那次压测,持续了整整三天。
工程师小张把 QUIC 所有能调的参数过了一遍:换拥塞算法(BBR → Copa → Cubic),调 ACK 频率(每包 ACK → 每 10ms 一次),调 initial_rtt(50ms → 80ms → 100ms),调流量控制窗口。P99 延迟从 235ms 降到了 220ms,然后就卡住了。
最后是用 eBPF 追踪才找到答案。tracepoint:net:net_dev_queue 显示:控制信号的 QUIC 包进入 qdisc 的时刻,和实际发出的时刻,之间差了 180ms。OTA 下载开着,发送队列满了,控制信号小包排在 OTA 大包后面,等了将近两个空口传输窗口才出队。
和 QUIC 参数毫无关系。
这个故事的教训是:在优化传输协议之前,先把延迟预算算清楚。250ms 的 SLA,传输层能用的预算可能只有 20-70ms;而 qdisc 和进程调度这两个看起来不在传输层的因素,也是最容易把 P99 顶穿的元凶之一。
第一章:端到端延迟的逐跳拆解
1.1 一条控制指令走过的路
从云控平台发出一条指令,到 T-Box 上的应用程序收到并转发给 MCU 执行,中间经过多少跳?
完整的路径:
objectivec
云控坐席
↓ 有线网络(专线/公网)
↓ 云控云端
↓ 运营商骨干网
↓ 基站回传链路
↓ 无线接入(空口)
↓ 4G/5G 模组
↓ USB 接口(模组到主控SoC)
↓ 内核网络协议栈
↓ qdisc(发送队列调度)
↓ QUIC 应用进程
↓ 云控应用程序(车内以太网)
↓ CAN总线
↓ MCU 执行每一跳都有延迟,而且大小差异悬殊。
1.2 各跳延迟的真实数据
以下数据来自 T-Box 实测,部分结合 3GPP 规范和运营商网络测量:
| 路径段 | 延迟范围(单程) | 说明 |
|---|---|---|
| 云控坐席自身处理 | 10-30ms | 坐席软件处理,含在端到端 SLA 内 |
| 云控坐席 → 云控云端(有线网络) | 5-10ms(专线),抖动更大(公网) | 专线稳定;走公网时 P99 可达 30-50ms |
| 云控云端 → 基站(运营商骨干网) | P99:20-35ms(跨省) | 取决于云部署位置与基站距离;一线城市低,偏远地区高 |
| 基站 → 4G 模组(空口) | P99:80-150ms(信号弱、基站切换、拥塞) | 4G LTE 典型 RTT 50-150ms;弱信号/切换时 P99 大幅拉长 |
| 基站 → 5G 模组(空口) | P99:40-100ms(NSA 架构、切换、弱覆盖) | 5G NR 典型 RTT 30-100ms;NSA 架构下偶尔抖动 |
| 模组 → 内核驱动(USB) | 0.1-2ms | USB 接口典型 0.3-0.8ms;通常可忽略 |
| 内核协议栈处理 | 0.05-5ms | 软中断处理;CPU 负载高时(如 OTA 期间)可增加 |
| qdisc 排队等待 | 0-300ms | 无 QoS 时,取决于队列深度和上行带宽 |
| 进程调度延迟 | 0-2000ms | eMMC 卡顿时,进程在 IO 上阻塞 |
| QUIC 应用进程处理 | 0.1-2ms | 事件循环调度、加解密;正常负载下可忽略 |
| 云控应用程序 → MCU(车内总线) | 0.1-1ms | 以太网或 CAN 总线;几乎可以忽略 |
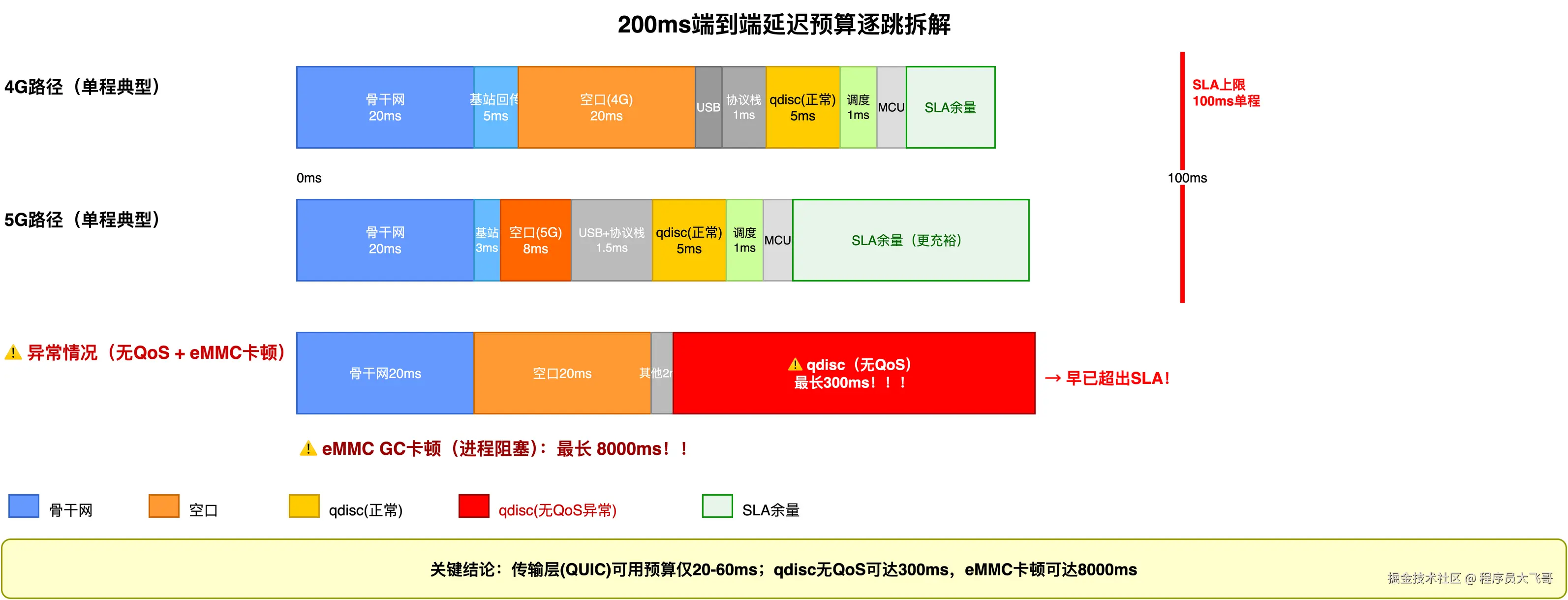
把 P99 场景下(qdisc 有 QoS,进程正常调度)的不可控延迟加起来:
4G P99 单程 :坐席 20ms + 有线 7ms + 骨干网 35ms(P99)+ 空口 115ms(P99 中间值)+ 模组到内核 1ms + 内核协议栈 1ms ≈ 179ms
5G P99 单程 :坐席 20ms + 有线 7ms + 骨干网 35ms(P99)+ 空口 70ms(P99 中间值)+ 模组到内核 1ms + 内核协议栈 1ms ≈ 134ms
这是 SLA 250ms 里已经被"占走"的部分,剩给传输层的预算见下一节。
1.3 传输层能用的预算有多少
SLA 要求:端到端单程延迟 < 250ms(含云控坐席自身),按 P99 保障。
从 250ms 里扣掉不可控的部分(P99 场景):
- 云控坐席自身:20ms
- 有线网络(坐席→云端):7ms(专线)
- 运营商骨干网(P99 中间值):27ms(范围 20-35ms)
- 空口 4G(P99 中间值):115ms(范围 80-150ms)
- 模组到内核:1ms
- 内核协议栈:1ms
- 合计不可控部分:171ms
剩给传输层(qdisc + 进程调度 + QUIC 处理)的预算:约 79ms(典型 P99)
极端情况(骨干网 35ms + 空口 150ms):250 - 20 - 7 - 35 - 150 - 2 = 36ms
这就是"P99 下传输层预算约 20-70ms"这个数字的来源。(极端情况可低至 36ms,典型情况约 79ms,取中间值约 20-70ms 作为工程参考区间)
然而,看看 qdisc 无 QoS 时的最大延迟:300ms。看看 eMMC 卡顿时的进程挂起:最长 2 秒。这两项都不在传输层,但它们的上限分别是传输层预算(20-70ms)的 4-15 倍和数十倍。
结论变得清晰:调 QUIC 参数,是在 20-70ms 的预算里做优化;而 qdisc 和 eMMC 问题,一旦发作,SLA 就直接超标,跟 QUIC 参数无关。
bash
# 测量 T-Box 上行链路的 qdisc 状态
# rmnet0 是 4G 模组的网络接口(具体名称可能是 ccmni0 或 wwan0,视平台而定)
tc -s qdisc show dev rmnet0
# 关注输出中:
# Sent X bytes Y packets(已发送)
# Dropped Z(丢弃数,qdisc 满了才丢)
# backlog N bytes M pkts(当前队列中的数据量)
# 实时监控 qdisc 积压
watch -n 1 'tc -s qdisc show dev rmnet0 | grep -A4 "qdisc"'
# 快速估算最大排队延迟
# 公式:backlog_bytes × 8 / link_speed_bps
# 示例:100000字节 × 8 / 5000000(4G上行5Mbps)= 160ms第二章:qdisc 是最容易被忽视的定时炸弹
2.1 什么是 bufferbloat,为什么它在 T-Box 上特别严重
Bufferbloat 是一个网络界的老问题,但在 T-Box 上有其特殊的严重性。
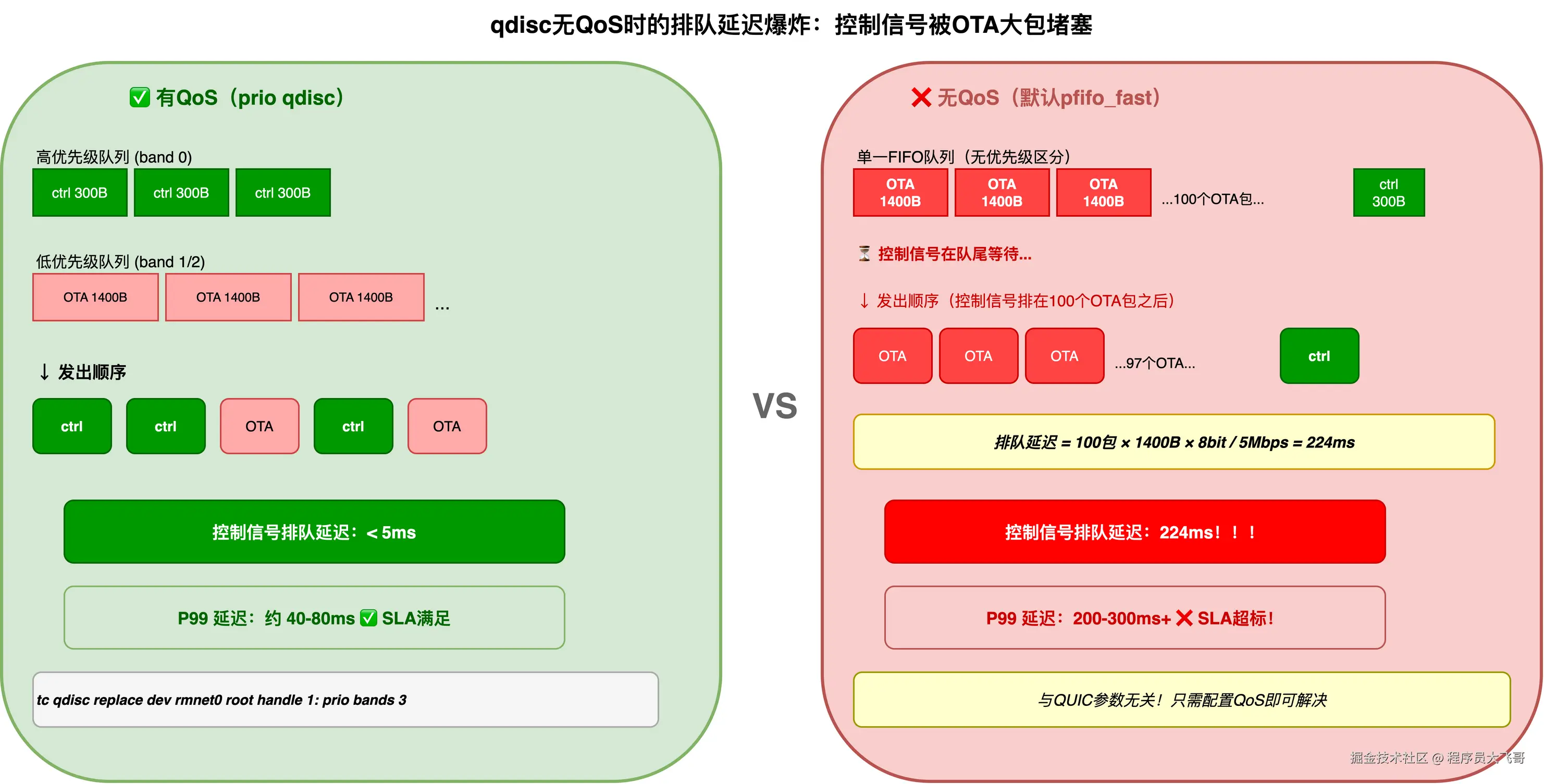
Bufferbloat 的本质:当发送缓冲区(qdisc)很大,而链路带宽相对有限时,大量数据在缓冲区中排队,导致延迟急剧上升。缓冲区就是为了"平滑"流量波动设计的,但当缓冲区太大、排队时间太长时,"平滑"就变成了"堵塞"。
用"高速公路收费站"来类比:假设收费站只有一个窗口(发送队列),没有 ETC 专用车道(没有 QoS)。货车(OTA 大包,1400 字节)和轿车(控制信号小包,100 字节)混在一起排队。轿车急着走,但货车排在前面,必须等。
T-Box 的特殊性:
第一,4G 上行带宽有限。4G LTE 上行典型 2-20Mbps,高速场景下有时只有 1-2Mbps。带宽越小,同样队列深度造成的排队延迟越长。
第二,T-Box 上的流量类型差异巨大。控制信号:几十字节到几百字节,延迟敏感。OTA 升级包:几十 MB 到几百 MB,持续大流量,对延迟不敏感。日志上报:突发性大流量。这三种流量如果不加区分,OTA 和日志会把队列塞满,控制信号等在后面。
2.2 排队延迟的量化计算
以下是精确计算:
场景:T-Box 发起 OTA 下载,同时发送控制信号。上行带宽 5Mbps。Linux 默认 qdisc 是 pfifo_fast 或 fq_codel,队列深度 1000 个包。
OTA 流量填满队列:1000 包 × 1400 字节 × 8 bit/byte = 11,200,000 bits
队列发完需要:11,200,000 / 5,000,000 = 2.24 秒
这是极端情况。更常见的是队列半满状态:
队列 100 个包 × 1400 字节:100 × 1400 × 8 / 5,000,000 = 224ms
控制信号小包进入队列的那一刻,如果前面有 100 个 OTA 大包,就要等 224ms。
这就是那次压测的真相:P99 卡在 220ms,因为压测脚本里有一个后台进程在做文件上传,每隔 5 分钟触发一次,恰好在 P99 采样点把队列塞了一下。
换一种表达:无论你把 QUIC 的拥塞算法调得多激进,小包在 qdisc 里等待的时间和 QUIC 无关------它纯粹是操作系统发送队列调度的问题。
2.3 QUIC 层能做什么,不能做什么
qdisc 问题的完整解决方案是在操作系统层用 TC(Traffic Control)配置 QoS,给控制信号的 UDP 流量设置高优先级队列(详见 Series A 第 8 篇的 TC eBPF 方案)。
但在 QUIC 层,也可以做一些有限的缓解:
方案一:用 DSCP 标记控制信号包。 QUIC 运行在 UDP 上,UDP 包的 IP 头有 DSCP/TOS 字段。设置高 DSCP 值(如 CS5 = 0b101000 = 46),配合 OS 层的 iptables/tc 规则,可以让控制信号包进入高优先级队列。
方案二:控制发送速率,避免主动塞满 qdisc。 QUIC 的拥塞控制会控制 QUIC 连接的总发送速率,但前提是它知道链路带宽。如果链路带宽探测不准确(比如网络刚恢复),发送速率可能瞬间过高,把 qdisc 塞满。设置合理的 max_pacing_rate 上限可以缓解。
bash
# 查看 rmnet0 的 qdisc 类型
tc qdisc show dev rmnet0
# 如果是 pfifo_fast(无 QoS),可以换成 prio(优先级调度)
# 注意:修改 qdisc 需要 root,T-Box 上通常需要 su 或特权进程
tc qdisc replace dev rmnet0 root handle 1: prio bands 3 priomap 2 2 2 2 1 2 0 0 2 2 2 2 2 2 2 2
# 把 DSCP CS5 的包(控制信号)导入最高优先级队列(band 0)
tc filter add dev rmnet0 parent 1: protocol ip u32 match ip dsfield 0xa0 0xfc flowid 1:1
# 验证:控制信号包是否带了正确的 DSCP 标记
tcpdump -i rmnet0 -v 'udp port 443' 2>/dev/null | grep "tos" | head -20第三章:eMMC 卡顿------那个 2 秒的隐藏 Boss
3.1 NAND Flash 的 GC 风暴
T-Box 的存储通常是 eMMC(嵌入式多媒体卡),本质是 NAND Flash 加上一个控制器。NAND Flash 的物理特性决定了它不能原地覆写,必须先擦后写。当空闲块不足时,控制器要做垃圾回收(GC)------把多个块合并、擦除,再腾出空间写入。
这个 GC 过程是后台进行的,但当 GC 压力大时,写延迟会飙升。不同 eMMC 型号的 GC 写延迟差异极大:
- 普通消费级 eMMC(常见于低端 T-Box):GC 期间写延迟 0.5-1 秒,极端情况可达 1-2 秒
- 工业级 eMMC(标称 pSLC 模式):通常 <100ms
当 T-Box 上的 QUIC 进程做以下任何一件事时,就可能触发同步 eMMC IO:
- 写日志文件(
fprintf,fwrite) - 写 qlog 文件(QUIC 调试日志)
- 写配置文件(参数持久化)
write() 系统调用触发 VFS 写入,如果文件在 eMMC 分区上(而不是 tmpfs 内存文件系统),进程会在 write() 上阻塞,等待 eMMC 完成写操作。阻塞期间,进程不运行,QUIC 发送循环停止,控制信号不发出。
这个过程从外部看:控制信号中断了 X 秒,X 在 0.5-2 秒之间,没有规律。tcpdump 抓包可以看到有一段时间完全没有 QUIC 包发出,然后突然恢复。
重要的是:这段时间内 T-Box 的信号是正常的,TCP 连接也没有断,TCP keepalive 也没有超时------就是应用进程卡住了没有发包。如果你不知道 eMMC GC 这个机制,排查起来会非常困惑。
3.2 QUIC 集成时的必要配置
这是集成 QUIC 时最容易踩的坑之一,需要在代码架构层面解决:
规则一:日志文件必须在 tmpfs 上。 把 QUIC 进程的日志路径指向 /tmp(Linux 系统默认挂载为 tmpfs)或者专门的内存文件系统挂载点。
c
// 错误做法:日志写到 eMMC
tquic_set_log_path("/data/logs/tquic.log");
// 正确做法:日志写到 tmpfs
tquic_set_log_path("/tmp/tquic.log");
// 或者自定义日志回调,写到内存缓冲区,后台线程异步刷到磁盘规则二:qlog 文件同样必须在 tmpfs 上。 QUIC 的 qlog 是调试利器,但 qlog 文件可以很大(高频连接每分钟 10-50MB),如果写在 eMMC 上后果很严重。
规则三:任何持久化操作都不能在 QUIC 回调中同步执行。 状态保存、证书写入、配置更新------这些操作如果在 QUIC 的 on_connected/on_stream_data 等回调里同步做,就会阻塞 QUIC 的事件循环。
规则四:监控 eMMC 写延迟,提前发现问题。
bash
# 检查 QUIC 进程当前打开的文件,确认日志路径
lsof -p $(pgrep -f tquic_client) | grep -E "\.log|\.qlog|qlog"
# 确认 /tmp 是否在 tmpfs 上
df -h /tmp
# 输出应该显示 tmpfs 而不是 mmcblk0p...
# 监控 eMMC 写延迟(需要 iostat)
iostat -x mmcblk0 1 10
# 关注 await(IO 等待时间),如果 >100ms 说明 GC 在运行
# 用 eBPF 追踪进程级别的 IO 延迟(需要 BCC 工具)
biosnoop -p $(pgrep -f tquic_client) 2>/dev/null | head -20第四章:把 SLA 翻译成 QUIC 参数
4.1 双路 RTT 不对称对去重窗口的影响
回到冗余发送架构:T-Box 同时在 4G 和 5G 两条路径上发送相同的 QUIC 包,云端网关做去重。
去重逻辑:收到一个 Packet Number 为 N 的包后,在接下来 W ms 内,再收到相同 Packet Number 的包,就丢弃。这个 W 就是去重窗口。
W 设多大?
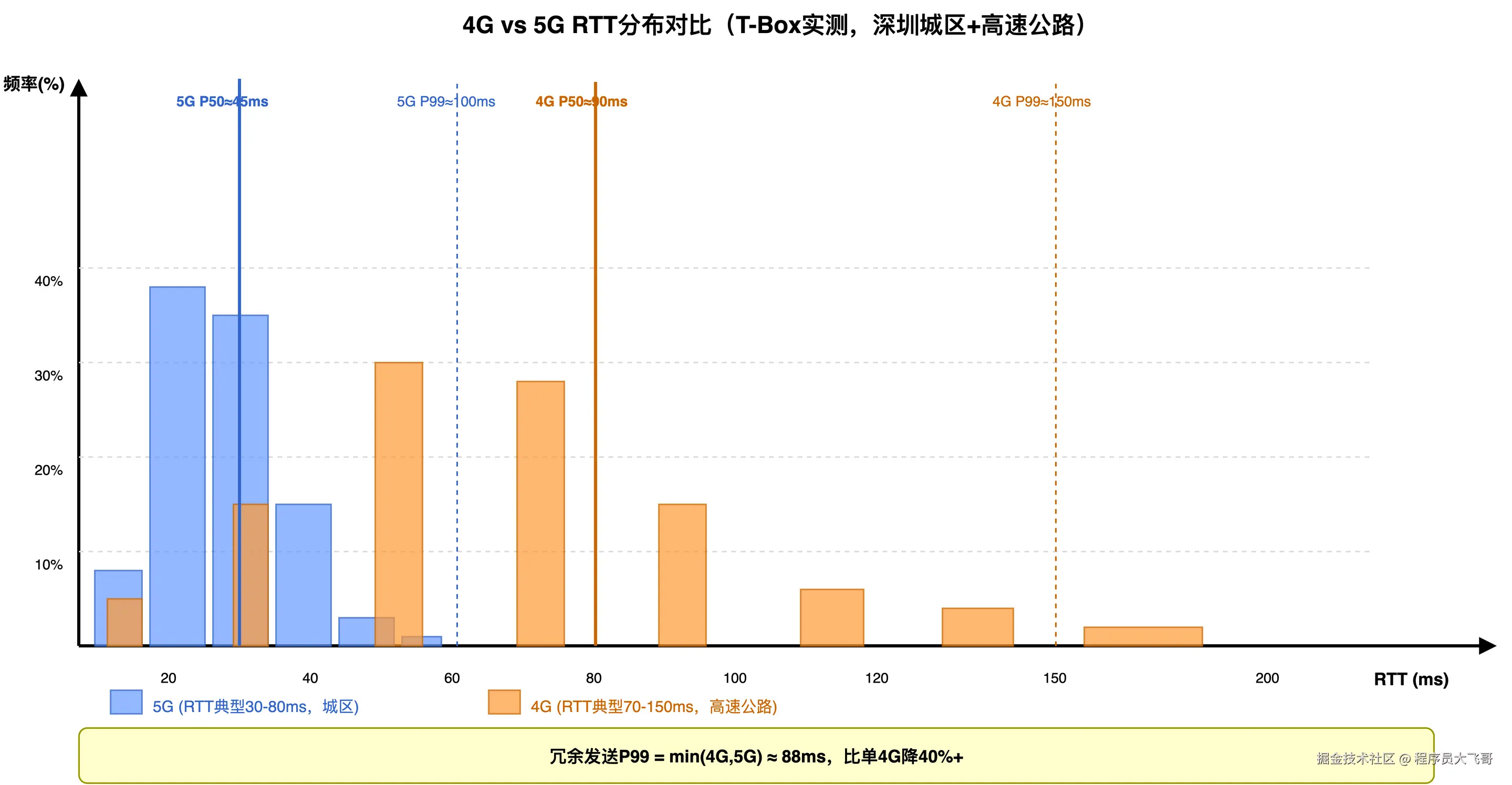
下图是深圳城区+高速公路的实测 RTT 分布,可以直观看到 4G 尾部(P99 约 150ms)比 5G 更长、抖动更大,这是去重窗口不能设得太小的直接依据。
设 RTT_4G 是 4G 路径的往返时延,RTT_5G 是 5G 路径的往返时延。单程延迟大约是 RTT 的一半。
两路包到达云端的时间差 ΔT = |RTT_4G/2 - RTT_5G/2| = |RTT_4G - RTT_5G| / 2
如果 4G P99 RTT = 150ms,5G P99 RTT = 100ms:
ΔT_max = |150 - 100| / 2 = 25ms(平均情况)
但极端情况下(4G 切换时抖动到 194ms,5G 正常 30ms):
ΔT_extreme = |194 - 30| / 2 = 82ms
所以去重窗口 W 至少要 100ms 才能覆盖大部分情况。建议设为 200ms------在极端 ΔT(82ms)基础上保留约 2x 安全余量,应对两路同时发生抖动叠加的场景(4G 切换抖动和 5G NSA 抖动恰好同时发生时,实际 ΔT 可能短暂超过 82ms)。
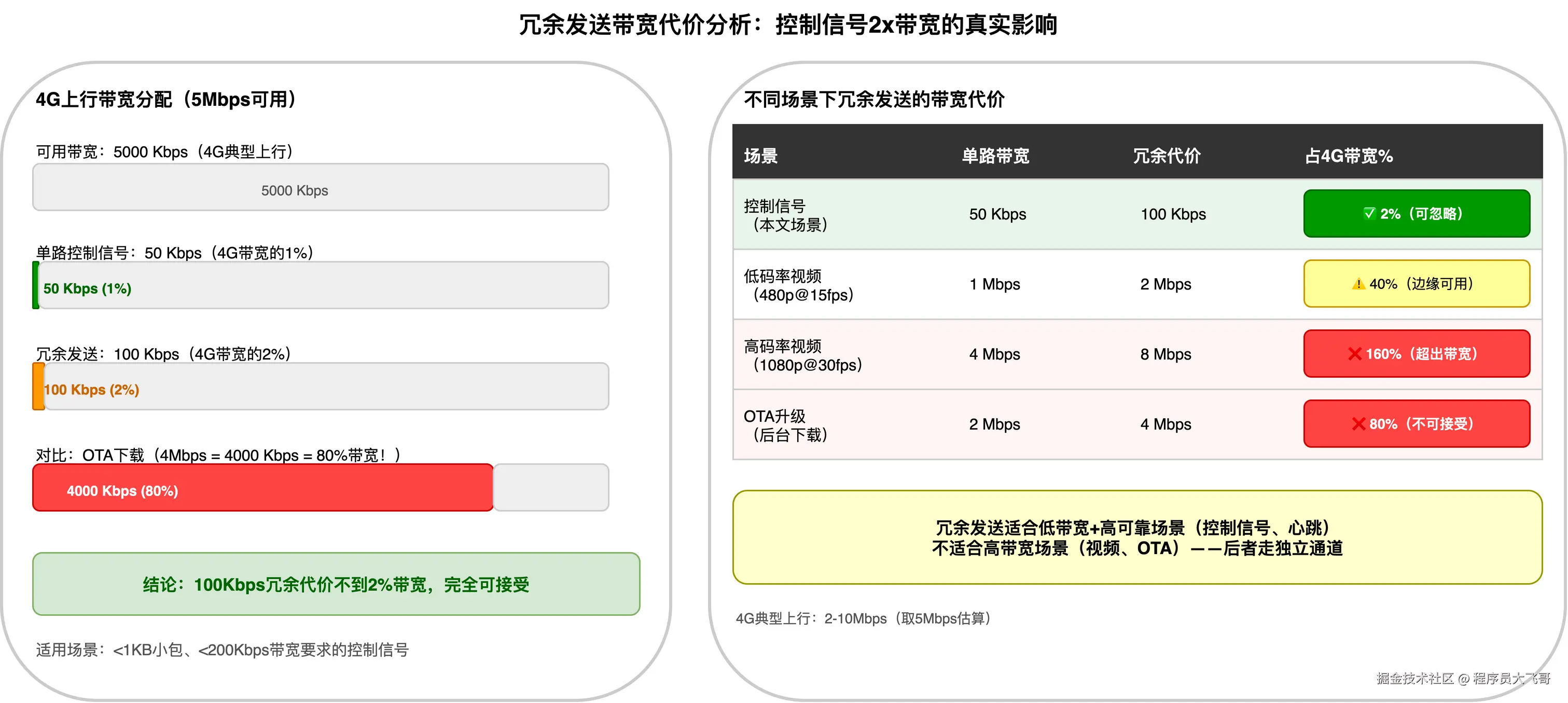
W 太大的代价:内存消耗增加(需要维护更长时间内的 Packet Number 历史),以及如果某个 Packet Number 因网络错误被重用(极小概率),可能误丢弃。200ms 窗口在实践中是安全的。
W 太小的代价:重复包漏过去重,应用层收到同一条控制指令两次,需要应用层自己去重(通过消息序列号)。这会增加应用层复杂度,建议在去重窗口层面解决。
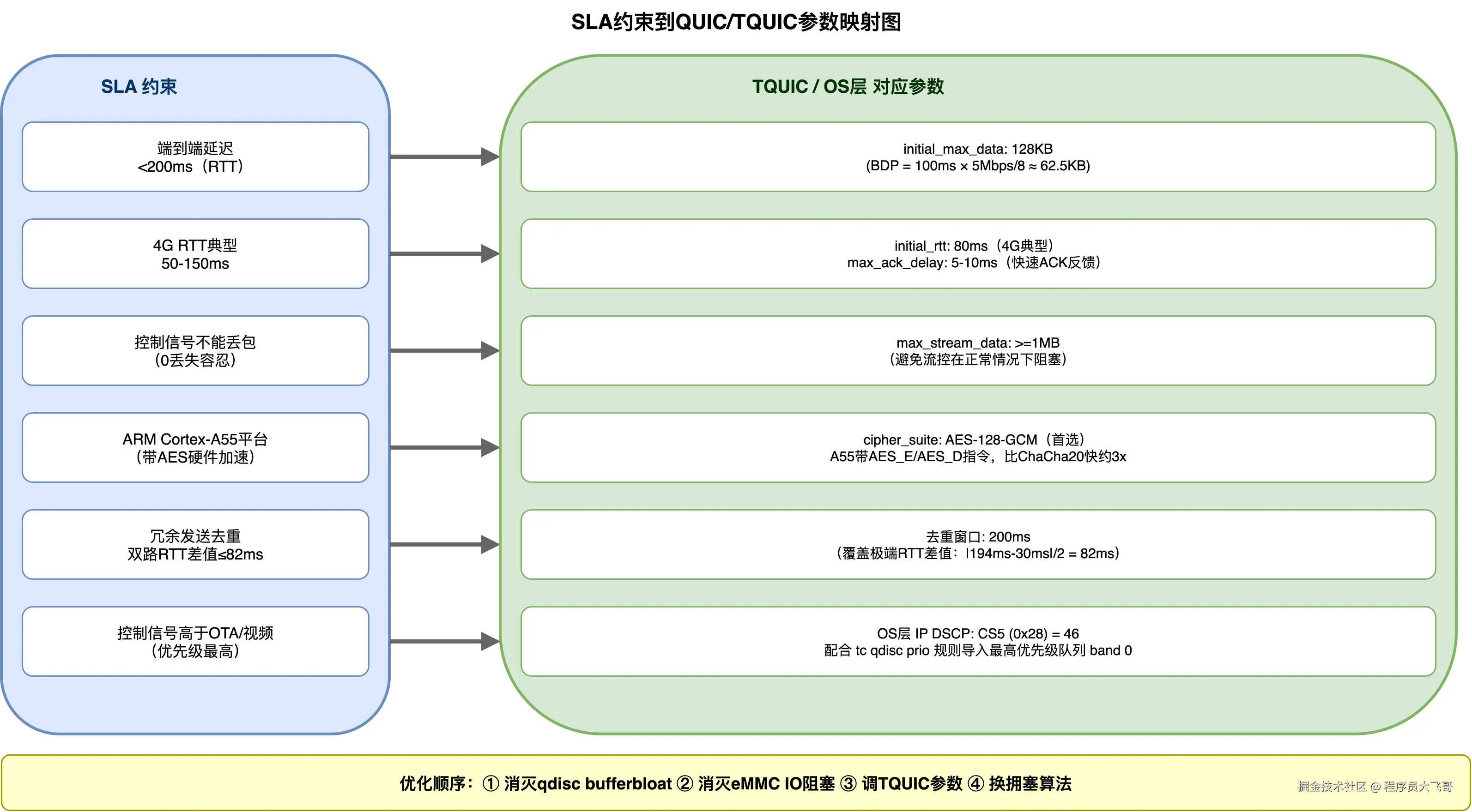
4.2 SLA 约束到 QUIC 参数的映射表
以下是实际部署中,从 SLA 约束推导出 QUIC 配置参数的映射关系:
| SLA 约束 | 影响的参数层 | 具体参数 | 推荐值 | 说明 |
|---|---|---|---|---|
| 传输层单程预算 <70ms | QUIC 流量控制 | initial_max_data |
BDP = RTT × Bandwidth ≈ 100ms × 5Mbps / 8 = 62.5KB → 设 128KB | 避免流量控制窗口限制发送速率 |
| 4G RTT 典型 50-150ms | QUIC ACK 策略 | max_ack_delay |
5-10ms | 降低 ACK 延迟,让发送方更快得到反馈 |
| 4G RTT 典型 50-150ms | 拥塞控制初始值 | initial_rtt |
80ms(4G 典型) | 初始 RTT 估计影响初始拥塞窗口和重传超时 |
| 冗余发送去重 | 应用层配置 | 去重窗口大小 | 200ms | 覆盖极端 RTT 差值(见上节) |
| 控制信号不能丢包 | 流量控制 | max_stream_data |
>=1MB | 避免流量控制在正常情况下阻塞发送 |
| ARM Cortex-A55 | TLS 加密算法 | cipher suite | AES-128-GCM(首选) | A55 带 AES 硬件加速指令,AES-GCM 比 ChaCha20-Poly1305 快约 3x |
| 控制信号优先级高 | OS 层 | IP DSCP | CS5 (0x28) | 配合 qdisc QoS 规则 |
4.3 视频和控制信号的参数为什么不能共用
这个问题在第 03 篇会详细展开,这里先埋一个钩子。
假设你有一个 QUIC 连接同时承载控制信号(stream A)和一些元数据(stream B)。QUIC 的多流设计消除了流级别的队头阻塞------stream A 的包丢了不会阻塞 stream B。听起来没问题。
但是,两个 stream 共享同一个连接的拥塞窗口(cwnd)。 当一个大流量的 stream 把 cwnd 撑开,然后某个大包触发拥塞,cwnd 减半,所有 stream 都要跟着减速。控制信号的 stream 也不例外------即使它本身没有任何问题,它也会受到 cwnd 缩减的影响。
这是 QUIC 多流隔离的一个常见误解,也是为什么控制信号要走独立连接甚至独立通道的原因。更详细的量化分析,见第 03 篇。
bash
# 查看当前 QUIC 连接的 RTT 和 cwnd 统计(需要 qlog)
# 启用 qlog 后,日志文件位于 /tmp/tquic_qlog/
# 解析 qlog 中的 RTT 数据
cat /tmp/tquic_qlog/*.sqlog 2>/dev/null | python3 - << 'EOF'
import json, sys, fileinput
rtts = []
for line in fileinput.input():
line = line.strip()
if not line:
continue
try:
# sqlog 格式:每行是一个 JSON 事件
event = json.loads(line)
if isinstance(event, list) and len(event) >= 3:
# [time, category, event_type, data]
if event[1] == "recovery" and "min_rtt" in str(event):
data = event[3] if len(event) > 3 else {}
if "min_rtt" in data:
rtts.append(data["min_rtt"])
except:
pass
if rtts:
rtts.sort()
print(f"RTT 样本数: {len(rtts)}")
print(f"最小 RTT: {min(rtts)}ms")
print(f"中位 RTT: {rtts[len(rtts)//2]}ms")
print(f"P99 RTT: {rtts[int(len(rtts)*0.99)]}ms")
print(f"最大 RTT: {max(rtts)}ms")
else:
print("未找到 RTT 数据,请确认 qlog 文件路径和格式")
EOF第五章:从数字到行动------正确的优化顺序
有了前面四章的延迟分析,现在可以给出一个清晰的优化优先级框架。
5.1 三层优化,不同的收益量级
第一层:消除 qdisc 异常延迟(优先级最高,收益最大)
不需要改 QUIC,不需要改协议,只需要给 T-Box 的上行接口配置 QoS 优先级。无 QoS 时,qdisc 排队延迟单项就可达 200-300ms,直接顶穿 SLA。配置优先级队列后,qdisc 等待降到接近 0ms,端到端 P99(5G 路径)可稳定在 130-170ms,SLA 余量充足。
操作:给 rmnet0/rmnet1 配置 prio qdisc,把控制信号 UDP 流量(按 DSCP 或目标端口区分)导入最高优先级队列。
第二层:消除进程调度异常(优先级第二,防止 SLA 彻底失效)
把 QUIC 进程的所有 IO 路径迁移到 tmpfs,把日志写入改为异步。这不会降低平均延迟,但会消除偶发性的 0.5-2 秒中断。
操作:改代码,日志路径改到 /tmp,IO 操作异步化。
第三层:调 QUIC 参数(优先级第三,精细化调优)
前两层做完之后,端到端 P99 已经回落到 SLA 预算范围内(5G 路径约 130-170ms),传输层预算(20-70ms)得到充分释放,这时候调 QUIC 参数才有意义------在这个空间内继续压缩尾延迟。但如果 qdisc 没做 QoS,调 QUIC 参数是在 qdisc 已经吃掉 200-300ms 的基础上做精细优化,性价比极低。
第四层:换拥塞算法(最后考虑)
BBR vs Copa vs Cubic 在 4G 网络上的差异通常在 10-30ms 以内。这在前三层完成后才有意义。
5.2 一个快速诊断方法
在不知道当前 P99 超标的根因时,可以用以下步骤快速定位:
bash
# 步骤 1:检查 qdisc 是否有积压
tc -s qdisc show dev rmnet0 | grep backlog
# 如果 backlog > 0 且持续增长:qdisc 是瓶颈
# 步骤 2:检查进程是否有 IO 等待
ps aux | grep tquic
# 如果 STAT 列显示 "D"(不可中断等待):进程在等 IO
# 步骤 3:检查 eMMC IO 延迟
iostat -x mmcblk0 1 5
# 如果 await > 100ms:eMMC GC 在运行
# 步骤 4:如果步骤 1-3 都正常,再看 QUIC 的 qlog RTT
# 参考上一节的 qlog 解析命令
# 最快的单命令诊断:
# 看 qdisc backlog + 进程状态 + IO 延迟,三合一
echo "=== qdisc backlog ===" && tc -s qdisc show dev rmnet0 | grep backlog
echo "=== tquic process state ===" && ps aux | grep -E "tquic|quic" | grep -v grep
echo "=== eMMC IO latency ===" && iostat -x mmcblk0 1 2 | tail -5结尾
回到开头那次压测:P99 卡在 220ms,调了三天 QUIC 参数没用。
最终的解决方案很简单:给 rmnet0 配置了 prio qdisc,把控制信号的 DSCP 标记导入 band 0(最高优先级),关掉了压测脚本里的后台文件上传。qdisc 排队延迟从 180ms 降到了接近 0ms,端到端 P99 从 220ms 回落到 150ms 以内------压测环境是模拟局域网,没有真实空口,所以数字偏低;真实 4G/5G 部署下,端到端 P99 会加上空口延迟,落在 130-200ms 区间。
整个过程里,QUIC 的代码一行没改,QUIC 参数一个没动。
这是这篇文章最想传递的观点:SLA 超标的根因,往往不在传输协议本身。250ms 的延迟预算,传输层能用的只有 20-70ms(P99 场景),而 qdisc 和 eMMC 这两个"系统层"的问题,上限分别是 300ms 和 2000ms------它们任何一个发作,传输层的优化都是杯水车薪。
优化顺序应该是:先消灭 qdisc bufferbloat 和 eMMC IO 阻塞,再调 QUIC 参数,最后才考虑换拥塞算法。很多工程师把这个顺序完全搞反了。
现在延迟预算的框架建立起来了,下一个问题来了:为什么控制信号和视频流必须走完全不同的传输通道?"QUIC 有多个 stream,不是已经隔离了吗"------这个误解,在第 03 篇里用一次凌晨 3 点的告警来解释清楚。