在创建自己的技能之前,我还是想详细参照一下 claude的方法。
所有技能都是按照元技能的规范来创建的,结构范式相同。
首先假设存在一个skills文件夹,一般在项目的第一层路径下,所有的技能,包括skill-creator都会在这里。
bash
skill-creator/
├── SKILL.md # 核心定义文件(210 行)
├── LICENSE.txt # Apache 2.0 许可证
└── scripts/
├── init_skill.py # 技能初始化脚本
├── package_skill.py # 技能打包脚本
└── quick_validate.py # 技能快速验证脚本1 SKILL.md
这个是技能最核心的文件,原文是英文的,我们翻成中文逐段阅读。
- 1 元数据
ymal format的数据,用于检索
bash
---
name: skill-creator
description: 用于创建有效技能的指南。当用户希望创建新技能(或更新已有技能),以通过专业知识、工作流或工具集成来扩展 Claude 的能力时,应使用此技能。
license: 完整条款见 LICENSE.txt
---其中name和description是不可缺的,用于大模型根据用户的文字输入进行匹配。除了这段,剩下的都是属于正文(content)
- 2 技能简介
一段汇总,说明技能的主要作用,功能和SOW。
bash
# 技能创建器(Skill Creator)
本技能提供创建有效技能的指导。
## 关于技能(About Skills)
技能是模块化、自包含的包,通过提供专业知识、工作流和工具来扩展 Claude 的能力。可以将它们视为特定领域或任务的"入职指南"------它们将 Claude 从通用代理转变为配备任何模型都无法完全具备的程序性知识的专业代理。
### 技能提供的功能
1. **专业工作流** --- 针对特定领域的多步骤流程
2. **工具集成** --- 使用特定文件格式或 API 的指令
3. **领域专业知识** --- 公司特定知识、数据模式、业务逻辑
4. **捆绑资源** --- 用于复杂和重复任务的脚本、参考文档和资产- 3 精确的带架构约束
指明了skill 所对应的树状文件结构层级。并指明了其中必要的部分。可以看到 SKILL.md 这个文件是必须的,里面有若干元素也是不可缺的,其他的是附带的部分。这个从图的角度,应该是在描述节点(node),主要说了某个东西是什么,有什么。
bash
### 技能的结构(Anatomy of a Skill)
每个技能由必需的 SKILL.md 文件和可选的捆绑资源组成:
skill-name/
├── SKILL.md(必需)
│ ├── YAML frontmatter 元数据(必需)
│ │ ├── name:(必需)
│ │ └── description:(必需)
│ └── Markdown 指令(必需)
└── 捆绑资源(可选)
├── scripts/ - 可执行代码(Python/Bash 等)
├── references/ - 按需加载到上下文中的文档
└── assets/ - 输出中使用的文件(模板、图标、字体等)
#### SKILL.md(必需)
**元数据质量:** YAML frontmatter 中的 `name` 和 `description` 决定了 Claude 何时使用该技能。应明确说明技能的功能和使用时机。使用第三人称(例如"本技能应在...时使用",而非"在...时使用本技能")。
#### 捆绑资源(可选)
##### 脚本(`scripts/`)
用于需要确定性可靠性或被重复编写的任务的可执行代码(Python/Bash 等)。
- **何时包含**:当代码被反复重写或需要确定性可靠性时
- **示例**:用于 PDF 旋转任务的 `scripts/rotate_pdf.py`
- **优势**:节省 Token、具有确定性、可以无需加载到上下文中即可执行
- **注意**:脚本可能仍需要被 Claude 读取以进行修补或环境特定的调整
##### 参考文档(`references/`)
旨在按需加载到上下文中,以指导 Claude 的流程和思考的文档和参考材料。
- **何时包含**:Claude 在工作过程中应引用的文档
- **示例**:用于财务模式的 `references/finance.md`、用于公司保密协议模板的 `references/mnda.md`、用于公司政策的 `references/policies.md`、用于 API 规范的 `references/api_docs.md`
- **使用场景**:数据库模式、API 文档、领域知识、公司政策、详细的工作流指南
- **优势**:保持 SKILL.md 精简,仅在 Claude 判断需要时加载
- **最佳实践**:如果文件较大(超过 1 万词),请在 SKILL.md 中包含 grep 搜索模式
- **避免重复**:信息应存在于 SKILL.md 或参考文件中,而非两者皆有。详细信息优先放在参考文件中,除非它确实是技能的核心------这样可以保持 SKILL.md 精简,同时使信息可发现而不占用上下文窗口。仅在 SKILL.md 中保留必要的程序性指令和工作流指导;将详细的参考资料、模式和示例移至参考文件中。
##### 资产文件(`assets/`)
不用于加载到上下文中,而是在 Claude 产出的输出中使用的文件。
- **何时包含**:当技能需要在最终输出中使用的文件时
- **示例**:用于品牌资产的 `assets/logo.png`、用于 PowerPoint 模板的 `assets/slides.pptx`、用于 HTML/React 样板的 `assets/frontend-template/`、用于字体的 `assets/font.ttf`
- **使用场景**:模板、图片、图标、样板代码、字体、被复制或修改的示例文档
- **优势**:将输出资源与文档分离,使 Claude 可以无需加载文件到上下文中即可使用它们- 4 使用(流程)说明
先说了原则(渐近式披露),然后按照一个类似CRUD的方式对各部分展开说明。在细节部分除了方法说明,还有示例(打样)。这些都是帮助大模型能够准确实现意图的方法。
bash
### 渐进式披露设计原则(Progressive Disclosure Design Principle)
技能使用三级加载系统来高效管理上下文:
1. **元数据(name + description)** --- 始终在上下文中(约 100 词)
2. **SKILL.md 正文** --- 技能触发时加载(少于 5000 词)
3. **捆绑资源** --- 由 Claude 按需加载(无限制*)
*无限制是因为脚本可以无需读取到上下文窗口中即可执行。
## 技能创建流程
要创建技能,请按顺序执行"技能创建流程",仅在有明确理由不适用时才跳过步骤。
### 步骤 1:通过具体示例理解技能
仅当技能的使用模式已经清楚理解时才跳过此步骤。即使处理已有技能,此步骤仍然有价值。
要创建有效的技能,需清楚地理解该技能将如何使用的具体示例。这种理解可以来自用户的直接示例,也可以是经过用户反馈验证的生成示例。
例如,在构建 image-editor 技能时,相关问题包括:
- "image-editor 技能应支持哪些功能?编辑、旋转,还有其他吗?"
- "能否提供一些使用该技能的示例?"
- "我可以想象用户会要求诸如'去除这张图片的红眼'或'旋转这张图片'之类的事情。还有其他使用方式吗?"
- "用户会说什么来触发这个技能?"
为避免让用户感到压力,不要在单条消息中提出过多问题。从最重要的问题开始,按需跟进以提高效率。
当清楚了解技能应支持的功能后,即可结束此步骤。
### 步骤 2:规划可复用的技能内容
要将具体示例转化为有效的技能,分析每个示例:
1. 考虑如何从头执行该示例
2. 识别在重复执行这些工作流时哪些脚本、参考文档和资产会有帮助
示例:构建 `pdf-editor` 技能以处理诸如"帮我旋转这个 PDF"的查询时,分析显示:
1. 旋转 PDF 每次都需要重写相同的代码
2. 一个 `scripts/rotate_pdf.py` 脚本存储在技能中会很有帮助
示例:设计 `frontend-webapp-builder` 技能以处理诸如"帮我构建一个待办事项应用"或"帮我构建一个步数追踪仪表盘"的查询时,分析显示:
1. 编写前端 Web 应用每次都需要相同的 HTML/React 样板
2. 一个包含 HTML/React 项目文件样板的 `assets/hello-world/` 模板存储在技能中会很有帮助
示例:构建 `big-query` 技能以处理诸如"今天有多少用户登录了?"的查询时,分析显示:
1. 查询 BigQuery 每次都需要重新发现表模式和关系
2. 一个记录表模式的 `references/schema.md` 文件存储在技能中会很有帮助
为确定技能内容,分析每个具体示例以创建可包含的可复用资源列表:脚本、参考文档和资产。
### 步骤 3:初始化技能
此时,是时候实际创建技能了。
仅当正在开发的技能已存在,且需要迭代或打包时才跳过此步骤。在这种情况下,继续下一步。
从零开始创建新技能时,始终运行 `init_skill.py` 脚本。该脚本方便地生成一个新的模板技能目录,自动包含技能所需的一切内容,使技能创建过程更加高效和可靠。
用法:
scripts/init_skill.py <skill-name> --path <output-directory>
该脚本会:
- 在指定路径创建技能目录
- 生成带有正确 frontmatter 和 TODO 占位符的 SKILL.md 模板
- 创建示例资源目录:`scripts/`、`references/` 和 `assets/`
- 在每个目录中添加可自定义或删除的示例文件
初始化后,根据需要自定义或删除生成的 SKILL.md 和示例文件。
### 步骤 4:编辑技能
编辑(新生成的或已有的)技能时,请记住该技能是为另一个 Claude 实例创建的。专注于包含对 Claude 有益且非显而易见的信息。考虑哪些程序性知识、领域特定细节或可复用资产能帮助另一个 Claude 实例更有效地执行这些任务。
#### 从可复用的技能内容开始
开始实现时,从上述识别的可复用资源开始:`scripts/`、`references/` 和 `assets/` 文件。请注意,此步骤可能需要用户输入。例如,在实现 `brand-guidelines` 技能时,用户可能需要提供要存储在 `assets/` 中的品牌资产或模板,或要存储在 `references/` 中的文档。
同时,删除技能不需要的示例文件和目录。初始化脚本会在 `scripts/`、`references/` 和 `assets/` 中创建示例文件以演示结构,但大多数技能不需要全部。
#### 更新 SKILL.md
**写作风格:** 整个技能使用**祈使句/不定式形式**(动词开头的指令)编写,而非第二人称。使用客观、指导性的语言(例如"要完成 X,执行 Y",而非"你应该做 X"或"如果你需要做 X")。这保持了 AI 消费的一致性和清晰度。
要完善 SKILL.md,回答以下问题:
1. 技能的目的是什么,用几句话概括?
2. 何时应该使用该技能?
3. 在实践中,Claude 应如何使用该技能?应引用上述开发的所有可复用技能内容,以便 Claude 知道如何使用它们。
### 步骤 5:打包技能
技能准备就绪后,应将其打包为可分发的 zip 文件,以便与用户共享。打包过程会先自动验证技能,确保其满足所有要求:
scripts/package_skill.py <path/to/skill-folder>
可选的输出目录指定:
scripts/package_skill.py <path/to/skill-folder> ./dist
打包脚本将:
1. **验证** 技能,检查:
- YAML frontmatter 格式和必填字段
- 技能命名规范和目录结构
- 描述的完整性和质量
- 文件组织和资源引用
2. **打包** 技能(如果验证通过),创建以技能命名的 zip 文件(例如 `my-skill.zip`),包含所有文件并维护正确的分发目录结构。
如果验证失败,脚本将报告错误并退出,不创建包。请修复验证错误后重新运行打包命令。
### 步骤 6:迭代
测试技能后,用户可能会要求改进。这通常在使用技能后立即发生,带着技能表现的新鲜上下文。
**迭代工作流:**
1. 在实际任务中使用技能
2. 注意困难或低效之处
3. 确定 SKILL.md 或捆绑资源应如何更新
4. 实施更改并再次测试2 资源包
在这个场景下,有三个py来辅助技能的初始化,打包和检查(md里约束的各项),就不展开了。
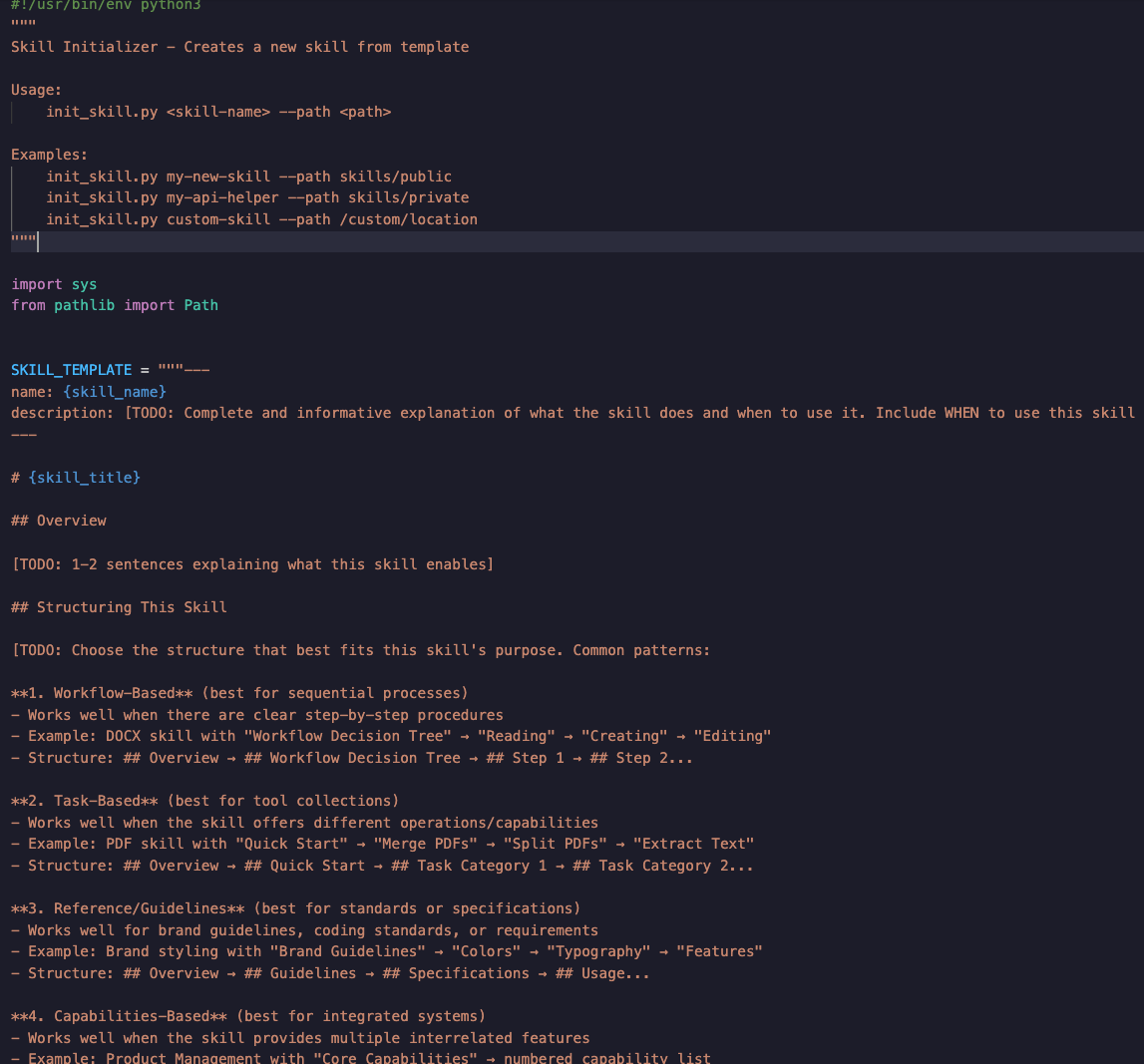
里面的一些核心可以看出来,其实也是高度模板化的
总结
- 1 skill creator里的经验和我的体验是一致的,例如正文长度小于5000词(和我之前理解的一致:大模型表现最好的时候prompt最好在10k以内,其中5k用于基本的prompt, 5k用于具体业务相关的prompt)

-
2 模板化。大模型可以很灵活,但其实背后恰恰是通过一些固定的模板来约束这种灵活的。一般往上需要建立若干层的模板(2~3层)才能实现很灵活的应用。
-
3 用在哪里?
SKILL.md 支持的四种模式
- Workflow-Based --- 基于工作流的技能
- Task-Based --- 基于任务的技能
- Reference/Guidelines --- 参考/指南类技能
- Capabilities-Based --- 基于能力的技能
有些是可以不必要有脚本资源的,例如我让他每天帮我执行一些固定的汇报任务。那么只要把这个业务流程在md里说明白就行(所以我之前做的团队汇报的事,没有做成skill,而是让openclaw自己发挥,结果做的很差);另外,我认为最好能用mcp,而不是脚本执行。