目录
- 第一类:回归任务(预测具体数值)
-
- [👓1. MSE (均方误差) ------ 重罚离群点](#👓1. MSE (均方误差) —— 重罚离群点)
- [👓2. MAE (平均绝对误差) ------ 鲁棒性强](#👓2. MAE (平均绝对误差) —— 鲁棒性强)
- 第二类:分类任务(判断属于哪一类)
-
- [👓3. Binary Cross-Entropy (二分类交叉熵) ------对自信的错误零容忍](#👓3. Binary Cross-Entropy (二分类交叉熵) ——对自信的错误零容忍)
- [👓4. Categorical Cross-Entropy (多分类交叉熵) ------ 竞争机制](#👓4. Categorical Cross-Entropy (多分类交叉熵) —— 竞争机制)
- [👓5. Hinge Loss (铰链损失) ------ 边界思维](#👓5. Hinge Loss (铰链损失) —— 边界思维)
没有最强的损失函数,只有最契合业务逻辑的标尺。回归任务是在衡量'物理距离',所以我们根据对噪声的容忍度在 MSE 与 MAE 间抉择;分类任务是在衡量'决策信心',所以我们根据对概率的渴望程度在 交叉熵 与 Hinge Loss 间博弈。
第一类:回归任务(预测具体数值)
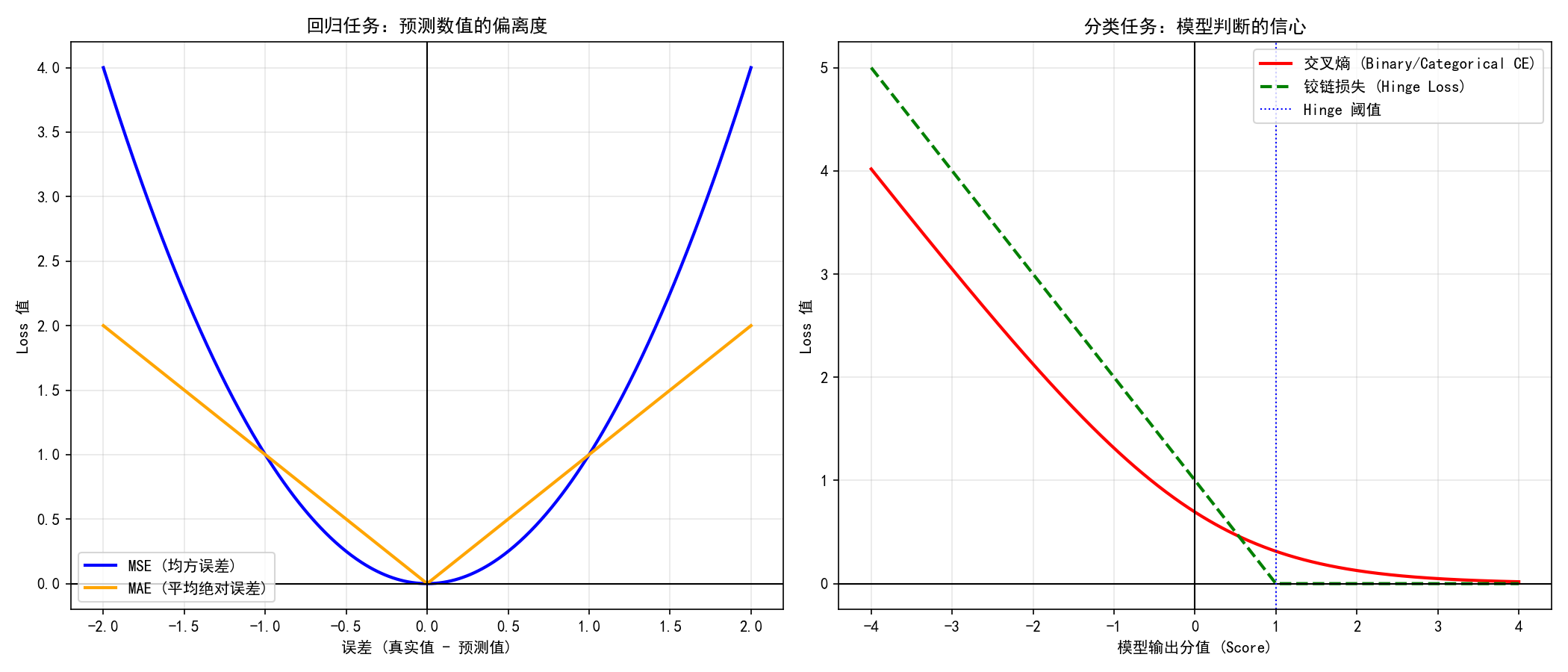
👓1. MSE (均方误差) ------ 重罚离群点
- 应用场景:房价预测、自动驾驶中的车距预测、气温预报。
- 特性体现:由于误差被平方,模型对较大的偏离极其敏感。
- 差异化选择:如果你的业务场景要求绝对不许出现巨大误差(例如自动驾驶,差 1 米可能没事,差 10 米就是事故),请选 MSE。它会强迫模型去修正那些大误差,代价是它可能会被少量的"脏数据"带偏。
👓2. MAE (平均绝对误差) ------ 鲁棒性强
- 应用场景:存在异常值的金融数据分析、带有噪声的传感器数据建模。
- 特性体现:误差是线性增长的。它对离群点(Outliers)非常迟钝。
- 差异化选择:如果你的数据里经常有信号干扰产生的"脏数据"(比如温度计偶尔跳出一个 1000 度),请选 MAE。它会忽略这些极端个例,专注于拟合大部分正常数据的规律。
第二类:分类任务(判断属于哪一类)
👓3. Binary Cross-Entropy (二分类交叉熵) ------对自信的错误零容忍
- 应用场景:垃圾邮件过滤(是/否)、疾病诊断(患病/健康)、广告点击率预测。
- 特性体现:利用对数(Log)大幅放大错误概率的惩罚。
- 差异化选择:它不仅要求你分类正确,还要求你概率越高越好。在医学诊断中,如果你把癌症患者预测为"健康"的概率是 90%,BCE 会给模型一个近乎"无限大"的惩罚,逼迫模型产生极其剧烈的调整。
👓4. Categorical Cross-Entropy (多分类交叉熵) ------ 竞争机制
- 应用场景:人脸识别、手写数字识别(MNIST)、动物种类识别。
- 特性体现:配合 Softmax 使用,将多个类别的得分转化为总和为 1 的概率分布。
- 差异化选择:它具有 "排他性" 。当你提升"猫"这个类别的置信度时,它会自动压低"狗"和"鸟"的置信度。适用于这种"一画一物"的排他性分类。
👓5. Hinge Loss (铰链损失) ------ 边界思维
- 应用场景:支持向量机 (SVM) 文本分类、人脸比对(Face Verification)。
- 特性体现:只关注 "安全间隔(Margin)" 。
- 差异化选择:它非常"佛系"。只要你的分类正确,并且两类之间拉开了足够的距离(比如得分超过了 1.0),它就认为任务完成了,Loss 变成 0,不再浪费算力。
- 硬件优势:在 AI 芯片实现中,它比交叉熵省电得多,因为它不需要复杂的对数和指数运算,只需要简单的减法和比较。