文章目录
- 递归、搜索与回溯算法相关介绍及解析
- [一、面试题 08.06. 汉诺塔问题](#一、面试题 08.06. 汉诺塔问题)
- 二、合并两个有序链表
- 小总结
- 三、反转链表
- [四、Pow(x, n) (快速幂)](#四、Pow(x, n) (快速幂))
递归、搜索与回溯算法相关介绍及解析
- 我们都知道所谓递归就是函数自己调用自己,但是做题是又不是无脑照搬递归,我们都是通过分析题目的特征而得出应该使用递归算法的。
什么时候使用递归?
递归的本质:
- 我们发现一个主问题可以分解为若干个"相同的"子问题--->而这些子问题也可以继续分解为同样的若干个子问题。面对这样的问题,就可以使用递归算法来解决。
比如我们学习过的二叉树的遍历、快速排序、归并...等等:
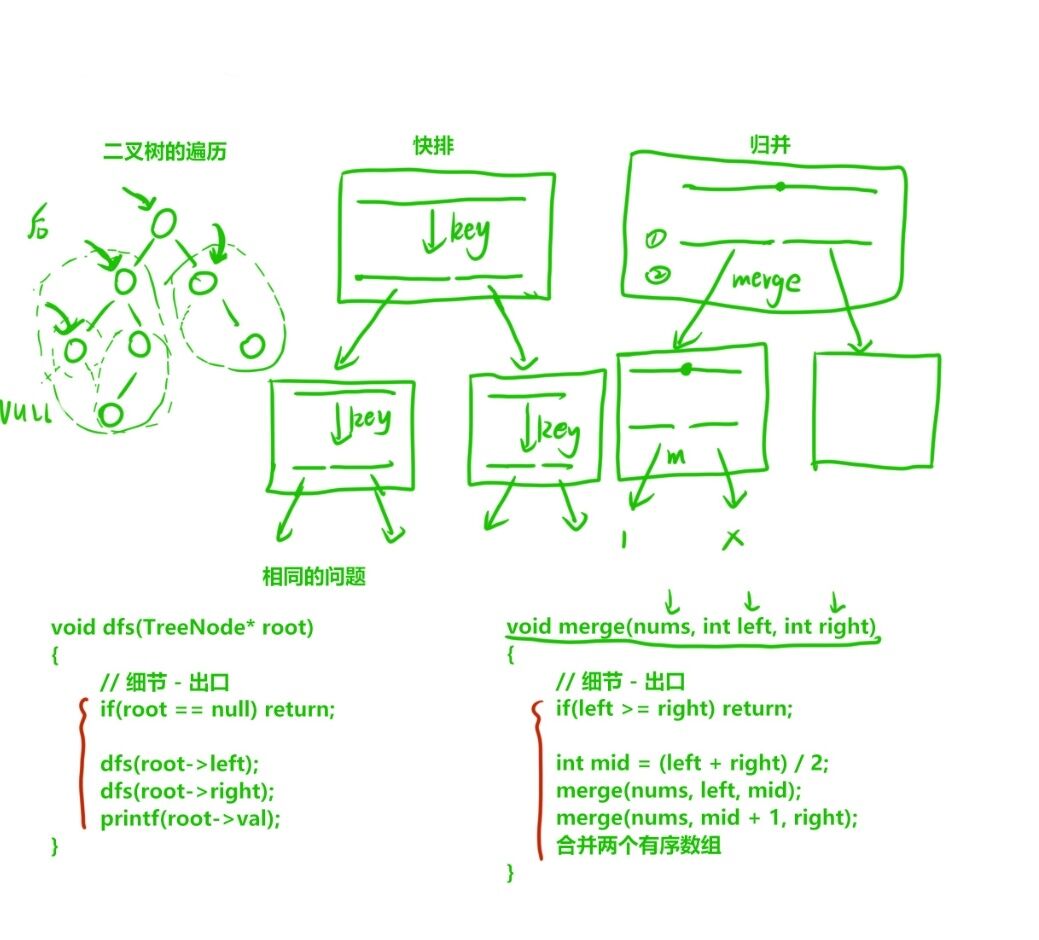
如何更好地理解递归算法?
宏观看待递归的过程:
-
不要过于在意递归的细节展开图,总是刻意在脑海中复刻递归一层一层的这个详细过程,而是先仅专注一层子问题的逻辑,这样宏观的看待递归。
-
把递归的函数当成一个黑盒,先不去管它内部具体实现
-
相信这个黑盒一定能完成它任务
一些想法总结:
- 说是要把递归函数理解为一个黑盒,不让我们去在意它的具体实现,但一个压根没有去实现其逻辑的函数让我们直接用,确实不太能赞同。
- 但其实我是这样理解的,对于一层递归我们在乎的应当是它所return的结果(或者即使没有返回值,也处理了一些数据),只要它能够return出我想要的结果,那它就NB,我们确实不用去关心它内部的具体实现,我想这也是宏观看待递归的一种方式,因为递归的最后过程其实就是一层一层地往回"传递"结果。
那么我们的问题就是这一层递归所产生的结果是哪来的?
-
若把每一层递归看做一个人,每个人return结果的过程就是在干活,那就只有递归到最后一层的一个或几个人在真正干活,其他人都在"偷懒"!我们知道只有问题分解到最小的状态(最后一层),递归才会停止,这个时候是可以直接得到这些最小问题的答案的,而往上层回溯的过程中其实每层递归都相当于是拿到这些最底层递归所返回的结果进行整和、合并处理一下而产生了新的结果,那其实还是人家的功劳。
-
所以不要纠结这每层递归的结果到底哪来的?其实就是它的下一层给它的,而所有结果的源头:最底层确实是产生了结果,由它而来的结果没有太复杂的处理,因为它是最小问题。
如何写好一个递归的代码?
- 先找到相同的子问题的逻辑
这不仅可以帮助我们意识到递归问题,而且是函数头设计的关键。
比如,为啥二叉树遍历的函数头这样设计:
java
void dfs(TreeNode* root){
}而归并排序的函数头这样设计:
java
void merge(nums, int left, int right){
}- 那都是因为二叉树的子问题就是要一个跟节点,然后对种棵树遍历。
- 而归并排序的子问题逻辑就是给一个数组,在left,right范围内对其排序
2.只关心某一个子问题是如何解决的--->函数体的书写
3.再注意一下递归函数的结束条件即可
- 还有不要将递归算法局限于二叉树问题、图论问题。只要具有问题拆解的特征,就可以使用递归算法。
再比如全排列问题:
对1、2、3三个数字进行全排列,使用的是树状图进行分析,那也可以使用递归算法:
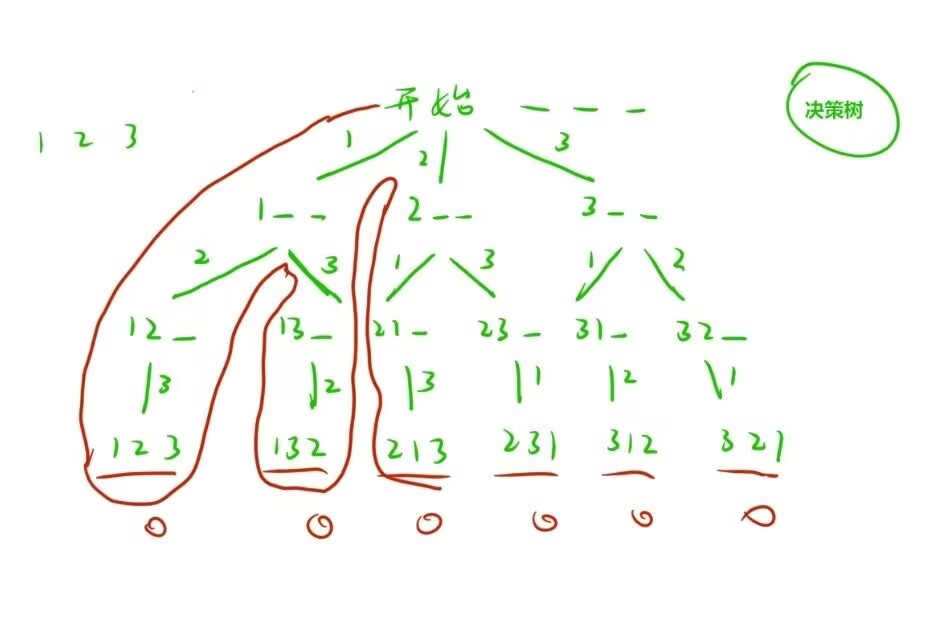
回溯与剪枝
回溯和剪枝是算法思想中,特别是在解决【约束满足问题】和【组合优化问题】时,两种紧密结合的策略。
-
回溯的本质其实就是dfs,在dfs一层一层往下递归到最底层后(或已经判断该分支不可行后)开始往上层return,那么这个返回的过程就是回溯。
-
剪枝是在回溯搜索过程中,提前判断某些分支(选择路径)不可能产生有效解或最优解,从而主动放弃对该分支的进一步搜索的算法思想,避免大量无用的递归调用。。
-
没有剪枝的回溯,就是纯粹的暴力穷举,效率通常极低。加入了有效的剪枝策略,回溯算法才能解决规模较大的实际问题。
经典的回溯算法应用:
【迷宫问题】
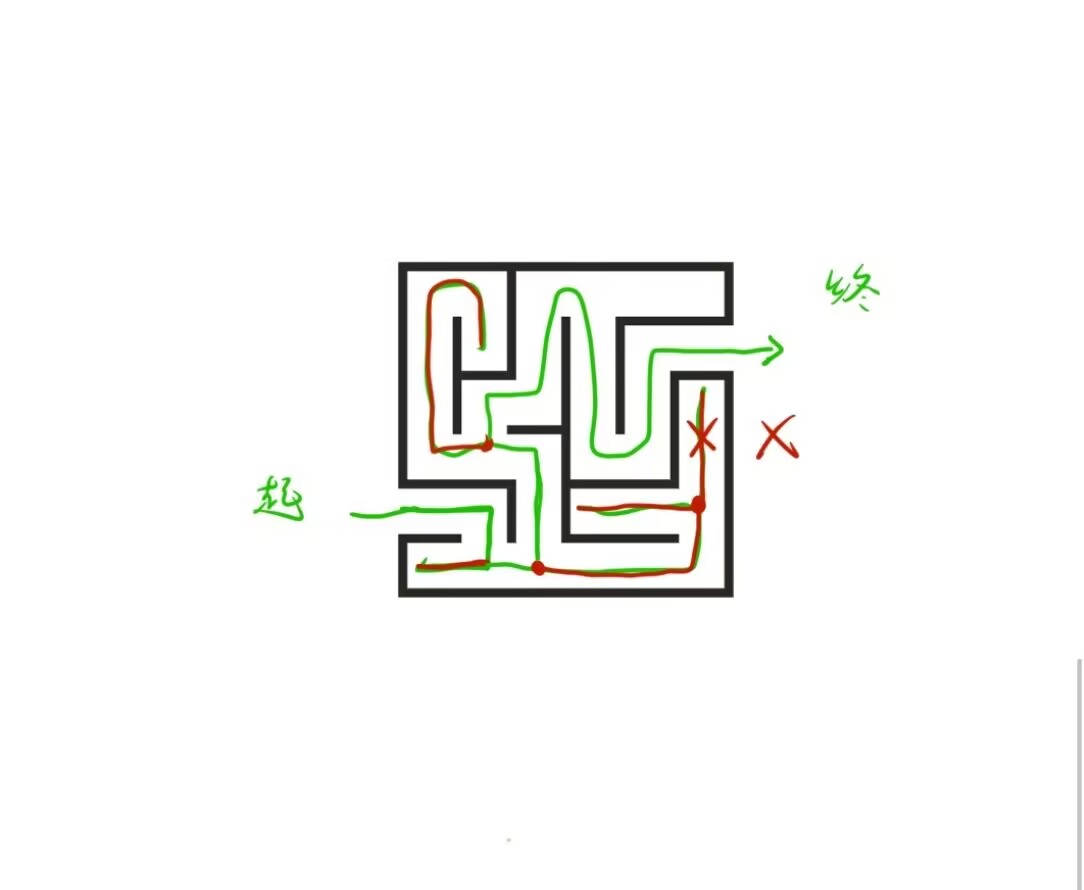
如何从起点找到终点?
- 使用的就是回溯算法,从起点开始进行深搜(dfs),"一条路走到黑",遇到障碍就return(回溯过程),换一条路走,直到遇到出口。
- 还可以进行剪枝优化:通过标记"已访问"或"无效",避免重复走绕圈或已知的死路,极大提升搜索效率。
下面开始整理【递归】专题算法题:
一、面试题 08.06. 汉诺塔问题
在经典汉诺塔问题中,有 3 根柱子及 N 个不同大小的穿孔圆盘,盘子可以滑入任意一根柱子。一开始,所有盘子自上而下按升序依次套在第一根柱子上(即每一个盘子只能放在更大的盘子上面)。移动圆盘时受到以下限制:
(1) 每次只能移动一个盘子;
(2) 盘子只能从柱子顶端滑出移到下一根柱子;
(3) 盘子只能叠在比它大的盘子上。
请编写程序,用栈将所有盘子从第一根柱子移到最后一根柱子。
你需要原地修改栈。
示例 1:
输入:A = 2, 1, 0, B = \[\], C = \[\]
输出:C = 2, 1, 0
解题思路
- 利用规律结合递归算法解决问题,只不过本题加入了List让我们进行操作更改
代码实现及解析
java
class Solution {
public void hanota(List<Integer> a, List<Integer> b, List<Integer> c) {
recursion(a,b,c,a.size());//将a柱上所有的圆盘通过辅助柱:b柱放到c柱上
}
//F:from(起点) A:assist(辅助) T:to(终点)
void recursion(List<Integer> F, List<Integer> A, List<Integer> T,int n){//n:F的前n个圆盘
if(n==1){
T.add(F.remove(F.size()-1));//栈顶(柱顶)为List的最后一个元素,所以用F.size()方法
return;
}
recursion(F,T,A,n-1);//1.将F柱上前size-1个圆盘通过辅助柱:T柱放到A柱上
T.add(F.remove(F.size()-1));//2.此时F柱上仅剩下一个圆盘,将其放到目标柱:T柱上
recursion(A,F,T,n-1);//3.最后使用同样的方法将A柱上所有的圆盘通过辅助柱:F柱放到T柱上
}
}总结
翻看这篇文章的最后的讲解:Java算法题分享(一) ,这篇文章中的解法还加入了具体操作的打印等
二、合并两个有序链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
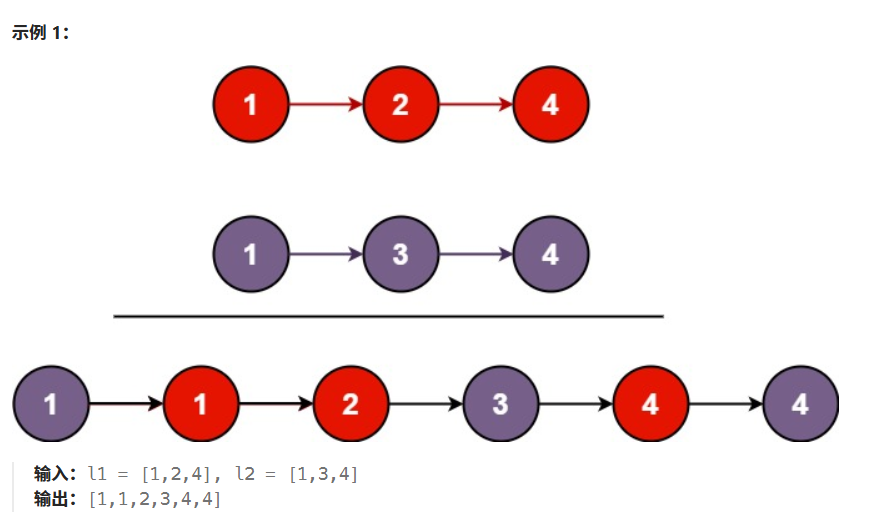
解题思路
- 按照原来双指针算法的解法,我们发现每次通过比较node.val 的值得出较小的节点之后,该节点就成为了"此后处理的节点的头节点",也就是说此后处理的节点都将以该节点为首,那么我们将剩下的两个链表合并,再连接到该节点的后面就行了。
- 这样我们就发现了该题目的这种"大问题--->子问题"的特性:每此通过比较node.val的值得出一个"首节点",再将剩下的两个链表合并连接到该"首节点"后面,"合并剩下的两个链表"就是相同的子问题。所以可用递归解题。
代码实现及解析
java
class Solution {
public ListNode mergeTwoLists(ListNode list1, ListNode list2) {
//递归结束条件:
if(list1==null) return list2;
if(list2==null) return list1;
if(list1.val<list2.val){
list1.next=mergeTwoLists(list1.next,list2);//把list1做为头节点
return list1;
}else{
list2.next=mergeTwoLists(list2.next,list1);//把list2做为头节点
return list2;
}
}
}总结
复习解题思路我们可以看到寻找题目"大问题--->子问题"这样的特性不是想当然地将一大块数据切割为一小部分数据,就这样得到了所谓的子问题,在有些题目中"子问题"可能也会这样简单地呈现,但也有些问题是需要我们对普通解题思路进行模拟,在其中发掘出解题过程中题目所呈现的"大问题--->子问题"特性
小总结
循环(迭代) VS 递归
- 我们知道递归和迭代是可以互相转化的,可是为什么呢?
- 因为不难发现递归和迭代都是在处理"重复的子问题"。迭代通过循环来不断地处理这个重复的子问题,递归通过一层一层的函数调用来处理重复的子问题。
那什么时候使用迭代好?什么时候使用递归好呢?
递归 VS dfs
-
在初学递归时为了方便理清递归的过程,我们通常会画出递归一层一层的函数展开图,而递归的顺序展开图就是一个树形结构(常见为二叉树),那么递归函数的一层一层的调用过程其实就相当于对该树进行一次深度优先遍历(dfs)
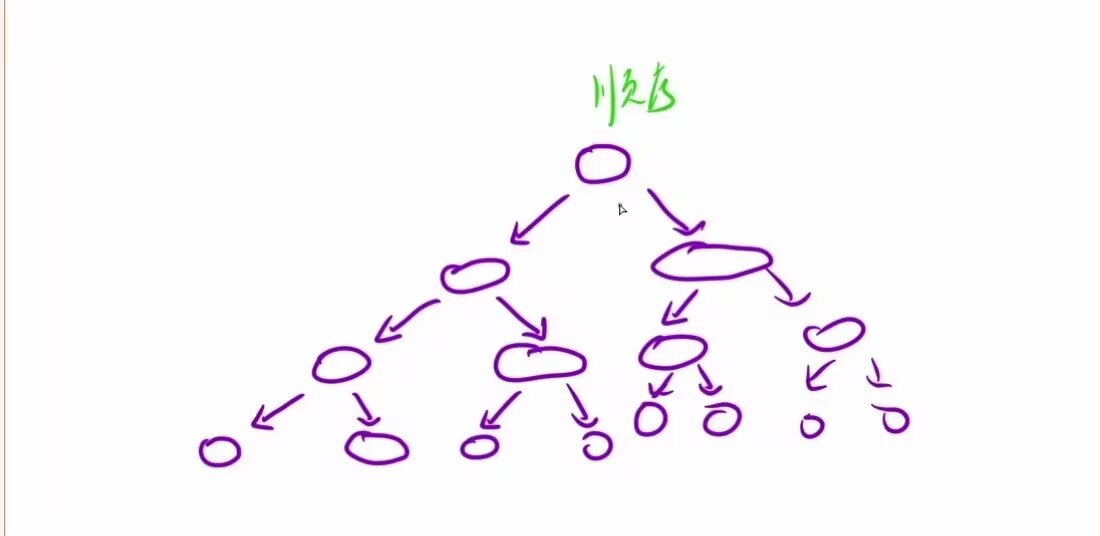
-
像上面这样函数递归展开图比较复杂的,就不适合改为迭代算法,因为改为迭代要用到Stack,处理起来也比较麻烦
-
而像下面这样的递归展开图为单分支树的就可以使用迭代来解决:
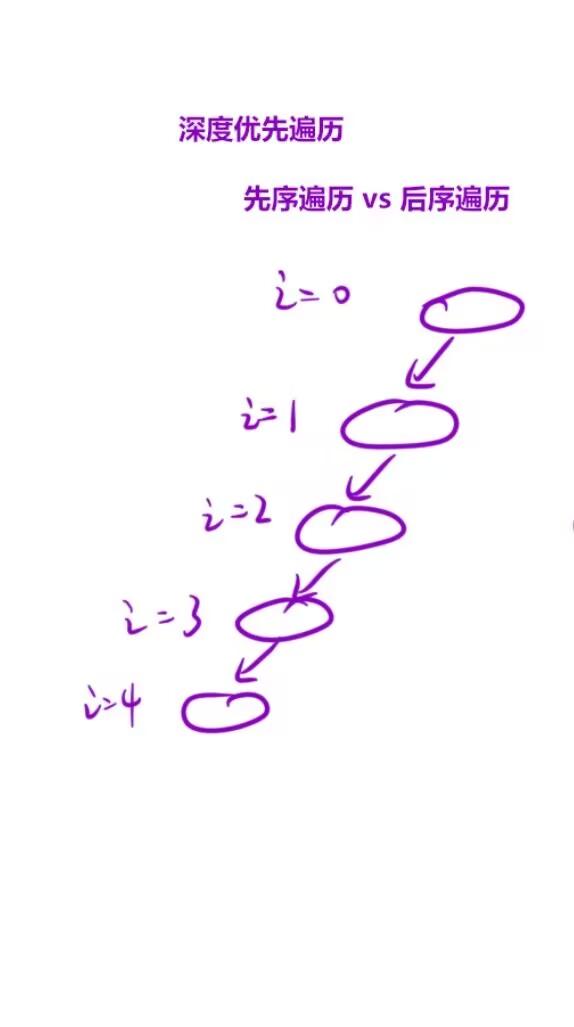
-
比如,最普通的数组的遍历,使用递归来解决的话,递归展开图就是单分支树
三、反转链表
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
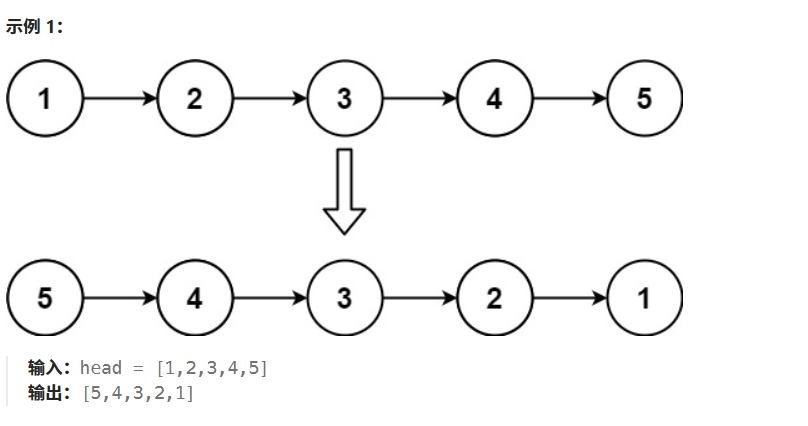
解题思路
- 使用递归算法,反转链表head--->先反转head后面的链表--->再将反转后的链表连接到head后面
代码实现及解析
java
class Solution {
public ListNode reverseList(ListNode head) {
if(head==null||head.next==null) return head;//递归结束条件
ListNode newHead=reverseList(head.next);//先将head后面的链表反转,并将新的头节点返回
head.next.next=head;//注意这里只能使用head寻找新链表的末尾
head.next=null;
return newHead;
}
}总结
复习解题思路,熟悉链表题目的这种递归解法套路
四、Pow(x, n) (快速幂)
实现 pow(x, n) ,即计算 x 的整数 n 次幂函数(即,xn )。
解题思路
- 如果使用循环一个一个的乘肯定超时,但是举例发现:316=2*38=2*34=2*32=2*31=2*30*3,所以就可以使用递归算法每次计算x的(n/2)次方,避免重复的计算,这就是
快速幂算法。
代码实现及解析
java
class Solution {
public double myPow(double x, int n) {
return n<0?1.0/pow(x,-n):pow(x,n);//n可能为负数
}
double pow(double x,int n){
if(n==0) return 1;//递归结束条件
double tmp=pow(x,n/2);
return n%2==0?tmp*tmp:tmp*tmp*x;//处理n值为奇偶数两种情况(奇数的话,tmp结果就少乘了一个x)
}
}总结
复习解题思路和代码注释