在数字化转型浪潮中,企业CRM系统已从单一客户管理工具升级为驱动业务增长的核心引擎,其架构设计直接决定了系统的可扩展性、稳定性与迭代效率。传统单体CRM架构存在耦合度高、扩展困难、故障影响范围广等痛点,难以适配企业规模化发展与业务快速迭代的需求。基于此,宏天技术结合多年企业级系统研发经验,采用微服务架构模式,依托Spring Cloud生态,设计并实现了一套高可用、高可扩展的企业CRM系统。本文将详细拆解该CRM系统的微服务设计实践,涵盖整体架构设计、服务拆分方案、数据一致性保障,并提供架构图与核心代码示例,为企业CRM架构升级提供可落地的参考方案,助力开发者快速掌握CRM架构与微服务结合的核心要点。

一、CRM系统整体架构设计(基于Spring Cloud生态)
本次宏天技术设计的企业CRM微服务架构,严格遵循"分层解耦、高内聚低耦合"原则,基于Spring Cloud生态组件构建,整体分为五层架构,从下至上依次为基础设施层、数据层、微服务层、网关层、应用层,各层职责清晰、协同联动,既保证了系统的稳定性,又提升了开发与运维效率,完美契合微服务架构的核心优势。
1.1 架构整体概览
架构设计核心目标:解决单体CRM系统的扩展性瓶颈,实现业务模块独立迭代、故障隔离,同时保障数据安全与系统高可用,支撑企业从几十人到上万人的规模扩张。整体架构图如下(宏天技术实际落地版本):
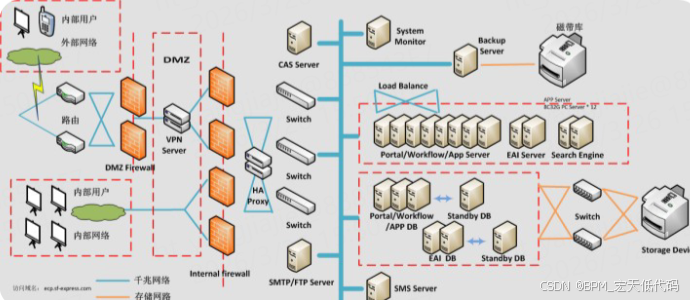
应用层:PC端管理后台、移动端APP、第三方系统对接接口(如ERP、OA系统); 网关层:Spring Cloud Gateway(路由转发、鉴权、限流、日志收集); 微服务层:核心业务微服务(客户服务、销售服务等)、公共服务(认证授权、消息通知等); 数据层:MySQL(主从架构)、Redis(缓存)、Elasticsearch(全文检索)、Kafka(消息队列); 基础设施层:Docker容器化部署、K8s编排、Nacos服务注册与配置中心、SkyWalking链路追踪。
1.2 核心架构组件选型(Spring Cloud生态)
结合企业CRM业务特性(高频查询、多模块联动、数据安全性要求高),核心组件选型均基于Spring Cloud生态,兼顾成熟度与实用性,具体如下:
-
服务注册与配置中心:Nacos,替代传统Eureka,同时实现服务注册发现与配置集中管理,支持动态配置更新,适配微服务架构下的灵活部署需求,是CRM微服务架构的核心支撑组件之一。
-
网关组件:Spring Cloud Gateway,非阻塞式网关,负责请求路由、鉴权、限流、跨域处理,作为CRM系统的统一入口,隔离外部请求与内部微服务,提升系统安全性与可维护性。
-
服务通信:OpenFeign,声明式REST客户端,简化微服务间的调用流程,结合Spring Cloud LoadBalancer实现客户端负载均衡,保障CRM各服务间通信的高效与稳定。
-
熔断与降级:Sentinel,处理微服务调用异常,防止服务雪崩,例如当销售服务异常时,熔断该服务调用,避免影响客户管理等核心模块,保障CRM系统核心功能可用。
-
分布式事务:Seata,解决微服务间数据一致性问题,适配CRM系统中跨服务操作(如客户创建与销售线索关联)的事务需求。
-
数据存储:MySQL(主从复制,实现读写分离)存储核心业务数据,Redis缓存高频访问数据(如客户基础信息),Elasticsearch实现客户信息、销售记录的全文检索,提升查询效率。
该选型方案既保证了微服务架构的灵活性,又依托Spring Cloud生态的成熟性,降低了系统开发与运维成本,是企业CRM架构微服务转型的最优实践之一。
二、CRM系统微服务拆分方案(核心实践)
微服务拆分是CRM架构设计的核心,直接决定了系统的耦合度与可扩展性。宏天技术采用"领域驱动设计(DDD)"思想,以CRM业务领域为核心,结合"单一职责"原则,将传统单体CRM系统拆分为10个核心微服务,拆分后各服务独立部署、独立迭代,互不影响,同时通过服务间通信实现业务联动,既满足了微服务架构的设计要求,又贴合CRM业务实际场景。
2.1 拆分原则
- 业务领域拆分:以CRM核心业务领域为边界,拆分出客户管理、销售管理、营销管理等独立服务,每个服务聚焦一个核心业务场景,实现高内聚; 2. 单一职责原则:每个微服务仅负责一项核心业务,避免跨领域职责叠加,降低服务耦合度,便于后期维护与迭代; 3. 数据自治原则:每个微服务拥有独立的数据库(或数据 schema),避免跨服务数据共享,减少服务间依赖,同时提升数据安全性; 4. 可扩展性原则:拆分后的服务支持独立扩容,例如销售旺季时,可单独扩容销售服务,无需影响整个CRM系统,适配业务波动需求。
2.2 核心微服务拆分详情
结合企业CRM实际业务场景,核心微服务拆分如下(附核心职责),完美适配微服务架构的解耦需求,同时保障CRM业务的完整性:
| 微服务名称 | 核心职责 | 依赖服务 |
|---|---|---|
| 客户服务(customer-service) | 客户信息新增、编辑、查询、删除,客户标签管理、客户分组管理,是CRM架构的核心业务服务之一 | 认证服务、消息服务 |
| 销售服务(sales-service) | 销售线索管理、跟进记录、商机管理、合同管理,支撑销售全流程管控 | 客户服务、认证服务、支付服务 |
| 营销服务(marketing-service) | 营销活动创建、推广、数据统计,客户精准营销,提升客户转化率 | 客户服务、消息服务 |
| 客服服务(service-service) | 客户咨询、投诉处理、服务工单管理,提升客户满意度 | 客户服务、消息服务 |
| 认证服务(auth-service) | 用户登录、权限管理、Token生成与校验,保障CRM系统安全 | 无(基础公共服务) |
| 消息服务(message-service) | 短信、邮件、站内信发送,支撑各服务的消息通知需求 | 无(基础公共服务) |
| 数据统计服务(statistics-service) | CRM核心数据统计(客户数量、销售业绩、营销效果),生成统计报表 | 客户服务、销售服务、营销服务 |
| 文件服务(file-service) | 客户附件、合同文件、营销素材的上传、下载、存储管理 | 无(基础公共服务) |
| 支付服务(payment-service) | 合同付款、费用结算管理,对接第三方支付接口 | 销售服务、认证服务 |
| 第三方对接服务(api-service) | 对接ERP、OA等第三方系统,实现数据同步与业务联动 | 客户服务、销售服务 |
2.3 拆分核心优势
- 降低耦合度:各服务独立开发、测试、部署,修改某一服务(如营销服务)不会影响其他核心服务(如客户服务),减少故障传导; 2. 提升迭代效率:不同团队可同时开发不同服务,例如销售团队负责销售服务迭代,客服团队负责客服服务优化,大幅缩短开发周期; 3. 灵活扩容:针对高频访问服务(如客户服务、销售服务),可单独扩容实例,无需扩容整个系统,降低服务器资源成本; 4. 便于维护:服务职责清晰,问题定位精准,例如客户信息查询异常,可直接定位到客户服务,无需排查整个CRM系统。
三、CRM微服务架构的数据一致性保障
微服务拆分后,各服务拥有独立的数据存储,跨服务操作(如"创建客户并关联销售线索")容易出现数据不一致问题,这是CRM微服务架构设计的核心难点。宏天技术结合CRM业务特性(部分场景需强一致性,部分场景可接受最终一致性),采用"分层保障"策略,基于Seata、Kafka等组件,实现数据一致性,既保障了核心业务的数据准确性,又兼顾了系统性能,完美解决微服务架构下的数据一致性痛点。
3.1 核心一致性场景分析
CRM系统中,数据一致性场景主要分为两类,不同场景采用不同的保障方案,贴合业务实际需求:
-
强一致性场景:客户信息创建与认证信息同步、合同创建与付款记录关联,此类场景要求操作要么全部成功,要么全部失败,否则会导致业务异常(如客户创建成功但认证信息未同步,导致无法登录);
-
最终一致性场景:客户标签更新与统计数据同步、营销活动结束与客户积分更新,此类场景可接受短暂的数据不一致,最终通过异步机制实现数据同步即可。
3.2 具体保障方案(附代码示例)
结合上述场景,宏天技术采用"Seata分布式事务 + Kafka异步消息"的组合方案,实现数据一致性保障,以下是核心实现方案与代码示例(基于Spring Cloud + Seata):
方案1:强一致性场景------Seata AT模式
针对强一致性场景,采用Seata AT模式,基于"两阶段提交"思想,实现跨服务事务一致性,无需手动编写补偿逻辑,降低开发成本。以下是"创建客户并关联销售线索"的核心代码示例:
java
// 1. 客户服务(customer-service)核心接口
@Service
public class CustomerServiceImpl implements CustomerService {
@Autowired
private CustomerMapper customerMapper;
@Autowired
private SalesFeignClient salesFeignClient; // 调用销售服务的Feign客户端
@Autowired
private GlobalTransactionScanner globalTransactionScanner;
// 分布式事务注解,标记该方法为全局事务
@GlobalTransactional(rollbackFor = Exception.class)
@Override
public Boolean createCustomerAndLinkSales(CustomerDTO customerDTO, SalesLeadDTO salesLeadDTO) {
// 第一步:本地事务------创建客户
Customer customer = new Customer();
BeanUtils.copyProperties(customerDTO, customer);
customerMapper.insert(customer);
// 第二步:远程调用销售服务,创建销售线索并关联客户ID
salesLeadDTO.setCustomerId(customer.getId());
Boolean result = salesFeignClient.createSalesLead(salesLeadDTO);
if (!result) {
throw new RuntimeException("销售线索创建失败,触发全局回滚");
}
return true;
}
}
// 2. 销售服务(sales-service)核心接口
@Service
public class SalesLeadServiceImpl implements SalesLeadService {
@Autowired
private SalesLeadMapper salesLeadMapper;
@Override
public Boolean createSalesLead(SalesLeadDTO salesLeadDTO) {
SalesLead salesLead = new SalesLead();
BeanUtils.copyProperties(salesLeadDTO, salesLead);
salesLeadMapper.insert(salesLead);
return true;
}
}
// 3. Feign客户端配置(customer-service中)
@FeignClient(name = "sales-service", fallback = SalesFeignFallback.class)
public interface SalesFeignClient {
@PostMapping("/sales/lead/create")
Boolean createSalesLead(@RequestBody SalesLeadDTO salesLeadDTO);
}核心说明:通过@GlobalTransactional注解标记全局事务,当销售服务调用失败时,Seata会自动回滚客户服务的本地事务,确保客户创建与销售线索关联的数据一致性,适配CRM核心业务的强一致性需求。
方案2:最终一致性场景------Kafka异步消息+重试机制
针对最终一致性场景,采用"本地事务 + Kafka异步消息 + 重试机制",实现数据最终同步,避免分布式事务带来的性能损耗。以下是"客户标签更新与统计数据同步"的核心代码示例:
java
// 1. 客户服务(customer-service)发送消息
@Service
public class CustomerTagServiceImpl implements CustomerTagService {
@Autowired
private CustomerTagMapper customerTagMapper;
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@Autowired
private ObjectMapper objectMapper;
// 本地事务:更新客户标签,并发送消息
@Transactional(rollbackFor = Exception.class)
@Override
public Boolean updateCustomerTag(Long customerId, List<String> tags) {
// 第一步:本地事务------更新客户标签
CustomerTag customerTag = customerTagMapper.selectByCustomerId(customerId);
if (customerTag == null) {
customerTag = new CustomerTag();
customerTag.setCustomerId(customerId);
customerTag.setTags(JSON.toJSONString(tags));
customerTagMapper.insert(customerTag);
} else {
customerTag.setTags(JSON.toJSONString(tags));
customerTagMapper.updateById(customerTag);
}
// 第二步:发送Kafka消息,通知统计服务同步数据
try {
CustomerTagMessage message = new CustomerTagMessage();
message.setCustomerId(customerId);
message.setTags(tags);
message.setUpdateTime(LocalDateTime.now());
// 发送消息到指定主题
kafkaTemplate.send("customer-tag-update-topic", objectMapper.writeValueAsString(message));
} catch (Exception e) {
// 消息发送失败,记录日志,后续通过定时任务重试
log.error("客户标签更新消息发送失败,customerId:{}", customerId, e);
// 写入消息重试表,定时任务重试
messageRetryMapper.insert(new MessageRetry("customer-tag-update-topic", objectMapper.writeValueAsString(message)));
}
return true;
}
}
// 2. 统计服务(statistics-service)消费消息
@Component
public class CustomerTagMessageConsumer {
@Autowired
private StatisticsMapper statisticsMapper;
@Autowired
private ObjectMapper objectMapper;
@KafkaListener(topics = "customer-tag-update-topic", groupId = "statistics-group")
public void consumeMessage(String message) {
try {
CustomerTagMessage tagMessage = objectMapper.readValue(message, CustomerTagMessage.class);
// 同步客户标签统计数据
statisticsMapper.updateCustomerTagCount(tagMessage.getTags());
} catch (Exception e) {
log.error("消费客户标签更新消息失败,消息内容:{}", message, e);
// 触发重试(可配置Kafka重试机制,或写入重试表)
throw new RuntimeException("消息消费失败,触发重试", e);
}
}
}核心说明:客户标签更新完成后,通过Kafka发送异步消息,统计服务消费消息并同步数据;若消息发送或消费失败,通过重试机制确保数据最终同步,既保证了数据一致性,又避免了分布式事务的性能开销,适配CRM非核心业务的最终一致性需求。
3.3 额外保障措施
- 幂等性设计:所有跨服务接口均实现幂等性(如通过唯一ID标识请求),避免重复调用导致的数据重复; 2. 定时任务校验:针对异步消息同步场景,增加定时任务,定期校验数据一致性,发现不一致时自动修复; 3. 日志与监控:通过SkyWalking链路追踪、ELK日志聚合,实时监控跨服务操作与数据同步情况,快速定位数据不一致问题。
四、架构落地注意事项与优化建议
宏天技术在CRM微服务架构落地过程中,积累了大量实践经验,针对企业CRM系统的特性,总结以下注意事项与优化建议,助力开发者规避常见坑,提升CRM架构的稳定性与可扩展性,更好地发挥微服务与Spring Cloud生态的优势:
-
服务拆分不宜过细:拆分过细会导致服务间调用频繁,增加系统复杂度与网络开销,建议以"业务领域"为单位拆分,确保每个服务具备完整的业务能力,这是CRM微服务架构落地的关键。
-
重视服务治理:微服务数量增多后,需加强服务注册、配置管理、熔断降级、链路追踪,建议采用Nacos + Sentinel + SkyWalking的组合,实现服务全生命周期管理,保障CRM系统稳定运行。
-
数据缓存优化:CRM系统高频查询场景多(如客户信息查询、销售线索查询),建议合理使用Redis缓存,设置合理的缓存过期时间,避免缓存雪崩、缓存穿透,提升查询性能,同时减轻数据库压力。
-
数据库优化:采用MySQL主从复制实现读写分离,核心业务表(如客户表、合同表)建立合理索引;当数据量较大时,采用分库分表策略(如Sharding-JDBC),避免单一数据库成为性能瓶颈,支撑CRM系统的规模化发展。
-
容器化部署:采用Docker + K8s实现微服务容器化部署,实现服务的弹性扩容、故障自愈,降低运维成本,适配企业业务的波动需求,这是微服务架构落地的重要保障。
五、总结
本文详细介绍了宏天技术企业CRM系统的微服务设计实践,围绕整体架构设计、服务拆分方案、数据一致性保障三大核心内容,结合架构图描述与Spring Cloud相关核心代码示例,完整呈现了CRM微服务架构的落地思路。相较于传统单体CRM架构,基于微服务与Spring Cloud生态的CRM架构,具备可扩展性强、故障隔离、迭代高效等优势,能够有效适配企业规模化发展与业务快速迭代的需求。
在实际落地过程中,需结合企业自身业务场景,灵活调整服务拆分方案与数据一致性保障策略,重视服务治理与性能优化,才能充分发挥微服务架构的价值。宏天技术的CRM微服务设计实践,已在多家企业落地应用,验证了该架构的可行性与实用性,希望本文能为企业CRM架构升级、开发者进行微服务实践提供有价值的参考,助力更多企业实现CRM系统的数字化转型。