如果大家觉得文字版有些枯燥,可以访问b站链接有视频讲解,超级详细,欢迎大家观看,下面是链接:🔥Go 并发 Map 三大方案深度拆解!源码吃透读写锁 / 分片锁 /sync.Map_哔哩哔哩_bilibili
一、加读写锁
常见的map操作有增删改查和遍历,查和遍历需要加读锁,增删改需要加写锁


读写锁在功能上满足了需要,但是面对高并发的场景,不仅功能要满足,性能也要跟上,锁是导致性能下降的万恶之源之一,所以并发编程的原则就是尽可能减少锁的使用,当锁不得不用的时候,可以减小锁的粒度和持有的时间。
第一种方法中,加锁的对象是整个 map,协程A对map中的key进行修改操作,会导致其他协程无法对其它key进行读写操作,一种解决思路,就是将这个map分成n块,每个块之间的读写操作都互不干扰,从而降低冲突的可能性
二、分片加锁
本质是降低锁粒度,把原本**一个大map + 一把全局锁 的结构,拆成 N 个小map (分片) + N把独立锁**的结构,让不同 key的操作落在不同的分片上,只锁对应的分片,不影响其他分片的并发操作
第一步: 初始化分片(创建32个独立的分片+锁)
底层源码解析版:


第二步:定位key所属的分片(哈希函数)

**举个例子:**key = "a" ( a的ASCII码是97 )
-
初始 hash = 2166136261
-
第一步:hash = 2166136261 * 16777619 = 3635685984(大数,不用记)
-
第二步:hash = 3635685984 ^ 97 = 3635686081(异或运算,让哈希值更独特)
-
最终返回 3635686081 作为 "a" 的哈希值。
为什么选 FNV32 ?
1)快:只有乘法和异或运算,CPU 执行效率极高,适合高并发场景;
2)**冲突率低:**通过大质数和初始种子,能让不同字符串的哈希值尽量不重复;
3)**轻量:**无需依赖第三方库,代码实现简单。
第三步:分粒度加锁(操作只锁对应分片)
所有读写操作(Set/Get/Remove等)都遵循"先定位分片➡只锁该分片➡操作➡解锁"的逻辑,这是分片加锁的核心体现
三、sync.map
还是从底层给大家介绍一下这个map
1)sync.map 结构

2)read区的只读容器

3)删除时涉及到的字段

举个例子:
用sync.map来存储用户id ➡ 用户名,看各字段如何协作:
1. 初始化:read为空,dirty为空,misses = 0
2. 新增key = 1,value = "张三"
1)加锁,把key=1存入dirty(dirty1 = &entry{p: 指向"张三"})
2)把readOnly.amended 设为 true(表示dirty有read里面没有的数据)
3. 读取 key = 1:
1)先查 read,没找到➡misses +=1
2)因为amended = true,加锁查dirty,找到后返回"张三"
4. 多次读取 key=1:misses持续增加,直到等于len(dirty)(此时len(dirty)=1, misses=1)
5. dirty 提升为 read
加锁后,将"dirty"赋值给"readonly.m",将"read"改为新的"readonly"形式;
置空 dirty, misses 清零,amended=false;
6. 删除key = 1
1)找到相应的条目,将 entry.p 设为"expunged(贴上"已删除"标签);
- 不删除 key,等后续 dirty 提升时批量清理;
**7. 再次读取 key = 1:**看到entry.p == expunged,返回不存在
2)查数据(Load方法)

3)增/改数据(Store方法)
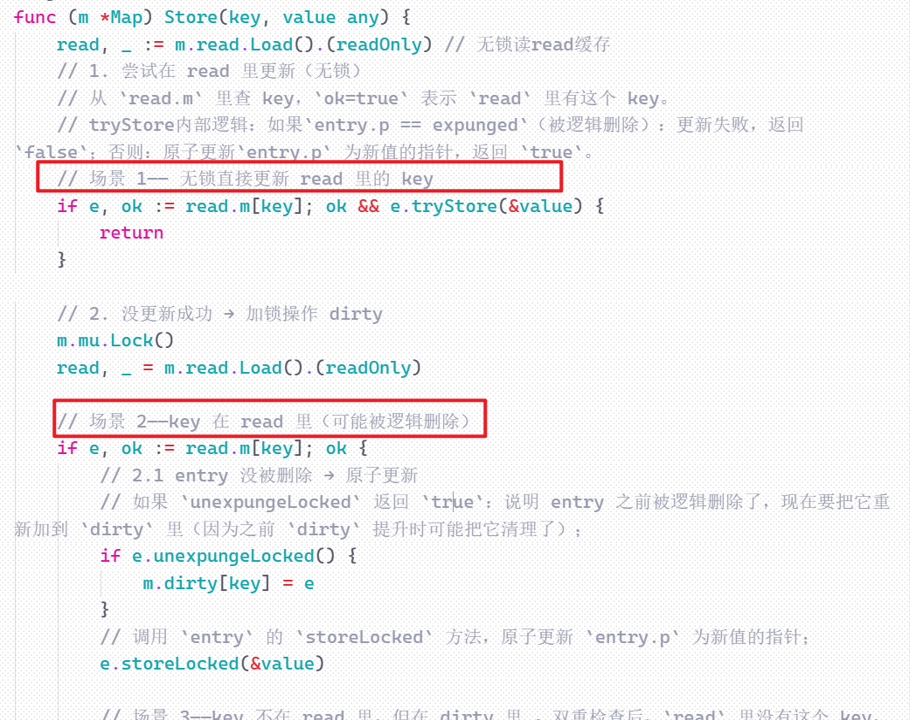
**场景一:**更新read里面已有的、没被删除的key
**场景二:**更新read里面被逻辑删除的key
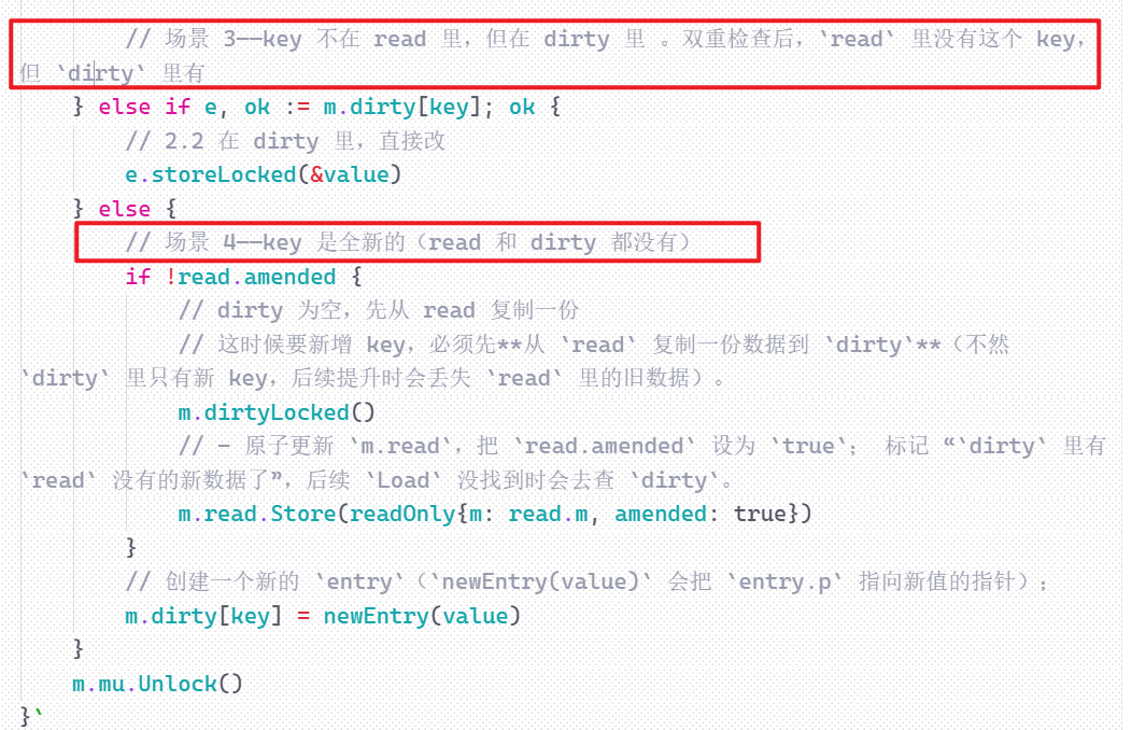
**场景三:**更新dirty里面已有的key
**场景四:**新增全新的key
4)删除数据(Delete方法)

5)遍历数据(Range方法)

四、总结对比
对比 sync.map 和分片map
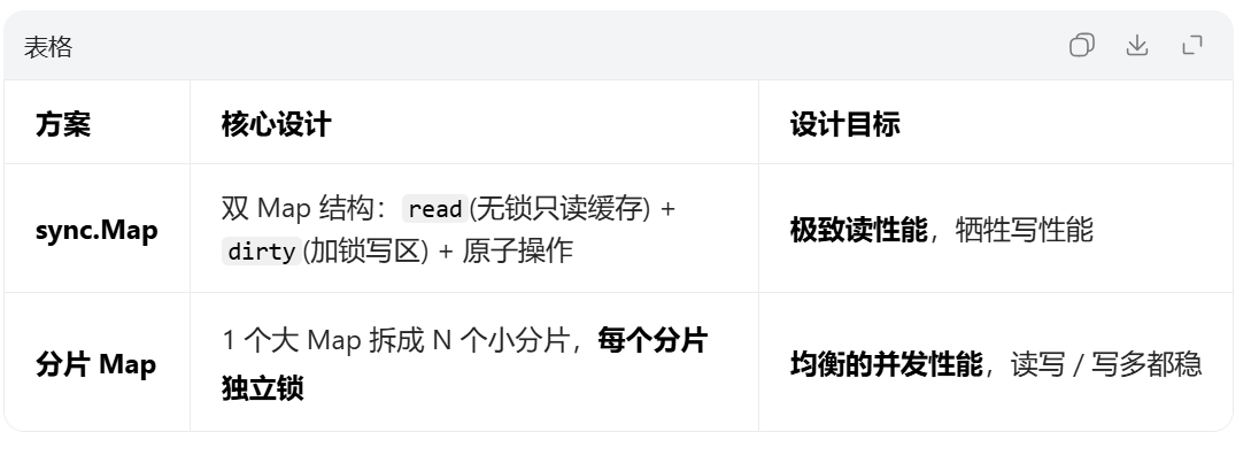
sync.map :
1. 读性能碾压所有方案(极致无锁)
1)读操作完全不加锁,优先走 read 缓存(atomic.Value 原子读)99%的请求全程无锁;
2)无锁 = 所有 CPU 核心可以同时读,互不阻塞。
3)遍历前自动把 dirty 合并到 read,无锁遍历快照,不阻塞读写。
2. 写/新增性能差,频繁写会暴跌
1) 所有写 / 新增必须加锁操作 dirty; 读未命中次数过多,会触发 dirty → read 全量提升
2)内存占用更高,数据冗余:采用延迟删除(打标记expunged),不立即清理内存;read + dirty 双 Map,同一个 key 可能存在两份;
3) key 频繁增删 → 性能雪崩:只要 key 不稳定,dirty 会频繁提升,无锁优势完全消失,退化成加锁 Map。
分片map:
1. 读写均衡/写多场景性能无敌(高并发写、混合读写,比 sync.Map 稳得多)
1)锁粒度极小(只锁一个分片);不同分片的操作完全并行; 无 read/dirty 切换,无提升开销
2)内存占用低,没有冗余数据:单一层结构,每个 key只存一次;无双 Map 冗余,无延迟删除垃圾。
3)无论 key 稳定与否,锁竞争只限制在单个分片,不会全局阻塞。
2. 读性能远不如 sync.map (必须加锁)
1)读必须加读锁(RLock),锁操作再快也比「无锁原子操作」慢得多。
2)要遍历 N 个分片,逐个加锁 / 解锁,开销巨大。
3)Go 标准库不提供,自己写极易出 bug。
4)分片数固定,无法动态扩容:初始化定好分片数,后期不能改,扩容等于重建整个 Map。
以上就是今天给大家分享的解决map并发的三种方法,希望大家能有所收获,有我没讲明白的欢迎在评论区留言或者私信