文章目录
-
- 每日一句正能量
- 一、时序数据爆发:从边缘到云端的数据革命
- 二、时序数据库选型的五大核心维度
-
- [2.1 写入性能:大数据入口的第一道关卡](#2.1 写入性能:大数据入口的第一道关卡)
- [2.2 存储效率:成本控制的关键](#2.2 存储效率:成本控制的关键)
- [2.3 查询性能:从监控到分析的全场景覆盖](#2.3 查询性能:从监控到分析的全场景覆盖)
- [2.4 生态兼容性:融入大数据技术栈](#2.4 生态兼容性:融入大数据技术栈)
- [2.5 部署灵活性:从边缘到云的全场景适配](#2.5 部署灵活性:从边缘到云的全场景适配)
- 三、国外主流时序数据库的局限性分析
-
- [3.1 InfluxDB:开源版的"功能天花板"](#3.1 InfluxDB:开源版的"功能天花板")
- [3.2 TimescaleDB:PostgreSQL 的"双刃剑"](#3.2 TimescaleDB:PostgreSQL 的"双刃剑")
- [3.3 Prometheus:监控专用,非通用时序数据库](#3.3 Prometheus:监控专用,非通用时序数据库)
- [四、Apache IoTDB:面向大数据场景的"中国方案"](#四、Apache IoTDB:面向大数据场景的"中国方案")
-
- [4.1 极致性能:重新定义时序数据处理能力](#4.1 极致性能:重新定义时序数据处理能力)
-
- 写入性能:千万级吞吐的硬核实力
- 查询性能:从毫秒到秒级的全场景覆盖
- [存储效率:20:1 压缩比的降本利器](#存储效率:20:1 压缩比的降本利器)
- [4.2 端边云协同:全场景部署的架构创新](#4.2 端边云协同:全场景部署的架构创新)
- [4.3 大数据生态无缝集成:打破数据孤岛](#4.3 大数据生态无缝集成:打破数据孤岛)
-
- [与 Apache Flink 集成:实时流处理](#与 Apache Flink 集成:实时流处理)
- [与 Apache Spark 集成:离线分析与机器学习](#与 Apache Spark 集成:离线分析与机器学习)
- [与 Grafana 集成:可视化监控](#与 Grafana 集成:可视化监控)
- [4.4 工业级数据模型:贴合物理世界的树形架构](#4.4 工业级数据模型:贴合物理世界的树形架构)
- [4.5 开源开放与国产化适配](#4.5 开源开放与国产化适配)
- [五、实战指南:10 分钟快速体验 IoTDB](#五、实战指南:10 分钟快速体验 IoTDB)
-
- [5.1 环境准备与安装](#5.1 环境准备与安装)
- [5.2 核心功能演示](#5.2 核心功能演示)
- [5.3 性能测试建议](#5.3 性能测试建议)
- 六、场景化选型建议
- 七、结语:时序数据库选型的未来趋势

每日一句正能量
希望我们都成为那种,即使再孤单,生活再坎坷,不管天晴天阴,不管有无人爱,都会眷恋着夕阳和晨光,捕捉生活美好瞬间的人。
一、时序数据爆发:从边缘到云端的数据革命
在数字化转型浪潮中,时序数据已成为企业最核心的数字资产之一。所谓时序数据,即按时间顺序记录的数据点,广泛存在于工业传感器、金融交易、能源监控、车联网等场景。据 IDC 预测,到 2025 年,全球物联网设备产生的时序数据将占企业数据总量的 30% 以上,年复合增长率超过 28%。
以智能制造为例,一条现代化汽车生产线可能部署超过 10,000 个传感器,每秒产生数百万个数据点。这些数据不仅用于实时监控,更承载着设备预测性维护、工艺优化、质量追溯等关键业务价值。然而,传统关系型数据库(如 MySQL、PostgreSQL)在面对如此高频写入和海量存储时,往往面临写入瓶颈、查询延迟高、存储成本激增等困境。
这正是时序数据库(Time-Series Database, TSDB)诞生的背景------专为时间序列数据优化的存储引擎,通过列式存储、时间分区、专用压缩算法等技术,实现高吞吐写入、低延迟查询和极致存储效率。本文将从大数据架构视角,深度剖析时序数据库选型关键维度,并重点解读 Apache IoTDB 的技术优势与实战价值。
二、时序数据库选型的五大核心维度

2.1 写入性能:大数据入口的第一道关卡
时序数据库的首要任务是应对"数据洪流"。工业物联网场景下,单系统往往需要支持每秒数百万甚至千万级的数据点写入。评估写入性能时,需关注以下指标:
- 峰值吞吐量:单节点与集群模式下的最大写入能力
- 乱序数据处理能力:工业现场网络抖动导致的数据时序错乱容忍度
- 批量写入优化 :是否支持高效的批量提交接口,降低网络开销

2.2 存储效率:成本控制的关键
时序数据具有"写多读少、总量巨大"的特点,存储成本直接影响项目 ROI。核心评估点包括:
- 压缩算法:是否针对时序数据特征(数值缓慢变化、时间戳连续性)设计专用编码
- 冷热分层:是否支持自动将历史数据迁移至廉价存储(如 HDFS、S3)
- 生命周期管理:自动过期数据清理(TTL)的灵活性与性能损耗
2.3 查询性能:从监控到分析的全场景覆盖
时序查询场景多样,需平衡实时性与分析深度:
- 实时监控:最新值查询、阈值告警的毫秒级响应
- 历史分析:时间范围聚合、降采样查询的效率
- 复杂分析:多设备关联查询、模式匹配、异常检测的支持程度
2.4 生态兼容性:融入大数据技术栈
现代企业数据架构依赖 Hadoop、Spark、Flink 等大数据生态,时序数据库需提供:
- 标准接口:JDBC/ODBC、REST API、MQTT 等协议支持
- 流批一体:与 Flink 的实时流处理集成,与 Spark 的离线分析集成
- 可视化对接:Grafana、Tableau 等 BI 工具的原生支持
2.5 部署灵活性:从边缘到云的全场景适配
工业场景部署环境复杂,需支持:
- 端侧部署:轻量化嵌入式版本,运行在资源受限设备(ARM 架构、MB 级内存)
- 边缘计算:边缘节点本地自治与云端协同
- 云原生:Kubernetes 容器化编排、弹性扩缩容
三、国外主流时序数据库的局限性分析
在国际市场,InfluxDB、TimescaleDB、Prometheus 等产品占据一定份额,但在大数据场景下均存在明显局限:

3.1 InfluxDB:开源版的"功能天花板"
InfluxDB 是时序数据库领域的先行者,在监控场景有广泛应用。但其开源版(OSS)存在显著限制:
- 集群功能缺失:开源版仅支持单节点,高可用与水平扩展需购买昂贵的 Enterprise 版(每节点年费超过 5,000 美元)
- 写入性能瓶颈:在高基数(High Cardinality)场景下(如数万设备、百万级时间序列),写入性能急剧下降
- 存储压缩一般:默认压缩比约 8:1~15:1,长周期数据存储成本较高
- 生态封闭:与 Hadoop、Spark 等大数据框架集成需二次开发
3.2 TimescaleDB:PostgreSQL 的"双刃剑"
TimescaleDB 基于 PostgreSQL 扩展,对 SQL 兼容性极佳,但这也带来固有局限:
- 写入性能受限:继承 PostgreSQL 的 MVCC 机制,高频写入时锁竞争严重,实测单机写入吞吐量仅 40-120 万条/秒
- 压缩效率中等:依赖通用压缩算法(LZ4、Zstd),压缩比约 6:1~12:1,低于专用时序存储引擎
- 架构复杂度高:需维护 PostgreSQL 主从复制、分片等,运维成本较高
3.3 Prometheus:监控专用,非通用时序数据库
Prometheus 是云原生监控的事实标准,但设计定位决定了其局限性:
- 存储能力薄弱:默认仅保留 15 天数据,长周期存储需依赖 Thanos、Cortex 等复杂外挂方案
- 写入性能一般:单机写入吞吐量 30-80 万条/秒,不适合海量物联网设备接入
- 查询能力有限:PromQL 仅适合简单聚合,不支持复杂分析查询
四、Apache IoTDB:面向大数据场景的"中国方案"
Apache IoTDB 是由清华大学自主研发、捐献给 Apache 软件基金会的顶级开源项目,自 2020 年毕业成为 Apache Top-Level Project 以来,已成为全球时序数据库领域的重要力量。其设计初衷即面向工业物联网大数据场景,在性能、成本、生态等维度实现全面突破。
4.1 极致性能:重新定义时序数据处理能力
写入性能:千万级吞吐的硬核实力
IoTDB 采用 LSM-Tree(日志结构合并树)变体架构,结合内存缓冲区(MemTable)与专用 TsFile 存储格式,将随机写转换为顺序写。实测数据显示:
- 单机写入吞吐量:可达 150-500 万点/秒,是 InfluxDB 的 3-7 倍
- 集群扩展能力:线性扩展至千万级点/秒,轻松应对 5000 万+ 测点接入需求
- 乱序数据容忍:支持 5 分钟内的数据时序错乱,自动排序归并,无需人工干预
在 TPCx-IoT(工业物联网国际权威性能测试)中,IoTDB 写入性能达到 363 万点/秒,远超 InfluxDB 的 52 万点/秒和 TimescaleDB 的 15 万点/秒 。
查询性能:从毫秒到秒级的全场景覆盖
IoTDB 采用时间分区索引与设备前缀索引双层索引机制:
- 实时监控查询:最新值查询延迟 < 5ms,满足产线实时监控需求
- 历史聚合查询:10 亿级数据量的时间范围聚合,P99 延迟控制在 50ms 内
- 复杂分析支持:支持 SQL 标准语法与专用时序扩展(如降采样、插值、模式匹配)
存储效率:20:1 压缩比的降本利器
IoTDB 针对时序数据特征设计多级压缩策略:
| 数据类型 | 压缩技术 | 压缩效果 | 技术原理 |
|---|---|---|---|
| 时间戳 | Delta + Zigzag 编码 | 20:1 | 利用时间序列的单调性和连续性 |
| 浮点数值 | Gorilla + 自适应精度 | 12:1 | 基于前值的 XOR 差分编码 |
| 整型数据 | RLE + 位级打包 | 15:1 | 游程编码结合位级压缩 |
| 布尔状态 | 位图 + 稀疏编码 | 64:1 | 位级存储配合稀疏数据优化 |
实际案例显示,某风电企业采用 IoTDB 后,3 年历史数据存储成本从 4800 万元降至 240 万元,压缩比达到惊人的 20:1 。
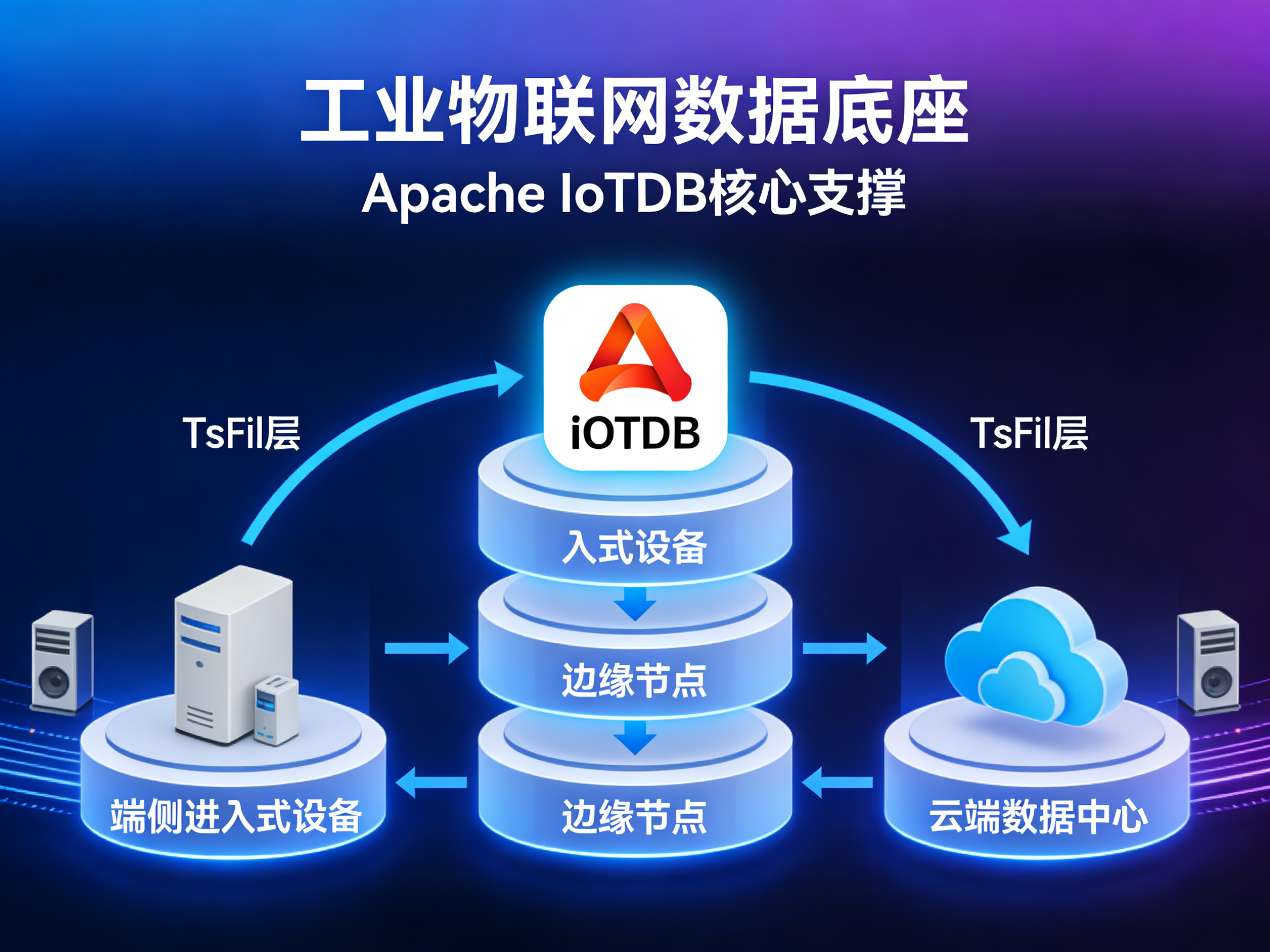
4.2 端边云协同:全场景部署的架构创新
IoTDB 1.3 版本完成了架构重构,构建了可组装的"端边云"协同数据架构,以自主研发的 TsFile 时序文件格式为基础,支撑三大核心组件 :
- IoT Node(端侧):面向嵌入式设备的轻量化存储引擎,仅需 2MB 内存即可实现 200 万点/秒写入,支持 SylixOS 等实时操作系统
- Data Node(边缘/云端):高性能时序数据管理引擎,支持分布式集群与水平扩展
- AI Node(智能分析):内置机器学习训练推理能力,支持异常检测、时序预测等 AI 任务
这种架构实现了数据在端、边、云之间的自由流转:端侧负责实时采集与本地自治,边缘侧进行数据汇聚与初步分析,云端支撑长期存储与深度挖掘。数据通过 TsFile 格式批量压缩传输,可减少 90% 网络带宽消耗,完美解决弱网环境下的数据同步难题 。
4.3 大数据生态无缝集成:打破数据孤岛
IoTDB 从设计之初即注重与大数据生态的融合,提供完整的连接器生态:
与 Apache Flink 集成:实时流处理
sql
-- 在 Flink SQL Client 中注册 IoTDB 表
CREATE TABLE iotdb_sensor (
device STRING,
time TIMESTAMP(3),
temperature FLOAT,
pressure FLOAT,
WATERMARK FOR time AS time - INTERVAL '5' SECOND
) WITH (
'connector' = 'iotdb',
'url' = 'jdbc:iotdb://127.0.0.1:6667/',
'user' = 'root',
'password' = 'root',
'sql' = 'select device, time, temperature, pressure from root.factory.line1.device001'
);
-- 实时计算温度超过 28℃ 的异常数据
SELECT device, time, temperature
FROM iotdb_sensor
WHERE temperature > 28;与 Apache Spark 集成:离线分析与机器学习
scala
// 读取 IoTDB 数据创建 DataFrame
val iotdbDF = spark.read
.format("org.apache.iotdb.spark.db")
.option("url", "jdbc:iotdb://127.0.0.1:6667/")
.option("sql", """
SELECT temperature, pressure, vibration
FROM root.factory.*
WHERE time > now() - 30d
""")
.load()
// 使用 Spark ML 进行设备故障预测
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.ml.clustering.KMeans
val assembler = new VectorAssembler()
.setInputCols(Array("temperature", "pressure", "vibration"))
.setOutputCol("features")
val assembledData = assembler.transform(iotdbDF)
val kmeans = new KMeans().setK(3).setSeed(1L)
val model = kmeans.fit(assembledData)
// 保存预测结果回 IoTDB
model.transform(assembledData)
.filter($"prediction" === 2) // 异常簇
.select($"timestamp", $"temperature", $"prediction")
.write
.format("org.apache.iotdb.spark.db")
.option("url", "jdbc:iotdb://127.0.0.1:6667/")
.option("device", "root.factory.anomaly")
.save()与 Grafana 集成:可视化监控
IoTDB 提供原生 Grafana 数据源插件,支持 30+ 种时序专用图表,可快速构建工业监控大屏:
bash
# 安装 IoTDB 数据源插件
grafana-cli plugins install apache-iotdb-datasource配置完成后,可通过 SQL 直接查询设备数据并生成实时趋势图、热力图、告警面板等。
4.4 工业级数据模型:贴合物理世界的树形架构
与传统时序数据库的扁平表结构不同,IoTDB 创新性地采用树形层级模型组织数据,完美匹配工业设备的物理拓扑:
sql
-- 创建风电场设备模型
CREATE DATABASE root.wind_farm;
CREATE DEVICE TEMPLATE turbine_template
WITH (
wind_speed FLOAT ENCODING=GORILLA,
rotation_speed FLOAT ENCODING=GORILLA,
power_output FLOAT ENCODING=GORILLA,
status INT32 ENCODING=RLE
);
-- 将模板应用到所有风机设备
SET DEVICE TEMPLATE turbine_template TO root.wind_farm.area1.turbine_*;这种模型的优势在于:
- 路径即索引 :设备路径
root.wind_farm.area1.turbine_001.wind_speed天然形成索引,无需额外维护标签索引表 - 层级聚合 :支持
GROUP BY LEVEL语法,一键统计"所有厂区的平均风速"或"各区域的设备在线率" - 模板复用:同类设备共享 Schema 定义,避免"表爆炸"问题,新设备接入时自动继承模板
4.5 开源开放与国产化适配
作为 Apache 顶级项目,IoTDB 完全开源(Apache 2.0 协议),拥有活跃的全球开发者社区。同时,针对中国市场特点,IoTDB 具备独特优势:
- 国产化适配:完整支持龙芯、飞腾、鲲鹏等国产 CPU 架构,与麒麟 OS、统信 UOS 完成兼容认证
- 政策合规:通过等保 2.0 三级认证,满足金融、能源、政务等关键行业的安全合规要求
- 本地化服务:由天谋科技(Timecho)提供企业版商业支持,在全国建立 8 个区域技术支持中心,平均响应时间 < 2 小时
五、实战指南:10 分钟快速体验 IoTDB

5.1 环境准备与安装
IoTDB 支持多种部署方式,以下以单机版为例:
bash
# 下载 IoTDB(最新稳定版 1.3.3)
wget https://dlcdn.apache.org/iotdb/1.3.3/apache-iotdb-1.3.3-all-bin.zip
unzip apache-iotdb-1.3.3-all-bin.zip
cd apache-iotdb-1.3.3-all-bin
# 启动服务
./sbin/start-standalone.sh
# 验证安装
./sbin/start-cli.sh -h 127.0.0.1 -p 6667 -u root -pw root5.2 核心功能演示
sql
-- 1. 创建时间序列(模拟温度传感器)
CREATE TIMESERIES root.factory.line1.device001.temperature WITH DATATYPE=FLOAT, ENCODING=GORILLA;
CREATE TIMESERIES root.factory.line1.device001.pressure WITH DATATYPE=FLOAT, ENCODING=GORILLA;
-- 2. 插入数据(支持批量插入)
INSERT INTO root.factory.line1.device001(time, temperature, pressure)
VALUES (2024-01-01T00:00:00, 25.5, 101.3),
(2024-01-01T00:01:00, 25.8, 101.2),
(2024-01-01T00:02:00, 26.1, 101.4);
-- 3. 实时查询最新值
SELECT LAST temperature, pressure FROM root.factory.line1.device001;
-- 4. 历史数据聚合查询(5 分钟降采样)
SELECT AVG(temperature), MAX(pressure)
FROM root.factory.line1.device001
WHERE time >= 2024-01-01T00:00:00 AND time <= 2024-01-01T01:00:00
GROUP BY ([2024-01-01T00:00:00, 2024-01-01T01:00:00), 5m);
-- 5. 层级聚合(统计所有产线的平均温度)
SELECT AVG(temperature) FROM root.factory.*.* GROUP BY LEVEL=2;5.3 性能测试建议
对于生产环境选型,建议进行以下基准测试:
- 写入压力测试:使用 IoT-Benchmark 工具模拟实际设备数量与采样频率,测试集群最大吞吐
- 查询延迟测试:构造典型查询场景(最新值、范围查询、聚合查询),测量 P99 延迟
- 压缩率测试:导入 1-7 天真实业务数据,对比压缩前后存储占用
- 故障恢复测试:模拟节点宕机,验证数据一致性与恢复时间
六、场景化选型建议
基于前文分析,针对不同业务场景提供选型建议:
| 场景特征 | 推荐方案 | 核心考量 |
|---|---|---|
| 中小规模监控(< 1TB/年,< 1万点/秒) | Prometheus / InfluxDB OSS | 轻量易用,社区生态丰富 |
| 工业物联网中大规模(1-100TB/年,1-10万点/秒) | Apache IoTDB(开源版) | 高性能、高压缩、低成本、生态完善 |
| 关键业务大规模(> 100TB/年,> 10万点/秒) | Timecho(IoTDB 企业版) | 高可用集群、专业运维支持、金融级安全 |
| 云原生监控 | Prometheus + Thanos | K8s 生态原生集成 |
| SQL 重度依赖 | TimescaleDB | PostgreSQL 生态兼容 |
七、结语:时序数据库选型的未来趋势
随着工业 4.0 与数字孪生技术的深入发展,时序数据库正从"数据存储工具"进化为"工业智能底座"。未来的时序数据库需具备:
- AI 原生能力:内置时序预测、异常检测、根因分析等 AI 算法,实现"数据即智能"
- 云边端一体化:无缝覆盖从传感器到云端的全链路数据管理
- 实时分析融合:流处理与批处理的统一,支撑数字孪生的实时仿真
Apache IoTDB 凭借其在性能、架构、生态上的全面优势,已成为中国工业物联网领域的首选时序数据库。无论是开源版的灵活自主,还是企业版的专业保障,IoTDB 都能为企业的数字化转型提供坚实的数据基础设施。
相关资源:
- Apache IoTDB 开源版下载 :https://iotdb.apache.org/zh/Download/
- 企业版官网(Timecho) :https://timecho.com
- 官方文档 :https://iotdb.apache.org/zh/UserGuide/Master/QuickStart/QuickStart.html
- GitHub 仓库 :https://github.com/apache/iotdb
本文基于 Apache IoTDB 1.3.x 版本技术特性撰写,部分性能数据来源于官方 Benchmark 报告与公开案例。技术选型需结合具体业务场景进行 POC 验证。
转载自:<>
欢迎 👍点赞✍评论⭐收藏,欢迎指正