目录
1.基础流程
-
通过TCP套接字 recv 接收HTTP请求
-
反序列化解析请求行和报头,提取资源路径
-
在配置的Web根目录中查找对应文件
-
构造响应(状态行、报头、正文),通过 send 返回
客户端 服务器(接收) 服务器(解析) 服务器(查找) 服务器(发送)
│ │ │ │ │
│─请求───> │ │ │ │
│ │─数据─────> │ │ │
│ │ │─路径─────> │ │
│ │ │ │─内容────> │
│ │ │ │ │─组装
│ │ │ │ │
│<─────────┼────────────┼────────────┼────────────┤ 响应
│ │ │ │ │
2.文件处理细节
- 根目录:服务器配置的目录,/ 通常映射为 index.html
- 文件读取:需区分文本(如HTML)和二进制(如图片)。二进制读取更万能,但若误将图片按文本读取,可能因编码转换导致数据损坏;若将文本按二进制读,则无影响
- 资源类型:响应头需用Content-Type指明MIME类型(如 text/html、image/jpeg),以便浏览器正确渲染
- MIME是一种互联网标准,用于标识文档、文件或字节流的性质和格式
3.资源加载流程
以短连接为例(好实现)
-
浏览器请求HTML页面(一次请求)
-
解析HTML时发现图片、CSS等资源,自动发起额外请求
-
若为短连接,每请求一个资源即断开;若为长连接,可复用同一连接完成多次请求
-
HTML文档本质上是文本文件,服务器可以将其内容作为字符串直接拼接到HTTP响应报文的正文部分,通过设置Content-Type: text/html告诉浏览器按网页解析渲染,但完整的网页通常还包含CSS、JS、图片等多个独立资源,需要浏览器二次请求获取
浏览器 服务器
│ │
│── 请求 HTML ─────────>│
│<─ 返回 HTML ──────────│
│ │
│── 请求 图片 ─────────>│
│<─ 返回 图片 ──────────│
│ │
│── 请求 CSS ──────────>│
│<─ 返回 CSS ───────────│
│ │
│── 请求 JS ───────────>│
│<─ 返回 JS ────────────│
浏览器访问服务器的本质是请求指定路径下的资源(HTML、CSS、JS、图片等),前端负责编写web根目录下的网页资源,后端负责编写服务器程序处理请求并返回资源,浏览器首次跳转时一定发生了HTTP请求
4.简易代码
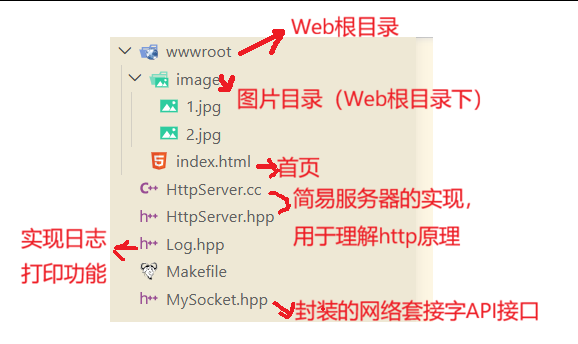
(1)文件结构
所有文件如下,下面只展示HttpServer
(2)全局变量与线程传参结构
const std::string wwwroot = "./wwwroot";
const std::string sep = "\r\n";
const std::string homepage = "index.html";
extern Log logObj;
static const int defaultport = 8080;
class HttpServer;
class ThreadData
{
public:
ThreadData(int sockfd, HttpServer* ts):sockfd_(sockfd), svr(ts)
{}
public:
int sockfd_;
HttpServer* svr;
};- Web根目录路径、http报文的分隔符、网页首页的名称
- 声明日志对象,用于后续打印
- 服务器默认端口号
- 前向声明实现服务器的类,便于线程传参结构封装指针
(3)http简易请求类
class HttpRequest
{
public:
//提取给行内容
void Deserialize(std::string req)
{
while(true)
{
size_t pos = req.find(sep);
//找不到,说明所有报头已经处理完毕了
if(pos == std::string::npos) break;
std::string tmp = req.substr(0, pos);
//找到空行就跳出
if(tmp.empty())
{
//清除换行符就退出
req.erase(0, pos + sep.size());
break;
}
//否则加入并删除
req_head.push_back(tmp);
req.erase(0, pos + sep.size());
}
text = req;
}
//打印结果
void DebugPrint()
{
for(auto& line: req_head)
{
std::cout << "-------------------------" << std::endl;
std::cout << line << "\n\n";
}
std::cout << "method: " << method << std::endl;
std::cout << "url: " << url << std::endl;
std::cout << "http_version: " << http_version << std::endl;
std::cout << "file_path: " << file_path << std::endl;
std::cout << text << std::endl;
}
//解析报头
void Parse()
{
std::stringstream ss(req_head[0]);
ss >> method >> url >> http_version;
//解析文件路径
file_path = wwwroot;//./wwwroot
if(url == "/" || url == "/index.html")
{
file_path += "/";
file_path += homepage;
}
else file_path += url;
//解析数据类型
size_t pos = file_path.rfind('.');
if(pos == std::string::npos) suffix = ".html";
else suffix = file_path.substr(pos);
}
public:
std::vector<std::string> req_head;//存储一行行字符串
std::string text;//请求正文
//解析之后的结果
std::string method;//http请求方法
std::string url;
std::string http_version;
std::string file_path;
std::string suffix;//字符串后缀,用于后续返回数据类型
};- 包含反序列化提取内容、Debug打印结构与状态行解析函数
(4)http简易服务器
class HttpServer
{
public:
//初始化端口号
HttpServer(uint16_t port = defaultport):port_(port)
{
content_type[".html"] = "text/html";
content_type[".jpg"] = "image/jpeg";
}
~HttpServer()
{}
public:
//启动服务器:创建、绑定、监听
bool Start()
{
listenSock_.Socket();
listenSock_.Bind(port_);
listenSock_.Listen();
//接收连接
for(;;)
{
std::string clientip;
uint16_t clientport;
//接受连接
int sockfd = listenSock_.Accept(&clientip, &clientport);
if(sockfd < 0) continue;
logObj(Info, "get a new connect, sockfd:%d", sockfd);
pthread_t tid;
ThreadData* td = new ThreadData(sockfd, this);
pthread_create(&tid, nullptr, ThreadRun, td);
}
return true;
}
//将文件后缀映射的数据类型,便于浏览器显示
std::string SuffixToDesc(const std::string& suffix)
{
if(content_type.count(suffix))
return content_type[suffix];
else return content_type[".html"];
}
//读取网页文件内容,需要二进制读取比较万能
std::string ReadHtmlContent(const std::string& htmlPath)
{
//打开文件
std::ifstream in(htmlPath, std::ios::binary);
if(!in.is_open()) return "";
//读取内容
// std::string content;
// std::string line;
// while(std::getline(in, line))
// {
// content += line;
// }
//二进制读取
in.seekg(0, std::ios_base::end);
auto len = in.tellg();
in.seekg(0, std::ios_base::beg);
std::string content;
content.resize(len);
in.read((char*)content.c_str(), content.size());
//关闭并返回
in.close();
return content;
}
//处理请求并相应
void HandleHttp(int sockfd)
{
//读取
char buffer[10240];
ssize_t n = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
//为了测试,简单粗暴
if(n > 0)
{
buffer[n] = 0;
std::cout << buffer;//为了了解原理,假设读取完整
//构建请求,反序列化提取内容
HttpRequest req;
req.Deserialize(buffer);
req.Parse();
// req.DebugPrint();
//返回响应
//构造响应报文
std::string text;
bool ok = true;
text = ReadHtmlContent(req.file_path);//响应正文
if(text.empty())//未能找到对应资源
{
ok = false;
std::string err_html = wwwroot;
err_html += "/err.html";
text = ReadHtmlContent(err_html);
}
std::string response_line;
if(ok)
response_line = "HTTP/1.0 200 OK\r\n";//状态行
else
response_line = "HTTP/1.0 404 Not Found\r\n";//状态行
// response_line = "HTTP/1.0 302 Found\r\n";//状态行
std::string response_header = "Content-Length: ";//响应属性
response_header += std::to_string(text.size());
response_header += "\r\n";
// response_header += "Location: https://www.qq.com\r\n";
response_header += "Content-Type: ";
response_header += SuffixToDesc(req.suffix);
response_header += "\r\n";
response_header += "Set-Cookie: name=123&password=123\r\n";
std::string blank_line = "\r\n";
std::string response = response_line;
response += response_header;
response += blank_line;
response += text;
//发送响应
send(sockfd, response.c_str(), response.size(), 0);
}
close(sockfd);
}
static void* ThreadRun(void* args)
{
//线程分离:不用主线程去等待
pthread_detach(pthread_self());
//获取参数
ThreadData* td = static_cast<ThreadData*>(args);
//处理请求
td->svr->HandleHttp(td->sockfd_);
//防止内存泄漏
delete td;
return nullptr;
}
private:
MySocket listenSock_;//负责监听端口、接受连接
uint16_t port_; //默认使用构造函数传入的值
std::unordered_map<std::string, std::string> content_type;//文件后缀 → Content-Type
};-
整体架构
┌─────────────────────────────────────────────────────────────────┐
│ HttpServer 类 │
├─────────────────────────────────────────────────────────────────┤
│ 成员变量 │
│ ├── listenSock_ : 监听套接字 │
│ ├── port_ : 端口号 │
│ └── content_type_ : MIME类型映射表 │
├─────────────────────────────────────────────────────────────────┤
│ 核心方法 │
│ ├── Start() : 启动服务器 │
│ ├── HandleHttp() : 处理HTTP请求 │
│ ├── ReadHtmlContent(): 读取文件内容 │
│ ├── SuffixToDesc() : 后缀转MIME类型 │
│ └── ThreadRun() : 线程执行函数 │
└─────────────────────────────────────────────────────────────────┘ -
相关知识点
| 知识点 | 代码体现 |
|---|---|
| TCP服务器模型 | Socket → Bind → Listen → Accept |
| 多线程并发 | pthread_create + 线程分离 |
| HTTP报文格式 | 状态行 + 头部 + 空行 + 正文 |
| MIME类型 | content_type映射表 |
| 二进制文件读取 | ifstream + binary + seekg/tellg |
| 资源管理 | new/delete配对,close关闭socket |