今天,我们接着来看Langchain4j里面的消息记忆和Rag这两个部分
一、消息记忆
1.概念
首先来看官方的描述
- 历史记录保存了用户与AI之间的所有信息**。**历史是用户在界面中看到的内容。它代表了实际说过的内容。
- 记忆会保留一些信息,这些信息会呈现给大型语言模型,使其表现得好像"记住"了对话内容。 记忆与历史截然不同。根据所使用的内存算法,它可以以多种方式修改历史: 删除部分消息,摘要多条消息,摘要单独消息,删除消息中的不重要细节, 在消息中注入额外信息(例如,针对RAG)或指令(例如,用于结构化输出)等。
LangChain4j 目前只提供"内存",没有"历史"。如果你需要保留完整的历史记录,请手动保存
让我来总结一下,就是每次的对话都会被保存起来,同时他也提供了一个接口来实现,删除消息,摘要消息等等,但是官方只提供了一个
apl
InMemoryChatMemoryStore这个对象来将消息存储到内存中,并不能够持久化
使用Langchain4j的消息关键需要知道两个接口ChatMemory这个是调用历史消息的接口,如果你需要自定义消息处理的方法,则需要实现这个接口,否则的话需要使用框架自带的
MessageWindowChatMemory2.实现
首先我们先来看看MessageWindowChatMemory里面是如何实现的
java
public interface ChatMemory {
/**
* The ID of the {@link ChatMemory}.
*/
Object id();
/**
* Adds a message to the chat memory.
*/
void add(ChatMessage message);
/**
* Adds messages to the chat memory
*/
default void add(ChatMessage... messages) {
if ((messages != null) && (messages.length > 0)) {
add(Arrays.asList(messages));
}
}
/**
* Adds messages to the chat memory
*/
default void add(Iterable<ChatMessage> messages) {
if (messages != null) {
messages.forEach(this::add);
}
}
/**
* Replaces all messages in the chat memory with the specified messages.
*/
default void set(ChatMessage... messages) {
ensureNotEmpty(messages, "messages");
set(Arrays.asList(messages));
}
/**
* Replaces all messages in the chat memory with the specified messages.
*/
default void set(Iterable<ChatMessage> messages) {
ensureNotNull(messages, "messages");
if (!messages.iterator().hasNext()) {
throw new IllegalArgumentException("messages must not be empty");
}
clear();
add(messages);
}
/**
* Retrieves messages from the chat memory.
*/
List<ChatMessage> messages();
/**
* Clears the chat memory.
*/
void clear();
}这个接口里面总共有7个方法,分别就是获取当前会话的id,添加消息,替换所有消息,获取消息,清空消息。
这里我们主要看一下它的添加方法
java
@Override
public void add(ChatMessage message) {
List<ChatMessage> messages = messages();
if (message instanceof SystemMessage) {
Optional<SystemMessage> systemMessage = SystemMessage.findFirst(messages);
if (systemMessage.isPresent()) {
if (systemMessage.get().equals(message)) {
return; // do not add the same system message
} else {
messages.remove(systemMessage.get()); // need to replace existing system message
}
}
}
if (message instanceof SystemMessage && this.alwaysKeepSystemMessageFirst) {
messages.add(0, message);
} else {
messages.add(message);
}
Integer maxMessages = this.maxMessagesProvider.apply(this.id);
ensureGreaterThanZero(maxMessages, "maxMessages");
ensureCapacity(messages, maxMessages);
store.updateMessages(id, messages);
}
private static void ensureCapacity(List<ChatMessage> messages, int maxMessages) {
while (messages.size() > maxMessages) {
int messageToEvictIndex = 0;
if (messages.get(0) instanceof SystemMessage) {
messageToEvictIndex = 1;
}
ChatMessage evictedMessage = messages.remove(messageToEvictIndex);
if (evictedMessage instanceof AiMessage aiMessage && aiMessage.hasToolExecutionRequests()) {
while (messages.size() > messageToEvictIndex
&& messages.get(messageToEvictIndex) instanceof ToolExecutionResultMessage) {
// Some LLMs (e.g. OpenAI) prohibit ToolExecutionResultMessage(s) without corresponding AiMessage,
// so we have to automatically evict orphan ToolExecutionResultMessage(s) if AiMessage was evicted
messages.remove(messageToEvictIndex);
}
}
}
}可以看到,它首先会去调用message()去拿到所有的消息,然后检查传进来的是否是系统消息,如果是相同跳过,不同替换,然后他会根据最大消息上下文去剔除掉最早的那个消息,但是保留最早的系统消息
3.实现
接着,我们实现一个简单的消息存储
java
private final InMemoryChatMemoryStore store = new InMemoryChatMemoryStore();
@RequestMapping("/ServiceChat")
public String chat5(@RequestParam("chatId")String chatId,@RequestParam("message")String message) {
MessageWindowChatMemory chatMemory = MessageWindowChatMemory.builder().maxMessages(20)
.chatMemoryStore(this.store)
.alwaysKeepSystemMessageFirst(true)
.id(chatId)
.build();
Assistant assistant1 = AiServices.builder(Assistant.class)
.chatModel(chatModel)
.chatMemoryProvider(memoryId -> chatMemory)
.build();
return assistant1.chat2(chatId, message);
}
}这里官方提供了两个示例,一个就是支持根据会话id进行存储的如上,和不支持id存储的这个直接吧new出来的store传给AiServices.builder里面去就行了,不使用MessageWindowChatMemory对象。
因为消息是存在内存中的这里我们就不使用单元测试了,使用postman进行测试一下
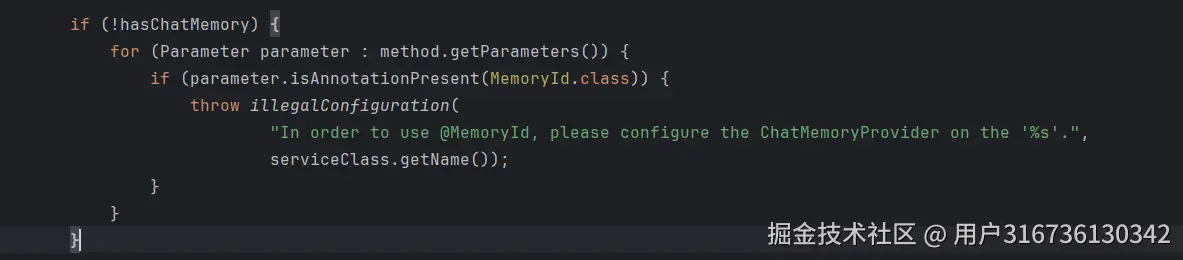
注意
上文说了可以直接使用@AiService注解获取一个AiService对象,但是如果你使用了MemoryId参数,只能手动去build一个AiService,因为他在创建的时候会去判断如果存在@MemoryId这个注解,就必须存在chatMemoryProvider对象。
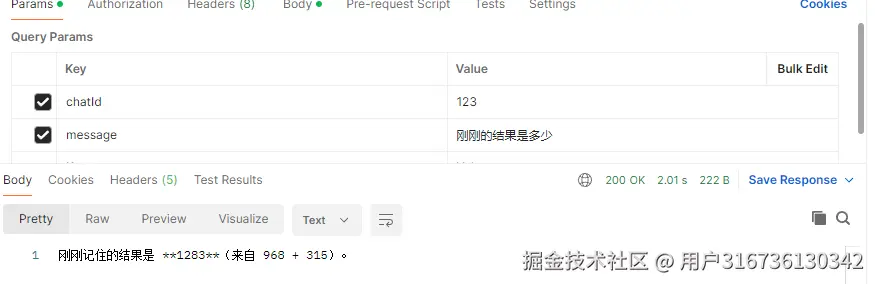
此时ai已经有了记忆功能,我们来看它发送的消息
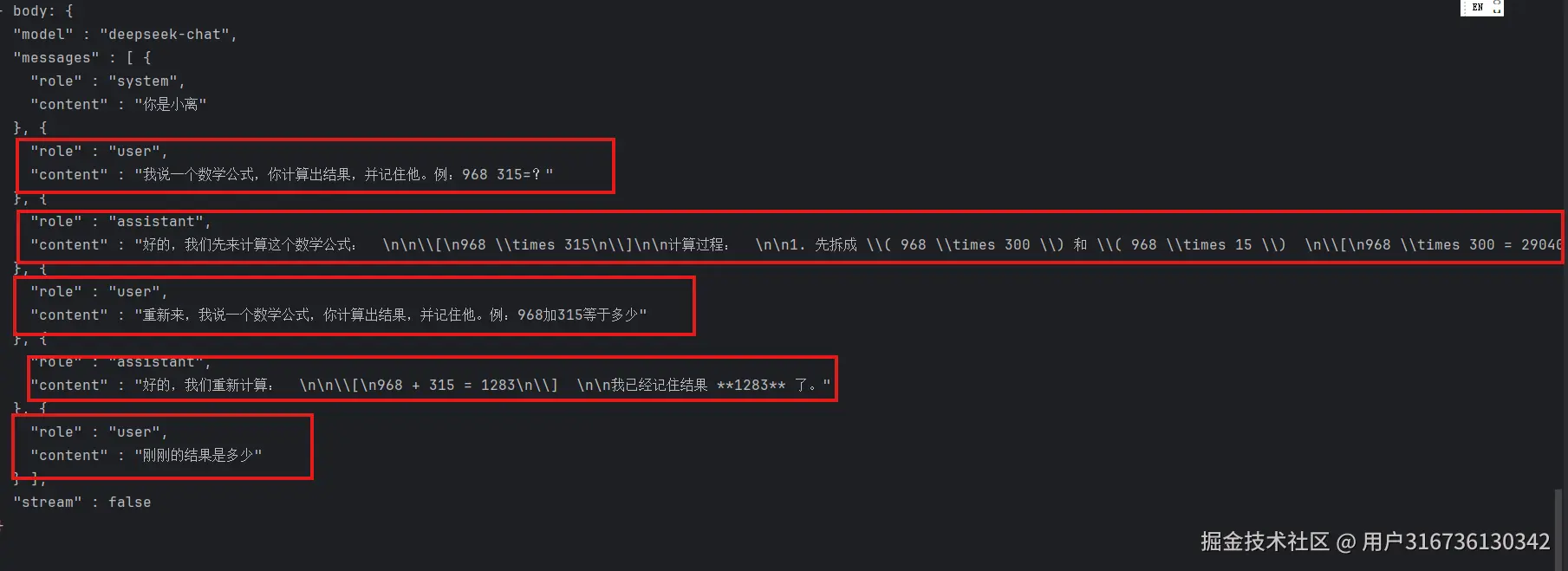
可见,他把我们之前对话的所有消息都存储了下来,并一次性都发送给了模型接口。
3.持久化消息
很多时候我们需要持久化消息,不能只放在内存中,假如出现故障或者程序关掉,宿主机内存不足了。这些情况发送的话,之前的消息可就都没了,官方提供了一个模板案例,是将数据持久化到数据库,这里我将消息持久化到Redis里面去,因为我刚刚数了一下,一次对话操作要读取两次所有的消息,还要一次性写入全部消息(覆盖之前的),可见是非常的消耗IO操作。
typescript
@Component
public class RedisChatStore implements ChatMemoryStore {
@Autowired
private RedissonClient redissonClient;
private final String STORE_KEY="CHAT_STORE:";
@Override
public List<ChatMessage> getMessages(Object memoryId) {
RMap<Object,Object> rset= redissonClient.getMap(this.STORE_KEY);
Object value= rset.get(memoryId);
if(value==null)return Collections.emptyList();
return ChatMessageDeserializer.messagesFromJson((String) value);
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> messages) {
RMap<Object,Object> rset= redissonClient.getMap(this.STORE_KEY);
rset.put(memoryId,ChatMessageSerializer.messagesToJson(messages));
}
@Override
public void deleteMessages(Object memoryId) {
redissonClient.getMap(this.STORE_KEY).remove(memoryId);
}
}首先我们需要先自己去实现这个接口,实现存储消息的逻辑
这里我使用了LangChain4j提供的方法来进行文本的序列化操作,底层使用的jackson
java
ChatMessageDeserializer.messagesFromJson();
ChatMessageSerializer.messageToJson()
java
.chatMemoryStore(this.redisStore)把刚刚的store替换成上面那个

这样我们就成功的把数据存储到了redis里面去,至于长期存储,也可以加个定时任务,定期落库存储。
二、文档检索
1.概念
什么是RAG?
简单来说,RAG 是在将提示发送给 LLM 之前,从您的数据中找到并注入相关信息片段的方法。
通过这种方式,LLM 将获得(希望是)相关信息,并能够利用这些信息进行回复,从而降低幻觉的发生概率。
目前最流行的RAG方法有:
- 全文(关键词)搜索:此方法使用 TF-IDF 和 BM25 等技术,通过将查询(例如用户的提问)中的关键词与文档数据库进行匹配来搜索文档。它根据关键词在每个文档中的频率和相关性对结果进行排名。
- 向量搜索 ,也称为"语义搜索":使用嵌入模型将文本文档转换为数字向量。然后,它根据查询向量和文档向量之间的余弦相似度或其他相似度/距离度量来查找和排名文档,从而捕捉更深层次的语义含义。
- 混合搜索:结合多种搜索方法(例如全文 + 向量)通常可以提高搜索的有效性。
这里langChain4j主要使用了向量搜索
同时也提供了三种不同的RAG
- Easy RAG:开始使用 RAG 的最简单方法
- Naive RAG:使用向量搜索的 RAG 基本实现
- Advanced RAG:一个模块化的 RAG 框架,允许进行额外的步骤,例如查询转换、从多个来源检索和重新排名
2.使用
这里我们从easyRag开始
2.1首先需要引入依赖
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.3.0-beta9</version>
</dependency>这里我使用Pg数据库进行向量数据的存储
具体的pg数据库以及pgvector插件安装可以看我上一篇文章
2.2需要引入pgEmbeddingStore的依赖,这是存储、删除和查询向量数据的对象
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-pgvector</artifactId>
<version>1.12.2-beta22</version>
</dependency>2.3我们需要弄一个向量模型用来拆分文本和检索向量数据使用.
这里我使用的阿里云来做演示具体看自己的情况也可以使用Ollama
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope</artifactId>
<version>1.0.0-beta3</version>
</dependency>接着我们需要去阿里云去申请apiKey等操作
2.4创建Bean对象
java
@Configuration
public class RagConfig {
@Bean
public PgVectorEmbeddingStore createEmbeddingStore() {
return PgVectorEmbeddingStore.builder()
.database("knowledge")
.dimension(1024)
.port(5432)
.host("127.0.0.1")
.user("postgres")
.table("items")
.password("password")
.build();
}
@Bean
public QwenEmbeddingModel createDashVectorClient(){
return QwenEmbeddingModel.builder()
.apiKey("sk-xxxxxxxxxxxxx")
.modelName("text-embedding-v4")
.build();
}
}比较坑的是阿里云集成Langchain的客户端的这个embedding不支持自定义维度,默认的1024,这里我们先改成1024吧。如果后面有能力的话,我再来尝试自己封装一个客户端
修改数据库的向量维度为1024
sql
ALTER TABLE items ALTER COLUMN embedding TYPE vector(1024);2.5文档解析器
scss
@Component
public class LoadMdDocument implements loadDocument {
@Autowired
private PgVectorEmbeddingStore store;
@Autowired
private QwenEmbeddingModel embeddingModel;
@Override
public void parseDocument(String path) {
Document document = FileSystemDocumentLoader.loadDocument(path, new ApacheTikaDocumentParser());
DocumentByParagraphSplitter documentByParagraphSplitter =new DocumentByParagraphSplitter(1000,500);
EmbeddingStoreIngestor ingestor= EmbeddingStoreIngestor.builder().embeddingModel(embeddingModel)
.embeddingStore(this.store)
.documentSplitter(documentByParagraphSplitter)
.textSegmentTransformer(textSegment->TextSegment.from(
textSegment.metadata().getString("file_name")+"\n"+textSegment.text(),
textSegment.metadata()))
.documentTransformer(doc -> {doc.metadata().put("usrId",123);
return doc;
}).build();
ingestor.ingest(document);
}
}这里官方提供了一个示例,LangcHain4j一共提供了三个解析文档的对象
分别是
arduino
ApacheTikaDocumentParser //能够解析PDF, DOC, PPT, XLS, and many others.
TextDocumentParser //只能够解析纯文本
ApachePdfBoxDocumentParser //解析pdf专用DocumentByParagraphSplitter是文本拆分器,它的两个参数分别是,多长的文本拆分为一段和重叠的长度

除此之外框架还提供了其中分词器,分别是根据单词和句子分词,等。这里不再细究了。
textSegmentTransformer:处理document文档时进行的一些操作,这里是添加到将文件的名称添加到textSegment的对象里面去了
documentTransformer:是为textSegment对象的metadata添加更多的信息,方便检索消息时根据条件进行过滤使用

我在文档加载那里打个断点,可以看见md文档的所有文档和文件本身的metadata属性已经被加载出来了。
2.6文档处理和插入
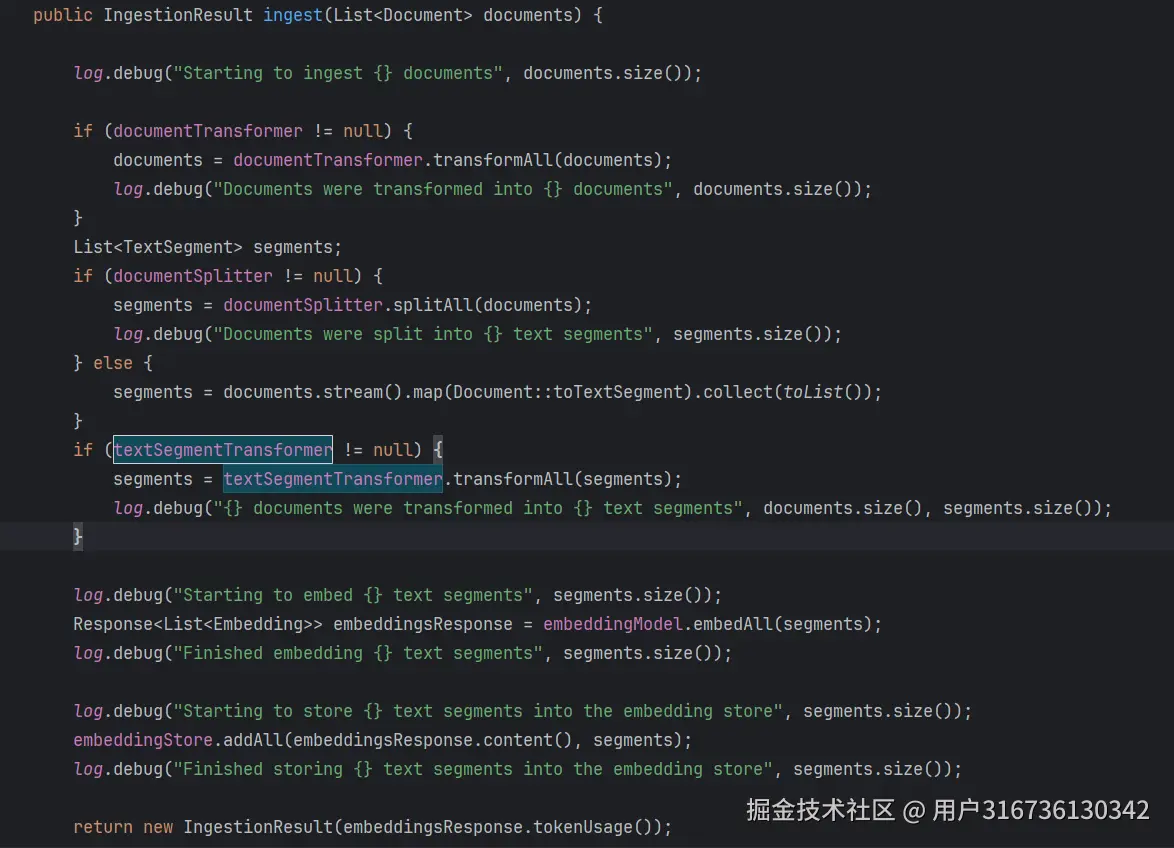
在ingest方法里面进行了一些的信息组装和向量拆分的操作,好比刚才做的是准备工作,这里直接按流水线执行了。
但是这里面有一个比较鸡肋的点,如果使用他这个,你没有办法获取插入每条数据的id,不能很方便的在移出文档的时候去删除
我这里想了几个做法,
1.重写这个对象和方法
因为**embeddingStore.addAll(embeddingsResponse.content(), segments);**本身是由返回值的返回了生成的id,在整个操作完成我们可以把这个id存到数据库里面去
2.为textSegment的metadata这个对象添加id(匹配)
我们自己实现对数据库的delete功能,本身pg数据有对json数据的存储和查询有较好的支持,根据匹配的数据进行删除
2.7数据落库
放行断点,可见embeddingStore这个对象已经把数据插入到了数据库里面去了

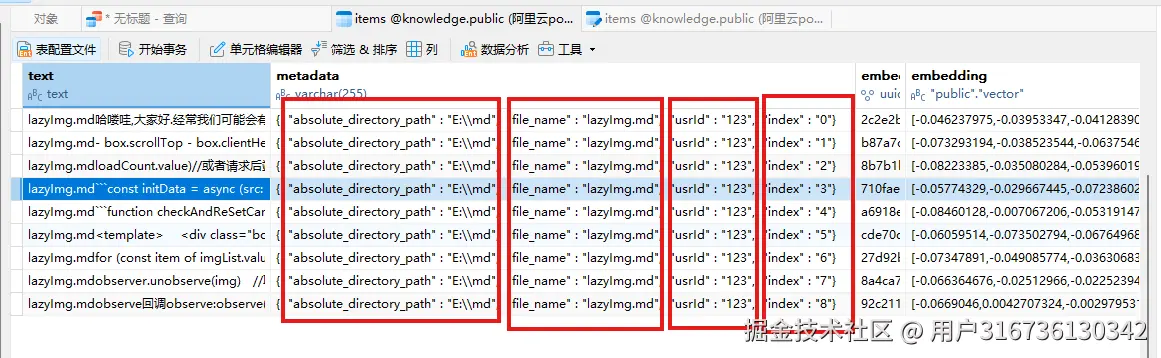
一个简单的文档检索和存储过程大概就是这样
3.使用文档检索
上面我们成功存储了文档的向量数据,紧接着需要去使用它
3.1contentRetriever对象
默认情况下Langchain带有三个检索器
从上到下分别是

- 向量仓库检索器
- 检索监听器
- 网页搜索检索器
第一个必备多说,是我们将要使用的
第二个是检索文档的时候会去调用实现了ContentRetrieverListener接口的方法去处理检索之前和之后的文本上下文
第三个是搜索网络上与用户信息(UsrMessage)相关的内容
java
@RequestMapping("/ServiceChat")
public String chat5(@RequestParam("chatId")String chatId,@RequestParam("message")String message) {
MessageWindowChatMemory chatMemory = MessageWindowChatMemory.builder().maxMessages(20)
.chatMemoryStore(this.redisStore)
.alwaysKeepSystemMessageFirst(true)
.id(chatId)
.build();
Assistant assistant1 = AiServices.builder(Assistant.class)
.chatModel(chatModel)
.chatMemoryProvider(memoryId -> chatMemory)
.contentRetriever(EmbeddingStoreContentRetriever.builder()
.embeddingStore(this.pgStore)
.embeddingModel(this.embeddingModel)
.maxResults(3)
.minScore(0.75)
.build()
)
.build();
List<ChatMessage> chatMessages=chatMemory.messages();
chatMessages.forEach(System.err::println);
return assistant1.chat2(chatId, message);
}这里我简单实现一下
maxResults是匹配3条数据
minScore是匹配相似度分数,必须达到0.75分以上才会添加进去
3.2测试
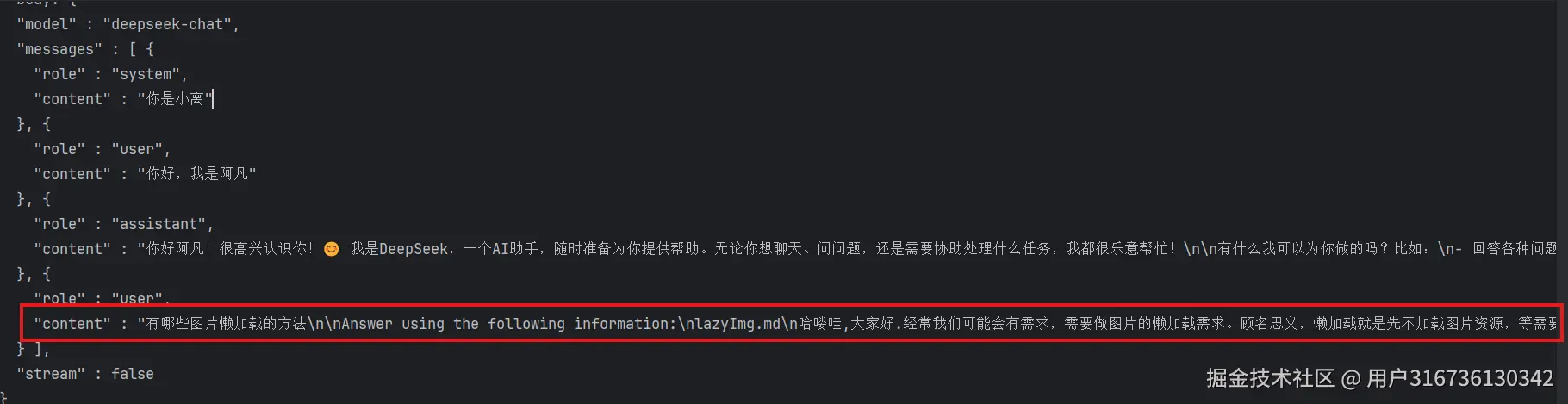
从发出的文本可以看见,他已经把检索到的文档内容添加到了userMessage里面去了

最后呢ai也是把我的文档做了一个总结,可以看出他是比较贴合我的文档内容的,同时也对我文档内容进行了一个更好的总结和优劣势总结。
好了,今天我就给大家分享到这里,下次我们接着看这个框架,彻底吃透它。