做内核开发的同学应该都有过这样的困扰:多核CPU普及后,共享数据的并发访问成了性能瓶颈。传统的自旋锁、互斥锁虽然能保住数据一致性,但高并发下的锁竞争的问题,真的太影响效率了。
大家可以想象一个场景:一个繁忙的十字路口,每个方向的车辆都想同时通过,没有规则的话必然堵成一锅粥。传统锁机制就像一个"一刀切"的管理员,只要有一辆车(线程)要过马路(访问数据),就拦住所有其他车,哪怕是不同方向的。这样一来,线程要么原地等待(自旋锁)浪费CPU,要么睡眠唤醒(互斥锁)增加上下文切换开销,CPU流水线也会被打断,效率自然上不去。
尤其是在多核系统中,CPU核心越多,这种"堵车"现象越严重。就像多条高速路的车都挤向一个收费站,核心数量翻倍,锁竞争的开销可能会呈指数级上升。更头疼的是传统读写锁,虽然区分了读写,但写锁一拿,所有读操作都得等着,这在"读多写少"的场景里,简直是"捡了芝麻丢了西瓜"。
而RCU机制的出现,刚好解决了这个痛点,相当于给这个十字路口装了一套智能交通系统。它不搞"一刀切"的封锁,反而给读操作开了"专用通道"------读者不用等、不用抢,能自由并行访问;写操作则悄悄"抄作业",不打扰读者。这种设计在"读多写少"场景里的优势,简直是碾压级的。
一、认识 RCU
1.1 RCU 的定义与核心定位
很多人第一次听到RCU(Read-Copy-Update,读-拷贝-更新),都会被"读-拷贝-更新"这六个字绕晕,其实用一个通俗的例子就能懂。共享数据就像图书馆里的一本热门参考书,很多人(读者)想借来看,偶尔有管理员(写者)要修改书中内容。
传统锁机制下,管理员修改时会把书锁起来,所有人都不能看;而RCU的思路很灵活:管理员不直接改原书,先拿一本副本,在副本上修改,改完之后,把图书馆里的原书换成新副本,等所有正在看原书的人都看完了,再把原书回收。对应到内核中,就是这样一段极简的核心逻辑(入门级示例):
#include <linux/rculist.h>
#include <linux/sched.h>
// 定义一个RCU保护的共享数据结构
struct my_data {
int id;
char name[32];
struct rcu_head rcu; // 用于RCU延迟回收
};
struct my_data *g_shared_data; // 全局共享指针,由RCU保护简单说,RCU就是为"读多写少"场景量身定做的内核同步机制,它摒弃了传统锁的"排他性",让读者零等待、写者异步更新,这也是它能在 kernel 里广泛应用的核心原因。
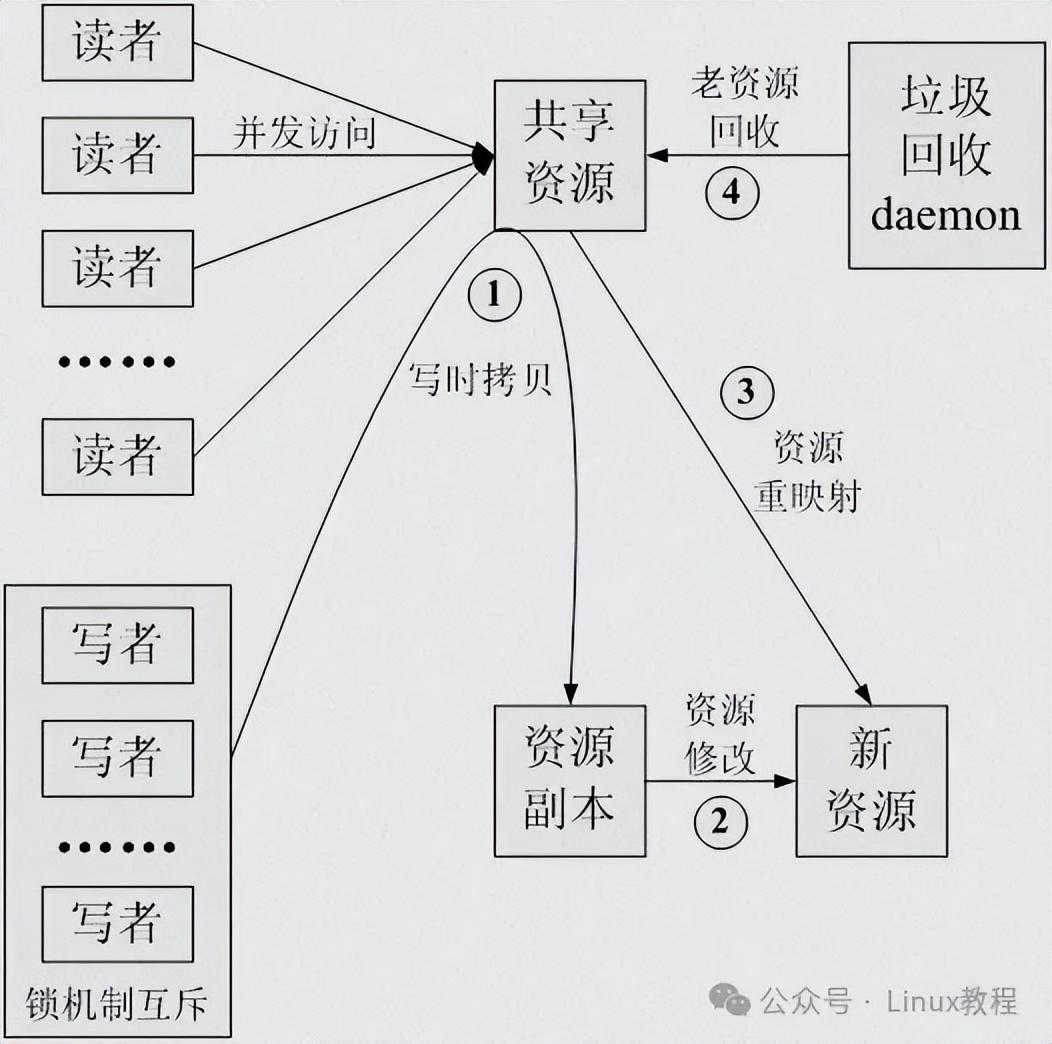
它的核心逻辑其实就三点:读者无锁、写者拷贝、延迟回收,咱们结合上面的代码再细化说。读者访问g_shared_data这个共享指针时,不用加任何锁,直接通过RCU专属接口读取,多个读者能同时并行;写者要修改数据时,先拷贝一份g_shared_data的副本,在副本上修改id、name等字段,改完之后用原子操作替换指针,最后等所有读者都看完原数据,再回收旧副本的内存。
比如写者修改数据的简易流程(后续会讲完整API):
// 写者:修改共享数据(核心流程简化版)
void update_shared_data(int new_id, const char *new_name) {
struct my_data *new_data, *old_data;
// 1. 分配新内存,拷贝旧数据(写者拷贝)
new_data = kmalloc(sizeof(struct my_data), GFP_KERNEL);
old_data = g_shared_data;
memcpy(new_data, old_data, sizeof(struct my_data));
// 2. 在副本上修改数据
new_data->id = new_id;
strncpy(new_data->name, new_name, sizeof(new_data->name)-1);
// 3. 原子替换指针,发布新数据(后续讲rcu_assign_pointer)
rcu_assign_pointer(g_shared_data, new_data);
// 4. 延迟回收旧数据(后续讲call_rcu)
call_rcu(&old_data->rcu, free_old_data);
}
// 旧数据回收回调函数
void free_old_data(struct rcu_head *rcu) {
struct my_data *data = container_of(rcu, struct my_data, rcu);
kfree(data); // 宽限期结束后,安全释放旧数据
}目前大家不用纠结API的细节,重点理解"拷贝-修改-替换-回收"的思路就行。RCU在kernel里的应用特别广,文件系统的dcache、网络协议栈的路由表、进程管理的任务链表,都有它的身影,本质上都是因为这些场景符合"读多写少"的特点。
就拿最常见的文件系统dcache来说,咱们执行ls命令查看目录时,内核会先去dcache里查目录项,这个读操作每秒可能发生上千次;而创建、删除目录项的写操作,可能每秒只有几次。用RCU保护dcache,就能让所有ls操作并行执行,不用等、不卡顿;写操作悄悄拷贝修改,完全不影响读者,这就是RCU的实战价值。
2.2 传统锁机制的两大致命痛点
明白了RCU的基本思路后,咱们再回头看看传统锁机制的问题------不是它不好,而是在高并发读场景里,它的痛点太明显了。我总结了两个最致命的问题,结合代码场景大家更容易理解。
第一个痛点是效率极低,咱们用自旋锁和RCU做个简单对比就清楚了。比如同样是读取共享数据,自旋锁的代码是这样的:
// 自旋锁读取共享数据(有锁竞争开销)
spinlock_t my_lock = SPIN_LOCK_UNLOCKED;
struct my_data *g_shared_data;
void read_with_spinlock() {
struct my_data *data;
spin_lock(&my_lock); // 拿锁,可能自旋等待
data = g_shared_data;
// 读取数据...
spin_unlock(&my_lock); // 释放锁
}这段代码里,多个线程同时调用read_with_spinlock时,只有一个线程能拿到锁,其他线程都要原地自旋,浪费CPU资源;就算是互斥锁,线程睡眠唤醒的上下文切换开销,也比自旋锁好不到哪里去。而且锁的实现依赖硬件原子操作,会打断CPU流水线,就像生产线频繁停工,效率自然高不了。
更坑的是读写锁,咱们再看一段读写锁的代码:
// 读写锁示例(写锁排他,阻塞读操作)
rwlock_t my_rwlock = RW_LOCK_UNLOCKED;
struct my_data *g_shared_data;
// 读操作
void read_with_rwlock() {
read_lock(&my_rwlock); // 拿读锁
// 读取g_shared_data...
read_unlock(&my_rwlock);
}
// 写操作
void write_with_rwlock() {
write_lock(&my_rwlock); // 拿写锁,排他性
// 修改g_shared_data...
write_unlock(&my_rwlock);
}这段代码里,只要有一个线程拿到写锁,所有读线程都得阻塞等待,哪怕读操作比写操作频繁10倍、100倍。在高并发读场景里,这种设计相当于"因噎废食",本来读操作能并行,结果被写锁堵得水泄不通,系统整体效率直接拉胯。
第二个痛点是扩展性差,这个问题在多核CPU上会被无限放大。还是拿收费站的例子来说,传统锁就是那个唯一的收费站,CPU核心越多(车辆越多),拥堵越严重。比如4核CPU时,锁竞争开销可能是1核的4倍;到了32核、64核,开销可能会翻几十倍,完全发挥不出多核的优势。
而RCU刚好避开了这两个痛点,这也是它能成为内核"并发神器"的关键------咱们接下来就看看RCU的核心优势,结合代码对比,差距一眼就能看出来。
1.3 RCU 的核心优势
对比传统锁的痛点,RCU的优势其实很明确,总结下来就三点,每一点都能解决实际开发中的难题,咱们结合代码一个个说,大家看完就能明白为什么RCU这么好用。
优势一:读操作零开销这是RCU最核心的优势,没有之一。咱们看RCU读操作的代码,对比之前的自旋锁、读写锁,差距特别明显:
// RCU读操作(零开销,无锁竞争)
void read_with_rcu() {
struct my_data *data;
rcu_read_lock(); // 标记读临界区,仅禁用抢占,无锁竞争
data = rcu_dereference(g_shared_data); // 安全读取指针
if (data) {
// 读取数据:打印id和name
printk("RCU read: id=%d, name=%s\n", data->id, data->name);
}
rcu_read_unlock(); // 退出临界区,启用抢占
}这段代码里,rcu_read_lock只是禁用内核抢占,没有原子操作、没有锁竞争,多数CPU架构下甚至不用加内存屏障。多个线程同时调用read_with_rcu,能真正实现并行执行,CPU资源完全不浪费------这就是"读操作零开销"的精髓,也是RCU在读多写少场景里碾压传统锁的关键。
优势二:读写操作互不阻塞 这一点解决了传统读写锁的致命问题。还是结合代码来看,当写者执行update_shared_data修改数据时,读者依然能调用read_with_rcu读取旧数据,完全不会被阻塞;反过来,读者在读数据时,写者也能正常进行拷贝、修改操作,互不干扰。
举个实际场景:网络路由表更新(写操作)时,数据包转发需要读取路由表(读操作)。如果用读写锁,写路由表时,所有数据包转发都会阻塞,网络延迟会飙升;而用RCU,写者拷贝修改路由表,读者继续读取旧路由表转发数据包,完全不卡顿,等写者更新完成,读者再自动读取新路由表------这种"读写并行"的特性,在高并发场景里太重要了。
优势三:彻底规避死锁风险 做内核开发的同学,应该都被死锁坑过------排查死锁的过程又耗时又费力,有时候调试几天都找不到问题。而RCU从根源上解决了这个问题,因为读者根本不需要拿锁。
死锁的产生,本质是多个线程互相等待对方释放锁;而RCU的读者不用拿任何锁,自然就不会产生锁等待,死锁也就无从谈起。就像上面的read_with_rcu函数,全程没有拿锁操作,不管多少个读者并行,不管和写者如何交互,都不会出现死锁------这大大降低了内核开发的复杂度,也减少了调试成本。
二、深度拆解:RCU 的核心原理
2.1 三大核心思想:读无锁、写复制、延迟回收
理解了RCU的优势,接下来咱们深入拆解它的核心原理------其实所有优势的背后,都是"读无锁、写复制、延迟回收"这三大核心思想在支撑。
读操作无锁化这一点前面已经提过,这里再结合代码细化,让大家知道"无锁"到底是怎么实现的。RCU的读者不用拿锁,但需要用rcu_read_lock和rcu_read_unlock标记读临界区,核心目的是禁用/启用内核抢占------不是为了互斥,而是为了让写者能准确判断"还有没有读者在访问旧数据"。
// 完整RCU读操作示例(含异常处理)
void rcu_reader_demo() {
struct my_data *data;
// 1. 进入读临界区:禁用内核抢占,防止读者被切换
rcu_read_lock();
// 2. 安全读取共享指针:rcu_dereference防止指令重排
data = rcu_dereference(g_shared_data);
// 3. 读取数据(需判断指针非空,避免空指针异常)
if (data != NULL) {
printk("Reader: id=%d, name=%s\n", data->id, data->name);
} else {
printk("Reader: shared data is NULL\n");
}
// 4. 退出读临界区:启用内核抢占,允许线程切换
rcu_read_unlock();
}这里要注意:rcu_read_lock不是锁,它只是禁用抢占,所以没有锁竞争开销;rcu_dereference的作用是防止编译器或CPU指令重排,避免读者读到"半初始化"的指针(后面讲发布-订阅机制会细说)。多个读者同时执行这段代码,能真正实现并行,CPU利用率拉满。
写操作复制更新这是RCU"不阻塞读者"的关键------写者不碰原数据,只修改副本,修改完再替换指针。咱们结合完整的写者代码,看看这一步具体怎么实现:
// 完整RCU写者操作示例(含内存分配检查)
void rcu_writer_demo(int new_id, const char *new_name) {
struct my_data *new_data, *old_data;
// 1. 分配新内存,创建旧数据副本(写者拷贝核心步骤)
new_data = kmalloc(sizeof(struct my_data), GFP_KERNEL);
if (!new_data) { // 检查内存分配是否成功,避免内存泄漏
printk("Writer: kmalloc failed\n");
return;
}
// 2. 读取旧数据指针(无需加锁,直接读取)
old_data = g_shared_data;
// 3. 拷贝旧数据到新副本,再修改新副本内容
if (old_data) {
memcpy(new_data, old_data, sizeof(struct my_data));
} else {
// 旧数据为空,初始化新数据默认值
memset(new_data, 0, sizeof(struct my_data));
}
new_data->id = new_id;
strncpy(new_data->name, new_name, sizeof(new_data->name)-1);
// 4. 原子替换指针,发布新数据(后面讲rcu_assign_pointer细节)
rcu_assign_pointer(g_shared_data, new_data);
printk("Writer: update success, new id=%d, new name=%s\n", new_id, new_name);
}这段代码的核心是"拷贝-修改-替换":写者先分配新内存,拷贝旧数据,再修改副本,最后用rcu_assign_pointer替换指针。整个过程中,原数据(old_data)完全没被修改,读者依然能正常访问,不会被阻塞------这就是"读写并行"的底层逻辑。
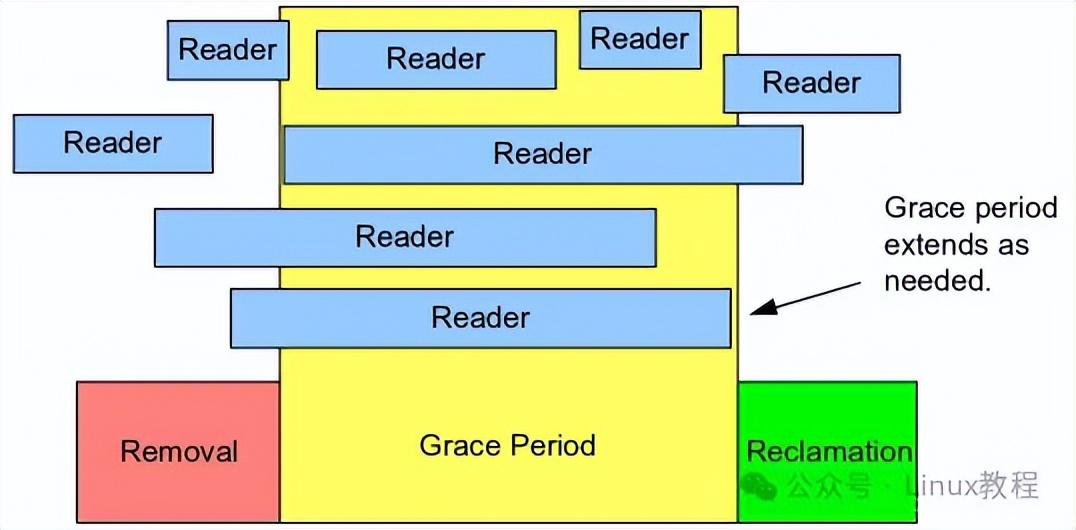
写者替换指针后,不能立即释放old_data的内存------因为可能还有读者在访问old_data(这些读者是在指针替换前进入读临界区的)。只有等所有这些读者都退出临界区,才能安全释放旧数据,这段等待时间就是"宽限期"。
咱们完善写者代码,加上延迟回收的逻辑(用call_rcu异步回收,内核常用方式):
// 旧数据回收回调函数(宽限期结束后自动调用)
void rcu_free_old_data(struct rcu_head *rcu) {
// 通过container_of宏,从rcu_head反向获取my_data结构体
struct my_data *data = container_of(rcu, struct my_data, rcu);
printk("Free old data: id=%d, name=%s\n", data->id, data->name);
kfree(data); // 安全释放旧数据内存
}
// 完善写者代码,添加延迟回收步骤
void rcu_writer_demo(int new_id, const char *new_name) {
struct my_data *new_data, *old_data;
// 步骤1-4:拷贝、修改、替换指针(同前面代码,省略重复部分)
// ...(省略内存分配、拷贝、修改代码)
// 5. 延迟回收旧数据:注册回调,宽限期结束后自动回收
if (old_data) {
call_rcu(&old_data->rcu, rcu_free_old_data);
}
}这里的关键是call_rcu函数:它不会阻塞写者,写者注册完回调后就能继续执行其他任务;等宽限期结束,内核会自动调用rcu_free_old_data,释放old_data的内存。这样既保证了读者能安全访问旧数据,又避免了写者阻塞------这就是延迟回收的核心价值。
2.2 关键概念:宽限期、宁静状态与发布 - 订阅
掌握了三大核心思想,咱们再来看RCU里三个必须懂的关键概念------宽限期、宁静状态、发布-订阅。这三个概念是理解RCU底层实现的关键,也是面试常考的点。
2.2.1 宽限期(Grace Period):旧数据的 "安全等待期"
宽限期(Grace Period),咱们前面已经提过,简单说就是"旧数据的安全等待期"------从写者用rcu_assign_pointer替换指针开始,到所有访问旧数据的读者都退出临界区结束,这段时间就是宽限期。
宽限期的核心作用,就是保证"没有读者再访问旧数据",这样写者才能安全释放old_data。咱们结合前面的写者代码,再补充一个同步等待宽限期的示例(synchronize_rcu,阻塞式):
// 同步等待宽限期(阻塞式,适用于无需异步的场景)
void rcu_writer_sync_demo(int new_id, const char *new_name) {
struct my_data *new_data, *old_data;
// 步骤1-4:拷贝、修改、替换指针(同前面代码)
new_data = kmalloc(sizeof(struct my_data), GFP_KERNEL);
if (!new_data) return;
old_data = g_shared_data;
memcpy(new_data, old_data, sizeof(struct my_data));
new_data->id = new_id;
strncpy(new_data->name, new_name, sizeof(new_data->name)-1);
rcu_assign_pointer(g_shared_data, new_data);
// 同步等待宽限期结束(阻塞当前写者线程)
synchronize_rcu();
// 宽限期结束,安全释放旧数据
if (old_data) {
printk("Sync free old data: id=%d\n", old_data->id);
kfree(old_data);
}
}这里要注意:synchronize_rcu会阻塞写者,直到宽限期结束;而call_rcu不会阻塞,更适合内核高性能场景。宽限期的长度不固定,取决于所有CPU是否都经历了"宁静状态"------这也是宽限期的判断标准。
宽限期的判断标准很简单:所有CPU都至少经历一次宁静状态。什么是宁静状态?就是CPU不在RCU读临界区内的状态,最常见的就是上下文切换------当CPU发生上下文切换时,说明当前CPU上的线程被切换了,之前的读临界区自然也就结束了,没有读者再访问旧数据了。
比如一个CPU上的读者正在执行rcu_reader_demo,此时CPU处于"非宁静状态";当读者执行完rcu_read_unlock,或者被内核抢占、发生上下文切换,CPU就进入了"宁静状态"。内核会监测每个CPU的宁静状态,当所有CPU都进入过一次宁静状态,就说明"所有旧读者都退出了",宽限期结束。
举个实际例子:写者替换指针后,有3个CPU上还有读者在访问旧数据;当这3个CPU依次发生上下文切换(进入宁静状态),宽限期就结束了,写者就能安全释放旧数据------这就是宽限期的底层判断逻辑,不用死记硬背,理解"上下文切换"这个关键场景就够了。
内核监测宁静状态的方式很灵活,会利用定时器、软中断等机制,定期检查每个CPU的状态。写者等待宽限期的两种方式,咱们再总结一下(结合代码,方便大家实际使用):
// 两种等待宽限期的方式对比
void wait_grace_period_demo() {
// 方式1:同步等待(阻塞式)
synchronize_rcu();
// 特点:简单直接,写者阻塞,直到宽限期结束
// 适用场景:写操作不频繁、对延迟不敏感的场景
// 方式2:异步等待(非阻塞式)
struct my_data *old_data = g_shared_data;
if (old_data) {
call_rcu(&old_data->rcu, rcu_free_old_data);
}
// 特点:写者不阻塞,注册回调后立即返回,宽限期结束后自动回收
// 适用场景:写操作频繁、对延迟敏感的内核场景(推荐使用)
}实际内核开发中,call_rcu用得更多,因为它不会阻塞写者,能提升系统并发性能;synchronize_rcu只用在一些简单的、非高性能场景中,比如内核初始化时的少量更新操作。
2.2.2 宁静状态(Quiescent State):读者活动的 "休止符"
宁静状态,说白了就是CPU"不处理RCU读操作"的状态,就像读者看完书放下了,进入了"休息状态"。除了最常见的上下文切换,还有几种情况也属于宁静状态,咱们结合内核场景简单说,不用太深入:
-
CPU进入空闲状态:没有线程在执行,自然没有RCU读操作;
-
中断/软中断处理过程:中断执行时,内核会暂时禁用抢占,且中断处理函数中一般不会执行RCU读操作;
-
线程退出:线程退出前,会执行完所有临界区操作,自然也就退出了RCU读临界区。
内核会给每个CPU维护一个"宁静状态标记",当CPU进入上述状态时,标记会被更新;宽限期检测机制会定期读取所有CPU的标记,判断是否都进入过宁静状态------这就是宽限期结束的核心判断逻辑,理解起来其实很简单。
可能有粉丝会问:**为什么一定要等所有CPU都经历一次宁静状态?**因为写者替换指针后,不知道哪个CPU上还有读者在访问旧数据------可能CPU1、CPU3上还有读者,CPU2、CPU4上没有。只有等所有CPU都进入过一次宁静状态,才能确保"不管哪个CPU上有旧读者,都已经退出临界区了"。
举个例子:CPU1上有一个读者正在读旧数据,此时CPU1处于"非宁静状态";过了一段时间,CPU1发生上下文切换,读者退出临界区,CPU1进入"宁静状态"。当所有CPU都经历过这样的过程,写者就可以确定"没有旧读者了",旧数据就能安全释放------这就是宁静状态的核心作用,是宽限期判断的基础。
内核监测宁静状态的实现不算复杂,核心是"per-CPU状态跟踪"------每个CPU都有一个结构体,记录自己最近一次进入宁静状态的时间、状态类型等信息。宽限期检测线程会定期遍历所有CPU的这个结构体,判断是否都满足"至少一次宁静状态"的条件,满足则触发宽限期结束,调用回调函数回收旧数据。
这里不用纠结底层实现细节,重点记住:宁静状态是CPU不在RCU读临界区的状态,上下文切换是最典型的宁静状态,所有CPU都经历一次宁静状态,宽限期就结束------面试问到这一点,能说清楚这个逻辑就够了。
2.2.3 发布 - 订阅机制:数据一致性的 "守护神"
发布-订阅机制,听起来很高大上,其实就是为了解决"指令重排"导致的数据不一致问题。咱们结合代码场景,就能轻松理解------如果没有这个机制,可能会出现"写者还没改完数据,读者就读到了半初始化的新数据"的情况。
先看一个反面例子(没有发布-订阅,可能出问题):
// 错误示例:无发布-订阅机制,可能出现指令重排
void bad_writer() {
struct my_data *new_data = kmalloc(sizeof(struct my_data), GFP_KERNEL);
g_shared_data = new_data; // 先更新指针(指令重排可能导致)
new_data->id = 100; // 后修改数据
new_data->name = "bad_data";
}编译器或CPU为了优化性能,可能会重排指令------把"g_shared_data = new_data"提前到"修改数据"之前。这样一来,读者可能会读到"指针已经更新,但数据还没改完"的半初始化数据(id和name是随机值),导致程序异常。而RCU的发布-订阅机制,就是为了防止这种情况。
正确的做法,就是用rcu_assign_pointer(发布)和rcu_dereference(订阅):
// 正确示例:发布-订阅机制,确保数据一致性
void good_writer() {
struct my_data *new_data = kmalloc(sizeof(struct my_data), GFP_KERNEL);
// 1. 先修改数据(写者完成初始化)
new_data->id = 100;
strncpy(new_data->name, "good_data", sizeof(new_data->name)-1);
// 2. 发布新数据:rcu_assign_pointer插入内存屏障,防止指令重排
rcu_assign_pointer(g_shared_data, new_data);
}
// 读者订阅数据:rcu_dereference防止指令重排
void good_reader() {
struct my_data *data;
rcu_read_lock();
// 订阅数据:确保读到的指针,对应完整的初始化数据
data = rcu_dereference(g_shared_data);
if (data) {
printk("Good reader: id=%d, name=%s\n", data->id, data->name);
}
rcu_read_unlock();
}这里的核心逻辑的是:rcu_assign_pointer(发布)会插入内存屏障(比如smp_wmb),确保"数据修改"的指令一定在"指针更新"之前执行,不会被重排;rcu_dereference(订阅)也会插入内存屏障(弱内存序架构上),确保"指针读取"的指令一定在"数据访问"之前执行,避免读者读到无效数据。
简单说,发布-订阅机制就像一个"信号同步":写者改完数据,发一个"信号"(rcu_assign_pointer),告诉读者"数据改完了,可以读了";读者看到"信号"(rcu_dereference),才去读数据,确保读到的是完整、正确的内容。
再举一个内核实战场景:路由表更新。写者更新路由表项后,用rcu_assign_pointer发布新路由表;读者(数据包转发线程)用rcu_dereference订阅路由表,这样就能确保转发时读到的路由表是完整的,不会出现"路由表指针更新,但路由项还没改完"的情况,避免数据包转发错误。
总结一下发布-订阅机制的作用:它是RCU数据一致性的"守护神",通过rcu_assign_pointer(发布)和rcu_dereference(订阅)的配合,插入内存屏障,防止指令重排,确保写者发布的是完整数据,读者读到的是有效数据------这是RCU机制能安全运行的关键保障,也是内核开发中必须注意的细节(写错会导致隐蔽的bug)。
三、实战视角:RCU 的工作流程与核心 API
3.1 读者操作流程:三步实现无锁访问
前面咱们讲了很多理论和零散的代码片段,这一节咱们进入实战视角------先把读者的操作流程讲透,它的操作非常简单,全程三步,零开销、无锁竞争,咱们结合完整的可复用代码,一步步实操。
第一步,调用rcu_read_lock(),标记读临界区开始。很多同学会误以为这是"拿锁",其实不是------它的核心作用是禁用内核抢占,确保读者线程在临界区内不会被其他高优先级线程抢占、不会发生上下文切换。
为什么要禁用抢占?因为写者需要判断"所有旧读者都退出了临界区",如果读者在临界区内被抢占,写者就无法准确判断宽限期是否结束,可能会提前释放旧数据,导致读者访问悬空指针。咱们看代码中的细节:
rcu_read_lock(); // 禁用内核抢占,标记读临界区开始
// 注意:rcu_read_lock不是锁,没有锁竞争,执行速度极快
// 底层实现类似:preempt_disable(),仅禁用抢占,不做互斥检查举个例子:如果读者正在读共享数据,突然被一个高优先级线程抢占,读者的执行被暂停,此时写者检测到这个CPU还处于"非宁静状态",就会继续等待;直到读者被重新调度、执行完rcu_read_unlock,CPU进入宁静状态,宽限期才会结束------这就是禁用抢占的核心目的。
第二步,用rcu_dereference()安全访问共享数据指针。这一步是读者操作的关键,也是容易出错的地方------直接访问共享指针可能会因为指令重排,读到半初始化的数据,而rcu_dereference就是为了解决这个问题。
咱们结合完整的读取代码,看看它的用法和注意事项:
// 第二步:安全读取共享指针,避免指令重排
struct my_data *data = rcu_dereference(g_shared_data);
// 关键注意点:必须判断指针非空,避免空指针异常
if (data != NULL) {
// 访问数据:这里可以读取data的所有成员
printk("Reader: id=%d, name=%s\n", data->id, data->name);
// 注意:读者只能读,不能修改数据(RCU保护的是读多写少,读者只读)
} else {
printk("Reader: shared data is NULL, no data to read\n");
}rcu_dereference的底层会根据CPU架构,插入对应的内存屏障(比如alpha架构的smp_read_barrier_depends),防止编译器或CPU重排"指针读取"和"数据访问"的指令。不管是强内存序架构(x86)还是弱内存序架构(alpha),用rcu_dereference都能保证读取的安全性,这也是代码可移植性的关键。
第三步,调用rcu_read_unlock(),退出读临界区。这一步的作用和第一步对应------重新启用内核抢占,告诉内核"读者已经完成访问,这个CPU可以进行线程调度、上下文切换了"。
rcu_read_unlock(); // 启用内核抢占,标记读临界区结束
// 底层实现类似:preempt_enable(),恢复抢占机制这里有一个重要细节:rcu_read_lock和rcu_read_unlock必须成对使用,就像括号一样------如果漏写rcu_read_unlock,会导致内核抢占一直被禁用,系统可能会出现调度异常、死锁等严重问题;如果漏写rcu_read_lock,读者可能会被抢占,导致写者宽限期判断错误,提前释放旧数据。
总结一下读者的三步流程:禁用抢占→安全读指针→启用抢占,全程零锁竞争、零原子操作,效率极高,这也是RCU在读多写少场景里的核心优势。
咱们把读者的三步流程整合起来,写一个完整的、可直接用于内核模块的示例代码,大家可以直接参考使用:
#include <linux/init.h>
#include <linux/module.h>
#include <linux/rculist.h>
// 定义RCU保护的共享数据结构
struct my_data {
int id;
char name[32];
struct rcu_head rcu;
};
struct my_data *g_shared_data __read_mostly; // __read_mostly标记,优化读性能
// 完整RCU读者示例函数
void rcu_reader_full_demo(void) {
struct my_data *data;
// 第一步:标记读临界区开始,禁用抢占
rcu_read_lock();
// 第二步:安全读取共享指针,判断非空后访问数据
data = rcu_dereference(g_shared_data);
if (data) {
printk(KERN_INFO "RCU Reader: id=%d, name=%s\n", data->id, data->name);
}
// 第三步:退出读临界区,启用抢占
rcu_read_unlock();
}
MODULE_LICENSE("GPL");
MODULE_DESCRIPTION("RCU Reader Demo");
MODULE_AUTHOR("Kernel Blogger");这段代码可以直接编译成内核模块,加载后调用rcu_reader_full_demo,就能实现RCU无锁读操作。注意__read_mostly这个标记,它会告诉编译器,这个变量主要用于读操作,会优化其内存布局,提升读性能------这是内核开发中的一个小技巧,大家可以记
3.2 写者操作流程:五步完成安全更新
写者线程在 RCU 机制下的操作相对复杂,需要遵循严格的五步流程,以确保数据更新的安全性和一致性。
第一步,拷贝旧数据,生成新副本。写者线程在更新共享数据时,首先会使用 kmalloc() 等函数分配新的内存空间,并将旧数据完整地拷贝到新的副本中。这一步就像是制作一份文件的副本,在副本上进行修改,而不直接影响原始文件。在更新网络设备的配置信息时,写者会先分配一块新的内存,然后将当前的配置信息拷贝到新内存中,为后续的修改操作做准备。
第二步,在新副本上完成修改操作。写者线程在得到旧数据的副本后,就可以在这个副本上自由地进行各种修改操作,而不会干扰到正在访问旧数据的读者线程。这是因为读者线程访问的是原数据,而写者操作的是副本,两者相互独立。例如,在修改文件系统的目录结构时,写者可以在副本上添加、删除或修改目录项,而不会影响其他线程对当前目录结构的读取。
第三步,通过 rcu_assign_pointer() 原子替换指针,发布新数据。当写者完成对新副本的修改后,需要将指向原数据的指针更新为指向新的修改后的副本。rcu_assign_pointer() 函数会使用内存屏障(如 smp_wmb() ),确保在更新指针之前,新数据的所有修改都已经完成并对其他 CPU 可见 。这样可以防止读者线程读到半初始化的新数据。假设在更新路由表时,写者使用 rcu_assign_pointer() 将指向新路由表的指针更新,内存屏障会保证新路由表的所有配置信息都已经正确写入内存后,才让读者线程看到新的指针,从而确保了数据的一致性。
第四步,调用 synchronize_rcu() (同步等待)或 call_rcu() (异步回调)等待宽限期结束。synchronize_rcu() 函数会阻塞写者线程,直到所有在旧数据上的读者线程都离开临界区,即宽限期结束。这就像是写者在等待所有借阅旧版本书籍的读者都归还书籍后,才进行下一步操作。而 call_rcu() 函数则是注册一个回调函数,当宽限期结束时,内核会自动调用这个回调函数来完成后续的回收操作,写者线程在调用 call_rcu() 后可以继续执行其他任务,不会被阻塞 。在更新内核链表时,如果使用 synchronize_rcu() ,写者线程会等待所有遍历链表的读者完成操作后才继续;如果使用 call_rcu() ,写者线程可以立即返回,由内核在合适的时候调用回调函数处理旧链表节点的回收。
第五步,在回调函数中释放旧数据内存。当宽限期结束后,如果使用的是 call_rcu() 方式,内核会调用注册的回调函数。在这个回调函数中,写者线程可以安全地释放旧数据所占用的内存空间,使用 kfree() 等函数回收内存资源。例如,在回收旧的网络设备配置信息内存时,回调函数会调用 kfree() 释放之前分配的内存,避免内存泄漏。
通过这五步流程,写者线程能够在不影响读者线程正常访问的情况下,安全地完成数据的更新操作。这种机制在保证数据一致性的同时,也提高了系统的并发性能,特别适用于读多写少的场景。
3.3 内核核心 API 详解
3.3.1 读侧核心 API:rcu_read_lock/unlock 与 rcu_dereference
rcu_read_lock() 和 rcu_read_unlock() 是 RCU 读侧的关键 API,它们共同标记了读临界区的开始和结束。rcu_read_lock() 的核心作用是禁止内核抢占,它通过调用 preempt_disable() 函数来实现这一功能。在多线程环境下,当一个线程进入 RCU 读临界区时,如果不禁止内核抢占,可能会发生线程被抢占的情况。而在 RCU 机制中,写者需要等待所有读者都退出临界区后才能回收旧数据,如果读者在临界区内被抢占,可能会导致写者无法准确判断宽限期是否结束,从而影响数据的安全回收。例如,在一个多线程的文件系统操作中,当一个线程调用 rcu_read_lock() 后,它就可以放心地访问文件系统的元数据,不用担心被其他线程抢占而导致数据访问的不一致。
rcu_read_unlock() 的作用则是重新启用内核抢占,标志着读临界区的结束。当读者线程完成对共享数据的访问后,调用 rcu_read_unlock() ,内核就可以根据调度策略对线程进行调度,其他线程有机会获取 CPU 资源并执行。在一个多线程的数据库查询系统中,当一个线程完成对数据库索引的读取后,调用 rcu_read_unlock() ,内核就可以调度其他线程进行查询或更新操作。
rcu_dereference() 是读侧另一个重要的 API,用于安全地读取 RCU 保护的指针。在多核系统中,由于内存访问的复杂性和指令重排的可能性,直接读取共享数据指针可能会导致读取到不一致的数据。rcu_dereference() 在读取指针时,会根据不同的 CPU 架构采取相应的措施。在 alpha 等弱内存序架构上,它会插入内存屏障(如 smp_read_barrier_depends() ),防止指令重排,确保读取到的指针是最新且有效的 。它还能防止编译器对指针读取操作进行优化,避免出现潜在的错误。在网络协议栈中读取路由表指针时,使用 rcu_dereference() 可以确保读取到的路由表指针是完整且正确的,从而保证数据包能够正确转发。
3.3.2 写侧核心 API:rcu_assign_pointer 与 call_rcu
rcu_assign_pointer() 是写侧的核心 API 之一,它在写者发布新数据的过程中起着关键作用。当写者完成对新数据副本的修改后,需要将指向原数据的指针更新为指向新数据。rcu_assign_pointer() 函数会使用内存屏障(如 smp_wmb() ),确保在更新指针之前,新数据的所有修改都已经完成并对其他 CPU 可见 。这是因为在多线程环境下,如果没有内存屏障,编译器和 CPU 可能会对指令进行重排,导致读者线程读到半初始化的新数据。
假设在更新网络设备的配置信息时,写者先分配了新的内存并修改了配置信息,然后使用 rcu_assign_pointer() 更新指针。如果没有内存屏障,可能会出现这样的情况:指针先被更新,而新的配置信息还没有完全写入内存,此时读者线程读取到的就是一个不完整的配置信息,这将导致网络设备的配置错误。通过使用 rcu_assign_pointer() ,内存屏障会保证新数据的所有修改都完成后,才更新指针,从而确保了数据的一致性。
call_rcu() 是写侧用于注册异步回收回调函数的 API。在 RCU 机制中,写者在完成数据更新并切换指针后,不能立即释放旧数据的内存,需要等待宽限期结束,确保所有可能访问旧数据的读者都已经完成访问。call_rcu() 函数允许写者注册一个回调函数,当宽限期结束时,内核会自动调用这个回调函数来释放旧数据。这种方式与 synchronize_rcu() 不同,synchronize_rcu() 会阻塞写者线程,直到宽限期结束,而 call_rcu() 不会阻塞写者线程,写者可以继续执行其他任务,提高了系统的并发性能 。
在 Linux 内核的链表操作中,当删除一个链表节点时,写者可以使用 call_rcu() 注册一个回调函数,在回调函数中释放节点的内存。这样,写者在删除节点后可以立即返回,而不需要等待所有读者都完成对链表的遍历,从而提高了链表操作的效率。call_rcu() 是 Linux 内核中更常用的回收旧数据的方式,尤其适用于那些不希望被阻塞的场景。
3.3.3 链表操作专属 API:list_add_rcu 与 list_del_rcu
Linux 内核为 RCU 机制专门设计了一套链表操作 API,其中 list_add_rcu() 和 list_del_rcu() 是两个常用的函数,用于安全地添加和删除 RCU 保护的链表节点。
list_add_rcu() 用于将新节点添加到 RCU 保护的链表中。在添加节点时,它首先会检查新节点插入的有效性,如果插入不合法(如节点重复或冲突),则函数将返回,避免不正确的操作。然后,它会设置新节点的 next 和 prev 指针,使其正确地链接到链表中的相邻节点。关键的一步是使用 rcu_assign_pointer() 来安全地更新链表中前一个节点的 next 指针,确保在并发环境下指针更新不会出现问题 。这样可以保证在其他 CPU 上的读者线程能够正确地遍历链表,不会因为新节点的添加而导致链表遍历错误。在网络协议栈中添加一个新的协议处理节点时,就可以使用 list_add_rcu() 来确保新节点能够安全地加入到链表中,同时不影响其他线程对协议链表的读取操作。
list_del_rcu() 用于从 RCU 保护的链表中删除节点。它会先调用 __list_del_entry() 函数将节点从链表中移除,但并不会立即释放节点的内存。这是因为可能还有读者线程正在遍历链表,访问到这个即将被删除的节点。在调用 list_del_rcu() 后,节点的状态处于 "已删除" 但未释放的状态,需要配合 call_rcu() 或 synchronize_rcu() 来完成后续的内存释放操作 。在 Linux 内核的设备驱动中,当删除一个设备节点时,使用 list_del_rcu() 将节点从设备链表中移除,然后通过 call_rcu() 注册一个回调函数,在宽限期结束后释放节点的内存,这样可以保证在设备链表遍历过程中不会出现悬空指针等错误。
四、内核中的 RCU:典型应用场景与调优技巧
4.1 典型应用:RCU 在 Linux 内核中的 "主战场"
在文件系统中,目录项缓存(dcache)是一个典型的应用场景。dcache 用于缓存文件系统的目录结构,当用户执行 ls 命令查看目录内容时,内核会首先在 dcache 中查找相关信息。由于文件系统的读操作(如目录查找)非常频繁,而写操作(如创建或删除目录项)相对较少,RCU 机制在这里就派上了大用场。在多线程环境下,多个线程可能同时执行 ls 命令,使用 RCU 机制可以让这些读操作无锁并发执行,大大提高了目录查找的效率 。而当需要创建或删除目录项时,写者线程会先复制相关的目录项结构,在副本上进行修改,然后通过 rcu_assign_pointer() 原子替换指针,完成更新操作,整个过程不会影响读者线程的正常访问。
在网络协议栈中,路由表管理是 RCU 机制的另一个重要应用场景。路由表存储了网络数据包转发的路径信息,当网络设备接收到数据包时,需要根据路由表中的信息进行转发。由于网络流量的特点,路由表的读操作(数据包转发时的路由查找)远远多于写操作(路由表的更新)。在高并发的网络环境下,大量的数据包需要快速转发,如果采用传统的锁机制,读操作会因为锁竞争而受到严重影响,导致网络延迟增加,吞吐量下降。而 RCU 机制允许读操作无锁并发执行,使得数据包能够快速地在路由表中查找转发路径,提高了网络数据转发的效率 。当路由表需要更新时,写者线程会先创建新的路由表项副本,在副本上进行修改,然后通过 rcu_assign_pointer() 更新指针,将新的路由表项发布出去,确保读者线程能够及时获取到最新的路由信息。
进程管理中的任务链表维护也是 RCU 机制的常见应用场景。任务链表记录了系统中所有进程的相关信息,包括进程状态、优先级等。在系统运行过程中,内核需要频繁地读取任务链表中的信息,例如调度器在选择下一个运行的进程时,需要遍历任务链表来获取各个进程的优先级和状态。而写操作,如创建或销毁进程,相对来说发生的频率较低。在多处理器系统中,多个 CPU 核心可能同时需要读取任务链表,如果使用传统的锁机制,会导致严重的锁竞争,降低系统的并发性能。采用 RCU 机制后,读者线程可以无锁并发访问任务链表,提高了进程信息读取的效率 。当有新进程创建或旧进程销毁时,写者线程会按照 RCU 的流程,先复制相关的链表节点,在副本上进行修改,然后更新指针,最后等待宽限期结束后回收旧节点的内存。
这些应用场景大多具有 "读多写少" 的特点,非常适合 RCU 机制发挥作用。
4.2 实用调优:启动参数让 RCU 性能再升级
4.2.1 rcupdate.rcu_expedited=1:加速宽限期
在某些对实时性要求极高的系统场景中,如工业控制系统、金融交易系统等,传统的 RCU 宽限期检测方式可能无法满足需求,因为它依赖 CPU 自然进入宁静状态,这个过程可能会产生较大的延迟。而 rcupdate.rcu_expedited=1 这个启动参数就像是给 RCU 机制注入了一剂 "强心针",它开启了 RCU 的加速模式。
当设置了这个参数后,内核会强制加速宽限期的检测过程。在传统模式下,宽限期的结束依赖于所有 CPU 自然地经历上下文切换等宁静状态,这个过程可能需要一定的时间,特别是在 CPU 负载较高、上下文切换不频繁的情况下,宽限期可能会持续较长时间,导致写者线程长时间等待旧数据的回收,影响系统的响应速度。而在加速模式下,内核会主动采取措施,通过向所有 CPU 发送处理器间中断(IPI),强制唤醒所有 CPU,让它们立即报告宁静状态 。这样可以将宽限期从常规的毫秒级大幅缩短至百微秒级,典型值可达到 200μs 左右,极大地减少了写者的等待延迟,使得系统能够更快地完成数据更新和内存回收操作,满足了对低延迟和高响应性的严格要求。
不过,天下没有免费的午餐。这种加速模式虽然能够显著提高系统的响应速度,但也会带来一定的代价,那就是增加 CPU 的负载。因为频繁地发送 IPI 中断并处理相关操作,会占用 CPU 的大量时间和资源。在一个工业控制系统中,如果频繁地触发 RCU 加速模式,可能会导致 CPU 忙于处理这些中断,而无法及时响应其他关键的控制任务,从而影响整个系统的稳定性和可靠性。因此,在使用 rcupdate.rcu_expedited=1 参数时,需要谨慎权衡系统对延迟的要求和 CPU 资源的实际情况,确保在满足性能需求的同时,不会对系统的整体运行造成负面影响。
4.2.2 rcu_nocbs=all:优化多核负载均衡
在大规模多核系统中,随着 CPU 核心数量的不断增加,RCU 回调任务的处理成为了一个挑战。传统情况下,内核会在每个 CPU 核心上进行 RCU 更新回调,当多个核心都需要执行大量的 RCU 任务时,会导致 CPU 核心之间的负担不均衡,出现某些核心负载过高,而其他核心相对空闲的情况。这不仅会影响系统的整体性能,还可能导致内存访问的竞争加剧,进一步降低系统的并发性能。
rcu_nocbs=all 这个启动参数的作用就是解决这个问题,它就像是一个智能的任务分配器,告诉内核将 RCU 的更新工作(回调)从每个 CPU 核心的常规执行队列中分离出来。启用此选项后,内核会避免在所有 CPU 上执行这些回调,而是将这些任务转移到特定的 CPU 上,通常是一个核心。这样做的好处是显而易见的,它可以有效地减少每个 CPU 上的负载,特别是当系统中有大量的 RCU 回调任务时,能够避免 CPU 核心之间的竞争,使得每个核心都能够更专注于其他重要的任务,提高了系统的整体并发性能 。
在一个拥有 32 个 CPU 核心的服务器系统中,如果没有启用 rcu_nocbs=all 参数,当大量的 RCU 回调任务同时到来时,可能会导致每个核心都忙于处理这些回调,使得系统的整体性能大幅下降。而启用该参数后,将 RCU 回调任务集中到一个特定的核心上执行,其他 31 个核心就可以释放出来,用于处理其他关键的业务逻辑,如数据库查询、网络数据处理等,从而显著提升了系统的整体性能。
需要注意的是,如果过度分离回调任务,也可能会带来一些问题。例如,当特定的 CPU 被大量的 RCU 回调任务占用时,可能会导致该 CPU 无法及时处理其他重要的任务,从而形成性能瓶颈,增加系统的延迟。因此,在使用 rcu_nocbs=all 参数时,需要根据系统的实际负载情况和硬件配置,合理地选择承担 RCU 回调任务的 CPU,避免出现 CPU 负载过载的情况,以确保系统能够稳定高效地运行。
五、RCU vs 传统锁:何时选它才是最优解?
在 Linux 内核的并发控制领域,RCU 机制和传统的锁机制各有其独特的优势和适用场景。了解它们之间的差异以及在不同场景下的表现,对于开发者选择合适的同步机制至关重要。接下来,我们将深入探讨 RCU 和传统锁的适用场景,并通过对比它们的核心区别,帮助大家更好地理解何时选择 RCU 才是最优解。
5.1 适用场景:读多写少是核心前提
RCU 机制的设计初衷是为了解决读多写少场景下的并发访问问题,因此,其最优应用场景是读操作占比极高(如 90% 以上)的情况。在这种场景下,RCU 读者零开销的优势能够得到最大化体现,而写者的额外开销(如数据拷贝、等待宽限期等)由于发生频率较低,可以忽略不计。
在 Linux 内核的文件系统中,目录项缓存(dcache)的管理是一个典型的读多写少场景。当用户频繁执行 ls 命令查看目录内容时,内核需要不断地读取 dcache 中的目录项信息。由于这种读操作非常频繁,而写操作(如创建或删除目录项)相对较少,使用 RCU 机制可以让多个读操作无锁并发执行,大大提高了目录查找的效率 。在一个拥有大量文件的文件系统中,可能每秒会有数千次的读操作,而写操作可能只有几十次甚至更少。此时,采用 RCU 机制可以显著提升系统的性能,减少读操作的延迟。
在网络协议栈中,路由表的读取和更新也是一个适合 RCU 机制的场景。当网络设备接收到数据包时,需要根据路由表中的信息进行转发,这是一个频繁的读操作。而路由表的更新(写操作)通常是由于网络拓扑的变化或者配置的更改,相对来说发生的频率较低。在高并发的网络环境下,大量的数据包需要快速转发,如果采用传统的锁机制,读操作会因为锁竞争而受到严重影响,导致网络延迟增加,吞吐量下降。而 RCU 机制允许读操作无锁并发执行,使得数据包能够快速地在路由表中查找转发路径,提高了网络数据转发的效率 。
5.2 不适用场景:写频繁时请绕道
虽然 RCU 机制在读多写少的场景中表现出色,但当写操作频繁时,它的优势就会消失殆尽,甚至可能比传统的读写锁效率更低。这是因为写者在 RCU 机制下需要进行数据拷贝、等待宽限期等操作,这些额外的开销在写操作频繁时会急剧增加,导致系统性能大幅下降。
当写操作频繁时,写者需要频繁地分配新的内存空间来拷贝数据,这会增加内存分配的开销。频繁的写操作会导致宽限期频繁出现,写者需要花费大量的时间等待宽限期结束,才能回收旧数据的内存空间。在一个频繁更新配置信息的系统中,如果使用 RCU 机制,写者可能会因为等待宽限期而被阻塞,无法及时响应新的写请求,从而影响系统的整体性能。
读临界区需要阻塞的场景也不适合 RCU 机制。在 RCU 机制中,读者线程在访问共享数据时禁止抢占,这是为了确保宽限期的准确判断。然而,在某些场景下,读临界区可能需要阻塞等待其他资源或者事件,例如等待磁盘 I/O 完成、等待信号量等。由于 RCU 读临界区禁止抢占,无法满足这种阻塞需求,因此在这种场景下不适合使用 RCU 机制 。如果一个读操作需要等待磁盘上的文件数据读取完成,而在 RCU 读临界区内无法进行阻塞等待,就会导致读操作无法正常完成。
5.3 与读写锁的核心区别
为了更直观地对比 RCU 机制和传统读写锁的差异,我们通过下面这张表格来总结它们在读者开销、读写并行性和适用场景等方面的核心区别:
|--------|------------------------------------|------------------|
| 特性 | RCU | 读写锁 |
| 读者开销 | 零开销,无需加锁和原子操作,多数架构下无需内存屏障 | 有锁竞争开销,读操作需要获取读锁 |
| 读写并行性 | 支持读写并行,读者线程可以在写者更新数据时继续访问旧数据 | 写锁排他,写操作时无法进行读操作 |
| 适用场景 | 读多写少,读操作占比极高的场景,如文件系统目录遍历、网络路由表读取等 | 读写均衡或 |