做远程运维时,服务器数量一旦上来,很多人第一反应还是继续靠命令行硬扛。
但当规模到了几百台、上千台之后,问题往往已经不是"能不能连上",而是:
- 资产怎么组织,才不会越用越乱
- 目标机器怎么快速定位,而不是靠人脑记忆
- 协议怎么切换,才不会在不同工具之间反复跳转
- 认证信息怎么复用,才不会改一次密码就到处补
- 列表很大时,怎么保证操作流畅,不被 UI 拖慢
这时候,单纯依赖命令行其实会越来越吃力。命令行很强,但它更适合"执行";而在大规模服务器管理场景里,真正消耗时间的,往往是查找、筛选、切换、整理、维护这些动作。
我后来把这个问题拆了拆,发现想让 Mac 上的服务器管理变轻松,至少要把下面这几件事解决掉。DartShell 也是按这个思路去做的。
1. 先解决"资产组织"问题:多级分组比平铺列表更重要
当服务器数量很少时,列表怎么摆都还凑合。
但一旦机器开始按环境、项目、地区、业务线、角色不断增长,平铺结构很快就会失控。因为你会发现,真正难的不是"存下这些连接",而是怎么在下一次需要它的时候,仍然能快速找到它。
更合理的方式,通常是树形结构的多级分组。
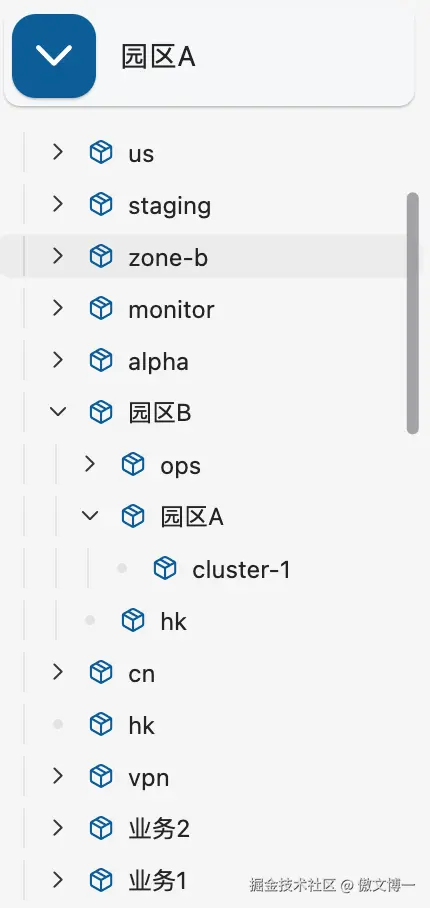
这样做的好处是:
- 可以按业务、环境、团队、地域逐层拆分
- 分组关系更贴近真实基础设施结构
- 后续继续扩容时,不需要推翻已有组织方式
- 视觉上更可控,不会出现一长串无意义的连接列表
本质上,这解决的是可维护性问题。
服务器管理不是一次性录入,而是一个持续演化的资产管理过程。只要结构能持续承载增长,数量再多也不会马上变乱。理论上支持无限分级,这一点在规模上来之后会非常重要。
2. 再解决"检索效率"问题:名称、IP、模糊搜索必须一步到位
组织结构再清晰,也不代表每次都应该靠手动展开目录去找。
在实际运维里,很多时候你只记得部分信息:
- 记得一段 IP
- 记得机器命名里有某个关键字
- 记得它属于某个服务,但不记得具体放在哪一层分组里
- 记得是某次临时加的机器,但不记得完整名字
这时,如果没有搜索能力,管理成本就会直接转化成查找时间。

所以更高效的方式一定是支持:
- 按名称搜索
- 按 IP 搜索
- 模糊匹配
- 尽量少跳转、少展开、少滚动
这看起来只是一个搜索框,但它解决的其实是定位路径过长的问题。
在机器很多的情况下,能不能"一步到位"找到目标服务器,直接决定了日常操作效率。尤其是处理故障、临时登录、切换环境时,这种差距会被放大得非常明显。
3. 补一个"横向维度":颜色标签比你想象中更有用
分组是纵向结构,但真实工作里,很多信息并不适合只放在树里表达。
比如:
- 这台机器是否核心
- 哪些是生产环境高风险节点
- 哪些是临时机器
- 哪些是近期重点关注对象
- 哪些属于同一批任务目标
这些信息如果只靠名字约定,时间一长就容易失效;如果只靠脑子记,也不现实。
所以需要一个额外的横向维度,比如颜色标签。

颜色标签的价值在于,它不会替代分组,而是对分组做补充:
- 让同一类机器跨分组也能被快速识别
- 降低误连、误操作的概率
- 在视觉上快速建立"重要性"和"类别感知"
- 帮助你从另一个维度直达目标服务器
这类设计本质上是在提升识别效率,而不是单纯做界面装饰。
当服务器越来越多时,纯文字列表会让人越来越依赖逐行阅读;而标签体系能把这部分认知负担明显降下来。
4. 协议要能按类型过滤,否则工作流会被频繁打断
很多人的服务器管理,实际并不只有 SSH。
你可能还会遇到:
- Linux 主机用 SSH
- Windows 主机用 RDP
- 文件操作要走 SFTP
- 某些特殊场景还有别的远程协议
如果这些连接全部混在一起,结果通常就是:
- 找目标连接慢
- 切协议时脑内频繁切换上下文
- 一个资产库里混着不同用途的连接,阅读成本上升
- 任务一多时,操作节奏会被不断打断
所以更合理的方式是支持按协议分类过滤。

这件事看起来很简单,但在工作流层面很关键。因为它把"资产很多"这个问题,进一步拆成了"当前我只看哪一类资产"。
这样做有几个直接收益:
- SSH、RDP、SFTP 等连接不会混成一团
- 针对当前任务只看需要的协议集合
- 降低信息噪音
- 在同一个工具里完成更多操作,减少来回切换
说白了,协议过滤解决的是上下文收敛的问题。不是所有东西都同时展示出来才叫全面,很多时候,能在当前任务里只看到必要的信息,反而更高效。
5. 当列表足够大时,性能本身就是体验的一部分
很多服务器管理工具在连接数量不多时都没问题,但一旦数据量上来,就会暴露出另一个问题:卡。
卡顿的影响并不只是"不舒服",更实际的结果是:
- 搜索响应变慢
- 展开分组有延迟
- 滚动列表不顺畅
- 操作反馈滞后,影响判断
而在高频使用场景里,这种小卡顿会不断积累,最后把整条工作流拖慢。
所以如果目标真的是管理上千台服务器,性能设计就不能只停留在"能显示出来"。更合理的思路是采用动态缓存、按需加载这类机制,让大量数据下的交互依旧保持可用。
这一点其实很工程化:
不是单纯把数据堆进去,而是要考虑在大规模资产列表下,界面如何继续稳定响应。
当服务器列表再多也不卡时,用户感受到的不是某一个"亮点功能",而是整体使用过程始终顺手。这种顺手,往往才是大规模管理里最值钱的体验之一。
6. 认证信息必须统一管理,否则维护成本会指数上升
管理少量机器时,用户名、密码、证书分散一点,好像也还能接受。
但机器一多,这种方式会迅速失控。
常见问题包括:
- 同一套认证信息被重复填写很多次
- 证书更新时要一个个改
- 密码轮换时容易漏改
- 连接配置和认证配置耦合在一起,后期维护非常痛苦
所以更合理的方式,是把认证信息从连接配置里抽出来做统一管理。
同样的用户名、密码或者证书,只填一次;后续多个连接可以直接复用;如果凭据变更,也只需要改一个地方。
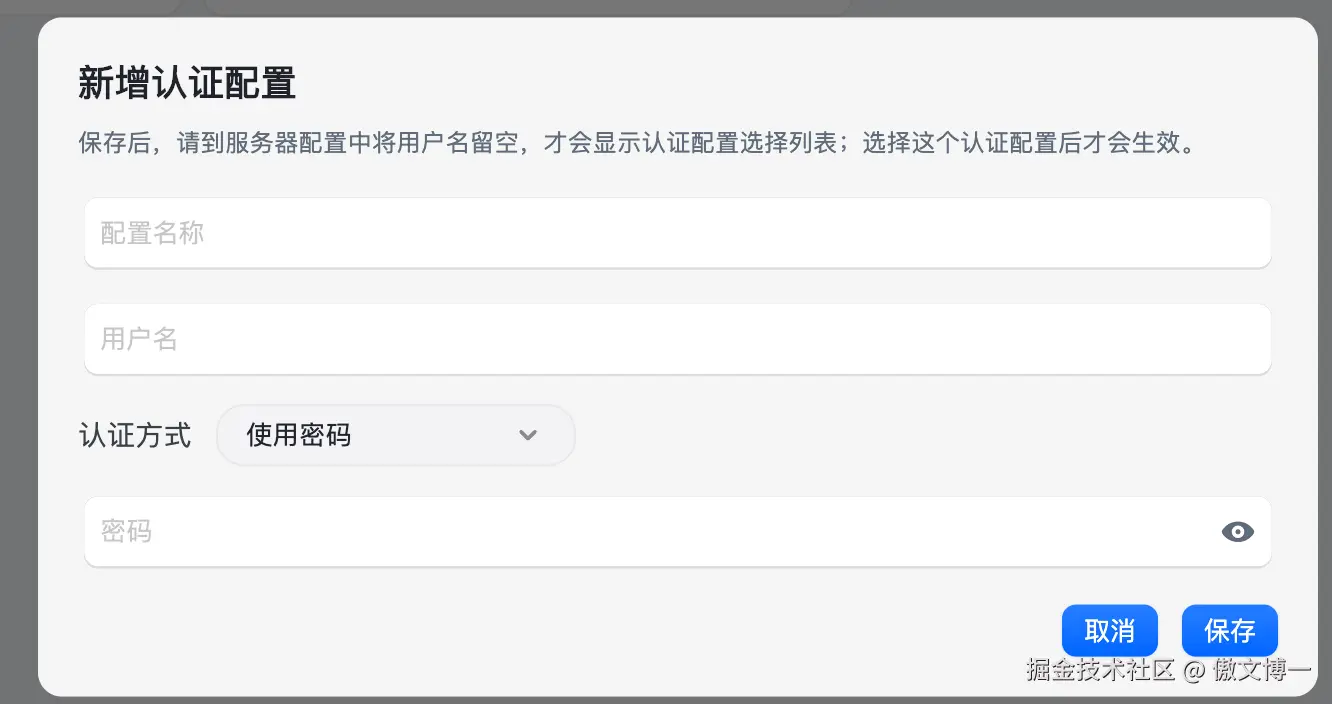
这样做的收益非常直接:
- 减少重复录入
- 降低配置错误概率
- 降低批量变更时的维护成本
- 让连接信息和认证信息各自保持清晰职责
这本质上是在解决配置复用 和后期维护的问题。
很多时候,真正让人崩溃的不是第一次录入,而是后面的持续修改。统一管理认证信息,才能让资产规模扩大之后,系统仍然维持在一个可控状态。
为什么"不能只靠命令行"其实不是在否定命令行
这里并不是说命令行不好。
恰恰相反,命令行依然是远程运维里非常核心的部分。但当场景进入"大量服务器管理"之后,问题的重点已经从"如何执行命令"扩展成了:
- 如何组织资产
- 如何快速检索
- 如何降低误操作
- 如何在多协议之间切换
- 如何减少重复配置
- 如何保证规模增长后的可维护性
命令行解决的是执行效率,管理工具解决的是组织效率和工作流效率。
当机器规模不大时,这两者的边界没那么明显;但当规模上来之后,这个差异会越来越明显。
最后的结论
如果你在 Mac 上只是偶尔连几台服务器,命令行当然足够直接。
但如果你的场景已经变成:
- 服务器数量很多
- 环境复杂
- 协议混合
- 需要频繁查找、筛选、切换和维护
那真正值得优化的,就不只是"连接能力",而是整套管理工作流。
从这个角度看,让大规模服务器管理变轻松,核心并不神秘,无非就是把这几件事做好:
-
用多级分组解决资产组织
-
用搜索解决定位效率
-
用标签补充横向识别
-
用协议过滤减少上下文噪音
-
用按需加载保证大列表性能
-
用统一认证管理降低维护成本
这几个点单独看都不复杂,但组合在一起,才会真正把"管理上千台服务器"这件事,从勉强能用,变成长期可维护、可扩展、可操作。