一、智能体容错设计
1. 核心概念
医疗AI智能体的容错设计,是指针对医疗场景中用户输入的模糊性、错误性、极端性等不确定性问题,通过技术手段让AI系统具备"包容错误、引导正确、应对极端"的能力,既避免系统崩溃或生硬报错,又能保障医疗咨询的安全性、有效性和人性化。
与普通场景的容错设计不同,医疗AI的容错设计有三大核心特征:
- 安全性优先:医疗场景直接关联用户健康甚至生命,容错设计不能仅追求不报错,更要避免误导用户或遗漏高危风险;
- 人性化交互:医疗用户常处于焦虑、不适状态,模糊、错误输入多源于表达能力受限,如老人、儿童、急症患者,容错设计需兼顾情绪安抚;
- 合规性约束:需符合医疗数据隐私、AI 医疗应用规范,极端场景处理还需对接合规的医疗、心理援助资源。

2. 医疗场景的不确定性体现
| 不确定性类型 | 典型案例 | 潜在风险 |
|---|---|---|
| 模糊输入 | "浑身不舒服""没力气""身体不得劲" | AI 无法精准识别症状,给出无效建议,甚至遗漏关键病症 |
| 错误输入 | 上传风景照 / 美食照、输入乱码(如 "asdfg123%%%")、错别字连篇的症状描述 | 系统报错引发用户反感,或误判输入内容导致医疗建议偏差 |
| 极端场景输入 | 提及 "重度抑郁""大量服药""急性心梗无人照料" | 未及时响应导致人身安全风险,违反医疗 AI 伦理规范 |
3. 容错设计的核心意义
- **提升用户体验与信任度:**医疗场景中用户尤其是非专业人士难以精准描述症状,容错设计通过引导式交互降低用户使用门槛,避免因不会说而放弃使用,提升对 AI 的信任;
- **保障医疗安全底线:**极端场景的容错处理是医疗AI的"生命线",能及时对接人工资源,避免 AI 独自处理高危问题引发的安全事故;
- **增强模型落地实用性:**真实医疗场景中,纯标准化输入占比不足 30%,容错设计让大模型从实验室效果走向真实场景可用,解决落地最后一公里问题;
- **降低运维成本:**通过自动化的容错逻辑处理80%以上的异常输入,减少人工客服的无效介入,提升整体服务效率。
二、容错设计的逻辑
1. 大模型的基本框架
"输入 - 处理 - 输出"是大模型的基本框架,医疗AI智能体的核心交互逻辑遵循大模型通用的"输入层→处理层→输出层"架构,容错设计本质是在这个架构中增加"异常识别"和"异常处理"分支:
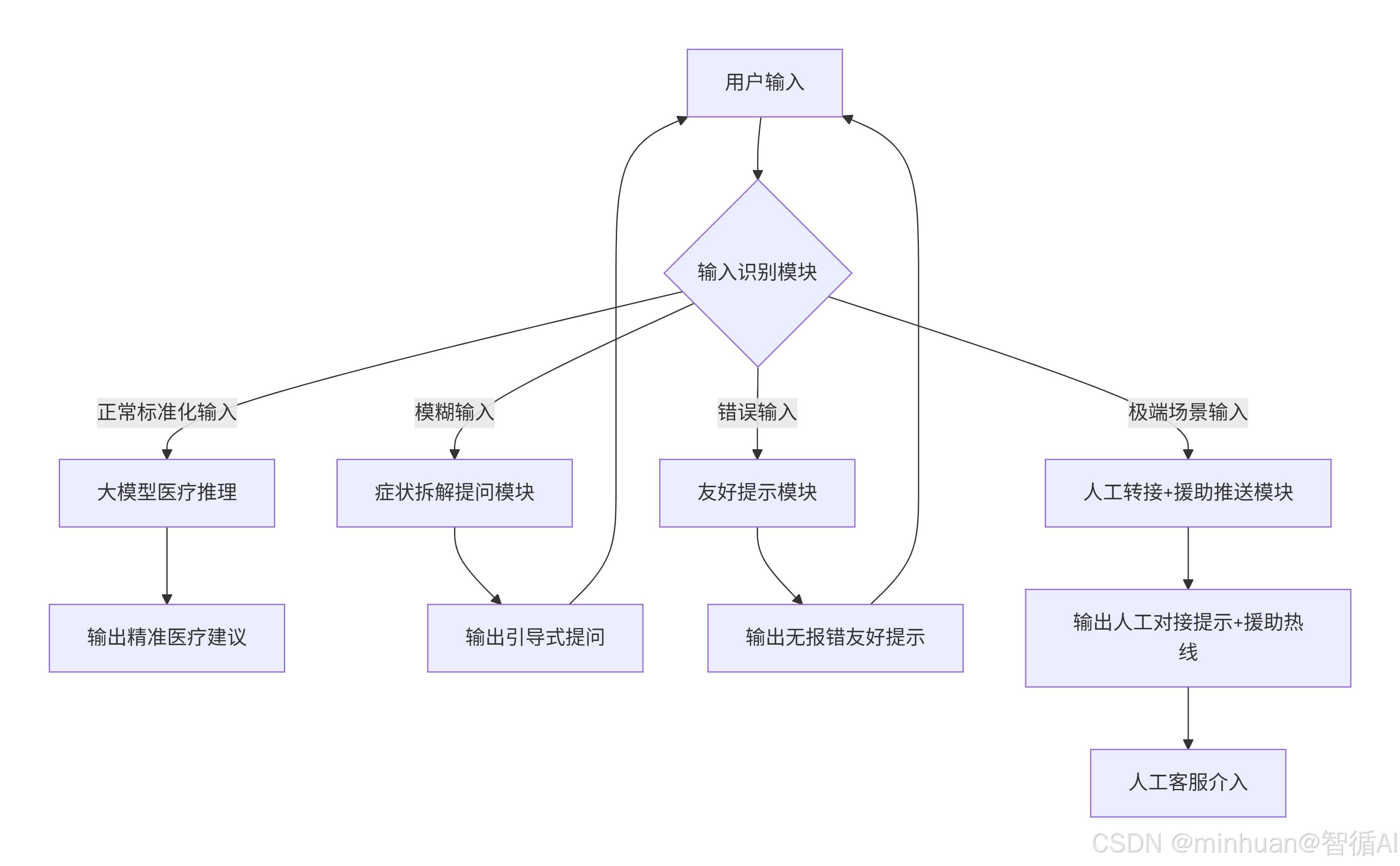
2. 异常识别的核心
2.1 文本\图片输入的异常识别
- 文本分类: 核心是让大模型或辅助小模型能区分"正常症状描述"、"模糊症状描述"、"乱码或无意义文本"、"高危关键词文本"。通俗的可理解为 "给输入贴标签":
- 正常标签:"我头痛 3 天,伴随恶心,体温 37.8℃";
- 模糊标签:"浑身不舒服"、"没力气";
- 错误标签:"asdfg@@@"、"今天天气真好";
- 高危标签:"不想活了"、"重度抑郁有轻生念头"。
- **图片识别:**通过预训练的图像分类模型(如 ResNet、MobileNet)识别上传图片是否为医疗相关的检查报告、症状部位照片,非医疗图片直接归类为"错误输入"。
- **关键词匹配:**构建高危关键词库,通过"精确匹配 + 语义相似匹配"识别极端场景输入。我们可理解为"关键词字典查找",比如字典里有"轻生"、"重度抑郁"、"自伤"等词,输入中出现这些词就触发特殊处理。
2.2 交互引导
针对模糊输入的"症状拆解提问",核心是大模型的"意图拆解"能力:
- 基础逻辑:大模型先识别模糊输入的症状大类,如"浑身不舒服"属于"全身症状类",再从预设的症状库中提取该大类下的常见具体症状,生成引导式提问;
- 示例逻辑:"浑身不舒服"→ 识别为"全身症状"→ 提取常见具体症状,头痛、乏力、关节痛、肌肉痛、发热 → 生成"是头痛/乏力/关节痛?还是其他?"。
2.3 流程触发
极端场景的"人工转接 + 热线推送",核心是"规则引擎 + 接口调用":
- 规则引擎:当输入匹配高危关键词库,自动触发预设规则,如"转接人工客服接口 + 调取心理援助热线数据";
- 接口调用:AI系统对接医院或平台的人工客服系统接口、心理援助热线数据库接口,实现自动化推送。
3. 必要的核心原则
- **"不硬刚"原则:**面对无法识别的输入,优先引导而非报错。比如用户上传风景照,不要输出"输入错误:非医疗图片",而是输出"我暂时无法识别这个内容,你可以描述具体症状或上传检查报告,我会尽力解答";
- **"逐步聚焦"原则:**模糊输入处理不追求"一步到位",而是通过多次提问逐步缩小范围,直到获取足够精准的症状信息;
- **"安全兜底"原则:**极端场景必须人工介入,AI不单独处理高危问题,所有高危交互记录需留存,符合医疗合规要求;
- **"人性化"原则:**所有容错回复需避免冰冷的技术语言,加入安抚性表达,如极端场景回复中加入"请不要担心,我们的人工客服会马上联系你,你不是一个人"。
三、容错设计的场景
1. 模糊输入处理
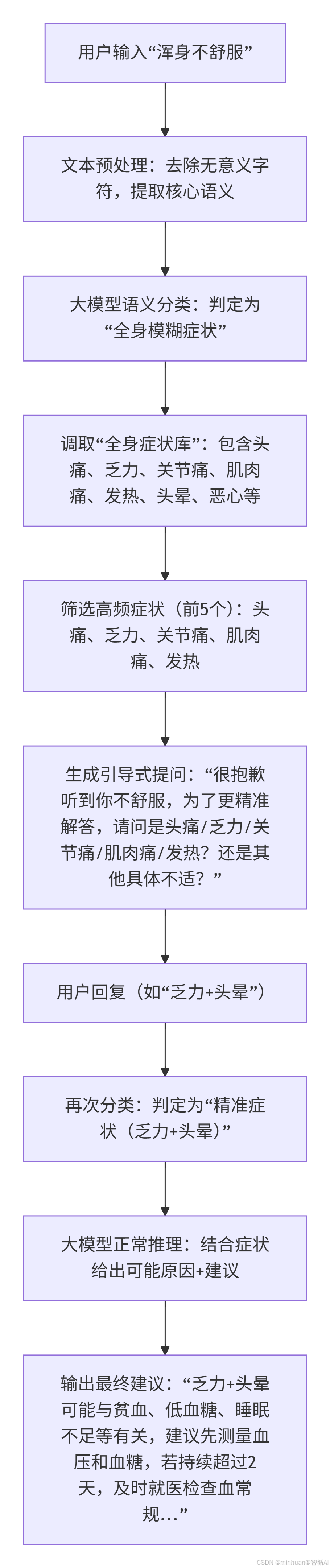
1.1 核心逻辑
模糊输入的本质是"用户意图不明确,症状描述粒度太粗",处理核心是"先归类,再拆解,后聚焦",我们以"浑身不舒服"为例:
-
- 归类:大模型将模糊输入归类到预设的"症状大类",如全身症状、头部症状、腹部症状等;
-
- 拆解:从该大类的"具体症状库"中提取高频症状;
-
- 聚焦:生成引导式提问,让用户从具体症状中选择,逐步缩小范围,直到获取精准症状。
1.2 执行流程
1.3 应用示例
1.3.1 症状库构建
javascript
{
"symptom_categories": {
"全身症状": [
"头痛", "乏力", "关节痛", "肌肉痛", "发热", "头晕", "恶心", "呕吐", "盗汗", "体重骤降"
],
"头部症状": [
"偏头痛", "后脑勺痛", "太阳穴痛", "耳鸣", "视力模糊", "鼻塞", "牙痛"
],
"腹部症状": [
"胃痛", "腹痛", "腹泻", "便秘", "腹胀", "反酸", "烧心"
]
},
"fuzzy_keywords": [
"浑身不舒服", "没力气", "身体不得劲", "全身难受", "不舒服", "难受"
]
}1.3.2 示例代码
python
import json
import re
from transformers import pipeline
# 加载症状库和模糊关键词库
def load_symptom_database(file_path="symptom_database.json"):
"""加载症状分类库和模糊关键词库"""
try:
with open(file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
return data["symptom_categories"], data["fuzzy_keywords"]
except FileNotFoundError:
print("症状库文件未找到,使用默认库")
# 默认症状库
default_categories = {
"全身症状": ["头痛", "乏力", "关节痛", "肌肉痛", "发热", "头晕"],
"头部症状": ["偏头痛", "后脑勺痛", "太阳穴痛"],
"腹部症状": ["胃痛", "腹痛", "腹泻"]
}
default_fuzzy = ["浑身不舒服", "没力气", "身体不得劲"]
return default_categories, default_fuzzy
# 识别模糊输入
def is_fuzzy_input(user_input, fuzzy_keywords):
"""判断用户输入是否为模糊症状描述"""
# 去除标点和空格,统一为小写
clean_input = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9]', '', user_input).lower()
for keyword in fuzzy_keywords:
if keyword in clean_input:
return True
return False
# 症状归类与拆解提问生成
def generate_symptom_question(user_input, symptom_categories):
"""根据模糊输入生成症状拆解提问"""
# 简单的语义匹配(初学者版,进阶可使用大模型)
if any(word in user_input for word in ["浑身", "全身", "没力气", "不舒服"]):
category = "全身症状"
elif any(word in user_input for word in ["头", "晕", "痛", "耳鸣"]):
category = "头部症状"
elif any(word in user_input for word in ["肚子", "胃", "腹", "泻"]):
category = "腹部症状"
else:
category = "全身症状" # 默认归类
# 提取该类别下的前5个高频症状
top_symptoms = symptom_categories[category][:5]
# 生成引导式提问
symptom_str = "/".join(top_symptoms)
question = f"很抱歉听到你不舒服,为了更精准解答,请问是{symptom_str}?还是其他具体不适?"
return question
# 大模型推理(使用Hugging Face的开源模型)
def medical_inference(symptoms):
"""根据精准症状生成医疗建议"""
try:
# 使用 bert-base-chinese 的问答pipeline
pipe = pipeline("question-answering", model="bert-base-chinese")
# 构建更完整的上下文
context = f"""根据您的症状"{symptoms}",可能的原因包括感冒、疲劳或其他常见问题。建议措施如下:第一,多休息,保证充足睡眠;第二,多喝温水,保持水分充足;第三,监测体温变化;第四,适当进行轻度活动;第五,如症状持续或加重,请及时就医。本建议仅供参考,不替代专业医生的诊断和治疗。"""
# 询问具体的建议措施
question = "建议措施有哪些?"
# 调用模型,设置更大的最大答案长度
result = pipe(question=question, context=context, max_answer_len=100)
# 直接返回模型输出的答案
return result['answer']
except Exception as e:
# 如果模型调用失败,返回默认建议
return f"根据您的描述\"{symptoms}\",建议您多休息,保持充足睡眠,多喝温水。如果症状持续或加重,请及时就医。"
# 主流程
def fuzzy_input_handler(user_input):
"""模糊输入处理主函数"""
# 加载数据
symptom_categories, fuzzy_keywords = load_symptom_database()
# 第一步:判断是否为模糊输入
if not is_fuzzy_input(user_input, fuzzy_keywords):
# 非模糊输入,直接推理
return medical_inference(user_input)
# 第二步:生成拆解提问
question = generate_symptom_question(user_input, symptom_categories)
print("AI回复:", question)
# 模拟用户二次输入(实际场景中为用户真实回复)
user_second_input = input("请输入你的具体症状:")
# 第三步:根据精准症状推理
final_advice = medical_inference(user_second_input)
return f"AI回复:{final_advice}"
# 测试
if __name__ == "__main__":
user_input = "浑身不舒服"
result = fuzzy_input_handler(user_input)
print(result)代码说明:
- load_symptom_database:加载症状分类库和模糊关键词库,支持本地 JSON 文件,也有默认兜底,避免文件缺失导致程序崩溃,容错设计的小细节;
- is_fuzzy_input:通过关键词匹配识别模糊输入,先清洗输入文本,去除标点、空格,提升匹配准确率;
- generate_symptom_question:核心的"症状拆解"逻辑,先归类模糊输入的症状大类,再提取高频具体症状生成引导式提问;
- medical_inference:使用开源大模型bert-base-chinese进行症状的推理,生成专业建议;
- 主流程模拟了 "模糊输入→引导提问→精准输入→生成建议" 的完整闭环,可直接运行测试
2. 错误输入处理
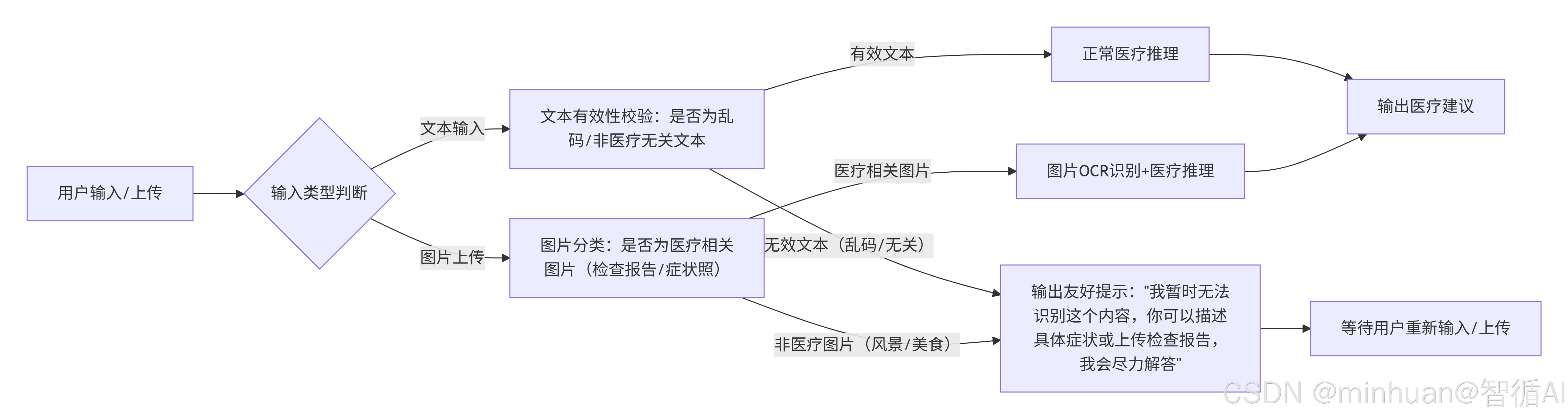
2.1 核心逻辑
错误输入的本质是"输入内容与医疗咨询无关,或格式无法识别",处理核心是"无报错 + 友好引导 + 明确告知可接受的输入类型",我们以"上传风景照和输入乱码"为例:
-
- 识别:通过图像分类、文本校验识别错误输入;
-
- 响应:避免输出"Error: 输入无效"等技术报错,使用自然、友好的语言告知用户无法识别;
-
- 引导:明确告知用户可接受的输入类型,如"描述具体症状"、"上传检查报告",降低用户再次输入错误的概率。
2.2 执行流程
2.3 应用示例
文本乱码识别 + 图片分类核心代码:
python
import re
import cv2
import numpy as np
from PIL import Image
from transformers import ViTImageProcessor, ViTForImageClassification
# 文本无效性校验(乱码/非医疗无关文本)
def is_invalid_text(user_input):
"""
判断文本是否为无效输入:
1. 纯乱码(字母+数字+符号组合,无有效中文)
2. 非医疗无关文本(如"今天天气真好""吃饭了吗")
"""
# 规则1:中文占比低于30%,且包含大量符号/乱码
chinese_chars = re.findall(r'[\u4e00-\u9fa5]', user_input)
chinese_ratio = len(chinese_chars) / len(user_input) if len(user_input) > 0 else 0
# 规则2:匹配非医疗无关关键词
non_medical_keywords = ["天气", "吃饭", "睡觉", "旅游", "风景", "电影", "游戏"]
non_medical_match = any(word in user_input for word in non_medical_keywords)
# 纯乱码(无中文)或非医疗无关文本,判定为无效
if (chinese_ratio < 0.3 and len(chinese_chars) == 0) or non_medical_match:
return True
return False
# 图片分类:识别是否为医疗相关图片
def is_medical_image(image_path):
"""
使用ViT模型识别图片是否为医疗相关(检查报告/症状部位)
初学者版:简化分类,仅区分"医疗图片"和"非医疗图片"
"""
# 加载预训练的ViT模型和处理器
processor = ViTImageProcessor.from_pretrained('google/vit-base-patch16-224')
model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224')
# 加载并预处理图片
try:
image = Image.open(image_path).convert('RGB')
inputs = processor(images=image, return_tensors="pt")
except:
# 图片无法打开,判定为无效
return False
# 模型推理
outputs = model(** inputs)
logits = outputs.logits
predicted_class_idx = logits.argmax(-1).item()
predicted_class = model.config.id2label[predicted_class_idx]
# 简单判定:包含"document"(文档,对应检查报告)或"human"(人体,对应症状照)为医疗图片
medical_keywords = ["document", "human", "person"]
if any(word in predicted_class.lower() for word in medical_keywords):
return True
return False
# 错误输入处理主函数
def error_input_handler(input_type, input_content):
"""
处理错误输入
input_type: "text" 或 "image"
input_content: 文本内容 或 图片路径
"""
# 文本错误输入
if input_type == "text":
if is_invalid_text(input_content):
return "我暂时无法识别这个内容,你可以描述具体症状或上传检查报告,我会尽力解答"
else:
return "你的症状描述已收到,我正在为你分析..."
# 图片错误输入
elif input_type == "image":
if not is_medical_image(input_content):
return "我暂时无法识别这个内容,你可以描述具体症状或上传检查报告,我会尽力解答"
else:
return "你的检查报告已收到,我正在为你解读..."
# 其他输入类型
else:
return "我暂时无法识别这个内容,你可以描述具体症状或上传检查报告,我会尽力解答"
# 测试
if __name__ == "__main__":
# 测试乱码文本
test_text = "asdfg123%%%今天天气真好"
print(error_input_handler("text", test_text))
# 测试风景照(替换为你的风景照路径)
test_image = "landscape.jpg"
print(error_input_handler("image", test_image))代码说明:
- is_invalid_text:从"中文占比"和"非医疗关键词匹配"两个维度判断文本是否为无效输入,避免将用户的正常模糊症状误判为错误输入;
- is_medical_image:使用ViT 预训练模型进行图片分类,简化版逻辑是识别"文档(检查报告)"和"人体(症状照)"为医疗图片,其他为非医疗图片;
- error_input_handler:统一的错误输入处理入口,无论文本还是图片错误,都输出相同的友好提示,避免用户困惑;
- 代码加入了异常处理,如图片无法打开时直接判定为无效,符合容错设计的不崩溃原则。
3. 极端场景处理
3.1 核心逻辑
极端场景输入的本质是"涉及人身安全的高危内容",处理核心是"AI 不单独决策 + 自动触发人工 + 推送援助资源",以"重度抑郁"为例:
-
- 识别:通过"精确关键词 + 语义相似匹配"识别高危输入;
-
- 触发:自动调用人工客服转接接口,同时调取援助热线数据库;
-
- 响应:输出安抚性提示 + 人工对接信息 + 援助热线,所有交互记录留存;
-
- 跟进:人工客服介入后,AI 持续辅助,如记录用户诉求、推送就医建议。
3.2 高危关键词库
javascript
{
"high_risk_keywords": {
"生命相关": ["轻生", "不想活了", "自伤", "自残"],
"抑郁相关": ["重度抑郁", "抑郁症想轻生", "抑郁到想死", "长期抑郁"],
"紧急医疗": ["大量服药", "急性心梗", "脑出血", "无人照料", "晕倒"]
},
"assistance_hotlines": {
"心理援助热线": "400-161-****",
"紧急医疗热线": "120",
"人工客服热线": "400-888-****"
}
}3.3 执行流程

3.4 应用示例
python
import json
import re
import time
from transformers import pipeline
# 加载高危关键词库和援助热线
def load_high_risk_database(file_path="high_risk_database.json"):
"""加载高危关键词库和援助热线"""
try:
with open(file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
# 扁平化高危关键词列表
high_risk_words = []
for category in data["high_risk_keywords"].values():
high_risk_words.extend(category)
return high_risk_words, data["assistance_hotlines"]
except FileNotFoundError:
print("高危数据库未找到,使用默认库")
default_words = [ "轻生", "不想活了", "重度抑郁", "大量服药"]
default_hotlines = {
"心理援助热线": "400-161-****",
"紧急医疗热线": "120",
"人工客服热线": "400-888-****"
}
return default_words, default_hotlines
# 识别高危输入
def is_high_risk_input(user_input, high_risk_words):
"""判断用户输入是否为高危内容"""
clean_input = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9]', '', user_input).lower()
# 精确匹配+语义相似匹配(简单版:先精确匹配)
for word in high_risk_words:
if word in clean_input:
return True
# 进阶:语义相似匹配(使用Sentence-BERT)
# from sentence_transformers import SentenceTransformer, util
# model = SentenceTransformer('all-MiniLM-L6-v2')
# input_embedding = model.encode(clean_input, convert_to_tensor=True)
# for word in high_risk_words:
# word_embedding = model.encode(word, convert_to_tensor=True)
# if util.cos_sim(input_embedding, word_embedding) > 0.7:
# return True
return False
# 调用人工客服转接接口(模拟)
def call_human_service():
"""模拟调用人工客服转接接口,标记为高危优先级"""
print("【后台日志】触发高危优先级人工转接,时间:", time.strftime("%Y-%m-%d %H:%M:%S"))
# 实际场景中为接口调用:
# import requests
# response = requests.post("https://api.your-platform.com/transfer-human",
# json={"priority": "high", "content": user_input})
# return response.status_code == 200
return True
# 极端场景处理主函数
def high_risk_input_handler(user_input):
"""极端场景输入处理主函数"""
# 加载数据
high_risk_words, hotlines = load_high_risk_database()
# 第一步:判断是否为高危输入
if not is_high_risk_input(user_input, high_risk_words):
# 非高危输入,正常推理
pipe = pipeline("text2text-generation", model="medicalai/medbert-base-chinese")
prompt = f"请给出{user_input}的建议:"
return pipe(prompt, max_length=200)[0]["generated_text"]
# 第二步:触发人工转接
transfer_success = call_human_service()
# 第三步:生成安抚+援助提示
if transfer_success:
response = (
f"请不要担心,我们的人工客服会在1分钟内联系你(人工客服热线:{hotlines['人工客服热线']})。"
f"同时为你提供心理援助热线:{hotlines['心理援助热线']},紧急医疗情况可直接拨打{hotlines['紧急医疗热线']},你不是一个人!"
)
else:
# 接口调用失败的容错处理
response = (
f"请不要担心,我们非常重视你的情况。心理援助热线:{hotlines['心理援助热线']},"
f"紧急医疗情况可直接拨打{hotlines['紧急医疗热线']},也可拨打我们的人工客服热线:{hotlines['人工客服热线']},我们会立即为你提供帮助!"
)
# 第四步:记录高危交互(合规要求)
with open("high_risk_log.txt", 'a', encoding='utf-8') as f:
log = f"{time.strftime('%Y-%m-%d %H:%M:%S')} - 高危输入:{user_input} - 回复:{response}\n"
f.write(log)
return response
# 测试
if __name__ == "__main__":
# 测试高危输入
test_input = "我有重度抑郁,想轻生"
result = high_risk_input_handler(test_input)
print(result)代码说明:
- load_high_risk_database:加载高危关键词库和援助热线,扁平化关键词列表便于匹配,同时有默认库兜底;
- is_high_risk_input:初步使用精确关键词匹配,注释中提供了进阶的语义相似匹配方案(Sentence-BERT),提升高危输入识别的准确率,比如识别"活着没意思" 这类间接高危表达;
- call_human_service:模拟人工客服转接接口调用,实际场景中需对接平台的客服系统,标记为 "高危优先级" 确保人工快速响应;
- 代码加入了 "接口调用失败的容错处理":即使人工转接接口故障,也能输出援助热线,保障用户能获取帮助;
- 增加了高危交互记录功能,符合医疗 AI 的合规要求,便于后续追溯和审计。
四、总结
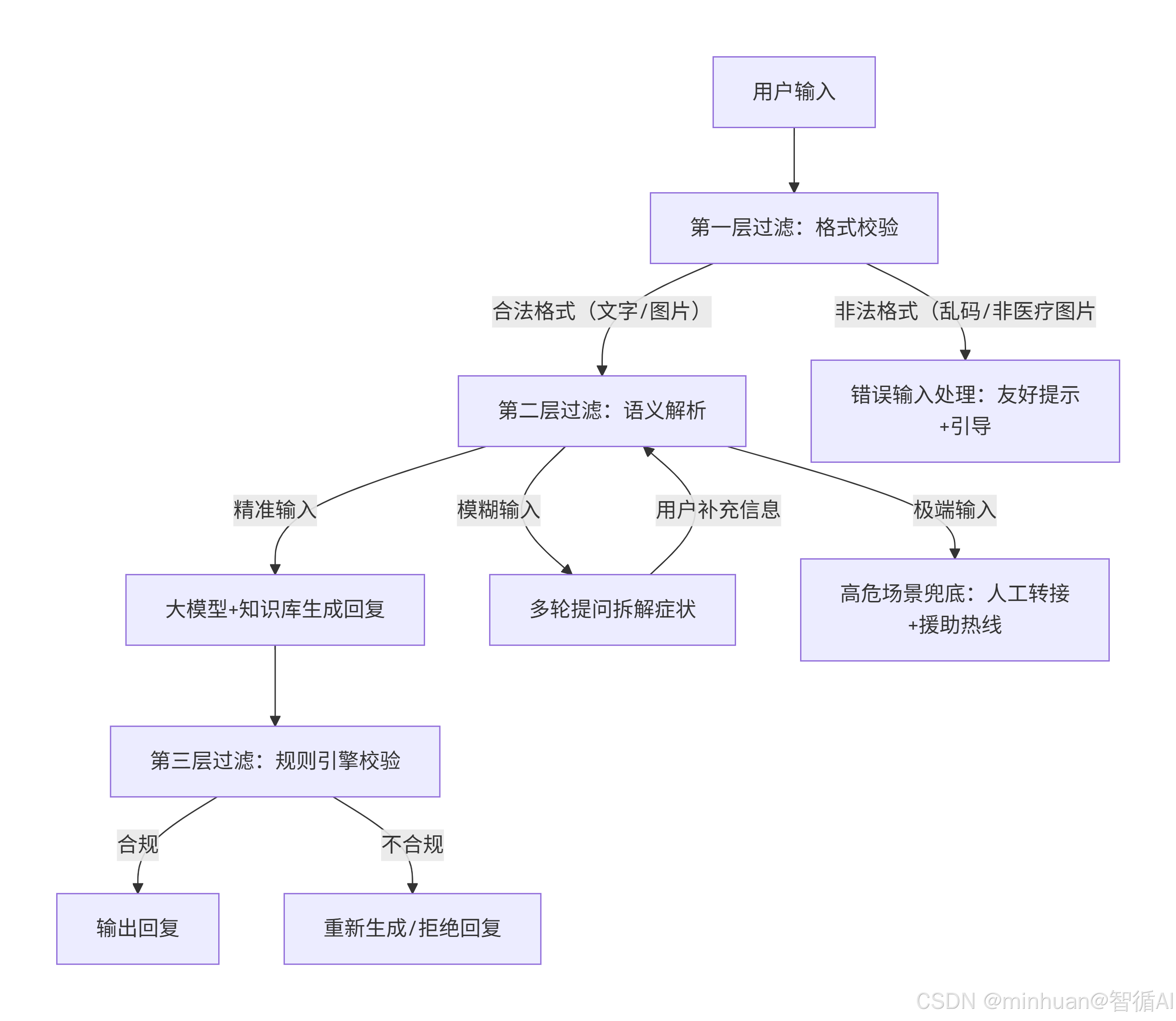
总的来说,系统通过格式校验拦截无效输入,语义解析区分精准/模糊/极端场景并分别走知识库生成、多轮提问或人工兜底,再经规则引擎确保回复合规,形成安全精准的医疗问答闭环。
医疗AI想真正落地能用,容错设计是地基。毕竟普通用户不是医生,说话含糊、输错内容、甚至情绪崩溃都很常见,不能像普通机器人那样一错就报错、一问就乱答。核心就盯三类棘手输入、守三条铁规矩:对付 "浑身不舒服" 这种模糊话,别瞎猜,按归类、拆解、聚焦一步步提问引导,慢慢抠准症状;遇到乱码、风景照这类错误输入,绝不甩技术报错,温柔提示能发啥、该咋说就行;碰到重度抑郁等极端高危内容,AI 绝不自作主张,立刻转人工、推援助热线,还要留好记录合规备查。
落地实操不用一上来搞复杂大模型堆叠,先搭好规则引擎,建好症状、模糊词、高危词三个基础词库,先跑通简单容错;再慢慢接入轻量开源医疗大模型,提升语义识别准度;保证人工转接和热线推送不掉链子。这样医疗AI才能不娇气、懂人情、守安全,才能用的放心。