一、前言:
Docker容器技术凭借其轻量级、可移植性和隔离性,已成为现代应用开发与部署的主流选择。然而,容器环境的安全漏洞与性能瓶颈也日益凸显。本文将深入解析Docker安全加固与性能优化的核心策略,结合具体代码示例和生产级实践经验,帮助开发者构建安全高效的容器化应用生态。
Docker容器的安全性,很大程度上依赖于Linux系统自身
评估Docker的安全性时,主要考虑以下几个方面:
Linux内核的命名空间机制提供的容器隔离安全
Linux控制组机制对容器资源的控制能力安全。
Linux内核的能力机制所带来的操作权限安全
Docker程序(特别是服务端)本身的抗攻击性。
其他安全增强机制对容器安全性的影响#在rhel9中默认使用cgroup-v2 但是cgroup-v2中不利于观察docker的资源限制情况,所以推荐使用cgroup-v1
bash
[root@docker-node1 ~]# mount -t cgroup
[root@docker-node1 ~]# mount -t cgroup2
cgroup2 on /sys/fs/cgroup type cgroup2 (rw,nosuid,nodev,noexec,relatime,nsdelegate,memory_recursiveprot)
[root@docker-node1 ~]# grubby --update-kernel=/boot/vmlinuz-$(uname -r) \
--args="systemd.unified_cgroup_hierarchy=0 systemd.legacy_systemd_cgroup_controller"
[root@docker-node1 ~]# reboot
[root@docker-node1 ~]# mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/misc type cgroup (rw,nosuid,nodev,noexec,relatime,misc)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)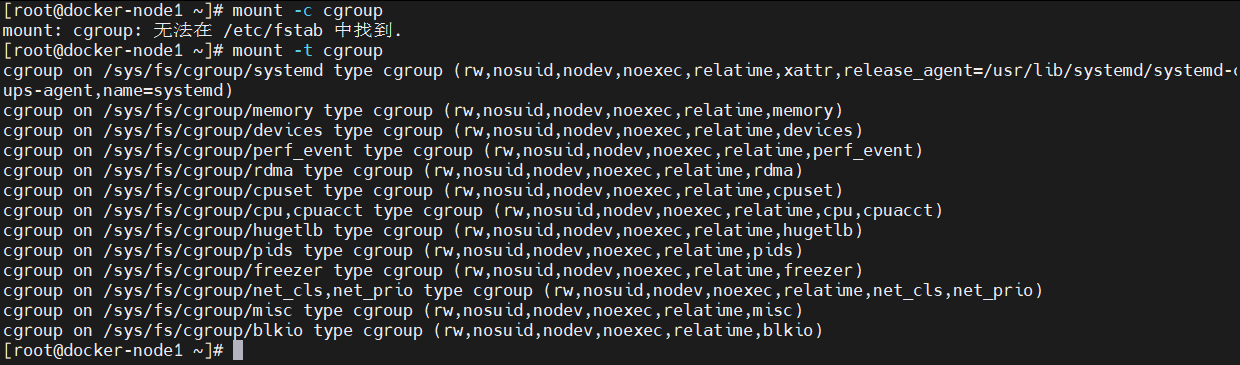
1 命名空间隔离的安全
当docker run启动一个容器时,Docker将在后台为容器创建一个独立的命名空间。命名空间提供了最基础也最直接的隔离。
与虚拟机方式相比,通过Linux namespace来实现的隔离不是那么彻底。
容器只是运行在宿主机上的一种特殊的进程,那么多个容器之间使用的就还是同一个宿主机的操作系统内核。
在 Linux 内核中,有很多资源和对象是不能被 Namespace 化的,比如:磁盘等等
bash
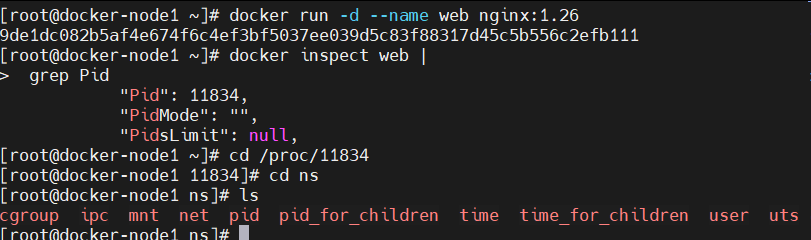
[root@docker ~]# docker run -d --name web nginx
3c6b649a200fc56afafe9f47494903fe56e71cabcd534d6c9e6f8b5854f29cac
[root@docker ~]# docker inspect web | grep Pid
"Pid": 4328,
"PidMode": "",
"PidsLimit": null,
[root@docker ~]# cd /proc/4328/ns/ #进程的namespace
[root@docker ns]# ls
cgroup ipc mnt net pid pid_for_children time time_for_children user uts
bash
[root@docker ns]# ls -d /sys/fs/cgroup/memory/docker/3c6b649a200fs省略部分854f29cac/ #资源隔离信息
/sys/fs/cgroup/system.slice/docker-ecb8abbbfc85bf3d62fc82afb3950ab6b6a2e80092738274a233bbb8db0c5ce2.scope
/sys/fs/cgroup/system.slice/docker.service
/sys/fs/cgroup/system.slice/docker.socket
[root@docker ns]# ls -d /sys/fs/cgroup/memory/docker/3c6b649a200fs省略部分854f29cac/ #资源隔离信息
/sys/fs/cgroup/system.slice/docker-ecb8abbbfc85bf3d62fc82afb3950ab6b6a2e80092738274a233bbb8db0c5ce2.scope
/sys/fs/cgroup/system.slice/docker.service
/sys/fs/cgroup/system.slice/docker.socket

2 控制组资源控制的安全
当docker run启动一个容器时,Docker将在后台为容器创建一个独立的控制组策略集合。
Linux Cgroups提供了很多有用的特性,确保各容器可以公平地分享主机的内存、CPU、磁盘IO等资源。
确保当发生在容器内的资源压力不会影响到本地主机系统和其他容器,它在防止拒绝服务攻击(DDoS)方面必不可少
bash
[root@docker ~]# docker run -it --name test busybox #内存资源默认没有被隔离
/ # free -m
total used free shared buff/cache available
Mem: 3627 648 516 16 2463 2678
Swap: 2063 1 2062
/ # exit
[root@docker ~]# free -m
total used free shared buff/cache available
Mem: 3627 907 557 15 2463 2719
Swap: 2062 1 2061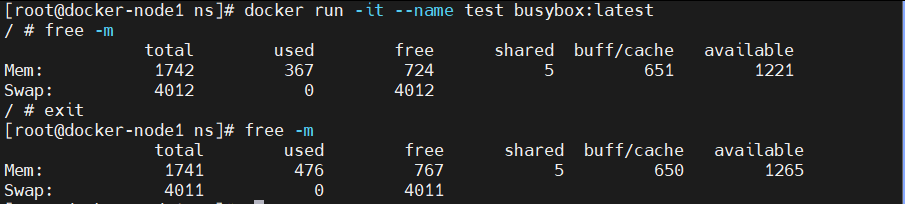
3 内核能力机制
能力机制(Capability)是Linux内核一个强大的特性,可以提供细粒度 的权限访问控制。
大部分情况下,容器并不需要真正的 root权限,容器只需要少数的能力即可。
默认情况下,Docker采白名单机制,禁用"必需功能"之外的其他权限。
4 Docker服务端防护
使用Docker容器的核心是Docker服务端 ,确保只有可信的用户 才能访问到Docker服务。
将容器的root用户映射到本地主机上的非root用户 ,减轻容器和主机之间因权限 提升而引起的安全问题。
允许Docker 服务端在非root权限下运行,利用安全可靠的子进程来代理执行需要特权权限的操作。这些子进程只允许在特定范围内进行操作。
bash
[root@docker ~]# ls -ld /var/lib/docker/ #默认docker是用root用户控制资源的
drwx--x--- 12 root root 171 8月 20 13:21 /var/lib/docker/
二、 Docker的资源限制
Linux Cgroups 的全称是 Linux Control Group。
是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
对进程进行优先级设置、审计,以及将进程挂起和恢复等操作。Linux Cgroups 给用户暴露出来的操作接口是文件系统
它以文件和目录的方式组织在操作系统的 /sys/fs/cgroup 路径下。
执行此命令查看:mount -t cgroup
bash
[root@docker ~]# mount -t cgroup #在rhel9中默认使用cgroup2
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio)
cgroup on /sys/fs/cgroup/misc type cgroup (rw,nosuid,nodev,noexec,relatime,misc)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
在 /sys/fs/cgroup 下面有很多诸如 cpuset、cpu、 memory 这样的子目录,也叫子系统。
在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录)。
控制组下面的资源文件里填上什么值,就靠用户执行 docker run 时的参数指定。2.1限制cpu使用
ubuntu-latest.tar.gz
(1). 限制cpu的使用量
bash
[root@docker ~]# docker run -it --rm --name test \
--cpu-period 100000 \ #设置 CPU 周期的长度,单位为微秒(通常为 100000,即 100 毫秒)
--cpu-quota 20000 ubuntu #设置容器在一个周期内可以使用的 CPU 时间,单位也是微秒。
root@5797d76b20f5:/# dd if=/dev/zero of=/dev/null &
root@5797d76b20f5:/# top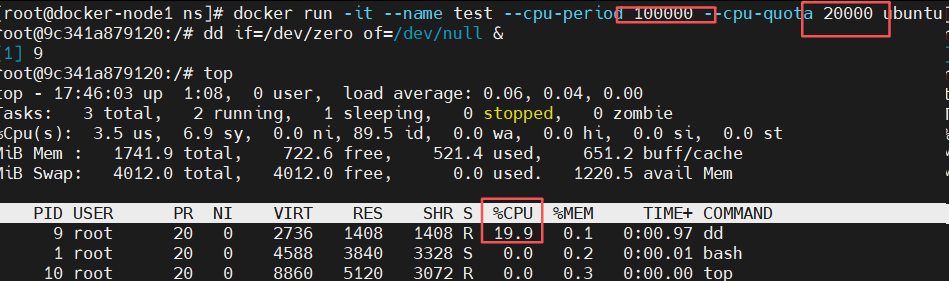
在cgroup中查看docker的资源限制
bash
[root@docker ~]# cat /sys/fs/cgroup/cpu/docker/"docker id(所要查看容器的id)"/cpu.cfs_period_us #cpu总量划分
[root@docker ~]# cat /sys/fs/cgroup/cpu/docker/"docker id(所要查看容器的id)"/cpu.cfs_quota_us #cpu限制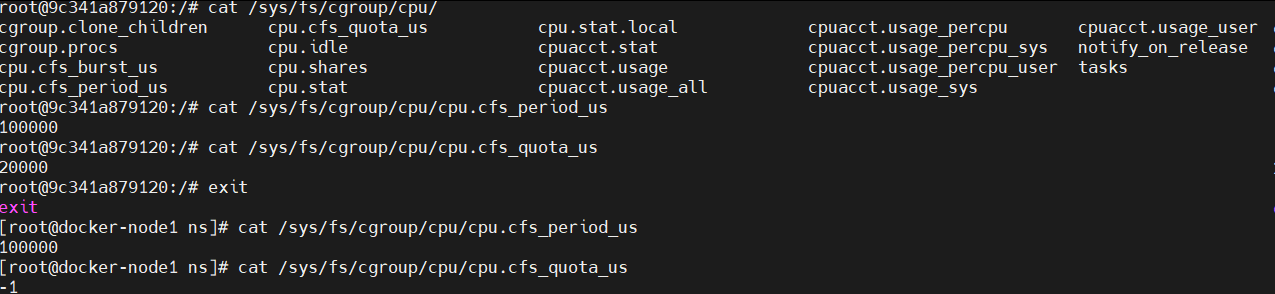
(2). 限制cpu的优先级
bash
#开启容器时如果指定了cpu使用优先级,那么设定文件为
[root@docker ~]# cat /sys/fs/cgroup/cpu/docker/"docker id(所要查看容器的id)"/cpu.shares
#确保在系统中只有一个cpu核心在下
[root@docker-node1 ~]# cd /sys/devices/system/cpu/
[root@docker-node1 cpu]# ls
cpu0 cpufreq crash_hotplug isolated modalias offline possible present uevent
cpu1 cpuidle hotplug kernel_max nohz_full online power smt vulnerabilities
#关闭cpu的核心,当cpu都不空闲下才会出现争抢的情况,为了实验效果我们可以关闭一个cpu核心
root@docker ~]# echo 0 > /sys/devices/system/cpu/cpu1/online
[root@docker ~]# cat /proc/cpuinfo
[root@docker-node1 cpu1]# cat /proc/cpuinfo | grep cores
cpu cores : 1
bash
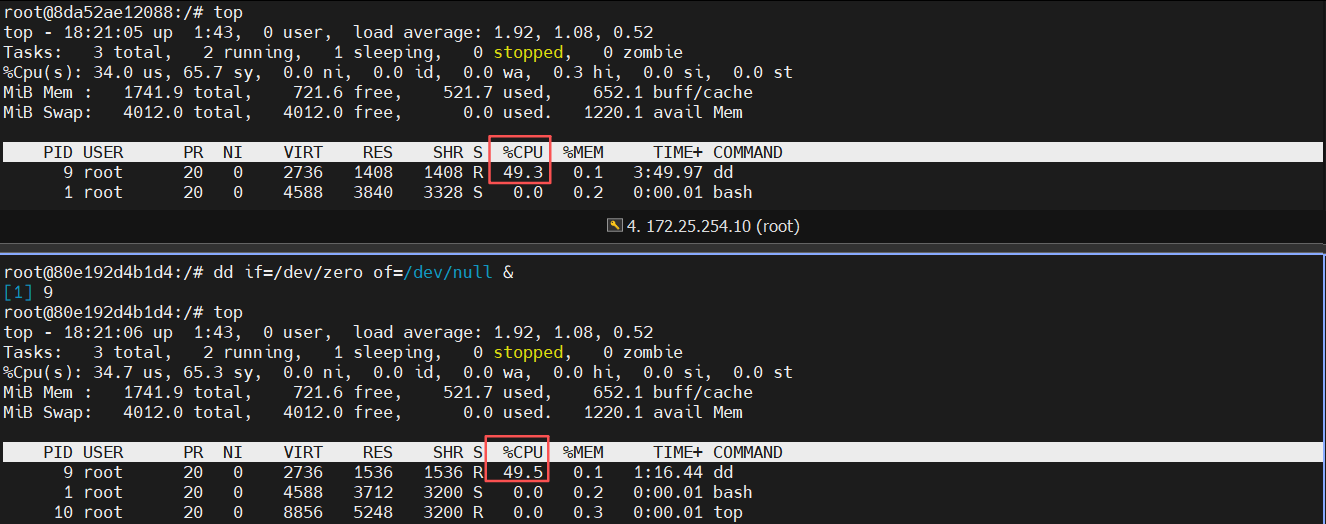
[root@docker-node1 ~]# docker run -it --rm --name test ubuntu
root@69183e546633:/# dd if=/dev/zero of=/dev/null &
root@69183e546633:/# top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9 root 20 0 2736 1408 1408 R 49.5 0.1 0:40.64 dd
1 root 20 0 4588 3712 3200 S 0.0 0.2 0:00.02 bash
10 root 20 0 8848 5248 3200 R 0.0 0.3 0:00.00 top
[root@docker-node1 ~]# docker run -it --rm --name test1 ubuntu
root@871f9f2bf1ba:/# dd if=/dev/zero of=/dev/null &
root@871f9f2bf1ba:/# top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9 root 20 0 2736 1408 1408 R 49.5 0.1 0:40.64 dd
1 root 20 0 4588 3712 3200 S 0.0 0.2 0:00.02 bash
10 root 20 0 8848 5248 3200 R 0.0 0.3 0:00.00 top
bash
#资源限制
[root@docker-node1 ~]# docker run -it --rm --cpu-shares 100 ubuntu #设定cpu优先级,最大为1024,值越大优先级越高
root@0dd481be0925:/# dd if=/dev/zero of=/dev/null &
root@0dd481be0925:/# top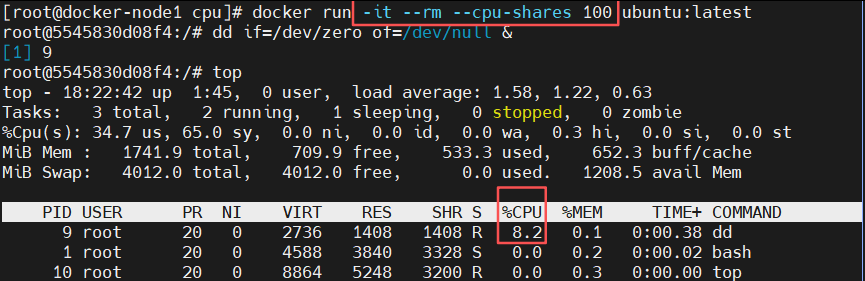
bash
[root@docker-node1 ~]# docker run -it --rm ubuntu:latest
root@f61925d3c218:/#
root@f61925d3c218:/# dd if=/dev/zero of=/dev/null &
root@f61925d3c218:/# top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
8 root 20 0 2736 1408 1408 R 89.7 0.1 0:24.24 dd
1 root 20 0 4588 3968 3456 S 0.0 0.2 0:00.01 bash
9 root 20 0 8848 5120 3072 R 0.0 0.3 0:00.00 top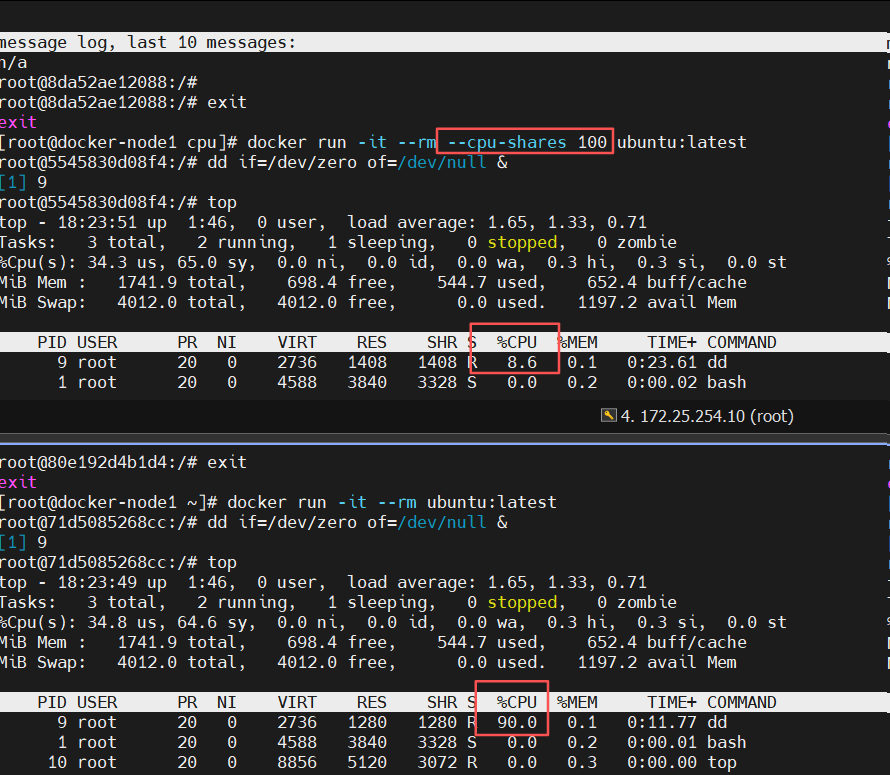
bash
(3). 限制内存使用
bahs
#开启容器并限制容器使用内存大小
[root@docker system.slice]# docker run -d --name test --memory 200M --memory-swap 200M nginx
#查看容器内存使用限制
[root@docker ~]# cd /sys/fs/cgroup/memory/docker/d09100472de41824bf0省略部分id96b977369dad843740a1e8e599f430/
[root@docker d091004723d4de41824f6b38a7be9b77369dad843740a1e8e599f430]# cat memory.limit_in_bytes
209715200
[root@docker d091004723d4de41824f6b38a7be9977369dad843740a1e8e599f430]# cat memory.memsw.limit_in_bytes
209715200
bash
#测试容器内存限制,在容器中我们测试内存限制效果不是很明显,可以利用工具模拟容器在内存中写入数据
#在系统中/dev/shm这个目录被挂在到内存中
```bash
#安装检测工具
[root@docker-node1 ~]# rpm -ivh libcgroup-0.41-19.el8.x86_64.rpm
[root@docker-node1 ~]# rpm -ivh libcgroup-tools-0.41-19.el8.x86_64.rpm
/sys/fs/cgroup/memory/docker/4f212de78b0847d54de5508aeec7930c984dec81d59c1d0d007358d55e62bdff/
[root@docker-node1 ~]# cgexec -g memory:docker/4f212de78b0847d54de5508aeec7930c984dec81d59c1d0d007358d55e62bdff dd if=/dev/zero of=/dev/shm/bigfile bs=1M count=200
已杀死cgexec -g memory:doceker/容器id -g表示使用指定控制器类型(4). 限制docker的磁盘io
bash
[root@docker-node1 ~]# docker run -it --name test --rm ubuntu:latest
root@0530d0384458:/# dd if=/dev/zero of=/bigfile bs=1M count=1000限制前下载速率到:412MB/s
硬盘直达,最快,用的是内存 1.7Gb/s


限制后下载速率到:31.4MB/s

三、 Docker的安全加固
1、Docker默认隔离性
在系统中运行容器,我们会发现资源并没有完全隔离开
bash
[root@docker ~]# free -m #系统内存使用情况
total used free shared buff/cache available
Mem: 3627 1128 1714 207 1238 2498
Swap: 2062 0 2062
[root@docker ~]# docker run --rm --memory 200M -it ubuntu
root@e06bdc13b764:/# free -m #容器中内存使用情况
total used free shared buff/cache available
Mem: 3627 1211 1630 207 1239 2415
Swap: 2062 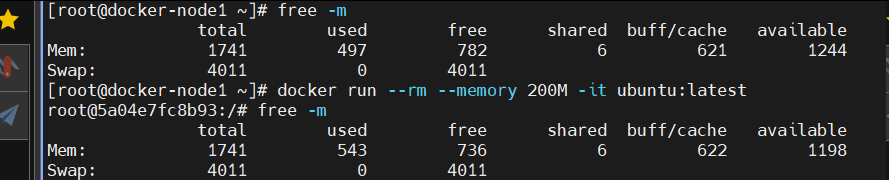
#虽然我们限制了容器的内容使用情况,但是查看到的信息依然是系统中内存的使用信息,并没有隔离开
2、解决Docker的默认隔离性
LXCFS 是一个为 LXC(Linux Containers)容器提供增强文件系统功能的工具。
主要功能
资源可见性:
LXCFS 可以使容器内的进程看到准确的 CPU、内存和磁盘 I/O 等资源使用信息。在没有 LXCFS 时,容器内看到的资源信息可能不准确,这会影响到在容器内运行的应用程序对资源的评估和管理。
性能监控:
方便对容器内的资源使用情况进行监控和性能分析。通过提供准确的资源信息,管理员和开发人员可以更好地了解容器化应用的性能瓶颈,并进行相应的优化。安装lxcfs
#在rhel9中lxcfs是被包含在epel源中,我们可以直接下载安装包进行安装
root@docker \~# ls lxcfs
lxcfs-5.0.4-1.el9.x86_64.rpm lxc-libs-4.0.12-1.el9.x86_64.rpm lxc-templates-4.0.12-1.el9.x86_64.rpm
root@docker \~# dnf install lxcfs/*.rpm
运行lxcfs并解决容器隔离性
root@docker \~# lxcfs /var/lib/lxcfs &
root@docker \~# docker run -it -m 256m
-v /var/lib/lxcfs/proc/cpuinfo:/proc/cpuinfo:rw
-v /var/lib/lxcfs/proc/diskstats:/proc/diskstats:rw
-v /var/lib/lxcfs/proc/meminfo:/proc/meminfo:rw
-v /var/lib/lxcfs/proc/stat:/proc/stat:rw
-v /var/lib/lxcfs/proc/swaps:/proc/swaps:rw
-v /var/lib/lxcfs/proc/uptime:/proc/uptime:rw
ubuntu
root@69ec0c67ff04:/# free -m
total used free shared buff/cache available
Mem: 256 1 254 0 0 254
Swap: 512 0 512
3、容器特权
在容器中默认情况下即使我是容器的超级用户也无法修改某些系统设定,比如网络
bash
[root@docker-node1 ~]# docker run -it --name test --rm busybox:latest
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0@if41: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether d2:c7:6e:f3:83:73 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
/ # ip a a 1.2.3.4/24 eth0@if41
ip: either "local" is duplicate, or "eth0@if41" is garbage
/ # fdisk -l
/ # exit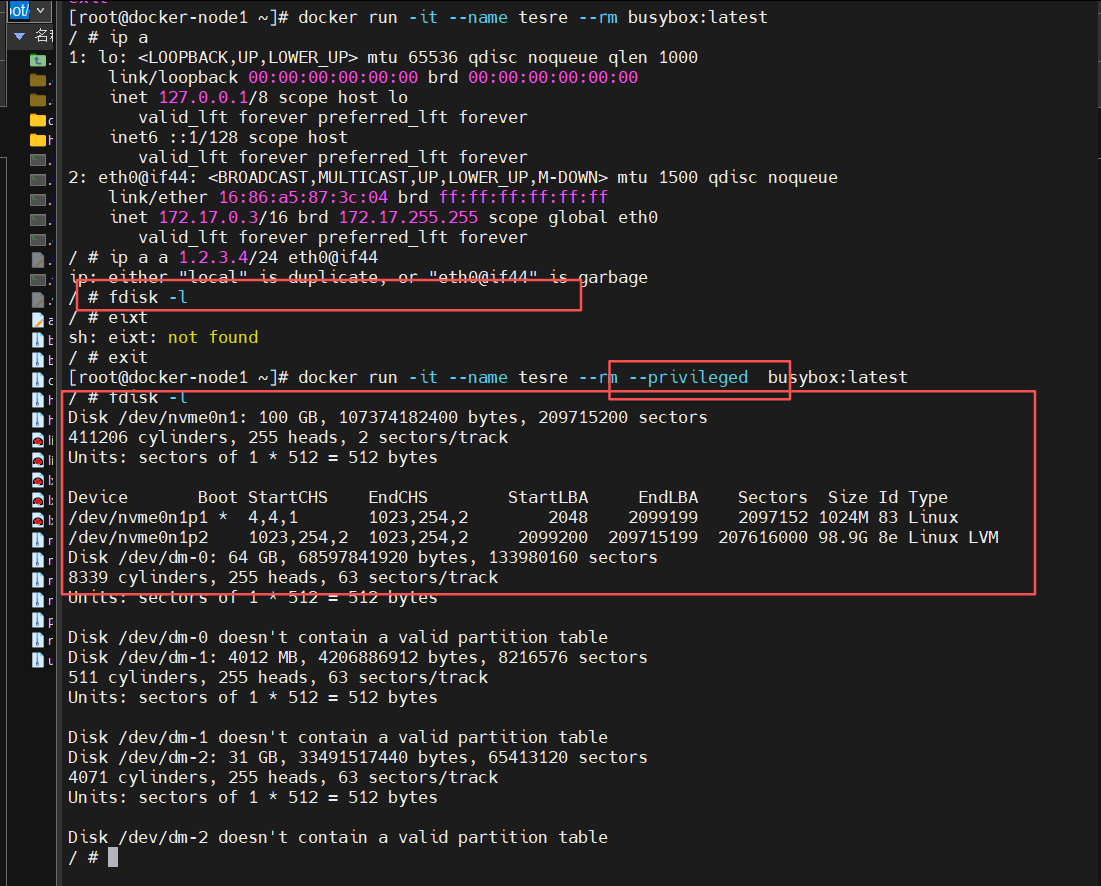
root@docker-node1 \~# docker run -it --rm --privileged busybox:latest
/ # fdisk -l
Disk /dev/nvme0n1: 100 GB, 107374182400 bytes, 209715200 sectors
411206 cylinders, 255 heads, 2 sectors/track
Units: sectors of 1 * 512 = 512 bytes
Device Boot StartCHS EndCHS StartLBA EndLBA Sectors Size Id Type
/dev/nvme0n1p1 * 4,4,1 1023,254,2 2048 2099199 2097152 1024M 83 Linux
/dev/nvme0n1p2 1023,254,2 1023,254,2 2099200 10307583 8208384 4008M 82 Linux swap
/dev/nvme0n1p3 1023,254,2 1023,254,2 10307584 209715199 199407616 95.0G 83 Linux
这是因为容器使用的很多资源都是和系统真实主机公用的,如果允许容器修改这些重要资源,系统的稳定性会变的非常差
但是由于某些需要求,容器需要控制一些默认控制不了的资源,如何解决此问题,这时我们就要设置容器特权
root@docker \~# docker run --rm -it --privileged busybox
/ # id root
uid=0(root) gid=0(root) groups=0(root),10(wheel)
/ # ip a a 192.168.0.100/24 dev eth0
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
29: eth0@if30: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.0.100/24 scope global eth0
valid_lft forever preferred_lft forever
/ # fdisk -l
Disk /dev/nvme0n1: 100 GB, 107374182400 bytes, 209715200 sectors
13003 cylinders, 256 heads, 63 sectors/track
Units: sectors of 1 * 512 = 512 bytes
Device Boot StartCHS EndCHS StartLBA EndLBA Sectors Size Id Type
/dev/nvme0n1p1 0,0,2 1023,255,63 1 209715199 209715199 99.9G ee EFI GPT
#如果添加了--privileged 参数开启容器,容器获得权限近乎于宿主机的root用户
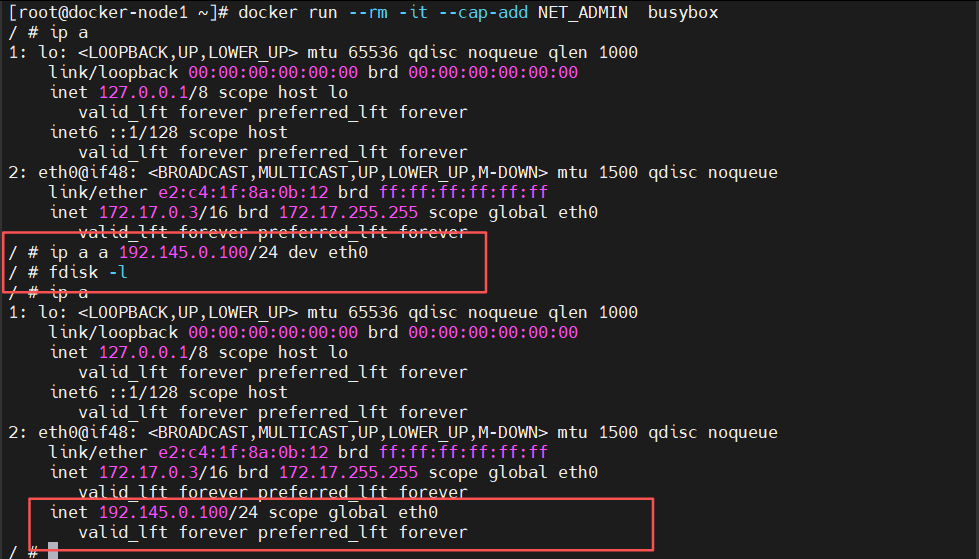
4、容器特权的白名单
--privileged=true 的权限非常大,接近于宿主机的权限,为了防止用户的滥用,需要增加限制,只提供给容器必须的权限。此时Docker 提供了权限白名单的机制,使用--cap-add添加必要的权限
capabilities手册地址:http://man7.org/linux/man-pages/man7/capabilities.7.html
#限制容器对网络有root权限
bash
[root@docker ~]# docker run --rm -it --cap-add NET_ADMIN busybox
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
31: eth0@if32: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
/ # ip a a 192.168.0.100/24 dev eth0 #网络可以设定
/ # fdisk -l #无法管理磁盘
/ #
四、总结:Docker 安全优化(面试重点版)
一、核心安全风险(面试开篇必问:Docker 有哪些安全隐患?)
1. 基础风险点
| 风险类型 | 具体表现 | 核心危害 |
|---|---|---|
| 内核共享风险 | 容器与宿主机共享 Linux 内核,容器漏洞可能突破隔离影响宿主机 | 单容器沦陷 → 整台主机被控制 |
| 权限过高 | 默认用 root 运行容器,容器内 root 等价于宿主机 root | 容器内恶意操作直接危害宿主机 |
| 镜像安全 | 拉取不明来源镜像、镜像包含恶意代码/漏洞 | 引入后门、挖矿程序等 |
| 网络隔离不足 | 容器默认桥接网络,未限制端口/通信范围 | 容器间横向攻击、端口暴露被扫描 |
| 数据卷权限 | 挂载敏感目录(/etc、/root)、数据卷权限过宽 | 篡改宿主机配置、窃取敏感数据 |
| 无资源限制 | 容器无 CPU/内存限制,易引发 DoS 攻击 | 耗尽宿主机资源,业务瘫痪 |
2. 经典漏洞案例(面试加分项)
- Dirty COW(CVE-2016-5195):内核提权漏洞,容器内普通用户可获取宿主机 root 权限;
- Docker API 未授权访问:2375 端口暴露,攻击者直接控制 Docker 引擎,创建特权容器;
- 镜像分层污染:基础镜像含漏洞,所有基于该镜像的容器均受影响。
二、核心安全优化策略(面试高频:如何保障 Docker 安全?)
1. 镜像安全(源头管控,重中之重)
(1)镜像选择与构建
-
优先使用官方镜像/可信仓库镜像,避免未知来源镜像;
-
选择精简镜像(alpine、distroless),减少攻击面(如 alpine 镜像仅几 MB,远小于 ubuntu 镜像);
-
多阶段构建:构建层与运行层分离,剔除编译依赖、源码等敏感文件;
dockerfile# 示例:多阶段构建(构建层用golang,运行层用alpine) FROM golang:1.21 AS builder WORKDIR /app COPY . . RUN go build -o app . FROM alpine:3.19 COPY --from=builder /app/app /app CMD ["/app"] -
镜像扫描:用
docker scan、Trivy、Harbor 镜像扫描功能,检测镜像内漏洞。
(2)镜像签名与验证
-
启用 Docker Content Trust(DCT),验证镜像签名,防止镜像被篡改:
bashexport DOCKER_CONTENT_TRUST=1 # 开启签名验证 docker pull 镜像名:标签 # 仅拉取已签名镜像
2. 容器运行安全(权限最小化)
(1)非 root 用户运行容器(核心!)
-
容器内默认 root 是最大安全隐患,必须创建普通用户:
dockerfile# Dockerfile 配置普通用户 FROM alpine:3.19 RUN adduser -D -H -s /sbin/nologin appuser # 创建无登录权限用户 USER appuser # 切换到普通用户 CMD ["/app"] -
运行时强制指定用户:
bashdocker run -d --user 1000:1000 镜像名 # 用UID/GID而非用户名,避免权限冲突
(2)限制容器特权
-
禁止使用
--privileged(全特权模式,等价于宿主机 root); -
按需添加权限(用
--cap-add),而非全特权:bash# 仅添加网络管理权限,而非--privileged docker run -d --cap-add NET_ADMIN --cap-drop ALL 镜像名 -
禁用容器内 ptrace(防止调试攻击):
bashdocker run -d --security-opt seccomp=unconfined --sysctl kernel.yama.ptrace_scope=1 镜像名
(3)资源限制(防止 DoS)
-
限制 CPU/内存/磁盘 IO,避免容器耗尽宿主机资源:
bashdocker run -d \ --memory 512M --memory-swap 512M \ # 内存限制512M,关闭交换分区 --cpu-quota 50000 --cpu-period 100000 \ # CPU限制50% --device-write-bps /dev/sda:10M \ # 磁盘写速度限制10MB/s 镜像名
(4)只读文件系统(防止篡改)
-
容器内文件系统设为只读,仅数据卷可写:
bashdocker run -d --read-only -v 数据卷:/data 镜像名
3. 网络安全(隔离与访问控制)
(1)网络隔离
-
禁用默认 bridge 网络,为不同业务创建独立自定义网络:
bashdocker network create --driver bridge app-network # 业务网络 docker network create --driver bridge db-network # 数据库网络 -
限制容器端口暴露:仅暴露必要端口,避免
--publish-all(-P):bashdocker run -d -p 8080:80 镜像名 # 仅暴露8080端口,而非所有端口
(2)防火墙与访问控制
-
宿主机启用 iptables/ufw,限制容器端口的外部访问;
-
用 Docker Compose 配置网络策略,限制容器间通信:
yaml# docker-compose.yml 示例:仅允许app访问db version: "3" services: app: networks: - app-db-network db: networks: - app-db-network networks: app-db-network: driver: bridge internal: true # 禁止外部访问该网络
4. 数据安全(防止数据泄露/篡改)
(1)数据卷权限控制
-
禁止挂载宿主机敏感目录(/etc、/root、/var/run/docker.sock);
-
数据卷权限设为最小:
bashdocker run -d -v app-data:/data --user 1000:1000 镜像名 # 宿主机修改数据卷权限 chown -R 1000:1000 /var/lib/docker/volumes/app-data/_data
(2)数据加密
- 敏感数据(如密码)通过 Docker Secrets(Swarm)/环境变量加密传递,避免硬编码在镜像中;
- 数据卷存储的敏感数据(如数据库)启用文件系统加密(如 LUKS)。
5. 引擎与宿主机安全(底层加固)
(1)Docker 引擎加固
-
禁用 Docker API 远程访问(2375/tcp),或启用 TLS 认证:
bash# 配置Docker守护进程仅监听本地Unix套接字(默认) # /etc/docker/daemon.json { "hosts": ["unix:///var/run/docker.sock"] } -
定期更新 Docker 引擎,修复已知漏洞:
bashyum update docker-ce # CentOS apt update && apt upgrade docker-ce # Ubuntu
(2)宿主机安全
-
宿主机最小化安装,仅安装必要依赖;
-
启用 Linux 安全模块(SELinux/AppArmor),限制容器行为:
bash# 运行容器时指定AppArmor配置文件 docker run -d --security-opt apparmor=docker-default 镜像名 -
禁止容器挂载宿主机
/var/run/docker.sock(防止容器控制 Docker 引擎)。
6. 监控与审计(事后追溯)
-
开启 Docker 日志收集:记录容器启动、镜像拉取、命令执行等操作;
-
用 Falco 监控容器异常行为(如容器内提权、敏感目录挂载);
-
定期审计容器/镜像/网络配置,清理无用资源:
bashdocker system prune -af # 清理无用镜像/容器/网络
三、经典面试题(含标准答案)
Q1:Docker 容器与虚拟机的安全区别?
- 隔离级别:虚拟机是硬件级隔离(独立内核),Docker 是内核级隔离(共享宿主机内核),Docker 隔离性更弱;
- 攻击面:Docker 镜像/容器轻量化,攻击面小,但内核漏洞会影响所有容器;虚拟机攻击面大,但内核独立,单虚拟机沦陷不影响其他;
- 权限:Docker 容器内 root 等价于宿主机 root,虚拟机内 root 仅作用于虚拟机;
- 优化方向:Docker 需重点做权限最小化、内核加固,虚拟机侧重系统层面安全。
Q2:如何防止容器突破隔离,攻击宿主机?
- 非 root 用户运行容器,禁用
--privileged; - 启用 SELinux/AppArmor,限制容器系统调用;
- 限制容器资源,禁止挂载敏感目录;
- 定期更新内核和 Docker 引擎,修复提权漏洞;
- 禁用容器内 ptrace、mount 等危险操作。
Q3:生产环境中,Docker 镜像的安全最佳实践?
- 选择官方/可信精简镜像,避免未知来源;
- 多阶段构建,剔除构建依赖,减小镜像体积;
- 镜像扫描,检测漏洞和恶意代码;
- 启用镜像签名验证,防止篡改;
- 不在镜像中硬编码敏感信息(密码、密钥)。
Q4:Docker API 暴露有哪些风险?如何防护?
- 风险:未授权访问可创建特权容器、删除宿主机数据、控制整个 Docker 引擎;
- 防护:
- 禁用远程访问,仅监听本地 Unix 套接字;
- 启用 TLS 认证,仅允许可信客户端访问;
- 宿主机防火墙限制 2375/2376 端口访问;
- 最小化 Docker 守护进程权限。
四、记忆口诀
镜像源头要干净,精简扫描加签名;
容器运行非 root,特权资源全限制;
网络隔离控端口,数据卷不挂敏感;
引擎加固禁 API,监控审计不放松。
要不要我帮你把「Docker 网络、镜像仓库、数据卷、安全优化」这四块整合为一份Docker 核心面试速记手册,方便你一次性背诵?