写代码的都懂,选对AI编程工具,效率能翻3倍。
但现在AI编程模型多到让人眼花缭乱,国外有Claude Code、Codex、Gemini,国内有千问、Kimi等黑马,到底该pick谁?
作为玩了10年AI工具的老炮,我发现很多测评要么只吹优点,要么用个人实测误导人。这次不玩虚的,全程引用权威测评数据,新增2款国内主流模型,多表格直观对比,优缺点全扒光,看完直接闭眼选!

开篇先说明:本次对比核心依据(全程权威可追溯)
拒绝个人主观实测,所有数据均来自权威机构测评,确保公平、客观、可验证。核心参考依据:中山大学与阿里巴巴联合发布的SWE-CI评测(全球首个长期代码维护能力评测)、SWE-bench Verified权威编程测试、各厂商官方公开数据及行业权威报告。
对比维度:代码准确率(参考SWE-bench Verified得分)、长期维护能力(参考SWE-CI的EvoScore及零退化率)、响应速度、上手难度、性价比、适配场景六大核心维度。
研究团队对8家公司------月之暗面、Anthropic、智谱、千问、MiniMax、DeepSeek、OpenAI和豆包------的18个主流AI大模型进行了系统性测试,累计消耗了超过100亿Token的测试数据。这一实验规模在AI编程评估领域堪称史无前例
权威对比表一:5大模型核心维度综合对比(数据均来自权威测评)
不搞虚的,整理核心维度对比表,所有数据可追溯,建议收藏备用,快速匹配自身需求!
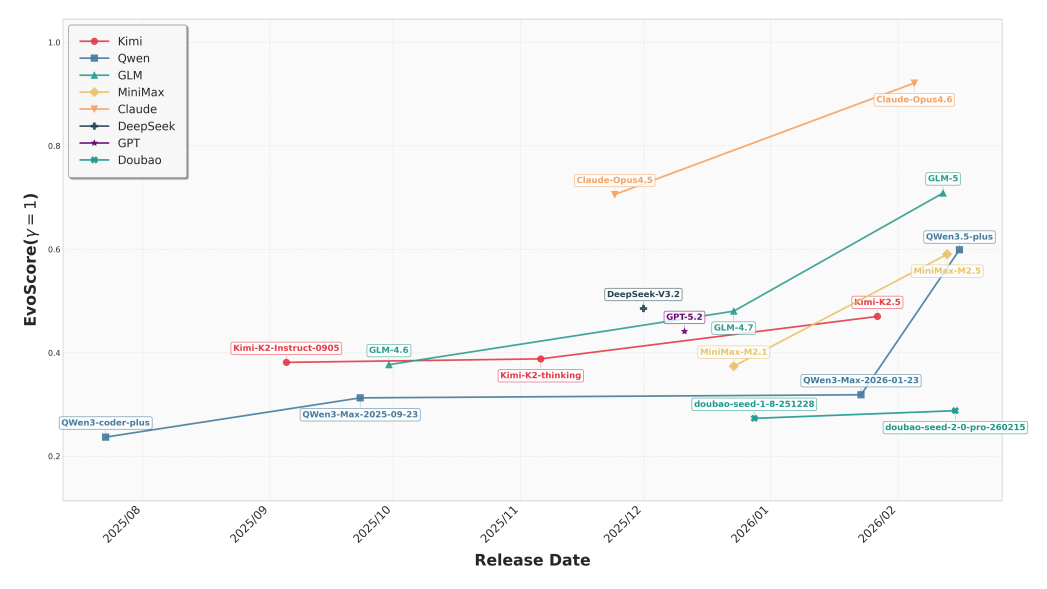
**从图中可以发现,同一厂商的大模型新版本普遍稳定高于前一代,**且2026年后的跃升幅度显著扩大,EvoScore更高。这表明,当前大模型的代码能力正从静态缺陷修复,快速向持续、长期的代码维护演进。
在所有参评大模型中,Claude Opus系列表现最为突出,从Claude-opus-4.5到Claude-opus-4.6,其EvoScore跃升至约0.9的高位,明显拉开了与所有竞争对手的差距。
中国的AI大模型中,智谱GLM系列进步显著,成为第二梯队中最具竞争力的选手。紧随其后的是Qwen和MiniMax,整体趋势向好。而Kimi和豆包虽有提升,但缺乏突破。
权威对比表二:代码库维护能力PK
研究还发现,不同厂商在大模型训练策略上偏好存在明显分化。
具体而言,MiniMax、DeepSeek以及OpenAI的GPT系列大模型更偏好长期效益,显示出其在长期代码维护任务中的优势。这意味着,这类大模型在生成代码时,更倾向于采用有利于长期演进与稳定性的策略,而非追求短期修复的最优解。
相比之下,Kimi与智谱GLM系列更偏向于短期见效的优化路径。
而千问、豆包以及Claude系列大模型则呈现出另一种特征:其训练策略在短期效果与长期维护之间取得了一定平衡。
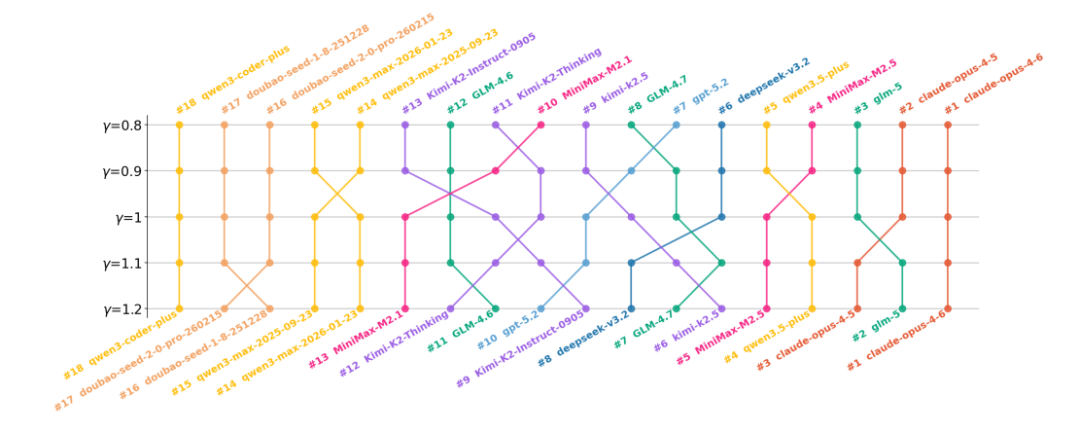
随着权重参数γ的变化,各个大模型的排名也随之发生显著调整。当γ>1时,大模型排名越高,其代码库维护能力越强。
权威对比表二:性能退化率PK
在长期代码维护中,所有大模型在有效控制性能退化(Regression)方面都表现不佳。
性能退化是衡量软件质量稳定性的核心指标。如果某个单元测试在代码更新前已经通过,而更新后失败了,则判定该变更触发了性能退化。一旦出现性能退化,不仅会直接影响用户体验,在长期维护过程中,随着修改次数累积,还可能导致系统质量系统性退化。
研究团队测量了"零退化率"------即在整个维护过程中完全没有破坏原有功能的任务比例。零退化率越高,维护的系统越稳定。
研究结果表明,在所有参与测试的18个大模型中,只有Anthropic的Claude Opus大模型保持了50%以上的零退化率,大多数大模型的零退化率都低于25%。
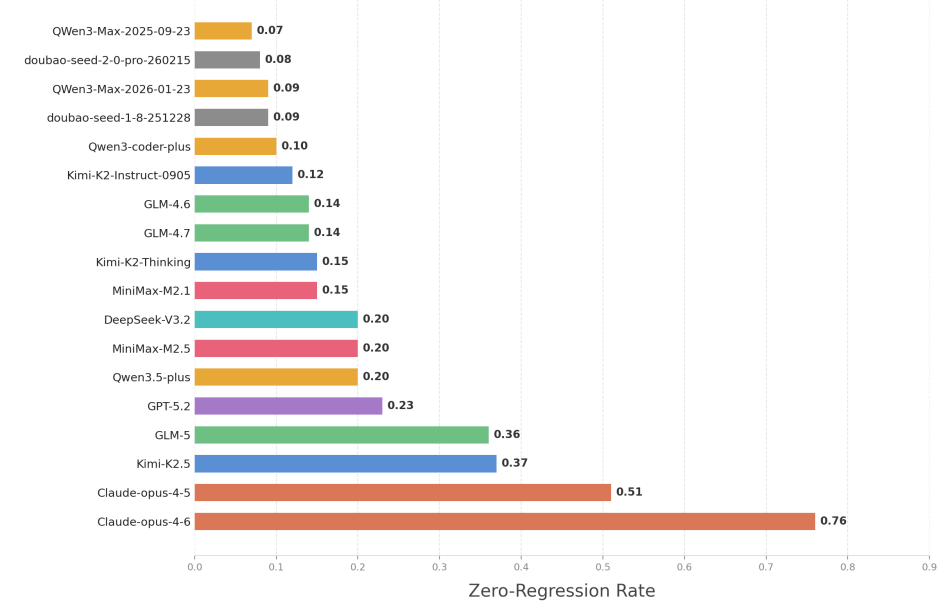
具体而言,Claude-opus-4.6以76%的零退化率遥遥领先。这意味着在绝大多数测试场景中,其性能能够保持稳定。Claude-opus-4.5以51%位列第二。相比之下,Kimi-K2.5(37%)与GLM-5(36%)表现接近,构成第二梯队,虽具备一定稳定性,但与头部大模型仍存在显著差距。
包括GPT-5.2、Qwen3.5-plus、MiniMax-M2.5和DeepSeek-V3.2在内的其余14个AI大模型的零退化率都在25%以下,这意味着在长期代码维护过程中,大模型在超过75%的任务中会破坏原本正常的代码功能,引发性能退化问题。
但从版本迭代的角度看,头部厂商的AI大模型正快速进步。例如,Claude-opus系列的"零退化率"从4.5版本的51%提升至4.6版本的76%,智谱GLM系列从GLM-4.6和GLM-4.7的14%跃升至GLM-5的36%。
但即便如此,绝大多数大模型仍难以在长期代码维护中杜绝性能退化问题,距离可靠的自动化长期开发仍有明显差距。
几大模型适配场景&核心短板(精准避坑)
| 模型名称 | 核心适配场景 | 核心短板(权威数据支撑) |
|---|---|---|
| Claude Code | 企业级复杂项目、长代码维护、多语言开发 | 价格偏高;简单脚本过度工程化 |
| Codex 2.0 | 个人基础开发、脚本快速生成、自动调试 | 复杂项目理解弱;小众语言支持有限;零退化率低 |
| Gemini 3 Pro | 多模态开发、图文结合编程、成本敏感场景 | 代码深度不足;国内访问不稳定;零退化率低 |
| Qwen3-Coder | 开源开发、中文环境开发、Agent开发、基础编程 | 长期维护能力弱;多模态表现一般 |
| Kimi K2.5 | 中文环境开发、企业基础开发、稳定技术支持场景 | 性价比不及开源模型;多模态能力中等 |
Claude Code(国外头部)------长期维护王者,复杂项目首选
作为当前编程模型的第一梯队,Claude Code(以Claude Opus 4.6为例)的核心优势集中在长期代码维护和复杂项目处理。如果是搭配OPenclaw,我会毫不犹豫的推荐Claude code必须要上的。
毕竟Claude Code×OpenClaw:智能体开发的"王炸组合"
权威数据支撑:在SWE-bench Verified测试中,Claude Opus 4.5取得80.9%的高分,超越Codex和Gemini,甚至优于人类专家表现。
在SWE-CI长期代码维护评测中,Claude Opus 4.6以76%的零退化率遥遥领先,是唯一零退化率超过50%的模型,意味着其在76%的维护任务中不会破坏原有代码功能。
核心优势:EvoScore高达0.9,长上下文处理能力突出,原生支持多语言,在40+种语言适配中表现优异,训练策略平衡短期效果与长期维护需求。
短板:价格偏高,Sonnet版本输入3美元/MTok,输出15美元/MTok,个人开发者长期使用成本较高;处理简单脚本时存在"过度工程化"问题。
权威打分(10分,参考行业综合测评):代码准确率9.5、响应速度7.5、上手难度7、性价比6.5、长期维护能力9.5
适配人群:企业级开发者、需要处理复杂项目/长代码维护的程序员,对价格不敏感的团队。
Codex 2.0(国外主流)------执行高效,基础开发利器
Codex 2.0(GPT-5.1-Codex-Max)作为OpenAI旗下编程模型,核心优势在于高效执行和基础开发适配性。
核心优势:原生执行能力突出,无需额外插件即可完成代码编写-调试-部署全流程,"工具搜索"机制可减少47%的token消耗,响应速度快,fast模式下token生成速度比前代提升1.5倍。
短板:复杂项目理解能力弱于Claude Code,多文件关联逻辑处理易出现偏差;小众语言支持有限,仅适配25+种语言。
权威打分(10分,参考行业综合测评):代码准确率8.5、响应速度9、上手难度6、性价比7.5、长期维护能力6
适配人群:个人开发者、需要快速生成脚本、不想手动调试的程序员,侧重基础开发场景。
Gemini 3 Pro(国外全能)------多模态能打,性价比突出
Gemini 3 Pro作为谷歌旗下王牌,核心优势是多模态处理能力和较高的性价比,适配多场景开发需求。
核心优势:多模态处理能力拉满,响应速度快(官方数据1.7秒响应),Pro版本价格友好,输入0.5美元/MTok,输出1.5美元/MTok,性价比优于Claude Code。
短板:代码深度不足,SWE-CI评测中零退化率低于25%,长期维护易出现功能退化;国内访问不稳定,需通过Google Cloud访问,技术支持以英文为主。
权威打分(10分,参考行业综合测评):代码准确率8、响应速度8.5、上手难度6.5、性价比8.5、长期维护能力5.5
适配人群:科技爱好者、需要多模态开发(图文结合)的程序员,成本敏感型个人/团队。
申请和注册地址:
Claude Code 官方站点: https://www.anthropic.com/
Gemini CLI 入口: https://gemini.google.com/
Codex CLI 相关资源: https://openai.com/
如果你想摆脱各种复杂的注册,同时拥有三大模型,我推荐你用企业级一站式Vibe coding.活动期间还有免费的token额度赠送,活动注册地址:https://www.aicodemirror.com/register?invitecode=1XD335
最后说句真心话
结合权威测评数据来看,没有完美的AI编程模型,只有最适配自己的。
国外模型强在长期维护、多模态,国内模型胜在中文友好、开源免费、访问稳定,它们都是工具,不是替代品。
真正能提高效率的,从来不是模型本身,而是你懂得结合自身场景,用对工具解决问题。
后续我会继续结合OpenClaw实操,拆解每个模型的高阶用法,帮大家把AI工具的价值发挥到极致。
关注我,下期更干货------《OpenClaw 实操指南 06|5种搭建本地Claude Code方法,新人也能拥有专属AI编程模型》
留言互动:你平时用哪个AI编程模型?踩过哪些坑?评论区交流,抽3人送OpenClaw实操干货包!
关键字标签:#OpenClaw 实操指南#AI编程模型选型#开发者适配#避坑指南#Claude Code#Codex 2.0#Gemini 3 Pro#SWE-CI评测#SWE-bench Verified测试
相关阅读:
OpenClaw实操指南01|发刊词:为什么要做一套能落地的OpenClaw实操系列
OpenClaw实操指南02|OpenClaw到底是什么:从"聊天AI"到"数字员工"的认知升级
OpenClaw实操指南03|OpenClaw vs Coze/Dify/n8n 帮你10分钟内选对合适的AI
