
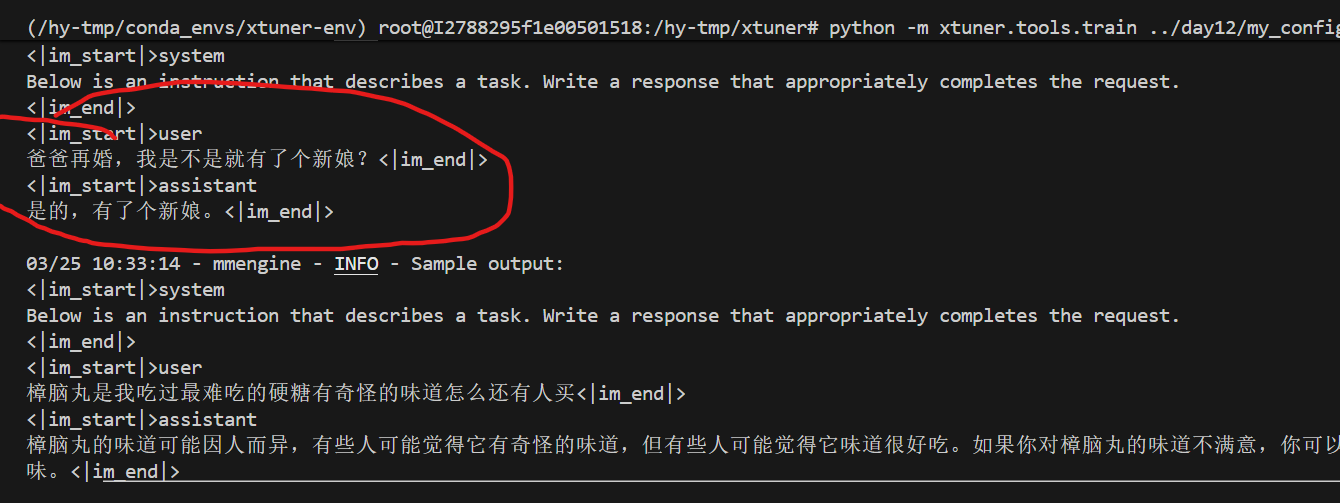
训练前
500轮训练后
xtuner命令不存在
版本:0.2.0存在
回退到0.2.0rc0版本,注意这个版本的依赖固定
bitsandbytes==0.45.0 datasets>=3.2.0 einops loguru mmengine==0.10.6 openpyxl peft>=0.14.0 scikit-image scipy SentencePiece tiktoken torch==2.5.1 torchvision==0.20.1 transformers==4.48.0 transformers_stream_generator

一、大模型分布式训练的基本概念
1.1 为什么需要分布式训练?
模型规模爆炸:现代大模型(如GPT-3、 LLaMA等)参数量达千亿级别,单卡GPU无法存储完整模型。
计算资源需求:训练大模型需要海量计算(如GPT-3需数万GPU小时),分布式训练可加速训练过程。
内存瓶颈:单卡显存不足以容纳大模型参数、梯度及优化器状态。
1.2 分布式训练的核心技术
数据并行(Data Parallelism)
原理:将数据划分为多个批次,分发到不同设备,每个设备拥有完整的模型副本。
同步方式:通过All-Reduce操作同步梯度(如PyTorch的DistributedDataParallel)。
挑战:通信开销大,显存占用高(需存储完整模型参数和优化器状态)。
模型并行(Model Parallelism)
原理:将模型切分到不同设备(如按层或张量分片)。
类型:
横向并行(层拆分):将模型的层分配到不同设备。
纵向并行(张量拆分):如Megatron-LM将矩阵乘法分片。
挑战:设备间通信频繁,负载均衡需精细设计。
流水线并行(Pipeline Parallelism)
原理:将模型按层划分为多个阶段(stage),数据分块后按流水线执行。
优化:微批次 (Micro-batching)减少流水线气泡(Bubble)
挑战:需平衡阶段划分,避免资源闲置。
混合并行(3D并行)
组合策略:结合数据并行、模型并行、流水线并行,典型应用如训练千亿级模型。
案例:微软Turing-NLG、Meta的LLaMA-2。

二、DeepSpeed框架介绍
2.1 DeepSpeed概述
定位:微软开源的分布式训练优化框架,支持千亿参数模型训练。
核心目标:降低大模型训练成本,提升显存和计算效率。
集成生态:与PyTorch无缝兼容,支持Hugging FaceTransformers库
2.2 核心技术
ZeRO(Zero Redundancy Optimizer)
原理:通过分片优化器状态、梯度、参数,消除数据并行中的显存冗余。
阶段划分:
ZeRO-1:优化器状态分片。
ZeRO-2:梯度分片 + 优化器状态分片。
ZeRO-3:参数分片 + 梯度分片 + 优化器状态分片。
优势:显存占用随设备数线性下降,支持训练更大模型。

2.3显存优化技术
梯度检查点(Activation Checkpointing) 用时间换空间,减少激活值显存占用。
CPU Offloading:将优化器状态和梯度卸载到CPU内存。
混合精度训练:FP16/BP16与动态损失缩放(Loss Scaling)
其他特性
大规模推理支持:模型并行推理(如ZeRO-Inference)。
自适应通信优化:自动选择最佳通信策略(如All-Reduce vs. All-Gather)。 (
2.4 优势与特点
显存效率高:ZeRO-3可将显存占用降低至1/设备数。
易用性强:通过少量代码修改即可应用(如DeepSpeed配置JSON文件)。
扩展性优秀:支持千卡级集群训练。
开源社区支持:持续更新,与Hugging Face等生态深度集成。
2.5 使用场景
训练百亿/千亿参数模型(如GPT-3、Turing-NLG) C
资源受限环境:单机多卡训练时通过Offloading扩展模型规模。
快速实验:通过ZeRO-2加速中等规模模型训练。
三、xtuner微调大模型教程

1.构建虚拟环境
拉取 XTuner,过程大约需要几分钟
python
git clone https://github.com/InternLM/xtuner.git
python
# 查看pip缓存大小和位置
pip cache info
# 清理整个pip缓存
pip cache purge建议执行
# 设置 pip 的缓存目录和系统的临时目录到 /hy-tmp export PIP_CACHE_DIR=/hy-tmp/pip_cache export TMPDIR=/hy-tmp/tmp # 确保这些目录存在 mkdir -p $PIP_CACHE_DIR $TMPDIR # 验证环境变量已设置 echo "PIP_CACHE_DIR = $PIP_CACHE_DIR" echo "TMPDIR = $TMPDIR"
conda create --name xtuner-env python=3.10 -y
conda activate xtuner-env 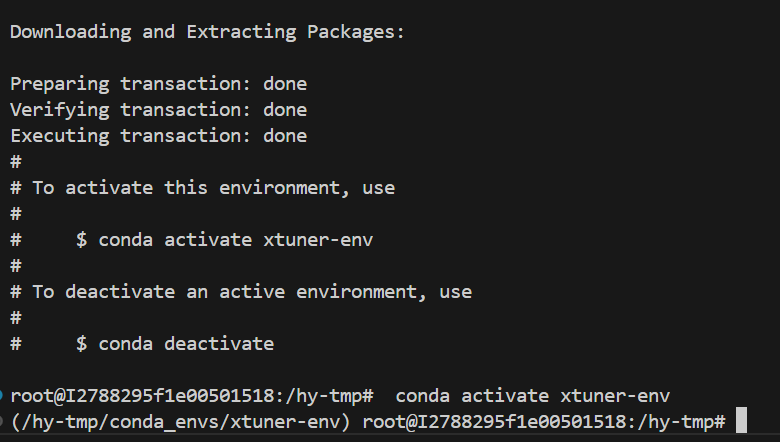
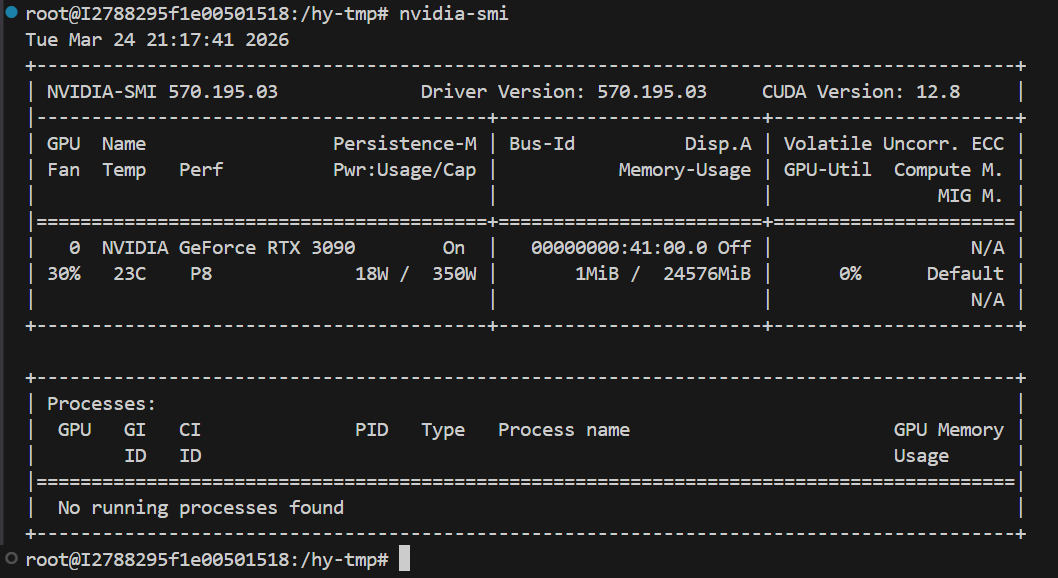
先查看显卡的版本,然后去官网下载对应的
pythonnvidia-smihttps://pytorch.org/get-started/previous-versions/
python# 验证安装 python -c "import torch; print(f'PyTorch版本: {torch.__version__}'); print(f'CUDA可用: {torch.cuda.is_available()}'); print(f'CUDA版本: {torch.version.cuda}')"
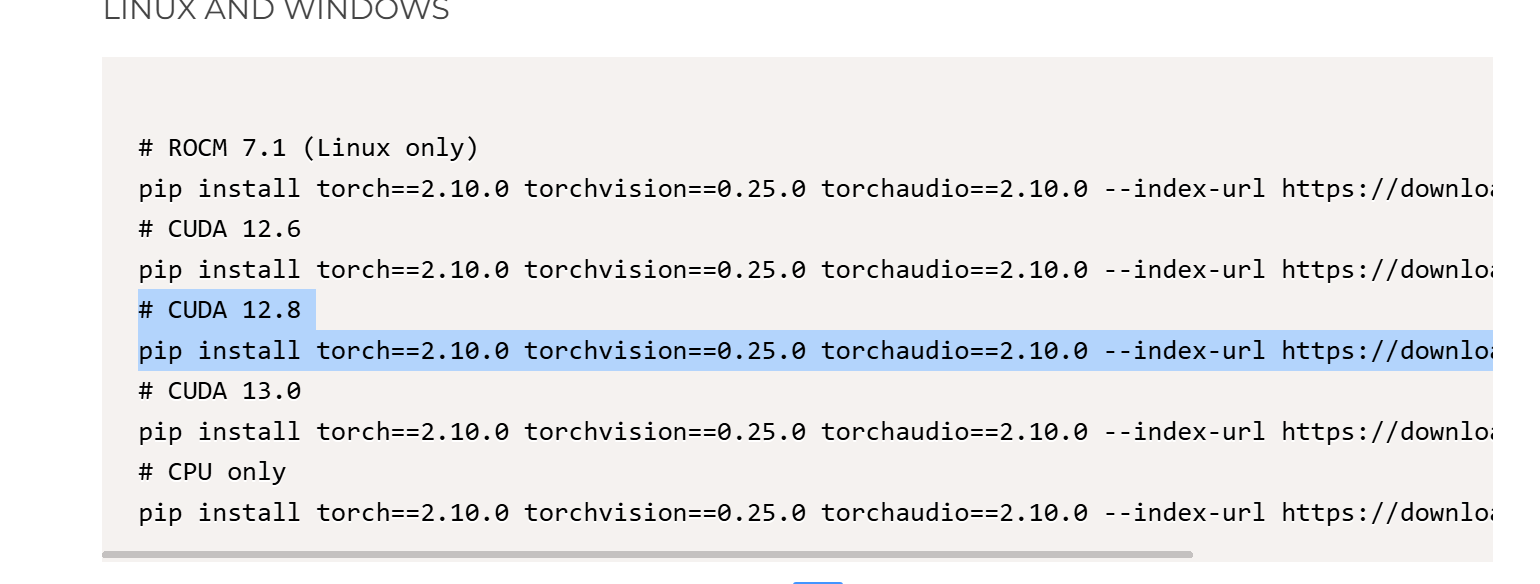

然后安装依赖的软件,这步需要的时间比较长。注意版本号
cd xtuner
pip install -e '.[all]'如果环境不通,请看附件
等以上所有步骤完成后,再进行下面的操作。
2.下载模型
pythonfrom modelscope import snapshot_download model_dir = snapshot_download('Shanghai_AI_Laboratory/internlm2-chat1_8b',cache_dir='/root/llm/internlm2-1.8b-chat')
官方支持的模型名称
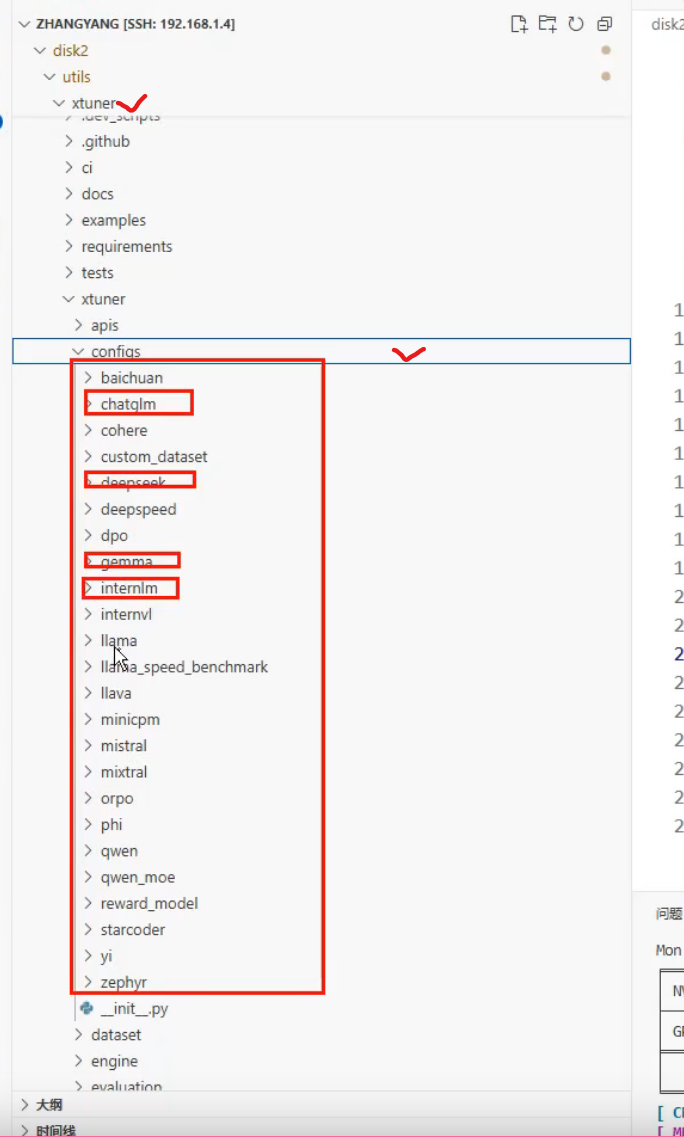
3.数据集
xtuner支持很多数据集,但是性能更高的是默认的数据集
社区数据集json样式xtune的格式

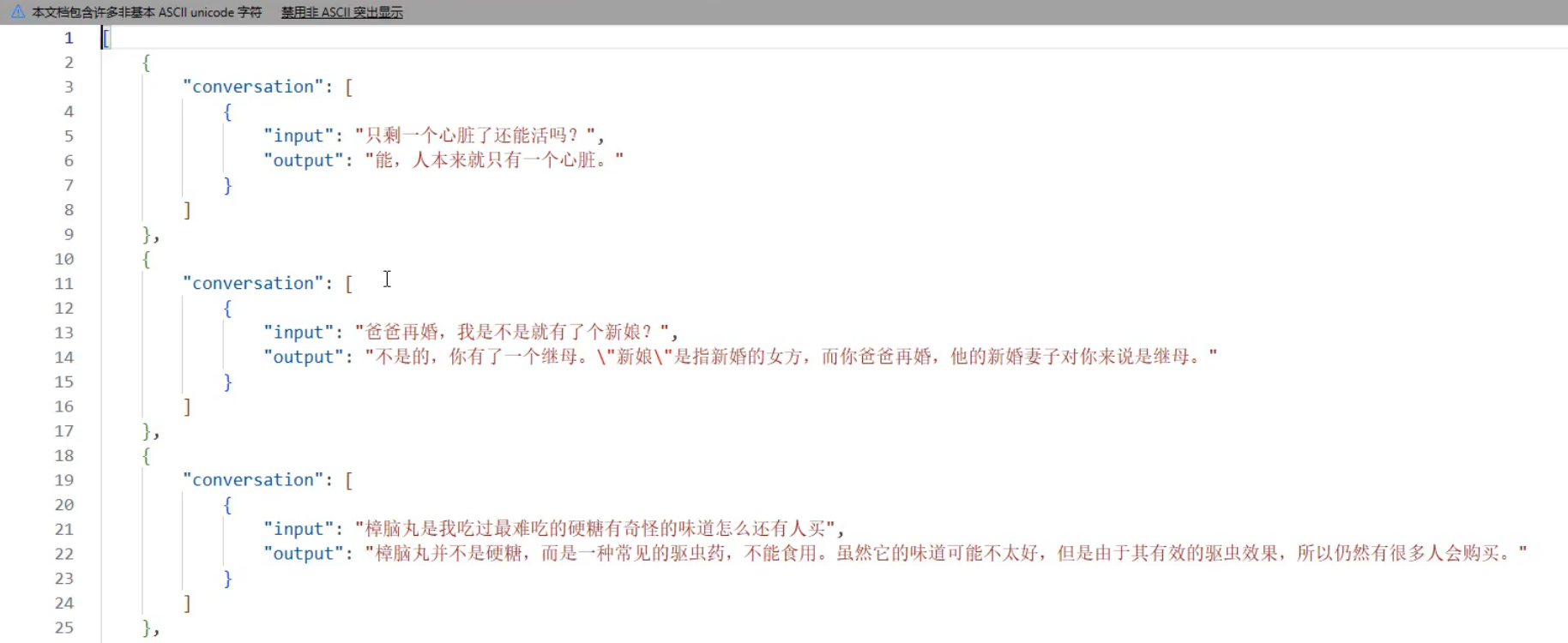
转换脚本
pythonimport json # 源数据文件路径 source_file = 'data/ruozhiba_qaswift.json' # 目标数据文件路径 target_file = 'data/target_data.json' # 读取源数据 with open(source_file, 'r', encoding='utf-8') as f: source_data = json.load(f) # 转换数据 target_data = [] for item in source_data: conversation = { "conversation": [ { "input": item["query"], "output": item["response"] } ] } target_data.append(conversation) # 保存转换后的数据 with open(target_file, 'w', encoding='utf-8') as f: json.dump(target_data, f, ensure_ascii=False, indent=4) print(f"数据已成功转换并保存到 {target_file}")
4.微调
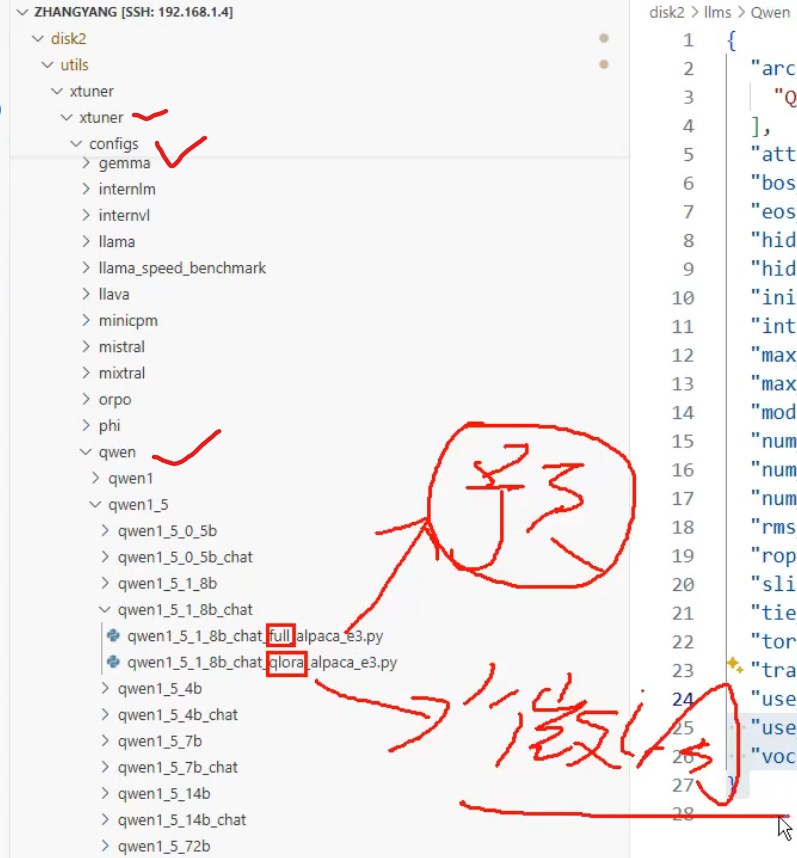
创建微调训练相关的配置文件在左侧的文件列表,xtuner 的文件夹里,打开
xtuner/xtuner/configs/internlm/internlm2_chat_1_8b/internlm2_chat_1_8b_qlora_alpaca_e3.py, 复制一份至根目录。
这里有预训练、微调的模版
打开这个文件,然后修改预训练模型地址,数据文件地址等。
注意对话模版是否匹配
权重的保存,500次,存最后两个(要存第三个,会自己删除第一个),如果想全保存,2改成-1
Q_lora的设置,如果不用将dict改成None
lora的参数
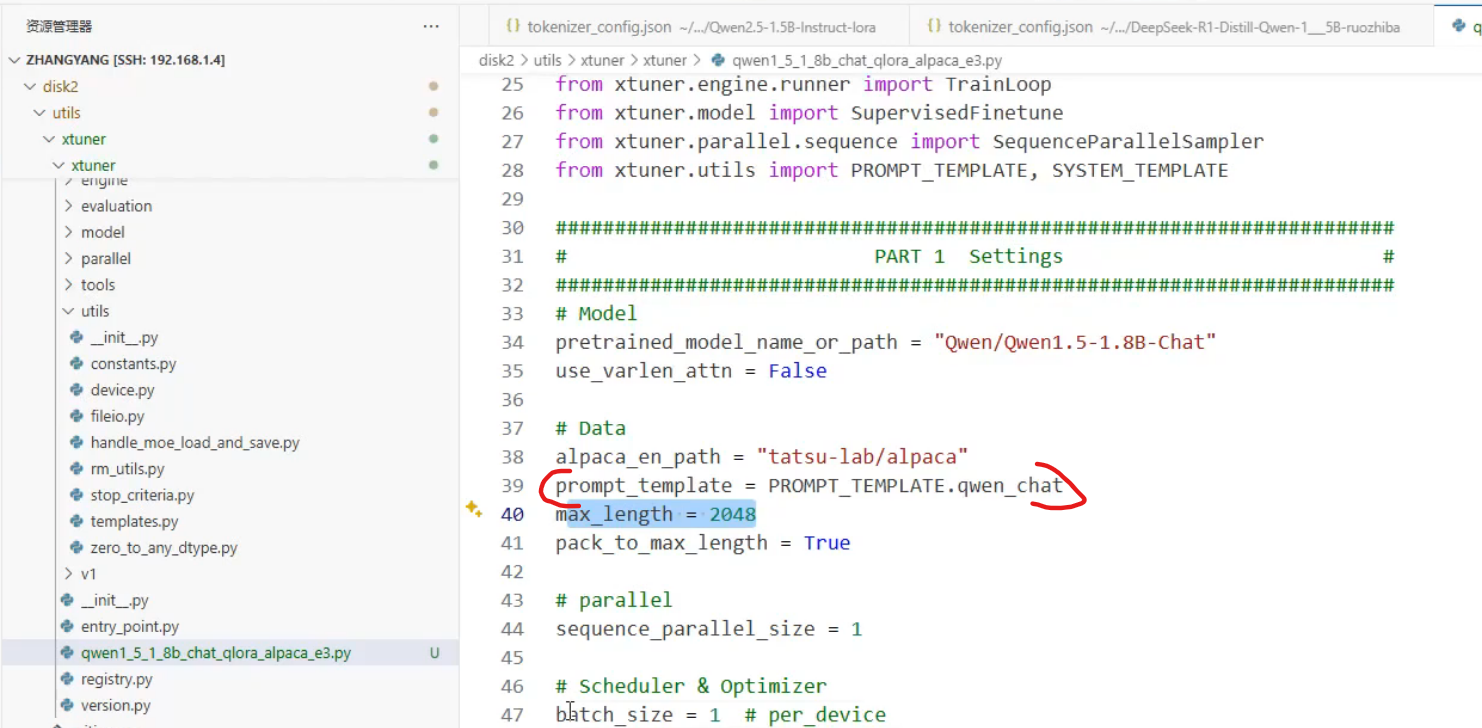

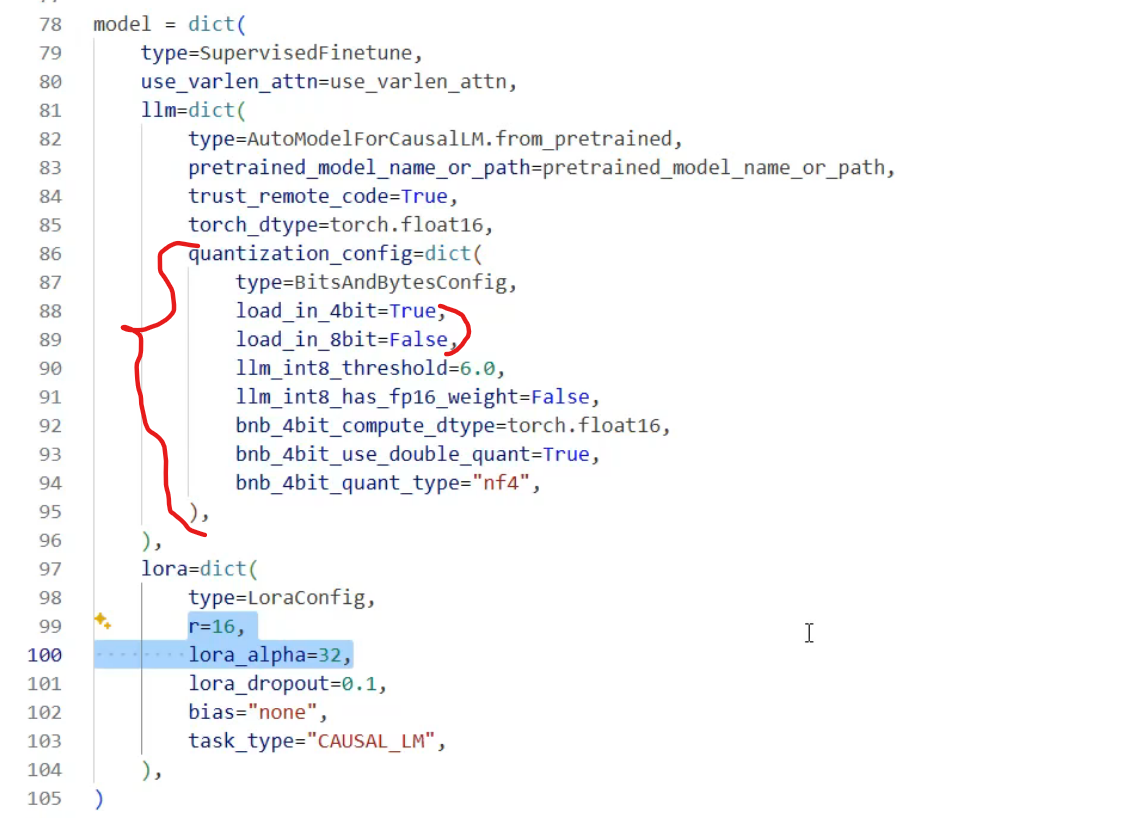
python
### PART 1中
#预训练模型存放的位置
pretrained_model_name_or_path = '/root/llm/internlm2-1.8b-chat'#基座模型路径
#微调数据存放的位置
alpaca_en_path = "tatsu-lab/alpaca"
# 训练中最大的文本长度
max_length = 512
# 每一批训练样本的大小
batch_size = 2
#最大训练轮数
max_epochs = 3
#验证数据
evaluation_inputs = [
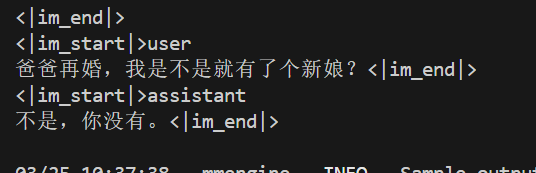
'只剩一个心脏了还能活吗?', '爸爸再婚,我是不是就有了个新娘?',
'樟脑丸是我吃过最难吃的硬糖有奇怪的味道怎么还有人买','马上要上游泳课了,昨天洗的泳裤还没
干,怎么办',
'我只出生了一次,为什么每年都要庆生'
]
# PART 3中
dataset=dict(type=load_dataset, path="json", data_files=alpaca_en_path)
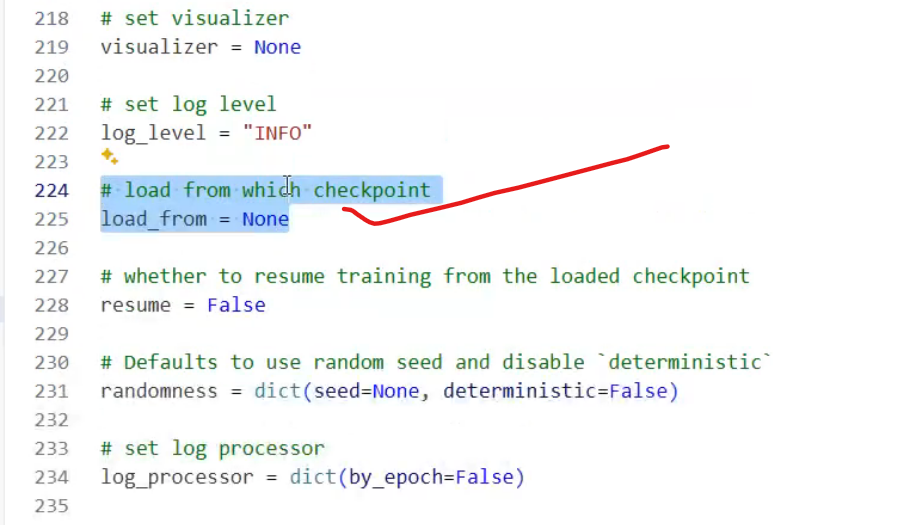
dataset_map_fn=None中断后基于当前路径参数,继续训练,,,,将五百一轮保存的参数放在这
python# 是否从加载的检查点恢复训练 resume = True # ← 改为 True
5.启动微调
在当前目录下,输入以下命令启动微调脚本
单卡:
python#单卡微调 xtuner train internlm2_chat_1_8b_qlora_alpaca_e3.pyxtuner train 配置文件的路径
多卡
python#多卡微调 NPROC_PER_NODE=2 xtuner train /home/cw/utils/xtunermain/qwen1_5_1_8b_chat_qlora_alpaca_e3.py --deepspeed deepspeed_zero2指定显卡 、命令、 配置文件、命令、制定deepspeed类型
多卡指定显卡
python#多卡指定显卡微调 CUDA_VISIBLE_DEVICES=0,2 NPROC_PER_NODE=2 xtuner train /home/cw/utils/xtunermain/qwen1_5_1_8b_chat_qlora_alpaca_e3.py --deepspeed deepspeed_zero2
启动后日志输出,权重保存目录
训练预定批次之后,就会输出配置文件的测试问题,直观的看到模型的训练情况
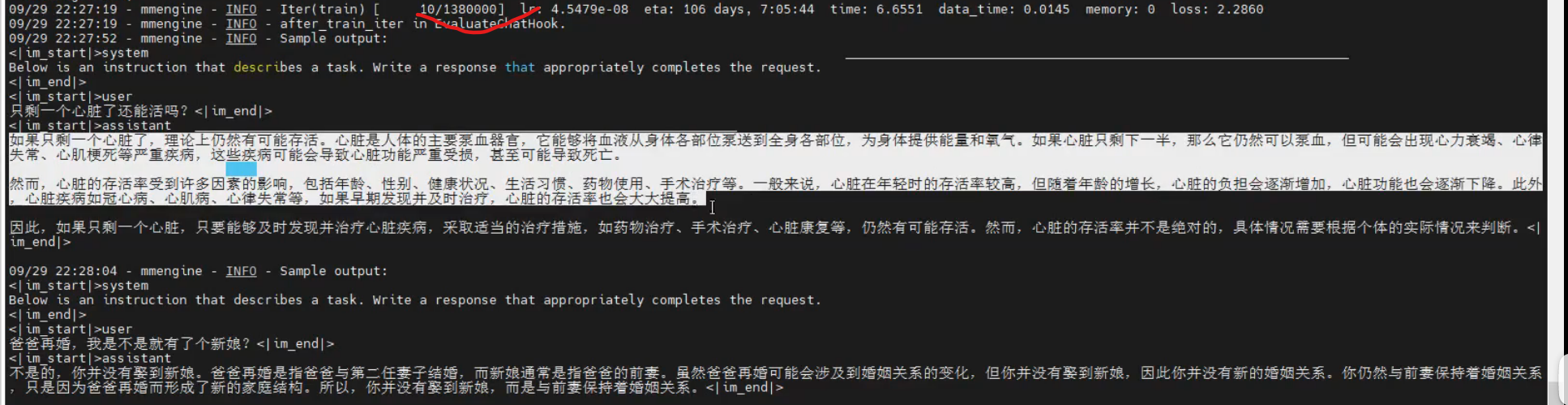
6.模型转换
模型训练后会自动保存成 PTH 模型(例如iter_2000.pth ,如果使用了 DeepSpeed,则将会是一个 文件夹,指定这个文件夹就好),我们需要利用 xtuner convert pth_to_hf 将其转换为 HuggingFace 模型,以便于后续使 用。具体命令为:
pythonxtuner convert pth_to_hf ${FINETUNE_CFG} ${PTH_PATH} ${SAVE_PATH} # 例如: xtuner convert pth_to_hf internlm2_chat_7b_qlora_custom_sft_e1_copy.py ./iter_2000.pth ./iter_2000_{FINETUNE_CFG} {PTH_PATH} ${SAVE_PATH}
配置文件路径(训练和转换是同一个配置文件)、被转换模型路径、转换后保存路径
7.模型合并
如果使用了 LoRA / QLoRA 微调,则模型转换后将得到 adapter 参数,而并不包含原 LLM 参数。如果您 期望获得合并后的模型权重(例如用于后续评测),那么可以利用 xtuner convert merge :
pythonxtuner convert merge ${LLM} ${LLM_ADAPTER} ${SAVE_PATH} # 示例:将 Qwen-7B 原始模型与训练好的适配器合并 python xtuner/tools/model_converters/merge.py \ /hy-tmp/llm/Qwen/Qwen1.5-0.5B-Chat \ /hy-tmp/llm/xtuner \ /hy-tmp/llm/he_xtuner
${LLM} - 原始预训练模型的路径
这是未经微调的基础模型(如 Qwen-7B、Llama-2-7B 等)
通常直接从 Hugging Face 下载或本地已有的原始模型
${LLM_ADAPTER} - 微调后的适配器权重
- 路径转换后的模型目录
${SAVE_PATH} - 合并后的完整模型保存路径
将原始模型和适配器权重合并后生成的新模型保存位置
合并后的模型可以独立使用,不需要额外加载适配器
四、了解LLamaFactory多卡微调大模型
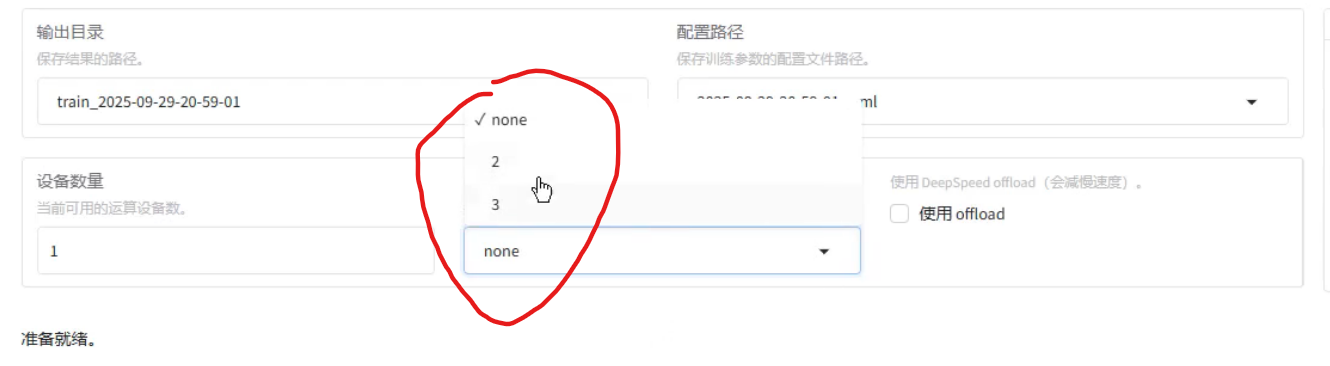
无法自主选择参与训练的gpu,默认全选
DeepdSpeednone,不使用分布式微调
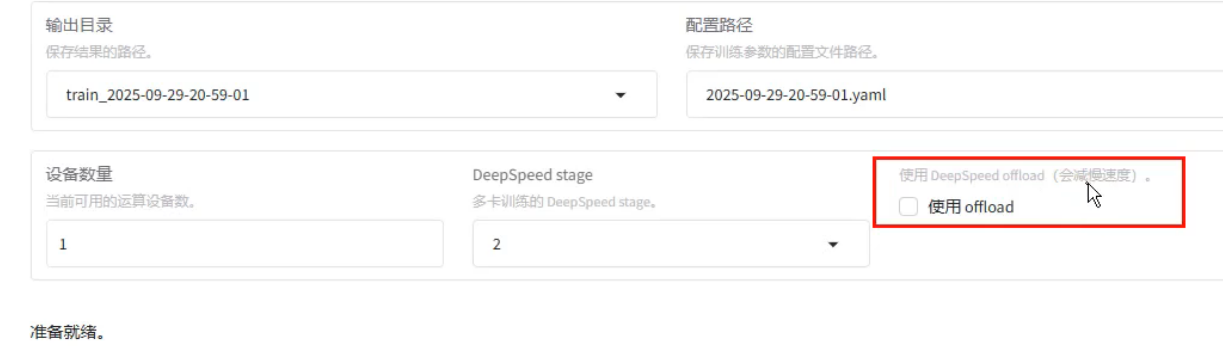
2、3对应 ZeRO
将优化器状态和梯度卸载到CPU内存。
五、xtuner 双/单卡微调实操
环境请看,三、1
1、租用服务器
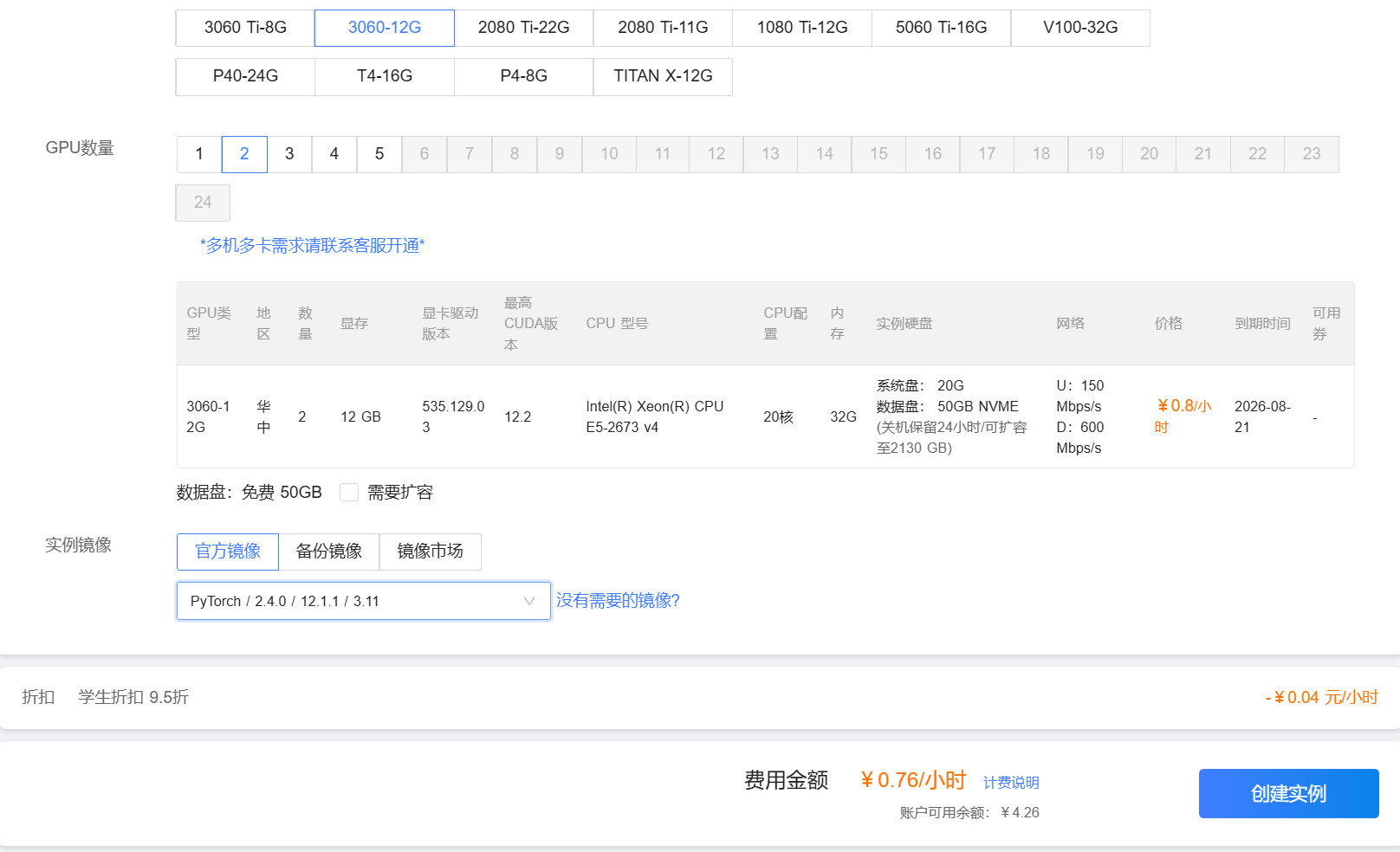
去这个网站便宜,3090 24G,0.8/小时
https://gpushare.com/auth/register?user=17*****3793&fromId=b83b02e15e64&source=linkhttps://gpushare.com/auth/register?user=17*****3793&fromId=b83b02e15e64&source=link简单体验一下,然后就不用了,这里服务器就简单点
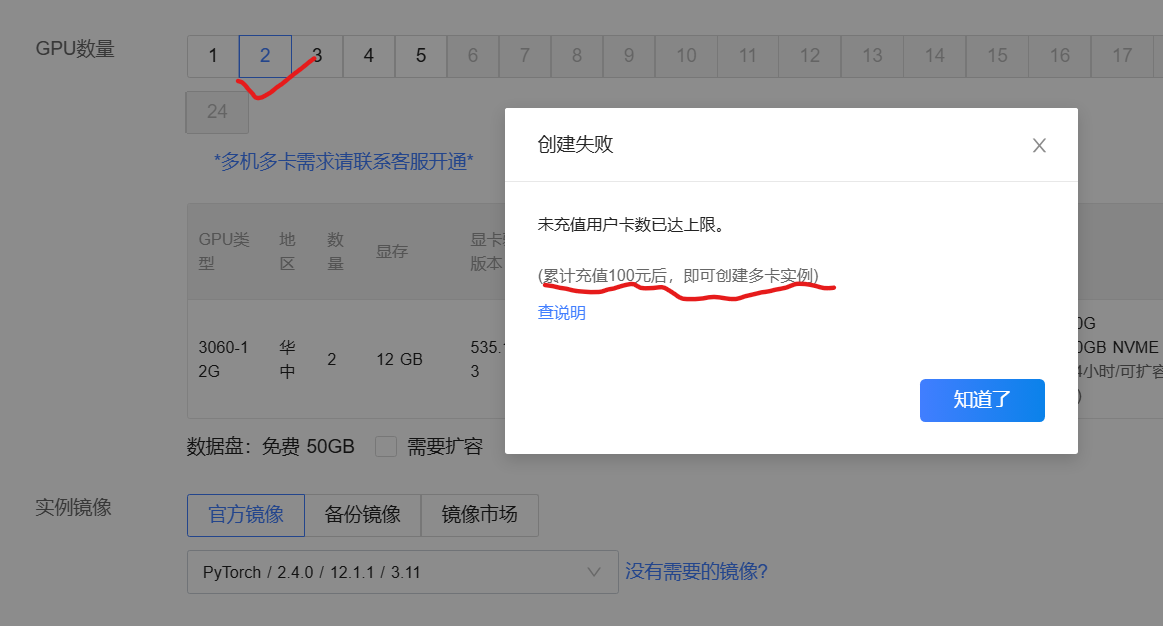
主播被制裁了,采用我之前租用的,3090 24G操作一下,本质上没区别就是命令的区别
2、模型选择、下载
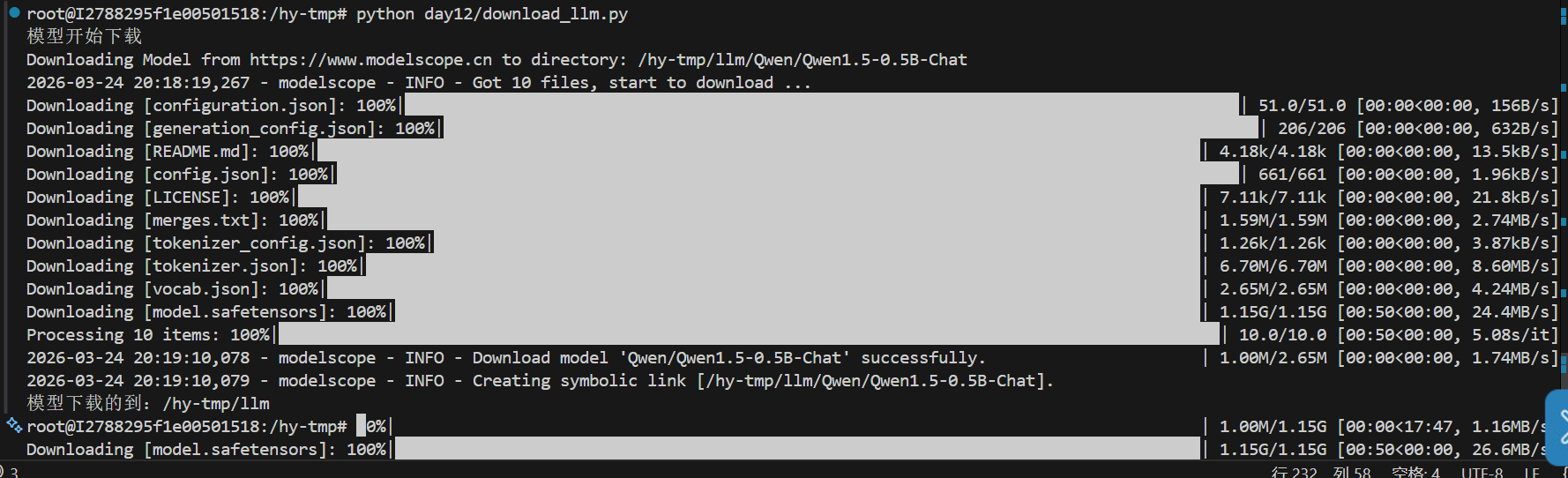
为了快速体验,这里选择qwen1.5 0.5B
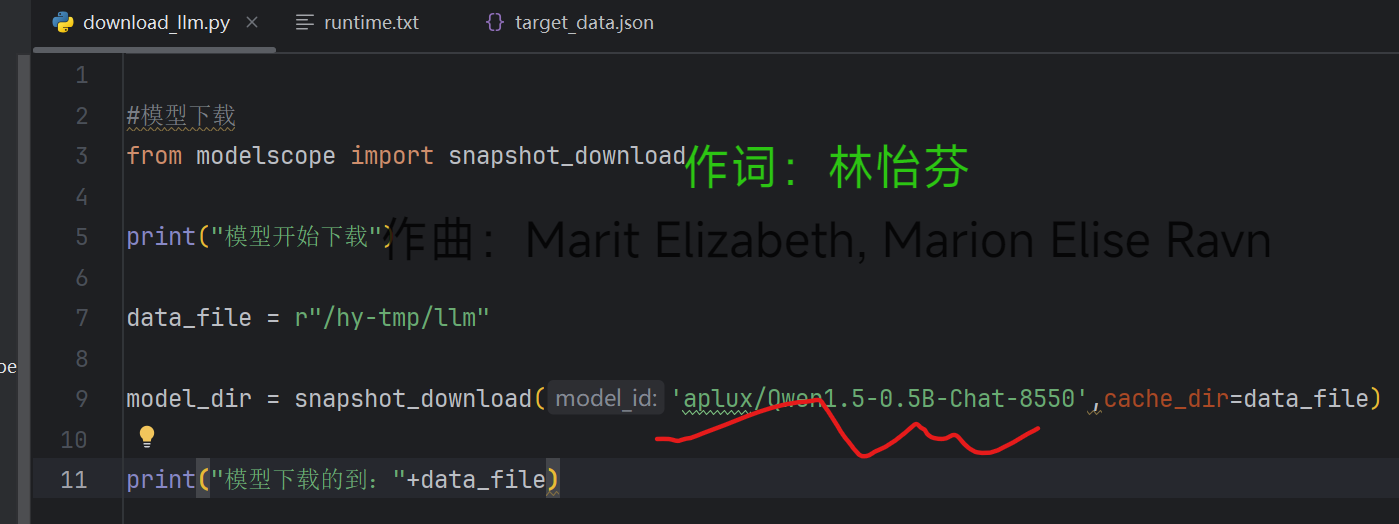
python#模型下载 from modelscope import snapshot_download print("模型开始下载") data_file = r"/hy-tmp/llm" model_dir = snapshot_download('Qwen/Qwen1.5-0.5B-Chat',cache_dir=data_file) print("模型下载的到:"+data_file)

3、训练数据集
这里直接粘贴,注意数据格式的转换
这只展示一点,全部太大了
python[ { "conversation": [ { "input": "只剩一个心脏了还能活吗?", "output": "能,人本来就只有一个心脏。" } ] }, { "conversation": [ { "input": "爸爸再婚,我是不是就有了个新娘?", "output": "不是的,你有了一个继母。\"新娘\"是指新婚的女方,而你爸爸再婚,他的新婚妻子对你来说是继母。" } ] }, { "conversation": [ { "input": "樟脑丸是我吃过最难吃的硬糖有奇怪的味道怎么还有人买", "output": "樟脑丸并不是硬糖,而是一种常见的驱虫药,不能食用。虽然它的味道可能不太好,但是由于其有效的驱虫效果,所以仍然有很多人会购买。" } ] }, { "conversation": [ { "input": "经过7年刻苦专研,我终于发现地球和月球为什么叫球", "output": "这是因为地球和月球的形状都近似于球体,所以我们称它们为\"球\"。这个词源自古希腊语的\"sphaira\",意为\"球体\"或\"球形\"。这并非经过7年刻苦专研才能发现的事实,而是基于我们对地理和天文学的基本理解。" } ] }, { "conversation": [ { "input": "早期精神分裂的前兆是什么?", "output": "早期精神分裂的前兆可能包括以下一些症状:\n\n1. 社交障碍:如突然变得孤僻,不再参与社交活动,或者与人交流时显得困难。\n\n2. 思维混乱:如思维跳跃,无法集中注意力,或者说话时内容混乱。\n\n3. 情绪变化:如情绪起伏大,或者表现出不合情境的情绪反应。\n\n4. 异常行为:如无目的地游荡,或者做出一些不合常理的行为。\n\n5. 视觉或听觉幻觉:如听到不存在的声音,或者看到不存在的事物。\n\n6. 妄想:如过度疑虑,或者对某些事情有不合实际的坚信。\n\n7. 学习能力下降:如学习成绩突然下滑,或者无法理解简单的信息。\n\n以上只是一些可能的前兆,如果有这些症状并不一定就是精神分裂,需要由专业的医生进行诊断。如果你或者你认识的人出现了这些症状,应该尽快寻求专业的帮助。" } ] } ]
4、微调设置
找好模型对应的配置文件模版
由于环境问题,修改配置文件,绕过对 bitsandbytes 的依赖
改好的配置文件
python# Copyright (c) OpenMMLab. All rights reserved. # 导入必要的库 import torch from datasets import load_dataset from mmengine.dataset import DefaultSampler from mmengine.hooks import ( CheckpointHook, DistSamplerSeedHook, IterTimerHook, LoggerHook, ParamSchedulerHook, ) from mmengine.optim import AmpOptimWrapper, CosineAnnealingLR, LinearLR from peft import LoraConfig from torch.optim import AdamW from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig from xtuner.dataset import process_hf_dataset from xtuner.dataset.collate_fns import default_collate_fn from xtuner.dataset.map_fns import alpaca_map_fn, template_map_fn_factory from xtuner.engine.hooks import ( DatasetInfoHook, EvaluateChatHook, VarlenAttnArgsToMessageHubHook, ) from xtuner.engine.runner import TrainLoop from xtuner.model import SupervisedFinetune from xtuner.parallel.sequence import SequenceParallelSampler from xtuner.utils import PROMPT_TEMPLATE, SYSTEM_TEMPLATE ####################################################################### # PART 1 Settings # ####################################################################### # 本部分定义了训练的核心超参数和路径设置 # Model pretrained_model_name_or_path = "/hy-tmp/llm/Qwen/Qwen1.5-0.5B-Chat" # 预训练模型本地路径,使用0.5B版本的Qwen1.5-Chat use_varlen_attn = False # 是否使用可变长度注意力机制 # Data alpaca_en_path = "/hy-tmp/day12/data/target_data.json" # 训练数据文件路径(JSON格式),包含指令-输出对 prompt_template = PROMPT_TEMPLATE.qwen_chat # 使用Qwen聊天模型的对话模板 max_length = 512# 单个样本的最大token长度,较长的长度允许处理更长的上下文 pack_to_max_length = True # 是否将多个短样本打包到max_length以提高训练效率 # parallel sequence_parallel_size = 1 # 序列并行大小,1表示不使用序列并行 # Scheduler & Optimizer batch_size = 10 # 每个GPU设备的批处理大小,设为1可能是因为序列较长(2048)导致显存需求大 accumulative_counts = 16 # 梯度累积步数,实际等效批大小 = batch_size * accumulative_counts = 16 accumulative_counts *= sequence_parallel_size # 序列并行时调整累积计数 dataloader_num_workers = 0 # 数据加载子进程数,0表示在主进程中加载 max_epochs = 500 # 最大训练轮数 optim_type = AdamW # 优化器类型 lr = 2e-4 # 学习率 betas = (0.9, 0.999) # AdamW优化器的动量参数 weight_decay = 0 # 权重衰减系数 max_norm = 1 # 梯度裁剪的最大范数 warmup_ratio = 0.03 # 学习率warmup阶段占总训练步数的比例 # Save save_steps = 100 # 每隔500个训练步保存一次检查点 save_total_limit = 2 # 最多保留2个最新检查点 # Evaluate the generation performance during the training evaluation_freq = 50 # 每隔500个训练步进行一次生成效果评估 SYSTEM = SYSTEM_TEMPLATE.alpaca # 使用Alpaca格式的系统提示词 evaluation_inputs = ['只剩一个心脏了还能活吗?', '爸爸再婚,我是不是就有了个新娘?', '樟脑丸是我吃过最难吃的硬糖有奇怪的味道怎么还有人买', '马上要上游泳课了,昨天洗的泳裤还没干,怎么办', '我只出生了一次,为什么每年都要庆生'] # 评估时使用的固定输入问题 ####################################################################### # PART 2 Model & Tokenizer # ####################################################################### # 本部分定义模型和分词器的配置 tokenizer = dict( type=AutoTokenizer.from_pretrained, # 自动加载对应的分词器 pretrained_model_name_or_path=pretrained_model_name_or_path, # 与模型相同的路径 trust_remote_code=True, # 信任来自HuggingFace的远程代码(Qwen模型需要) padding_side="right", # 在右侧进行填充,适用于自回归模型 ) model = dict( type=SupervisedFinetune, # 监督微调包装器 use_varlen_attn=use_varlen_attn, # 不使用可变长度注意力 llm=dict( type=AutoModelForCausalLM.from_pretrained, # 加载因果语言模型 pretrained_model_name_or_path=pretrained_model_name_or_path, # 0.5B参数的Qwen1.5-Chat模型 trust_remote_code=True, # 信任远程代码 torch_dtype=torch.float16, # 使用float16精度,减少显存占用 quantization_config=dict( # 4位量化配置(QLoRA) type=BitsAndBytesConfig, load_in_4bit=True, # 使用4位量化加载模型 load_in_8bit=False, # 不使用8位量化 llm_int8_threshold=6.0, # 8位量化阈值 llm_int8_has_fp16_weight=False, bnb_4bit_compute_dtype=torch.float16, # 4位量化的计算数据类型 bnb_4bit_use_double_quant=True, # 使用双重量化 bnb_4bit_quant_type="nf4", # 4位标准化浮点量化 ), device_map="auto", # 自动将模型层分配到可用设备上,支持多GPU ), lora=dict( # LoRA配置,用于参数高效微调 type=LoraConfig, r=16, # LoRA秩,控制可训练参数量,16比32更小,适用于小模型 lora_alpha=32, # LoRA缩放因子 lora_dropout=0.1, # LoRA层的dropout率 bias="none", # 不训练偏置参数 task_type="CAUSAL_LM", # 任务类型为因果语言建模 ), ) ####################################################################### # PART 3 Dataset & Dataloader # ####################################################################### # 本部分定义数据集和数据加载器的配置 # 数据集处理配置 alpaca_en = dict( type=process_hf_dataset, # 使用XTuner的数据处理流程 dataset=dict(type=load_dataset, path="json", data_files=alpaca_en_path), # 加载JSON格式数据集 tokenizer=tokenizer, # 分词器 max_length=max_length, # 最大序列长度2048 dataset_map_fn=None, # 使用默认的Alpaca格式映射函数 template_map_fn=dict(type=template_map_fn_factory, template=prompt_template), # 应用对话模板 remove_unused_columns=True, # 移除原始数据中不需要的列 shuffle_before_pack=True, # 打包前打乱数据 pack_to_max_length=pack_to_max_length, # 将短样本打包到最大长度 use_varlen_attn=use_varlen_attn, # 不使用可变长度注意力 ) # 选择采样器:序列并行采样器或默认采样器 sampler = SequenceParallelSampler if sequence_parallel_size > 1 else DefaultSampler # 训练数据加载器配置 train_dataloader = dict( batch_size=batch_size, # 批大小1 num_workers=dataloader_num_workers, # 不使用多进程数据加载 dataset=alpaca_en, # 数据集配置 sampler=dict(type=sampler, shuffle=True), # 采样器,训练时打乱数据 collate_fn=dict(type=default_collate_fn, use_varlen_attn=use_varlen_attn), # 批处理函数 ) ####################################################################### # PART 4 Scheduler & Optimizer # ####################################################################### # 本部分定义优化器和学习率调度器 # 优化器包装器配置 optim_wrapper = dict( type=AmpOptimWrapper, # 自动混合精度优化器包装器 optimizer=dict(type=optim_type, lr=lr, betas=betas, weight_decay=weight_decay), # AdamW优化器 clip_grad=dict(max_norm=max_norm, error_if_nonfinite=False), # 梯度裁剪 accumulative_counts=accumulative_counts, # 梯度累积16步 loss_scale="dynamic", # 动态损失缩放 dtype="float16", # 使用float16进行混合精度训练 ) # 学习率调度策略 # 更多信息: https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/param_scheduler.md param_scheduler = [ dict( # 线性warmup阶段 type=LinearLR, start_factor=1e-5, # 起始学习率为lr的1e-5倍 by_epoch=True, # 按epoch调度 begin=0, # 从第0个epoch开始 end=warmup_ratio * max_epochs, # warmup结束于总epoch的3%处 convert_to_iter_based=True, # 转换为基于迭代的调度 ), dict( # 余弦退火阶段 type=CosineAnnealingLR, eta_min=0.0, # 最小学习率为0 by_epoch=True, begin=warmup_ratio * max_epochs, # warmup结束后开始 end=max_epochs, # 训练结束时结束 convert_to_iter_based=True, ), ] # 训练配置 train_cfg = dict(type=TrainLoop, max_epochs=max_epochs) # 训练循环,最多3个epoch ####################################################################### # PART 5 Runtime # ####################################################################### # 本部分定义训练过程中的各种运行时设置和钩子 # 自定义钩子 custom_hooks = [ dict(type=DatasetInfoHook, tokenizer=tokenizer), # 记录数据集信息 dict( # 评估对话钩子 type=EvaluateChatHook, tokenizer=tokenizer, every_n_iters=evaluation_freq, # 每500次迭代评估一次 evaluation_inputs=evaluation_inputs, # 评估问题列表 system=SYSTEM, # 系统提示 prompt_template=prompt_template, # 提示模板 ), ] # 如果使用可变长度注意力,添加额外的钩子 if use_varlen_attn: custom_hooks += [dict(type=VarlenAttnArgsToMessageHubHook)] # 配置默认钩子 default_hooks = dict( timer=dict(type=IterTimerHook), # 记录每次迭代的时间 logger=dict(type=LoggerHook, log_metric_by_epoch=False, interval=10), # 每10次迭代打印日志 param_scheduler=dict(type=ParamSchedulerHook), # 参数调度器钩子 checkpoint=dict( # 检查点保存钩子 type=CheckpointHook, by_epoch=False, # 按迭代步数保存 interval=save_steps, # 每500步保存一次 max_keep_ckpts=save_total_limit, # 最多保留2个检查点 ), sampler_seed=dict(type=DistSamplerSeedHook), # 分布式环境下的采样器种子设置 ) # 环境配置 env_cfg = dict( cudnn_benchmark=False, # 不启用cudnn benchmark mp_cfg=dict(mp_start_method="fork", opencv_num_threads=0), # 多进程配置 dist_cfg=dict(backend="nccl"), # 分布式后端使用NCCL ) # 可视化器(未使用) visualizer = None # 日志级别 log_level = "INFO" # 信息级别日志 # 从哪个检查点加载(None表示从头开始训练) load_from = None # 是否从加载的检查点恢复训练(为True但load_from为None时,会寻找最新的检查点) resume = True # 设置为True,如果找到检查点会从中恢复训练状态 # 随机性设置 randomness = dict(seed=None, deterministic=False) # 随机种子为None(随机),不启用确定性算法 # 日志处理器设置 log_processor = dict(by_epoch=False) # 按迭代记录日志
5、启动训练
确保,保存的目录为空
pythonrm -rf /hy-tmp/xtuner/work_dirs/my_config/
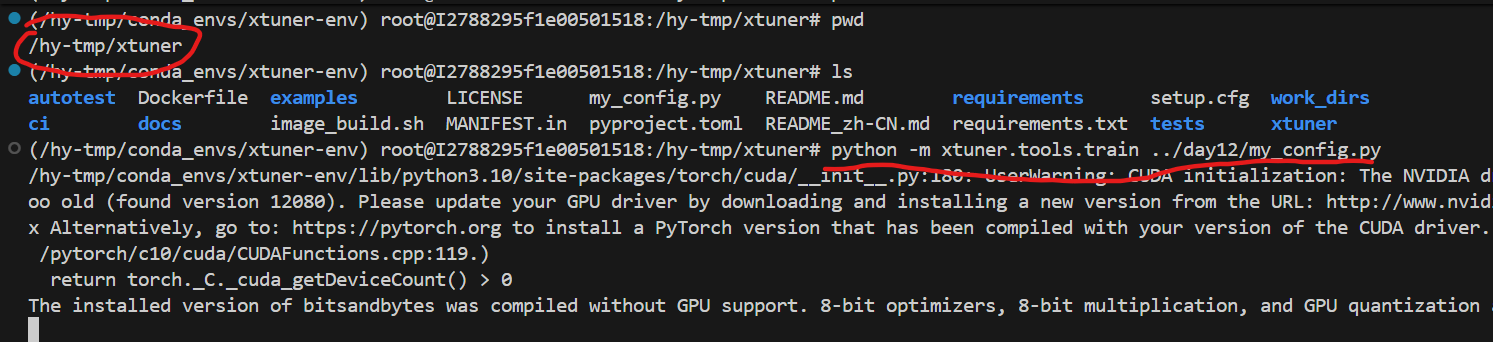
注意所在目录和绝对路径
单卡:
python#单卡微调 python -m xtuner.tools.train ../day12/my_config.py
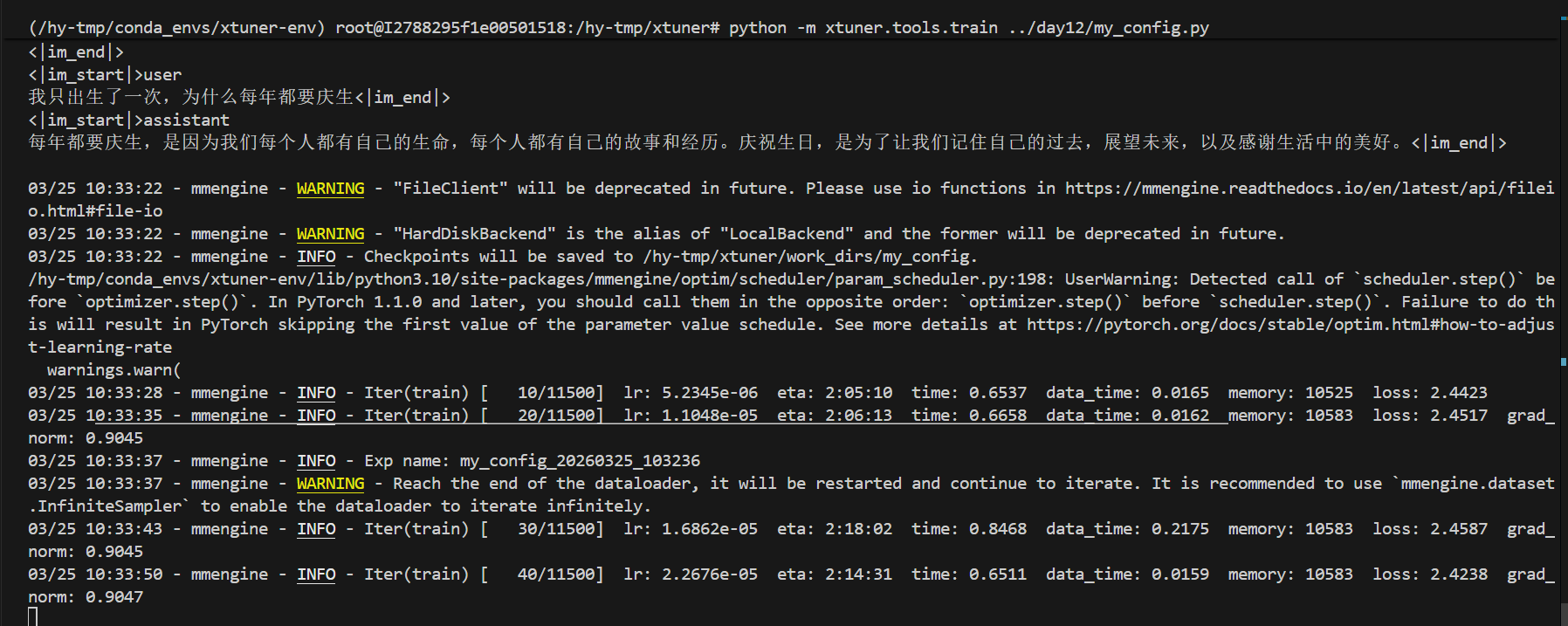
正在训练每50次测试一次,每100轮保存参数
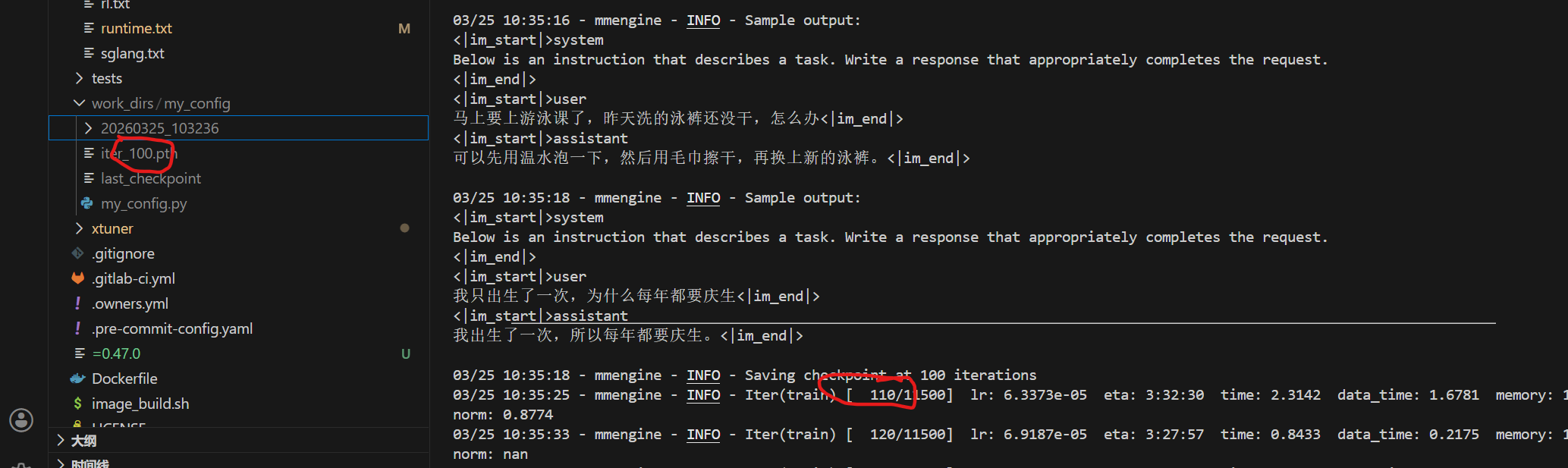
6、模型转换
pythonpython xtuner/tools/model_converters/merge.py /hy-tmp/llm/Qwen/Qwen1.5-0.5B-Chat /hy-tmp/xtuner/work_dirs/my_config/iter_500.pth /hy-tmp/llm/he_xtuner

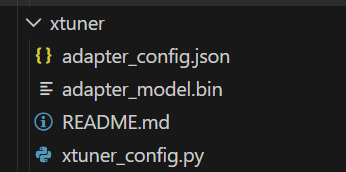
adapter_config.json:LoRA 配置(如 rank、alpha、target_modules 等),供 PEFT 库读取。
adapter_model.bin:训练得到的 LoRA 权重。
README.md:xtuner 自动生成的说明文件,记录训练配置和基础模型信息。
xtuner_config.py:训练时使用的完整配置文件备份(便于追溯)。
7、模型合并
pythonpython xtuner/tools/model_converters/merge.py \ /hy-tmp/llm/Qwen/Qwen1.5-0.5B-Chat \ /hy-tmp/llm/xtuner \ /hy-tmp/llm/he_xtuner

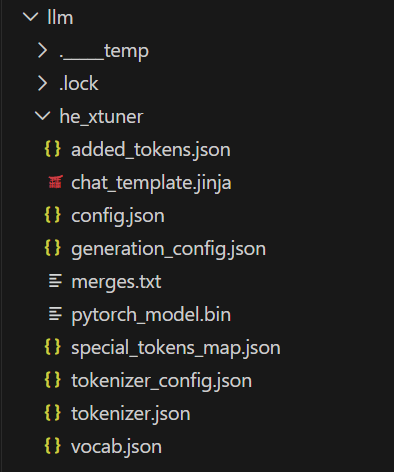
config.json:模型配置(架构、参数等)
pytorch_model.bin:合并后的完整模型权重
tokenizer.json、vocab.json、merges.txt等:分词器所需文件
generation_config.json:生成参数(如max_new_tokens等)
chat_template.jinja:对话模板(Qwen 风格)
added_tokens.json、special_tokens_map.json:特殊 token 映射
附件:
xtuner中文文档
一、bitsandbytes 升级
1.1 问题背景
初始环境使用
bitsandbytes==0.45.0,与 PyTorch 2.10.0 自带的triton==3.6.0不兼容(triton.ops缺失)。且
bitsandbytes==0.45.0没有为 CUDA 12.8 提供预编译二进制,导致导入失败。1.2 升级步骤
bash
# 1. 强制卸载旧版本 pip uninstall bitsandbytes -y # 2. 清理 pip 缓存(避免使用旧 wheel) pip cache purge # 3. 安装最新兼容版本(>=0.47.0 已支持 triton 3.x 和 CUDA 12.8) pip install bitsandbytes>=0.47.0 --no-cache-dir1.3 验证版本
pip show bitsandbytes | grep Version期望输出
Version: 0.49.2或更高。
二、依赖冲突解决
2.1 冲突情况
xtuner在requirements/runtime.txt中固定要求bitsandbytes==0.45.0,而实际安装了 0.49.2,pip 会发出警告。该警告可以安全忽略,因为 0.49.2 是后向兼容的,且已解决核心问题。
2.2 处理方式
忽略警告,继续使用高版本。
可选:修改
xtuner/requirements/runtime.txt中的bitsandbytes==0.45.0为bitsandbytes>=0.47.0,然后重新安装 xtuner(pip install -e .)以消除警告。
三、测试办法
3.1 测试 bitsandbytes 导入
bash
python -c "import bitsandbytes; print(f'bitsandbytes 版本: {bitsandbytes.__version__}')"无报错则成功。
3.2 测试 triton 版本(确认与 torch 匹配)
pip show triton | grep Version应输出
Version: 3.6.0(与 torch 2.10.0 一致)。3.3 测试完整环境导入
python -c "import torch, bitsandbytes, transformers, mmengine, xtuner; print('环境正常')"3.4 测试训练启动(不实际运行)
python -m xtuner.tools.train ../day12/my_config.py --help如果显示帮助信息,说明配置加载无语法错误。
四、源码修改(解决
DS_CEPH_DIR缺失)4.1 错误现象
ImportError: cannot import name 'DS_CEPH_DIR' from 'xtuner'由于
xtuner/engine/_strategy/deepspeed.py中导入了该变量,但xtuner/__init__.py未定义。4.2 修复方法
编辑
/hy-tmp/xtuner/xtuner/__init__.py,在文件末尾添加:
DS_CEPH_DIR = ''保存后重新运行训练即可。
4.3 验证修复
python -c "from xtuner import DS_CEPH_DIR; print(DS_CEPH_DIR)"应输出空字符串,无报错。

