LMRing 实测榜:GPT-5.4 登顶?Claude 4.6 还能打吗?
如果你最近也在刷各种"大模型实测榜",大概率已经发现一个问题:
大家都在讨论"谁第一",但很少有人认真回答"这个结论到底是怎么得出来的"。
这两个月,大模型圈的内容越来越像体育解说。
今天有人说 GPT-5.4 已经"全面断档领先"。
明天又有人说 Claude 4.6 依然是代码场景天花板。
再过两天,Gemini 3.1 Pro、GLM 5.0 又会被拉出来重新排位。
看起来很热闹,但作为开发者,我越来越烦这种讨论方式了。
因为绝大多数"实测榜",最后都只剩一句话:
某模型第一。
问题是,第一有什么用?
我真正想知道的不是"谁第一",而是:
- 同一个真实任务下,多个模型到底差在哪
- 为什么这个模型会赢
- 这个结论能不能复现
- 换一个业务场景后,排名会不会立刻反转
- 如果我是团队负责人,到底该给谁预算、接谁的接口
说白了,大家缺的从来不是另一个"结论型榜单",而是一个能自己下场验证的模型竞技场。
这也是我们做 LMRing 的原因。
它不是想替你宣布冠军,
而是想把"谁更强"这件事,从社交媒体口水战,重新拉回到一个开发者可以亲手验证的系统里。
在 LMRing 里,你可以把同一个 Prompt 同时发给多个模型,看它们实时输出、对结果投票、沉淀成排行榜,再把整个过程保留下来。
与其争论 GPT-5.4 有没有登顶、Claude 4.6 还能不能打,
不如直接把题目放进去,跑一轮再说。
而且更关键的是,LMRing 不只是一个"多开几个模型窗口"的小工具。
它背后其实是一套完整的架构设计:
- 用统一 Provider 层接入不同模型服务商
- 用独立 workflow 管理每个模型的上下文和状态
- 用流式事件把回答、推理、指标实时推到前端
- 用数据库把消息、回答、投票、排行拆开持久化
- 用本地实测结果和外部评测数据一起构建排行榜
这篇文章就不只想介绍"LMRing 是什么",
也想讲清楚:一个真正能打的多模型竞技场,到底应该怎么设计。
LMRing 是什么?
LMRing 是一个开源的多模型对比竞技场,你可以把它理解成一个专门给开发者和团队准备的 AI Arena。
它解决的是一个很现实的问题:
当你要比较多个模型时,不能每次都开 4 个网页、复制 4 次 Prompt、靠肉眼记忆谁更好。
所以 LMRing 做了几件事:
- 同时拉起 2 到 5 个模型一起回答
- 实时流式展示输出
- 对回答结果进行投票
- 把投票沉淀成排行榜
- 保存对话历史,方便回看和分享
- 支持文本、图片、视频等不同生成场景
- 支持自部署,数据和 API Key 自己掌控
换句话说,LMRing 不只是一个"多模型聊天页",它更像是一套 模型对比 + 结果沉淀 + 团队协作 的基础设施。
为什么今天还需要一个新的模型对比平台?
因为大模型评测的重点已经变了。
过去大家更关心"模型聪不聪明",现在更关心:
- 写代码时谁更稳
- 改 Bug 时谁更少跑偏
- 多轮上下文里谁更听指令
- 复杂任务里谁的输出更可落地
- 团队到底该优先接哪家模型
- 价格、速度、质量三者怎么平衡
也就是说,模型评测已经从"围观式评分"变成"工程化选型"。
这时候,一张静态排行榜就不够了。
你需要的是:
- 能跑真实业务 Prompt
- 能对多个模型横向比较
- 能把结果保存下来
- 能让团队一起参与判断
- 能持续累积,而不是一次性截图
这才是 LMRing 想解决的问题。
从产品体验看,LMRing 的核心能力是什么?
最核心的是 Arena 模式。
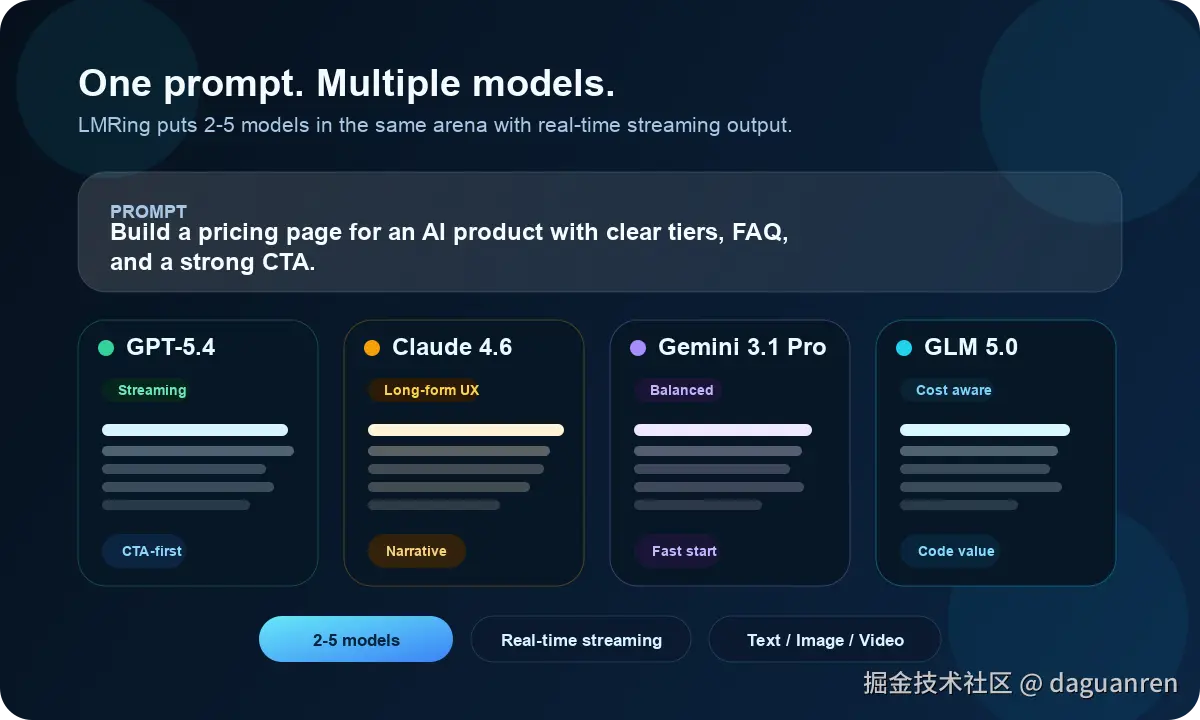
你可以一次选择多个模型,把同一个问题同时发出去,然后看它们实时输出。
比如这些场景都很适合拿来比:
- "请用 Next.js 16 写一个支持 SSR 的评论组件"
- "解释这段 SQL 为什么慢,并给出优化建议"
- "把这段中文技术说明改写成英文 PR 描述"
- "为一个 AI SaaS 产品写一版落地页文案"
- "根据一张图片生成更准确的提示词"
跑一轮之后,谁理解需求更准,谁结构更清楚,谁代码更稳,基本一眼就能看出来。
但如果只是把多个回答摆在一起,这还不够。
LMRing 更关键的地方在于,它背后不是"拼页面",而是有一套明确的架构设计。
下面就从实现角度讲讲,它是怎么做到的。
架构上,LMRing 是怎么把"多模型对比"做出来的?
我更愿意把它拆成 4 层来看:
- 模型接入层
- 工作流执行层
- 持久化与投票层
- 排行榜与外部评测层
可以先看一张简化版结构图:
text
用户输入 Prompt
↓
Arena 页面创建多个独立 workflow
↓
每个 workflow 通过统一流式接口请求对应模型
↓
后端根据 keyId / provider / modelId 动态创建 provider
↓
SSE 持续返回 chunk / reasoning / complete / error
↓
前端实时渲染多个回答卡片
↓
对话、回答、投票、统计结果落库
↓
排行榜页统一展示本地投票结果 + 外部评测数据这套设计的好处是:
- 前端体验统一
- 后端模型接入统一
- 不同模型保留独立上下文
- 每个模型回答都可以单独持久化和统计
- 后续扩展图片、视频、WebDev 等场景时,不需要推翻原有结构
第一层:模型接入层,怎么做到"多服务商统一接入"?
这个问题本质上是:
OpenAI、Anthropic、Google、兼容 OpenAI 协议的服务商,接口长得不一样,怎么在一个系统里统一使用?
LMRing 的做法是把"模型元数据"和"Provider 构建"拆开。
1. 用 model-depot 管模型元数据
项目里有一个 model-depot 包,负责维护 Provider 和模型能力描述,比如:
- 是否支持流式输出
- 是否支持结构化输出
- 是否支持 Vision
- 是否支持 Function Calling
- 是否属于官方 Provider
- 是否走兼容 OpenAI 的接入方式
这层的价值不是"聊天",而是"定义模型能力边界"。
这样前端和后端都不需要写死一堆 if/else,而是可以基于统一元数据决定:
- UI 要不要显示某个能力入口
- 请求时能不能带某些参数
- 某个模型是不是 reasoning model
- 某个 Provider 应该怎么构建
2. 用 provider-factory 动态创建 provider
真正的接入发生在服务端。
LMRing 的 provider-factory 做了几件很实用的事:
- 根据用户自己的
keyId拉取并解密 API Key - 区分官方 Provider 和自定义 Provider
- 自动规范化代理 URL
- 对兼容 OpenAI 协议的服务统一走 compatible provider 模式
- 如果某个 Provider 不在官方列表里,但给了
proxyUrl,也能正常接入
这意味着项目不是只支持少数硬编码模型,而是支持:
- 官方 SDK Provider
- OpenAI Compatible Provider
- 用户自定义代理地址
- 用户自定义模型覆盖和能力声明
这对真实开发环境特别重要,因为很多团队不会只用一家模型服务。
第二层:工作流执行层,怎么做到"多个模型同时流式输出"?
这是 LMRing 最核心的一层。
1. 一个模型,一个独立 workflow
LMRing 并不是把多个模型塞进一个大请求里统一处理。
它的设计更像:
- 每个模型对应一个独立 workflow
- 每个 workflow 有自己的状态、消息历史、pending response、配置
- Arena 页面只负责把多个 workflow 组合起来渲染
这种设计的好处很明显:
- 某个模型失败,不会拖垮整个 Arena
- 每个模型都能保留独立上下文
- 后续支持继续追问、单列重试、单列取消会更自然
- 文本、视频、WebDev 这些扩展能力也更容易复用 workflow 概念
2. 后端通过 SSE 流式返回事件
LMRing 的流式接口不是简单返回一个大文本,而是基于 SSE 做事件流传输。
服务端在 /api/workflow/stream 里会持续推送这些事件:
ttft:首 token 时间chunk:普通文本增量reasoning:推理过程增量complete:完成事件,附带 metricserror:错误信息
例如:
json
{ "type": "chunk", "workflowId": "...", "chunk": "Hello" }
{ "type": "reasoning", "workflowId": "...", "reasoning": "Let me think..." }
{ "type": "complete", "workflowId": "...", "metrics": { "totalTime": 1820, "totalTokens": 913 } }所以 LMRing 不只是把 token 流出来,而是把一整套工作流指标也一起流出来了。
3. 对 reasoning model 做了专门处理
很多多模型产品在这里会掉坑。
因为 reasoning model 和普通聊天模型,不只是输出内容不同,连参数支持都不同。
LMRing 在服务端做了专门判断:
- 非 reasoning 模型支持
temperature - reasoning 模型禁用
temperature - OpenAI / Anthropic / Google 还能带各自特定的 reasoning 配置
- 某些模型如果把思考过程塞在
<think>标签里,也会被解析成独立 reasoning 事件
这意味着前端不是把思维链混进正文,而是能把"回答"和"推理过程"分开处理。
这对做多模型对比很重要。
因为开发者很多时候不只看最终答案,还会看模型"是怎么想出来的"。
第三层:前端怎么把多个独立流合成一个顺滑的 Arena 体验?
如果后端只是能流式返回,那还不够。
前端体验如果做不好,多模型对比会非常卡。
LMRing 在前端 workflow 执行这层做了几个比较合理的设计。
1. 用 workflow store 管独立状态
每个 workflow 都会保存:
- 当前模型和 key
- 消息列表
- pendingResponse
- reasoning 内容
- 运行状态
- metrics
- abortController
- 是否处于 synced 模式
也就是说,在 Arena 页里,每一列并不是一个"纯 UI 卡片",而是一套完整的状态单元。
2. 用 requestAnimationFrame 做 chunk 缓冲
流式输出如果每来一个 token 就直接 setState,前端会非常容易抖动。
LMRing 在 useWorkflowExecution 里不是直接把每个 chunk 都打进组件,而是先放进 buffer,再通过 requestAnimationFrame 批量刷新。
这个设计的价值很实际:
- 降低高频渲染开销
- 多列同时输出时更稳定
- 页面滚动和输入框交互更顺滑
这类细节往往不容易在产品截图里看出来,但体验差异其实非常明显。
3. 会话不是一开始就创建,而是"首 chunk 成功后再建"
这个点我觉得很巧。
很多应用会在用户点击发送的那一刻立即建会话。
LMRing 则更谨慎:如果是新会话,它会等到首个 chunk 到来后,再触发 conversation 创建和消息持久化。
这样做的好处是:
- 减少"空会话"或失败会话残留
- 让数据落库更贴近真正开始生成的时刻
- 失败请求不会污染历史记录
这就是一个非常典型的"为了真实使用体验而做的架构细节"。
第四层:数据怎么落库,为什么能支持历史、投票和分享?
如果想让模型对比不只是即时体验,而是能长期沉淀,就必须把数据结构设计好。
LMRing 的数据库拆分得很清楚,核心几张表基本能看出产品设计思路:
1. conversations
保存会话主记录,对应一个完整对话线程。
2. messages
保存每一轮用户或系统消息,包括用户上传的附件信息。
3. model_responses
这张表很关键。
它不是把所有模型回答塞进一条消息里,而是为每个模型单独保存一条 response,包含:
modelNameproviderNameresponseContentattachmentstokensUsedresponseTimeMsdisplayPosition
这意味着每个模型输出天然是"可独立管理、可独立统计"的。
4. comparison_votes 和 comparison_vote_results
投票不是简单记一个"我喜欢 A"。
LMRing 会先记一条 vote 主记录,再把每个参与模型的结果分开记录成:
winnerlosertieall_bad
这让后续统计非常灵活。
因为系统不仅知道"谁赢了",还知道"参与者是谁""其他人输没输""是不是平局""是不是全不行"。
5. model_comparison_stats
投票结果不会只停留在明细层。
系统还会把比较结果汇总成统计表,保存:
- 总比较次数
- wins
- losses
- ties
- allBadCount
- winRate
- eloRating
这说明 LMRing 不是把"投票"当一个装饰按钮,而是真把它设计成排行榜和长期统计的基础。
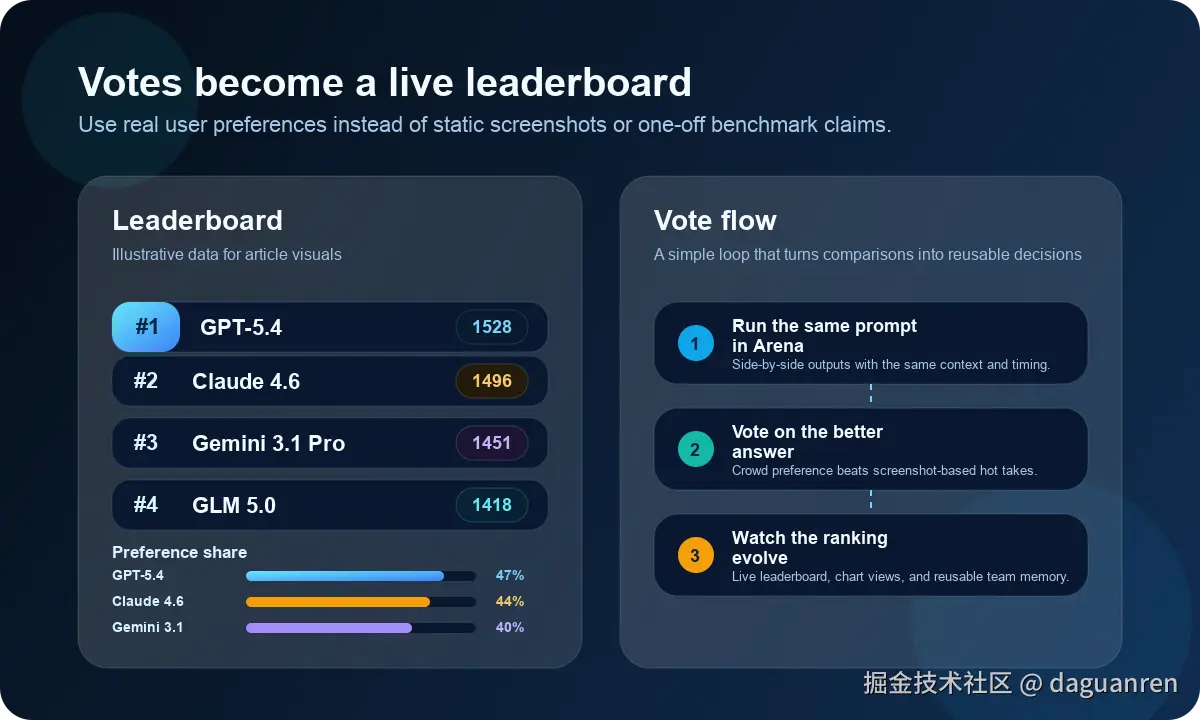
投票之后,排行榜是怎么做出来的?
LMRing 的排行榜不是单一来源。
它本质上有两种数据视角:
1. 平台内真实使用投票数据
这是前面说的本地比较结果。
它代表的是你和你的用户在真实 Prompt 下的偏好。
这部分适合回答:
- 在我自己的使用场景里,哪个模型更稳?
- 团队内部实际更喜欢哪个模型?
- 某类任务里谁更常赢?
2. 外部评测聚合数据
Leaderboard 页面同时接了 ZeroEval 的外部评测数据,并且通过自己的 API route 做了一层代理:
/api/zeroeval/arena-scores/api/zeroeval/magia/leaderboard
这层代理不是多余的,它解决了几个问题:
- 前端不直接暴露外部 API 细节
- 可以统一参数格式
- 可以做缓存控制
- 后续替换上游或聚合多源数据更方便
页面层则基于分类配置,把不同能力的评测结果组织起来,例如:
- chat arena
- code arena
- image generation
- video generation
- text-to-speech
- speech-to-text
这样 Leaderboard 就不只是"一个表",而是一个可以切维度、切图表视图、按指标排序的评测面板。
为什么这套架构适合继续扩展到图片、视频和 WebDev?
因为 LMRing 从一开始就不是按"聊天页面"做的,而是按"工作流系统"做的。
这一点从几个地方能看出来。
1. 输入输出是按能力类型建模的
在校验层里,文本消息、图片附件、响应附件都有独立 schema。
工作流请求也支持 attachments,而不是把多模态内容硬塞进纯文本字段里。
2. 视频能力是独立 runtime
项目里还有一个独立的 video-runtime 包,用来封装多 Provider 视频生成能力。
这不是在聊天逻辑里硬扩出来的,而是单独抽成了 runtime 层。
这意味着:
- 文本 workflow 和视频 workflow 可以共用一套产品结构
- Provider 差异可以在 runtime 里吸收
- 前端只需要消费统一的视频事件
3. WebDev 能力也是单独 session 化
数据库里还有 webdev_sessions、webdev_responses、webdev_iterations 这类表。
这说明项目已经在往"多任务形态"扩展,而不是只围绕 chat 做增强。
也就是说,LMRing 的真正方向并不是"把聊天做花",而是把各种 AI 生成任务都纳入一个统一竞技场。
自部署为什么重要?
很多人第一次看 LMRing,可能会觉得它只是一个"多模型对比 UI"。
但对开发者和团队来说,自部署能力往往比 UI 更重要。
因为一旦进入真实业务场景,你会很在意这些问题:
- API Key 谁来保管
- 用户对话能不能落自己的库
- 图片和视频附件放哪里
- 能不能接内部代理网关
- 能不能加自定义模型
- 能不能把排行榜和投票只用于团队内部
LMRing 在这些点上其实都给了比较明确的扩展空间:
- API Key 走数据库存储和解密
- Proxy URL 支持用户自定义
- 文件附件有独立文件表和存储服务
- Conversation / Message / Response / Vote 都是明确分表
- 自定义模型、模型覆盖和能力声明都能配置
这意味着它不是只能做"公开演示站",也适合往团队内部评测工具演进。
这对个人开发者和团队分别意味着什么?
对个人开发者
你能得到的是一个真正可复用的模型实验台,而不是临时截图工具。
你可以:
- 用自己的高频 Prompt 长期测试模型
- 比较代码、文案、多模态任务效果
- 保存结果、回看历史、分享给别人
- 逐步沉淀自己的模型使用方法论
对团队
你得到的更像一套 AI 选型基础设施。
你可以:
- 接多个模型服务商
- 统一入口比较输出
- 用真实任务做内部评测
- 用投票沉淀团队偏好
- 把对话、结果、投票都留在自己的环境里
当模型越来越多、版本越来越快时,这种"基础设施化能力"会比单次热榜更有长期价值。
为什么我觉得这类产品接下来会越来越重要?
因为未来大家讨论模型,不会再只围绕一句"谁最强"。
真正重要的是:
- 谁更适合你的业务
- 谁在你的任务集里更稳定
- 谁在你们团队内部真实更受欢迎
- 谁在成本和效果之间更平衡
这类问题不能靠别人替你回答。
你需要的是一个能自己验证、自己沉淀、自己扩展的平台。
LMRing 想做的,正是这件事。
它不是想宣布某个模型永远第一,而是想让你拥有自己建立判断的能力。
最后
大模型圈最不缺的,就是"谁最强"的标题。
今天是 GPT-5.4,
明天可能是 Claude 4.6,
后天也许又轮到 Gemini 3.1 Pro 或 GLM 5.0。
热点会一直变,版本会一直更,榜单也会一直刷新。
但有一件事不会变:
你永远不能把自己的模型判断,长期外包给别人。
因为别人测的是别人的任务,
别人的提示词,
别人的标准,
别人的业务场景。
真正对你有意义的,只能是你自己跑出来的结果。
这也是我觉得 LMRing 值得做、也值得被更多开发者看到的原因。
它不是在制造又一个"热闹排行榜",
而是在尝试把一件原本很主观、很碎片化、很容易被营销裹挟的事情,重新做成一个可验证、可复盘、可沉淀、可协作的系统。
如果你只是想随手玩一下多模型对比,它可以是一个很好用的 Arena。
如果你是认真做 AI 产品的开发者,它也可以继续长成你的模型评测工作台。
如果你在团队里负责选型,它甚至可以成为一套内部的 AI 评估基础设施。
所以,与其继续刷"某某模型登顶"的帖子,
不如换一种方式:
把你真正关心的问题丢进去,
同时跑几个模型,
看输出、看推理、看投票、看排行,
然后用你自己的结果做决定。
这可能比看一百篇"年度最强模型榜"都更有用。
- GitHub:
https://github.com/llm-ring/lmring - 在线体验:
https://www.lmring.com/
如果你也在做 AI 应用,或者正在纠结团队该接哪家模型,欢迎来试试。
下一次再看到"谁第一"的标题时,你至少可以先说一句:
别吵,先跑。