适用场景:企业私有化部署、离线推理环境、GPU 服务器模型服务化
硬件环境:CentOS-7 / E5-2680V4 (14核28线程) / DDR4 32G×2 / Tesla V100-32G (PG503 水冷)
软件环境:NVIDIA Driver 535 / CUDA 12.2 / Docker (with NVIDIA Container Toolkit)
一、环境准备与容器启动
1.1 前置检查清单
在启动容器前,请确认宿主机已满足以下条件:
| 检查项 | 命令 | 预期结果 |
|---|---|---|
| NVIDIA 驱动 | nvidia-smi |
显示 V100 信息,Driver Version: 535.x |
| Docker 版本 | docker --version |
≥ 20.10 |
| NVIDIA Container Toolkit | docker run --rm --gpus all nvidia/cuda:12.2.0-base-ubuntu22.04 nvidia-smi |
正常输出 GPU 信息 |
| 模型目录挂载 | ls /models/GGUF_LIST/ |
已放置 GGUF 模型文件 |
1.2 启动 Docker 容器
bash
docker run -itd --name local_ai_api --gpus all -p 35922:22 -p 35901:5901 -p 36080:6080 -p 38888:8888 -p 6006:6006 -v /models:/models -v /docker_share:/docker_share --shm-size=2g --restart=unless-stopped cuda-server-ssh参数详解:
| 参数 | 说明 |
|---|---|
--name local_ai_api |
容器命名,便于后续管理 |
--gpus all |
暴露所有 GPU 给容器,V100 的显存可被 llama.cpp 调用 |
-p 35922:22 |
SSH 端口映射(宿主机 35922 → 容器 22) |
-p 35901:5901 |
VNC 远程桌面端口 |
-p 36080:6080 |
可选 Web 服务端口 |
-p 38888:8888 |
Jupyter Notebook 端口 |
-p 6006:6006 |
llama-server 服务端口,模型推理 API 入口 |
-v /models:/models |
模型文件持久化挂载,避免容器重建后数据丢失 |
-v /docker_share:/docker_share |
共享目录,用于日志、配置、临时文件交换 |
--shm-size=2g |
共享内存大小,多线程推理时避免 bus error |
--restart=unless-stopped |
宿主机重启后自动拉起容器 |
cuda-server-ssh |
基于 CUDA 镜像构建的自定义镜像(含 SSH、基础工具链) |
提示 :若宿主机防火墙开启,需放行
6006端口供外部调用推理 API。
1.3 进入容器
bash
docker exec -it local_ai_api /bin/bash二、容器内构建工具链安装
进入容器后,首先安装编译 llama.cpp 所需的依赖:
bash
apt update && apt install -y build-essential cmake git curl wget pkg-config| 包名 | 用途 |
|---|---|
build-essential |
GCC/G++ 编译器、make 工具 |
cmake |
跨平台构建系统,生成 Makefile |
git |
拉取 llama.cpp 源码 |
curl / wget |
下载模型、依赖 |
pkg-config |
库文件路径管理 |
三、llama.cpp 源码编译(CUDA 加速版)
3.1 进入源码目录
假设已将 llama.cpp 源码放置于 /opt/ai-runner/llama-server/llama.cpp-b8971/:
bash
cd /opt/ai-runner/llama-server/llama.cpp-b8971/3.2 清理并创建构建目录
bash
rm -rf build && mkdir build && cd build建议 :每次重新编译前清理
build目录,避免 CMake 缓存导致配置错误。
3.3 CMake 配置(V100 专用优化参数)
bash
cmake .. -DGGML_CUDA=ON -DGGML_AVX=ON -DGGML_AVX2=ON -DGGML_F16C=ON -DGGML_FMA=ON -DGGML_CUDA_ARCH="70" -DCMAKE_C_COMPILER=gcc -DCMAKE_CXX_COMPILER=g++ -DCMAKE_CUDA_COMPILER=/usr/local/cuda-12.1/bin/nvcc参数深度解析:
| 参数 | 值 | 说明 |
|---|---|---|
-DGGML_CUDA=ON |
开启 | 核心参数:启用 NVIDIA GPU 加速推理 |
-DGGML_AVX=ON |
开启 | 启用 AVX 指令集,加速 CPU 回退计算 |
-DGGML_AVX2=ON |
开启 | 启用 AVX2 指令集,E5-2680V4 支持 |
-DGGML_F16C=ON |
开启 | 支持 FP16 转换指令,减少显存占用 |
-DGGML_FMA=ON |
开启 | fused multiply-add,提升矩阵运算效率 |
-DGGML_CUDA_ARCH="70" |
70 | V100 计算能力 (Compute Capability),必须精确匹配 |
-DCMAKE_C_COMPILER=gcc |
gcc | 指定 C 编译器 |
-DCMAKE_CXX_COMPILER=g++ |
g++ | 指定 C++ 编译器 |
-DCMAKE_CUDA_COMPILER=... |
nvcc | 指定 CUDA 编译器路径 |
关于
GGML_CUDA_ARCH="70":Tesla V100 的 Compute Capability 为 7.0,对应架构代号
Volta。若填写错误(如填 80 对应 A100),编译虽可通过,但运行时会出现CUDA error: no kernel image is available错误。
3.4 设置 HuggingFace 镜像(国内网络加速)
bash
export HF_ENDPOINT=https://hf-mirror.com此环境变量用于后续通过 llama.cpp 工具下载 tokenizer、聊天模板等资源时走国内镜像。
3.5 执行编译
bash
cmake --build . --config Release -j $(nproc)| 参数 | 说明 |
|---|---|
--config Release |
发布模式编译,启用 -O3 优化,去除调试符号 |
-j $(nproc) |
并行编译,使用全部 28 线程,大幅缩短编译时间 |
编译耗时参考:
- 首次全量编译:约 5-10 分钟(28 线程)
- 增量编译:约 30 秒 - 2 分钟
编译产物检查:
bash
ls -lh bin/llama-server
# 预期输出:bin/llama-server (可执行文件,约 50-100MB)四、Qwen3.6-27B 模型推理服务启动
4.1 进入构建产物目录
bash
cd /opt/ai-runner/llama-server/llama.cpp-b8971/build4.2 启动 llama-server(含 MTP 投机采样加速)
bash
./bin/llama-server -m /models/GGUF_LIST/Qwen3.6-27B-MTP-GGUF/Qwen3.6-27B-UD-Q4_K_XL.gguf --alias "Qwen3.6-27B-MTP" --host 0.0.0.0 --port 6006 --gpu-layers 999 --ctx-size 64000 --threads 28 --temp 0.7 --top-p 0.8 --top-k 20 --min-p 0.00 --chat-template-kwargs '{"enable_thinking": false}' --spec-type draft-mtp --spec-draft-n-max 3启动参数全景解析:
基础服务配置
| 参数 | 值 | 说明 |
|---|---|---|
-m |
/models/.../Qwen3.6-27B-UD-Q4_K_XL.gguf |
模型文件路径,UD-Q4_K_XL 为高质量 4-bit 量化 |
--alias |
Qwen3.6-27B-MTP |
API 中显示的模型名称,便于客户端识别 |
--host |
0.0.0.0 |
监听所有网络接口,支持容器外访问 |
--port |
6006 |
服务端口,与 Docker 映射的 6006 对应 |
GPU 与内存配置
| 参数 | 值 | 说明 |
|---|---|---|
--gpu-layers |
999 |
将所有模型层卸载到 GPU,V100 32G 显存可完整承载 Qwen3.6-27B Q4 量化版 |
--ctx-size |
64000 |
上下文窗口大小,64K 适合长文档分析、代码理解 |
采样参数(控制生成质量)
| 参数 | 值 | 说明 |
|---|---|---|
--temp |
0.7 |
温度系数,0.7 为平衡值,越低越确定,越高越创造性 |
--top-p |
0.8 |
核采样,从累积概率前 80% 的 token 中采样 |
--top-k |
20 |
限制候选 token 数量为前 20 个 |
--min-p |
0.00 |
最小概率阈值,0 表示不额外过滤 |
对话模板配置
| 参数 | 值 | 说明 |
|---|---|---|
--chat-template-kwargs |
'{"enable_thinking": false}' |
关闭 Qwen3 的思考模式,直接输出最终答案,减少 token 消耗 |
Qwen3 系列模型默认启用
<think>...</think>思考链,关闭后响应更直接,适合 API 场景。
MTP 投机采样加速(关键优化)
| 参数 | 值 | 说明 |
|---|---|---|
--spec-type |
draft-mtp |
启用 Multi-Token Prediction 投机采样 |
--spec-draft-n-max |
3 |
每次预测最多生成 3 个 draft token,由 MTP 模块验证 |
MTP (Multi-Token Prediction) 原理:
传统自回归: [token_1] → [token_2] → [token_3] → [token_4] (4 次前向传播)
MTP 投机采样: [token_1, token_2, token_3] → 验证 → 接受/回退 (1-2 次前向传播)MTP 模块预先预测后续多个 token,主模型并行验证,可提升 1.5x - 2.5x 吞吐,是 Qwen3 系列的核心加速特性。
五、服务验证与 API 调用
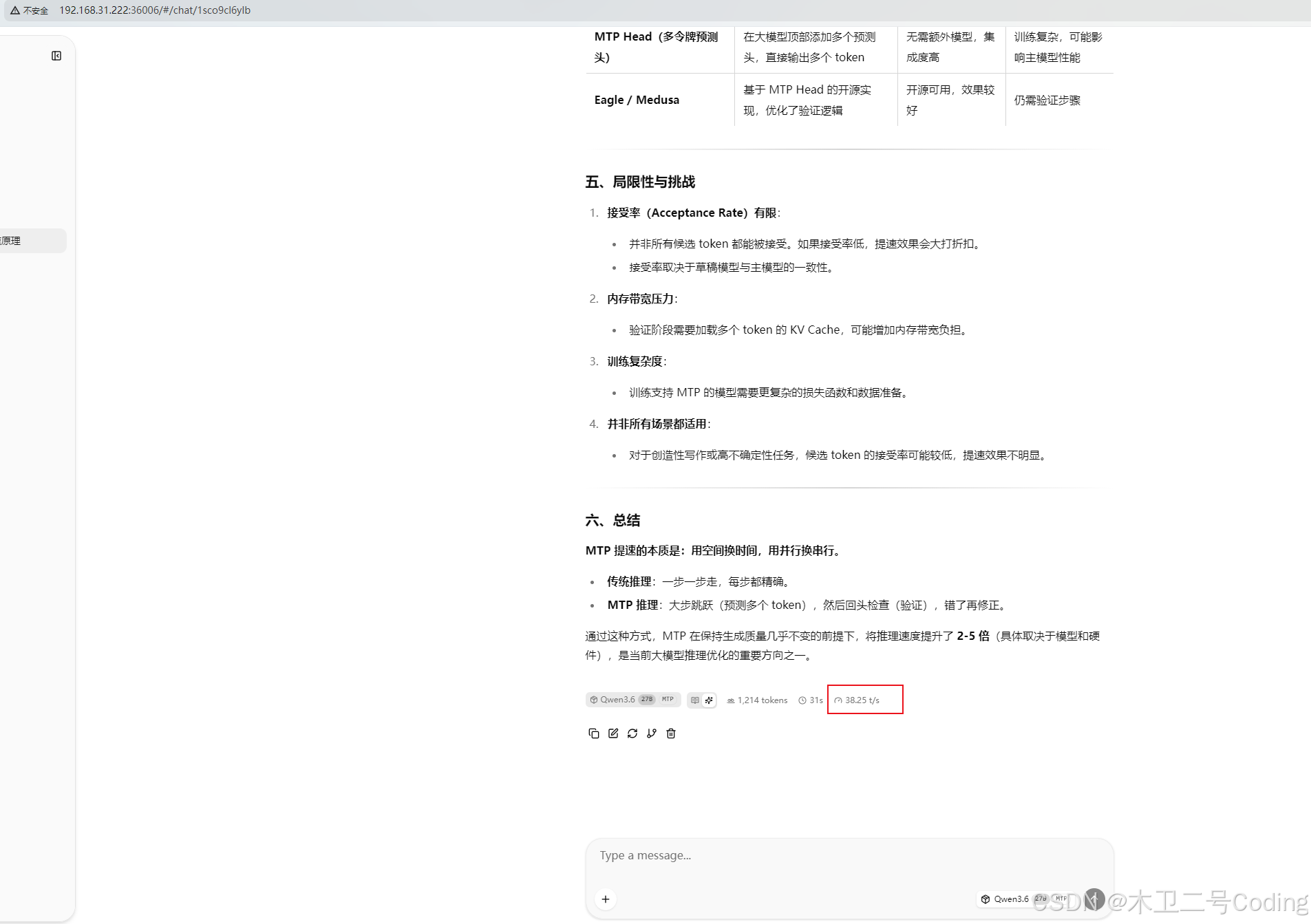
速度 38T/S 默认 29T/S,速度有提升(MTP可以哦)
六、总结
本文完整梳理了在 CentOS-7 + Tesla V100 环境下,通过 Docker 容器编译并运行 Qwen3.6-27B-MTP 大模型的全流程:
- 容器化部署 :通过
--gpus all暴露 GPU,端口映射实现服务化,数据卷挂载保证模型持久化 - 精准编译 :针对 V100 的
Compute Capability 7.0配置 CMake,启用 AVX2/FMA 等 CPU 指令集加速 - 模型优化:采用 UD-Q4_K_XL 量化平衡精度与显存,启用 MTP 投机采样提升 1.5x-2.5x 推理吞吐
- 生产适配:关闭思考模式适配 API 场景,64K 上下文支持长文档处理
该方案可直接应用于企业私有化知识库、智能客服、代码辅助等生产场景。