国家区试试验方差分析、多重比较与变异系数计算
农业统计 · 育种分析
一年多点随机区组 · 区组嵌套于地点 · LSD 双水平 · 误差方差驱动的 CV
导读: 国家区域试验(区试)是作物新品种审定的核心环节。本文以一年多点随机区组设计为例,系统讲解三个关键分析步骤------方差分析 (区组嵌套于地点的混合模型)、多重比较 (0.05 与 0.01 双水平 LSD)、以及地点变异系数计算(基于误差均方而非表型数据直接计算)------并附完整 R 代码,可直接用于实际数据分析。
1 试验设计背景
国家区试通常采用随机完全区组设计(RCBD),在多个生态区的多个地点同时开展。典型结构为:
- 地点(Location):代表不同生态区或省份,是试验的"环境"因子
- 品种(Cultivar/Genotype):待评价的参试品种,是研究的核心因子
- 区组(Block/Replicate):每个地点内设置 3~4 个重复区组,用于控制地点内的土壤异质性
⚠️ 关键设计要点:区组嵌套于地点
各地点的区组是相互独立的------L1 的"第 1 区组"与 L2 的"第 1 区组"在地理上毫无关联。因此,区组必须作为地点的嵌套效应处理,不能作为跨地点的完全区组处理。这一点在模型设定上至关重要,直接影响误差项的正确性。
本文使用的示例数据包含 10 个地点(L1~L10)、9 个品种、每地点 4 个区组,共 360 条记录(性状为产量,单位 kg/m²)。
loc,cul,block,yield
L1,1,1,2.205
L1,1,2,1.925
L2,1,1,2.400
...(共 360 行,10地点 × 9品种 × 4重复)2 方差分析:区组嵌套于地点的模型
2.1 模型结构
对于一年多点随机区组试验,标准的线性模型为:
y_ijk = μ + L_i + C_j + (LC)_ij + B_k(i) + ε_ijk
各项说明:
μ ------ 总体均值
L_i ------ 地点 i 的主效应
C_j ------ 品种 j 的主效应(关注重点)
(LC)_ij ------ 地点 × 品种互作效应
B_k(i) ------ 地点 i 内第 k 区组效应(嵌套效应)
ε_ijk ------ 随机误差❌ 常见错误:把区组当做完全因子处理
错误写法:
yield ~ loc + cul + block + loc:cul这隐含假设"第1区组"在所有地点具有相同含义,会导致:①自由度分配错误;②误差项估计不准确;③品种 F 检验结果失真。
✅ 正确写法:区组嵌套于地点正确写法:
yield ~ loc * cul + loc:block展开等价于:
yield ~ loc + cul + loc:cul + loc:block
loc:block项即"区组嵌套于地点",每个地点各自估计区组方差,互不干扰。
2.2 R 代码实现
r
# 加载所需包
library(agricolae) # 多重比较
library(tidyverse) # 数据处理
library(openxlsx) # 结果输出
# 读取数据并因子化
dd <- read.csv("one-year-locs.csv")
dd$loc <- as.factor(dd$loc)
dd$cul <- as.factor(dd$cul)
dd$block <- as.factor(dd$block)
# 构建模型:区组嵌套于地点
m1 <- aov(yield ~ loc * cul + loc:block, data = dd)
# 查看方差分析表
summary(m1)2.3 方差分析表结构
典型的一年多点方差分析表包含以下变异来源(括号内为本例数值):
| 变异来源 | 自由度 df | 均方 MS | F 值 |
|---|---|---|---|
| 地点 (loc) | L−1 = 9 | --- | --- |
| 品种 (cul) | C−1 = 8 | MS_cul | ★★ |
| 地点×品种 (loc:cul) | (L−1)(C−1) = 72 | MS_L×C | |
| 区组(地点) loc:block | L(R−1) = 30 | MS_B(L) | |
| 残差(误差) | 240 | MS_e | --- |
📌 自由度验算(本例:10地点 × 9品种 × 4区组)
地点:10 − 1 = 9 | 品种:9 − 1 = 8 | 地点×品种:9 × 8 = 72
区组(地点):10 × (4−1) = 30 | 总 df:360 − 1 = 359
残差 df:359 − 9 − 8 − 72 − 30 = 240
3 多重比较:0.05 与 0.01 双水平 LSD
3.1 为什么要做双水平多重比较?
国家区试品种审定标准通常要求同时给出品种在 0.05(显著) 和 0.01(极显著) 两个显著性水平的差异归组结果,分别用小写字母和大写字母标记,便于直观判断各品种的相对位置。
小写字母(a, b, c ...)代表 0.05 水平显著差异;大写字母(A, B, C ...)代表 0.01 水平极显著差异。相同字母表示差异不显著,不同字母表示存在显著差异。
3.2 LSD 法统计量
LSDα=tα, dfe×2×MSen\text{LSD}\alpha = t{\alpha,\, df_e} \times \sqrt{\frac{2 \times MS_e}{n}}LSDα=tα,dfe×n2×MSe
t_α,df_e ------ 误差自由度下的 t 临界值
MS_e ------ 方差分析的残差均方
n ------ 每个处理的重复总数(地点数 × 区组数)
两品种均值差 > LSD 时,认为差异显著3.3 R 代码实现
r
# 0.05 水平多重比较(小写字母标记)
lsd05 <- LSD.test(m1, "cul", alpha = 0.05)
print(lsd05$groups)
# 0.01 水平多重比较(大写字母标记)
lsd01 <- LSD.test(m1, "cul", alpha = 0.01)
# 将字母转为大写,符合区试报告惯例
lsd01$groups$groups <- toupper(lsd01$groups$groups)
print(lsd01$groups)3.4 结果示例
| 品种 | 均值 (kg/m²) | 0.05 水平(小写) | 0.01 水平(大写) |
|---|---|---|---|
| 品种 3 | 2.334 | a | A |
| 品种 10 | 2.240 | ab | A |
| 品种 6 | 2.142 | b | AB |
| 品种 1 | 2.088 | bc | B |
| 品种 5 | 2.047 | bc | B |
| 品种 7 | 1.950 | cd | BC |
| 品种 8 | 1.878 | d | C |
| 品种 2 | 1.867 | d | C |
| 品种 4 | 1.866 | d | C |
💡 双水平结果解读技巧
- 0.05 字母组区分更细,显著差距"门槛"更低
- 0.01 字母组区分更粗,只有差异很大时才分到不同组
- 在 0.01 水平字母仍不同,说明品种间差距相当可观
- 审定时通常要求优良品种在两个水平均显著优于对照
4 地点变异系数:基于误差均方计算
4.1 为什么不能用表型数据直接计算 CV?
许多初学者会直接用该地点所有观测值的标准差除以均值来得到变异系数(CV)。这看似直观,却存在严重缺陷:
❌ 表型 CV 的问题
错误公式:
CV = sd(yield) / mean(yield)该公式将品种间差异也纳入了"变异"的计算------如果一个地点的参试品种本身高矮悬殊,即使该试验点精度很高,这个 CV 也会虚高,无法反映试验的真实误差水平。
✅ 正确做法:用误差均方(MSE)计算 CVMSE 是方差分析中扣除了品种效应和区组效应后的纯误差,真正代表试验的重复精度。用 MSE 计算的 CV 才是衡量试验点"可靠性"的正确指标。
4.2 计算原理与公式
CVi=MSEiYˉi×100%CV_i = \frac{\sqrt{MSE_i}}{\bar{Y}_i} \times 100\%CVi=YˉiMSEi ×100%
MSE_i ------ 地点 i 单点 RCBD 方差分析的残差均方
Ȳ_i ------ 地点 i 所有观测值的均值
√MSE_i ------ 即该地点的试验误差标准差方差分析表结构如下,MSE 取自残差行(第3行)的均方列:
| 变异来源 | df | SS | MS | 说明 |
|---|---|---|---|---|
| 区组 (block) | R−1 | SS_B | MS_B | 控制环境变异 |
| 品种 (cul) | C−1 | SS_C | MS_C | 处理效应 |
| 残差(误差)← 取这里 | (R−1)(C−1) | SS_e | MSE | 用于计算 CV |
4.3 结果示例与精度评价
| 地点 | 均值 | MSE | √MSE | CV (%) | 精度 |
|---|---|---|---|---|---|
| L1 | 1.807 | 0.0312 | 0.177 | 9.8% | ✓ 合格 |
| L2 | 1.856 | 0.0284 | 0.169 | 9.1% | ✓ 合格 |
| L3 | 2.270 | 0.0198 | 0.141 | 6.2% | ★ 优良 |
| L4 | 1.829 | 0.0456 | 0.214 | 11.7% | ⚠ 偏高 |
| L5 | 2.036 | 0.0267 | 0.163 | 8.0% | ✓ 合格 |
| L6 | 2.147 | 0.0159 | 0.126 | 5.9% | ★ 优良 |
| L7 | 1.939 | 0.0321 | 0.179 | 9.2% | ✓ 合格 |
| L8 | 1.828 | 0.0445 | 0.211 | 11.5% | ⚠ 偏高 |
| L9 | 1.588 | 0.0198 | 0.141 | 8.9% | ✓ 合格 |
| L10 | 2.240 | 0.0154 | 0.124 | 5.5% | ★ 优良 |
📊 CV 精度评价参考标准
- CV ≤ 8%:试验精度优良,数据可靠性高
- 8% < CV ≤ 10%:试验精度合格,数据可用
- 10% < CV ≤ 15%:试验精度偏低,结果使用时需谨慎
- CV > 15%:试验精度不合格,结果通常不予采用
注:具体阈值因作物和性状而异,以各作物区试实施方案规定为准。
5 完整分析流程
① 数据整理:loc / cul / block / trait 四列格式
↓
② 全局方差分析:yield ~ loc * cul + loc:block
↓
③ 品种多重比较(0.05 水平)→ 小写字母
↓
④ 品种多重比较(0.01 水平)→ 大写字母
↓
⑤ 各地点单独 RCBD → 提取 MSE → 计算 CV
↓
⑥ 汇总输出:方差分析表 + 多重比较表 + CV 表6 核心知识点回顾
- 区组必须嵌套于地点 :模型中须用
loc:block而非单独的block,否则自由度和 F 检验均出错 - 完整模型 :
yield ~ loc * cul + loc:block,含地点主效、品种主效、地点×品种互作、嵌套区组四个效应 - 双水平多重比较 :
alpha=0.05输出小写字母;alpha=0.01输出后须toupper()转大写 - CV 基于误差均方 :单点 RCBD 方差分析表残差行取 MSE,公式
CV = √MSE / 均值,才是真正的试验精度指标 - 表型 CV ≠ 误差 CV :直接用
sd/mean计算的 CV 包含品种间差异,不能作为试验精度指标
🌾 代码与数据开放获取
本文代码基于 R 语言
agricolae包实现,支持命令行参数化运行,适用于任意多点随机区组区试数据分析。如有问题或建议,欢迎在评论区交流探讨。
7 自动化分析平台实现方案
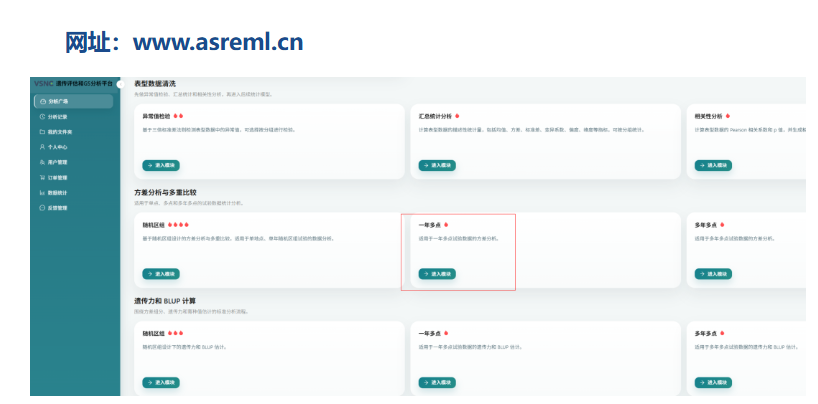
找到"植物模块"-->方差分析与多重比较 --> 一年多点:
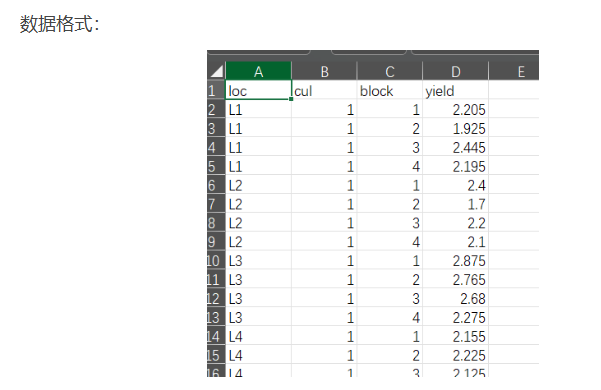
上传数据,选择地点、品种、区组和产量,导入到对应的列:(如果稍等一会,AI会自动根据数据结构自动导入,666)
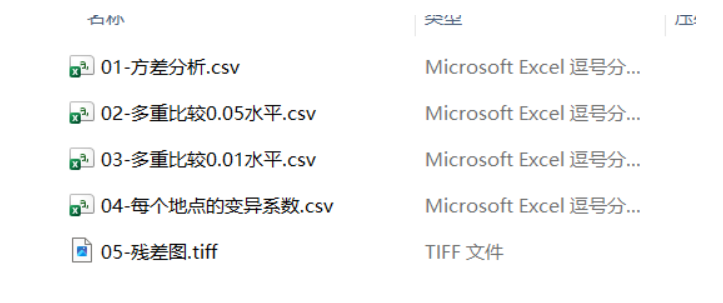
下载结果:
邮箱中还可以得到AI结果解读:

不用编写代码,全程鼠标操作,就能得到最专业的分析!快到www.asreml.cn 中试一下吧。