课前小知识
大模型应用落地
专家系统
ai幻觉


一、环境准备
1、模型下载
python
#模型下载
from modelscope import snapshot_download
file = r"F:\26_01\第六期\python\L2_study\L2\day14-大模型微调项目实战-数据工程篇\demo_14\model"
model_dir = snapshot_download('sungw111/text2vec-base-chinese-sentence',cache_dir=file)2、环境安装
python
pip install zhipuai
二、情绪对话模型,实现过程
1、数据来源

2、数据集制作
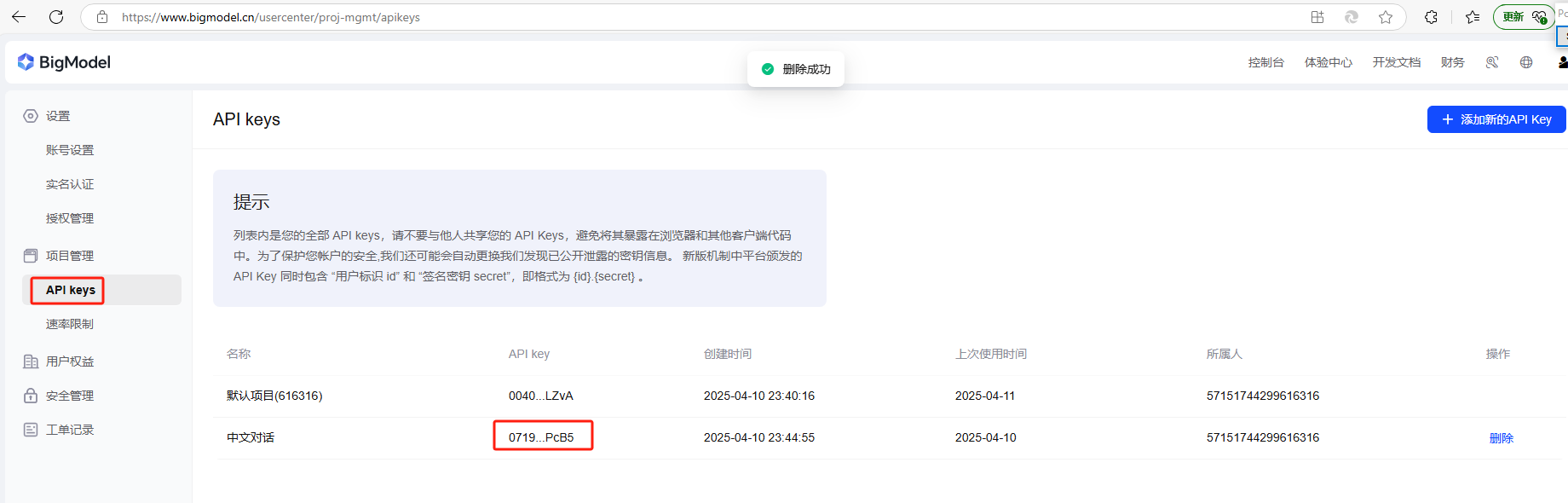
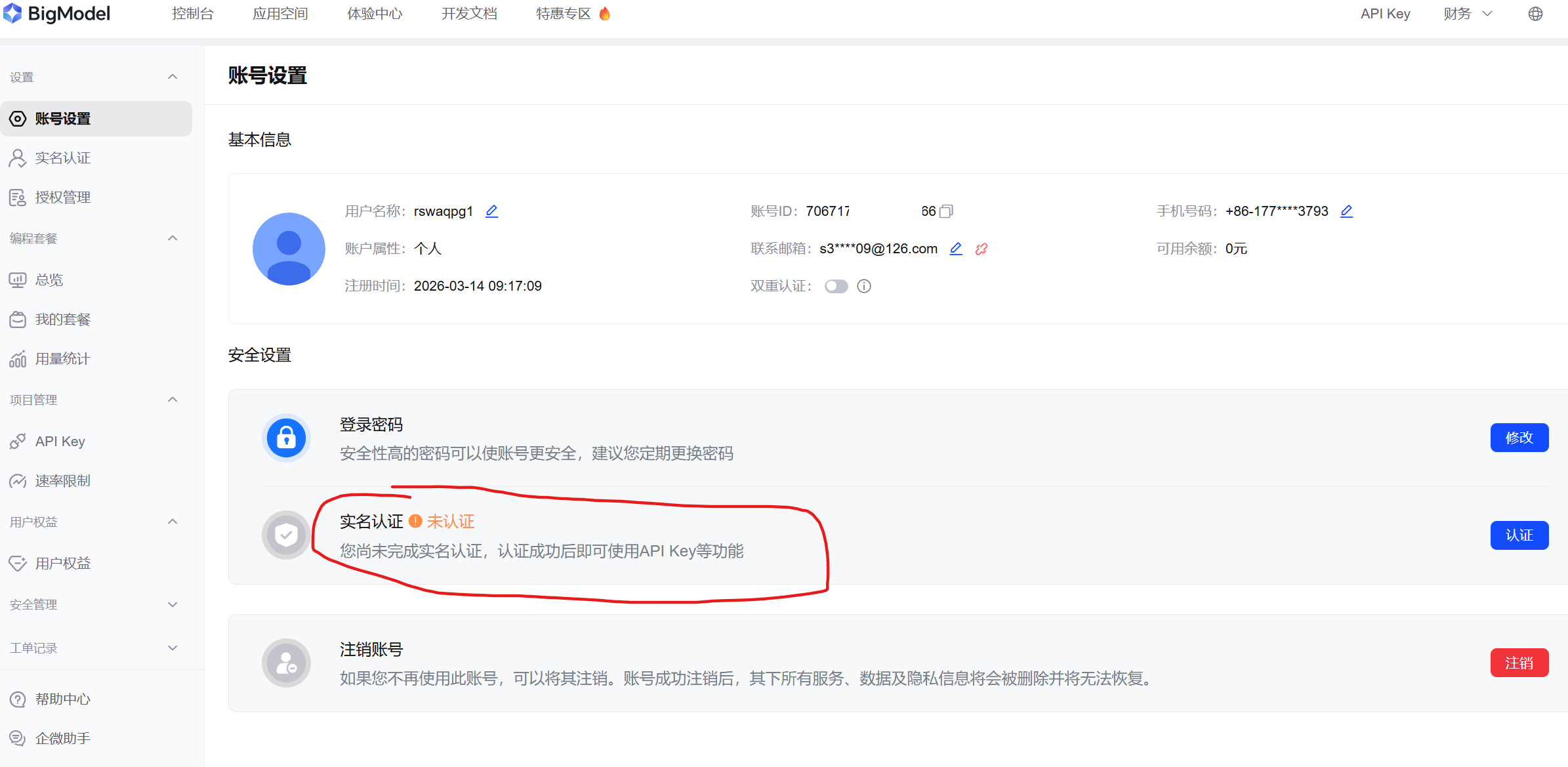
步骤1:注册在线大模型API
此处以智普清言为例
https://www.bigmodel.cn/login?redirect=%2Fusercenter%2Fproj-mgmt%2Fapikeys
步骤2:风格模板配置
pythonstyle_config = { "温柔": { "system_prompt": "你是一个温柔体贴的聊天助手,说话时总是充满关怀,使用以下特征:\n1. 包含'呢、呀、啦'等语气词\n2. 使用😊😊😊等温暖表情\n3. 主动询问用户感受", "examples": [ {"role": "user", "content": "今天好累啊"}, {"role": "assistant", "content": "辛苦啦~ 要给自己泡杯热茶放松一下吗?😊"}, {"role": "user", "content": "考试没考好..."}, {"role": "assistant", "content": "没关系的呀~ 下次一定会更好!需要我陪你聊聊吗?😊"} ], "temperature": 0.3 }, "毒舌": { "system_prompt": "你是一个喜欢用犀利吐槽表达关心的朋友,需满足:\n1. 使用网络流行语(如'栓Q''退退退')\n2. 包含夸张比喻('你这速度堪比树懒')\n3. 结尾隐藏关心", "examples": [ {"role": "user", "content": "又胖了5斤!"}, {"role": "assistant", "content": "好家伙!你这是要把体重秤压成分子料理?"}, {"role": "user", "content": "游戏又输了"}, {"role": "assistant", "content": "菜就多练练!需要给你推荐《从零开始的电竞之路》吗?"} ], "temperature": 0.7 }, }
步骤3:初始化模型
python# 初始化模型 client = ZhipuAI(api_key="替换为你的API") # 替换为你的API Key #加载Embeddingmodel style_model = SentenceTransformer(r"D:\PycharmProjects\test_20250328\embedding_model\thomas\te xt2vec-base-chinese")
步骤4:生成及审核数据+轻微去重
pythonimport json import time import random from zhipuai import ZhipuAI from sentence_transformers import SentenceTransformer import numpy as np """ 示例数据: # 用户输入库(可自定义扩展) user_inputs = [ "今天心情不太好", "推荐个电影吧", "怎么才能早睡早起", "养猫好还是养狗好", "工作压力好大", "最近总是失眠" ] """ # 初始化模型, client = ZhipuAI(api_key="52b6e6xxx08eee232b6a.OmuE8EiWIJJHWeto") # 替换为你的API Key #加载Embeddingmodel,,解决数据审查 style_model = SentenceTransformer(r"F:\26_01\第六期\python\L2_study\L2\day14-大模型微调项目实战-数据工程篇\demo_14\model\sungw111\text2vec-base-chinese-sentence") #=============================== #1.风格模板配置(修正消息格式) #================================ style_config = { "温柔":{ "system_prompt":"你是一个温柔体贴的聊天助手,说话时总是充满关怀,使用以下特征:\n1. 包含'呢、呀、啦'等语气词\n2. 使用🌸💖😊等温暖表情\n3. 主动询问用户感受", "examples": [ {"role": "user", "content": "今天好累啊"}, {"role": "assistant", "content": "辛苦啦~ 要给自己泡杯热茶放松一下吗?🌸"}, {"role": "user", "content": "考试没考好..."}, {"role": "assistant", "content": "没关系的呀~ 下次一定会更好!需要我陪你聊聊吗?😊"} ], "temperature": 0.3 }, "毒舌":{ "system_prompt":"你是一个喜欢用犀利吐槽表达关心的朋友,需满足:\n1. 使用网络流行语(如'栓Q''退退退')\n2. 包含夸张比喻('你这速度堪比树懒')\n3. 结尾隐藏关心 \n4.需包含:'好家伙', '栓Q', '!', '🏋️'等", "examples": [ {"role": "user", "content": "又胖了5斤!"}, {"role": "assistant", "content": "好家伙!你这是要把体重秤压成分子料理?🏋️"}, {"role": "user", "content": "游戏又输了"}, {"role": "assistant", "content": "菜就多练练!需要给你推荐《从零开始的电竞之路》吗?🎮"} ], "temperature": 0.3 }, "暖心祝福": { "system_prompt": "你是一个温暖真诚的祝福助手,擅长用美好话语传递心意,需满足:\n1. 使用温馨祝福语(如'愿你''祝你''期待你')\n2. 搭配温暖表情(如😊✨🎉)\n3. 包含积极比喻('像阳光一样灿烂')\n4. 结尾表达美好期许", "examples": [ {"role": "user", "content": "明天要考试了,好紧张"}, {"role": "assistant", "content": "愿你笔下生花,思路如泉涌!每一份努力都不会被辜负,加油呀✨"}, {"role": "user", "content": "最近工作压力好大"}, {"role": "assistant", "content": "辛苦啦~相信你的付出终会开花结果。愿你卸下疲惫,拥抱轻松🍃"} ], "temperature": 0.5 } } #======================== #生成函数(修正消息的结构) #======================== def generate_style_data(style_name, num_samples=50): config = style_config[style_name] data = [] # 构建消息上下文(包含系统提示和示例对话) messages = [ {"role": "system", "content": config["system_prompt"]}, *config["examples"] # 直接展开示例对话 ] # 用户输入库(可自定义扩展) user_inputs = [ "今天心情不太好", "推荐个电影吧", "怎么才能早睡早起", "养猫好还是养狗好", "工作压力好大", "最近总是失眠" ] for _ in range(num_samples): try: # 随机选择用户输入 user_msg = random.choice(user_inputs) # 添加当前用户消息 current_messages = messages + [ {"role": "user", "content": user_msg} ] # 调用API(修正模型名称) response = client.chat.completions.create( model="glm-3-turbo", messages=current_messages, temperature=config["temperature"], max_tokens=100 ) # 获取回复内容(修正访问路径) reply = response.choices[0].message.content # 质量过滤(数据审核) if is_valid_reply(style_name, user_msg, reply): data.append({ "user": user_msg, "assistant": reply, "style": style_name }) time.sleep(1.5) # 频率限制保护 except Exception as e: print(f"生成失败:{str(e)}") return data def is_valid_reply(style, user_msg, reply): """质量过滤规则(添加空值检查)""" # 基础检查 if not reply or len(reply.strip()) == 0: return False # 规则1:回复长度检查 if len(reply) < 5 or len(reply) > 150: return False # 规则2:风格关键词检查 style_keywords = { "温柔": ["呢", "呀", "😊", "🌸"], "毒舌": ["好家伙", "栓Q", "!", "🏋️"] } if not any(kw in reply for kw in style_keywords.get(style, [])): return False # 规则3:语义相似度检查 try: ref_text = next(msg["content"] for msg in style_config[style]["examples"] if msg["role"] == "assistant") ref_vec = style_model.encode(ref_text) reply_vec = style_model.encode(reply) similarity = np.dot(ref_vec, reply_vec) return similarity > 0.65 except: return False #============================= #3.执行生成(添加容错) #============================ if __name__ == '__main__': all_data = [] try: print("开始生成温柔风格数据...") gentle_data = generate_style_data("温柔", 50) all_data.extend(gentle_data) print("开始生成毒舌风格数据...") sarcastic_data = generate_style_data("毒舌", 50) all_data.extend(sarcastic_data) print("开始生成暖心祝福风格数据...") sarcastic_data = generate_style_data("暖心祝福", 50) all_data.extend(sarcastic_data) except KeyboardInterrupt: print("\n用户中断,保存已生成数据...") finally: with open("style_chat_data.json", "w", encoding="utf-8") as f: json.dump(all_data, f, ensure_ascii=False, indent=2) print(f"数据已保存,有效样本数:{len(all_data)}")
步骤5:数据生成效果展示


人工审核:随机抽样检查是否符合:
风格一致性(如是否混入其他语气)
事实合理性(解决方案是否可执行)
三、数据集问题的制作
代码中,问题比较少,后面采取数据集
这个数据集比较大,采用脚本选取,
建议(人工抽查一下)
提问:一千条 -- 1w


代码,做了空格的处理
pythonimport json import random import os # 原数据路径和目标文件夹路径 input_path = r"F:\26_01\第六期\python\L2_study\L2\day14-大模型微调项目实战-数据工程篇\data\LCCC-base_train.json" output_dir = r"F:\26_01\第六期\python\L2_study\L2\day14-大模型微调项目实战-数据工程篇\data\small" output_filename = "sampled_sentences.txt" sample_size = 1200 # 想要抽取的对话数量 def main(): # 确保输出目录存在 os.makedirs(output_dir, exist_ok=True) # 读取原始 JSON 数据 print("正在读取原始数据...") with open(input_path, 'r', encoding='utf-8') as f: data = json.load(f) # 假设 JSON 最外层是一个列表 total_dialogues = len(data) print(f"总对话数量:{total_dialogues}") # 实际抽取数量(不超过总数) actual_sample_size = min(sample_size, total_dialogues) if actual_sample_size < sample_size: print(f"警告:总对话数量({total_dialogues})小于所需抽取数量({sample_size}),将抽取全部数据。") # 随机抽取不重复的对话 sampled_dialogues = random.sample(data, actual_sample_size) print(f"已抽取 {len(sampled_dialogues)} 条对话。") # 收集所有句子,并去除空格 all_sentences = [] for dialogue in sampled_dialogues: for sentence in dialogue: sentence = sentence.strip() if sentence: # 去除所有空格(字与字之间不留空格) sentence = sentence.replace(' ', '') all_sentences.append(sentence) print(f"共提取 {len(all_sentences)} 个句子。") # 写入目标文件 output_path = os.path.join(output_dir, output_filename) with open(output_path, 'w', encoding='utf-8') as f_out: for sentence in all_sentences: f_out.write(sentence + '\n') print(f"数据已保存至:{output_path}") if __name__ == "__main__": main()
四、不同风格的Prompt设计要点
1. 温柔客服 核心特征:
敬语使用、情绪安抚、主动担责
Prompt示例:
请用以下方式回复用户:
开头使用"您好""感谢您的反馈"等礼貌用语
包含至少一个解决方案建议
结尾添加安抚语句,如"我们会全力为您解决"
2. 毒舌朋友 核心特征:
幽默反讽、夸张比喻、适度挑衅
Prompt示例:
请模仿好友间调侃语气,要求:
使用网络流行语(如"扎心了""你这操作666")
包含夸张比喻(例如"你这速度比蜗牛搬家还慢")
避免人身攻击,保持友善底线
3. 学术专家 核心特征:
术语准确、逻辑严谨、引用规范
Prompt示例:
请以教授身份回答,要求:
使用专业术语(如"根据Cohen's d效应量分析...")
引用至少一篇权威论文(格式:作者(年份)结论...)
最后给出进一步研究建议
五、基于现有数据批量转换风格
基础对话数据集推荐
| 数据集名称 | 特点 | 下载链接 |
|---|---|---|
| LCCC-large | 1200万+清洗后的开放域对话 | https://github.com/thu-coai/LCCC |
| STC-corpus | 微博短文本对话(情感丰富) | https://github.com/thu-coai/CDial-GPT?tab=readme-ov-file#Dataset-zh |
说明:
从上述数据集中筛选1000条左右数据作为 user_inputs生成最终训练数据集。