家人们我又更新了,代码和科研绘图在论文末尾,欢迎大家评论点赞和收藏,你们的认可是我坚持的动力,祝大家科研顺利。
因果推断 | CATE条件平均处理效应估计:五大方法原理详解与模拟数据实战
本文是因果推断系列文章。本篇聚焦 CATE(Conditional Average Treatment Effect,条件平均处理效应) 的估计,从ATE的局限性讲起,深入介绍S-Learner、T-Learner、X-Learner、因果森林DML和线性DML五种主流方法的原理,并在模拟数据上进行完整的代码实操与效果对比。
1 从ATE到CATE:为什么需要异质性处理效应?
1.1 ATE只能回答"平均有没有用"
ATE(Average Treatment Effect)回答的是:干预措施对整个群体的平均效果是什么?
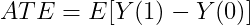
但在实际业务中,我们更想知道的是:对于不同的个体或子群,干预效果有什么不同?
举几个例子:
- 精准营销:给所有人发满减券ATE为正,但拆开看,高消费用户根本不需要券,低消费用户反而是增量用户------CATE帮你找到真正的增量人群。
- 个性化医疗:某新药对年轻患者效果显著,对老年患者副作用大于疗效------只看ATE可能得出"有效"的结论,但对老年患者施加干预反而有害。
- 政策评估:教育补贴对低收入家庭的效果远大于高收入家庭------CATE可以指导财政资源的精细化分配。
1.2 CATE的数学定义
CATE(条件平均处理效应)定义为:
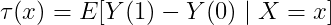
其中:
- Y(1):个体接受处理时的潜在结果
- Y(0):个体未接受处理时的潜在结果
- X:协变量/特征向量
- τ(x):给定特征x条件下的处理效应
CATE是协变量X的函数,刻画了处理效应的异质性(Heterogeneity)。ATE只是CATE的期望:
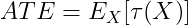
1.3 估计CATE的核心难点
根本问题(Fundamental Problem of Causal Inference):对同一个个体,我们只能观察到一种潜在结果。要么看到Y(1),要么看到Y(0),不可能同时观察到两者。
因此,τ(x) = EY(1) - Y(0) \| X=x 不能直接通过数据计算,需要借助统计方法来估计。
2 五大CATE估计方法原理详解
下面介绍五种最常用的CATE估计方法,按照"从简单到复杂"的顺序排列。
2.1 S-Learner(Single Model Learner)
核心思想 :把处理变量T当作一个普通特征,训练一个统一的模型。
步骤:
- 将T拼接到协变量X中,训练模型 μ̂(X, T) 拟合结果Y
- CATE估计:
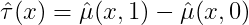
优点:实现最简单,只需训练一个模型。
缺点 :当使用正则化模型(如Lasso、随机森林)时,模型可能认为T的贡献不重要而将其效应缩小甚至忽略,导致CATE估计偏向于零(regularization bias)。
def s_learner(X, T, Y):
XT = np.column_stack([X, T])
model = GradientBoostingRegressor(n_estimators=200, max_depth=4)
model.fit(XT, Y)
tau_hat = model.predict(np.c_[X, np.ones(len(X))]) \
- model.predict(np.c_[X, np.zeros(len(X))])
return tau_hat2.2 T-Learner(Two Model Learner)
核心思想 :处理组和控制组各自训练一个模型,然后做差。
步骤:
- 用处理组数据训练 μ̂₁(x) 拟合 EY\|X=x, T=1
- 用控制组数据训练 μ̂₀(x) 拟合 EY\|X=x, T=0
- CATE估计:
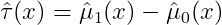
优点:允许处理组和控制组的结果模型完全不同,灵活性高。
缺点:当处理组或控制组样本很少时,对应的模型估计不准确。两个独立模型的误差会叠加。
def t_learner(X, T, Y):
model_1 = GradientBoostingRegressor().fit(X[T==1], Y[T==1])
model_0 = GradientBoostingRegressor().fit(X[T==0], Y[T==0])
tau_hat = model_1.predict(X) - model_0.predict(X)
return tau_hat2.3 X-Learner(Cross Learner)
核心思想:利用"反事实插补"的思想,用一个组的模型去预测另一个组的反事实结果,弥补T-Learner在样本不均衡时的不足。出自 Künzel et al. (2019) 的经典论文。
步骤(三阶段):
阶段1:分别拟合结果模型(同T-Learner),训练控制组模型 μ̂₀(x) 和处理组模型 μ̂₁(x)。
阶段2:计算伪处理效应(Imputed Treatment Effects)
对处理组个体(观测结果 - 预测的反事实):
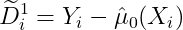
对控制组个体(预测的反事实 - 观测结果):
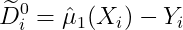
阶段3:拟合CATE模型并加权
- 处理组CATE模型 τ̂₁(x) 拟合 D̃¹ ~ X
- 控制组CATE模型 τ̂₀(x) 拟合 D̃⁰ ~ X
- 最终CATE:
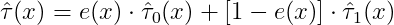
其中e(x)是倾向性得分。直觉是:哪个组样本多,就更多地依赖那个组的CATE估计。
优点:在处理组/控制组样本严重不均衡时表现远优于T-Learner。
2.4 因果森林DML(CausalForestDML)
核心思想 :结合双重机器学习(DML)的去偏框架 和因果森林来捕捉非线性异质性效应。
步骤(两阶段):
第一阶段------去偏/正交化(Orthogonalization):
使用机器学习模型去除协变量对Y和T的影响:
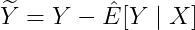
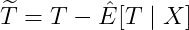
关键操作是交叉拟合(Cross-Fitting):将数据分为K折,每折用其余K-1折训练的模型来预测当前折,避免过拟合偏差。
第二阶段------CATE估计:
用因果森林(Generalized Random Forest)在残差Ỹ和T̃上估计异质性效应τ(X)。因果森林的分裂准则:最大化子节点间处理效应差异(而非预测误差)。
优点:能捕捉复杂的非线性CATE模式,同时DML去偏保证了估计的无偏性。
2.5 线性DML(LinearDML)
核心思想 :与因果森林DML共享相同的第一阶段去偏过程,但第二阶段假设CATE是协变量的线性函数:
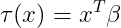
优点:
- 可解释性极强:β的每个分量直接告诉你对应特征对CATE的边际效应
- 提供统计推断:可以输出系数的置信区间和p值
- 适合特征影响近似线性的场景
缺点:无法捕捉非线性异质性(如我们模拟数据中X₂²的效应)。
2.6 方法对比总结
| 方法 | 模型数 | 能否捕捉非线性CATE | 是否去偏 | 是否有置信区间 | 适用场景 |
|---|---|---|---|---|---|
| S-Learner | 1 | 是 | 否 | 否 | 快速基线 |
| T-Learner | 2 | 是 | 否 | 否 | 样本均衡 |
| X-Learner | 4+ | 是 | 部分 | 否 | 样本不均衡 |
| CausalForestDML | 多 | 强 | 是 | 是 | 通用首选 |
| LinearDML | 多 | 否 | 是 | 是 | 需要可解释性 |
3 模拟数据设计(DGP)
为了公平评估各方法,我们设计了如下的数据生成过程(DGP):
3.1 变量设计
| 符号 | 说明 |
|---|---|
| X(5维) | 协变量,服从标准正态分布 |
| T(0或1) | 二值处理变量 |
| Y(连续) | 结果变量 |
3.2 数据生成公式
真实CATE函数:
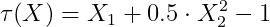
设计意图:
- X₁ :对CATE有线性影响
- X₂ :对CATE有**非线性(二次)**影响
- X₃, X₄, X₅ :对CATE无影响(噪声特征)
倾向性得分(处理分配机制):
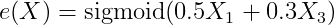
X₁和X₃同时影响处理分配和结果(混淆变量),这使得朴素估计存在偏差。
基线结果函数:
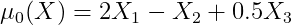
观测结果:
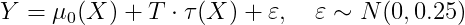
3.3 数据生成代码
def generate_data(n=5000, seed=42):
np.random.seed(seed)
X = np.random.randn(n, 5)
X1, X2, X3 = X[:, 0], X[:, 1], X[:, 2]
# 真实CATE
tau_true = X1 + 0.5 * X2**2 - 1.0
# 倾向性得分(存在混淆)
e_x = 1.0 / (1.0 + np.exp(-(0.5*X1 + 0.3*X3)))
T = np.random.binomial(1, e_x)
# 基线结果 + 处理效应 + 噪声
Y = (2.0*X1 - X2 + 0.5*X3) + T * tau_true + np.random.randn(n)*0.5
return X, T, Y, tau_true4 实验结果
4.1 评估指标
MSE(均方误差):
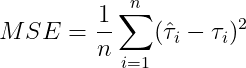
Bias(平均偏差):
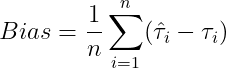
| 指标 | 含义 | 越小/大越好 |
|---|---|---|
| MSE | 均方误差 | 越小越好 |
| MAE | 平均绝对误差 | 越小越好 |
| Bias | 平均偏差 | 越接近0越好 |
| R² | 对真实CATE变异的解释比例 | 越大越好 |
| Corr | 与真实CATE的相关系数 | 越大越好 |
4.2 各方法评估结果
以n=5000的模拟数据运行结果:
| 方法 | MSE | MAE | Bias | R² | Corr |
|---|---|---|---|---|---|
| S-Learner | 0.1003 | 0.2168 | 0.0469 | 0.9362 | 0.9788 |
| T-Learner | 0.1311 | 0.2652 | 0.0474 | 0.9166 | 0.9593 |
| X-Learner | 0.0516 | 0.1539 | 0.0226 | 0.9672 | 0.9840 |
| DML-CausalForest | 0.1329 | 0.2220 | 0.0666 | 0.9155 | 0.9648 |
| DML-Linear | 0.7658 | 0.7626 | 0.5035 | 0.5132 | 0.8220 |
4.3 结果分析
1. X-Learner表现最优(MSE=0.0516, R²=0.9672)
X-Learner通过反事实插补和倾向性加权,充分利用了两组数据的信息互补。在本实验中MSE最低、R²最高,是五种方法中表现最好的。
2. S-Learner表现稳健(MSE=0.1003, R²=0.9362)
S-Learner只用了一个模型,但GBT能自动捕捉T与X的交互效应,表现仅次于X-Learner。在快速验证场景下是很好的基线方法。
3. DML-CausalForest受限于简化实现
本代码中的DML-CausalForest是基于"残差比值+随机森林"的简化实现。完整的因果森林(如EconML的CausalForestDML)使用专门的因果分裂准则,效果会更好。如果安装了econml,建议直接使用CausalForestDML。
4. DML-Linear的局限性(MSE=0.7658, R²=0.5132)
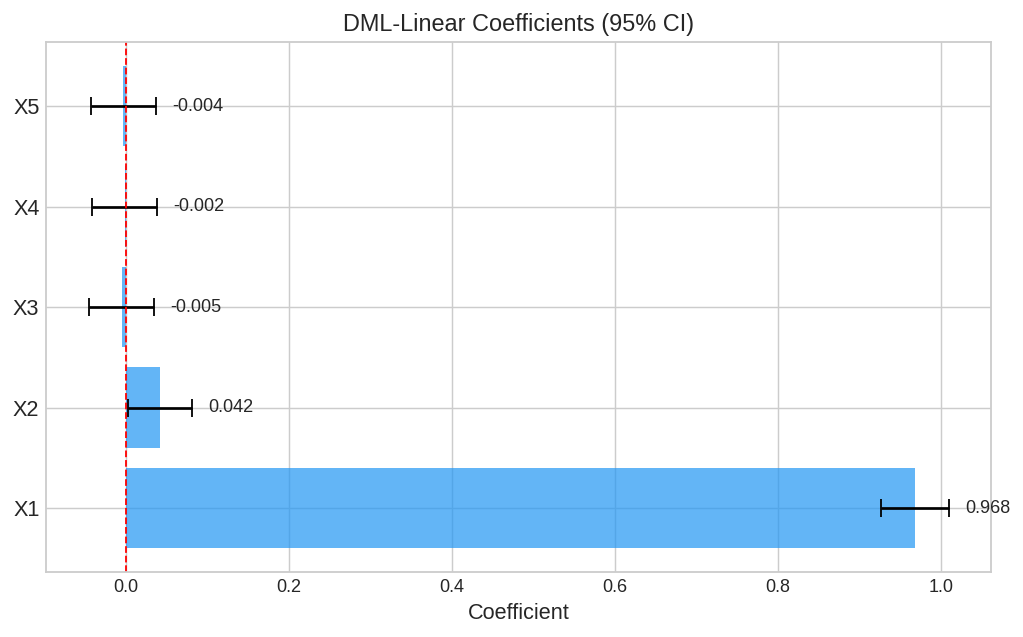
由于真实CATE包含X₂²项(非线性),LinearDML无法捕捉这部分异质性。但它成功识别出了X1的系数约为1.0(真实值为1.0),X3/X4/X5的系数接近0(符合真实DGP)。当你需要可解释的系数和置信区间时,LinearDML仍有不可替代的价值。
5. T-Learner中规中矩
T-Learner独立训练两个模型,误差会叠加。在样本不均衡或效应较弱时劣势更明显。
5 可视化解读
5.1 CATE估计值 vs 真实值散点图
每个子图展示一种方法的估计值(纵轴)与真实CATE(横轴)的关系。理想情况下所有点应落在对角线上。
- X-Learner的点最紧密地围绕对角线
- LinearDML由于线性假设,在CATE极端值处偏离明显
【在此插入 fig1_cate_scatter.png】
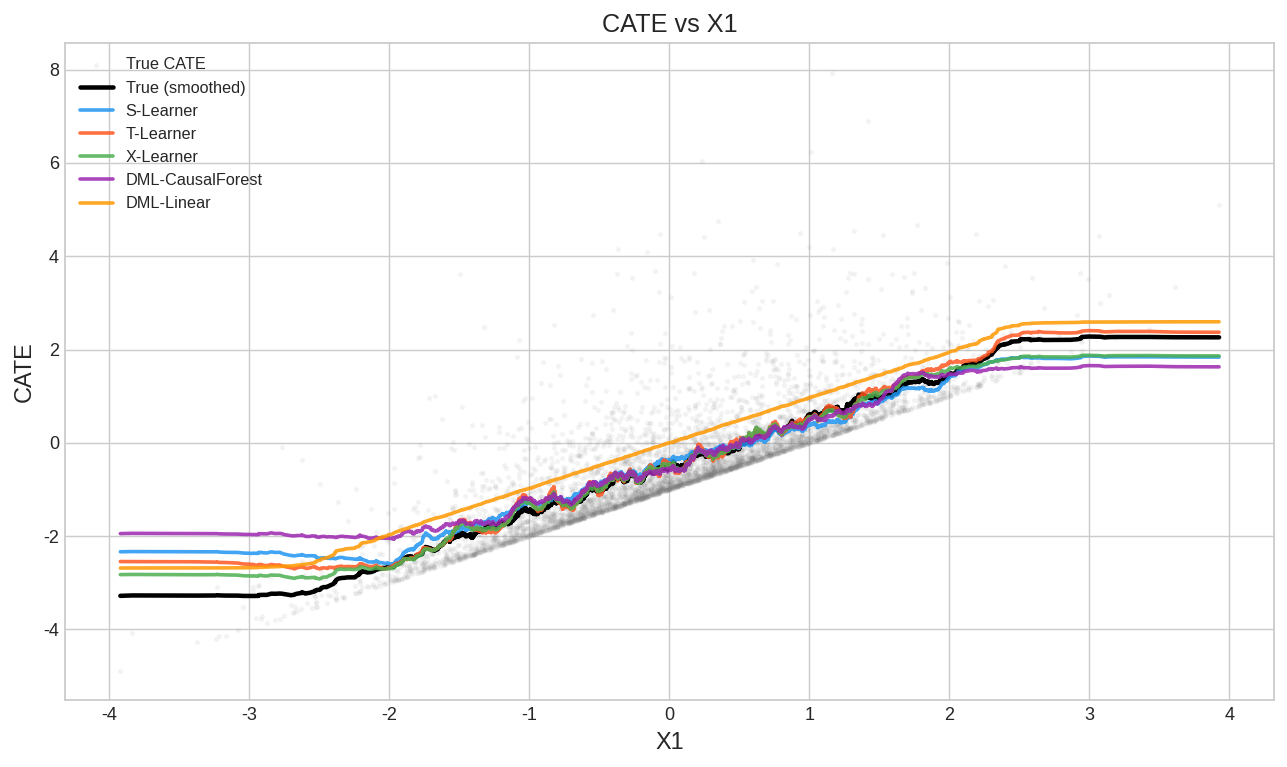
5.2 CATE随X1变化趋势
真实CATE与X1呈线性关系(τ随X1增大而增大)。可以看到:
- 所有方法都能捕捉到这个线性趋势
- 差异主要体现在噪声大小和边缘区域的偏差
【在此插入 fig2_cate_by_x1.png】
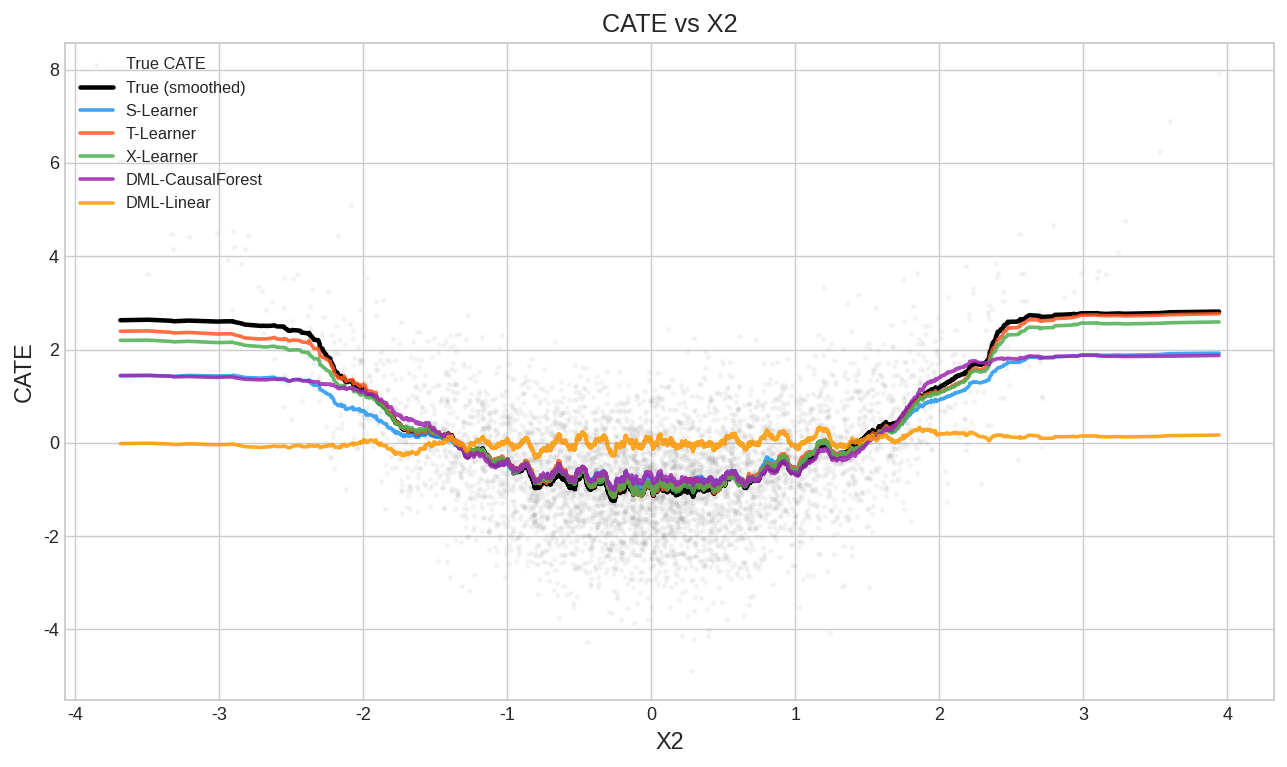
5.3 CATE随X2变化趋势
真实CATE与X2呈U型关系(X₂²项)。这是对各方法的关键测试:
- CausalForestDML和X-Learner能较好地还原U型
- LinearDML只能拟合出线性趋势,完全丢失了非线性信息
【在此插入 fig2b_cate_by_x2.png】
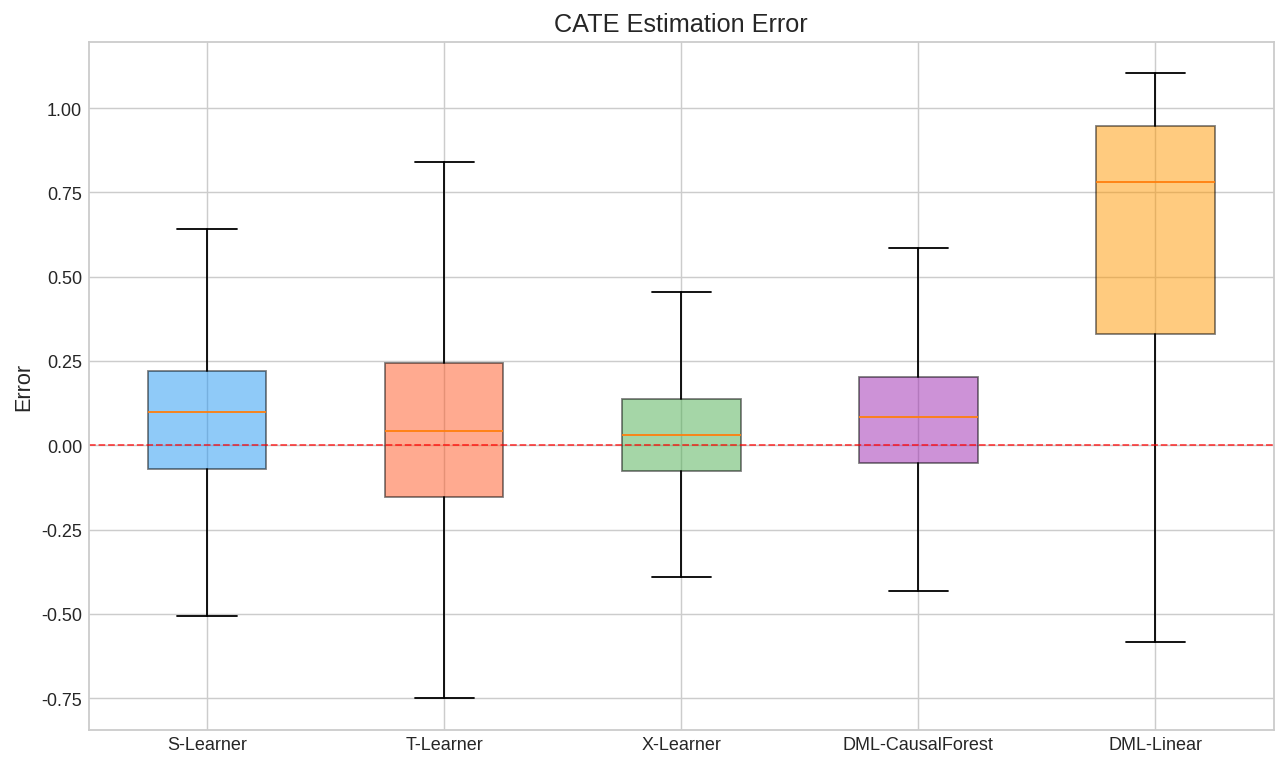
5.4 误差箱线图
箱线图展示各方法估计误差的分布:
- 中位线接近0说明无偏
- 箱体越窄说明估计越精确
- X-Learner的箱体最窄且最居中
【在此插入 fig4_error_boxplot.png】
6 实战建议与方法选择指南
6.1 该用哪种方法?
根据你的实际需求选择:
场景1:快速验证异质性是否存在 → 先用 S-Learner 或 T-Learner 作为基线。
场景2:样本不均衡(处理组远少于控制组) → 优先选择 X-Learner。
场景3:需要无偏估计 + 非线性CATE → 使用 CausalForestDML(推荐首选)。
场景4:需要系数可解释性和置信区间 → 使用 LinearDML,可输出每个特征对CATE的边际效应。
场景5:高维稀疏特征 → 使用 SparseLinearDML(EconML提供),自动做特征选择。
6.2 注意事项
- SUTVA假设:个体间无干扰(Stable Unit Treatment Value Assumption)
- 无未观测混淆:所有影响T和Y的变量都被纳入X(Unconfoundedness)
- 正值假设:0 < e(X) < 1,每个个体都有可能被分配到任一组(Overlap / Positivity)
- 交叉拟合很重要:DML方法中的cross-fitting可以有效降低过拟合偏差
- 基学习器选择:第一阶段的ML模型不宜过于复杂,避免引入额外偏差
7 完整代码
完整代码文件 cate_simulation.py 包含:
- 数据生成函数(可调节样本量、效应强度、混淆程度)
- 5种CATE估计方法的实现
- 评估指标计算
- 6张可视化图表的生成
环境安装:
pip install numpy pandas matplotlib scikit-learn scipy注:本代码纯sklearn实现,无需econml。如需使用完整的CausalForestDML,额外安装 pip install econml
运行方式:
python cate_simulation.py运行后会在当前目录生成以下图表文件:
| 文件名 | 内容 |
|---|---|
| fig1_cate_scatter.png | 各方法 CATE 估计 vs 真实值散点图 |
| fig2_cate_by_x1.png | CATE 随 X1 变化趋势对比 |
| fig2b_cate_by_x2.png | CATE 随 X2 变化趋势对比 |
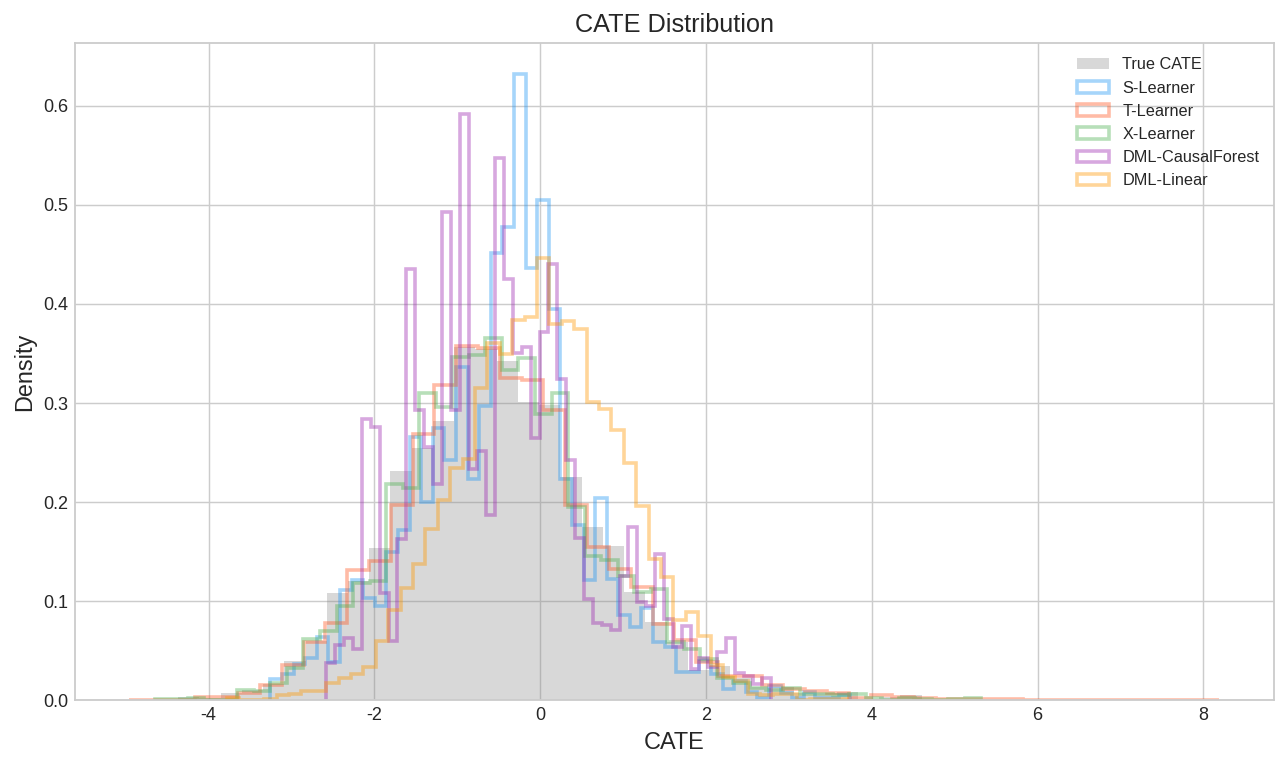
| fig3_cate_dist.png | CATE 估计值分布直方图 |
| fig4_error_boxplot.png | 估计误差箱线图 |
| fig5_dml_linear_coef.png | LinearDML 系数(含置信区间) |
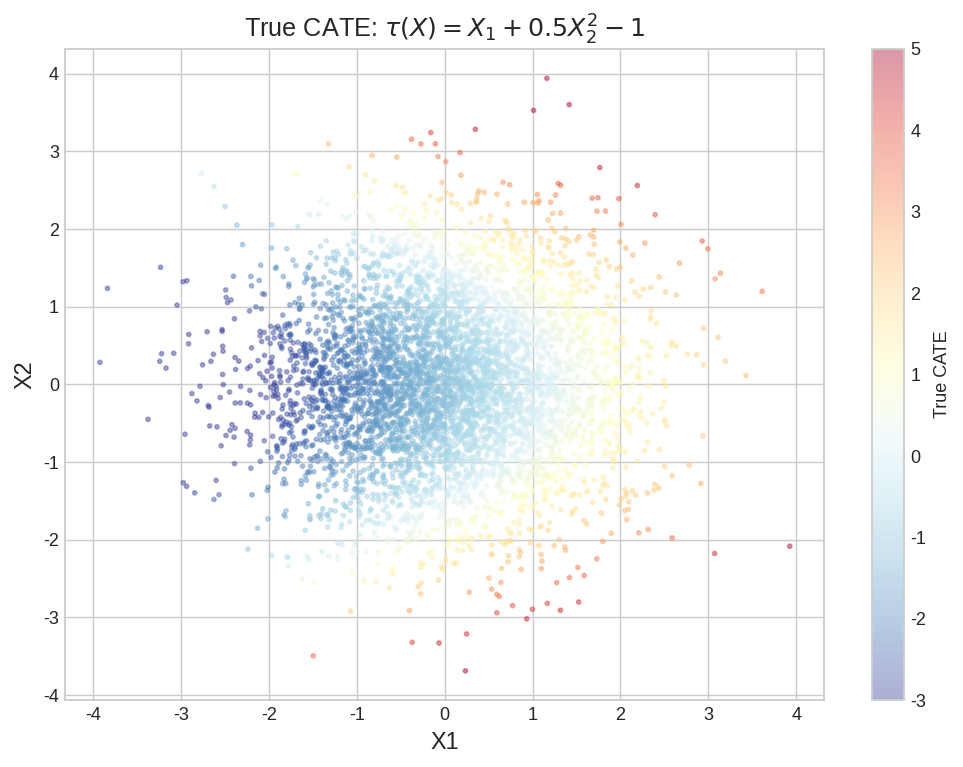
| fig6_true_cate_heatmap.png | 真实 CATE 在 X1-X2 平面的热力图 |
8 总结
| 要点 | 说明 |
|---|---|
| CATE是什么 | 条件平均处理效应,刻画处理效应的异质性 |
| 为什么需要CATE | ATE是"一刀切",CATE支持个性化决策 |
| 核心难点 | 反事实不可观测,需要统计方法估计 |
| 推荐方法 | CausalForestDML(通用首选)+ LinearDML(需要可解释性时) |
| 关键假设 | 无未观测混淆 + SUTVA + Positivity |
下一篇我们将介绍DML在真实数据集上的应用实战,敬请期待!
参考文献
- Künzel S R, Sekhon J S, Bickel P J, et al. Metalearners for estimating heterogeneous treatment effects using machine learningJ. PNAS, 2019.
- Chernozhukov V, Chetverikov D, Demirer M, et al. Double/debiased machine learning for treatment and structural parametersJ. The Econometrics Journal, 2018.
- Athey S, Tibshirani J, Wager S. Generalized random forestsJ. The Annals of Statistics, 2019.
- EconML Documentation: https://econml.azurewebsites.net/
python
"""
因果推断 | CATE(条件平均处理效应)估计方法:模拟数据下的完整实战
=================================================================
包含以下方法:
1. S-Learner 2. T-Learner 3. X-Learner
4. DML + 因果森林 5. DML + 线性模型
全部基于 numpy / sklearn 实现,无需 econml。
"""
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
from matplotlib import rcParams
from scipy.ndimage import uniform_filter1d
import warnings
warnings.filterwarnings('ignore')
rcParams['font.sans-serif'] = ['DejaVu Sans']
rcParams['axes.unicode_minus'] = False
plt.style.use('seaborn-v0_8-whitegrid')
COLORS = ['#2196F3', '#FF5722', '#4CAF50', '#9C27B0', '#FF9800']
from sklearn.ensemble import GradientBoostingRegressor, RandomForestRegressor
from sklearn.linear_model import LogisticRegression, LinearRegression
from sklearn.model_selection import KFold
# ==================== DGP ====================
def generate_data(n=5000, seed=42):
np.random.seed(seed)
X = np.random.randn(n, 5)
X1, X2, X3 = X[:,0], X[:,1], X[:,2]
tau_true = X1 + 0.5*X2**2 - 1.0
logit_e = 0.5*X1 + 0.3*X3
e_x = 1.0/(1.0+np.exp(-logit_e))
T = np.random.binomial(1, e_x)
mu_0 = 2.0*X1 - X2 + 0.5*X3
Y = mu_0 + T*tau_true + np.random.randn(n)*0.5
print("="*60)
print(" Data Summary")
print("="*60)
print(f" n={n} dim={X.shape[1]} treat_rate={T.mean():.3f} ATE={tau_true.mean():.3f}")
print(f" CATE range: [{tau_true.min():.2f}, {tau_true.max():.2f}]")
print("="*60)
return X, T, Y, tau_true
# ==================== Methods ====================
def s_learner(X, T, Y):
XT = np.column_stack([X, T])
m = GradientBoostingRegressor(n_estimators=200, max_depth=4, learning_rate=0.1, random_state=42)
m.fit(XT, Y)
return m.predict(np.c_[X, np.ones(len(X))]) - m.predict(np.c_[X, np.zeros(len(X))])
def t_learner(X, T, Y):
m1 = GradientBoostingRegressor(n_estimators=200, max_depth=4, learning_rate=0.1, random_state=42)
m0 = GradientBoostingRegressor(n_estimators=200, max_depth=4, learning_rate=0.1, random_state=42)
m1.fit(X[T==1], Y[T==1]); m0.fit(X[T==0], Y[T==0])
return m1.predict(X) - m0.predict(X)
def x_learner(X, T, Y):
m1 = GradientBoostingRegressor(n_estimators=200, max_depth=4, learning_rate=0.1, random_state=42)
m0 = GradientBoostingRegressor(n_estimators=200, max_depth=4, learning_rate=0.1, random_state=42)
m1.fit(X[T==1], Y[T==1]); m0.fit(X[T==0], Y[T==0])
D1 = Y[T==1] - m0.predict(X[T==1])
D0 = m1.predict(X[T==0]) - Y[T==0]
tm1 = GradientBoostingRegressor(n_estimators=200, max_depth=4, learning_rate=0.1, random_state=42)
tm0 = GradientBoostingRegressor(n_estimators=200, max_depth=4, learning_rate=0.1, random_state=42)
tm1.fit(X[T==1], D1); tm0.fit(X[T==0], D0)
ps = LogisticRegression(random_state=42, max_iter=1000); ps.fit(X, T)
e = ps.predict_proba(X)[:,1]
return e*tm0.predict(X) + (1-e)*tm1.predict(X)
def dml_cross_fit(X, T, Y, n_splits=5):
kf = KFold(n_splits=n_splits, shuffle=True, random_state=42)
Y_res, T_res = np.zeros(len(Y)), np.zeros(len(T), dtype=float)
for tr, te in kf.split(X):
my = GradientBoostingRegressor(n_estimators=100, max_depth=3, learning_rate=0.1, random_state=42)
mt = GradientBoostingRegressor(n_estimators=100, max_depth=3, learning_rate=0.1, random_state=42)
my.fit(X[tr], Y[tr]); mt.fit(X[tr], T[tr].astype(float))
Y_res[te] = Y[te] - my.predict(X[te])
T_res[te] = T[te] - mt.predict(X[te])
return Y_res, T_res
def dml_causal_forest(X, T, Y):
Y_res, T_res = dml_cross_fit(X, T, Y)
T_clip = np.clip(np.abs(T_res), 0.01, None)*np.sign(T_res)
T_clip[T_clip==0] = 0.01
pseudo = Y_res / T_clip
q_lo, q_hi = np.percentile(pseudo, [2, 98])
pseudo = np.clip(pseudo, q_lo, q_hi)
rf = RandomForestRegressor(n_estimators=300, max_depth=6, min_samples_leaf=20, random_state=42)
rf.fit(X, pseudo)
return rf.predict(X)
def dml_linear(X, T, Y):
Y_res, T_res = dml_cross_fit(X, T, Y)
Z = T_res.reshape(-1,1) * X
reg = LinearRegression(fit_intercept=True); reg.fit(Z, Y_res)
tau_hat = X @ reg.coef_ + reg.intercept_
resid = Y_res - reg.predict(Z)
n, p = Z.shape
sigma2 = np.sum(resid**2)/(n-p-1)
se = np.sqrt(np.diag(sigma2 * np.linalg.inv(Z.T@Z + 1e-8*np.eye(p))))
return tau_hat, reg.coef_, se
# ==================== Evaluation ====================
def evaluate(tau_true, tau_hat, name):
mse = np.mean((tau_true-tau_hat)**2)
mae = np.mean(np.abs(tau_true-tau_hat))
bias = np.mean(tau_hat-tau_true)
ss_res = np.sum((tau_true-tau_hat)**2)
ss_tot = np.sum((tau_true-tau_true.mean())**2)
r2 = 1 - ss_res/ss_tot
corr = np.corrcoef(tau_true, tau_hat)[0,1]
return {'Method':name, 'MSE':round(mse,4), 'MAE':round(mae,4),
'Bias':round(bias,4), 'R2':round(r2,4), 'Corr':round(corr,4)}
# ==================== Plots ====================
def plot_scatter(tau_true, res, path='fig1_cate_scatter.png'):
n = len(res)
fig, axes = plt.subplots(1, n, figsize=(3.8*n, 4), dpi=130)
if n==1: axes=[axes]
for i,(name,th) in enumerate(res.items()):
ax=axes[i]
ax.scatter(tau_true, th, alpha=0.12, s=6, c=COLORS[i%5])
lims=[min(tau_true.min(),th.min())-0.5, max(tau_true.max(),th.max())+0.5]
ax.plot(lims,lims,'k--',lw=1,alpha=0.5)
c=np.corrcoef(tau_true,th)[0,1]; m=np.mean((tau_true-th)**2)
ax.set_title(f'{name}\nCorr={c:.3f} MSE={m:.3f}',fontsize=10)
ax.set_xlabel('True CATE',fontsize=9)
if i==0: ax.set_ylabel('Estimated CATE',fontsize=9)
plt.tight_layout(); plt.savefig(path,bbox_inches='tight'); plt.close()
print(f" [saved] {path}")
def plot_by_feature(X, tau_true, res, fi=0, fn='X1', path='fig2_cate_by_x1.png'):
fig,ax=plt.subplots(1,1,figsize=(10,6),dpi=130)
si=np.argsort(X[:,fi]); xs=X[si,fi]; w=100
ax.scatter(xs,tau_true[si],alpha=0.06,s=4,c='gray',label='True CATE')
ax.plot(xs,uniform_filter1d(tau_true[si],w),'k-',lw=2.5,label='True (smoothed)')
for i,(name,th) in enumerate(res.items()):
ax.plot(xs,uniform_filter1d(th[si],w),lw=2,alpha=0.85,color=COLORS[i%5],label=name)
ax.set_xlabel(fn,fontsize=13); ax.set_ylabel('CATE',fontsize=13)
ax.set_title(f'CATE vs {fn}',fontsize=14); ax.legend(fontsize=9,loc='upper left')
plt.tight_layout(); plt.savefig(path,bbox_inches='tight'); plt.close()
print(f" [saved] {path}")
def plot_dist(tau_true, res, path='fig3_cate_dist.png'):
fig,ax=plt.subplots(1,1,figsize=(10,6),dpi=130)
ax.hist(tau_true,bins=50,alpha=0.3,color='gray',density=True,label='True CATE')
for i,(name,th) in enumerate(res.items()):
ax.hist(th,bins=50,alpha=0.4,color=COLORS[i%5],density=True,label=name,histtype='step',lw=2)
ax.set_xlabel('CATE',fontsize=13); ax.set_ylabel('Density',fontsize=13)
ax.set_title('CATE Distribution',fontsize=14); ax.legend(fontsize=9)
plt.tight_layout(); plt.savefig(path,bbox_inches='tight'); plt.close()
print(f" [saved] {path}")
def plot_error_box(tau_true, res, path='fig4_error_boxplot.png'):
fig,ax=plt.subplots(1,1,figsize=(10,6),dpi=130)
errs=[th-tau_true for th in res.values()]; labs=list(res.keys())
bp=ax.boxplot(errs,labels=labs,patch_artist=True,showfliers=False)
for p,c in zip(bp['boxes'],COLORS[:len(labs)]): p.set_facecolor(c); p.set_alpha(0.5)
ax.axhline(0,color='red',ls='--',lw=1,alpha=0.7)
ax.set_ylabel('Error',fontsize=12); ax.set_title('CATE Estimation Error',fontsize=14)
plt.tight_layout(); plt.savefig(path,bbox_inches='tight'); plt.close()
print(f" [saved] {path}")
def plot_coef(coef, se, fnames, path='fig5_dml_linear_coef.png'):
fig,ax=plt.subplots(1,1,figsize=(8,5),dpi=130)
y=np.arange(len(fnames)); ci=1.96*se
ax.barh(y,coef,xerr=ci,color=COLORS[0],alpha=0.7,capsize=5)
ax.set_yticks(y); ax.set_yticklabels(fnames,fontsize=12)
ax.axvline(0,color='red',ls='--',lw=1)
ax.set_xlabel('Coefficient',fontsize=12); ax.set_title('DML-Linear Coefficients (95% CI)',fontsize=13)
for i,(c,s) in enumerate(zip(coef,se)):
ax.text(c+ci[i]+0.02, i, f'{c:.3f}', va='center', fontsize=10)
plt.tight_layout(); plt.savefig(path,bbox_inches='tight'); plt.close()
print(f" [saved] {path}")
def plot_heatmap(tau_true, X, path='fig6_true_cate_heatmap.png'):
fig,ax=plt.subplots(1,1,figsize=(8,6),dpi=130)
sc=ax.scatter(X[:,0],X[:,1],c=tau_true,cmap='RdYlBu_r',alpha=0.4,s=5,vmin=-3,vmax=5)
plt.colorbar(sc,ax=ax,label='True CATE')
ax.set_xlabel('X1',fontsize=13); ax.set_ylabel('X2',fontsize=13)
ax.set_title(r'True CATE: $\tau(X) = X_1 + 0.5 X_2^2 - 1$',fontsize=14)
plt.tight_layout(); plt.savefig(path,bbox_inches='tight'); plt.close()
print(f" [saved] {path}")
# ==================== Main ====================
def main():
print("\n"+"="*60)
print(" CATE Estimation - Simulation Study")
print("="*60+"\n")
X, T, Y, tau_true = generate_data(n=5000, seed=42)
fnames = ['X1','X2','X3','X4','X5']
res = {}; metrics = []
print("\n>>> [1/5] S-Learner...")
res['S-Learner'] = s_learner(X,T,Y)
metrics.append(evaluate(tau_true, res['S-Learner'], 'S-Learner'))
print(">>> [2/5] T-Learner...")
res['T-Learner'] = t_learner(X,T,Y)
metrics.append(evaluate(tau_true, res['T-Learner'], 'T-Learner'))
print(">>> [3/5] X-Learner...")
res['X-Learner'] = x_learner(X,T,Y)
metrics.append(evaluate(tau_true, res['X-Learner'], 'X-Learner'))
print(">>> [4/5] DML-CausalForest...")
res['DML-CausalForest'] = dml_causal_forest(X,T,Y)
metrics.append(evaluate(tau_true, res['DML-CausalForest'], 'DML-CausalForest'))
print(">>> [5/5] DML-Linear...")
tau_l, coef_l, se_l = dml_linear(X,T,Y)
res['DML-Linear'] = tau_l
metrics.append(evaluate(tau_true, tau_l, 'DML-Linear'))
# Results table
print("\n"+"="*60)
print(" Evaluation Results")
print("="*60)
df = pd.DataFrame(metrics)
print(df.to_string(index=False))
# DML-Linear coefficients
print("\n"+"="*60)
print(" DML-Linear Coefficients (true: X1=1.0, X2=nonlinear, others=0)")
print("="*60)
for i,f in enumerate(fnames):
lo=coef_l[i]-1.96*se_l[i]; hi=coef_l[i]+1.96*se_l[i]
sig = "*" if lo>0 or hi<0 else ""
print(f" {f:>4}: {coef_l[i]:>7.4f} SE={se_l[i]:.4f} 95%CI=[{lo:.4f}, {hi:.4f}] {sig}")
# Plots
print("\n>>> Generating plots...")
plot_scatter(tau_true, res)
plot_by_feature(X, tau_true, res, 0, 'X1', 'fig2_cate_by_x1.png')
plot_by_feature(X, tau_true, res, 1, 'X2', 'fig2b_cate_by_x2.png')
plot_dist(tau_true, res)
plot_error_box(tau_true, res)
plot_coef(coef_l, se_l, fnames)
plot_heatmap(tau_true, X)
print("\n"+"="*60)
print(" All done!")
print("="*60)
return res, df
if __name__ == '__main__':
results, df_metrics = main()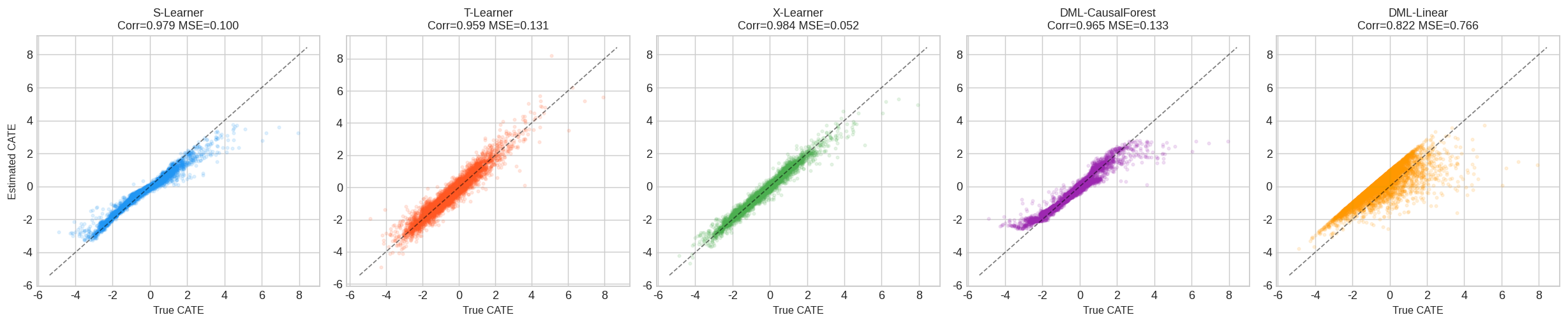
如果觉得有帮助,请点赞+收藏+关注,你的支持是我持续输出的动力!