一、Kafka 概述
1.1 什么是 Kafka
Apache Kafka 是由 LinkedIn 开发并于 2011 年开源的分布式流处理平台 ,现由 Apache 软件基金会维护。它最初设计为高吞吐量的分布式消息系统 ,现已发展成为功能强大的事件流平台。
1.2 核心特性
| 特性 | 说明 |
|---|---|
| 高吞吐量 | 每秒可处理百万级消息 |
| 低延迟 | 消息发布到消费延迟可控制在毫秒级 |
| 可扩展性 | 支持水平扩展,动态添加 Broker |
| 持久性 | 消息持久化到磁盘,支持多副本机制 |
| 容错性 | 自动故障转移,数据不丢失 |
| 高并发 | 支持数千个客户端同时读写 |
1.3 核心概念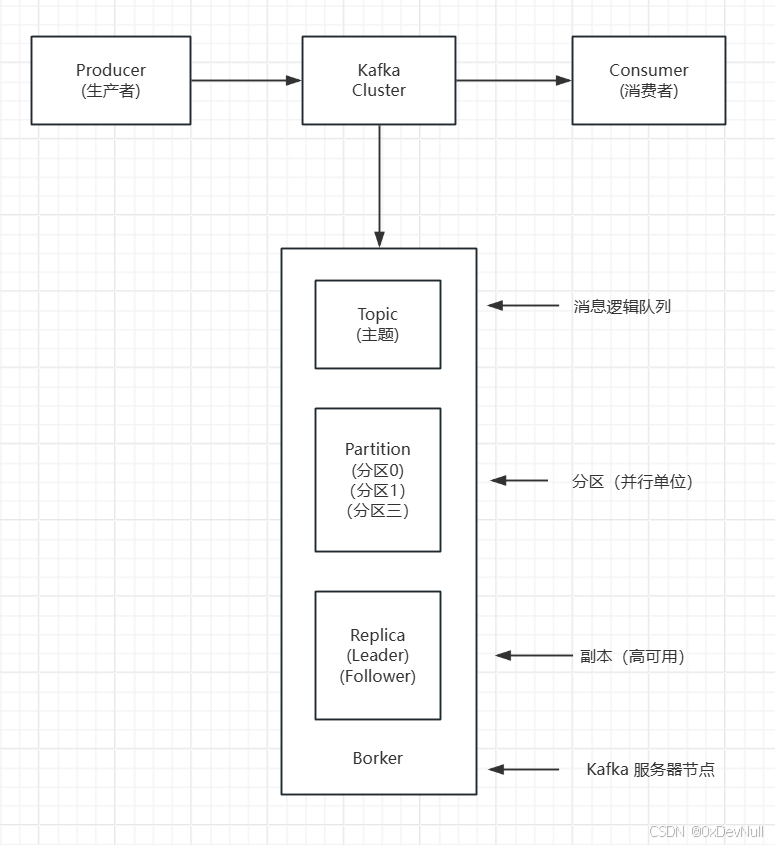
核心术语:
- Producer(生产者):向 Kafka 发送消息的应用程序
- Consumer(消费者):从 Kafka 读取消息的应用程序
- Consumer Group(消费者组):一组消费者共同消费一个 Topic
- Topic(主题):消息的分类名称,逻辑上的消息队列
- Partition(分区):Topic 的物理分片,实现并行处理
- Offset(偏移量):消息在分区中的唯一标识(位置)
- Broker(代理):Kafka 服务器节点,负责存储和转发消息
- ZooKeeper/KRaft:集群协调服务(新版使用 KRaft 替代 ZooKeeper)
二、核心原理
2.1 存储机制
Kafka 的消息存储采用顺序写磁盘方式,性能极高:
Partition 0 文件结构:
├── 00000000000000000000.log ← 消息数据文件(Segment 0)
├── 00000000000000000000.index ← 稀疏索引文件
├── 00000000000000356892.log ← Segment 1(达到 1GB 滚动)
├── 00000000000000356892.index
└── 00000000000000712345.log ← Segment 2
└── ...关键设计:
- Segment 分段:每个分区被划分为多个 Segment(默认 1GB)
- 顺序写入:追加写磁盘,避免随机 I/O
- 零拷贝(Zero-Copy) :通过
sendfile系统调用直接传输数据 - 页缓存(Page Cache):依赖 OS 缓存而非 JVM 堆内存
2.2 生产者原理
Producer 发送流程:
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 拦截器 │────▶│ 序列化器 │────▶│ 分区器 │
│Interceptor │ │Serializer │ │Partitioner │
└─────────────┘ └─────────────┘ └──────┬──────┘
│
┌────────────────────────┘
▼
┌─────────────────┐
│ RecordAccumulator │ ← 消息累加器(批量发送)
│ (32MB 缓冲区) │
└────────┬────────┘
│
┌────────▼────────┐
│ Sender 线程 │ ← 单独的 I/O 线程
│ (batch 发送) │
└────────┬────────┘
│
┌────────▼────────┐
│ Broker 集群 │
└─────────────────┘生产者关键配置:
| 参数 | 默认值 | 说明 |
|---|---|---|
acks |
1 |
确认机制:0(不等待)、1(Leader确认)、all(全部ISR确认) |
retries |
2147483647 |
发送失败重试次数 |
batch.size |
16384 |
批次大小(字节) |
linger.ms |
0 |
发送等待时间(配合 batch 使用) |
buffer.memory |
33554432 |
缓冲区总大小(32MB) |
compression.type |
none |
压缩类型:gzip、snappy、lz4、zstd |
分区策略:
- 指定分区:直接发送到指定分区
- 指定 Key :
hash(key) % partitionNum - 轮询(RoundRobin):无 Key 时轮流发送到各分区
- 粘性分区(Sticky):2.4+ 版本默认,减少延迟
2.3 消费者原理
Consumer Group 消费模型:
Topic: order-events (3 partitions)
Partition 0 ──────┐
├─ Consumer Group A ──┐
Partition 1 ──────┤ ├── Consumer 1 (消费 P0,P1)
│ │
Partition 2 ──────┘ ├── Consumer 2 (消费 P2)
│
└── 再平衡(Rebalance)
Partition 0 ──────┐
├─ Consumer Group B ──┐
Partition 1 ──────┤ ├── Consumer 3 (消费 P0)
│ │
Partition 2 ──────┘ ├── Consumer 4 (消费 P1,P2)消费者关键概念:
- Consumer Group:组内消费者共同消费一个 Topic,每条消息只被组内一个消费者消费
- Rebalance:消费者加入/退出时,分区重新分配
- Offset 管理 :消费位置存储在
__consumer_offsetsTopic 或外部系统
Offset 提交策略:
| 策略 | 配置 | 特点 |
|---|---|---|
| 自动提交 | enable.auto.commit=true |
定期提交,可能丢消息或重复消费 |
| 手动同步 | commitSync() |
阻塞直到成功,可靠性高 |
| 手动异步 | commitAsync() |
不阻塞,可能提交失败 |
| 自定义存储 | 存到数据库 | 实现 Exactly-Once 语义 |
2.4 副本机制(Replication)
ISR(In-Sync Replicas)机制:
┌─────────┐ ┌─────────┐ ┌─────────┐
│ Leader │◄───────►│Follower1│◄───────►│Follower2│
│ (ISR) │ 同步复制 │ (ISR) │ │ (非ISR) │
└────┬────┘ └─────────┘ └─────────┘
│
│ 写入流程(acks=all):
│ 1. Producer 发送消息到 Leader
│ 2. Leader 写入本地 log
│ 3. Leader 等待所有 ISR 副本同步完成
│ 4. 返回成功响应给 Producer关键配置:
replication.factor:副本因子(建议 ≥3)min.insync.replicas:最小同步副本数unclean.leader.election.enable:是否允许非 ISR 副本成为 Leader(默认 false,避免数据丢失)
三、适用场景
3.1 典型应用场景
| 场景 | 说明 | 示例 |
|---|---|---|
| 日志收集 | 聚合分布式系统的日志数据 | ELK 栈中的 Logstash → Kafka → Elasticsearch |
| 消息系统 | 解耦生产者和消费者 | 订单系统 → Kafka → 库存/支付/物流系统 |
| 流处理 | 实时数据处理和分析 | Kafka Streams / Flink 实时计算 |
| 事件溯源 | 记录系统状态变更事件 | 微服务架构中的事件总线 |
| 指标监控 | 实时采集和传输监控数据 | Prometheus → Kafka → 告警系统 |
3.2 与其他消息队列对比
| 特性 | Kafka | RabbitMQ | RocketMQ | Pulsar |
|---|---|---|---|---|
| 吞吐量 | 极高(百万级/秒) | 高(万级/秒) | 极高 | 极高 |
| 延迟 | 毫秒级 | 微秒级 | 毫秒级 | 毫秒级 |
| 消息持久化 | 是(长时间) | 是 | 是 | 是 |
| 消费模式 | Pull | Push/Pull | Pull | Push/Pull |
| 副本机制 | ISR | 镜像队列 | 主从同步 | 分层存储+多副本 |
| 事务消息 | 支持 | 支持 | 支持 | 支持 |
| 延迟消息 | 不支持(需插件) | 支持 | 支持 | 支持 |
| 社区活跃度 | 极高 | 高 | 中(阿里主导) | 中 |
| 云原生 | 良好 | 一般 | 一般 | 优秀 |
四、Spring Boot 集成实战
4.1 版本兼容性
Spring Boot 与 Kafka 版本对应关系:
| Spring Boot 版本 | Spring Kafka 版本 | Kafka Client 版本 | Java 版本 |
|---|---|---|---|
| 2.7.x | 2.8.x | 3.1.x | 8+ |
| 3.0.x | 3.0.x | 3.3.x | 17+ |
| 3.1.x | 3.1.x | 3.4.x | 17+ |
| 3.2.x | 3.2.x | 3.6.x | 17+ |
| 3.3.x | 3.3.x | 3.7.x | 17+ |
4.2 项目配置(Spring Boot 3.2.0 + Kafka 3.6.0)
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.0</version>
<relativePath/>
</parent>
<groupId>com.example</groupId>
<artifactId>kafka-demo</artifactId>
<version>1.0.0</version>
<properties>
<java.version>17</java.version>
<kafka.version>3.6.0</kafka.version>
</properties>
<dependencies>
<!-- Spring Boot Kafka Starter -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!-- Spring Boot Web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- JSON 处理 -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<!-- 测试 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
</project>application.yml:
spring:
kafka:
# =================== Producer 配置 ===================
producer:
bootstrap-servers: localhost:9092
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
# 可靠性配置
acks: all # 等待所有副本确认
retries: 3 # 发送失败重试次数
retry-backoff-ms: 1000 # 重试间隔
# 性能配置
batch-size: 16384 # 批次大小 16KB
buffer-memory: 33554432 # 缓冲区 32MB
compression-type: snappy # 压缩算法
properties:
linger.ms: 5 # 等待时间,配合 batch 使用
enable.idempotence: true # 幂等性(防止重复发送)
max.in.flight.requests.per.connection: 5 # 允许未确认请求数
# =================== Consumer 配置 ===================
consumer:
bootstrap-servers: localhost:9092
group-id: order-service-group
auto-offset-reset: earliest # 无偏移量时从最早开始
enable-auto-commit: false # 关闭自动提交(手动提交更可靠)
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
properties:
spring.json.trusted.packages: com.example.kafka.dto # 信任包路径
max.poll.records: 500 # 单次 poll 最大消息数
max.poll.interval.ms: 300000 # 两次 poll 最大间隔(消费者心跳)
# =================== Listener 配置 ===================
listener:
ack-mode: manual_immediate # 手动立即确认
concurrency: 3 # 并发消费者数(对应分区数)
type: single # single/batch 监听模式
# 自定义 Topic 配置
kafka:
topics:
order-created: order-created-events
order-completed: order-completed-events
dlq: order-events-dlq # 死信队列4.3 核心代码实现
DTO 类:
package com.example.kafka.dto;
import java.math.BigDecimal;
import java.time.LocalDateTime;
public record OrderEvent(
String orderId,
String userId,
BigDecimal amount,
String status, // CREATED, PAID, SHIPPED, COMPLETED
LocalDateTime timestamp,
String traceId // 用于链路追踪
) {}Producer 配置类:
package com.example.kafka.config;
import org.apache.kafka.clients.admin.NewTopic;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.config.TopicConfig;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.TopicBuilder;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import org.springframework.kafka.support.serializer.JsonSerializer;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class KafkaProducerConfig {
@Value("${spring.kafka.producer.bootstrap-servers}")
private String bootstrapServers;
@Bean
public ProducerFactory<String, Object> producerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
org.apache.kafka.common.serialization.StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
// 幂等性配置(精确一次语义)
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
props.put(ProducerConfig.ACKS_CONFIG, "all");
props.put(ProducerConfig.RETRIES_CONFIG, Integer.MAX_VALUE);
props.put(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, 5);
// 事务配置(如需事务)
// props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "order-producer-");
return new DefaultKafkaProducerFactory<>(props);
}
@Bean
public KafkaTemplate<String, Object> kafkaTemplate() {
KafkaTemplate<String, Object> template = new KafkaTemplate<>(producerFactory());
// 设置默认 Topic
template.setDefaultTopic("default-topic");
return template;
}
// 定义 Topic(生产环境建议在 Kafka 管理工具中创建)
@Bean
public NewTopic orderCreatedTopic() {
return TopicBuilder.name("order-created-events")
.partitions(6) // 6 个分区,支持 6 个并发消费者
.replicas(3) // 3 个副本
.config(TopicConfig.RETENTION_MS_CONFIG, "604800000") // 保留 7 天
.config(TopicConfig.MIN_INSYNC_REPLICAS_CONFIG, "2") // 最小同步副本
.build();
}
@Bean
public NewTopic orderCompletedTopic() {
return TopicBuilder.name("order-completed-events")
.partitions(6)
.replicas(3)
.build();
}
// 死信队列(用于处理失败消息)
@Bean
public NewTopic deadLetterTopic() {
return TopicBuilder.name("order-events-dlq")
.partitions(1)
.replicas(3)
.config(TopicConfig.RETENTION_MS_CONFIG, "2592000000") // 保留 30 天
.build();
}
}Consumer 配置类:
package com.example.kafka.config;
import com.example.kafka.dto.OrderEvent;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.listener.ConcurrentMessageListenerContainer;
import org.springframework.kafka.listener.ContainerProperties;
import org.springframework.kafka.listener.DefaultErrorHandler;
import org.springframework.kafka.support.serializer.ErrorHandlingDeserializer;
import org.springframework.kafka.support.serializer.JsonDeserializer;
import org.springframework.util.backoff.FixedBackOff;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class KafkaConsumerConfig {
@Value("${spring.kafka.consumer.bootstrap-servers}")
private String bootstrapServers;
@Value("${spring.kafka.consumer.group-id}")
private String groupId;
@Bean
public ConsumerFactory<String, OrderEvent> consumerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
// 心跳配置
props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 3000);
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10000);
// 反序列化器配置
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class);
// 错误处理反序列化器(防止因格式错误导致消费者停止)
props.put(ErrorHandlingDeserializer.KEY_DESERIALIZER_CLASS, StringDeserializer.class);
props.put(ErrorHandlingDeserializer.VALUE_DESERIALIZER_CLASS, JsonDeserializer.class);
// JSON 信任包
props.put(JsonDeserializer.TRUSTED_PACKAGES, "com.example.kafka.dto");
props.put(JsonDeserializer.VALUE_DEFAULT_TYPE, OrderEvent.class.getName());
props.put(JsonDeserializer.USE_TYPE_INFO_HEADERS, false);
return new DefaultKafkaConsumerFactory<>(props);
}
@Bean
public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, OrderEvent>>
kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, OrderEvent> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
// 并发度(应小于等于分区数)
factory.setConcurrency(3);
// 手动提交模式
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
// 批量消费(可选)
// factory.setBatchListener(true);
// 错误处理(重试 3 次,间隔 1 秒,之后发送到死信队列)
DefaultErrorHandler errorHandler = new DefaultErrorHandler(
new FixedBackOff(1000L, 3L)
);
errorHandler.addNotRetryableExceptions(IllegalArgumentException.class); // 立即跳过的异常
factory.setCommonErrorHandler(errorHandler);
return factory;
}
}Producer Service:
package com.example.kafka.service;
import com.example.kafka.dto.OrderEvent;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Service;
import java.util.concurrent.CompletableFuture;
@Slf4j
@Service
@RequiredArgsConstructor
public class OrderProducerService {
private final KafkaTemplate<String, Object> kafkaTemplate;
@Value("${kafka.topics.order-created}")
private String orderCreatedTopic;
/**
* 异步发送(推荐)
*/
public void sendOrderEventAsync(OrderEvent event) {
// 使用 orderId 作为 key,确保同一订单的消息进入同一分区(顺序性)
CompletableFuture<SendResult<String, Object>> future =
kafkaTemplate.send(orderCreatedTopic, event.orderId(), event);
future.whenComplete((result, ex) -> {
if (ex == null) {
log.info("消息发送成功: topic={}, partition={}, offset={}, key={}",
result.getRecordMetadata().topic(),
result.getRecordMetadata().partition(),
result.getRecordMetadata().offset(),
event.orderId());
} else {
log.error("消息发送失败: key={}, error={}", event.orderId(), ex.getMessage());
// 可在此处实现补偿机制(如存入数据库定时重试)
}
});
}
/**
* 同步发送(不推荐,阻塞性能差)
*/
public void sendOrderEventSync(OrderEvent event) throws Exception {
SendResult<String, Object> result =
kafkaTemplate.send(orderCreatedTopic, event.orderId(), event).get();
log.info("同步发送成功: offset={}", result.getRecordMetadata().offset());
}
/**
* 带事务的发送(多 Topic 原子写入)
*/
public void sendInTransaction(OrderEvent createdEvent, OrderEvent completedEvent) {
kafkaTemplate.executeInTransaction(operations -> {
operations.send(orderCreatedTopic, createdEvent.orderId(), createdEvent);
operations.send("order-completed-events", completedEvent.orderId(), completedEvent);
return true;
});
}
}Consumer Service:
package com.example.kafka.service;
import com.example.kafka.dto.OrderEvent;
import lombok.extern.slf4j.Slf4j;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.annotation.RetryableTopic;
import org.springframework.kafka.annotation.TopicRetryable;
import org.springframework.kafka.annotation.DltHandler;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.messaging.handler.annotation.Payload;
import org.springframework.retry.annotation.Backoff;
import org.springframework.stereotype.Service;
@Slf4j
@Service
public class OrderConsumerService {
/**
* 基础消费(手动 ACK)
*/
@KafkaListener(
topics = "${kafka.topics.order-created}",
groupId = "${spring.kafka.consumer.group-id}",
containerFactory = "kafkaListenerContainerFactory"
)
public void consumeOrderCreated(
@Payload OrderEvent event,
Acknowledgment acknowledgment,
@Header(KafkaHeaders.RECEIVED_PARTITION) int partition,
@Header(KafkaHeaders.OFFSET) long offset,
@Header(KafkaHeaders.RECEIVED_KEY) String key) {
log.info("收到订单创建事件: orderId={}, partition={}, offset={}, key={}",
event.orderId(), partition, offset, key);
try {
// 业务处理
processOrder(event);
// 手动确认(提交 offset)
acknowledgment.acknowledge();
log.debug("消息确认成功: offset={}", offset);
} catch (Exception e) {
log.error("消息处理失败: orderId={}, error={}", event.orderId(), e.getMessage());
// 不调用 acknowledge(),消息会重新消费(根据配置可能进入死信队列)
throw e; // 抛出异常触发重试或死信
}
}
/**
* 带重试策略的消费(声明式)
*/
@RetryableTopic(
attempts = "4", // 1 次原始 + 3 次重试
backoff = @Backoff(delay = 1000, multiplier = 2), // 1s, 2s, 4s 间隔
include = {RuntimeException.class}, // 只对运行时异常重试
notRetryableExceptions = {IllegalArgumentException.class},
dltTopicSuffix = "-dlt" // 死信队列后缀
)
@KafkaListener(topics = "${kafka.topics.order-completed}", groupId = "inventory-group")
public void consumeOrderCompletedWithRetry(OrderEvent event) {
log.info("处理订单完成事件: {}", event.orderId());
updateInventory(event);
}
/**
* 死信队列处理器
*/
@DltHandler
public void handleDlt(OrderEvent event,
@Header(KafkaHeaders.RECEIVED_TOPIC) String topic,
@Header(KafkaHeaders.EXCEPTION_FQCN) String exception) {
log.error("死信队列消息: topic={}, orderId={}, exception={}",
topic, event.orderId(), exception);
// 持久化到数据库或发送告警
saveToDeadLetterTable(event, topic, exception);
}
// ============ 业务方法 ============
private void processOrder(OrderEvent event) {
// 订单处理逻辑
if (event.amount().doubleValue() < 0) {
throw new IllegalArgumentException("订单金额不能为负");
}
// ...
}
private void updateInventory(OrderEvent event) {
// 库存更新逻辑
}
private void saveToDeadLetterTable(OrderEvent event, String topic, String error) {
// 保存到死信表
}
}4.4 高级特性
Kafka Streams 集成(实时处理):
@Configuration
@EnableKafkaStreams
public class KafkaStreamsConfig {
@Bean
public KStream<String, OrderEvent> orderStream(StreamsBuilder builder) {
KStream<String, OrderEvent> stream = builder.stream("order-created-events");
// 实时过滤和转换
stream.filter((key, value) -> value.amount().doubleValue() > 1000)
.mapValues(this::enrichOrderData)
.to("high-value-orders", Produced.with(Serdes.String(), orderEventSerde()));
return stream;
}
private OrderEvent enrichOrderData(OrderEvent event) {
// 添加额外信息
return new OrderEvent(
event.orderId(),
event.userId(),
event.amount(),
event.status(),
event.timestamp(),
UUID.randomUUID().toString() // 生成新的 traceId
);
}
}五、完整案例
5.1 电商订单系统实战
场景: 用户下单后,订单服务发送事件,库存服务扣减库存,支付服务处理支付,物流服务安排发货。
架构图:
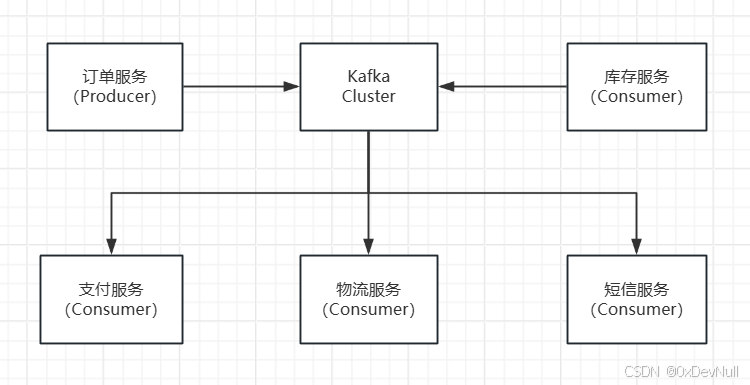
订单服务(Producer):
@RestController
@RequestMapping("/api/orders")
@RequiredArgsConstructor
public class OrderController {
private final OrderProducerService producerService;
private final OrderRepository orderRepository;
@PostMapping
public ResponseEntity<String> createOrder(@RequestBody CreateOrderRequest request) {
// 1. 保存订单到数据库
Order order = orderRepository.save(request.toEntity());
// 2. 构建事件
OrderEvent event = new OrderEvent(
order.getId(),
order.getUserId(),
order.getAmount(),
"CREATED",
LocalDateTime.now(),
MDC.get("traceId")
);
// 3. 发送 Kafka 事件(异步)
producerService.sendOrderEventAsync(event);
return ResponseEntity.ok(order.getId());
}
}库存服务(Consumer):
@Service
@Slf4j
public class InventoryConsumer {
@Autowired
private InventoryService inventoryService;
@KafkaListener(
topics = "order-created-events",
groupId = "inventory-service",
containerFactory = "kafkaListenerContainerFactory"
)
public void handleOrderCreated(
@Payload OrderEvent event,
Acknowledgment ack) {
log.info("[库存服务] 收到订单: {}", event.orderId());
try {
// 扣减库存
boolean success = inventoryService.deductStock(event.orderId(), event.userId());
if (success) {
ack.acknowledge();
log.info("[库存服务] 库存扣减成功: {}", event.orderId());
} else {
// 库存不足,发送补偿事件
sendStockInsufficientEvent(event);
ack.acknowledge();
}
} catch (Exception e) {
log.error("[库存服务] 处理失败: {}", event.orderId(), e);
throw e; // 触发重试
}
}
private void sendStockInsufficientEvent(OrderEvent event) {
// 发送库存不足事件到补偿 Topic
}
}5.2 测试用例
@SpringBootTest
@EmbeddedKafka(
partitions = 1,
topics = {"order-test-topic"},
brokerProperties = {
"listeners=PLAINTEXT://localhost:9092",
"port=9092"
}
)
class KafkaIntegrationTest {
@Autowired
private OrderProducerService producerService;
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
@Value("${kafka.topics.order-created}")
private String topic;
@Test
void testSendAndReceive() throws InterruptedException {
// 发送测试消息
OrderEvent event = new OrderEvent(
"TEST-001", "USER-001",
new BigDecimal("199.99"),
"CREATED",
LocalDateTime.now(),
"TRACE-001"
);
producerService.sendOrderEventAsync(event);
// 验证消费(使用 @KafkaListener 测试或 KafkaTemplate 接收)
// ...
}
}六、常见问题与排错
6.1 生产者问题
| 问题 | 原因 | 解决方案 |
|---|---|---|
TimeoutException |
Broker 不可用或网络问题 | 检查 Broker 状态、网络连通性、防火墙 |
RecordTooLargeException |
消息超过 max.request.size |
增大配置或压缩消息、拆分消息 |
SerializationException |
序列化失败 | 检查 DTO 是否实现 Serializable,配置正确的 Serializer |
NotEnoughReplicasException |
ISR 副本不足 | 检查 Broker 状态,降低 min.insync.replicas |
| 消息丢失 | acks=0 或异步发送未处理异常 |
设置 acks=all,添加发送回调处理 |
6.2 消费者问题
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 重复消费 | 自动提交 offset 失败,Rebalance | 关闭自动提交,手动提交;减少 max.poll.records |
| 消息积压 | 消费速度慢于生产速度 | 增加消费者实例(不超过分区数)、优化消费逻辑、扩容分区 |
| Rebalance 频繁 | 消费者心跳超时、处理时间过长 | 增大 session.timeout.ms,减少 max.poll.records,加快处理速度 |
| 消费停滞 | 消费者线程阻塞 | 检查死锁、I/O 阻塞,使用异步处理 |
DeserializationException |
消息格式不匹配 | 配置 ErrorHandlingDeserializer,检查 DTO 结构 |
6.3 集群问题
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 数据不一致 | Leader 切换导致 | 设置 unclean.leader.election.enable=false |
| 磁盘满 | 日志保留时间过长 | 调整 retention.ms 或 retention.bytes,扩容磁盘 |
| 性能下降 | 页缓存不足、磁盘 I/O 高 | 增加内存、使用 SSD、优化 log.segment.bytes |
| ZooKeeper 连接失败 | ZK 集群不稳定 | 检查 ZK 状态,升级到 KRaft 模式(Kafka 3.0+) |
6.4 排查命令
# 查看 Topic 列表
kafka-topics.sh --bootstrap-server localhost:9092 --list
# 查看 Topic 详情(分区、副本、ISR)
kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic order-events
# 查看消费者组状态
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group order-service-group
# 查看消费偏移量
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group order-service-group --offsets
# 生产测试消息
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test-topic \
--property "parse.key=true" --property "key.separator=:"
# 消费测试消息
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test-topic \
--from-beginning --group test-group
# 查看日志片段信息
kafka-run-class.sh kafka.tools.DumpLogSegments --files /tmp/kafka-logs/order-events-0/00000000000000000000.log --print-data-log
# 性能测试
kafka-producer-perf-test.sh --topic test --num-records 100000 --record-size 1000 \
--throughput -1 --producer-props bootstrap.servers=localhost:90926.5 监控指标
关键 JMX 指标:
| 指标 | 说明 | 告警阈值 |
|---|---|---|
kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec |
每秒入站消息数 | 根据业务设定 |
kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec |
每秒出站字节数 | - |
kafka.consumer:type=consumer-fetch-manager-metrics,client-id=*,attribute=records-lag-max |
消费者最大延迟 | > 10000 |
kafka.server:type=ReplicaManager,name=UnderReplicatedPartitions |
未充分复制的分区数 | > 0 |
kafka.controller:type=KafkaController,name=OfflinePartitionsCount |
离线分区数 | > 0 |
kafka.log:type=LogFlushStats,name=LogFlushRateAndTimeMs |
刷盘速率 | 延迟 > 1000ms |
Prometheus + Grafana 监控配置:
# kafka-jmx-exporter.yml
lowercaseOutputName: true
rules:
- pattern: kafka.server<type=(.+), name=(.+)PerSec\\w*><>Count
name: kafka_server_$1_$2_total
- pattern: kafka.consumer<type=consumer-fetch-manager-metrics, client-id=(.+)><>records-lag-max
name: kafka_consumer_records_lag_max
labels:
client_id: $1总结
Apache Kafka 是一个功能强大的分布式流处理平台,适用于高吞吐量、低延迟的消息场景。在 Spring Boot 中集成时,重点注意:
- 版本兼容性:Spring Boot 3.x 需要 Kafka Client 3.3+
- 可靠性配置 :
acks=all、enable.idempotence=true - 消费模式:关闭自动提交,使用手动 ACK
- 异常处理:配置死信队列(DLT)和重试策略
- 监控告警:关注消费延迟、Rebalance 频率、ISR 状态