在自然语言处理(NLP)和序列生成任务中,如何从模型的概率分布中生成高质量的输出序列,是一个核心问题。无论是机器翻译、文本摘要,还是语音识别,解码策略直接影响最终结果的准确性、流畅性和多样性。
本文将深入介绍 Beam Search(束搜索)------一种在精度和计算效率之间取得精妙平衡的解码算法。我们将从最朴素的方法出发,逐步揭示 Beam Search 的设计思想、实现细节、优缺点,并探讨其现代变体与实际应用中的最佳实践。
- 引言:为什么需要 Beam Search?
序列生成模型(如 Transformer、RNN)通常输出一个概率分布,表示在每个时间步上词汇表中每个词的概率。解码的任务就是从这些概率中选出一个完整的输出序列。
最直观的两种方法是:
贪心搜索(Greedy Search):在每个时间步直接选择概率最大的词。这种方法计算量最小,但容易陷入局部最优------一旦在某步选错,后续无法修正。
穷举搜索(Exhaustive Search):计算所有可能序列的概率,选择全局最优。这显然不可行,因为搜索空间随序列长度指数增长(词表大小 VVV 的 TTT 次方)。
Beam Search 正是两者的折中:它维护固定数量(束宽 BBB)的候选序列,在每个时间步扩展所有候选,再保留总概率最高的 BBB 个。这样既避免了贪心的短视,又将计算控制在了可控范围内。
- Beam Search 的核心原理
2.1 基本工作流程
假设束宽 B=2B=2B=2,词表大小为 VVV,解码步骤如下:
初始化:从起始标记 开始,生成第一个词的 BBB 个最可能的候选(每个候选是一个部分序列)。
迭代扩展:
对当前维护的 BBB 个候选序列,每个序列分别计算下一个词的 VVV 种可能。
得到 B×VB \times VB×V 个候选扩展序列。
计算每个扩展序列的累积对数概率(通常使用对数概率累加,避免数值下溢)。
按累积概率从高到低排序,保留前 BBB 个。
终止条件:
达到最大生成长度。
所有 BBB 个候选序列都以结束标记 结尾。
输出选择:从所有已完成的候选序列中,选择概率最高的作为最终输出。
2.2 概率计算
序列 y1,y2,...,yty_1, y_2, ..., y_ty1,y2,...,yt 的联合概率为:
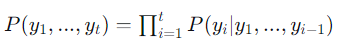
为避免极小数相乘,通常使用对数概率:
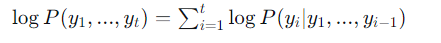
扩展时,每个新候选的分数 = 父序列的累积对数概率 + 当前词的对数概率。
2.3 一个具体示例
假设束宽 B=2B=2B=2,模型在第一步输出:
"the": -0.5
"a": -0.8
其余词概率更低。初始保留 "the" 和 "a"。
第二步,从 "the" 扩展得到:
"the cat": -1.2
"the dog": -1.5
"the a": -2.0 ...
从 "a" 扩展得到:
"a cat": -1.6
"a dog": -1.4
"a the": -2.2 ...
合并所有候选,按分数排序:
"the cat": -1.2
"a dog": -1.4
"the dog": -1.5
"a cat": -1.6
...
保留前 2 个:"the cat", "a dog"。如此反复,直到结束。
- Beam Search 的关键要素
3.1 束宽(Beam Width)
束宽 BBB 是 Beam Search 最关键的参数:
BBB 越大:搜索空间越大,越接近全局最优,但计算开销线性增长。当 BBB 等于词表大小时,退化(近似)为穷举搜索。
BBB 越小:速度越快,但更接近贪心搜索,容易丢失优质候选。
实践建议:机器翻译常用 B=4B=4B=4 或 555;文本摘要可稍大(888 或 101010);对话生成有时用 B=1B=1B=1(即贪心)以增加多样性。需根据任务特性与计算资源权衡。
3.2 长度归一化(Length Normalization)
Beam Search 天然偏向短序列,因为对数概率是负值累加,序列越长累加值越小(负得越多)。这导致算法倾向于选择更短的句子,即使其平均词概率较低。
解决方案是长度归一化:用序列长度对累积对数概率进行归一化。
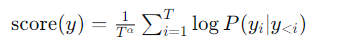
其中 TTT 为序列长度,α\alphaα 为平滑系数(通常 0.6≤α≤10.6 \le \alpha \le 10.6≤α≤1)。α=1\alpha=1α=1 时等价于取几何平均,α=0\alpha=0α=0 时不作归一化。
3.3 覆盖惩罚(Coverage Penalty)
在机器翻译、摘要等任务中,模型可能重复生成相同内容或遗漏源端信息。覆盖惩罚机制在分数中加入对已覆盖内容的惩罚项,鼓励模型关注未翻译或未提及的部分。
常见的实现方式:维护一个覆盖向量,记录源端每个位置已被"注意"的程度,对重复关注的位置施加惩罚。
- Beam Search 的局限与改进
尽管 Beam Search 应用广泛,但它并非完美无缺。近年来研究者指出了几个关键问题:
4.1 多样性不足
Beam Search 维护的 BBB 个候选往往高度相似------它们共享公共前缀,仅在结尾略有差异。这在需要多样化输出的场景(如创意写作、对话生成)中成为缺陷。
改进方向:
** Diverse Beam Search **:在候选间引入多样性惩罚,强制各 beam 在早期就产生差异。
采样方法:如 Top-kkk 采样、核采样(Nucleus Sampling),通过从概率最高的 kkk 个词或累积概率超过阈值 ppp 的词中随机采样,牺牲一定准确性换取多样性。
4.2 质量与多样性的权衡
对于翻译、摘要等客观任务,Beam Search 仍是首选------准确性优先于多样性。但对于开放域生成任务,采样方法往往能产生更自然、更富创意的结果。
4.3 计算效率
标准 Beam Search 是顺序解码,难以并行化。对于实时性要求高的场景,可采用以下优化:
缓存机制:缓存已计算的注意力权重和隐藏状态。
投机解码(Speculative Decoding):用小型模型快速生成候选,再由大模型并行验证。
- 实践中的最佳实践
基于大量实验和应用经验,以下是使用 Beam Search 的一些实用建议:
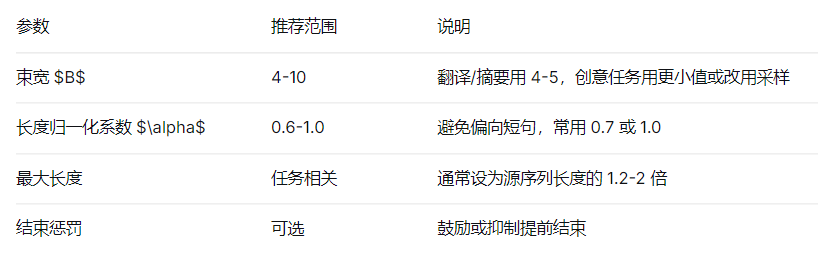
此外,还需注意:
始终使用对数概率,避免浮点下溢。
早期截断:当某候选序列以 结束时,将其保留为最终候选,不再扩展。
批次处理:实现时可将不同长度的序列填充对齐,利用矩阵运算加速。
- 代码实现示例
以下是一个简化的 Beam Search 实现(Python 伪代码),展示了核心逻辑:
python
import numpy as np
def beam_search(model, start_token, beam_width, max_len, alpha=0.7):
# 初始化: (序列, 累积对数概率)
beams = [([start_token], 0.0)]
completed = []
for _ in range(max_len):
all_candidates = []
for seq, score in beams:
if seq[-1] == end_token:
completed.append((seq, score))
continue
# 获取下一个词的概率分布 (模型前向)
probs = model.predict(seq) # 形状: (vocab_size,)
log_probs = np.log(probs)
# 扩展所有可能的词
for word_idx, log_prob in enumerate(log_probs):
new_seq = seq + [word_idx]
new_score = score + log_prob
all_candidates.append((new_seq, new_score))
# 按分数排序并保留前 beam_width 个
all_candidates.sort(key=lambda x: x[1], reverse=True)
beams = all_candidates[:beam_width]
# 如果所有 beam 都已结束,提前终止
if all(seq[-1] == end_token for seq, _ in beams):
break
# 合并已完成和未完成的候选,应用长度归一化
all_candidates = completed + beams
for seq, score in all_candidates:
if seq[-1] != end_token:
seq = seq + [end_token]
# 长度归一化
length = len(seq)
normalized_score = score / (length ** alpha)
all_candidates.append((seq, normalized_score))
# 返回最佳序列
best = max(all_candidates, key=lambda x: x[1])
return best[0]- 总结与展望
Beam Search 诞生至今已逾二十年,凭借其在精度与效率之间的优雅平衡,成为序列生成任务中最经典、最稳定的解码算法之一。它并不复杂,但细节之处见真章------束宽的选择、长度归一化、覆盖机制等,都需要根据具体任务精心调优。
当然,算法的发展从未停止。随着大规模语言模型的兴起,采样方法(Top-kkk、核采样)因其更好的多样性和自然度而受到青睐;而在一些需要高精度输出的场景,Beam Search 依然不可替代。理解其原理,不仅能帮助我们更好地使用现有模型,也能为设计更复杂的解码策略打下基础。
未来,随着模型规模的持续增长和应用场景的不断拓展,解码算法也将继续演进------在准确性、多样性、效率和可控性之间寻找新的平衡点。