一、虚拟机环境准备
|-----------|----------------------------|--------------------------------|------------|
| 主机节点(VM机) | HDFS集群角色 | YARN集群角色 | 硬件资源 |
| node01 | namenode 、datanode | resourcemananger、 nodemananger | 3G内存+40G磁盘 |
| node02 | secondarynamenode datanode | nodemanager | 3G内存+40G磁盘 |
| node03 | datanode | nodemanger | 3G内存+40G磁盘 |
三台虚拟机分别配置主机名为node01 、node02、node03,关闭防火墙、配置三者相互ssh免密登录,三台主机上分别安装JDK8 。注: hadoop3.x 版本在JDK11、17存在不兼容的问题,最好安装JDK8
二、Hadoop的安装配置
创建/export/server目录,作为我们服务的安装目录。
上传安装包到/export/server目录
tar -zxvf hadoop-3.3.6.tar.gz
cd /export/server/hadoop-3.3.6/etc/hadoop
修改配置文件
hadoop-env.sh,环境变量配置
bash
export JAVA_HOME=/usr/local/java/jdk1.8.0_251
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=rootcore-site.xml配置
XML
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.3.6</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>hdfs-site.xml配置
XML
<configuration>
<!-- 指定secondarynamenode运行位置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node02:50090</value>
</property>
</configuration>yarn-site.xml配置
XML
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定YARN的主角色(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 真实生产环境可去掉 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制 真实生产环境可去掉 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node01:19888/jobhistory/logs</value>
</property>
<!-- 保存的时间7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>mapred-site.xml 配置
XML
<configuration>
<!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node01:10020</value>
</property>
<!-- MR程序历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node01:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
~ workers配置
bash
node01
node02
node03三、安装目录分发到其他两个节点
scp -r hadoop-3.3.6 node02:/export/server
scp -r hadoop-3.3.6 node03:/export/server
分别配置3个主机的/etc/profiles文件,或者配置一台进行分发
bash
export HADOOP_HOME=/export/server/hadoop-3.3.6
export JAVA_HOME=/usr/local/java/jdk1.8.0_251
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH四、namenode初始化(集群执行一次即可)
在node01节点上执行
hdfs namenode -format
五、启动Hadoop集群(HDFS 、YARN)
HDFS集群
#hadoop2.x 命令
hadoop-daemon.sh start|stop namenode、datanode、 secondarynamenode
#hadoop3.x 命令
hdfs --daemon start|stop namenode、datanode、 secondarynamenode
YARN集群
#hadoop2.x 命令
yarn-daemon.sh start|stop resourcemanager、nodemanager
#hadoop3.x 命令
yarn --daemon start|stop resourcemanager、nodemanager
一键启动命令
start-dfs.sh #一键启动所有的hdfs节点
stop-dfs.sh #一键启动所有yarn节点
start-all.sh # 启动所有hdfs、yarn节点
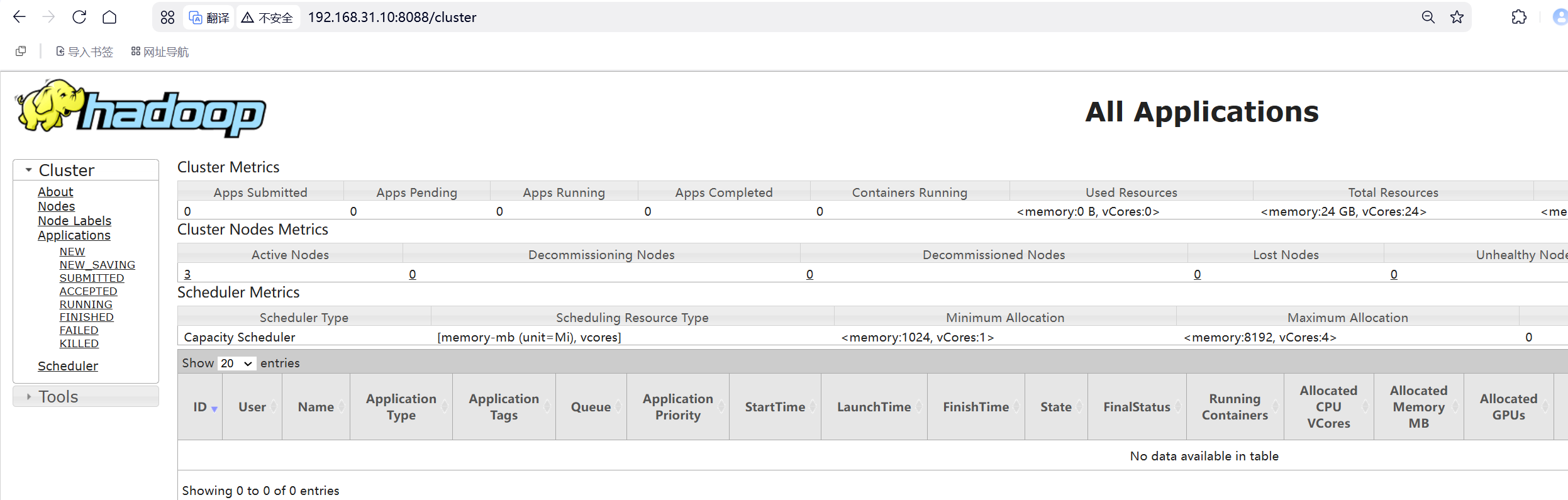
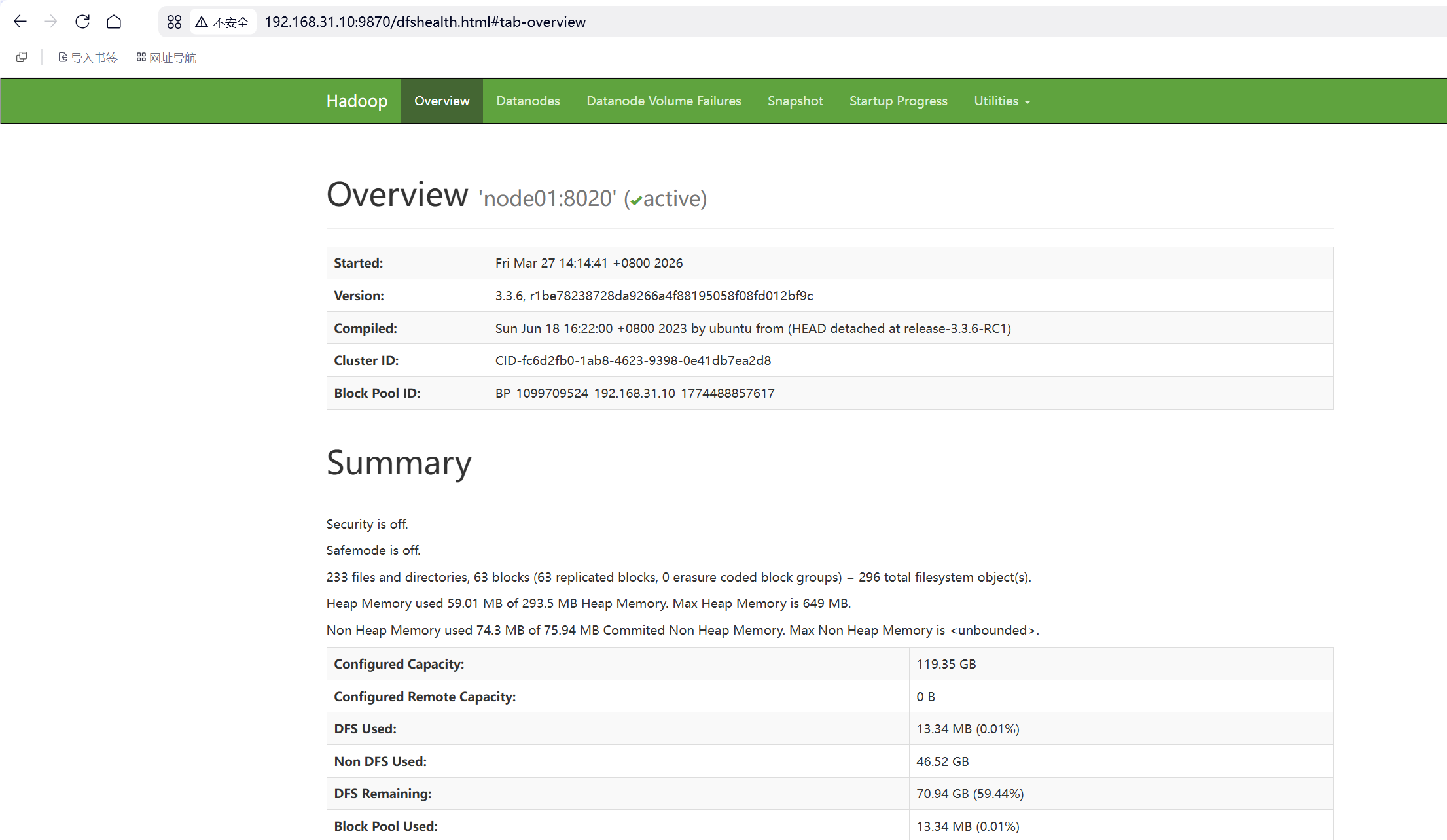
六、WEB UI页面
http://node01:9870 HDFS集群
http://node01:8088 YARN集群