本文通过一个简单的查询示例串起查询优化的流程。
- 逻辑层计划
- 物理层计划
优化线路图
txt
plan1->plan2->plan3->plan4->plan5->plan6->plan9->plan10->plan11;
plan1->plan2->plan3->plan4->plan12;
plan1->plan2->plan3->plan7->plan8;示例
Reserves (sid: integer, bid: integer, day: date, rname: text)
Sailors (sid: integer, sname: text, rating: integer, age: real)
Reserves:
- 每条记录的长度为 404040 字节
- 每页包含 100100100 条记录
- 该表共有 100010001000 页
- 该表共有 1000∗10=100000=10万1000*10=100000=10万1000∗10=100000=10万 条记录
- 假设共有 100100100 艘船
Sailors:
- 每条记录长度为 505050 字节
- 每页共有 808080 条记录
- 该表共有 500500500 页
- 该表共有 500∗80=40000=4万500*80=40000=4万500∗80=40000=4万 条记录
- 假设共有 10 个不同的等级。
假设在执行表的连接操作时,内存有 5 个可用的帧。
示例查询语句
sql
SELECT S.sname
FROM Reserves R, Sailors S
WHERE R.sid=S.sid
AND R.bid=100 AND S.rating>5;问题:针对不同的查询计划,计算上述查询语句触发的 IO 成本。
Plan 1 - 最差劲的查询计划
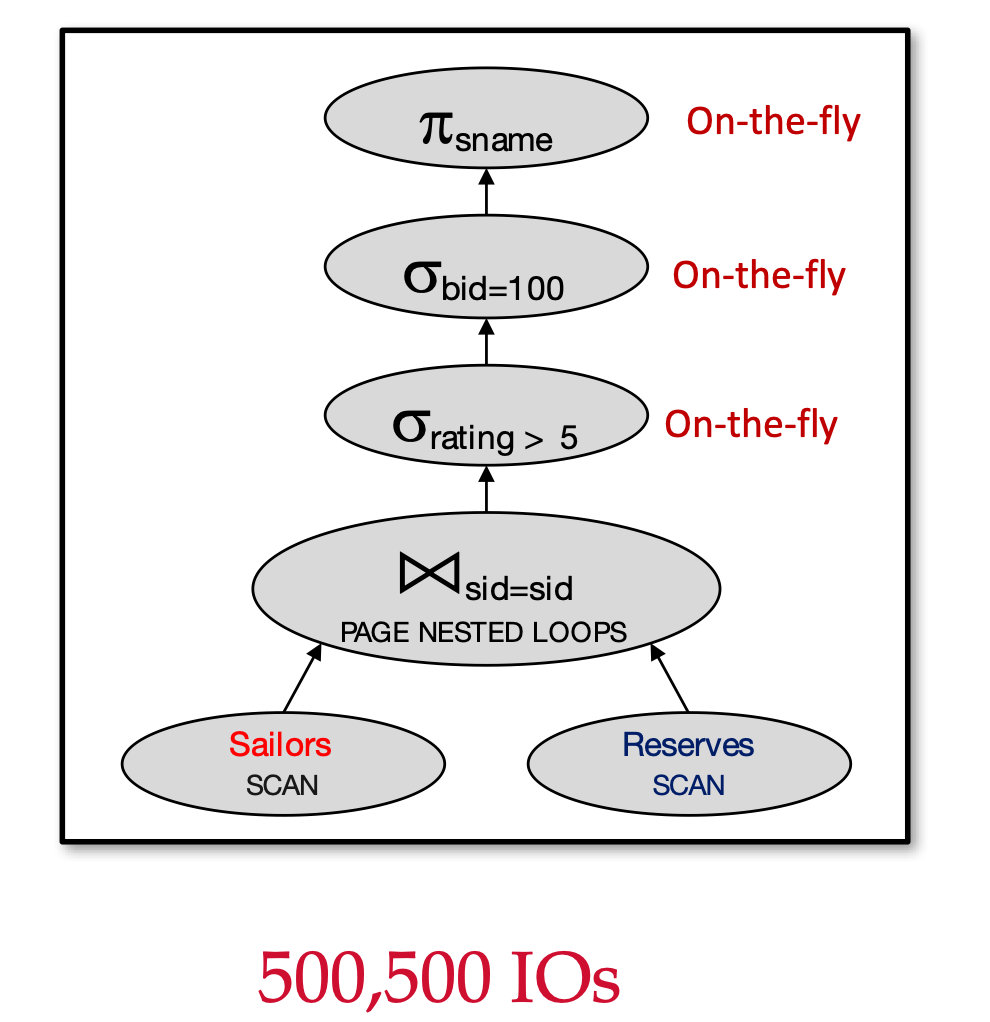
对应的关系代数表达式为
πsname(σbid=100(σrating>5(Sailors⋈sid=sidReserves))) \pi_{sname}(\sigma_{bid=100}(\sigma_{rating>5}(Sailors \Join_{sid=sid}Reserves))) πsname(σbid=100(σrating>5(Sailors⋈sid=sidReserves)))
Assume:
- Join algorithm: Page Nested Loop Join
- Outer relation:
Sailors(500 pages) - Inner relation:
Reserves(1000 pages) - No selection pushdown (logical plan)
让我们来计算该查询计划的 IO 成本
- 扫描
Sailors:500500500 IOs - 对
Sailors表的每一页,扫描Reserves:100010001000 IOs - 总成本:500+500∗1000=500500≈50万500+500*1000=500500\approx 50万500+500∗1000=500500≈50万
显然,这是最糟糕的查询计划,它没有使用一些优化措施,比如:
- 下推过滤操作(σ\sigmaσ)
- 建索引等
因此,我们的优化目标是:找出能跟 Plan 1 计算出相同结果且更快的查询计划。
Plan 2 - 第 1 次选择操作下推优化
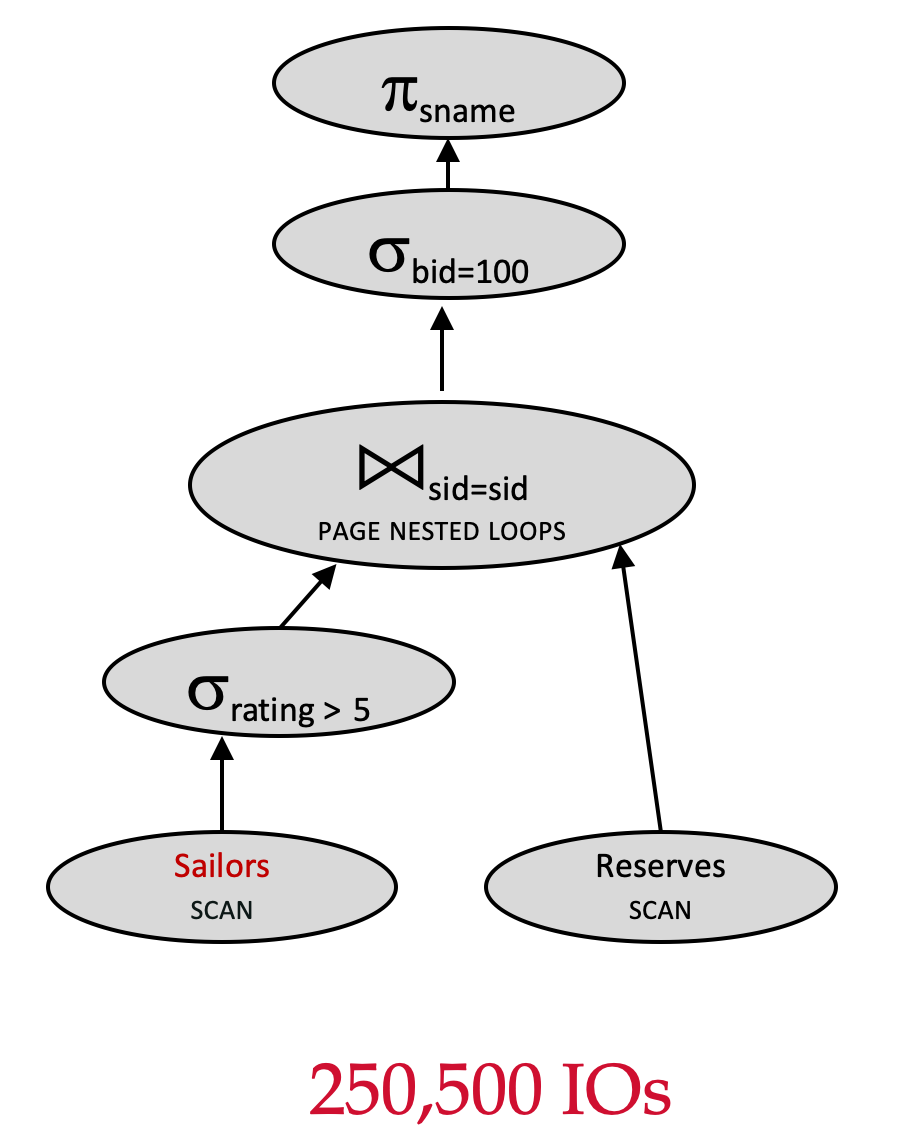
Assume:
- Join algorithm: Page Nested Loop Join
- Outer relation:
Sailors(500 pages) - Inner relation:
Reserves(1000 pages) - 逻辑计划优化:下推σrating>5\sigma_{rating>5}σrating>5
- no MAT
πsname(σbid=100(σrating>5(Sailors)⋈sid=sidReserves)) \pi_{sname}(\sigma_{bid=100}(\sigma_{rating>5}(Sailors) \Join_{sid=sid}Reserves)) πsname(σbid=100(σrating>5(Sailors)⋈sid=sidReserves))
让我们来计算该查询计划的 IO 成本:
- 扫描
Sailors:500500500 IOs - 对满足高等级的
Sailors的每一页来说,扫描Reserves:100010001000 IOs - 总成本=500+250∗1000=250500≈25万500+250*1000=250500\approx 25 万500+250∗1000=250500≈25万
请思考:为什么从 500变成了 250?
注意:这里用到了选择率,而且可以成功使用。
Plan 3 - 第 2 次选择操作下推优化
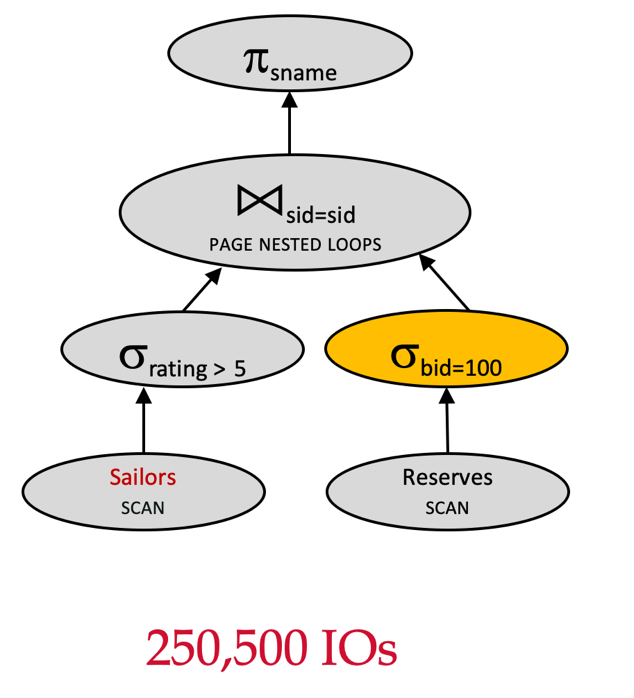
Assume:
- Join algorithm: Page Nested Loop Join
- Outer relation:
Sailors(500 pages) - Inner relation:
Reserves(1000 pages) - 逻辑计划优化:下推σrating>5\sigma_{rating>5}σrating>5
- 逻辑计划优化:下推σbid=100\sigma_{bid=100}σbid=100
- no MAT
πsname(σrating>5(Sailors)⋈sid=sidσbid=100(Reserves)) \pi_{sname}(\sigma_{rating>5}(Sailors) \Join_{sid=sid}\sigma_{bid=100}(Reserves)) πsname(σrating>5(Sailors)⋈sid=sidσbid=100(Reserves))
让我们来计算该查询计划的 IO 成本:
- 扫描
Sailors:500500500 IOs - 对满足高等级的
Sailors的每一页来说,仍然要扫描整个Reserves:100010001000 IOs - 总成本: 500+250∗1000=250500≈25万500 + 250*1000=250500\approx 25 万500+250∗1000=250500≈25万 IOs
请思考:在没有使用 MAT 的前提下,对已经下推了过滤条件的σbid=100(Reserves)\sigma_{bid=100}(Reserves)σbid=100(Reserves),为什么这里不能变成 10 页?
Plan 4 - 交换连接顺序
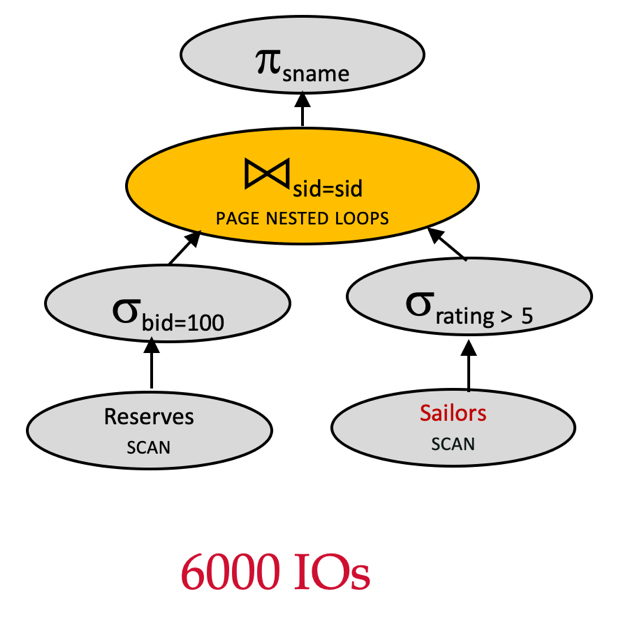
Assume:
- Join algorithm: Page Nested Loop Join
- Outer relation:
Reserves(500 pages) - Inner relation:
Sailors(1000 pages) - 逻辑计划优化:下推σrating>5\sigma_{rating>5}σrating>5
- 逻辑计划优化:下推σbid=100\sigma_{bid=100}σbid=100
- no MAT
- 交换连接顺序
πsname(σbid=100(Reserves)⋈sid=sidσrating>5(Sailors)) \pi_{sname}(\sigma_{bid=100}(Reserves)\Join_{sid=sid}\sigma_{rating>5}(Sailors) ) πsname(σbid=100(Reserves)⋈sid=sidσrating>5(Sailors))
让我们来计算该查询计划的 IO 成本:
- 扫描
Reserves:100010001000 IOs - 对满足
bid = 100的Reserves的每一页来说,仍然要扫描整个Sailors:500500500 IOs - 总成本: 1000+10∗500=6000≈6千1000 + 10*500=6000\approx 6 千1000+10∗500=6000≈6千 IOs
请思考:
- 在没有使用 MAT 的前提下,对已经下推了过滤条件的σrating>5(Sailors)\sigma_{rating>5}(Sailors)σrating>5(Sailors),为什么这里不能变成 250 页?
- 谁才是真正的小表?
结论:在没有 materialization 的 PNLJ 中,outer 决定成本,inner 的选择率几乎没用。
Plan 5 vs. Plan4 - 物化内表
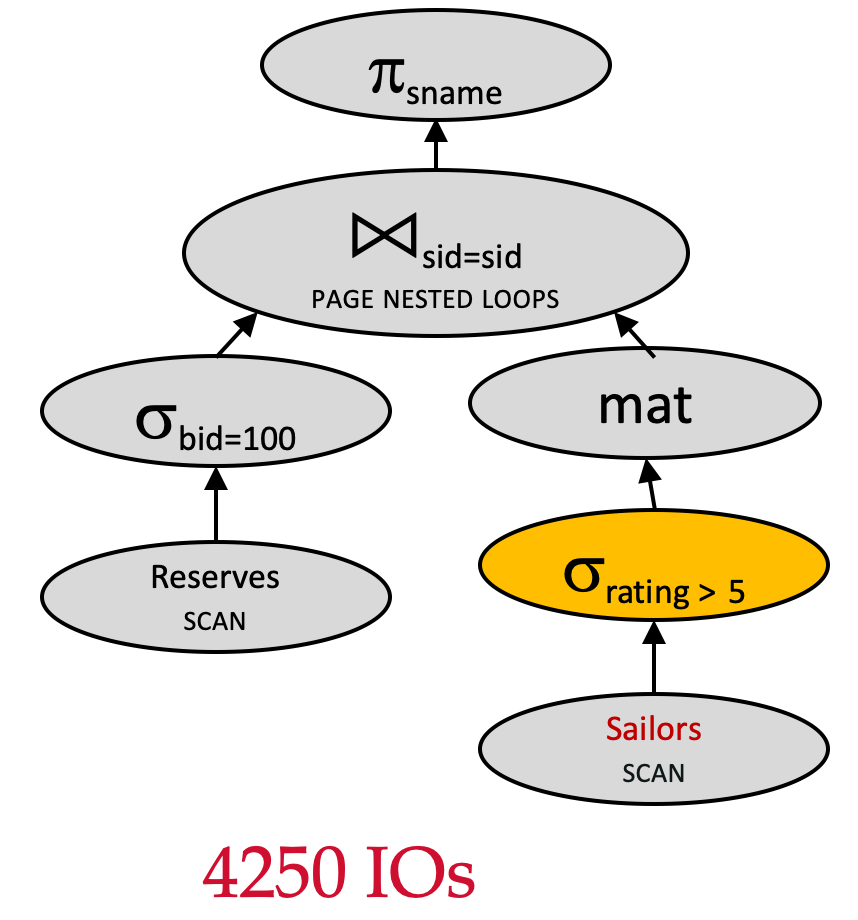
Assume:
- Join algorithm: Page Nested Loop Join
- Outer relation:
Reserves(500 pages) - Inner relation:
Sailors(1000 pages) - 逻辑计划优化:下推σrating>5\sigma_{rating>5}σrating>5
- 逻辑计划优化:下推σbid=100\sigma_{bid=100}σbid=100
- 交换连接顺序
- 对内表使用 MAT
πsname(σbid=100(Reserves)⋈sid=sidσrating>5(Sailors)) \pi_{sname}(\sigma_{bid=100}(Reserves)\Join_{sid=sid}\sigma_{rating>5}(Sailors) ) πsname(σbid=100(Reserves)⋈sid=sidσrating>5(Sailors))
让我们来计算该查询计划的 IO 成本:
- 扫描
Reserves:100010001000 IOs - 扫描
Sailors:500500500 IOs - 物化内表的过滤结果,创建临时表 T1T_1T1:250250250
- 对满足
bid=100的Reserves的每一页来说,扫描整个临时表T_1:250250250 IOs - 总成本: 1000+500+250∗10=4250≈4千1000+500 + 250*10=4250\approx 4千1000+500+250∗10=4250≈4千 IOs
Plan 6 vs. Plan 5 - 交换连接顺序
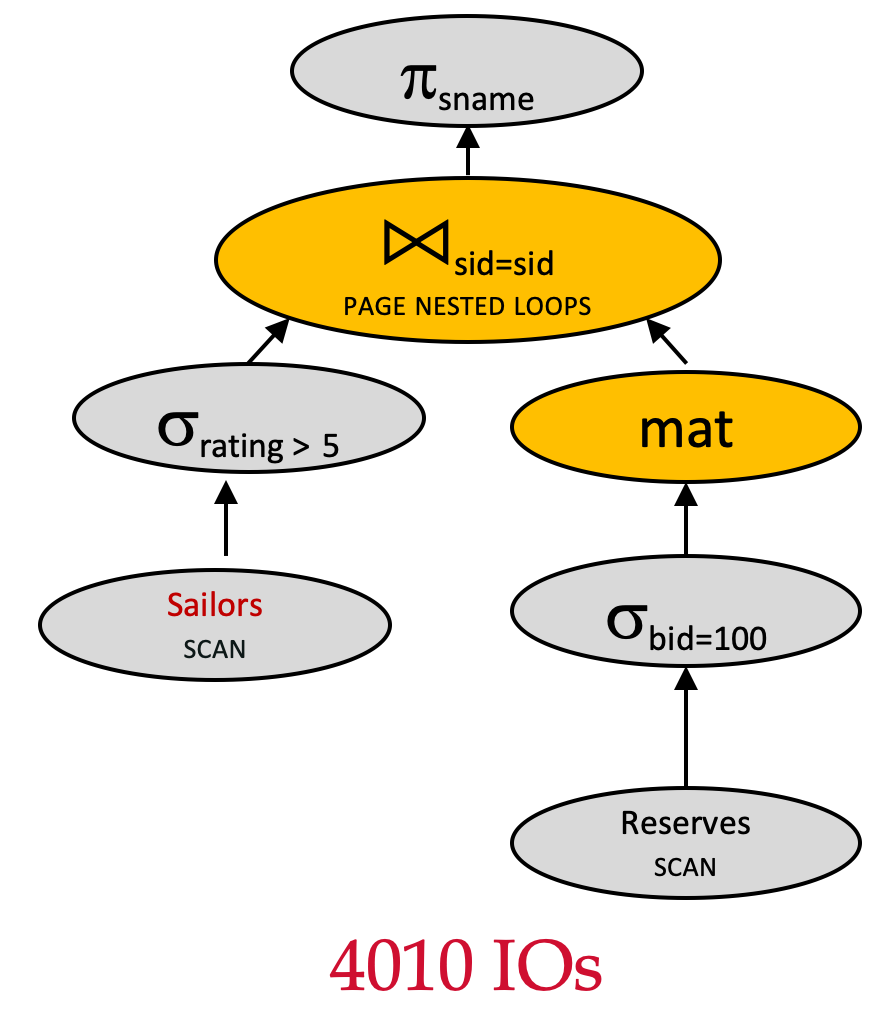
πsname(σrating>5(Sailors)⋈sid=sidσbid=100(Reserves)) \pi_{sname}(\sigma_{rating>5}(Sailors)\Join_{sid=sid} \sigma_{bid=100}(Reserves)) πsname(σrating>5(Sailors)⋈sid=sidσbid=100(Reserves))
Assume:
- Join algorithm: Page Nested Loop Join
- Outer relation:
Sailors(500 pages) - Inner relation:
Reserves(1000 pages) - 逻辑计划优化:下推 σrating>5\sigma_{rating>5}σrating>5
- 逻辑计划优化:下推 σbid=100\sigma_{bid=100}σbid=100
- 交换连接顺序
- 对内表使用 MAT
让我们来计算该查询计划的 IO 成本:
- 扫描
Sailors:500500500 IOs - 扫描
Reserves:100010001000 IOs - 物化内表的过滤结果,创建临时表 T1T_1T1:101010
- 对满足
rating>5的Sailors的每一页来说,扫描整个临时表T_1:101010 IOs - 总成本: 1000+500+10+250∗10=4010≈4千1000 + 500 + 10 + 250*10=4010\approx 4千1000+500+10+250∗10=4010≈4千 IOs
Plan 7 vs. Plan 3 - 更改连接算法
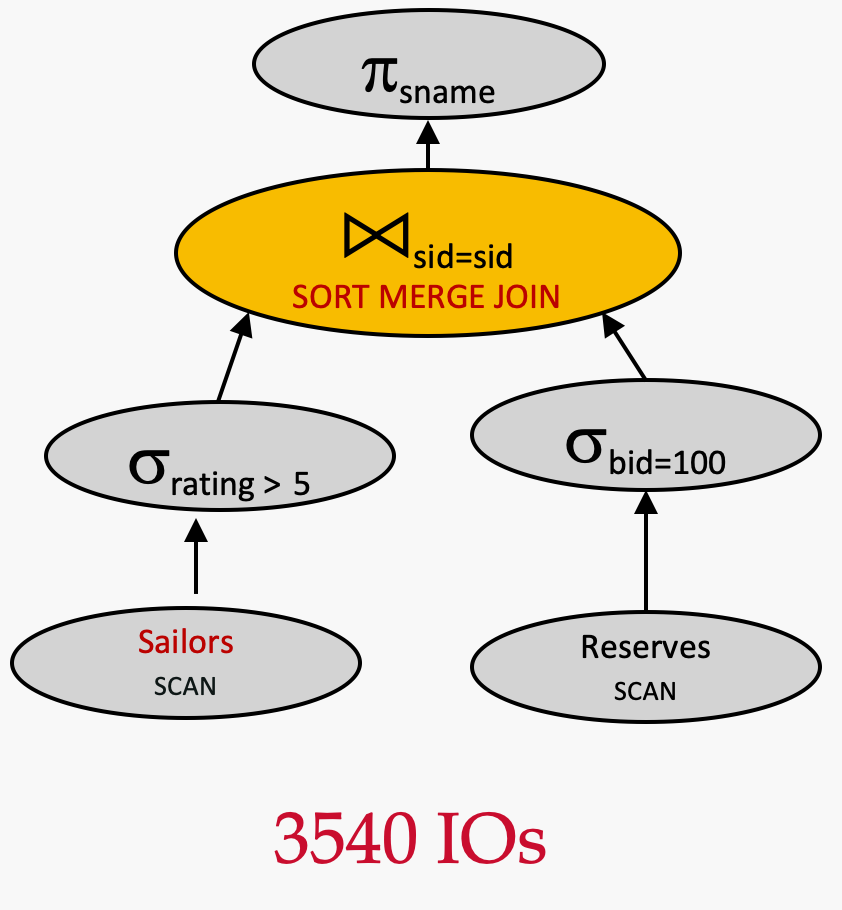
Assume:
- Join algorithm: Sort Merge Join
- Outer relation:
Sailors(500 pages) - Inner relation:
Reserves(1000 pages) - 逻辑计划优化:下推σrating>5\sigma_{rating>5}σrating>5
- 逻辑计划优化:下推σbid=100\sigma_{bid=100}σbid=100
- no MAT
πsname(σrating>5(Sailors)⋈sid=sidσbid=100(Reserves)) \pi_{sname}(\sigma_{rating>5}(Sailors) \Join_{sid=sid}\sigma_{bid=100}(Reserves)) πsname(σrating>5(Sailors)⋈sid=sidσbid=100(Reserves))
根据假设,在执行连接算法时,RAM 有 5 个帧可供使用。
让我们来计算该查询计划的 IO 成本:
- 扫描
Reserves:100010001000 IOs - 扫描
Sailors:500500500 IOs - 对满足
rating > 5的Sailors的页进行排序的成本 - 对满足
bid = 100的Reserves的页进行排序的成本 - 归并的成本:10+250=26010+250=26010+250=260
排序阶段
- 对
Reserves来说,共有 2 趟。具体地讲,第 0 趟只有写成本 101010 IOs,因为只需从内存中过滤后的结果中读即可。第 1 趟的读写成本为2∗10=202*10=202∗10=20 - 对
Sailors来说,共有 4 趟。具体地讲,第 0 趟只有写成本 250250250 IOs,因为只需从内存中过滤后的结果中读即可。第 1、2、3 趟的读写成本为2∗3∗250=15002*3*250=15002∗3∗250=1500
总成本为
1000+500+(10+2∗10)+(250+2∗3∗250)+(10+250)=3540 1000 + 500 + (10+2*10)+(250+2*3*250)+(10+250)=3540 1000+500+(10+2∗10)+(250+2∗3∗250)+(10+250)=3540
Plan 8 vs Plan 7 -- 内外表都添加 MAT
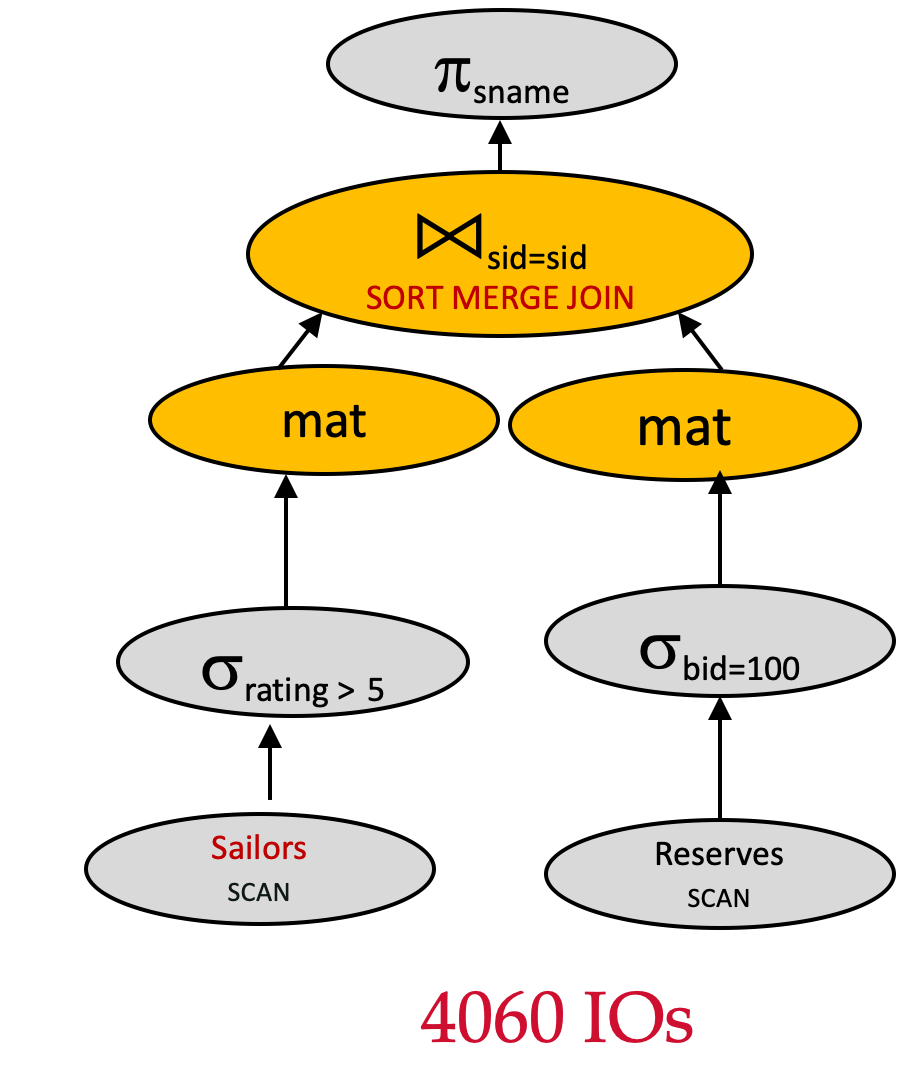
Assume:
- Join algorithm: Sort Merge Join
- Outer relation:
Sailors(500 pages) - Inner relation:
Reserves(1000 pages) - 逻辑计划优化:下推 σrating>5\sigma_{rating>5}σrating>5
- 逻辑计划优化:下推 σbid=100\sigma_{bid=100}σbid=100
- 内外表都添加 MAT
πsname(σrating>5(Sailors)⋈sid=sidσbid=100(Reserves)) \pi_{sname}(\sigma_{rating>5}(Sailors) \Join_{sid=sid}\sigma_{bid=100}(Reserves)) πsname(σrating>5(Sailors)⋈sid=sidσbid=100(Reserves))
根据假设,在执行连接算法时,RAM 有 5 个帧可供使用。
让我们来计算该查询计划的 IO 成本:
- 扫描
Reserves:100010001000 IOs,创建临时表 T1T_1T1的写入成本为 101010 IOs。 - 扫描
Sailors:500500500 IOs,创建临时表 T2T_2T2 的写入成本为250250250 IOs - 对满足
rating > 5的Sailors的页进行排序的成本 - 对满足
bid = 100的Reserves的页进行排序的成本 - 归并的成本:10+250=26010+250=26010+250=260
排序阶段
- 对
Reserves来说,共有 2 趟,成本为2∗(1+1)∗10=402*(1+1)*10=402∗(1+1)∗10=40 - 对
Sailors来说,共有 4 趟,成本为2∗(1+3)∗250=20002*(1+3)*250=20002∗(1+3)∗250=2000
总成本为
1000+500+(250+10)+(2∗2∗10)+(2∗4∗250)+(10+250)=4060 1000 + 500 + (250+10) + (2*2*10)+(2*4*250)+(10+250)=4060 1000+500+(250+10)+(2∗2∗10)+(2∗4∗250)+(10+250)=4060
Plan 9 vs. Plan6 -- 更改连接算法
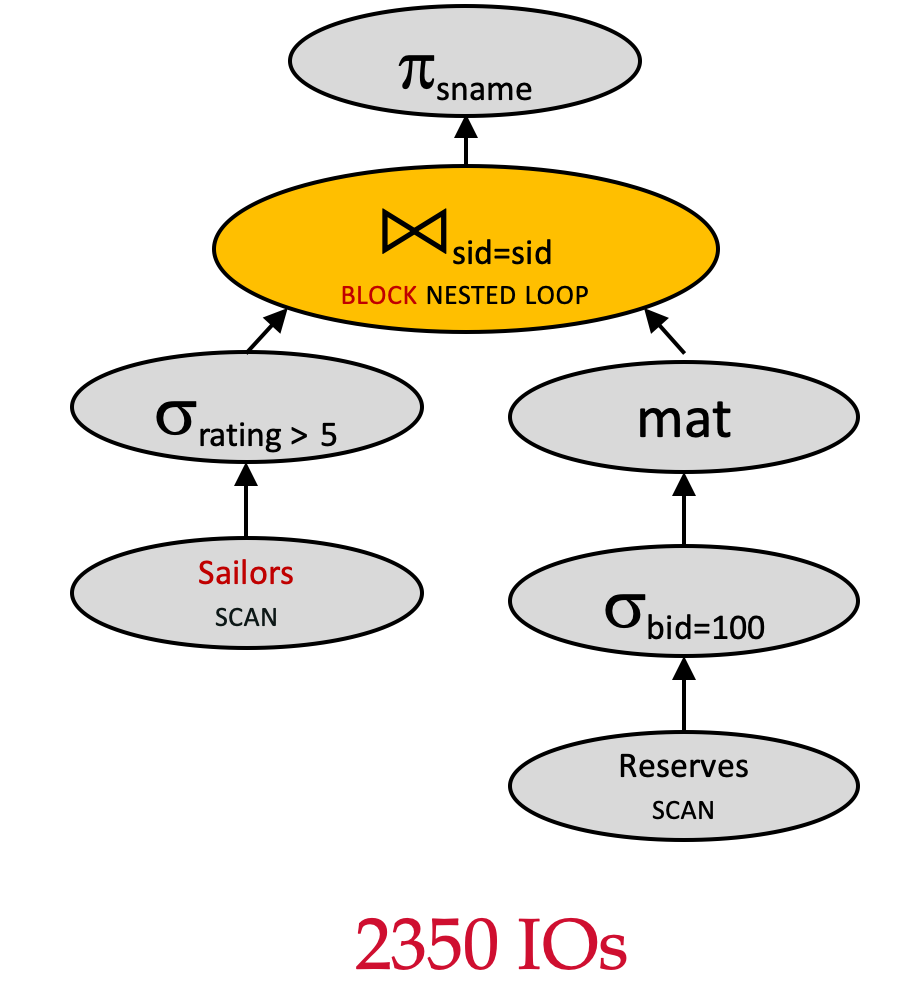
πsname(σrating>5(Sailors)⋈sid=sidσbid=100(Reserves)) \pi_{sname}(\sigma_{rating>5}(Sailors)\Join_{sid=sid} \sigma_{bid=100}(Reserves)) πsname(σrating>5(Sailors)⋈sid=sidσbid=100(Reserves))
Assume:
- Join algorithm: Block Nested Loop Join
- Outer relation:
Sailors(500 pages) - Inner relation:
Reserves(1000 pages) - 逻辑计划优化:下推 σrating>5\sigma_{rating>5}σrating>5
- 逻辑计划优化:下推 σbid=100\sigma_{bid=100}σbid=100
- 交换连接顺序
- 对内表使用 MAT
根据假设,在执行连接算法时,RAM 有 5 个帧可供使用。
让我们来计算该查询计划的 IO 成本:
- 扫描
Sailors:500500500 IOs - 扫描
Reserves:100010001000 IOs - 写入临时表T1T_1T1:101010 IOs
- 对满足
rating>5的Sailors的每个块来说,扫描整个临时表T_1:101010 IOs - 总成本: 1000+500+10+⌈(250/3)⌉∗10=2350≈2千1000 + 500 + 10 + \lceil(250/3)\rceil*10=2350\approx 2千1000+500+10+⌈(250/3)⌉∗10=2350≈2千 IOs
Plan 10 vs. plan 9 - Projection Cascade & Pushdown
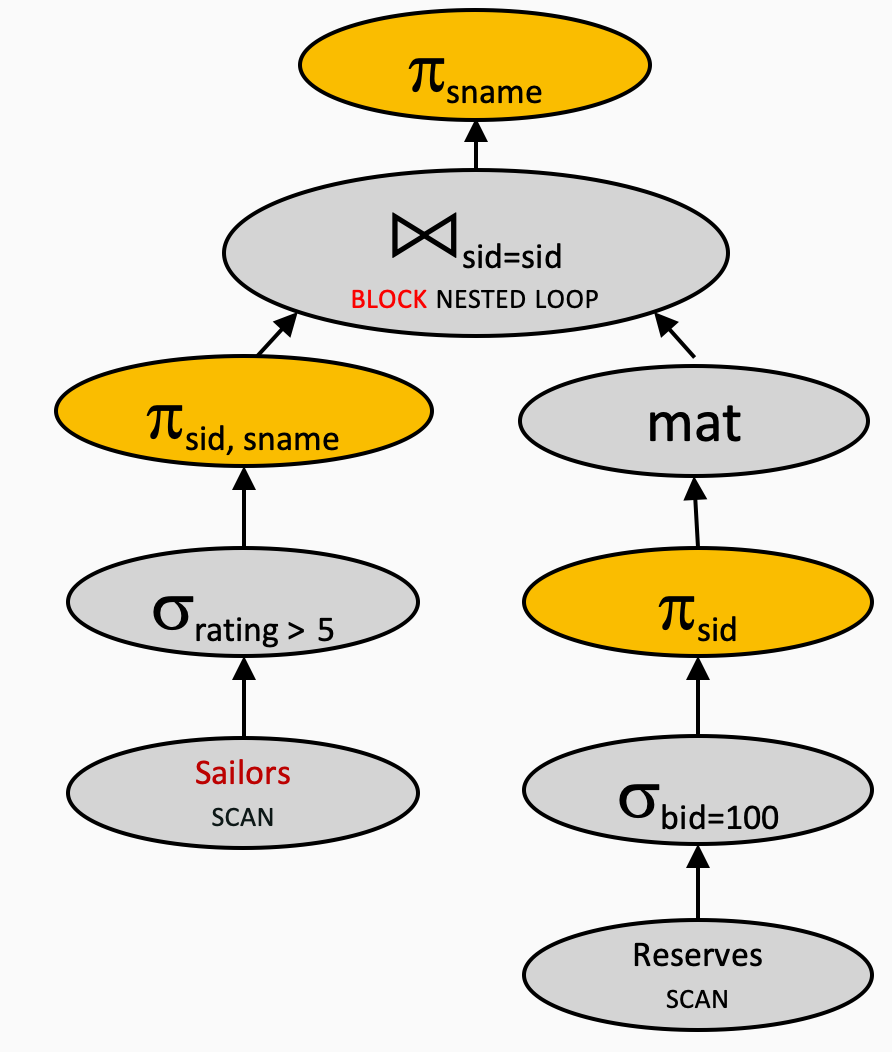
πsname(πsid,sname(σrating>5(Sailors)))⋈sid=sid(πsid(σbid=100(Reserves)))) \pi_{sname}(\pi_{sid, sname}(\sigma_{rating>5}(Sailors)))\Join_{sid=sid}(\pi_{sid}(\sigma_{bid=100}(Reserves)))) πsname(πsid,sname(σrating>5(Sailors)))⋈sid=sid(πsid(σbid=100(Reserves))))
- Join algorithm: Block Nested Loop Join
- Outer relation:
Sailors(500 pages) - Inner relation:
Reserves(1000 pages) - 逻辑计划优化:下推 σrating>5\sigma_{rating>5}σrating>5
- 逻辑计划优化:下推 σbid=100\sigma_{bid=100}σbid=100
- 交换连接顺序
- 对内表使用 MAT
- 逻辑计划优化:下推 πsid\pi_{sid}πsid 和 πsid,sname\pi_{sid,sname}πsid,sname
Plan 11 vs. Plan 10 - Join Reorder & no MAT
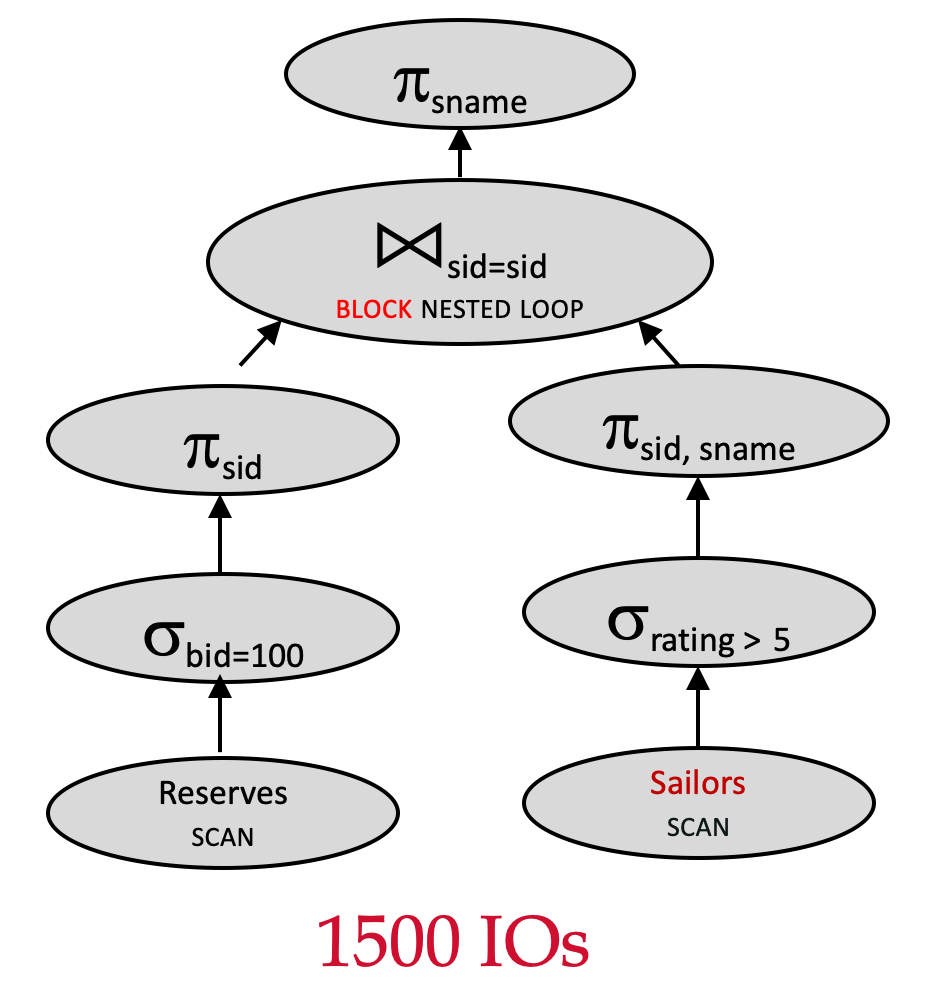
πsname(πsid(σbid=100(Reserves)))⋈sid=sid(πsid,sname(σrating>5(Sailors)))) \pi_{sname}(\pi_{sid}(\sigma_{bid=100}(Reserves)))\Join_{sid=sid} (\pi_{sid, sname}(\sigma_{rating>5}(Sailors)))) πsname(πsid(σbid=100(Reserves)))⋈sid=sid(πsid,sname(σrating>5(Sailors))))
- Join algorithm: Block Nested Loop Join
- Outer relation:
Reserves(1000 pages) - Inner relation:
Sailors(500 pages) - 逻辑计划优化:下推 σrating>5\sigma_{rating>5}σrating>5
- 逻辑计划优化:下推 σbid=100\sigma_{bid=100}σbid=100
- 交换连接顺序
- No MAT
- 逻辑计划优化:下推 πsid\pi_{sid}πsid 和 πsid,sname\pi_{sid,sname}πsid,sname
根据假设,在执行连接算法时,RAM 有 5 个帧可供使用。
让我们来计算该查询计划的 IO 成本:
- 扫描
Reserves:100010001000 IOs - 对满足
bid=100的Reserves的每个块来说,Reserves的每条记录为 40字节长,假设sid占 4 个字节,那么对sid列进行投影操作,则 10 页就变成 1 页了 - 因为内表没有使用 MAT,所以还是 500 IOs。
- 总成本: 1000+⌈1/3⌉∗5001000+\lceil1/3\rceil*5001000+⌈1/3⌉∗500=1500 IOs
Plan 12 vs. Plan 4 - Index
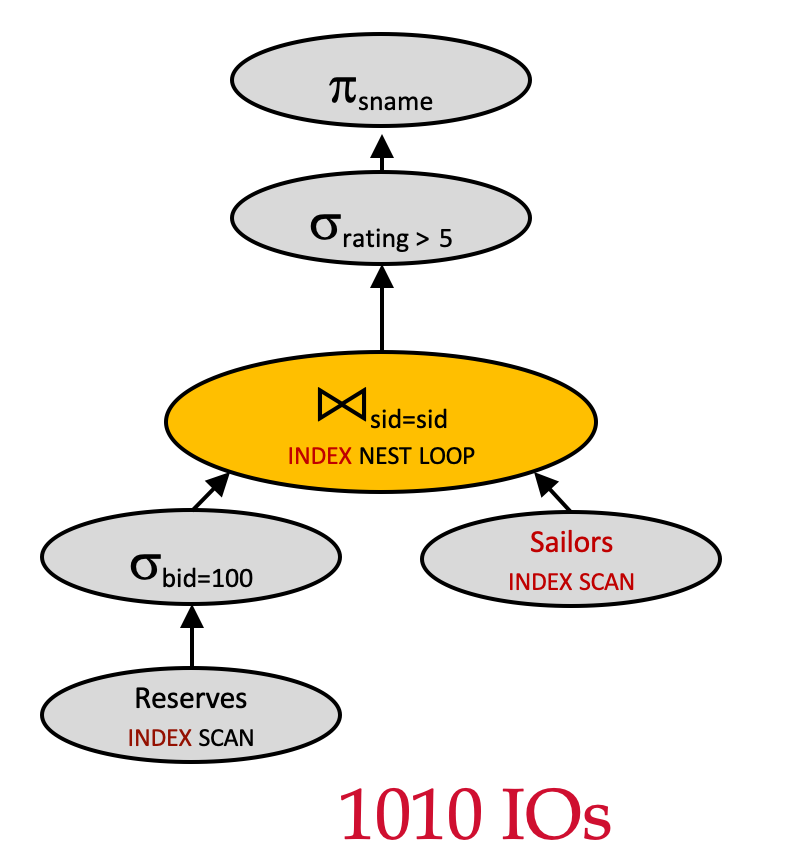
Assume:
- Join algorithm: Page Nested Loop Join
- Outer relation:
Reserves(1000 pages) - Inner relation:
Sailors(500 pages) - 逻辑计划优化:下推 σbid=100\sigma_{bid = 100}σbid=100
- no MAT
- 在连接键上建索引
- 底层文件扫描更改为索引扫描
πsname(σrating>5(σbid=100(Reserves)⋈Sailors)) \pi_{sname}(\sigma_{rating>5}(\sigma_{bid=100}(Reserves)\Join Sailors)) πsname(σrating>5(σbid=100(Reserves)⋈Sailors))
假设两张表都在sid列上建了索引,且
Reserves.bid是聚簇索引Sailors.sid是非聚簇索引
假设索引都能装入内存。
对左侧不执行投影下推πsname\pi_{sname}πsname
- 在索引嵌套循环连接的外层表中剔除无关字段,不会带来 I/O 上的收益。
对右侧不执行选择下推 σrating>5\sigma_{rating>5}σrating>5
- 该条件不会影响对
Sailors.sid索引的查找过程。
在 Reserves 表的 bid 列上建有聚簇索引的情况下,我们需要访问多少页 Reserves?
- 1000页×100条/页=100,0001000 页\times 100 条/页 = 100,0001000页×100条/页=100,000 条记录
- 满足
bid=100的记录共 100,000/100=1000100,000 / 100 = 1000100,000/100=1000 条 - 这些记录占用:1000/100=101000 / 100 = 101000/100=10 页
连接列 sid 是 Sailors 表的主键:
- 最多只会匹配到 1 条记录
- 因此在
sid上使用非聚簇索引完全可行
对这 1000 条 Reserves 记录中的每一条,都要去 Sailors 中查找匹配记录(每次 1 次 I/O)。
- 回顾:
Reserves每页 100 条,共 1000 页
总成本:10+1000×110 + 1000 × 110+1000×1
- 筛选 Reserves 记录:10 次 I/O
- 之后对每条记录查找对应的 Sailors 记录:1000 次 I/O
- 总计:1010 次 I/O
思考
既然索引优化效果这么明显,那么为什么还要讲 Plan 1~11?
因为:在真实系统中:
- 不是每个条件都有索引
- 不是每个 join key 都建索引
- 索引维护成本高(写入慢)
所以必须学会:
- 没索引也要优化
- 有索引也要用对
场景 1:没有索引(必须靠优化器)
WHERE rating > 5
没索引只能:
- pushdown
- join reorder
- block join
否则就是 500,000 IOs(Plan1)
场景 2:有索引但优化器很差
即使有索引,如果你:
- 错误 join 顺序
- 错误 join 算法
- 没有 pushdown
仍然可能:
- 退化到接近 full scan
- 或重复 index lookup(很贵)
总结
Plan1~Plan13 优化策略与 IO 成本汇总表
| 计划 | 核心优化策略 | 估算 IO |
|---|---|---|
| Plan1 | 无优化:先连接再过滤,全表扫描 + PNLJ | 500,500 |
| Plan2 | 选择下推:先过滤 Sailors(rating>5) 再连接 | 250,500 |
| Plan3 | 双重选择下推:两边都先过滤,仍用 PNLJ | 250,500 |
| Plan4 | 改变连接顺序:以 Reserves 为外层,减少循环次数 | 6,000 |
| Plan5 | 物化内层表:先生成临时表再循环,降低重复扫描成本 | 2,250 |
| Plan6 | 连接顺序调换 + 物化临时表 | 3,750 |
| Plan7 | 换为 Sort-Merge Join,减少循环 I/O | 3,540 |
| Plan8 | Sort-Merge + 双表物化,更规整的归并 | 4,060 |
| Plan9 | 换为 Block Nested Loop,利用内存分块 | 2,350 |
| Plan10 | 投影下推:提前剔除无用列,减少数据量 | 接近 2350 |
| Plan11 | 连接重排序 + 投影下推 + 无物化,极致逻辑优化 | 1,500 |
| Plan12 | 逻辑优化到底:全表扫描 + PNLJ | 6,000 |
| Plan13 | 聚簇/非聚簇索引 + Index NLJ,直接定位数据 | 1,010 |
- 从上到下:逻辑优化 → 物理算法优化 → 索引优化
- 量级变化:50万 → 25万 → 6千 → 3千 → 1千5 → 1010
- 结论:索引带来的提升远超所有逻辑+物理优化之和