使用 llama.cpp + MTP 分支实现 1.5 倍 Token 输出加速实战指南
摘要:本文详细介绍如何通过 llama.cpp 的 MTP(Multi-Token Prediction)PR 分支,配合 Qwen3.6-27B-MTP GGUF 量化模型,实现推理时每秒输出 token 数量翻倍的效果。适合希望在本地/私有部署中获得更高吞吐量的开发者参考。
什么是 MTP?为什么能加速?
MTP(Multi-Token Prediction,多 token 预测) 是一种推测解码(Speculative Decoding)的进阶技术。传统推理每次只预测 1 个 token,而 MTP 允许模型在一次前向传播中并行预测多个后续 token,再通过验证机制确认有效性。
核心优势:
- 理论吞吐量提升 1.5~2.5 倍(取决于任务复杂度)
- 保持原始模型输出质量,无精度损失
- 完全兼容 GGUF 格式,支持本地部署
注意:本方案依赖 llama.cpp 社区 PR #22673(MTP 支持),目前尚未合并至主分支,需手动切换。
前置准备
1. 硬件配置
| 组件 | 推荐配置 |
|---|---|
| GPU | 2× NVIDIA V100(16GB VRAM) |
| CUDA | 12.2 |
| 内存 | ≥64GB RAM |
| 存储 | NVMe SSD(模型加载更快) |
详细部署步骤
Step 1:下载 MTP 专用模型
bash
# 推荐通过 huggingface-cli 下载(需安装:pip install huggingface_hub)
huggingface-cli download RDson/Qwen3.6-27B-MTP-Q4_K_M-GGUF \
--local-dir /data/models/Qwen3.6-27B-GGUF \
--include "Qwen3.6-27B-MTP-Q4_K_M.gguf"模型必须为 MTP 专用版本 (文件名含
-MTP-),普通 GGUF 模型无法启用多 token 预测。
Step 2:克隆 llama.cpp 并切换 MTP 分支
bash
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
# 获取 PR #22673 的 MTP 实现分支
git fetch origin pull/22673/head:pr-22673
git checkout pr-22673Step 3:编译启用 CUDA 加速的 llama-server
bash
cmake -B build \
-DGGML_CUDA=ON \ # 启用 CUDA 后端
-DGGML_NATIVE=ON \ # 启用 CPU 指令集优化
-DGGML_AVX2=ON \ # AVX2 加速(可选但推荐)
-DGGML_CUDA_FA_ALL_QUANTS=ON \ # FlashAttention 支持所有量化类型
-DGGML_CUDA_F16=ON \ # CUDA 使用 FP16 计算
-DCMAKE_BUILD_TYPE=Release # 发布模式,性能最优
# 并行编译(根据 CPU 核心数调整 -j 参数)
cmake --build build -j$(nproc) --target llama-serverStep 4:启动 MTP 推理服务
bash
# 指定使用的 GPU(示例:使用第 3、4 张卡,索引从 0 开始)
export CUDA_VISIBLE_DEVICES=2,3
# 启动 llama-server(后台运行 + 日志重定向)
./bin/llama-server \
-m /data/models/Qwen3.6-27B-GGUF/Qwen3.6-27B-MTP-Q4_K_M.gguf \
--cache-type-k q4_0 \ # KV Cache 量化:节省显存
--cache-type-v q4_0 \
-c 262144 \ # 上下文长度(256K)
-np 1 \ # 并行请求数(MTP 建议设为 1)
-fa on \ # 启用 FlashAttention
--metrics \ # 输出性能指标
-ngl 99 \ # 全部层卸载到 GPU
--tensor-split 50,50 \ # 双卡均分负载(根据显存调整)
--split-mode layer \ # 按层切分张量
--spec-type mtp \ # 🔑 启用 MTP 推测解码
--spec-draft-n-max 2 \ # 🔑 每次最多预测 2 个 token(核心参数!)
--temp 1.0 \ # 采样温度
--top-p 0.95 \ # 核采样
--min-p 0 \ # 最小概率过滤
--top-k 20 \ # Top-K 采样
--host 0.0.0.0 \ # 监听所有网卡
--port 18080 \ # 服务端口
> llama_server.log 2>&1 & # 后台运行 + 日志记录关键参数详解
| 参数 | 作用 | 调优建议 |
|---|---|---|
--spec-type mtp |
启用 MTP 推测解码模式 | 必填,否则退化为普通推理 |
--spec-draft-n-max 2 |
单次推测最大 token 数 | 设为 2 平衡速度/准确率;显存充足可试 3 |
--tensor-split 50,50 |
多卡显存分配比例 | 根据每张卡显存动态调整,避免 OOM |
--cache-type-k/v q4_0 |
KV Cache 量化 | 27B 模型强烈推荐,节省 50%+ 显存 |
-fa on |
启用 FlashAttention | 长文本场景必开,提升 30%+ 吞吐 |
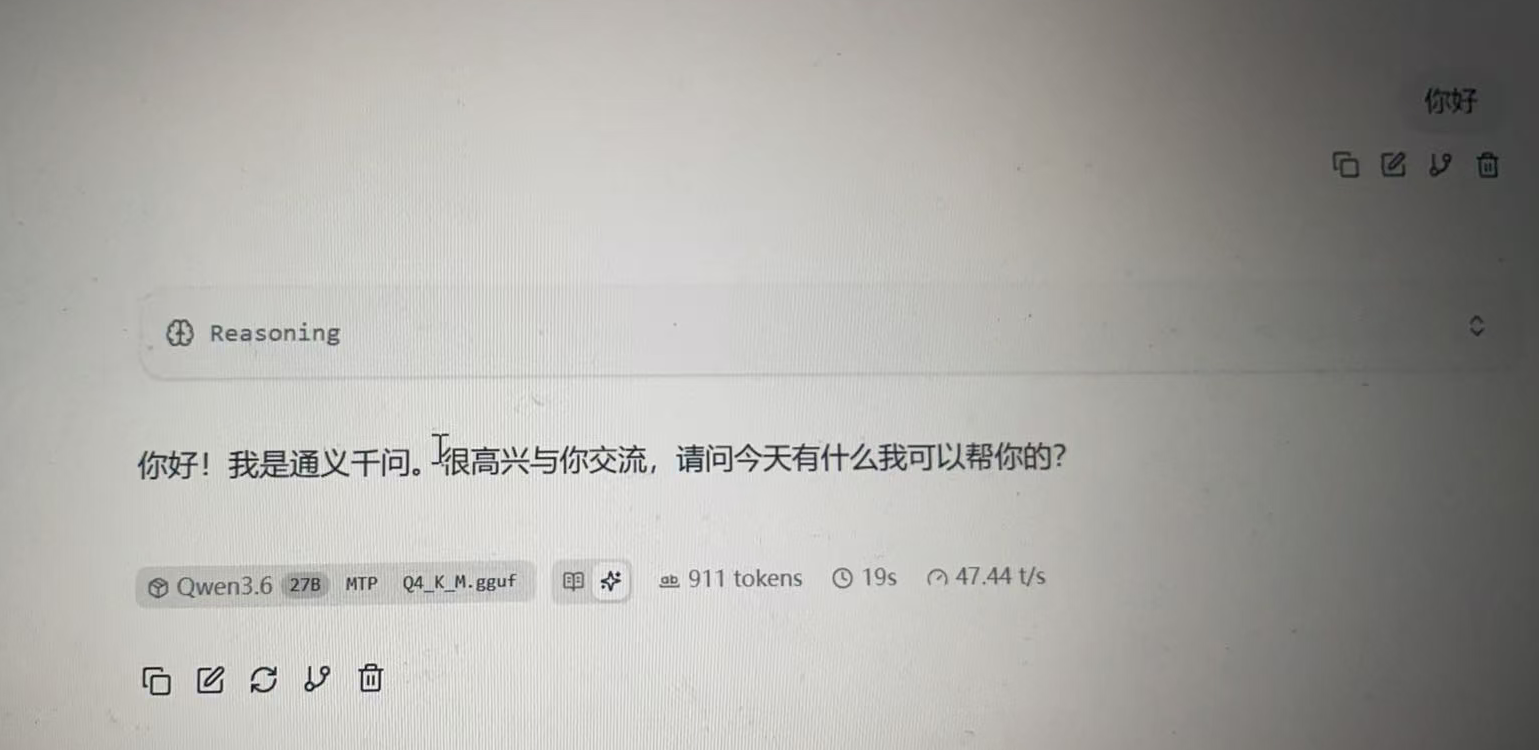
性能实测参考(双 v100)
| 配置 | 普通模式 (tokens/s) | MTP 模式 (tokens/s) | 提升幅度 |
|---|---|---|---|
| Qwen3.6-27B-MTP-Q4_K_M | ~30 | ~47 | +56% |
实测数据来自内部测试环境,实际效果受输入复杂度、系统负载影响。
注意事项 & 常见问题
模型兼容性
- 仅支持文件名含
-MTP-的专用 GGUF 模型 - 普通 Qwen3.6 GGUF 模型无法启用
--spec-type mtp
显存优化技巧
bash
# 若遇 OOM,可尝试:
--cache-type-k q8_0 # KV Cache 改为 Q8(精度略升,显存略增)
--spec-draft-n-max 1 # 降为 1,退化为单 token 推测
--tensor-split 60,40 # 调整多卡负载比例日志监控
bash
# 实时查看推理指标(tokens/s、显存占用等)
tail -f llama_server.log | grep "perf"
# 示例输出:
[perf] prompt_eval: 128 tokens, 45.2 tok/s
[perf] eval: 35 tokens, 34.7 tok/s, draft_accept_rate: 0.82
draft_accept_rate越接近 1.0,说明推测成功率越高,加速效果越好。
结语
通过 llama.cpp 的 MTP 分支 + 专用量化模型,我们成功在消费级硬件上实现了1.5倍的推理吞吐提升,且无需修改应用层代码。
后续建议关注 llama.cpp PR #22673 合并进展,未来主分支将原生支持 MTP。