一,初步认识数据库
数据库技术主要是⽤来解决数据处理的⾮数值计算问题,数据处理的主要内容是数据的存储、查 询、修改、排序和统计等。
数据库优点:1. 数据持久化:数据库可以将数据保存在存储介质中,即使应⽤程序关闭或服务器重启,数据也不会丢失。 2. 数据结构化:数据库能够以结构化的⽅式存储数据,使得数据易于管理和查询。 3. **数据完整性:数据库管理系统提供了数据完整性的保障,确保数据的准确性和⼀致性。4. 并发控制 :数据库可以处理多个⽤户或进程同时访问和修改数据,同时确保数据的⼀致性。 5. 安全性 :数据库提供了多种安全机制,如访问控制、加密等,保护数据不被未授权访问。 6. 可扩展性:随着数据量的增⻓,数据库可以⽔平或垂直扩展,以适应不断增⻓的数据需求。 7. 备份和恢复:数据库⽀持数据的备份和恢复,以防数据丢失或损坏。 8. 查询优化 :数据库系统提供了⾼效的查询优化器,可以快速执⾏复杂的查询操作。**9. 事务管理:⼤部分关系型数据库都⽀持事务,确保⼀系列操作要么完全成功,要么完全失败,提⾼ 了操作的可靠性。 10. 支持多用户 :数据库允许多个用户同时访问和操作数据,适合多⽤户环境。
二,数据库操作
sql语句本身对大小写没有强制要求,这里根据我的习惯展示都为小写
2.1 查看数据库
show databases;
2.2 创建数据库
1,create database 数据库名; // 最基本的语句
2,create database (if not exists)数据库名;
//括号内容为如果不存在,如已存在使用2这个语句就会报出警告信息,用1则直接报错
3,create database (if not exists)数据库名 character set utf8mb4 collate utf8mb4_0900_ai_ci;
// character 表示字符集 ,collate 为排序规则,建议创建时指定字符集和排序规则
2.3 选择要操作的数据库
use 数据库名;
2.4 删除数据库
drop database (if not exists)数据库名; //删库是一件很危险的事情,操作需谨慎
三,数据类型
标红的为较为常见的,重点掌握
3.1 数值类型
|--------------|------------|-----------------------------------|-----------------------------|
| 数据类型 | 大小 | 说明 | 对应java类型 |
| BIT (M) | M指定位数,默认为1 | 二进制数,M范围从1到64,存储数值范围从0到2^M-1 | 常用boolean对应bit,默认是1位,只能存0和1 |
| tinyint | 1字节 | | byte |
| smallint | 2字节 | | short |
| int | 4字节 | | Integer |
| bigint | 8字节 | | long |
| float(M,D) | 4字节 | 单精度,M指定长度,D指定小数位数,会发生精度丢失 | float |
| double(M,D) | 8字节 | | double |
| decimal(M,D) | M/D最大值+2 | 双精度,M指定长度,D指定小数点位数。省D默认为0,省M默认为10 | bigdecimal |
| numeric(M,D) | M/D最大值+2 | 和decimal一样 | bigdecimal |
3.2 字符串类型
|---------------|---------------|-------------|-----------|
| 数据类型 | 大小 | 说明 | 对应java类型 |
| varchar(size) | 0~65535字节 | 可变长度字符串 | string |
| text | 0~65535字节 | 长文本数据 | string |
| mediumtext | 0~16777215字节 | 中等长文本数据 | string |
| blob | 0~65535字节 | 二进制形式的长文本数据 | byte |
3.3 日期类型
|----------|--------------|
| date | 年月日 |
| datetime | 年月日 时分秒,精确到秒 |
四,数据表操作
4.1 基本操作
4.1.1 查看当前数据库所有的表
show tables;
4.1.2 创建表
create table (if not exists)自定义表名(
字段名 数据类型,
字段名 数据类型 //最后应该字段的定义后无 逗号
);
4.1.3 查看表结构
desc 表名;
4.1.4 删表
drop table(if exists)表名,表名; //危险操作,需谨慎!! 可同时删多个表,逗号隔开
4.2 CRUD操作
以下所有操作基于这张表,且 中内容为可省内容
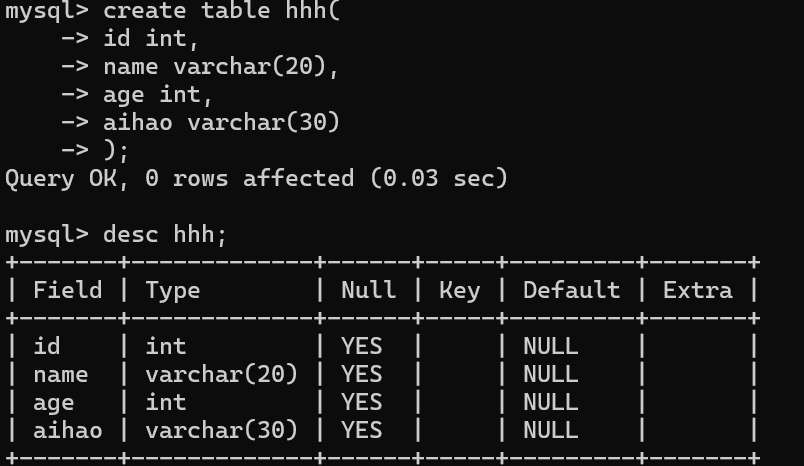
4.2.1 增(create)
insert into 表名 values(值1,值2,,,); //单行插入
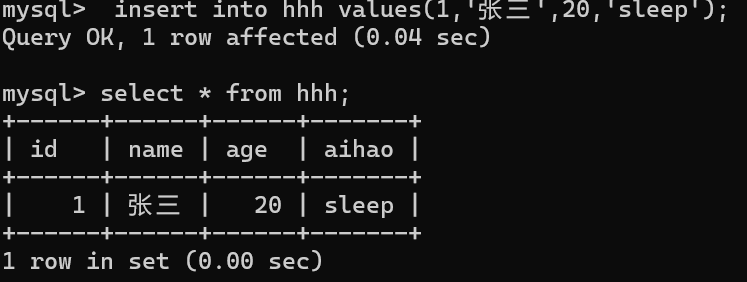
insert into 表名(字段1,字段2,,,) values (值1,值2,,,) ; //指定列插入
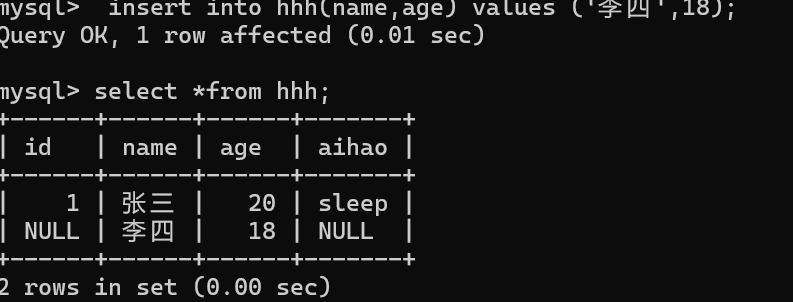
insert into 表名(指定列) values (值,值,),(值\[,值,)] //多行插入

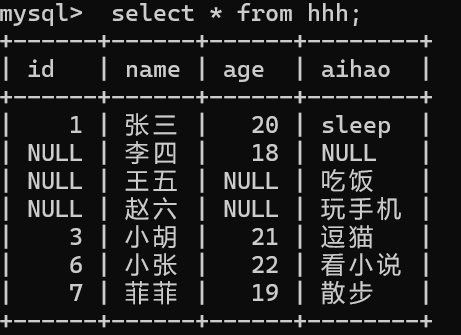
4.2.2 查(retrieve)
1, 全列查询
select * from 表名; //查询表中的所有列,不加条件限制,表中所有记录查出来
2, 指定列查询
select 列名,列名,,, from 表名; //按实际需要指定要查询的列
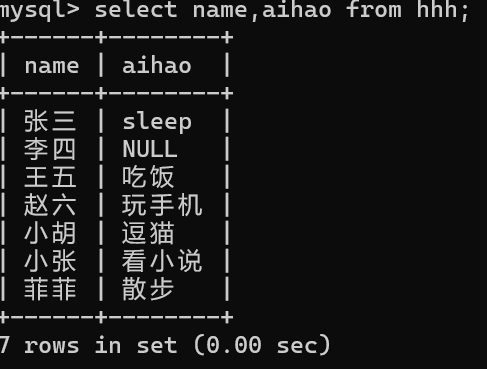
3,列名为表达式
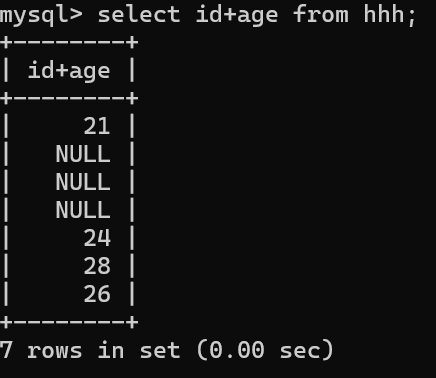
select 列名/表达式 from 表名; //表达式可为常量,也可为多个列运算
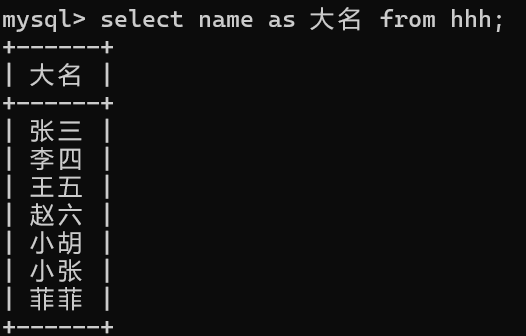
4,查询中使用别名
select 列名/表达式 as 别名 from 表名;
//as可省,别名可为任意字符串,如字符串有空格需用单引号引出
5,去重查询
select distinct 列名,列名,, from 表名;
//查询多个列去重时,所有列都相同才判定为相同
这个由于前面插入数据不满足演示条件,且语句简单,就不演示了
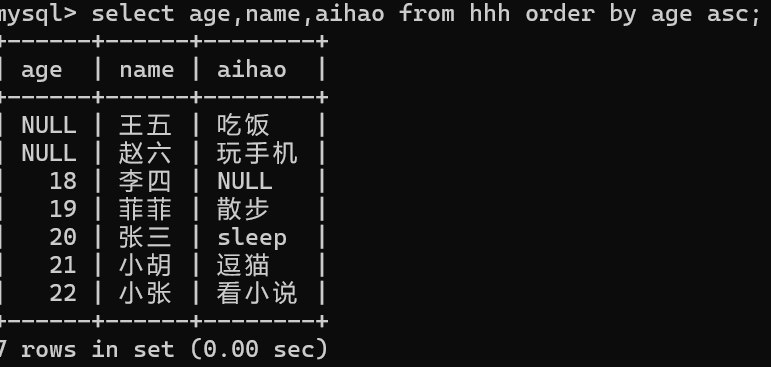
6,排序
select *from 表名 order by 列名/别名/表达式 asc/desc;
//asc为升序,desc为降序。有null时,升序在最上,降序在最下
7,条件查询
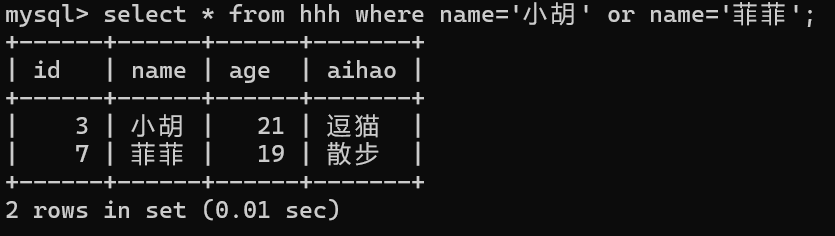
select * from 表名 where 列名/表达式 比较/逻辑运算符 order by 子句;
//where中只能有表达式和列名,不能为别名
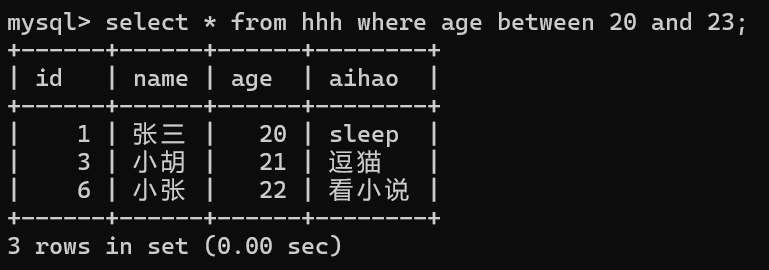
8,区间查询
select * from 表名 where 列名 between 开始条件 and 结束条件;
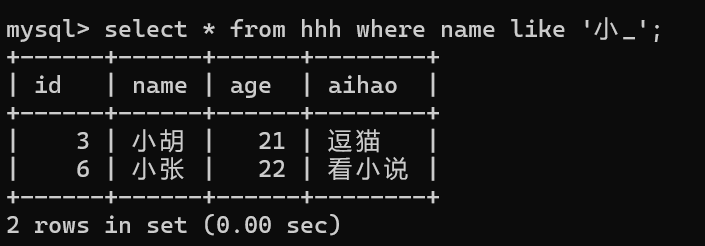
9,模糊查询
select * from 表名 where 列名 like ' %值___'; // % 可多个或0个字符,_ 只能配一个字符
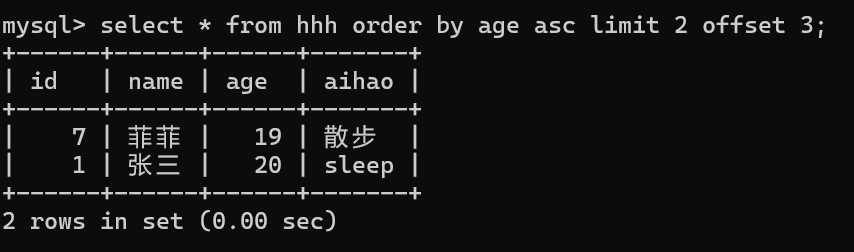
10,分页查询
select * from 表名 where 条件 order by 列名 desc/asc limit num;
//取前num条数据
select * from 表名 where 条件 order by 列名 desc/asc limit start num;//从start开始往后取num条
select * from 表名 where 条件 order by 列名 desc/asc limit num offset start;//跳过start条数据取num条
4.2.3 改(update)
不加where条件限制是危险操作,因为将会改掉整列值
update 表名 set 列名=值,列名=值,, where 条件 order by 列名 asc/desc limit n;
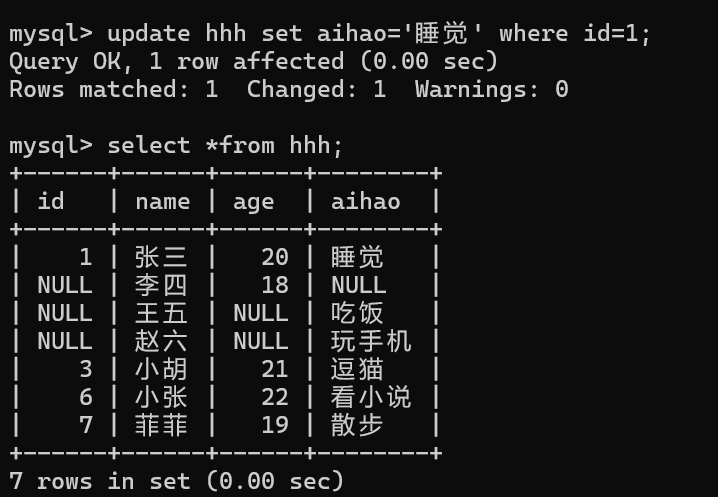
4.2.4 删(delete)
不加where条件限制是危险操作,因为将会改掉整列值
delete from 表名 where 条件 order by 列名 asc/desc limit n;
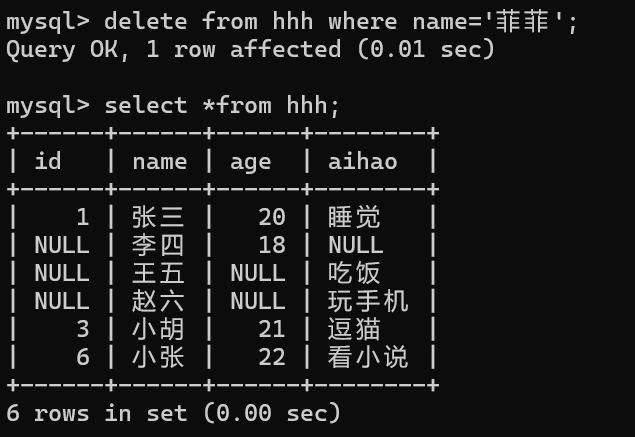
五,数据库约束和设计
5.1 数据库约束
数据库约束是指对数据库表中的数据所施加的规则或条件,⽤于确保数据的准确性和可靠性。这
些约束可以是基于数据类型、值范围、唯⼀性、⾮空等规则,以确保数据的正确性和相容性。
|------------------|-------------------------------------------------------|
| NOT NULL⾮空约束 | 指定⾮空约束的列不能存储 NULL 值 |
| DEFALUT 默认约束 | 当没有给列赋值时使⽤的默认值 |
| UNIQUE 唯⼀约束 | 指定唯⼀约束的列每⾏数据必须有唯⼀的值 |
| PRIMARY KEY 主键约束 | NOT NULL 和 UNIQUE的结合,可以指定⼀个列或多个列,有助于防⽌数据 重复和提⾼数据的查询性能 |
| FOREIGN KEY 外键约束 | 外键约束是⼀种关系约束,⽤于定义两个表之间的关联关系,可以确保数据 的完整性和⼀致性 |
在定义主键时,表中不能有多个主键,但可以有复合主键如下
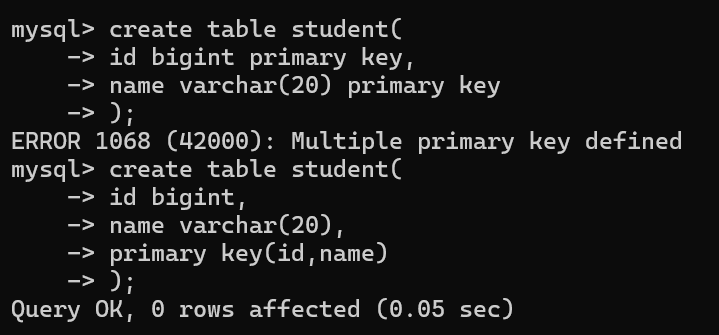
primary key 用auto_increment关键字可使指定主键自增,自增时找到序列最大值+1
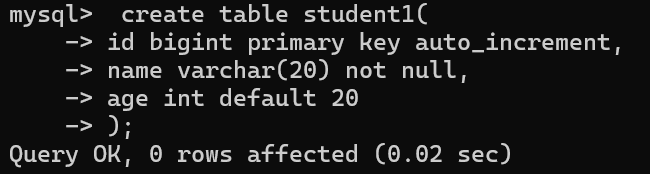
插入语句效果
5.2 数据库设计
认识范式:
第一范式(1NF):表中字段不可再分
关系型数据库的一个最基本要求,不满足第一范式不可称为关系型数据库
第二范式(2NF):在满⾜第⼀范式的基础上,不存在非关键字段对任意候选键的部分函数依赖。存在于表中定义了复合 主键的情况下。不满足第二范式产生的问题
1,数据冗余 2,更新异常 3,插入异常 4,删除异常
第三范式(3NF):在满⾜第⼆范式的基础上,不存在⾮关键字段,对任⼀候选键的传递依赖
设计过程
- 从现实业务中抽象得到概念类,概念类是从现实世界中抽象出来的,在需求分析阶段就需要确定下来 。类对应了数据库设计中的实体,实体对应了数据库中的表 。类中的属性对应实体中的属性,实体的属性对应了表中的列
- 确定实体与实体之间的关系,并画出E-R画,方便项目参与⼈员理解与沟通
- 根据E-R图完成SQL语句的编号并创建数据库
实体-关系图
实体-关系图(Entity-Relationship Diagram)简称E-R图,也称作实体联系模型、实体关系模型,是 ⼀种⽤于描述数据模型的概念图,主要⽤于数据库设计阶段。
E-R图包含了以下三种基本成分:
实体:即数据对象,⽤矩形框表⽰,⽐如⽤⼾、学⽣、班级等。
属性:实体的特性,⽤椭圆形或圆⻆矩形表⽰,如学⽣的姓名、年龄等。
关系:实体之间的联系,⽤菱形框表⽰,并标明关系的类型,并⽤直线将相关实体与关系连接起
六,联合查询
聚合函数
|------------------|----------------------|
| count(列名/常量/*) | 统计记录条数,建议使用count(*) |
| sum(列名) | 求和,列必须为数值类型 |
| avg(列名) | 求平均值,列必须为数值类型 |
| max(列名) | 求最大值,列必须为数值类型 |
| min(列名) | 求最小值,列必须为数值类型 |
| round(数值,小数点的位置) | 格式化小数输出格式 |
分组查询
where对表中真实数据操作,having对group by后结果过滤
select 要分组的列,聚合函数(列名) from 表名 group by 要分组的列 having 对分组的结果进行过滤
链接查询时的步骤:
1,确定要参与查询的表,也就是确定查询数据存在于那几张表中
2,取笛卡尔集
3,确定表与表之间的连接条件
4,确定查询的过滤条件 where
5,精减查询字段
内连接
select * from 表名,表名 where 链接条件 where......;
select * from 表名 inner join 表名 on 链接条件 where......;
外连接
select *from 表名 right/left join 表名 on 连接条件;
right为右链接,是以join右边的表为基准,这个表中的数据会全部显示出来,左边表没有与之匹配的记录全部用NULL填充。left与之相反
自链接
可以把行转换为列,在查询时可以用where条件进行过滤可以实现行与行间比较
子查询(嵌套查询)
select * from 表1 where 查询内容 in =(select 查询内容 from 表2 where 查询内容 select...... ) //加入in后变多行子查询
合并查询
select * from 表1 union select * from 表2;
select * from 表1 union all select * from 表2;
union:使用时,自动去除结果集中重复行
union all: 使用时,不去除结果集中重复行
sql语句执行顺序
from > join on > where > group by > having > select > distinct > order by > limit
七,小结
好久没有更新博客了,寒假只顾着吃吃喝喝了,来学校也不知道在忙啥,每天稀里糊涂过完了,哈哈哈。虽然没更新但是有往后学习捏,都攒着一口气更新,这期干货很多,内容丰富,整体难度不是特别大,但完全吃透还需要下一点功夫,mysql语句好多。这里给有个小教训就是一口气还是不能贪多啊,这边东西还是很多,应该把联合查询单开一章的,没有规划好,写了有种不到头的感觉,这期到现在已经写不动了,就没有配运行图片了,后期有空再给这个单开一章,有问题可以找我交流哦。学完Java还有好长的路要走啊,加油吧老铁们。如内容不全或有问题可以联系我,也希望各位大哥大姐能动动发财的小手给我点点赞。