第1章 MapReduce 概述
1.1 MapReduce定义
MapReduce是一个分布式运算程序的编程框架,是用户开发"基于Hadoop的数据分析应用"的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
1 .2 MapReduce 优缺点
优点:MapReduce易于编程、良好的扩展性、高容错性、适合PB级以上海量数据的离线处理
缺点:不擅长实时计算、不擅长流式计算、不擅长DAG(有向无环图)计算
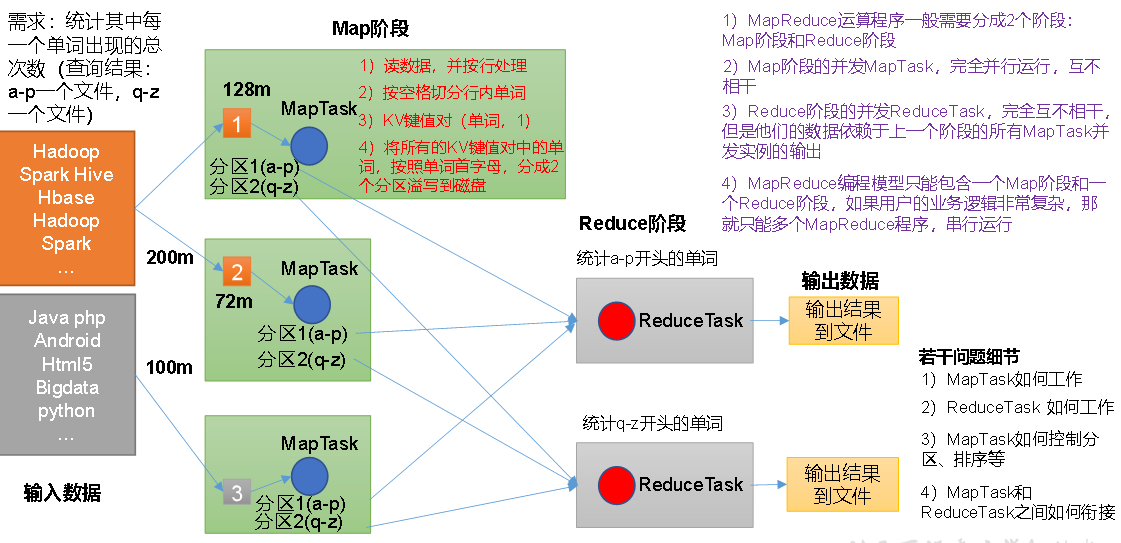
1. 3 M apReduce 核心 思想
第 2 章 Hadoop 序列化
序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输。
反序列化就是将收到字节序列(或其他数据传输协议)或者是磁盘的持久化数据,转换成内存中的对象。
第3章 MapReduce 框架原理
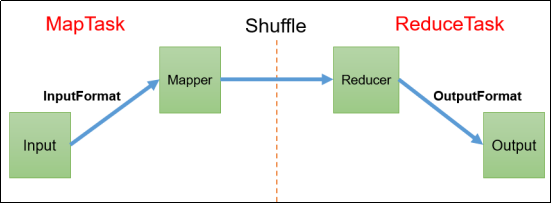
3. 1 InputForma t 数据输入
MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度。
数据块:Block是HDFS物理上把数据分成一块一块。数据块是HDFS存储数据单位。
数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。数据切片是MapReduce程序计算输入数据的单位,一个切片会对应启动一个MapTask。
切片机制
(1)简单地按照文件的内容长度进行切片
(2)切片大小,默认等于Block大小
(3)切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
3 .2 MapReduce 工作 流程
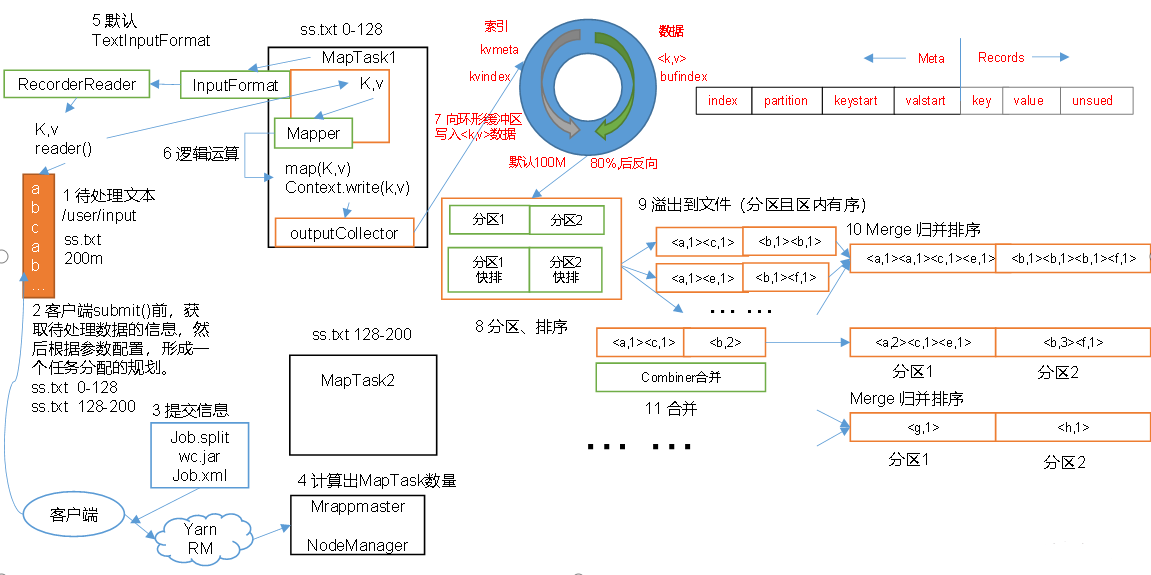
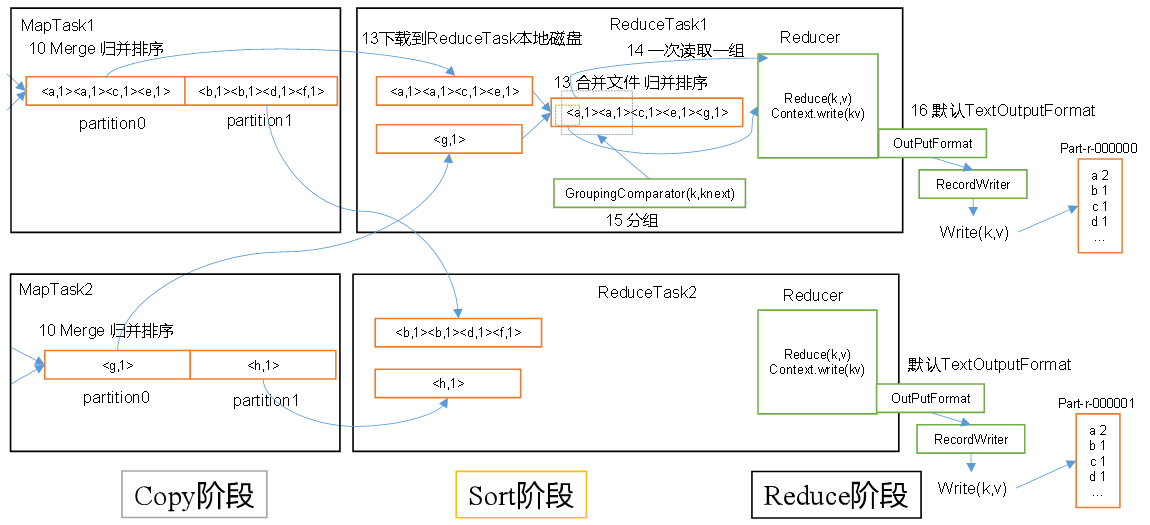
3. 3 S huffle机制
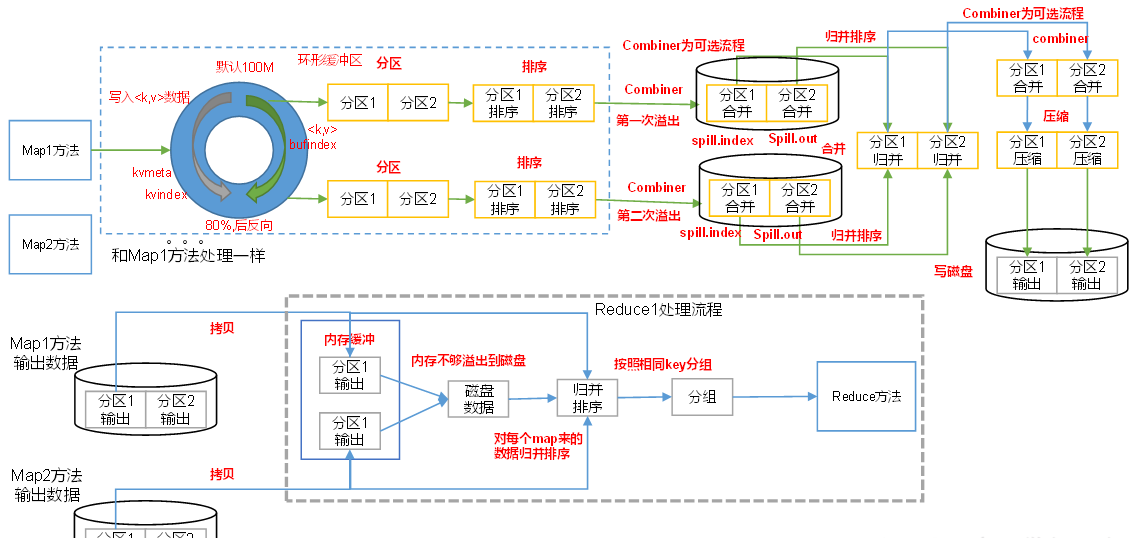
3.4 ReduceTask工作机制
3.5 Reduce Join
Map端的主要工作:为来自不同表或文件的key/value对,打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。
Reduce端的主要工作:在Reduce端以连接字段作为key的分组已经完成,我们只需要在每一个分组当中将那些来源于不同文件的记录(在Map阶段已经打标志)分开,最后进行合并就ok了。
3.6 数据清洗(ETL)
"ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程。ETL一词较常用在数据仓库,但其对象并不限于数据仓库
在运行核心业务MapReduce程序之前,往往要先对数据进行清洗,清理掉不符合用户要求的数据。清理的过程往往只需要运行Mapper程序,不需要运行Reduce程序。