Collection<AutoCloseable> handlesToClose) {
return currentOptions
.setWriteBufferSize(128 * 1024 * 1024L) // 128MB MemTable
.setMaxWriteBufferNumber(3); // 最多3个MemTable
}
});3.2 SST Files 与 LSM-Tree 分层结构
定义: SST(Sorted String Table)文件是 RocksDB 的不可变磁盘存储单元,按照 LSM-Tree(Log-Structured Merge-Tree)分层组织,从 Level0 到 LevelN 文件数量递增、大小递增、重叠度递减。
关键特性:
- 写优化: 顺序写磁盘,写放大(Write Amplification)小
- Column Family(列族)隔离: Flink 为每个状态注册一个 Column Family,实现状态隔离
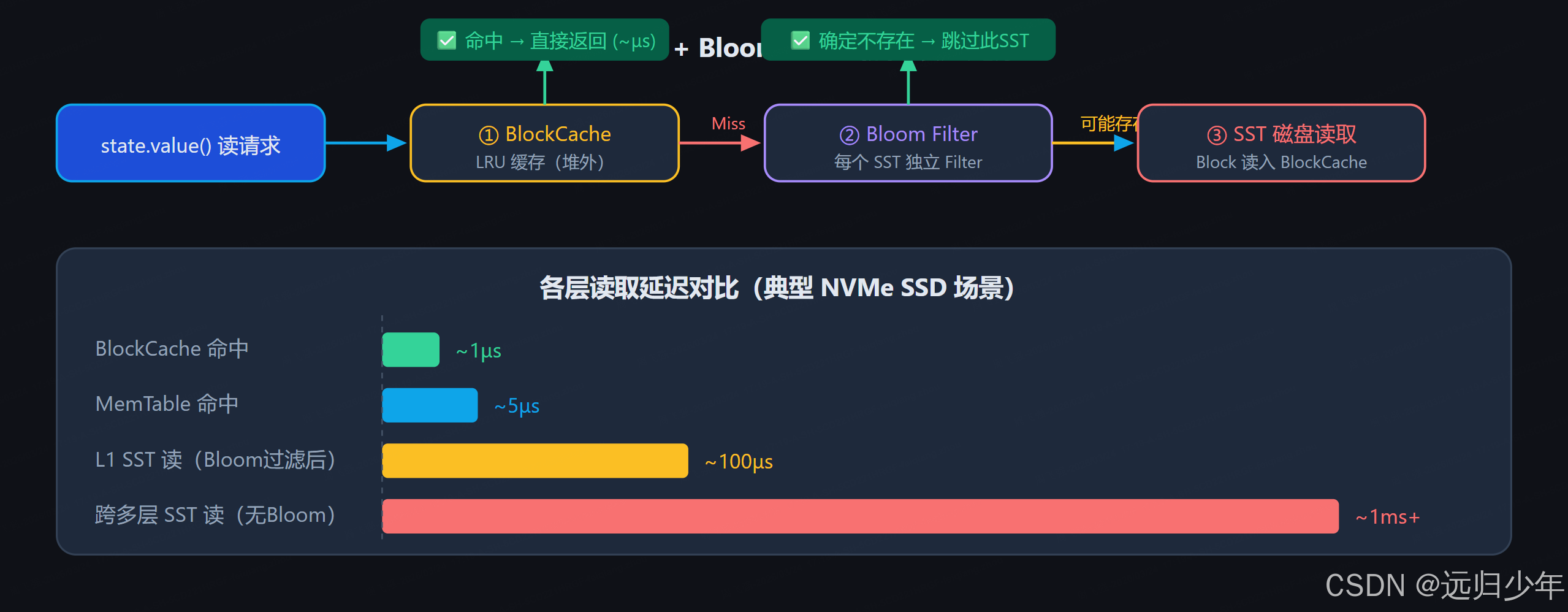
- 读放大(Read Amplification): 最坏情况需跨多层查找,Bloom Filter 大幅缓解

3.3 Column Family(列族)隔离机制
定义: Column Family 是 RocksDB 内部的命名空间,Flink 为每一个注册的状态(State)创建一个独立的 Column Family,实现不同状态数据的物理隔离,同时共享同一个 RocksDB 实例的后台线程和 BlockCache。
关键特性:
- 每个 Column Family 拥有独立的 MemTable 和 SST 文件集合
- Flink 对
defaultColumn Family 不使用,所有状态均在独立 CF 中 - Savepoint 时按 Column Family 进行序列化导出
java
// Flink 内部 RocksDBKeyedStateBackend 状态注册(简化版)
// 每次 getOrCreateKeyedState 都可能创建新的 Column Family
RocksDBValueState<K, N, V> createValueState(
TypeSerializer<N> namespaceSerializer,
StateDescriptor<S, V> stateDescriptor) {
// 根据 stateDescriptor.name 找或创建 ColumnFamilyHandle
ColumnFamilyDescriptor cfDescriptor = new ColumnFamilyDescriptor(
stateDescriptor.getName().getBytes(StandardCharsets.UTF_8),
createColumnFamilyOptions() // 独立配置
);
ColumnFamilyHandle cfHandle = db.createColumnFamily(cfDescriptor);
return new RocksDBValueState<>(db, cfHandle, ...);
}3.4 增量 Checkpoint(Incremental Checkpoint)
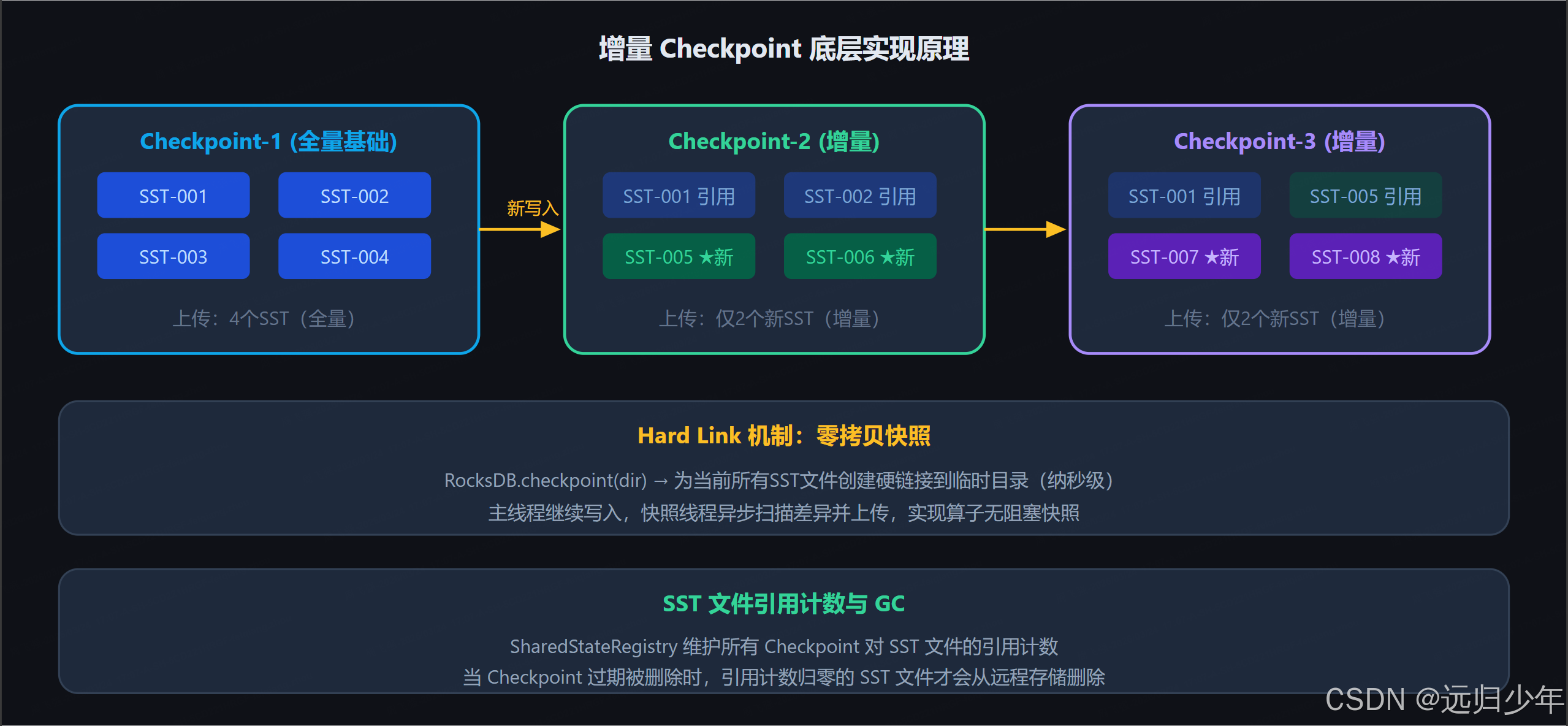
定义: 增量 Checkpoint 是 RocksDB State Backend 最重要的特性之一,它只将自上次 Checkpoint 以来新增的 SST 文件上传到远程存储,而不是每次全量上传所有状态数据,极大降低了大状态场景下的 Checkpoint 耗时和网络带宽消耗。
关键特性:
- 基于 RocksDB 的
CheckpointAPI 生成本地硬链接(Hard Link),零拷贝 - 通过文件引用计数(Reference Count)管理 SST 文件生命周期
- 恢复时需要下载多个 Checkpoint 的增量文件并重建完整状态
java
// 启用增量 Checkpoint(Flink 1.13+ 推荐方式)
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EmbeddedRocksDBStateBackend rocksDBBackend =
new EmbeddedRocksDBStateBackend(true); // true = 启用增量快照
env.setStateBackend(rocksDBBackend);
// Checkpoint 配置
env.enableCheckpointing(60_000L); // 每60秒一次
env.getCheckpointConfig()
.setCheckpointStorage("hdfs:///flink/checkpoints");
env.getCheckpointConfig()
.setMinPauseBetweenCheckpoints(30_000L); // 两次checkpoint间最小间隔
env.getCheckpointConfig()
.setMaxConcurrentCheckpoints(1); // 同时只允许1个checkpoint四、工作原理 / 执行流程图
4.1 写入流程
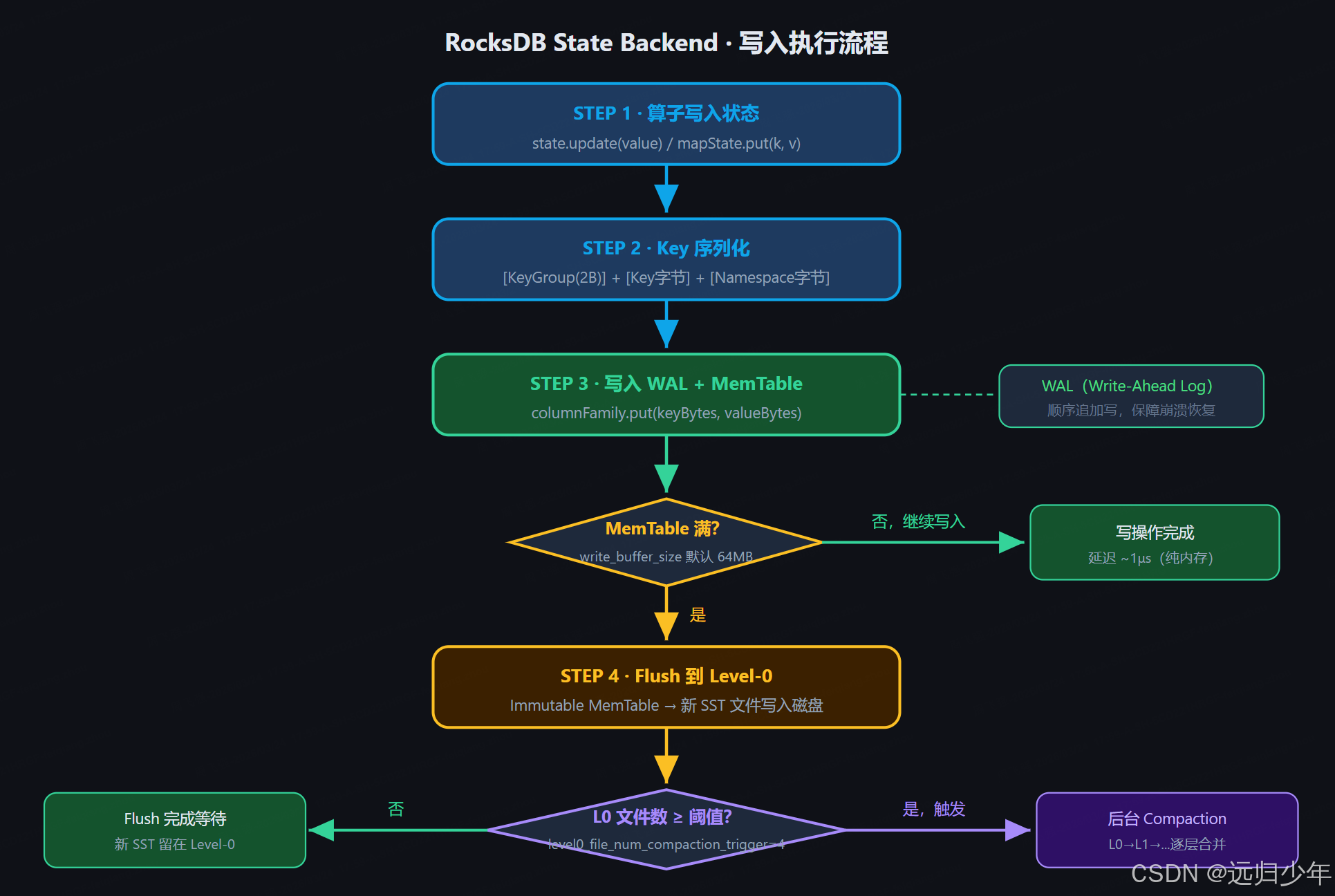
4.2 读取流程
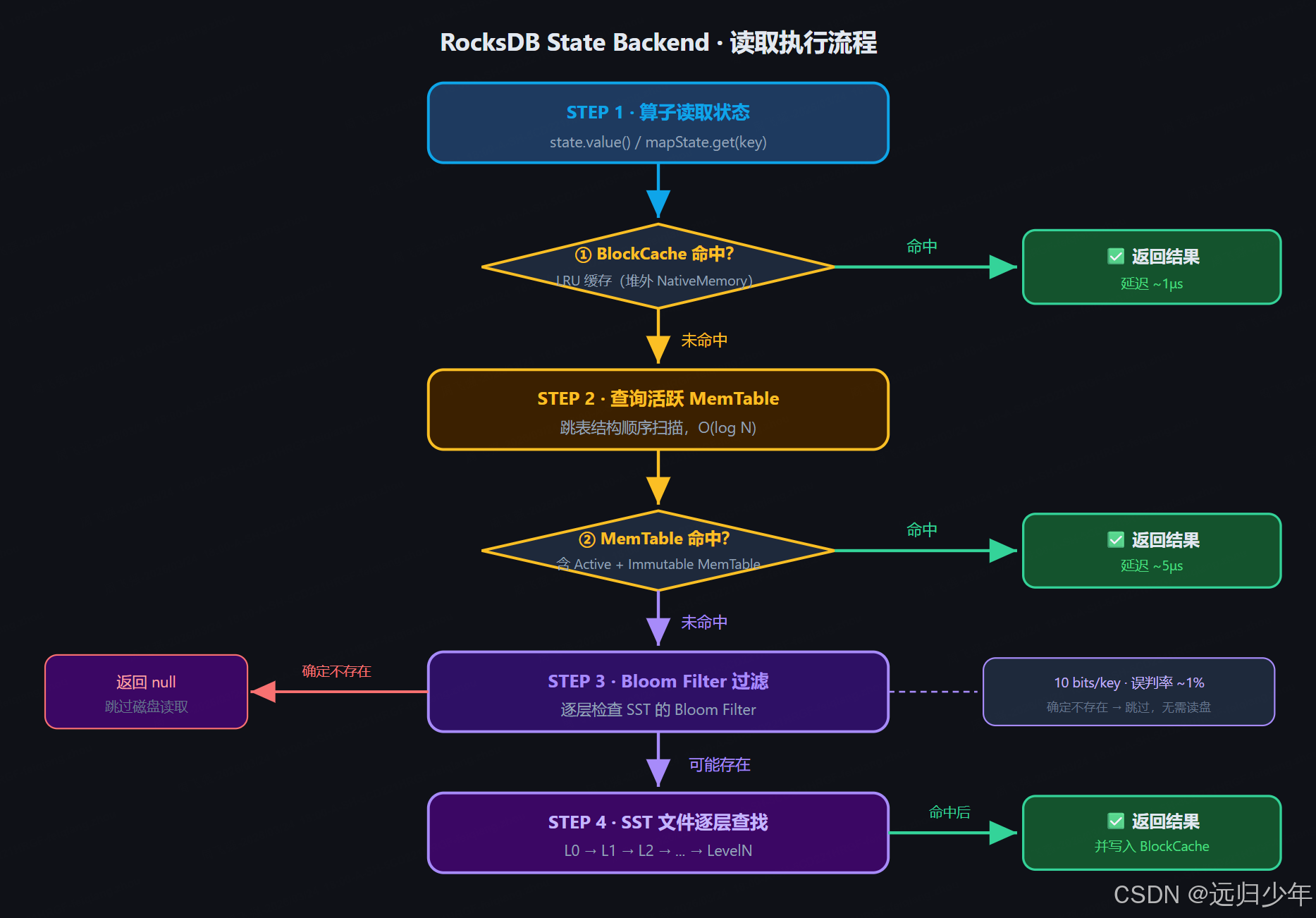
4.3 Checkpoint 执行时序
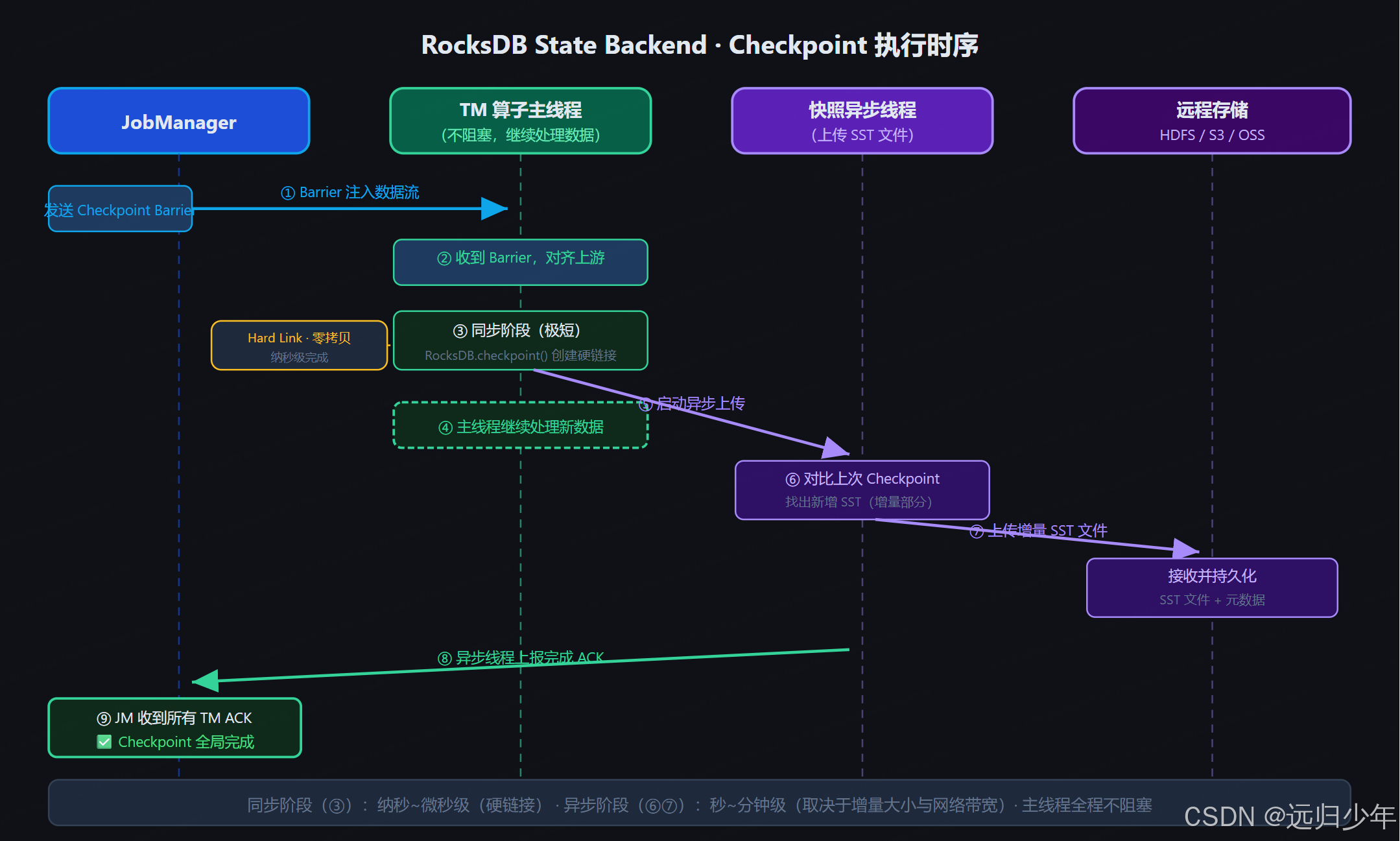
4.4 三个流程核心对比

五、核心分类对比
5.1 状态后端三者对比 SVG

5.2 对比表格
| 维度 | HashMapStateBackend | EmbeddedRocksDBStateBackend | 自定义实现 |
|---|---|---|---|
| 状态容量 | 受JVM堆限制(通常<10GB) | 仅受磁盘限制(TB级) | 实现相关 |
| 读写性能 | 最优(纯内存操作) | 有序列化+磁盘IO开销 | 不定 |
| Checkpoint | 全量,慢 | 增量,快 | 自定义 |
| GC压力 | 大状态时严重 | 极低(堆外) | 不定 |
| 精确一次 | ✅ 支持 | ✅ 支持 | 需实现 |
| 适用场景 | 小状态/测试 | 生产大状态首选 | 特殊需求 |
| 典型缺点 | OOM风险,全量Checkpoint慢 | 序列化成本,读放大 | 维护成本高 |
六、与其他概念的关联关系
RocksDB State Backend 在 Flink 完整体系中与多个核心概念深度关联:
1. Checkpoint Coordinator(检查点协调器)
JobManager 中的 CheckpointCoordinator 通过发送 CheckpointBarrier 触发 RocksDB 执行本地快照,协调所有 TaskManager 完成分布式一致性快照。
2. Keyed State 与 KeyGroupRange
RocksDB 中的 Key 存储格式为 [KeyGroup][Key][Namespace] 的二进制前缀,与算子并行度和 KeyGroup 的划分强绑定,这使得 rescale(变更并行度)时能够按 KeyGroup 粒度重新分配 RocksDB 数据。
3. Timer Service(定时器服务)
Flink 的 InternalTimerServiceImpl 将 Timer 也存储在 RocksDB 中(名为 _timers_ 的 Column Family),定时器状态同样参与 Checkpoint。
java
// 典型组合:RocksDB + KeyedProcessFunction + Timer
public class LargeStateProcessFunction
extends KeyedProcessFunction<String, Event, Alert> {
// 状态声明:存储在 RocksDB 对应的 Column Family
private ValueState<Long> countState;
private MapState<String, Double> featureState;
@Override
public void open(Configuration params) {
countState = getRuntimeContext().getState(
new ValueStateDescriptor<>("count", Long.class));
featureState = getRuntimeContext().getMapState(
new MapStateDescriptor<>("features", String.class, Double.class));
}
@Override
public void processElement(Event event, Context ctx, Collector<Alert> out)
throws Exception {
// RocksDB 读:触发序列化反序列化 + 磁盘/BlockCache 读取
Long count = countState.value();
count = (count == null) ? 1L : count + 1;
countState.update(count); // RocksDB 写:写入 MemTable
// 注册定时器:同样持久化到 RocksDB
ctx.timerService().registerEventTimeTimer(
event.getTimestamp() + 60_000L);
}
}4. Savepoint 与 Rescaling
RocksDB Savepoint 与 Checkpoint 不同,Savepoint 是全量的、可移植的快照,用于版本升级或并行度调整。Rescaling 时,Flink 根据 KeyGroupRange 重新分配 RocksDB 的 SST 文件,无需全量重写。
七、进阶特性与底层原理
7.1 增量 Checkpoint 的底层实现原理
增量 Checkpoint 的核心在于 RocksDB 原生的 Checkpoint API 与 Flink 的 SST 文件引用计数 机制的结合:
7.2 RocksDB Compaction 与写放大
写放大(Write Amplification, WA) 是 LSM-Tree 的固有代价:一次逻辑写入可能触发多次物理磁盘写入。理解并控制写放大对于 Flink 大状态任务的 I/O 性能至关重要。

7.3 BlockCache 与 Bloom Filter 读优化
BlockCache 和 Bloom Filter 是 RocksDB 应对读放大的两大核心武器,在 Flink 大状态场景中合理配置可将读性能提升 3~10 倍:
java
// Flink 中完整的 RocksDB 读优化配置
RocksDBOptionsFactory readOptFactory = new RocksDBOptionsFactory() {
@Override
public DBOptions createDBOptions(DBOptions currentOptions,
Collection<AutoCloseable> handlesToClose) {
return currentOptions
// 后台 Compaction + Flush 线程数(与 CPU 核数匹配)
.setMaxBackgroundJobs(8)
// 子压缩并行度(大 SST 文件并行 Compaction)
.setMaxSubcompactions(4)
// 字节计数单位开启统计(便于监控)
.setStatsDumpPeriodSec(60);
}
@Override
public ColumnFamilyOptions createColumnOptions(ColumnFamilyOptions currentOptions,
Collection<AutoCloseable> handlesToClose) {
// ① 配置 BlockBasedTable(SST 文件格式)
BlockBasedTableConfig tableConfig = new BlockBasedTableConfig()
// BlockCache:缓存热点 SST Block,减少磁盘读。
// 推荐:可用堆外内存的 50%
.setBlockCache(new LRUCache(512 * 1024 * 1024L)) // 512MB LRU Cache
.setBlockSize(32 * 1024L) // 32KB Block 大小
// ② Bloom Filter:10 bits/key,约1%误判率,过滤无效 SST 文件读
.setFilterPolicy(new BloomFilter(10, false))
// Block 索引缓存在 BlockCache 中(减少索引文件读取)
.setCacheIndexAndFilterBlocks(true)
// 高优先级保留 index/filter 在 cache 中不被驱逐
.setPinL0FilterAndIndexBlocksInCache(true)
// 数据压缩格式
.setDataBlockIndexType(DataBlockIndexType.kDataBlockBinaryAndHash);
return currentOptions
.setTableFormatConfig(tableConfig)
// ③ MemTable 写缓冲区
.setWriteBufferSize(128 * 1024 * 1024L) // 128MB
.setMaxWriteBufferNumber(3)
.setMinWriteBufferNumberToMerge(2)
// ④ 压缩算法(LZ4 在速度和压缩率之间平衡最优)
.setCompressionType(CompressionType.LZ4_COMPRESSION)
.setBottommostCompressionType(CompressionType.ZSTD_COMPRESSION) // 底层用更高压缩率
// ⑤ Compaction 策略
.setCompactionStyle(CompactionStyle.LEVEL)
.setLevelCompactionDynamicLevelBytes(true) // 动态 Level 大小
.setMaxBytesForLevelBase(256 * 1024 * 1024L);
}
};
八、完整性能调优指南
8.1 内存配置体系
Flink + RocksDB 的内存管理涉及多个层次,错误配置是生产环境性能问题的最主要来源:

8.2 完整 flink-conf.yaml 调优配置
yaml
# ===================================================
# Flink + RocksDB 生产环境推荐配置(以 8 核 32GB TM 为例)
# ===================================================
# --- TaskManager 内存布局 ---
taskmanager.memory.process.size: 28g # TM 进程总内存
taskmanager.memory.task.heap.size: 4g # JVM 堆(框架 + 用户逻辑)
taskmanager.memory.managed.fraction: 0.45 # 45% 给 RocksDB 托管内存 ≈ 12.6g
taskmanager.memory.network.fraction: 0.08 # 8% 网络缓冲
taskmanager.memory.jvm-overhead.fraction: 0.1 # JVM 元空间等
# --- RocksDB State Backend ---
state.backend: rocksdb
state.backend.incremental: true # 启用增量 Checkpoint(必须)
state.checkpoints.dir: hdfs:///flink/checkpoints
state.savepoints.dir: hdfs:///flink/savepoints
# --- RocksDB 内存配置(使用 Flink 托管内存)---
state.backend.rocksdb.memory.managed: true # 由 Flink 统一管理
state.backend.rocksdb.memory.write-buffer-ratio: 0.5 # 50% 给 MemTable
state.backend.rocksdb.memory.high-prio-pool-ratio: 0.1 # 10% 高优先级(index/filter)
# --- RocksDB MemTable 配置 ---
state.backend.rocksdb.writebuffer.size: 128mb
state.backend.rocksdb.writebuffer.count: 3
state.backend.rocksdb.writebuffer.number-to-merge: 2
# --- RocksDB Block 配置 ---
state.backend.rocksdb.block.cache-size: 256mb
state.backend.rocksdb.block.blocksize: 32kb
# --- RocksDB Compaction 配置 ---
state.backend.rocksdb.compaction.level.use-dynamic-size: true
state.backend.rocksdb.compaction.level.target-file-size-base: 64mb
state.backend.rocksdb.compaction.level.max-size-level-base: 256mb
state.backend.rocksdb.thread.num: 4 # 后台线程(Compaction+Flush)
# --- Checkpoint 配置 ---
execution.checkpointing.interval: 60s
execution.checkpointing.min-pause: 30s
execution.checkpointing.max-concurrent-checkpoints: 1
execution.checkpointing.timeout: 600s
execution.checkpointing.tolerable-failed-checkpoints: 3
execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION
# --- 本地恢复(Local Recovery)---
cluster.local-recovery: true # 节点重启优先用本地 RocksDB 数据
taskmanager.local-state-dir: /data/flink/local-recovery8.3 Rescaling 时的 KeyGroup 重分配
java
/**
* RocksDB 状态的 Key 二进制格式(Flink 内部)
*
* ┌─────────────────────────────────────────────────────────┐
* │ KeyGroup (2B) │ Key序列化字节 │ Namespace序列化字节 │
* └─────────────────────────────────────────────────────────┘
*
* KeyGroup = MathUtils.murmurHash(key) % maxParallelism
*
* Rescaling 时:
* 旧并行度 P1 → 新并行度 P2
* 每个 KeyGroup 被重新路由到新的 SubTask
* RocksDB 数据按 KeyGroup 前缀扫描并迁移
*/
public class KeyGroupRangeAssignment {
// 计算 key 属于哪个 KeyGroup
public static int assignToKeyGroup(Object key, int maxParallelism) {
return computeKeyGroupForKeyHash(key.hashCode(), maxParallelism);
}
// 计算该 KeyGroup 属于哪个并行子任务
public static int computeOperatorIndexForKeyGroup(
int maxParallelism, int parallelism, int keyGroupId) {
// 线性映射:[0, maxParallelism) → [0, parallelism)
return keyGroupId * parallelism / maxParallelism;
}
}九、故障恢复完整流程
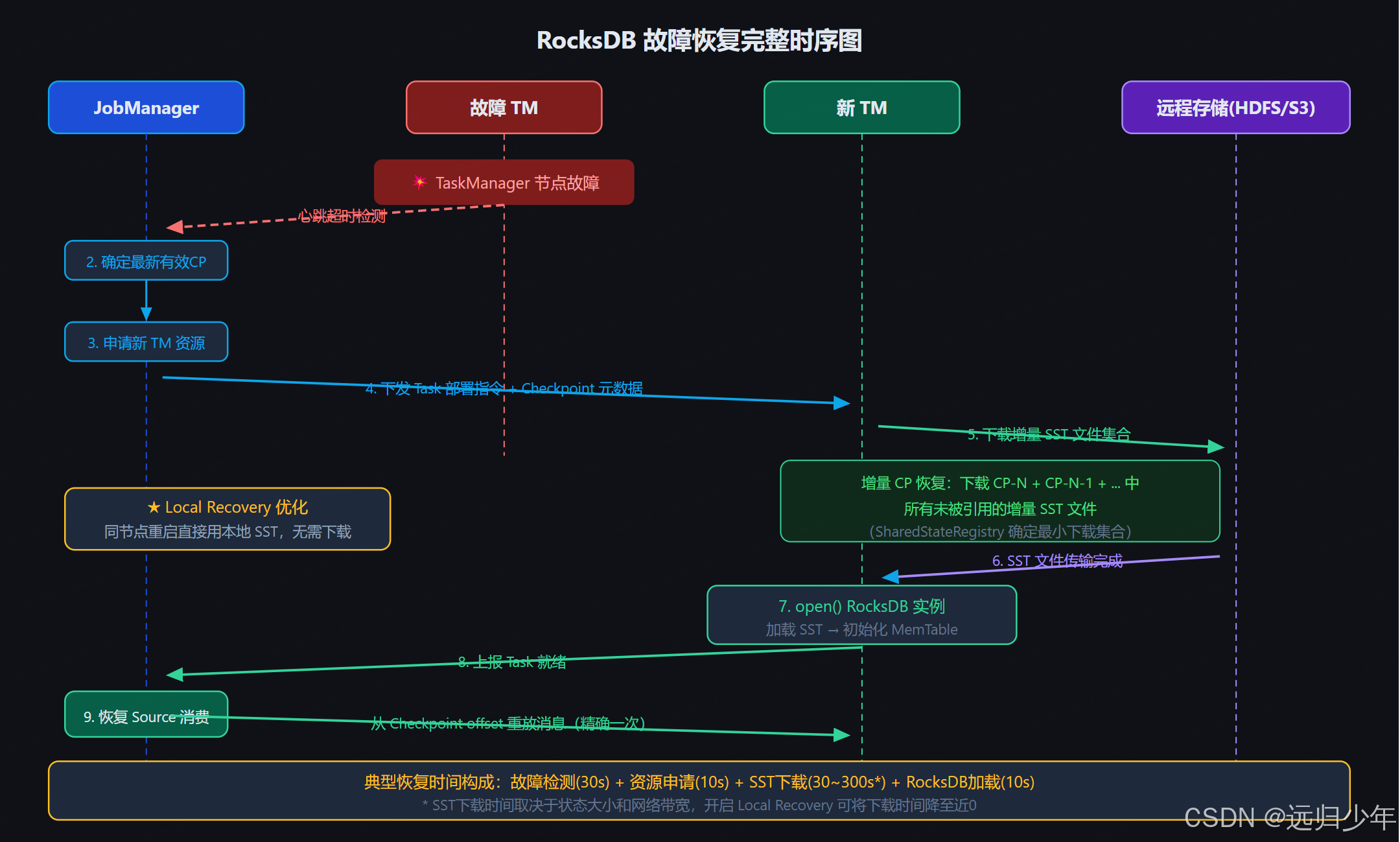
十、常见问题与排查手册
10.1 Checkpoint 超时:最高频故障场景
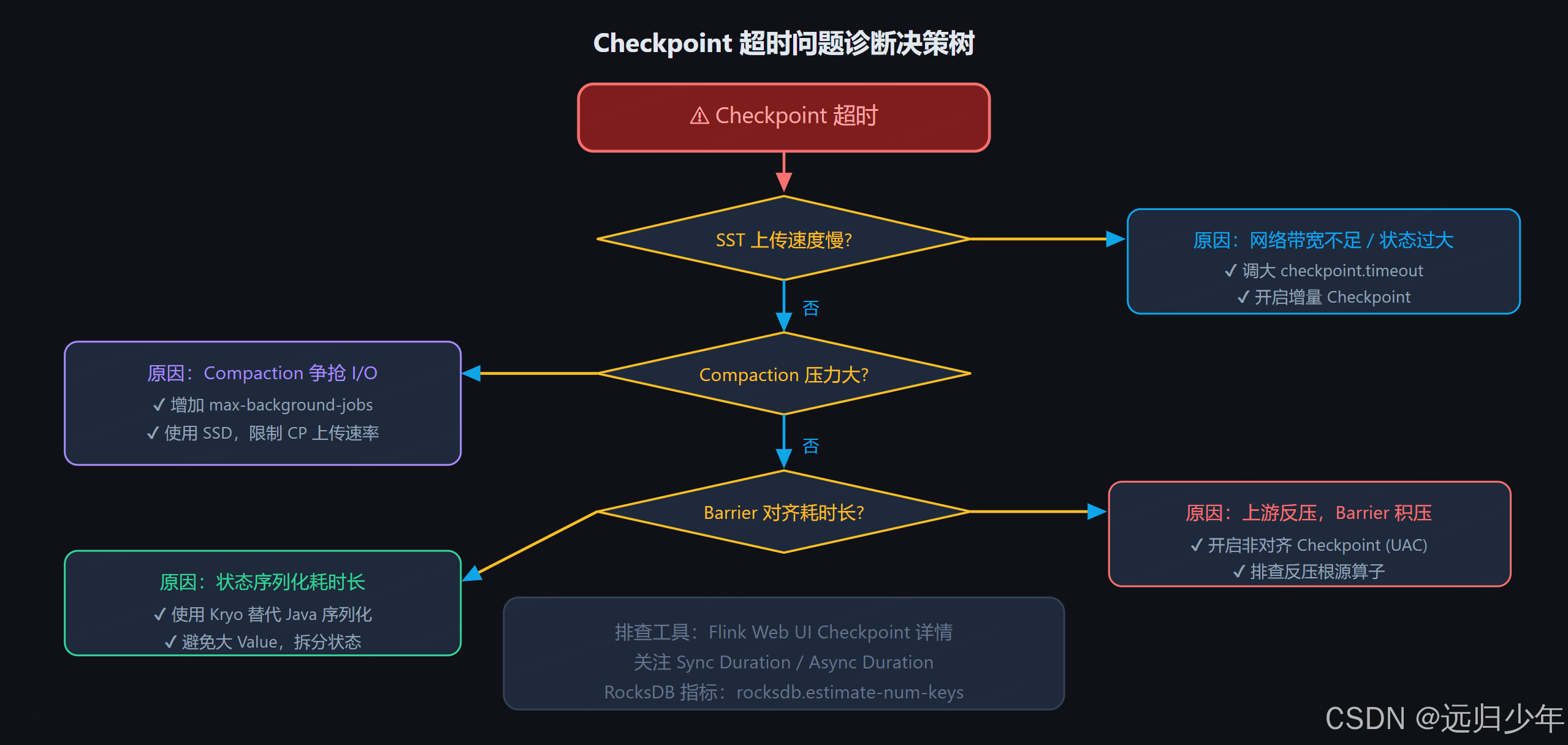
10.2 常见问题排查速查表
| 问题现象 | 根本原因 | 排查命令/指标 | 解决方案 |
|---|---|---|---|
| Checkpoint 持续超时 | 状态过大 + 全量快照 | Flink UI → Checkpoint → Sync/Async Duration | 启用增量 CP,调大 timeout |
| TM OOM(堆外) | BlockCache 过大 / 托管内存不足 | jmap -histo / TM 日志 OOM |
降低 block.cache-size,开启 memory.managed |
| 读延迟突刺(P99高) | Compaction 期间 I/O 争抢 | rocksdb.compaction.pending 指标 |
限制 Compaction 速率,使用 NVMe SSD |
| 状态恢复极慢 | 增量 CP 链过长 | Checkpoint 历史文件数 | 定期全量 Savepoint,控制 retained-checkpoints |
| 写入反压 | MemTable 写满速度 > Flush 速度 | rocksdb.write.stall.duration |
增加 writebuffer.count,提升 max-background-jobs |
| 磁盘空间持续增长 | Compaction 滞后,过期数据未清理 | du -sh <rocksdb-dir> |
配置 TTL,检查 Compaction 线程是否阻塞 |
| 任务重启后状态不一致 | 非对齐 CP + Exactly-Once 配置错误 | Source offset 与 State 版本比对 | 核查 processing-guarantee 配置 |
10.3 监控指标体系
java
// Flink RocksDB 关键监控指标(通过 MetricGroup 暴露至 Prometheus)
// 指标前缀:<host>.<job>.<operator>.rocksdb.*
// ① 状态大小类
rocksdb.cur-size-all-mem-tables // 当前所有 MemTable 占用内存 (bytes)
rocksdb.estimate-num-keys // 估算 Key 数量(近似值)
rocksdb.total-sst-files-size // 所有 SST 文件总大小
// ② 写入性能类
rocksdb.write-bytes // 写入字节数(累计)
rocksdb.write.stall.duration // 写停顿时长(Compaction 触发限速时出现)
rocksdb.num-running-flushes // 正在执行的 Flush 数量
rocksdb.compaction.pending // 等待 Compaction 的任务数
// ③ 读取性能类
rocksdb.block.cache.hit // BlockCache 命中次数
rocksdb.block.cache.miss // BlockCache 未命中次数
rocksdb.bloom.filter.useful // Bloom Filter 过滤次数(越高越好)
rocksdb.get.hit.l0 / l1 / l2 // 各 Level 命中次数
// ④ Compaction 类
rocksdb.compaction.read.bytes // Compaction 读取字节
rocksdb.compaction.write.bytes // Compaction 写入字节(体现写放大)
rocksdb.num-running-compactions // 正在执行的 Compaction 数量
// ⑤ 磁盘 I/O 类
rocksdb.bytes.read.rate // 磁盘读速率
rocksdb.bytes.written.rate // 磁盘写速率十一、最佳实践总结

十二、完整代码示例:端到端大状态作业
以下是一个生产级完整示例,涵盖 RocksDB 配置、状态声明、TTL 设置、监控埋点全链路:
java
package com.example.flink.largestate;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.*;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.contrib.streaming.state.EmbeddedRocksDBStateBackend;
import org.apache.flink.contrib.streaming.state.RocksDBOptionsFactory;
import org.apache.flink.metrics.Counter;
import org.apache.flink.metrics.Meter;
import org.apache.flink.metrics.MeterView;
import org.apache.flink.runtime.state.storage.FileSystemCheckpointStorage;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import org.rocksdb.*;
import java.util.Arrays;
import java.util.Collection;
/**
* 生产级 RocksDB 大状态 Flink 作业示例
*
* 场景:实时用户行为画像聚合(TB 级状态)
* - 统计每个用户各维度的行为次数(MapState)
* - 维护最近 N 次事件序列(ListState)
* - 记录用户首次/末次活跃时间(ValueState)
* - 状态 TTL:7 天自动过期清理
*/
public class LargeStateRocksDBJob {
// ─────────────────────────────────────────────
// 1. 环境初始化 + RocksDB 配置
// ─────────────────────────────────────────────
public static StreamExecutionEnvironment buildEnvironment() throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// ① 构建 RocksDB State Backend
EmbeddedRocksDBStateBackend rocksDBBackend =
new EmbeddedRocksDBStateBackend(true); // true = 增量 Checkpoint
// ② 自定义底层 RocksDB 参数(精细化调优)
rocksDBBackend.setRocksDBOptions(new ProductionRocksDBOptionsFactory());
// ③ 注入 State Backend
env.setStateBackend(rocksDBBackend);
// ④ Checkpoint 存储配置
env.getCheckpointConfig().setCheckpointStorage(
new FileSystemCheckpointStorage("hdfs:///flink/checkpoints/user-profile")
);
// ⑤ Checkpoint 策略配置
env.enableCheckpointing(120_000L, CheckpointingMode.EXACTLY_ONCE);
CheckpointConfig cpConfig = env.getCheckpointConfig();
cpConfig.setMinPauseBetweenCheckpoints(60_000L); // 两次 CP 最小间隔 60s
cpConfig.setCheckpointTimeout(600_000L); // 超时 10 分钟
cpConfig.setMaxConcurrentCheckpoints(1); // 同时只允许 1 个 CP
cpConfig.setTolerableCheckpointFailureNumber(3); // 允许连续 3 次失败
// 取消任务后保留最近 3 个 Checkpoint(便于手动恢复)
cpConfig.setExternalizedCheckpointCleanup(
CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
return env;
}
// ─────────────────────────────────────────────
// 2. RocksDB 底层参数工厂(生产调优版)
// ─────────────────────────────────────────────
public static class ProductionRocksDBOptionsFactory implements RocksDBOptionsFactory {
@Override
public DBOptions createDBOptions(
DBOptions currentOptions,
Collection<AutoCloseable> handlesToClose) {
return currentOptions
// 后台 Flush + Compaction 线程总数(建议 = CPU核数/2)
.setMaxBackgroundJobs(8)
// 大 SST 文件并行子压缩(减少单次 Compaction 时间)
.setMaxSubcompactions(4)
// 避免 WAL 日志(由 Flink Checkpoint 保证一致性)
.setAvoidUnnecessaryBlockingIO(true)
// 日志级别(生产环境用 WARN,避免日志过多)
.setInfoLogLevel(InfoLogLevel.WARN_LEVEL)
// 统计信息采集(接入 Prometheus 监控时开启)
.setStatsDumpPeriodSec(60);
}
@Override
public ColumnFamilyOptions createColumnOptions(
ColumnFamilyOptions currentOptions,
Collection<AutoCloseable> handlesToClose) {
// ① BlockBasedTable 配置(SST 文件读取优化)
LRUCache blockCache = new LRUCache(
512 * 1024 * 1024L, // 512MB BlockCache(每个 TM slot)
8, // shard_bits:8 → 256 个分片(减少锁竞争)
false, // strict_capacity_limit
0.1 // high_pri_pool_ratio:10% 给 index/filter
);
handlesToClose.add(blockCache);
BloomFilter bloomFilter = new BloomFilter(10, false);
handlesToClose.add(bloomFilter);
BlockBasedTableConfig tableConfig = new BlockBasedTableConfig()
.setBlockCache(blockCache)
.setBlockSize(32 * 1024L) // 32KB Block
.setFilterPolicy(bloomFilter) // Bloom Filter
.setCacheIndexAndFilterBlocks(true) // index/filter 常驻 cache
.setPinL0FilterAndIndexBlocksInCache(true) // L0 文件优先固定
.setDataBlockIndexType(
DataBlockIndexType.kDataBlockBinaryAndHash); // 二分+哈希索引
return currentOptions
.setTableFormatConfig(tableConfig)
// ② MemTable 配置
.setWriteBufferSize(128 * 1024 * 1024L) // 128MB
.setMaxWriteBufferNumber(4) // 最多 4 个 MemTable
.setMinWriteBufferNumberToMerge(2) // 至少 2 个才 Flush
// ③ 压缩算法(LZ4 速度最快,底层用 ZSTD 压缩率更高)
.setCompressionType(CompressionType.LZ4_COMPRESSION)
.setBottommostCompressionType(CompressionType.ZSTD_COMPRESSION)
// ④ Level Compaction 配置
.setCompactionStyle(CompactionStyle.LEVEL)
.setLevelCompactionDynamicLevelBytes(true) // 动态 Level 大小
.setMaxBytesForLevelBase(256 * 1024 * 1024L) // L1 上限 256MB
.setTargetFileSizeBase(64 * 1024 * 1024L) // SST 目标大小 64MB
// ⑤ Compaction 触发阈值(防止 L0 文件堆积导致写停顿)
.setLevel0FileNumCompactionTrigger(4)
.setLevel0SlowdownWritesTrigger(20)
.setLevel0StopWritesTrigger(36);
}
}
// ─────────────────────────────────────────────
// 3. 核心状态算子(用户画像聚合)
// ─────────────────────────────────────────────
public static class UserProfileAggregator
extends RichFlatMapFunction<UserEvent, UserProfile> {
// --- 状态声明 ---
/** 各维度行为计数:dimension → count */
private transient MapState<String, Long> dimensionCountState;
/** 最近 20 次事件序列(用于实时特征提取)*/
private transient ListState<String> recentEventsState;
/** 用户首次活跃时间戳 */
private transient ValueState<Long> firstActiveState;
/** 用户末次活跃时间戳 */
private transient ValueState<Long> lastActiveState;
/** 会话累计时长(秒)*/
private transient ValueState<Double> totalDurationState;
// --- 监控指标 ---
private transient Counter processedCounter;
private transient Counter stateReadCounter;
private transient Counter stateWriteCounter;
private transient Meter throughputMeter;
private static final int MAX_RECENT_EVENTS = 20;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// ① 定义公共 TTL 配置(7 天后自动清除过期状态)
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.days(7))
// 读取时刷新 TTL(用户每次访问都延续 7 天)
.setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite)
// 读取时返回已过期状态(false = 不返回,直接视为 null)
.setStateVisibility(
StateTtlConfig.StateVisibility.NeverReturnExpired)
// 后台 Compaction 时清理(不影响正常读写路径)
.cleanupInRocksdbCompactFilter(1000)
.build();
// ② 注册各状态(每个状态对应 RocksDB 一个 Column Family)
MapStateDescriptor<String, Long> dimCountDesc =
new MapStateDescriptor<>("dim-count", Types.STRING, Types.LONG);
dimCountDesc.enableTimeToLive(ttlConfig);
dimensionCountState = getRuntimeContext().getMapState(dimCountDesc);
ListStateDescriptor<String> recentEventsDesc =
new ListStateDescriptor<>("recent-events", Types.STRING);
recentEventsDesc.enableTimeToLive(ttlConfig);
recentEventsState = getRuntimeContext().getListState(recentEventsDesc);
ValueStateDescriptor<Long> firstActiveDesc =
new ValueStateDescriptor<>("first-active", Types.LONG);
firstActiveDesc.enableTimeToLive(ttlConfig);
firstActiveState = getRuntimeContext().getState(firstActiveDesc);
ValueStateDescriptor<Long> lastActiveDesc =
new ValueStateDescriptor<>("last-active", Types.LONG);
lastActiveDesc.enableTimeToLive(ttlConfig);
lastActiveState = getRuntimeContext().getState(lastActiveDesc);
ValueStateDescriptor<Double> totalDurDesc =
new ValueStateDescriptor<>("total-duration", Types.DOUBLE);
totalDurDesc.enableTimeToLive(ttlConfig);
totalDurationState = getRuntimeContext().getState(totalDurDesc);
// ③ 注册监控指标
processedCounter = getRuntimeContext()
.getMetricGroup()
.addGroup("userProfile")
.counter("processedEvents");
stateReadCounter = getRuntimeContext()
.getMetricGroup()
.addGroup("userProfile")
.counter("stateReads");
stateWriteCounter = getRuntimeContext()
.getMetricGroup()
.addGroup("userProfile")
.counter("stateWrites");
throughputMeter = getRuntimeContext()
.getMetricGroup()
.addGroup("userProfile")
.meter("throughput", new MeterView(processedCounter, 60));
}
@Override
public void flatMap(UserEvent event, Collector<UserProfile> out)
throws Exception {
processedCounter.inc();
long now = event.getTimestamp();
// ─── 读取状态 ───────────────────────────────
stateReadCounter.inc(4);
Long firstActive = firstActiveState.value(); // RocksDB 读
Long lastActive = lastActiveState.value(); // RocksDB 读
Double totalDur = totalDurationState.value(); // RocksDB 读
Long dimCount = dimensionCountState.get( // RocksDB 读(MapState)
event.getDimension());
// ─── 业务逻辑 ────────────────────────────────
if (firstActive == null) {
firstActive = now;
}
lastActive = now;
totalDur = (totalDur == null ? 0.0 : totalDur) + event.getDuration();
dimCount = (dimCount == null ? 0L : dimCount) + 1L;
// 维护最近 N 次事件(需控制 ListState 大小,防止无限增长)
recentEventsState.add(event.getEventType());
// 定期裁剪 ListState(避免 RocksDB 中 Value 过大)
if (dimCount % 100 == 0) {
trimRecentEvents();
}
// ─── 写回状态 ───────────────────────────────
stateWriteCounter.inc(4);
firstActiveState.update(firstActive); // RocksDB 写
lastActiveState.update(lastActive); // RocksDB 写
totalDurationState.update(totalDur); // RocksDB 写
dimensionCountState.put( // RocksDB 写
event.getDimension(), dimCount);
// ─── 输出结果(按需触发,非每条输出)──────────
if (shouldEmit(dimCount)) {
out.collect(buildProfile(event.getUserId(),
firstActive, lastActive, totalDur));
}
}
/** 裁剪 recentEvents,只保留最后 MAX_RECENT_EVENTS 条 */
private void trimRecentEvents() throws Exception {
java.util.List<String> events = new java.util.ArrayList<>();
for (String e : recentEventsState.get()) {
events.add(e);
}
if (events.size() > MAX_RECENT_EVENTS) {
recentEventsState.update(
events.subList(events.size() - MAX_RECENT_EVENTS, events.size())
);
}
}
private boolean shouldEmit(long count) {
// 每 50 次事件输出一次画像快照
return count % 50 == 0;
}
private UserProfile buildProfile(String userId,
long firstActive,
long lastActive,
double totalDuration) {
return new UserProfile(userId, firstActive, lastActive, totalDuration);
}
}
// ─────────────────────────────────────────────
// 4. 主作业入口
// ─────────────────────────────────────────────
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = buildEnvironment();
env.setParallelism(32); // 32 并行度,支撑 TB 级状态
// 数据源(Kafka)
DataStream<UserEvent> sourceStream = env
.addSource(buildKafkaSource())
.name("kafka-user-events")
.uid("source-kafka"); // uid 必须设置,Savepoint 恢复依赖
// 核心聚合算子
DataStream<UserProfile> profileStream = sourceStream
.keyBy(UserEvent::getUserId) // 按用户 ID 分区
.flatMap(new UserProfileAggregator())
.name("user-profile-aggregator")
.uid("agg-user-profile"); // uid 固定,变更并行度时状态可迁移
// 输出到下游
profileStream
.addSink(buildHBaseSink())
.name("hbase-profile-sink")
.uid("sink-hbase");
env.execute("User Profile Large State Job - RocksDB");
}
// 占位方法(实际项目中替换为真实实现)
private static org.apache.flink.streaming.api.functions.source.SourceFunction<UserEvent>
buildKafkaSource() { return null; }
private static org.apache.flink.streaming.api.functions.sink.SinkFunction<UserProfile>
buildHBaseSink() { return null; }
}
java
// ─── 数据模型 ──────────────────────────────────────────────────
/** 用户行为事件 */
class UserEvent {
private String userId;
private String eventType;
private String dimension; // 行为维度(如 page_view / add_cart / purchase)
private double duration; // 本次会话时长(秒)
private long timestamp;
// getters / setters / constructors omitted
public String getUserId() { return userId; }
public String getEventType() { return eventType; }
public String getDimension() { return dimension; }
public double getDuration() { return duration; }
public long getTimestamp() { return timestamp; }
}
/** 用户画像快照 */
class UserProfile {
private String userId;
private long firstActiveTs;
private long lastActiveTs;
private double totalDuration;
public UserProfile(String userId, long first, long last, double dur) {
this.userId = userId;
this.firstActiveTs = first;
this.lastActiveTs = last;
this.totalDuration = dur;
}
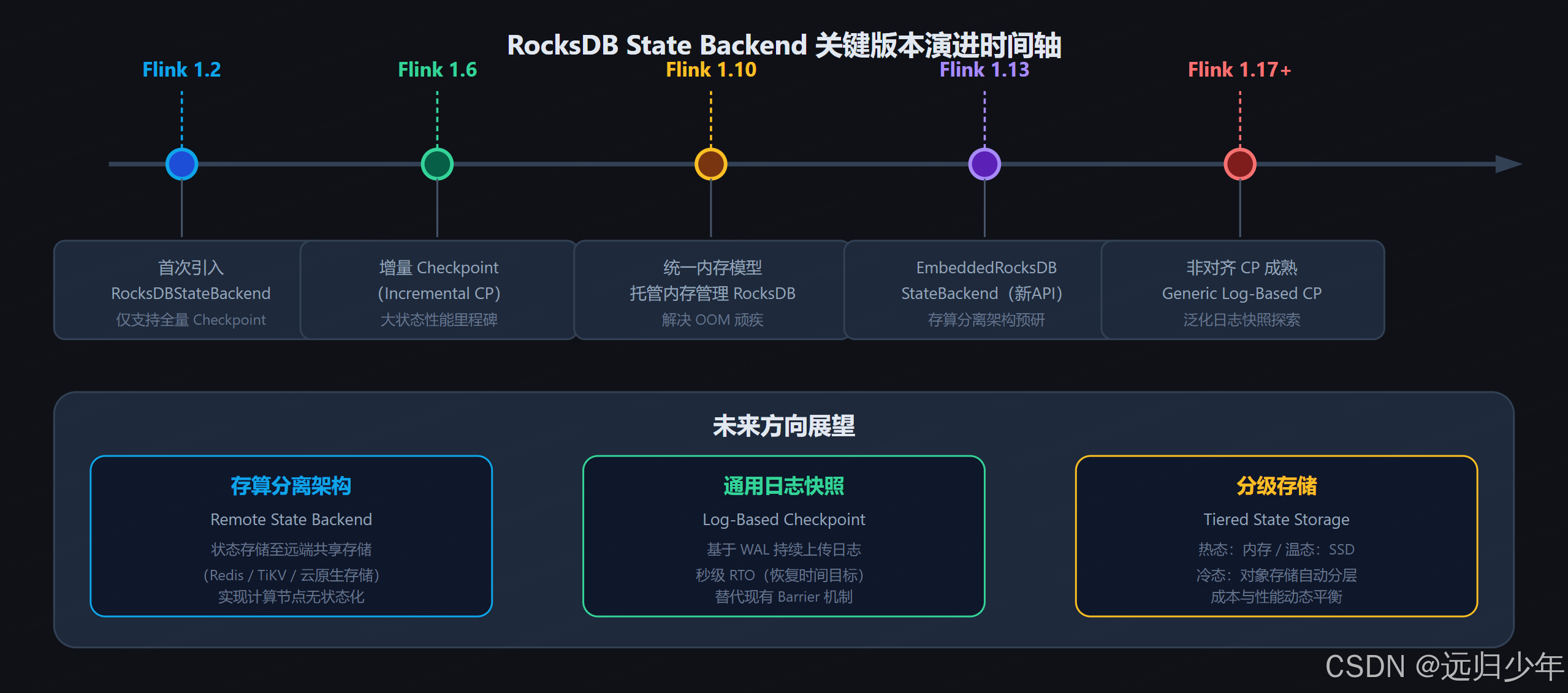
}十三、版本演进与未来展望
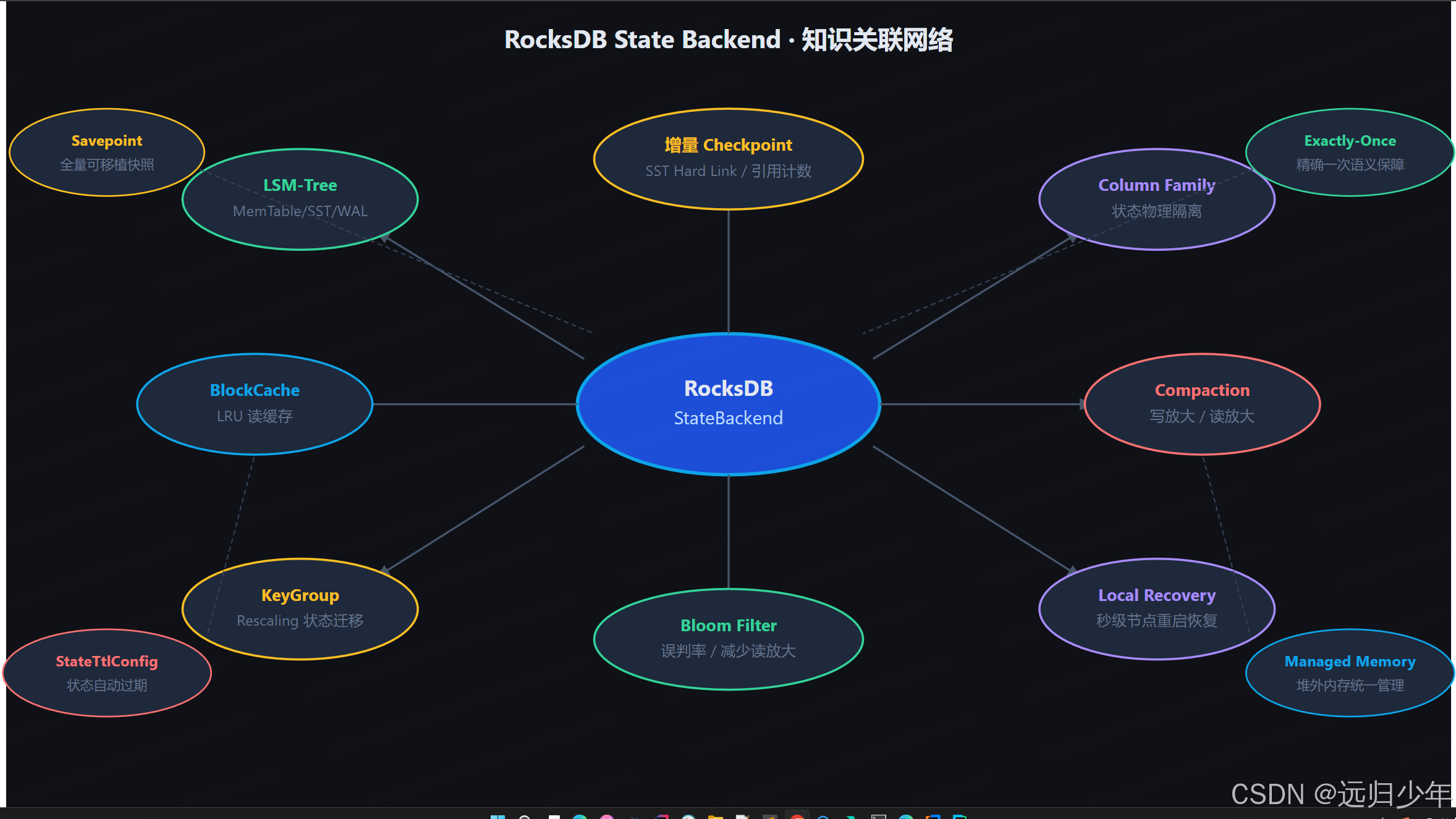
十四、核心知识网络图
十五、一句话总结
Apache Flink 的 RocksDB State Backend,是以 LSM-Tree 为核心存储结构、以增量 Checkpoint 为容错机制、以 Column Family 为状态隔离单元、以托管内存为资源边界的堆外大状态引擎------它突破了 JVM 堆内存的物理上限,将 Flink 流处理作业的状态承载能力从 GB 级拓展至 TB 级,是生产环境超大状态任务的首选也是事实标准。
参考资料索引
| 类型 | 资源 | 说明 |
|---|---|---|
| 官方文档 | Flink State Backends | 最权威配置参考 |
| 官方文档 | RocksDB Tuning Guide | RocksDB 官方调优指南 |
| 源码 | EmbeddedRocksDBStateBackend.java |
Flink 源码:状态后端实现入口 |
| 源码 | RocksDBKeyedStateBackend.java |
Checkpoint 与状态注册核心逻辑 |
| 论文 | The Log-Structured Merge-Tree (LSM-Tree) | LSM-Tree 原始论文 |
| FLIP | FLIP-158: Generalized Log-Based Checkpoint | 通用日志快照设计文档 |
| FLIP | FLIP-119: Pipelined Region Scheduling | 与状态恢复相关的调度优化 |