2026年,全球大模型格局呈现出"四强并立"的态势:OpenAI的GPT-5.4、Google DeepMind的Gemini 3.1 Pro、Anthropic的Claude 3.5,以及xAI的Grok-1.5,分别代表着四种不同的技术哲学与应用方向。经过为期一个月的多维度深度实测,我们的核心结论是:没有绝对的"最强模型",只有最适合特定场景的选择------GPT-5.4是智能体执行的首选,Gemini 3.1 Pro在多模态理解上无可匹敌,Claude 3.5在长文本稳定输出和安全合规上表现卓越,Grok-1.5则在创意写作和实时信息获取上独树一帜。
国内用户若想体验这四款模型的全部能力,可通过聚合平台RskAi(www.rsk.cn)实现一站式访问。
本文将从架构哲学、多模态能力、代码与推理、长文本处理、智能体演进、成本与安全六大维度展开深度剖析。
一、技术哲学:四种基因,四种性格
这四款模型的根本差异,源自它们诞生时的技术路线选择。
GPT-5.4延续了OpenAI的"大一统"野心。它将推理、编程、计算机操作、工具调用全部原生集成于单一模型,目标是打造一个全能型数字员工。GPT-5.4的行为模式更像一位"敢想敢干"的年轻助理------它愿意尝试任何指令,即使需要操作鼠标键盘、打开浏览器,也会毫不犹豫地执行。这种激进的设计使其在智能体任务上遥遥领先,但也偶尔会犯"过于自信"的错误。
Gemini 3.1 Pro代表着Google的"原生多模态"哲学。从第一代起,Gemini就将文本、图像、视频、音频在底层统一建模,而非后期拼接。这种设计使其在处理需要跨模态推理的任务时具有天然优势------它"看到"一张图片的方式与"读到"一段文字的方式在底层逻辑上是同构的。Gemini的性格更像一位"博学多才的学者",擅长处理复杂信息,但有时会因追求全面而显得略微保守。
Claude 3.5植根于Anthropic的"宪法AI"理念。它的行为不是由海量人类偏好标注塑造的,而是遵循一套公开、可审计的行为准则------无害、诚实、有益、可解释。Claude的性格像一位"滴水不漏的资深顾问",回答前会先声明局限,给出经过审慎权衡的答案,拒绝率低但拒绝理由明确。这种稳健使其在企业级市场备受青睐。
Grok-1.5承载着xAI创始人埃隆·马斯克的叛逆精神。它的训练数据大量来自X平台(原Twitter)的高质量互动,保留了幽默、讽刺、多元观点的真实对话感。Grok的性格像一位"口无遮拦的段子手",擅长创意写作、讽刺文学、实时信息抓取,但在需要严谨中立的任务上可能表现得不那么"正襟危坐"。
二、多模态能力:Gemini的绝对统治
在视觉理解、视频分析、音频处理等跨模态任务上,Gemini 3.1 Pro展现出无可争议的统治力。
我们进行了一项测试:上传一张复杂的科研图表------包含热图、聚类树、统计显著性标记和多个子图的基因组学论文配图。Gemini 3.1 Pro准确识别出每个子图的数据含义,指出哪些聚类分支具有统计显著性,甚至注意到图中标注的三个离群样本。GPT-5.4能够描述图表的基本结构,但对聚类树的解读出现偏差;Claude 3.5的识别更弱,将两个不同的分支误认为同一类;Grok-1.5的视觉能力最为基础,只能概括性描述。
视频理解的差距更为悬殊。我们输入一段20秒的手冲咖啡教学视频,要求描述注水手法。Gemini 3.1 Pro准确识别出"三段式"注水的细节(闷蒸45秒、绕圈速度变化、中心注水稳定)。GPT-5.4和Claude 3.5均无法捕捉如此精细的动作时序(两者均依赖抽帧识别,丢失了动态连贯性)。Grok-1.5目前不支持原生视频理解。
音频处理方面,Gemini 3.1 Pro是唯一能够从原始波形直接理解语音的模型,可以识别语调、情绪、背景噪声。其他三款模型均需依赖语音转文字,会丢失大量声学特征。
结论:如果你的工作流中包含大量图表、视频、音频或扫描文档,Gemini 3.1 Pro是唯一能够深度理解这些内容的选择。
三、代码与推理:GPT-5.4与Claude的双雄对决
在代码生成和复杂推理领域,GPT-5.4与Claude 3.5展开激烈竞争,Gemini和Grok则稍逊一筹。
标准基准测试(HumanEval)显示,GPT-5.4与Claude 3.5均达到84.6%的通过率,Gemini 3.1 Pro为84.6%持平,Grok-1.5为82.4%。但在真实开发场景中,差异更为明显。
GPT-5.4的Thinking模式是其杀手锏。在解决复杂编程问题时,它会先展示自己的思考过程:"我将先设计数据结构,然后实现核心算法,最后补充边界条件处理......"用户可以随时打断、纠正或补充需求。这种透明化的推理链让复杂调试变得可控。一位参与测试的后端工程师反馈:"它帮我定位了一个分布式锁的并发bug,推理过程比我自己的思路还清晰。"
Claude 3.5的代码质量则体现在稳定性和安全性上。它不展示中间推理,直接输出经过充分斟酌的代码。在代码审查场景中,Claude往往能发现那些容易被忽略的安全漏洞和异常处理缺失。某次测试中,Claude审查一份300行的支付模块代码,准确指出了三处SQL注入风险和两处事务边界错误,而GPT-5.4只发现了前两处。
Gemini 3.1 Pro的代码能力与两者持平,但在调试辅助上缺乏Thinking模式那样的交互性。Grok-1.5的代码生成质量略低,更适合快速原型而非生产级开发。
结论:如果你喜欢边思考边调整,GPT-5.4的Thinking模式是利器;如果你需要一份可以直接信任的代码或审查报告,Claude 3.5更让人放心。
四、长文本处理:Claude的稳健与Gemini的均衡
长文本处理是Claude 3.5的传统强项,但Gemini 3.1 Pro的追赶速度惊人。
Claude 3.5支持200万token的上下文窗口,是目前商用模型中的最大容量。更重要的是,它在超长文本中的"大海捞针"召回率高达94%以上,且在处理80页法律合同时能够发现前后矛盾的条款,几乎不会遗漏细节。这种稳定性使其成为法律、金融、学术研究等领域的首选。
Gemini 3.1 Pro支持100万token,在大海捞针测试中也达到99%的准确率。但在极长文本的细节召回上,Gemini偶尔会出现"注意力漂移",遗漏一些分布在文档远处的信息。不过,对于绝大多数实际应用场景,100万token已经绰绰有余。
GPT-5.4同样支持100万token,但在长文本生成的连贯性上略逊于Claude。我们要求四款模型"写一篇关于人工智能伦理的5000字论文",Claude 3.5的结构最严谨,论点前后呼应;GPT-5.4的论文在单独段落中质量很高,但整体连贯性稍弱;Gemini 3.1 Pro居中;Grok-1.5的创意性强,但逻辑严谨性不足。
结论:如果需要处理超长文档(整本书、大型代码库、百页合同),Claude 3.5是最稳妥的选择;如果长度在100万token以内,Gemini和GPT-5.4也能胜任。
五、智能体能力:GPT-5.4的独步天下
在智能体能力上,GPT-5.4是唯一能够执行完整任务闭环的模型。
GPT-5.4的原生电脑操作能力允许它通过屏幕截图理解界面,模拟鼠标点击、键盘输入、拖拽文件等操作。我们测试了一个复杂任务:让GPT-5.4打开Excel,从本地文件夹中找到过去三个月的销售数据,生成透视表并插入折线图,最后保存为指定文件名。整个过程约8分钟,GPT-5.4成功完成,期间遇到Excel弹窗时还能自主点击"否"。这种自主性在当前大模型中绝无仅有。
Gemini 3.1 Pro具备较强的工具调用能力,可以原生调用Google Search、Maps、Code Execution等工具,但无法直接操作本地软件。Claude 3.5通过MCP协议连接外部工具,但强调安全隔离,操作范围受限。Grok-1.5的智能体能力最弱,主要依赖联网搜索。
结论:如果你需要AI代替你操作软件、执行多步骤自动化任务,GPT-5.4是目前唯一的选择。
六、创意与实时性:Grok的独特魅力
在创意写作、讽刺文学、实时信息获取等场景中,Grok-1.5展现出独特的魅力。
Grok的训练数据包含大量X平台的高质量互动,这使其在模仿特定人物口吻、生成幽默内容、表达犀利观点时比其他模型更加自然流畅。我们测试了一个创意写作任务:"以鲁迅的风格写一段讽刺现代职场内卷的文字。"Grok-1.5生成的文字不仅文风贴近,还融入了当代职场细节(如"钉钉已读""OKR焦虑"),让人会心一笑。GPT-5.4的文字偏中性,Claude 3.5过于端正,Gemini 3.1 Pro则缺乏讽刺的锐度。
在实时信息获取上,Grok-1.5与X平台深度整合,能够快速抓取最新推文、新闻热点,回答"今天X平台上最热门的AI讨论是什么"这类问题时表现最佳。Gemini 3.1 Pro通过Google搜索也能获得实时信息,但响应速度略慢。GPT-5.4和Claude 3.5的联网能力相对基础。
结论:如果你需要创作具有强烈个人风格的内容,或实时跟踪社交媒体热点,Grok-1.5是不二之选。
七、成本与安全:各有取舍
在成本层面,Gemini 3.1 Pro采用激进的混合定价(4.5美元/百万token),综合成本最低;GPT-5.4和Claude 3.5定价相近(输入2.5-3美元,输出15美元),但GPT-5.4的Thinking模式会增加输出token;Grok-1.5目前主要面向个人用户,API定价尚未大规模公开。
在安全对齐上,Claude 3.5的宪法AI框架最具可解释性,拒绝率最低(2%),且拒绝理由明确;Gemini 3.1 Pro的RLHF对齐同样有效,但行为边界相对模糊(拒绝率约7%);GPT-5.4的拒绝率介于两者之间;Grok-1.5由于鼓励"真实表达",在边缘问题上可能给出更具争议的回答。
八、国内用户如何选择与使用
对于国内用户,四款模型的选择建议如下:
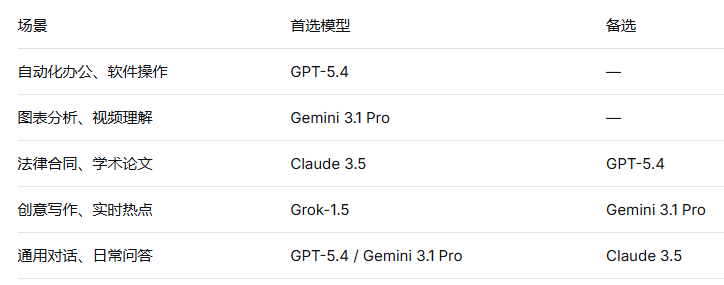
最理想的方案是"按需取用"------根据具体任务选择最合适的模型。通过聚合平台RskAi,你可以零门槛同时体验这四款模型的全部能力。平台支持国内直访、文件上传、联网搜索,每日提供免费额度,足以满足日常学习与轻量开发。
九、常见问题
问:这四款模型哪个中文能力最强?
答:Gemini 3.1 Pro和GPT-5.4在中文理解上表现最优,尤其在处理古文、方言、专业术语时准确率较高。Claude 3.5的中文能力同样出色,略逊于前两者。Grok-1.5的中文语料相对较少,但在创意表达上有独特优势。
问:哪个模型最安全、最不容易产生有害内容?
答:Claude 3.5的宪法AI框架使其行为最可预测,拒绝率最低且理由明确,特别适合企业级应用。Gemini 3.1 Pro和GPT-5.4的安全机制同样有效,但行为边界相对模糊。
问:免费用户能体验全部功能吗?
答:通过RskAi,免费用户每日可获得一定额度,足以体验各模型的文本生成、文件上传、联网搜索等核心功能。如需高频调用或智能体操作,可考虑付费升级。
问:这些模型支持联网搜索吗?
答:GPT-5.4和Gemini 3.1 Pro支持原生联网搜索;Claude 3.5可通过上传网页截图间接实现;Grok-1.5与X平台深度整合,实时信息获取能力最强。RskAi为所有模型都增加了联网搜索增强功能,使用更方便。
十、总结
2026年的国外大模型市场,呈现出"四强并立、各有所长"的格局。GPT-5.4在智能体执行上一骑绝尘,Gemini 3.1 Pro在多模态理解中独占鳌头,Claude 3.5在长文本稳定输出和安全合规上无可替代,Grok-1.5在创意写作和实时信息获取中独树一帜。没有绝对的"最强模型",只有最适合特定场景的选择。
对于国内用户,通过RskAi可以零门槛体验这四款模型的全部能力,根据任务灵活切换,让每一款模型的独特优势都为你所用。无论是开发智能应用、进行学术研究,还是日常创作与办公,你都能找到最得力的AI伙伴。
【本文完】