厌倦了手写 TypeScript 类型?我做了一个工具帮你从 Swagger 自动生成
背景:一个让人抓狂的日常
做前端的同学应该都经历过这种场景:
后端给你一个新接口,你打开接口文件,写下:
typescript
export async function getModelListApi(params?: any) {
return requestClient.post("/algo/model/list", params);
}然后你打开 Swagger 文档,找到这个接口,看着一堆字段,开始手动敲:
typescript
export interface GetModelListParams {
code?: string;
algoName?: string;
status?: number;
sceneId?: number;
// ... 还有十几个字段
}一个接口还好,一个文件里有二三十个接口,全是 any,这活儿干起来又枯燥又容易出错。
这就是我做这个工具的原因。
工具介绍
swagger-ts-mcp 是一个从 Swagger/OpenAPI 文档自动为前端接口文件生成 TypeScript 类型定义的工具。
核心能力:
- 解析你的接口文件,找出所有参数类型为
any或未定义的函数 - 自动从 Swagger 文档拉取对应接口的 Schema
- 生成规范的 TypeScript interface,插入到函数上方
- 把函数参数里的
any替换成具体类型名
支持两种使用方式:CLI 命令行 和 MCP Server(给 Kiro、Cursor 等 AI IDE 用)。
效果展示
处理前:
typescript
// 取消发布
export async function cancelPublishApi(params?: any) {
return requestClient.get("/model/publish/cancel", { params });
}处理后:
typescript
/** 取消发布请求参数 */
export interface CancelPublishParams {
/** 模型ID */
modelId?: number;
}
// 取消发布
export async function cancelPublishApi(params?: CancelPublishParams) {
return requestClient.get("/model/publish/cancel", { params });
}一个文件里几十个接口,一条命令全部搞定。
需求分析:这个工具到底要解决什么
在动手写代码之前,我梳理了几个核心问题:
1. 识别哪些函数需要处理
不是所有函数都要处理,只处理参数类型是 any 或者没有类型的函数。已经有明确类型定义的函数直接跳过,不重复生成。
2. 怎么找到对应的 Swagger 接口
接口文件里的函数调用了 requestClient.post('/algo/model/list', params),需要从这里提取出 HTTP 方法(post)和路径(/algo/model/list),然后去 Swagger 文档里找到对应的定义。
3. 路径前缀问题
实际项目里经常遇到:代码里的路径是 /algo/model/list,但 Swagger 文档里只有 /model/list(前缀 /algo 是网关加的)。需要支持配置前缀来处理这种情况。
4. 写入不能破坏原有代码
生成的类型要插入到函数上方,同时把函数参数里的 any 替换掉,但其他代码一行都不能动。
5. 幂等性
同一个文件跑两次,不能生成重复的类型定义。如果类型已经存在,直接跳过。
设计理念
模块化,职责单一
整个工具拆成 6 个独立模块,每个模块只做一件事:
bash
bin/index.ts # 入口,解析命令行参数
src/parser.ts # 解析接口文件,提取函数信息
src/fetcher.ts # 请求 Swagger 文档
src/converter.ts # Schema → TypeScript 类型字符串
src/writer.ts # 将类型写入文件
src/config.ts # 读取配置文件
src/ref-resolver.ts # 递归解析 $ref 引用
src/mcp-server.ts # MCP Server 实现这样每个模块可以独立测试,出问题也好定位。
错误不抛异常,结构化返回
所有错误都以结构化对象返回,不抛出未处理的异常:
typescript
type ErrorType =
| "SWAGGER_FETCH_ERROR" // Swagger 文档无法访问
| "ENDPOINT_NOT_FOUND" // 找不到对应接口
| "PARSE_ERROR" // 文件解析失败
| "WRITE_ERROR" // 文件写入失败
| "CONFIG_NOT_FOUND"; // 没有配置文件也没有传参数单个接口处理失败(比如 Swagger 里找不到这个路径),不影响其他接口继续处理。
两种调用方式,同一套核心逻辑
CLI 和 MCP Server 共用同一套核心引擎,入口层只负责参数解析和结果格式化,核心逻辑不重复。
实现细节
1. 解析接口文件:用 TypeScript Compiler API
用 ts.createSourceFile 做 AST 解析,识别这类调用模式:
typescript
requestClient.get(path, { params });
requestClient.post(path, data);
requestClient.put(path, data);
requestClient.delete(path, { params });从 AST 里提取出:函数名、HTTP 方法、路径、当前参数类型。
判断是否需要处理的逻辑很简单:参数类型是 any 或者根本没有类型注解,就加入待处理列表。
2. 获取 Swagger 文档:自动处理 URL 转换
Swagger UI 的地址(doc.html)和实际的 JSON 数据接口(/v3/api-docs)是两个不同的地址。工具会自动转换:
bash
https://your-api/doc.html
→ 先尝试 https://your-api/v3/api-docs
→ 失败则尝试 https://your-api/v2/api-docs所以你直接把浏览器里的 Swagger 地址粘进来就行,不用手动改。
3. Schema 转换:处理各种复杂情况
基础类型映射很简单,复杂的是这几种情况:
$ref 递归引用
Swagger 里经常有这种结构:
json
{
"schema": { "$ref": "#/components/schemas/ModelVO" }
}ModelVO 里可能又引用了其他类型,需要递归解析,同时用 Set 去重,避免同一个类型被生成多次。
oneOf / anyOf / allOf
css
oneOf / anyOf → 联合类型 A | B
allOf → 交叉类型 A & B可选字段
Swagger Schema 里有 required 数组,不在里面的字段生成时加 ?:
typescript
export interface GetModelListParams {
code?: string; // 不在 required 里,加 ?
status: number; // 在 required 里,不加 ?
}JSDoc 注释
Swagger 里每个字段都有 description,直接转成 JSDoc:
typescript
export interface GetModelListParams {
/** 算法编码 */
code?: string;
/** 状态:0-禁用 1-启用 */
status?: number;
}4. 写入文件:精准插入,不破坏原有代码
写入逻辑分两步:
- 在函数定义行的上方插入类型定义
- 把函数参数里的
any替换成生成的类型名
用行号定位插入位置,其他行的内容原封不动。写入前先检查文件里是否已有同名类型,有的话直接跳过(幂等性保证)。
5. 命名规范
函数名到类型名的转换规则:
getUserListApi
→ 去掉 Api 后缀 → getUserList
→ 首字母大写 → GetUserList
→ 加后缀 → GetUserListParams / GetUserListResult6. MCP Server:让 AI IDE 直接调用
MCP(Model Context Protocol)是一个让 AI IDE 调用外部工具的协议。工具以 stdio 方式启动,暴露一个 generate_types 工具:
typescript
{
name: "generate_types",
inputSchema: {
filePath: string, // 必填:目标文件路径
swaggerUrl?: string, // 可选:Swagger 地址(优先于配置文件)
functionNames?: string[], // 可选:只处理这些函数
dryRun?: boolean // 可选:预览模式
}
}配置好之后,在 Kiro 或 Cursor 里直接说"帮我给这个文件生成类型",AI 会自动调用工具完成处理。
使用方式
安装
bash
npm install -g swagger-ts-mcp方式一:CLI
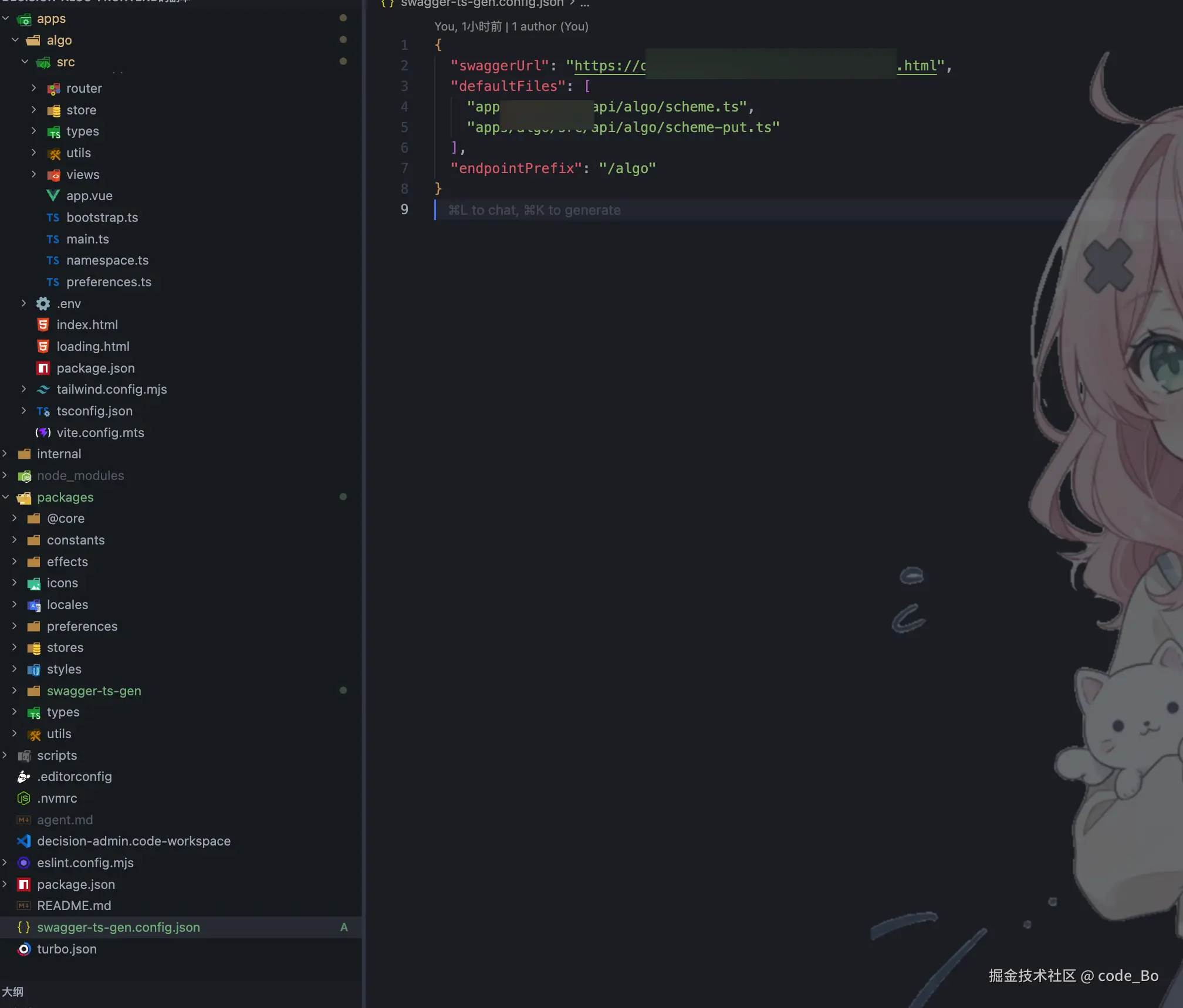
在项目根目录创建配置文件 swagger-ts-gen.config.json:
json
{
"swaggerUrl": "https://your-api/doc.html",
"defaultFiles": ["src/api/user.ts", "src/api/order.ts"],
"endpointPrefix": "/algo"
}
然后直接运行:
bash
swagger-ts-mcp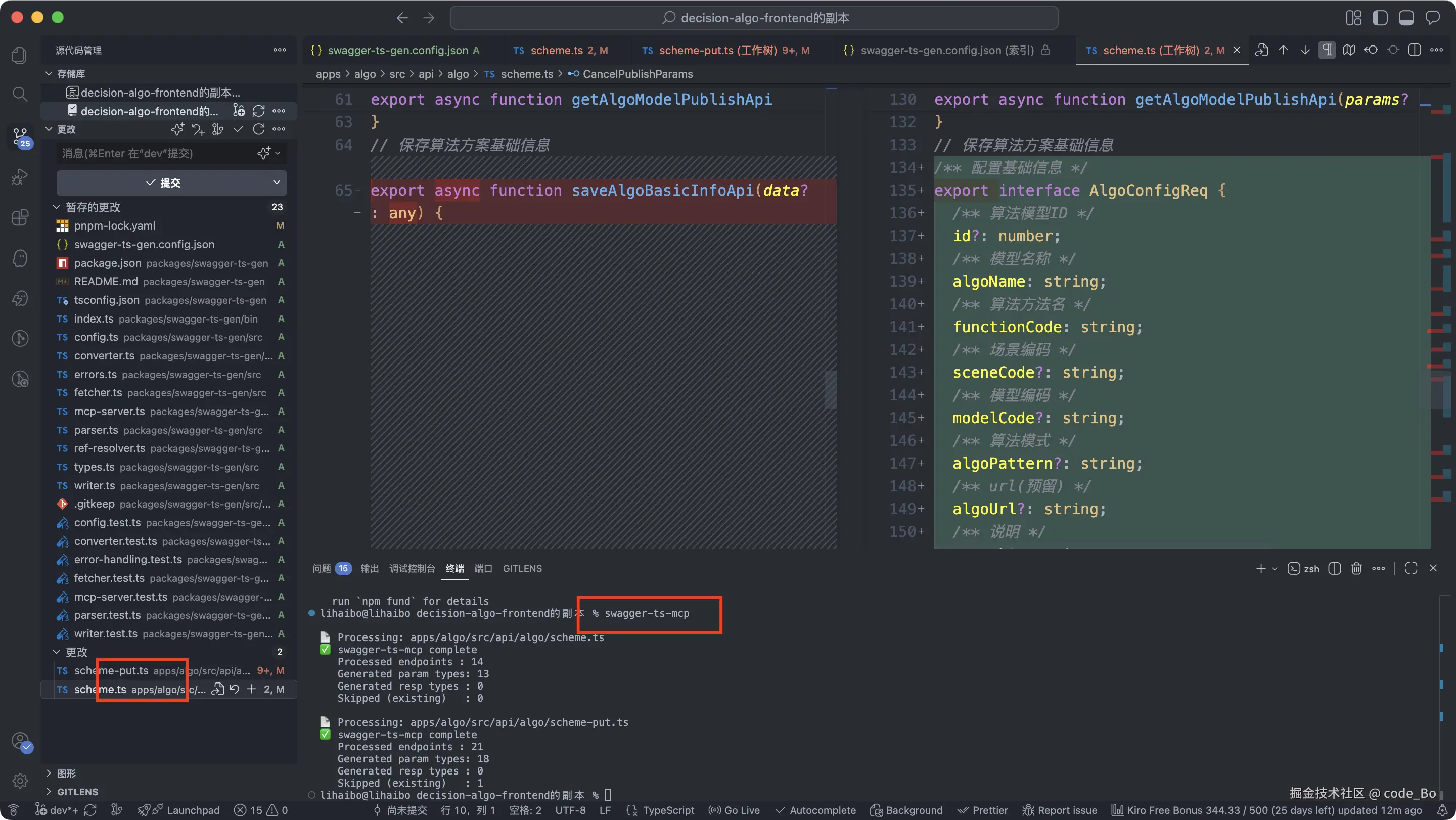
也可以不用配置文件,直接传参数:
bash
swagger-ts-mcp --file src/api/user.ts --swagger https://your-api/doc.html先用 --dry-run 预览,确认没问题再正式执行:
bash
swagger-ts-mcp --file src/api/user.ts --swagger https://your-api/doc.html --dry-runnpx 的方式使用:
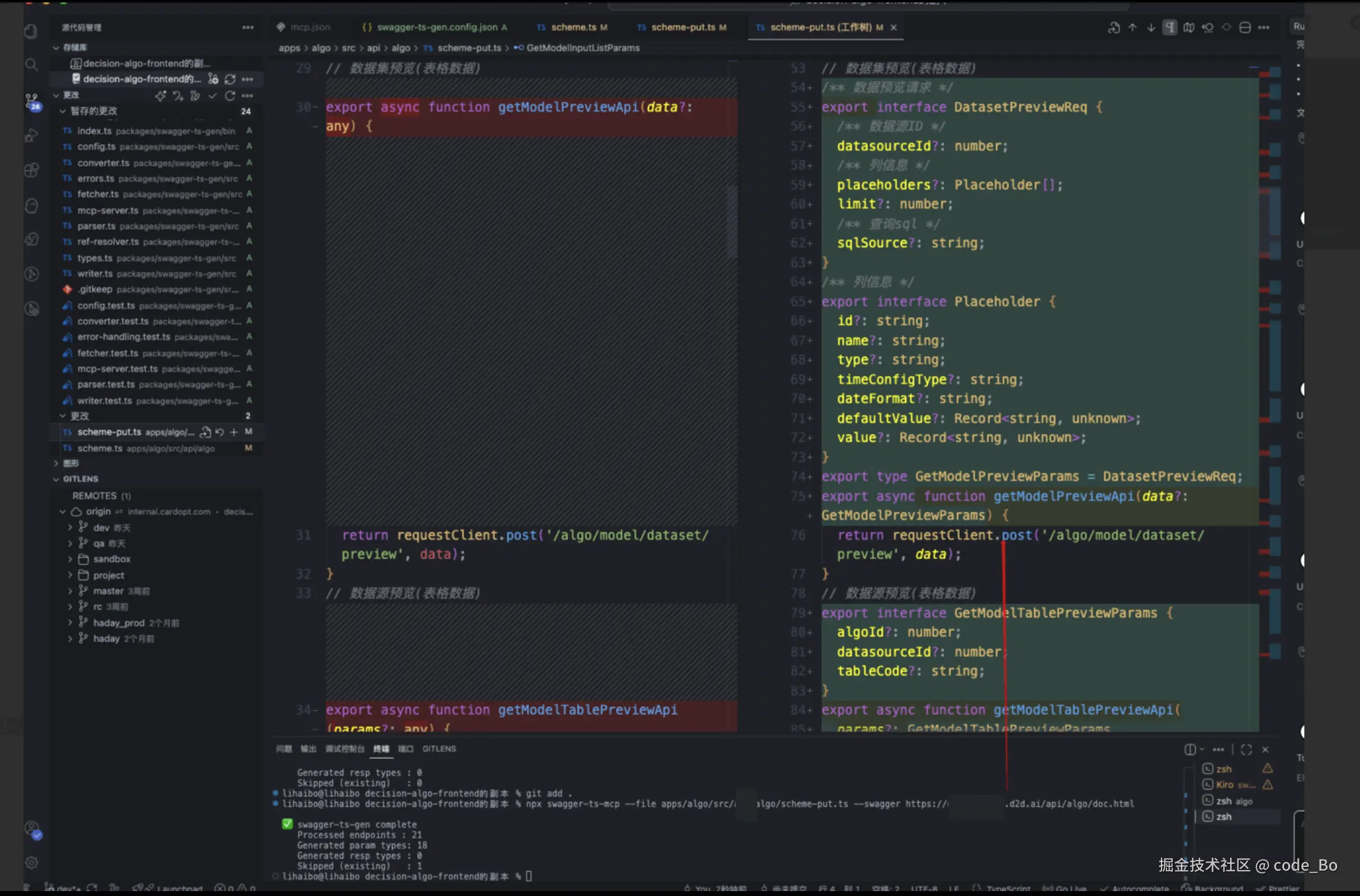
方式二:MCP Server(Kiro)
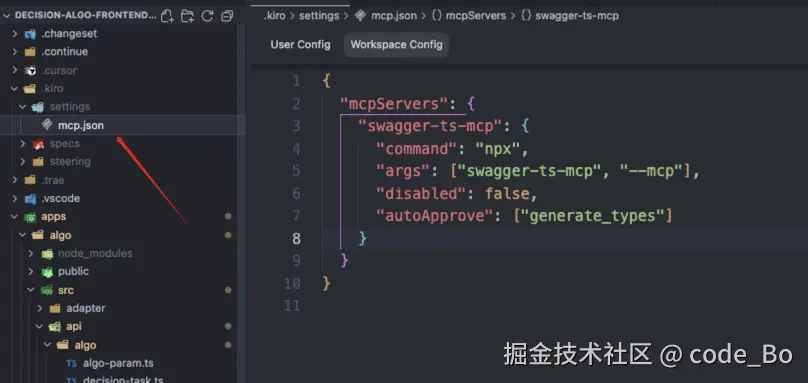
在 .kiro/settings/mcp.json 里添加:
json
{
"mcpServers": {
"swagger-ts-mcp": {
"command": "npx",
"args": ["swagger-ts-mcp", "--mcp"],
"autoApprove": ["generate_types"]
}
}
}
然后在聊天框里说:
帮我给 src/api/user.ts 生成 TypeScript 类型

方式二:MCP Server(Cursor)
在 .cursor/mcp.json 里添加:
json
{
"mcpServers": {
"swagger-ts-mcp": {
"command": "npx",
"args": ["swagger-ts-mcp", "--mcp"]
}
}
}
Cmd+Shift+P → Reload MCP Servers,然后在 Composer 里说:
使用 swagger-ts-mcp 工具,帮我给 src/api/user.ts 生成类型
支持的 API 文档工具
| 工具 | 使用方式 |
|---|---|
| Swagger / SpringDoc | 直接传 doc.html 地址,自动转换 |
| Knife4j | 同 Swagger,完全兼容 |
| YApi | 使用导出 URL:/api/plugin/export?type=swagger&pid=xxx&token=xxx |
| Apifox | 项目设置 → 导出 OpenAPI 3.0 URL |
配置项说明
| 配置项 | 说明 |
|---|---|
swaggerUrl |
Swagger 文档地址 |
defaultFiles |
默认处理的文件列表(支持多个) |
endpointPrefix |
路径前缀。代码里是 /algo/user/list,Swagger 里是 /user/list,设为 /algo |
clientName |
HTTP 客户端名称,默认 requestClient,可改为 axios 等 |
outputStyle |
生成 interface 还是 type,默认 interface |
用 AI 开发这个工具的完整过程
这个工具从需求到上线,全程在 Kiro(AI IDE)里完成,没有手写一行架构代码。说一下我是怎么引导 AI 一步步做出来的。
第一步:描述痛点,让 AI 帮你想清楚需求
很多人用 AI 写代码,上来就说"帮我写一个 xxx 工具",然后得到一堆不能用的代码。
我的做法是先描述问题,不急着让它写代码:
我有一个前端项目,接口文件里有很多函数参数是 any 类型,我想从 Swagger 文档自动生成 TypeScript 类型定义插入到文件里。你帮我梳理一下这个工具需要做哪些事情。
AI 会帮你把需求拆解成具体的验收标准,这个过程本身就是在帮你想清楚边界条件------比如"已有类型的函数要不要处理"、"路径前缀怎么处理"、"写入失败怎么办",这些细节如果一开始没想清楚,后面写代码会反复返工。
Kiro 有专门的 Spec 功能,可以把需求、设计、任务拆解都沉淀成文档,后续开发全程参照这些文档,不会跑偏。
第二步:需求确认后,让 AI 出设计文档
需求文档确认后,让 AI 基于需求出设计方案:
基于这些需求,帮我设计这个工具的架构,包括模块划分、每个模块的接口定义、数据流向。
这一步的关键是不要让 AI 直接写代码,先把设计定下来。
AI 给出了 6 个模块的划分(Parser、Fetcher、Converter、Writer、Config、RefResolver),每个模块的输入输出接口,以及完整的数据流。这份设计文档后来成了整个开发过程的"合同"------每个模块按接口开发,互不干扰。
设计文档里还有一个我觉得很有价值的部分:正确性属性。AI 把每个模块应该满足的行为约束都列出来了,比如"写入幂等性:同一个文件跑两次,结果不变"、"dry-run 不修改文件"。这些属性后来直接变成了属性测试的用例。
第三步:任务拆解,按模块逐个实现
设计文档确认后,让 AI 把开发任务拆成具体的实现步骤:
基于设计文档,帮我把实现拆成具体的任务列表,每个任务对应一个模块,标注依赖的需求条款。
拆出来大概 13 个任务,从"初始化项目结构"到"实现 CLI 入口",顺序是按依赖关系排的------先实现底层模块(Config、Fetcher、Converter),再实现上层(Parser、Writer),最后串联成完整流程(MCP Server、CLI)。
每个任务里还有对应的测试任务,单元测试和属性测试都在里面。
然后就是按任务列表逐个让 AI 实现:
现在实现任务 3:Swagger Fetcher。按照设计文档里的接口定义来,实现 URL 转换逻辑和错误处理。
每个模块实现完,让 AI 跑一下对应的测试,确认通过再继续下一个。
第四步:联调和边界情况处理
各模块实现完之后,串联起来跑真实场景,这时候会发现一些设计时没考虑到的问题。
比如我实际跑的时候发现:
defaultFiles配置了多个文件,但只处理了第一个------因为 CLI 入口里只取了config.defaultFiles?.[0],需要改成遍历所有文件- Swagger 地址需要登录认证的情况没有友好提示
这些问题直接描述给 AI,让它定位并修复:
defaultFiles 配置了多个文件,但实际只处理了第一个,帮我找一下问题在哪里修复。
AI 直接定位到 bin/index.ts 里的那行代码,改成了遍历逻辑。
第五步:发布和文档完善
工具本地测试没问题后,让 AI 帮我处理发布相关的事情:
- 完善
package.json(补充description、keywords、files、engines等字段) - 生成
.gitignore和.npmignore - 把 README 从中文扩展成中英双语(后来改成两个独立文件)
我的体会
用 AI 开发工具,最重要的不是"怎么让 AI 写代码",而是怎么把问题描述清楚。
几个实际有用的做法:
-
先描述问题,不要直接要代码。让 AI 帮你梳理需求,这个过程会暴露你自己没想清楚的地方。
-
设计先于实现。让 AI 出设计文档,确认接口定义,再开始写代码。跳过这步直接写代码,后面改起来很痛苦。
-
按模块推进,每步验证。不要让 AI 一次性把所有代码都写完,按模块来,每个模块实现完跑测试确认,再继续下一个。
-
遇到问题描述现象,不要猜原因。"defaultFiles 只处理了第一个文件"比"我觉得是循环逻辑有问题"更容易让 AI 定位到正确位置。
-
让 AI 生成测试。属性测试(Property-based testing)特别适合让 AI 来写,它能覆盖到你手动写用例时想不到的边界情况。
整个工具从开始到发布 npm,大概花了一个下午。如果纯手写,光设计文档和测试就得好几天。
总结
这个工具解决的问题很具体:消除前端接口文件里手写类型的重复劳动。
核心思路是:用 AST 解析找到需要处理的函数,从 Swagger 拉取 Schema,转换成 TypeScript 类型,精准写入文件。整个过程自动化,不需要人工介入。
MCP Server 模式让它可以直接集成到 AI IDE 的工作流里,配合 Kiro 或 Cursor 使用体验更顺滑。
项目地址:github.com/lhbDesign/s...
npm:www.npmjs.com/package/swa...
有问题或者建议欢迎提 issue。