在之前的两期详解系列中,我们介绍了导航模型 X-Mobility 的模仿学习和 VLA 模型 GR00T-N1.5 的 SFT:
-
PAI Physical AI Notebook 详解3:基于仿真的导航模型训练
-
PAI Physical AI Notebook 详解4:基于仿真的GR00T-N1.5模型微调
一般来说,对于基础技能,使用模仿学习或者微调的效果较好。但是对于复杂技能,需要较多步骤且需要处理多种意外扰动,就需要使用强化学习使模型学会自主处理复杂情形。
传统的机器人强化学习范式,往往局限于"本体感知"(Proprioception)------即依赖关节角度、力矩反馈等内部状态来学习灵巧的运动技能。然而,随着技术的不断进步,面对真实世界中非结构化、动态变化的复杂场景下的对于灵巧操作的强烈需求,新一代机器人智能体开始将包括RGB图像、深度图像、语义分割等多模态感知输入直接纳入强化学习策略闭环。这一趋势在近期兴起的VLA模型的强化学习探索中尤为显著,标志着机器人正从预设程序的执行者,逐步转变为具备环境感知理解能力的自主决策者。
然而,这一技术演进带来的直接挑战是计算规模的指数级上升。在强化学习训练中,为了获取足够的样本多样性以保障策略的泛化能力,我们通常需要并行运行成百上千个仿真环境,每一个并行环境不仅都需要独立的相机渲染管线,还伴随着高维视觉数据的实时处理与策略网络的前向和反向传播计算。当感知输入成为标配,GPU 的渲染负载与计算负载都将显著提升。渲染与计算的协同瓶颈已成为制约感知强化学习效率的核心挑战:如何支撑高保真视觉输入的大规模并行训练,同时保证算法收敛效率与训练吞吐量?
本文将围绕这一核心问题展开深入探讨。我们将基于 NVIDIA 强大的 Isaac Lab 机器人多模态强化学习框架,结合 NVIDIA 多卡多节点 GPU 集群的算力优势,探索如何将感知强化学习训练的规模化潜力真正释放出来。
在 PAI 的 Notebook Gallery 中,我们已经预置了本文介绍的最佳实践:
https://gallery.pai-ml.com/#/preview/deepLearning/cv/isaac_rl_exp

启动 DSW 并执行环境准备
通过 Notebook Gallery 启动 DSW,使用 Notebook Gallery 中指定的镜像,使用 GU8IS 的具备 RT Core 的机型规格,并挂载 Isaac Asset 5.1 公共数据集


在 DSW 启动完成后,执行 Notebook 中相应 Cell 以下载代码并完成环境配置
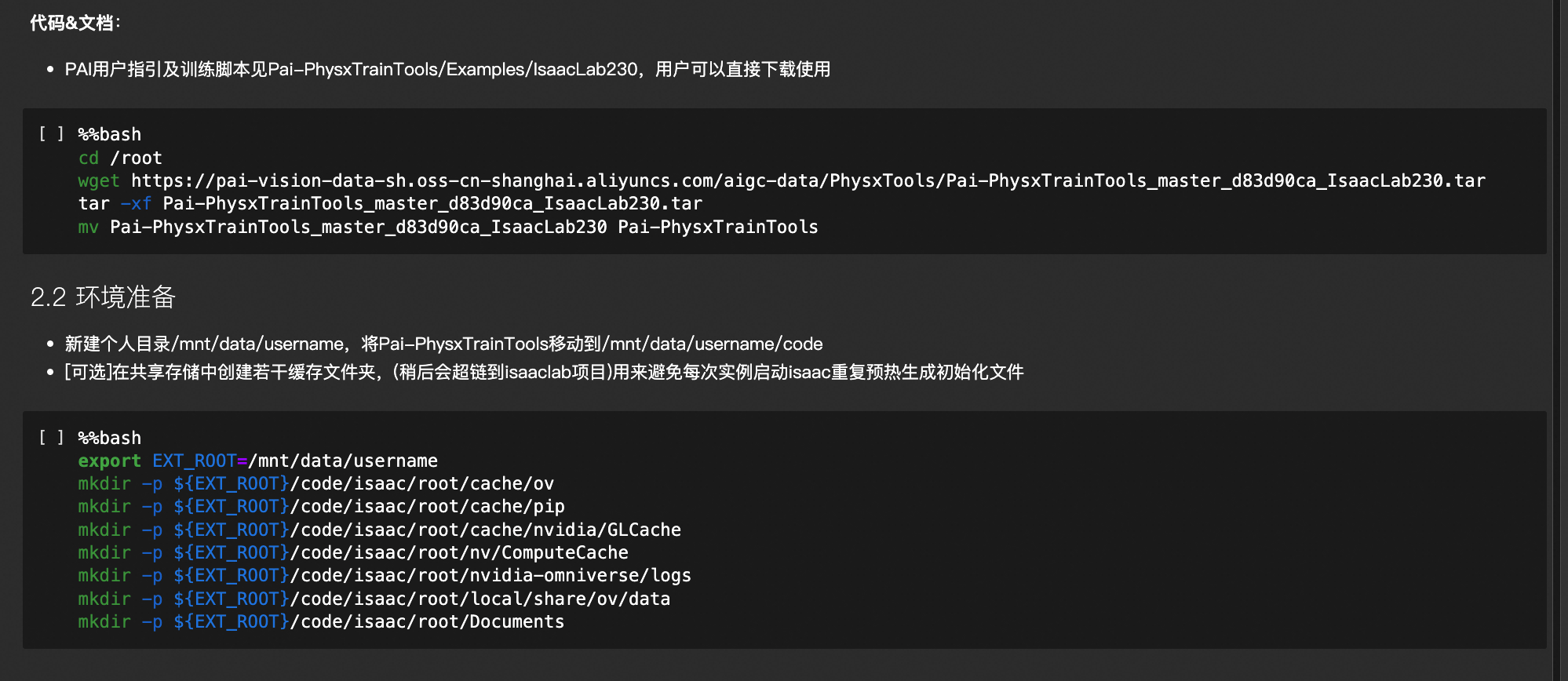
在 DSW 的 noVNC 环境中观察强化学习
在执行分布式强化学习之前,我们需要先在可视化环境下调试单机单卡强化学习过程,观察并确保过程很缺。
在云端环境进入可视化环境,标准的方式是通过 VNC。但是打通云端环境的 VNC 连接,需要配置服务端、打通网络隧道、配置本地客户端。这个过程不仅操作繁琐,需要反复在各种工具间切换,还存在一定安全隐患。
PAI-DSW 现在提供了 noVNC 功能,可以一键完成配置,并直接从 Web 端进入可视化环境并随时在 Notebook 和 Terminal 模式间切换,从而避免繁琐的网络隧道打通和 VNC 客户端配置。
进入 noVNC 环境后,执行以下命令启动强化学习:
shell
/workspace/isaaclab/isaaclab.sh -p ./Examples/IsaacLab230/rsl_rl/train.py --task Isaac-Repose-Cube-Shadow-Vision-Direct-v0 --enable_cameras --max_iterations 24000 --num_envs 512可以观察到,这个任务是通过强化学习,使 Shadow 机械手学会把方块按要求旋转到指定的朝向,一旦方块掉落或操作超时,则会判定本次操作失败。为了使模型充分探索并学习,训练过程需要并行启动多个仿真环境,并执行大量迭代。以上述命令为例:
● --max_iterations 24000:代表需要迭代24000次
● --num_envs 512:代表每张GPU卡启动512个环境
● --enable_cameras:代表需要启动视觉仿真
TiledCamera 使感知强化学习成为可能
从上述强化学习过程中可以看到,感知强化学习涉及大量视觉数据的并行仿真与多轮迭代,因此每一步的视觉成为计算资源开销的大头。如果使用传统 Camera 组件,其中的资源开销将非常巨大。
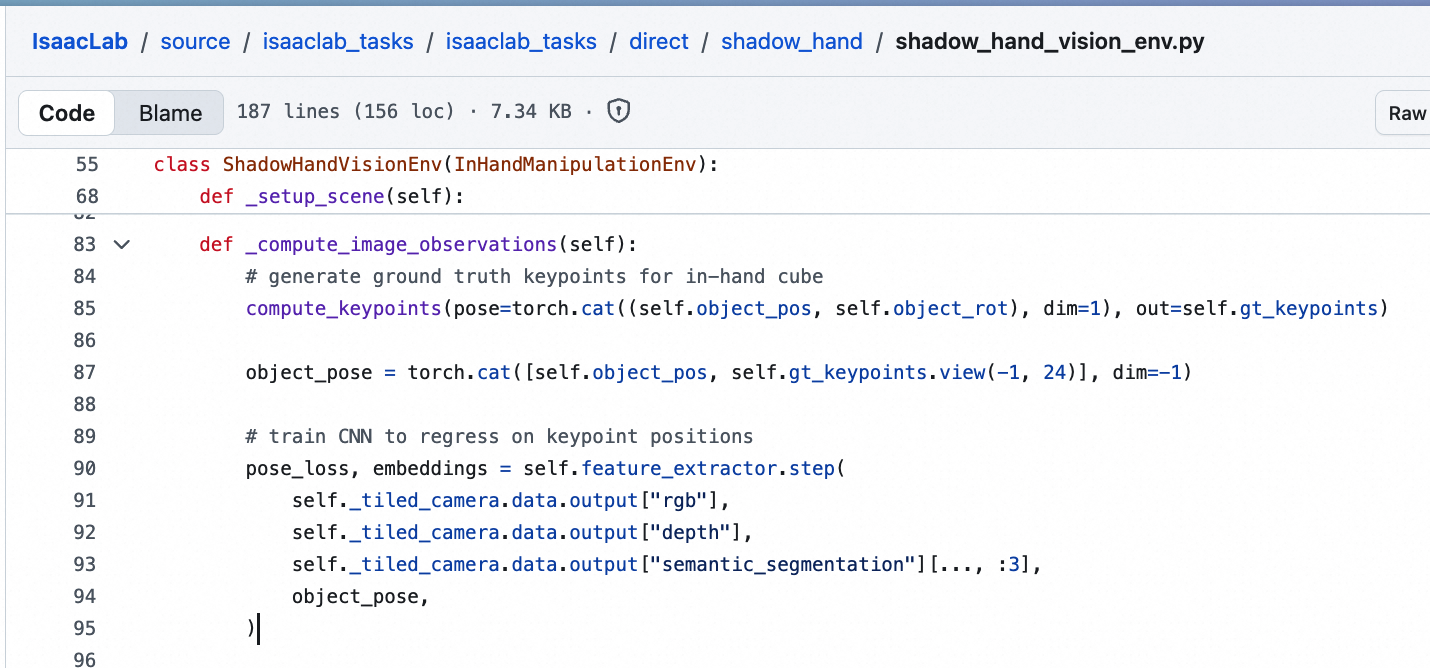
本 Notebook 中使用的 Isaac-Repose-Cube-Shadow-Vision-Direct-v0 任务,使用了 TiledCamera 组件解决这个问题。TiledCamera 的核心思想,是将所有并行环境中的相机视口在 GPU 上拼接成一张"大纹理图"(Tile),从而通过一次 GPU 渲染调用就能完成所有环境的图像输出,避免逐个环境单独渲染带来的巨大开销。
以本次实验环境为例,每个环境都配置了三类相机输入:RGB、深度(Depth)以及语义分割(Semantic Segmentation)。这些视觉信息共同用于引导 Shadow Hand(24 自由度的五指灵巧手)完成对积木的重定向操作。在 512 甚至更多并行环境的设置下,Tiled Camera 提供的批量并行渲染显著提升了整体训练吞吐量和效率,相比逐环境逐帧渲染具有明显优势。
使用 torchrun 启动分布式强化学习
Isaac Lab 原生支持 torchrun 方式启动分布式强化学习,支持通过 torch.distributed.run 启动跨 GPU、跨节点的分布式强化学习训练,并可与 rsl_rl、rl_games、skrl 等主流 RL 库无缝对接。典型流程中,每张 GPU 独立负责一组仿真环境及对应的神经网络前向推理,随后通过分布式通信在多卡之间同步梯度,从而在整体上实现数据并行的数据采集与策略更新。
可以通过以下命令启动单机8卡的强化学习:
shell
/workspace/isaaclab/isaaclab.sh -p -m torch.distributed.run \
--nproc_per_node=${NPROC_PER_NODE} \
--nnodes=${WORLD_SIZE} \
--node_rank=${RANK} \
--master_addr=${MASTER_ADDR} \
--master_port=${MASTER_PORT} \
./Examples/IsaacLab230/rsl_rl/train.py --task Isaac-Repose-Cube-Shadow-Vision-Direct-v0 --enable_cameras --headless --max_iterations 24000 --num_envs 512 --distributed其中:
- nproc_per_node、nnodes、node_rank、master_addr、master_port:典型的 torchrun 分布式配置,在PAI-DLC"PyTorch"类型任务中,将由DLC根据任务配置自动注入环境变量
● --distributed:启动 Isaac Lab 的分布式模式,确保各 Isaac Lab 进程间可通信
● --headless:在 Isaac Lab 分布式模式下,建议关闭可视化界面。如开启可视化,也仅能观察一个进程的过程,且会带来大量无效报警
在DLC中配置任务框架与任务规模

在DLC中配置任务启动命令
分布式感知强化学习效果分析
在 Notebook 中提供了两组系统性实验,从不同维度量化 GPU 规模对感知 RL 训练的影响。
实验一:横向扩展------更多 GPU,更多环境
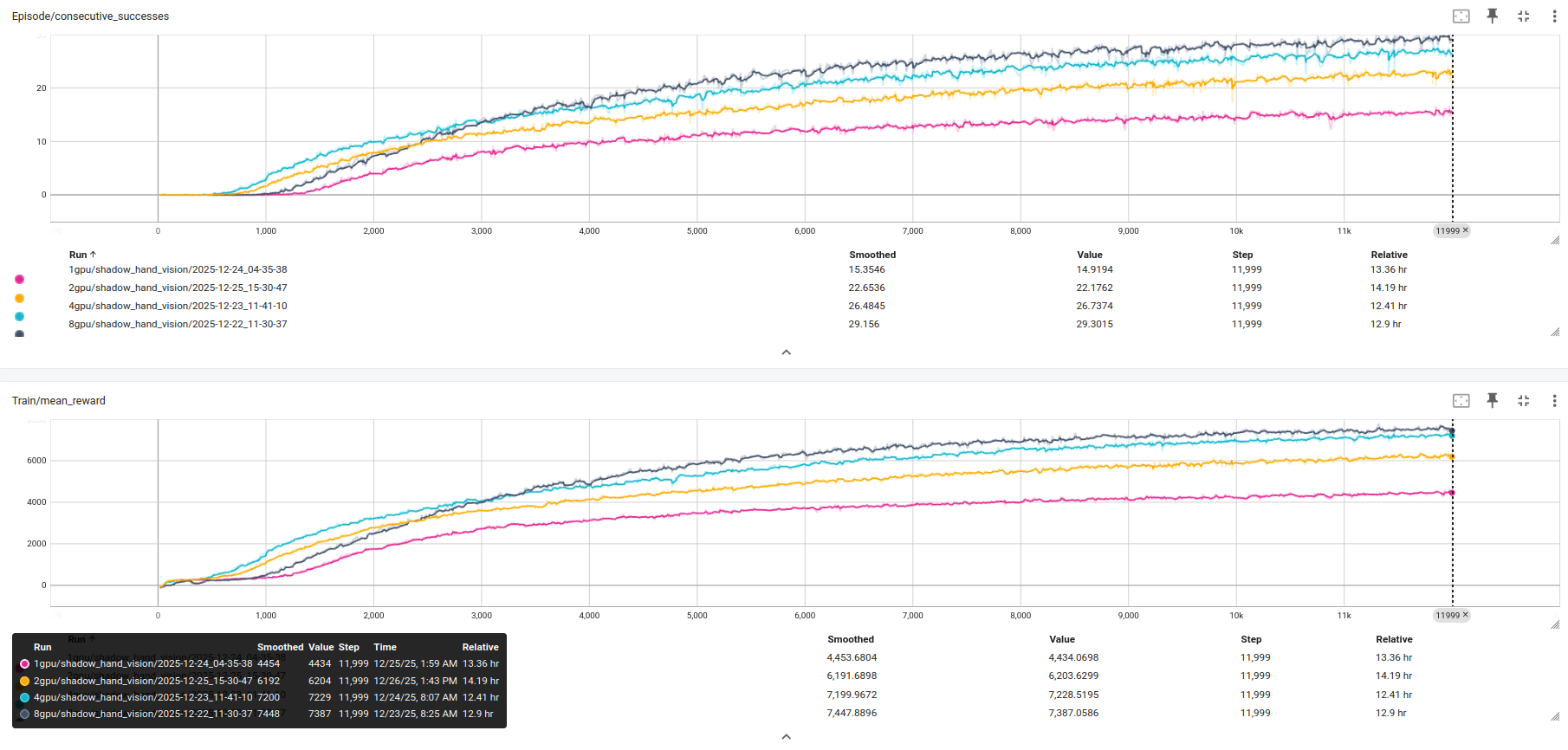
第一组实验中,每张 GPU 固定运行 512 个并行环境,从 1 卡逐步扩展到 4 卡(单机)、8 卡(单机)、16 卡(双节点)。总环境数随 GPU 数线性增长(512 → 2048 → 4096 → 8192),迭代次数均固定为 24,000 步。
通过 TensorBoard 可视化训练日志,两个核心指标的变化清晰可见:
• 任务成功率(Episode/consecutive_successes):随着总环境数增加,策略探索的多样性显著提升,任务成功率曲线更快上升,最终收敛值也随之提高。
• 收敛速度:熵损失和值函数损失在多卡配置下下降更为平稳,波动更小,体现出大批量并行采样对策略梯度估计质量的改善。
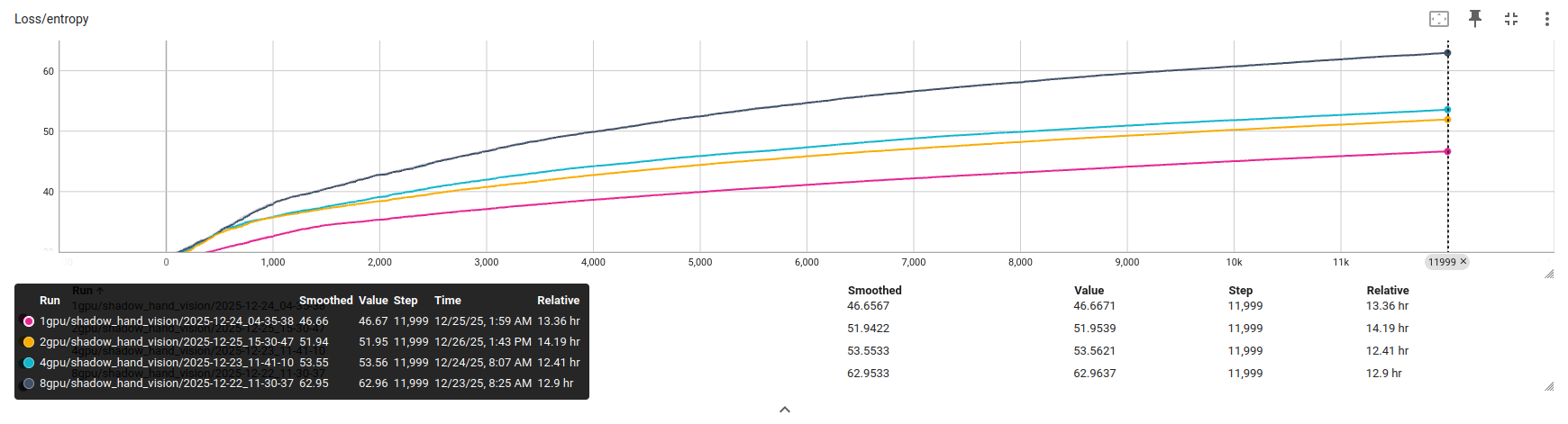
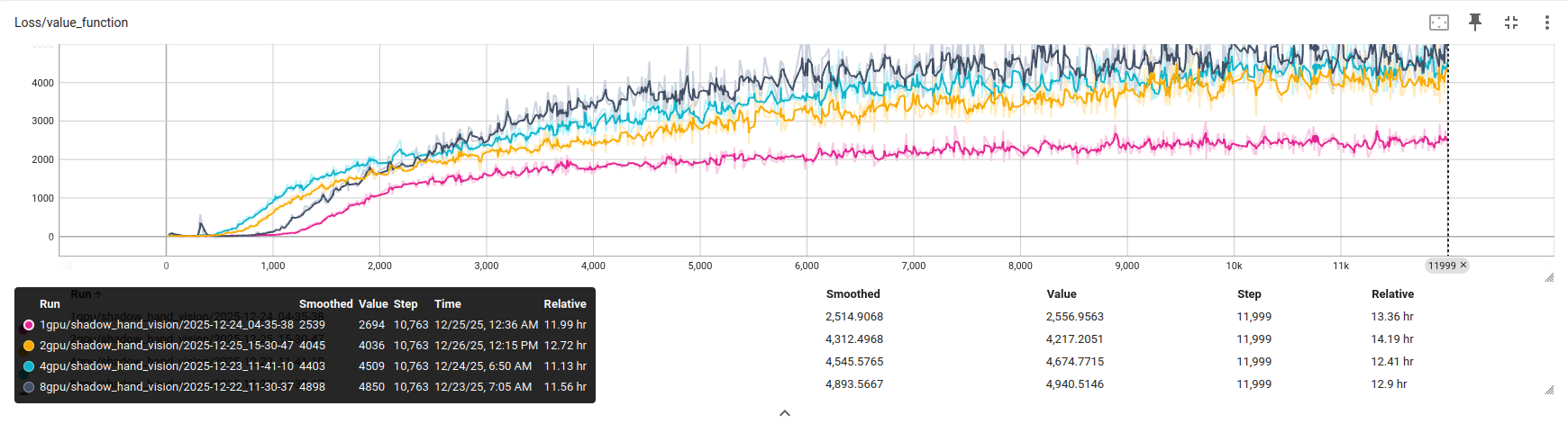
这一实验说明,在感知 RL 场景下,扩大 GPU 规模不只是加快同样质量的训练,而是能够训练出更好的策略。这与传统监督学习中"更多数据 = 更好模型"的规律高度一致。
实验二:纵向加速------多GPU并行提升训练效率
第二组实验将总环境数固定在约 2048 个,通过增加 GPU 卡数并按比例减少每卡环境数,在相同迭代次数下观察总训练时长的变化。
| GPU 卡数 | 每卡环境数 | 近似训练时长 |
|---|---|---|
| 1 卡 | 2048 | ~1.4 天 |
| 2 卡 | 1024 | ~21.0 小时 |
| 4 卡 | 512 | ~12.4 小时 |
关键指标 Perf/total_fps 的 TensorBoard 曲线显示,多卡配置下每秒完成的仿真步数显著增长。从单卡 1.3 天压缩到 4 卡 12.5 小时,这对于需要反复迭代超参数、快速验证新策略想法的研究人员而言,是研发效率的根本性提升。
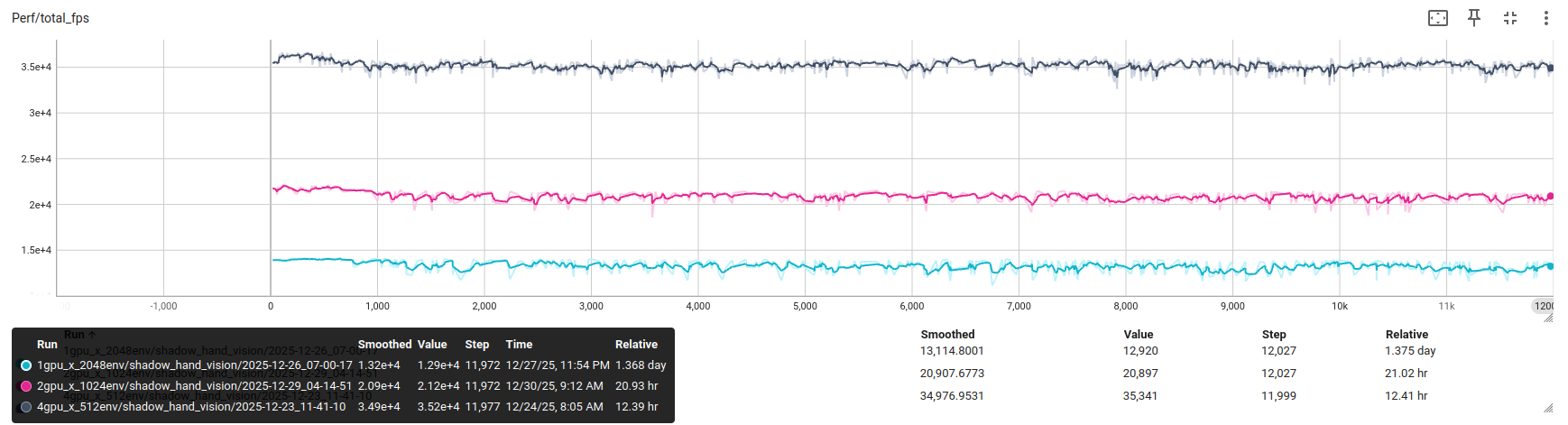
更值得关注的是,加速的同时准确性并不下降。通过 TensorBoard 对比 1 卡、2 卡、4 卡的 Train/mean_reward 和 Episode/consecutive_successes 曲线,可以看到:在相同迭代步数下,多卡配置的任务成功率与单卡训练结果保持高度一致,并未因为每卡分到的环境减少而产生精度损失。说明 Isaac Lab 的分布式训练策略在梯度同步上是几乎"无损"的------GPU 数量增加所提升的效率并不会以牺牲效率为代价
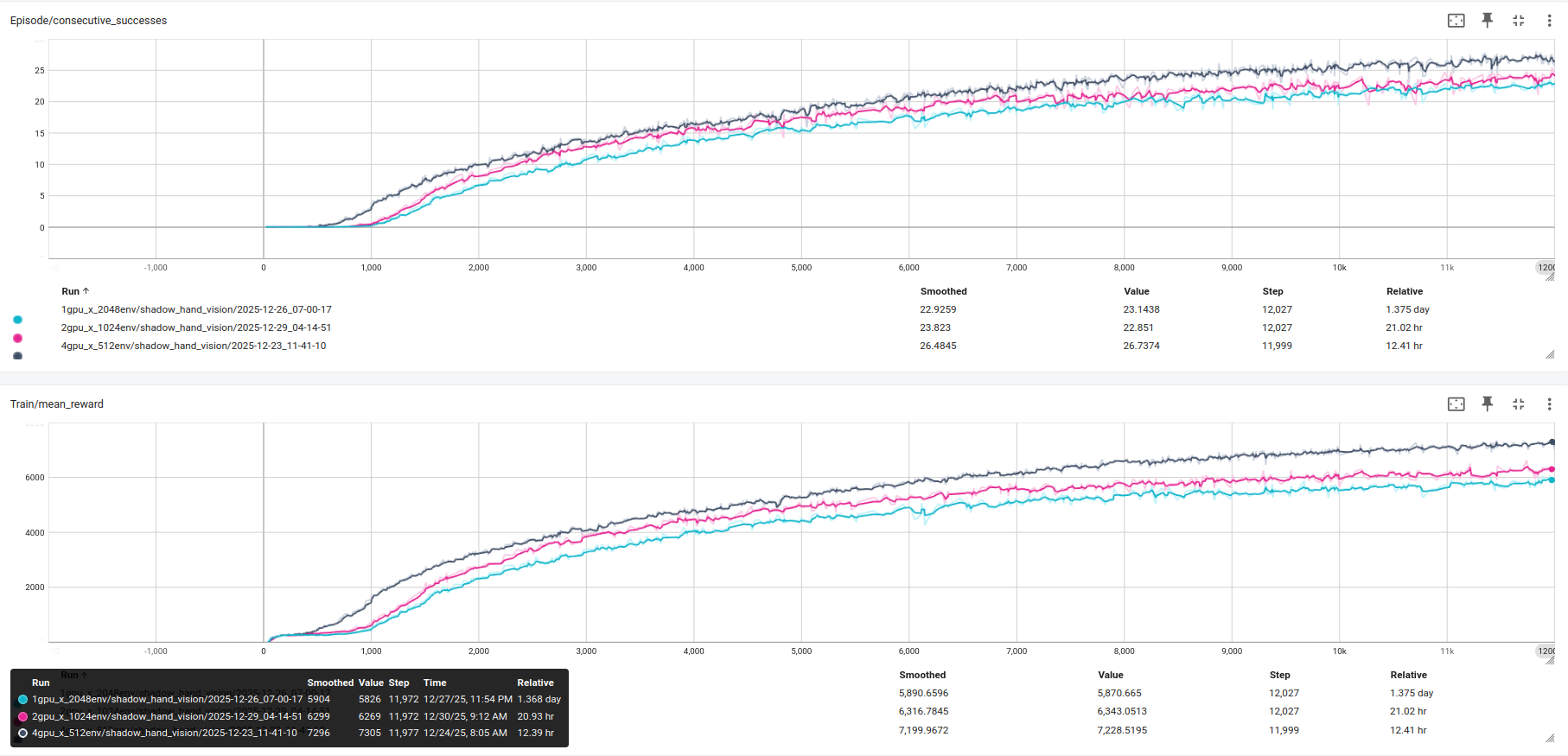
以上两个实验共同揭示了 NVIDIA GPU 集群在感知 RL 训练中的双重价值:既能通过扩大环境规模提升策略质量,又能通过增加算力密度缩短实验周期,二者可以根据实际研究需求灵活选择。
小结
本研究介绍了基于 PAI 平台和 NVIDIA Isaac Lab 进行分布式感知强化学习的过程。针对传统基于本体感知的强化学习框架难以处理高维度多模态感知数据流(包括 RGB-D 图像、点云等)的问题,依托 NVIDIA Isaac Lab 以及 TiledCamera 组件,将视觉传感器数据流分解为可并行处理的瓦片化数据块,实现了渲染任务与物理仿真计算的时空解耦,有效缓解了大规模分布式训练中的渲染并发瓶颈。
同时,结合 PAI-DSW 的 noVNC 可视化调试系统,建立了支持实时遥测与模型观测的闭环开发环境,显著提升了多模态感知强化学习算法的开发效率。结合 PAI-DLC 的 PyTorch 分布式任务,与 Isaac Lab 对 torchrun 的原生支持结合,可以快速启动多机多卡的分布式强化学习。
该Notebook为解决高维感知空间下的机器人智能体训练难题提供了系统级解决方案,释放了基于多模态感知的强化学习算法在规模化场景中的应用潜力。