你是不是经常听人聊AI时蹦出这些词:LLM、Token、Context、Prompt、Tool、MCP、Agent?听着好像都认识,但真要问"这到底是啥",又有点懵。别急,今天咱们就用工程师的大白话,把这些词一个个拆开揉碎,讲清楚它们到底是啥、有啥用、又是怎么串起来的。
LLM:(大模型)
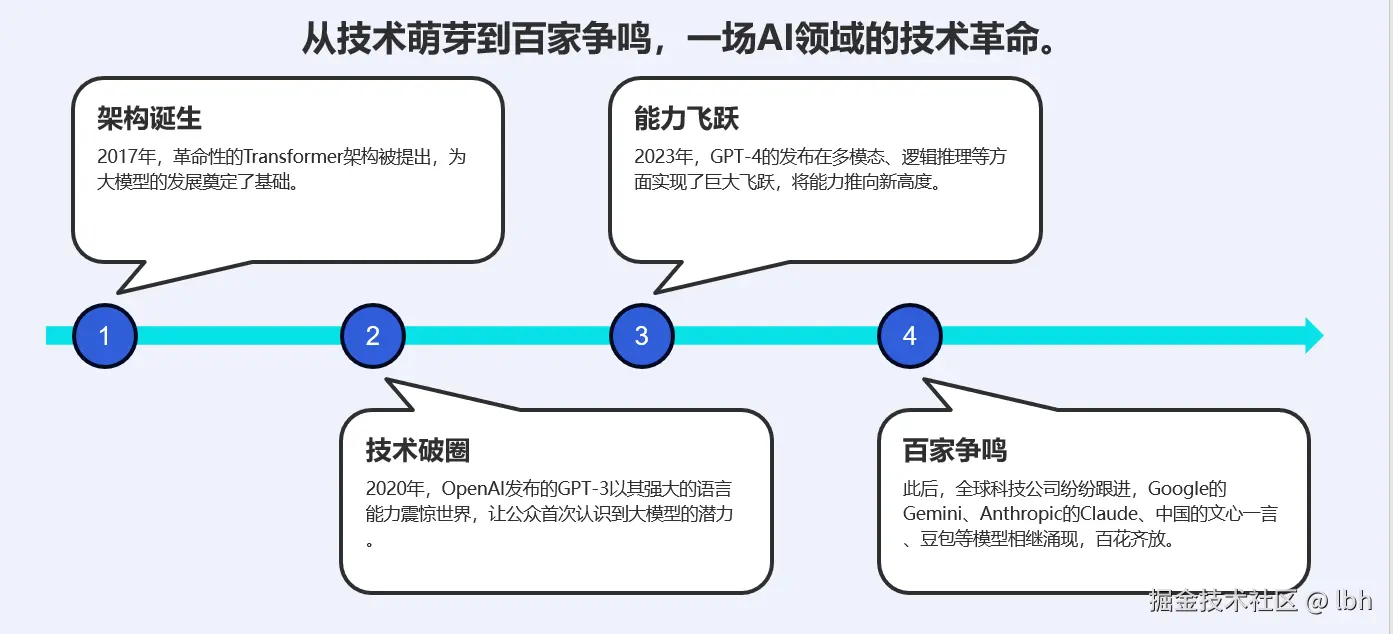
LLM的来历 :2017年Transformer架构诞生,OpenAI将其发扬光大;
历程 :从GPT-3.5破圈,到GPT-4飞跃,再到百家争鸣;
用途:从聊天起步,正在成为一切数字交互的"万能接口"。
LLM(大语言模型)通俗来讲,就是一个极其擅长"文字接龙"的超级智能程序。
你可以把它想象成一个玩接龙游戏的高手:
- 它只做一件事:给你一句话,它根据这句话,猜出下一个最可能出现的字或词。
- 它一个字一个字地"吐"出来:它先猜第一个字,然后把这个字加回原来的句子里,再猜下一个字。就这样一个字一个字地往外蹦,直到它觉得一句话说完整了。
- 它不懂文字,只懂数字:在它内部,所有的文字都会被转换成它认识的数字(也就是"Token"),运算完再把数字变回文字告诉你。
举个例子 :
你问它"这篇文章怎么样?",它不会一次性想好"特别棒"三个字。它的内部流程是:
- 先猜出第一个字:"特"
- 然后把"特"加回问题,变成"这个视频怎么样特",再猜出:"别"
- 再把"别"加进去,变成"这个视频怎么样特别",再猜出:"棒"
- 最后发现话说完了,输出"特别棒"。
你平时用的像GPT、Claude、豆包、文心一言这些产品,底层都是这种"接龙"模型。它们之所以显得"聪明",是因为它们用海量的数据训练过,猜下一个字的"经验"极其丰富,所以接出来的话看起来像是有逻辑、有思考一样。
简单理解,就是大模型就像一个读过全世界所有书、但只会玩"文字接龙"的超级学霸------它每时每刻只关心"下一个字该接什么",但因为接了几万亿次,它的"语感"好到让人觉得它真的在思考,当我们给它装上"工具"和"长记忆"后,它就从只会玩接龙游戏的玩家变成了能帮忙干活、做决策的搭档。
Token:(大模型处理数据的最基本单元)
Token 通俗来讲,就是大模型"眼中的文字"------它是模型处理文本时最小的"积木块"。
1. 它不是"字",也不是"词",而是"模型自己定义的积木"
我们看文字,是一个字一个字看的。
但大模型看文字,是先把一段话切成一小块一小块 ,每一块就叫一个 Token。
- 有时候一个 Token 就是一个汉字,比如"我""你""好"。
- 有时候一个 Token 是一个词,比如"苹果""电脑"。
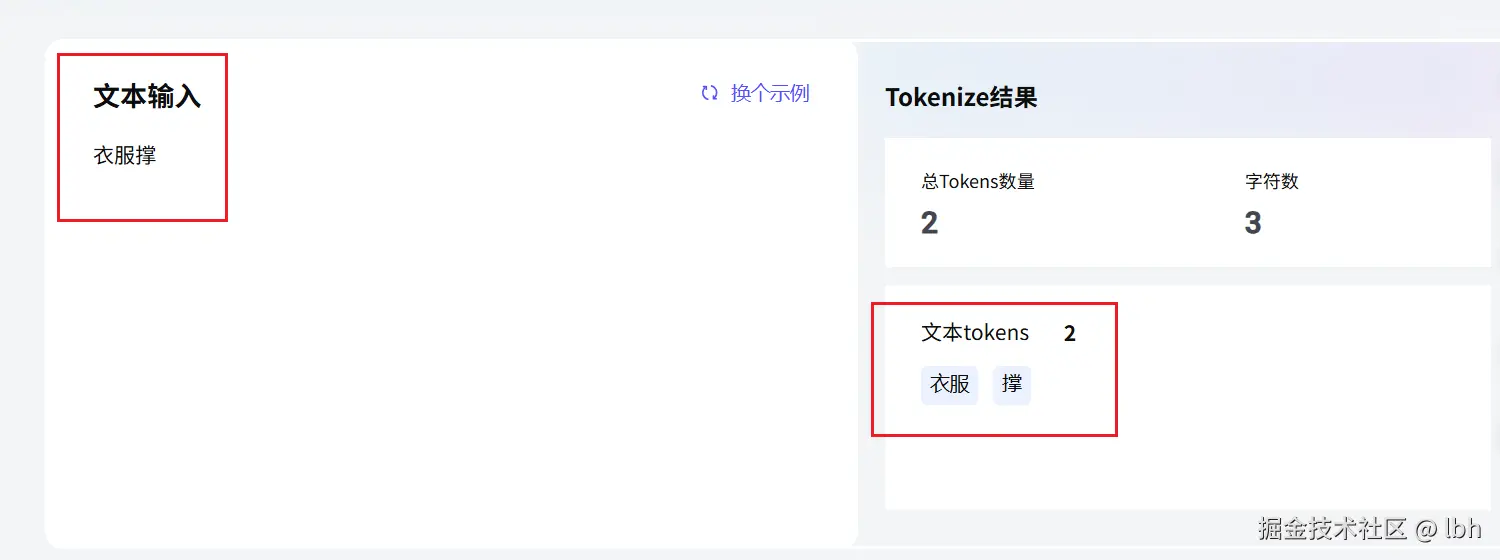
- 但更多时候,一个词会被切成多个 Token。
比如"衣服撑"这个词,在大模型眼里可能是两个 Token:"衣服"和"撑"。
再比如"Helpful"这个英文单词,可能会被切成"Help"和"ful"两个 Token。
一句话总结:Token 是模型自己学会的一套"切分规则",每个 Token 就是它一次能"看"或"吐"的最小单位。
在线查看token 工具: console.volcengine.com/ark/region:...
2. 为什么要有 Token?------因为模型只认数字
大模型内部全是数学运算,它不认识"你""我""他",只认识数字。
所以需要有一个"翻译官",把文字变成数字,这个数字就是 Token ID。
流程是这样的:
- 切分:把你说的话切成一个个 Token。
- 映射:每个 Token 对应一个唯一的编号(Token ID)。
- 运算:模型只处理这些数字。
- 还原:模型吐出一个数字(Token ID),再把它变回文字。
举个例子:
你问"这篇文章到底怎么样?"
它可能被切成 3 个 Token:"这篇文章" "到底" "怎么样"。
每个 Token 都有一个数字编号,模型看到的其实是 [1234, 5678, 9011,] 这样一串数字。
3. Token 和字数有什么关系?
这是一个很实用的知识点:
- 英文:平均 1 个 Token ≈ 0.75 个单词。比如"hello"是一个 Token,"helpful"是两个 Token。
- 中文:平均 1 个 Token ≈ 1.5 到 2 个汉字。一个常见汉字通常是一个 Token,但生僻字可能需要 2~3 个 Token。
为什么你要关心这个?
因为所有大模型产品都是按 Token 数量 计费的。
你提问时消耗 Token,模型回答时也消耗 Token。一段 1000 字的中文,大概会消耗 1500~2000 个 Token。
4. Token 决定了"它能记住多少"------上下文窗口
每个大模型都有一个"上下文窗口"(Context Window),它的大小就是用 Token 数量 衡量的。
- 比如一个模型说"上下文窗口是 100 万 Token",意思就是它一次最多能处理 100 万个 Token 的内容。
- 100 万 Token 大约相当于 150 万个汉字,或者《水浒传》整本那么多。
你每次和大模型聊天,它之所以能"记住"前面说的话,就是因为程序会把整个对话历史(用 Token 表示)一直塞给它。如果对话太长,超出了窗口,最早的对话就会被"挤出去",模型就"忘"了。
5. 用一张图帮你记住 Token
中间那一步"转成数字"之后,模型处理的就不再是"文字",而是"数字积木"。它所有的"思考",其实都是在计算"下一个数字积木应该是什么"。
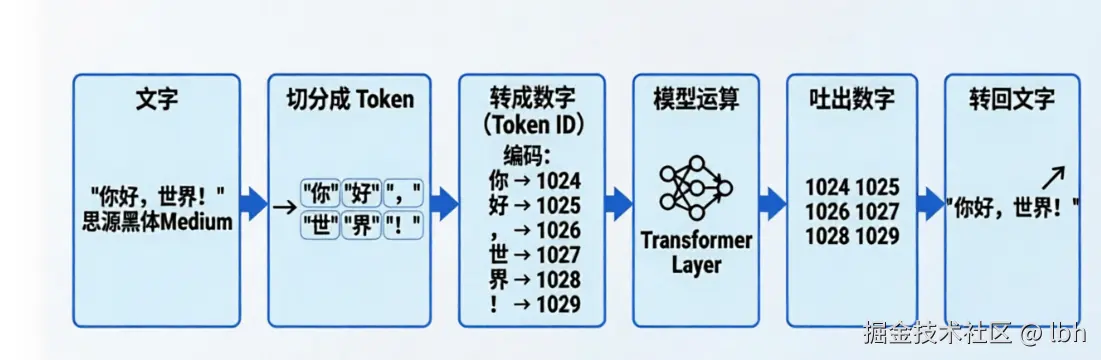
Token 就是大模型"看"和"写"文字时使用的最小积木块。它既不是字也不是词,而是模型自己学会的一种切分方式。你用大模型花的每一分钱、它能记住的每一句话,都是用 Token 来衡量的。
下次你再看到"这个模型有 100 万 Token 上下文",你就知道:它能一次吞下整本《水浒传》,然后跟你聊里面的任何细节。
Context: (大模型每次处理任务时接收到的信息总和)
Context window: (大模型的 Context 最多能够存储的 Token 量)
Prompt: (用户或系统当前给大模型下达的具体指令或问题)
Tool: (大模型用来感知和影响外部环境的函数)
MCP: (统一了工具接入格式的标准协议)
Agent: (能自主规划和调用工具、直至解决用户问题的程序)
Agent Skill: (给 Agent 看的说明文档)
| 英文术语 | 中文名称 | 核心定义 |
|---|---|---|
| LLM | 大模型 | 大模型本身(Large Language Model) |
| Token | 词元/令牌 | 大模型处理数据的最基本单元 |
| Context | 上下文 | 大模型每次处理任务时接收到的信息总和 |
| Context Window | 上下文窗口 | 大模型的 Context 最多能够存储的 Token 量 |
| Prompt | 提示词 | 用户或系统当前给大模型下达的具体指令或问题 |
| Tool | 工具 | 大模型用来感知和影响外部环境的函数 |
| MCP | 模型上下文协议 | 统一了工具接入格式的标准协议 |
| Agent | 智能体 | 能自主规划和调用工具、直至解决用户问题的程序 |
| Agent Skill | 智能体技能 | 给 Agent 看的说明文档 |
简单说明:
- LLM (大模型) :那个超级聪明的"大脑"。
- Token:大脑认识的最小"积木块"(文字切分后的单位)。
- Context (上下文) :大脑此刻"脑子里装着的所有信息"(包括你的提问和之前的聊天记录)。
- Context Window (上下文窗口) :大脑的"短期记忆容量上限"(最多能装多少 Token)。
- Prompt (提示词) :你给大脑出的"题目"或"指令"。
- Tool (工具) :大脑的"手和眼"(比如联网搜索、计算器,帮它看世界和做事情)。
- MCP:工具的"通用插座标准"(让所有工具都能插在大脑上用)。
- Agent (智能体) :一个有"大脑"且有"手脚"的完整办事员(它不只聊天,还能帮你把事办成)。
- Agent Skill (技能) :办事员手里的"操作说明书"(告诉它怎么用工具)。