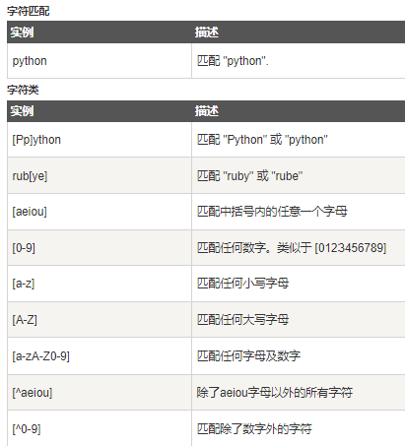
一、模糊查找与精确查找的区别
s="123 jdjslk 89"
#找出确定的数字1,这就是精确查找
print(s.find("1"))
#凡是数字都要找出来,但不确定具体是什么数字,这就是模糊查找
import re
print(re.findall('\d+',s))
二、match用法
'''
match函数:
尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
函数语法:re.match(pattern, string, flags=0)
'''
# !/usr/bin/python
import re
print(re.match('www', 'WwW.runoob.com',re.I).span()) # 在起始位置匹配
print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配
三、search
'''
search函数:
扫描整个字符串并返回第一个成功的匹配。
函数语法:re.search(pattern, string, flags=0)
'''
# !/usr/bin/python3
import re
print(type(re.search('www', 'www.runoob.com')))
print(re.search('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.search('com', 'www.runoob.com').span()) # 不在起始位置匹配
四、compile
import re
pattern = re.compile(r'\d+') # 用于匹配至少一个数字
m = pattern.match('one12twothree34four') # 查找头部,没有匹配
print( m )
m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
print( m )
m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
print( m ) # 返回一个 Match 对象
# <_sre.SRE_Match object at 0x10a42aac0>
print(m.group(0)) # 可省略 0
# '12'
print(m.start(0)) # 可省略 0
# 3
print(m.end(0)) # 可省略 0
# 5
print(m.span(0)) # 可省略 0
# (3, 5)
findall
import re
result1 = re.findall(r'\d+', 'runoob 123 google 456')
pattern = re.compile(r'\d+') # 查找数字
result2 = pattern.findall('runoob 123 google 456')
result3 = pattern.findall('run88oob123google456', 0, 10)
print(result1)
print(result2)
print(result3)
finditer
import re
it = re.finditer(r"\d+", "12a32bc43jf3")
for match in it:
print(match.group())
sub
#!/usr/bin/python3
import re
phone = "2004-959-559 # 这是一个电话号码"
# 删除注释
num = re.sub(r'#.*$', "", phone)
print("phone= ", phone)
print("电话号码 : ", num)
# 移除非数字的内容
num = re.sub(r'\D', "", phone)
print("电话号码 : ", num)
split
import re
a = "123 456 789".split(" ")
print(a)
res=re.split(r'\W+', 'runoob, runoob, runoob.')
print(res)
# ['runoob', 'runoob', 'runoob', '']
# >> > re.split('(\W+)', ' runoob, runoob, runoob.')
# ['', ' ', 'runoob', ', ', 'runoob', ', ', 'runoob', '.', '']
# >> > re.split('\W+', ' runoob, runoob, runoob.', 1)
# ['', 'runoob, runoob, runoob.']
#
# >> > re.split('a*', 'hello world') # 对于一个找不到匹配的字符串而言,split 不会对其作出分割
# ['hello world']
匹配汉字
import re
# 待匹配的字符串
title = "你好,hello,世界"
# 创建正则表达式,用于只匹配中文
pattern = re.compile(r"[\u4e00-\u9fa5]+")
#检索整个字符串,将匹配的中文放到列表中
result=pattern.findall(title)
print(result)
不同的pattern