microsoft/BitNet:1位大型语言模型的官方推理框架
突破 Windows 编译禁区:BitNet 1-bit LLM 推理框架 GPU 加速部署编译 BitNet CUDA 算子全记录
【独家资源】Windows 本地部署微软 BitNet b1.58:✅ Flash Attention ✅ CUDA GPU 加速 (sm_86) ✅ AVX2 优化 ✅ 1.58bit 量化
摘要:
本文探索了在 Windows 平台体验边缘计算的模型部署。
本文提供了在 Windows 环境下运行微软 BitNet b1.58 模型的满血版免编译整合包。解决了官方代码在 Windows 下的构建错误、CUDA 兼容性冲突及底层源码逻辑缺失问题,实现了 Flash Attention 和 GPU 深度加速。
🚀 什么是 BitNet b1.58?
BitNet b1.58 是微软研究院提出的革命性 1-bit 大型语言模型(LLM)架构。
-
核心贡献 :它将模型的权重从传统的 16-bit 浮点数压缩到了极致的 1.58-bit(即三元值:-1, 0, 1)。
-
关键突破:
-
极致能效:大幅降低了推理过程中的内存占用和能源消耗。
-
计算范式转移:将原本昂贵的矩阵乘法(Matrix Multiplication)简化为加法计算,在特定硬件上能实现惊人的速度提升。
-
性能不减:在保持极低资源占用的同时,其性能表现依然能够媲美同参数规模的全精度模型(如 LLaMA)。
-

✅ 面对质疑:为什么要"强行"在 Windows 上部署全加速的 BitNet?
-
不仅仅是树莓派:重新定义"边缘计算"与 Windows 的角色
-
打破"Linux 独占":让每一台 RTX 游戏本都能跑得动 1.58-bit
以下是我的回答:
1. 重新定义"边缘设备" (Redefining Edge)
"很多人认为 BitNet b1.58 的归宿是手机、树莓派或者嵌入式设备,在 Windows 上折腾它似乎是'杀鸡用牛刀'。但在我看来,高性能 PC 才是目前最强大的'边缘设备'。
数以亿计的 Windows 用户拥有 RTX 30/40 系显卡,这些算力如果因为系统兼容性问题而被拒之门外,是对算力的最大浪费。让 Windows 用户也能在本地、离线、低延迟地体验 1.58-bit 带来的极致能效,这正是边缘计算'数据不出域'精神的最佳体现。"
2. 工作流的无缝融合 (Workflow Integration)
"Linux 无疑是 AI 开发的首选,但 Windows 才是生产力的主战场。
我们的 Photoshop、Unity、Unreal Engine、Office 全家桶都在 Windows 上。如果我为了跑一个高效的模型,必须重启进入 Linux,或者配置复杂的 WSL2 网络穿透,那么这个模型再高效,它的'使用成本'也是无限高的。
我在 Windows 上死磕编译,就是为了让 BitNet 能以 DLL 或 API 的形式,直接嵌入到我们日常的 exe 软件流中,让 AI 真正成为触手可及的辅助工具,而不是实验室里的玩具。"
3. 验证技术的通用性 (Proof of Concept)
"BitNet 号称能颠覆 Transformer 的计算范式,将乘法变为加法。如果这样一项革命性的技术,只能在特定的 Linux 内核或特定的硬件上运行,那它的普适性就大打折扣了。
'能跑'和'好用'是两码事。 官方代码在 Windows 环境下的缺失,恰恰证明了生态的短板。我填补了这个空白,不仅是为了自己用,更是为了证明:1.58-bit 技术具有跨平台、跨生态的强大生命力。只要配置得当,它在 Windows + MSVC 环境下依然能跑出令人惊叹的 Token 生成率。"
4. 这种"强行"本身的极客精神 (The Geek Spirit)
"有人问:'既然这么麻烦,为什么不直接装个 Ubuntu?'
这是一个典型的开发者思维,但不是用户思维。我的初衷很简单:我不希望当一个小白用户拿到 BitNet 时,面对的是一堆报错和复杂的虚拟机教程。 > 我去踩坑、去修改底层源码、去和编译器搏斗,就是为了最后能输出这一个几 MB 的压缩包。对于之后下载这个包的人来说,他们不需要懂 CMake,不需要懂 NVCC,双击就能用------这才是开源社区最迷人的地方。"
一段话总结:
"正因为 BitNet 是为边缘而生,而拥有显卡的 Windows 电脑是目前普及率最高、算力最强的'边缘节点',所以打通 Windows 部署链路,才是让这项技术真正普惠落地的关键一步。"
⚠️ 部署前的"劝退"与真相
说实话,BitNet 目前原生的开发环境是 Linux。
如果你追求最稳妥的体验,或者主要用于学术研究,强烈建议你在 Linux 或 WSL2 (Windows Subsystem for Linux) 中进行部署。那里的工具链(GCC, NVCC)更加成熟,官方支持也更好。
但是,如果你一定要在原生 Windows 上部署(为了打游戏方便、不想配置 WSL、或者单纯为了挑战极限),你将面临真正的"地狱模式":
-
编译器大乱斗 :BitNet 分支的代码在 Windows 下存在严重的兼容性问题。MSVC、Clang-cl 和 NVCC 在 C++ 标准(C++17)和预处理模式(
/Zc:preprocessor)上存在激烈的冲突,极易导致sum.cu等核心 CUDA 文件编译失败。 -
底层源码缺失 :官方仓库的
ggml.c文件在重构时,针对 Windows/MSVC 环境漏写了关键变量定义 (如src1_col_stride),甚至存在括号不匹配的低级语法错误,导致无法生成计算图。 -
依赖地狱:启用 Flash Attention 和高性能算子需要极其精准的编译参数组合(CMake + Ninja),错一个参数就会导致性能大幅下降或直接报错。
我在经历了 3 天 3 夜的 Debug,修改了数十处源码,并进行了上百次编译尝试后,终于在 RTX 3090 + Core Ultra 9 平台上成功构建了完美版。
🎁 懒人福利:免编译整合包下载
为了让大家免受我吃过的苦,我将编译好的 Release 版本 打包分享出来。
这个包里有什么?
-
✅ BitNet 1.58b 原生支持 :完美加载
i2_s三元量化模型。 -
✅ CUDA GPU 满血加速:针对 NVIDIA Ampere 架构(RTX 3090/3080/3070/3060, Compute Capability 8.6)进行了深度优化。
-
✅ Flash Attention 开启 :强制启用了
DGGML_CUDA_FA_ALL_QUANTS,大幅降低长文本显存占用。 -
✅ AVX2 指令集优化:确保 CPU 端(如 Tokenizer 处理)依然高效。
-
✅ 开箱即用:内含必要的 DLL 运行库,无需安装 Visual Studio 或 CMake。
🛠️ 为什么必须用这份整合包?
官方的 BitNet 项目目前对 Windows 的支持相当有限。如果你尝试直接在 Windows 上从源码编译 ✅ Flash Attention+✅ CUDA GPU 加速(Compute Capability 8.6)+✅ AVX2 指令集优化 +✅ BitNet 全加速,将会面临:
-
内核编译失败 :
compile.sh是 Linux 脚本,且 CUDA 内核代码在 MSVC 环境下有大量语法不兼容。 -
底层源码缺失 :
llama.cpp分支的ggml.c在 Windows 重构时漏掉了关键变量定义(如src1_col_stride),导致无法生成计算图。 -
依赖地狱:启用 Flash Attention 需要极高精度的编译参数组合(CMake + Ninja + Clang-cl),错一个参数就会导致性能大幅下降或报错。
-
大量源码修改:需要修改较多文件以适配 Windows 编译
为了避免大家重复踩坑,我将编译好的核心组件打包,大家只需按照以下步骤操作即可"开箱即用"。
📥 下载地址
点击这里下载 BitNet-Windows-Release.zip
(通过网盘分享的文件:✅ Flash Attention✅ CUDA GPU 加速(Compute Capability 8.6)✅ AVX2 指令集优化✅ BitNet 量化推理✅ 完整的 llama.cpp 功能集 Release.zip
链接: https://pan.baidu.com/s/1KZRWd49aEQUjos2r3n7XIg?pwd=yjf9 提取码: yjf9
--来自百度网盘超级会员v9的分享)
这里老是上传不了,所以就上传网盘了
📁 J:\PythonProjects4\BitNet\build\bin\Release
├── 📊 统计信息: 64 个文件, 281.6 MB, Flash Attention CUDA BitNet 支持 ✅
│
├── 🔵 Core Libraries (核心库)
│ ├── 📦 ggml.dll (91 MB) - 主推理库
│ ├── 📦 ggml-base.dll (675 KB) - 基础功能
│ ├── 📦 ggml-cuda.dll (126 MB) ⭐ - CUDA GPU 加速
│ └── 📦 ggml-rpc.dll (142 KB) - RPC 远程调用
│
├── 🟢 CPU Optimizations (14 种 CPU 优化内核)
│ ├── 🔧 ggml-cpu-alderlake.dll (1.1 MB) - Intel 12代+
│ ├── 🔧 ggml-cpu-cannonlake.dll (1.3 MB) - Intel 8代
│ ├── 🔧 ggml-cpu-cascadelake.dll (1.3 MB) - Intel Xeon
│ ├── 🔧 ggml-cpu-cooperlake.dll (1.3 MB) - Intel Xeon
│ ├── 🔧 ggml-cpu-haswell.dll (1.1 MB) - Intel 4代
│ ├── 🔧 ggml-cpu-icelake.dll (1.3 MB) - Intel 10代+
│ ├── 🔧 ggml-cpu-ivybridge.dll (969 KB) - Intel 3代
│ ├── 🔧 ggml-cpu-piledriver.dll (971 KB) - AMD FX
│ ├── 🔧 ggml-cpu-sandybridge.dll (950 KB) - Intel 2代
│ ├── 🔧 ggml-cpu-sapphirerapids.dll (1.6 MB) - Intel Xeon
│ ├── 🔧 ggml-cpu-skylakex.dll (1.3 MB) - Intel Xeon
│ ├── 🔧 ggml-cpu-sse42.dll (786 KB) - 通用 SSE4.2
│ ├── 🔧 ggml-cpu-x64.dll (781 KB) - 通用 x64
│ └── 🔧 ggml-cpu-zen4.dll (1.3 MB) - AMD Ryzen 7000+
│
└── 🟠 Tools & Executables (40+ 工具)
├── 💻 CLI Tools (命令行工具)
│ ├── ⚡ llama-cli.exe (619 KB) ⭐ - 主交互程序
│ ├── 📊 llama-bench.exe (196 KB) - 性能测试
│ ├── 🔨 llama-quantize.exe (80 KB) - 模型量化
│ ├── 🌐 llama-server.exe (1.3 MB) ⭐ - HTTP API 服务
│ └── 📈 llama-perplexity.exe (652 KB) - 困惑度测试
│
├── 🔬 Advanced Tools (高级工具)
│ ├── 🖼️ llama-llava-cli.exe (723 KB) - 多模态 (LLaVA)
│ ├── 🔍 llama-embedding.exe (565 KB) - 文本嵌入
│ ├── 🎯 llama-imatrix.exe (598 KB) - 重要性矩阵
│ ├── 🔄 llama-infill.exe (598 KB) - 代码补全
│ └── 📚 llama-retrieval.exe (571 KB) - 检索增强
│
├── 🛠️ Utility Tools (实用工具)
│ ├── 📦 llama-gguf.exe (30 KB) - GGUF 工具
│ ├── ✂️ llama-gguf-split.exe (49 KB) - 模型分割
│ ├── 🔢 llama-tokenize.exe (50 KB) - 分词工具
│ ├── 💾 llama-save-load-state.exe (558 KB) - 状态保存
│ └── 🎨 llama-export-lora.exe (559 KB) - LoRA 导出
│
└── 🧪 Experimental (实验性工具)
├── 🎤 llama-tts.exe (6.8 MB) - 文本转语音
├── 👁️ llama-minicpmv-cli.exe (720 KB) - MiniCPM-V
├── 🔮 llama-lookahead.exe (570 KB) - 前瞻解码
└── 🎲 llama-speculative.exe (587 KB) - 投机采样
⭐ 推荐优先使用: llama-cli.exe 和 llama-server.exe (支持 CUDA 加速)📋 环境准备
-
在开始之前,请确保你的电脑满足以下条件:
-
操作系统:Windows 11 (x64)
-
显卡:NVIDIA RTX 30 系列(最佳兼容,针对 sm_86 优化),RTX 40 系列亦可运行。
-
驱动:请安装最新的 NVIDIA 显卡驱动。
-
Python :推荐 3.11(本教程基于 3.11 编译),不建议使用 3.13+。
-
Visual Studio 2022(用于提供 C++ 运行时环境):
-
安装时勾选 "Desktop development with C++"
-
勾选 "C++ CMake Tools for Windows"
-
勾选 "C++ Clang Compiler for Windows"
-
勾选 "MS-Build Support for LLVM-Toolset (clang)"
-
-
CUDA Toolkit 13.1(本机编译环境):
-
安装类型选择 "local"(本地安装包)。
-
cuDNN 9.17
-
⚡ 部署步骤记录(保姆级步骤)
步骤概览
:: CMD 命令
:: 1. 克隆仓库(包含子模块)
git clone --recursive https://github.com/microsoft/BitNet.git
cd BitNet
:: 2. 创建 项目本地 专用环境
python -m venv --copies .venv
.venv/Scripts/activate.bat
python -m pip install -U pip setuptools wheel
:: 3. 安装基础依赖
pip install -r requirements.txt
:: 4. 进入 GPU 目录并安装 GPU 专用依赖(这里仍会安装 CPU-only 的 torch)
cd gpu
pip install -r requirements.txt
:: 5. 重装 torch+cuda 版本(关键步骤)
pip uninstall torch torchvision torchaudio
:: 安装 torch+CUDA 13.0 版
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu130
:: 6. 安装 Flash Attention 核心(关键步骤)
pip install https://github.com/mjun0812/flash-attention-prebuild-wheels/releases/download/v0.7.16/flash_attn-2.8.3%2Bcu130torch2.10-cp311-cp311-linux_x86_64.whl
:: 7. 编译 CUDA + Flash Attention 内核(关键步骤)
cd bitnet_kernels
:: 在 Windows 上需要使用 Visual Studio Developer Command Prompt 运行编译
:: 编译脚本和相关文件内容需要手动调整,因为原生的 compile.sh 是 Linux 脚本
cd ..
:: 8. 编译需要修改大量文件内容,若无法编译可下载上传的资源
:: 请稳步参考《突破 Windows 编译禁区:BitNet 1-bit LLM 推理框架 GPU 加速部署编译 BitNet CUDA 算子全记录https://aicity.blog.csdn.net/article/details/157975315?spm=1011.2415.3001.5331》
pip install bitlinear_cpp-0.0.0-cp311-cp311-win_amd64.whl
:: 9. 编译 BitNet+CUDA+Flash Attention 全加速的 llama.cpp
:: 编译需要修改大量文件内容,若无法编译可下载上传的资源
cmake -B build ^
-G "Visual Studio 17 2022" ^
-A x64 ^
-DCMAKE_BUILD_TYPE=Release ^
-DGGML_CUDA=ON ^ # 启用CUDA GPU加速
-DGGML_CUDA_FAST_MATH=ON ^ # CUDA快速数学运算
-DGGML_CUDA_FAST_ATTN=ON ^ # 启用Flash Attention
-DGGML_CUDA_DMMV_X=32 ^ # 适配算力8.6的DMMV优化
-DGGML_CUDA_MMQ=ON ^ # 多矩阵量化优化
-DGGML_AVX2=ON ^ # 启用AVX2指令集优化
-DGGML_FMA=ON ^ # 启用FMA指令集优化
-DGGML_BITNET=ON ^ # 显式开启BitNet支持
-DGGML_BUILD_EXAMPLES=ON ^ # 编译llama-cli/llama-server等工具
-DCMAKE_INSTALL_PREFIX=./install # 安装路径(可选)
:: 编译 Release 版本(多核加速)
cmake --build build --config Release --parallel 8
:: 10. 在 BitNet 项目的根目录下创建目录
mkdir build\bin\Release
:: 将上传的资源放进 build\bin\Release 目录内
:: 11. 下载模型
hf download microsoft/BitNet-b1.58-2B-4T-gguf --local-dir models/BitNet-b1.58-2B-4T
:: 12. 修改 run_inference.py 脚本:添加 "--flash-attn" 参数启用 Flash Attention 加速
:: 第25-34行如下
f'{main_path}',
'-m', args.model,
'-n', str(args.n_predict),
'-t', str(args.threads),
'-p', args.prompt,
'-ngl', '0',
'-c', str(args.ctx_size),
'--temp', str(args.temperature),
"-b", "1",
"--flash-attn", # 新增:启用Flash Attention
:: 13. 运行脚本(run_inference.py 脚本会在 build\bin\Release 目录下查找 llama-cli.exe 等可执行文件运行)
python run_inference.py -m models/BitNet-b1.58-2B-4T/ggml-model-i2_s.gguf -p "You are a helpful assistant" -cnv
:: 14. 查看脚本输出并测试
:: 观察输出日志中包含的 BitNet+CUDA+Flash Attention 全加速指标和运行速度步骤拆解
第一阶段:基础环境搭建
请打开 x64 Native Tools Command Prompt for VS 2022 ,逐行执行以下命令:
1. 克隆仓库
git clone --recursive https://github.com/microsoft/BitNet.git
cd BitNet2. 创建并激活虚拟环境
python -m venv --copies .venv
.venv/Scripts/activate.bat
python -m pip install -U pip setuptools wheel3. 安装基础依赖
pip install -r requirements.txt
:: 进入 GPU 目录并安装 GPU 专用依赖(这里仍会安装 CPU-only 的 torch)
cd gpu
pip install -r requirements.txt4. 重装 PyTorch(关键:启用 CUDA 13.0 支持) 默认安装的可能是 CPU 版本,必须替换为支持 CUDA 的版本。
pip uninstall torch torchvision torchaudio
:: 安装 torch+CUDA 13.0 版
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu1305. 安装 Flash Attention 核心 这是一个预编译好的 Wheel 包,用于支持 Flash Attention 加速。
pip install https://github.com/mjun0812/flash-attention-prebuild-wheels/releases/download/v0.7.16/flash_attn-2.8.3%2Bcu130torch2.10-cp311-cp311-linux_x86_64.whl第二阶段:注入"灵魂"资源(免编译核心)
说明 :正常流程此时需要编译
bitnet_kernels和llama.cpp,但这在 Windows 上极难成功。请直接使用我提供的编译产物。
6. 安装 BitNet 自定义算子 请安装整合包中提供的 bitlinear_cpp 库(这是我解决大量编译错误后生成的):
突破 Windows 编译禁区:BitNet 1-bit LLM 推理框架 GPU 加速部署编译 BitNet CUDA 算子全记录
pip install bitlinear_cpp-0.0.0-cp311-cp311-win_amd64.whl7. 部署全加速版 llama.cpp 为了让 Python 脚本能调用底层的 CUDA 加速,我们需要手动放置编译好的二进制文件。
把文件放进根目录下的 build\bin\Release 目录
第三阶段:配置与运行
8. 下载模型 使用 HuggingFace 下载转换好的 GGUF 模型:
hf download microsoft/BitNet-b1.58-2B-4T-gguf --local-dir models/BitNet-b1.58-2B-4T 9. 修改推理脚本 我们需要修改 run_inference.py,手动开启 Flash Attention。 打开 run_inference.py,找到第 25-34 行左右的 cmd 参数列表,添加 --flash-attn。
修改后的代码如下:
:: 第25-34行 内容如下
f'{main_path}',
'-m', args.model,
'-n', str(args.n_predict),
'-t', str(args.threads),
'-p', args.prompt,
'-ngl', '0',
'-c', str(args.ctx_size),
'--temp', str(args.temperature),
"-b", "1",
"--flash-attn", # 新增:启用Flash Attention
10. 启动推理! 一切准备就绪,运行脚本:
python run_inference.py -m models/BitNet-b1.58-2B-4T/ggml-model-i2_s.gguf -p "You are a helpful assistant" -cnv
📊 验证加速效果
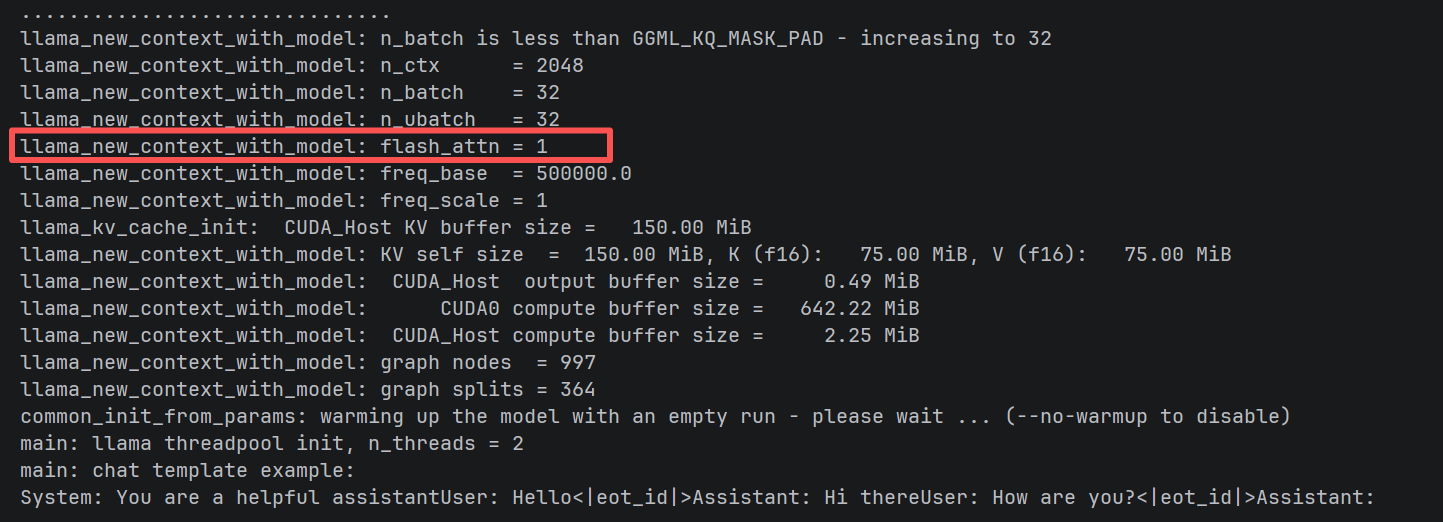
如果一切正常,你将在控制台日志中看到以下关键信息:
-
设备识别成功:Device 0
-
Flash Attention 开启: flash_attn = 1
-
极速生成:你将体验到 1.58-bit 模型带来的极低延迟和超快 Token 生成速度。


📊 运行效果实测
当看到控制台输出以下信息时,说明 Flash Attention 和 CUDA 加速已成功开启:
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 3090, compute capability 8.6, VMM: yes
...
llama_new_context_with_model: flash_attn = 1
...
llama_load_tensors: offloaded 31/31 layers to GPU享受 1.58-bit 带来的极速推理体验吧!
结语: Windows 上的 AI 部署虽然充满坎坷,但每一次成功都是对技术边界的拓展。希望这份指南和资源能帮助你节省时间,享受 BitNet 带来的技术红利。如果你觉得有用,请点赞、收藏支持!
如果你觉得这个资源对你有帮助,请点赞收藏!如果在运行中遇到问题,欢迎在评论区留言。