起源请看这篇文章:http://www.3fwork.com/kaifa209/000562MYM007928
整体架构知乎主页里有文章介绍:https://www.zhihu.com/people/openppl/posts,复制粘贴如下
整体架构:
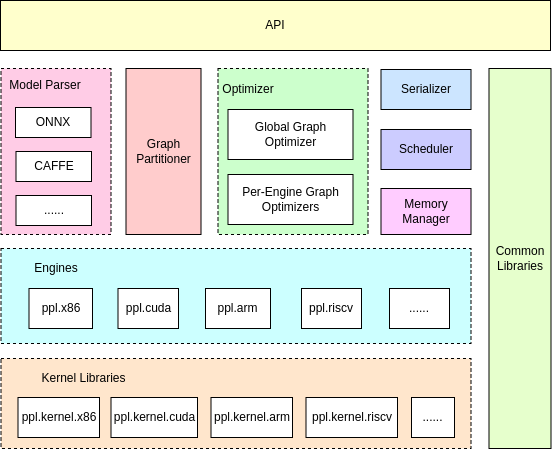
图片作者:OpenPPL
图片链接:https://zhuanlan.zhihu.com/p/663308297
图片来源:知乎
代码结构
include:对外暴露的接口;cmake:编译脚本;docker:构建用于运行 pplnn 的 docker 配置;docs:相关文档;python:python 接口封装;samples:例子集合;src/ppl/nnauxtools:一些辅助工具,不涉及功能的实现;common:一些公共库;engines:后端支持,每种后端的支持都在engines目录下的一个子目录,例如engines/x86;ir:模型中间表示;models:支持的模型格式,每种模型格式一个目录,例如models/onnx;optimizers:提供的一些通用优化实现,框架只提供实现,不会主动调用这些优化(GenericOptimizerManager除外,这个会默认调用),需要各个后端按需调用;oputils:和 op 相关的一些有用的函数;params:op 属性定义;quantization:量化配置文件解析;runtime:推理运行时的代码;utils:在实现中用到的一些有用的模块,大部分情况都会用到,非必需。
tests:单元测试;tools:有用的工具。
编译出来的 lib 包括以下部分:
pplnn_basic_static:这个是基本框架,包含除了engines和models之外的模块;pplnn_onnx_static:onnx 模型格式支持,由PPLNN_ENABLE_ONNX_MODEL控制是否编译,依赖 pplnn_basic_static;pplnn_cuda_static:cuda 支持,由PPLNN_USE_CUDA控制是否编译,依赖 pplnn_basic_static 和 cuda kernel;pplnn_x86_static:x86 支持,由PPLNN_USE_X86_64控制是否编译,依赖 pplnn_basic_static 和 x86 kernel;pplnn_arm_static:arm 支持,由PPLNN_USE_AARCH64控制是否编译,依赖 pplnn_basic_static 和 arm kernel;pplnn_riscv_static:riscv 支持,由PPLNN_USE_RISCV64控制是否编译,依赖 pplnn_basic_static 和 riscv kernel;- ...
其中engine目录里的不同实现(cuda/x86/arm)内部也有个Optimizer(优化器),和主目录的区别主要是:完全不同层次的分工 。简单来说,optimizers负责硬件无关的"通识"优化,而engines下的优化器则负责硬件相关的"深度"定制。
为了帮助你更清晰地理解,我把它们的核心区别整理成了下面的表格:
| 对比维度 | optimizers 目录下的优化器 |
engines 目录下的优化器 |
|---|---|---|
| 核心职责 | 硬件无关的图优化 | 硬件相关的后端优化 |
| 优化层次 | 计算图级别(Graph-Level) | 算子级别(Kernel-Level)及指令级别 |
| 依赖信息 | 仅依赖计算图结构 | 依赖硬件架构(如CUDA核心数、ARM指令集、内存排布) |
| 执行时机 | 模型加载后立即执行,仅一次 | 在引擎内部,为特定后端执行时进行 |
| 优化目标 | 减少计算量、简化图结构 | 极致利用硬件算力、访存带宽 |
| 典型技术 | 算子融合(如Conv+BN)、常量折叠、死节点消除 | Winograd卷积、内存排布优化(如NC4HW4)、汇编指令调优 |
1. 硬件无关的优化器 (optimizers)
这部分可以看作是"通识教育",其代码位于 src/ppl/nn/optimizers/ 目录下。它的优化不关心后续模型是跑在x86 CPU上还是NVIDIA GPU上,只关注模型本身的计算图结构。
在OpenPPL的预处理流程中,框架会通过一个名为 GraphOptimizerManager 的单例管理器来依次调用这些优化器。你可以把它想象成一个"流水线",依次对模型执行一系列标准的优化脚本。
例如,其中几个关键的优化器(GraphOptimizer)的功能如下:
-
FuseBNOptimizer(BN融合优化器):这个优化器会搜索模型中的"卷积层(Conv)+ 批归一化层(Batch Normalization)"的组合。它会将BN层的参数(均值和方差)计算并融合进卷积层的权重和偏置中。这样做的好处是,在推理时可以减少一次BN层的计算,从而降低访存和计算开销。 -
ConstantNodeOptimizer(常量节点优化器) :也称为常量折叠 。如果模型中存在一些节点,其所有输入都是已知的常量(例如Shape算子的输出),那么这个优化器会在编译阶段直接计算出结果,并将其替换为一个常量节点,从而省去运行时计算。 -
SkipDropoutOptimizer(丢弃法优化器):在模型推理阶段,Dropout层是无效的。这个优化器会直接将图中的Dropout节点删除,简化计算图。
2. 硬件相关的优化器 (engines)
这部分的优化工作是在具体的后端引擎内部完成的,例如 ppl/nn/engines/x86 或 ppl/nn/engines/cuda 等目录下。当模型被拆分成多个子图并分配给特定硬件后,由对应硬件的 EngineImpl::ProcessGraph() 函数来触发这些优化。
其优化目标是针对特定硬件架构,让算子的运行速度达到极致。它的深度主要体现在以下几个方面:
-
算子实现的选择与调优 :对于同一个卷积算子,在CUDA后端可能实现了多种算法 (如Im2col+GEMM、Winograd、直接卷积)。硬件相关的优化器会根据输入形状(如卷积核大小、特征图尺寸)运行一个"试跑"或基于启发式规则,自动选择性能最优的算法。
-
内存排布优化 :这是硬件优化非常关键的一环。GPU更喜欢数据以合并访问的方式排列。例如,OpenPPL在移动端GPU上会将数据排布调整为
NC4HW4(即把每4个channel打包在一起),以充分利用GPU的float4或RGBA纹理内存,从而提高访存效率和缓存命中率。 -
汇编级优化 :在x86和ARM CPU上,优化器会调用由手工汇编编写的算子。这些汇编代码针对特定的CPU微架构(如AVX512指令集或ARMv8.2的SVE指令)进行了精细的指令流水线编排,以实现极致的指令级并行。