一、引言
在实际爬虫开发中,最复杂的场景莫过于:网站通过POST请求动态加载更多内容,且返回的数据结构不稳定------某些字段可能在某些页面中缺失。这种情况下,爬虫需要同时处理复杂的请求参数计算和灵活的字段容错机制。
本文将深入分析一个针对 packaging-gateway.com 博客站点的爬虫设计案例。该爬虫创新性地解决了 "POST动态加载的偏移量计算" 和 "字段缺失的双路条件分支容错" 两大核心难题,实现了对动态加载数据的高效稳定采集。
与之前案例的核心差异:
- 加载方式差异:POST动态加载"更多"内容(之前多为静态分页)
- 分页计算差异:偏移量 = page × 9(之前多为page直接传递)
- 容错机制差异:双路条件分支处理字段缺失(之前多为单一判断)
- ID处理差异:无ID字段(直接使用URL去重)
- 请求参数差异:固定nonce令牌和post_not_ids黑名单
二、系统架构与核心流程
2.1 整体架构设计
该爬虫采用 "偏移量计算 + JSON嵌套HTML解析 + 双路条件分支容错" 的架构,整体流程如下:
是
否
否
是
存在
缺失
开始
时间范围计算
30天窗口
查询数据库已有记录
是否有新数据?
POST请求动态接口
offset = page × 9
结束流程
JSONPath解析
提取$.content
从HTML片段中
提取URL列表
输出URL列表
循环处理每个URL
是否已存在?
抓取新闻详情页
提取字段
标题/作者/时间/内容
release_date
是否存在?
正常输出
备用字段提取
从不同位置取时间
存入数据库
2.2 数据流向图

三、关键技术难点与解决方案
难点一:POST动态加载的偏移量计算
问题描述:
该网站通过POST请求动态加载更多内容,分页参数不是传统的page页码,而是offset偏移量。每页固定显示9条,需要将页码转换为偏移量:offset = page × 9。
解决方案:
在请求参数中动态计算偏移量:
javascript
// 抓取网站列表节点配置
{
"url": "https://www.packaging-gateway.com/wp-admin/admin-ajax.php",
"method": "POST",
"body-type": "form-data",
"parameter-form-name": ["action", "offset", "nonce", "taxonomy", "term_id"],
"parameter-form-value": [
"my_category_show_more", // 固定action
"${page*9}", // 动态计算偏移量
"419e756fb1", // 固定nonce令牌
"category", // 固定分类
"2" // 固定term_id
]
}
// 定义变量节点 - 分页控制
{
"variable-name": ["news_urllist", "page"],
"variable-value": [
"${page==null?null:extract.selectors(extract.jsonpath(resp.json, '$.content'), 'h3>a', 'attr', 'href')}",
"${page==null?0:page+1}" // page从0开始,便于计算offset
]
}
// 循环控制条件
"condition": "${page<=0}" // 只抓取第一页(offset=0)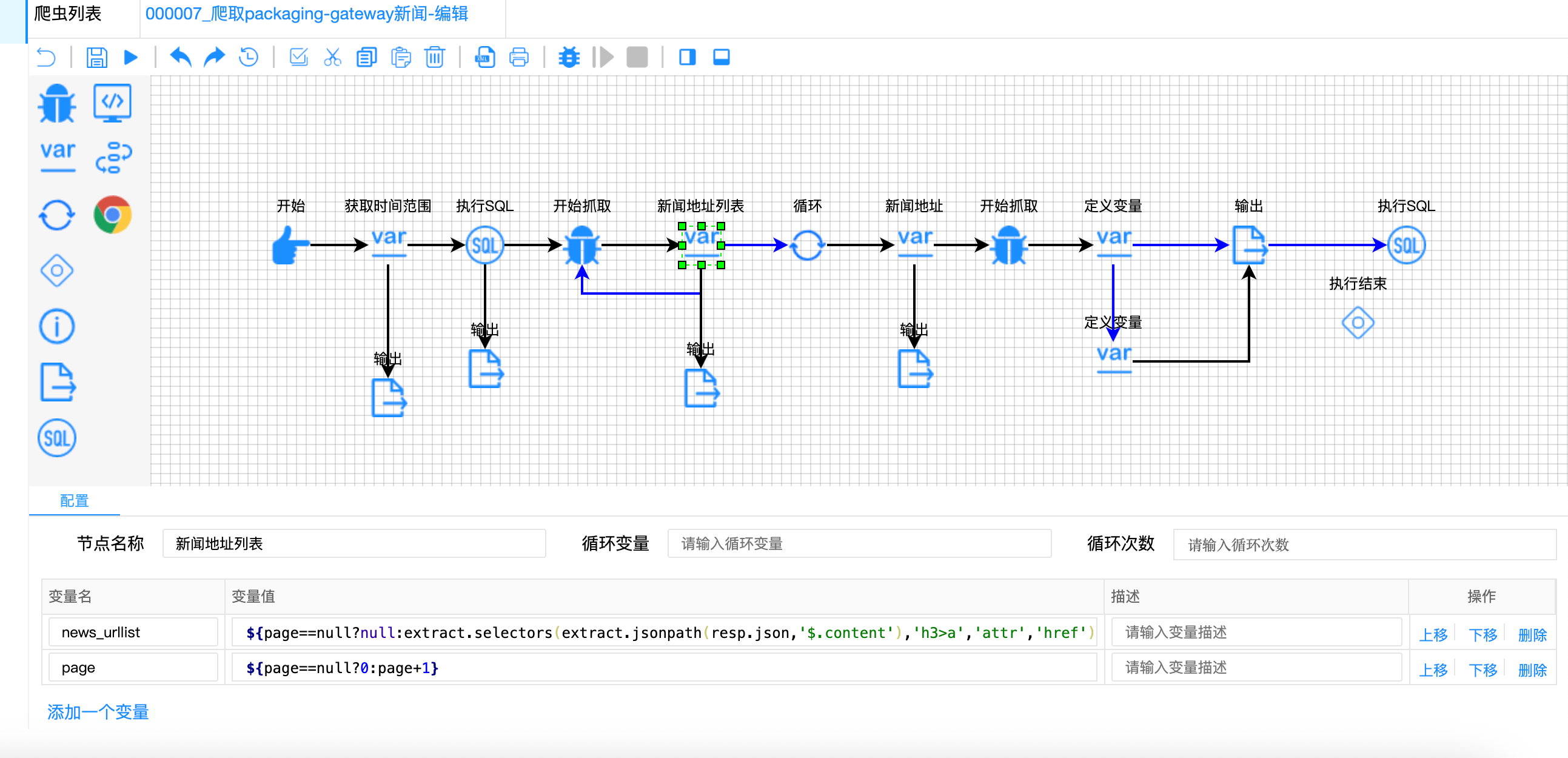
偏移量计算原理图:
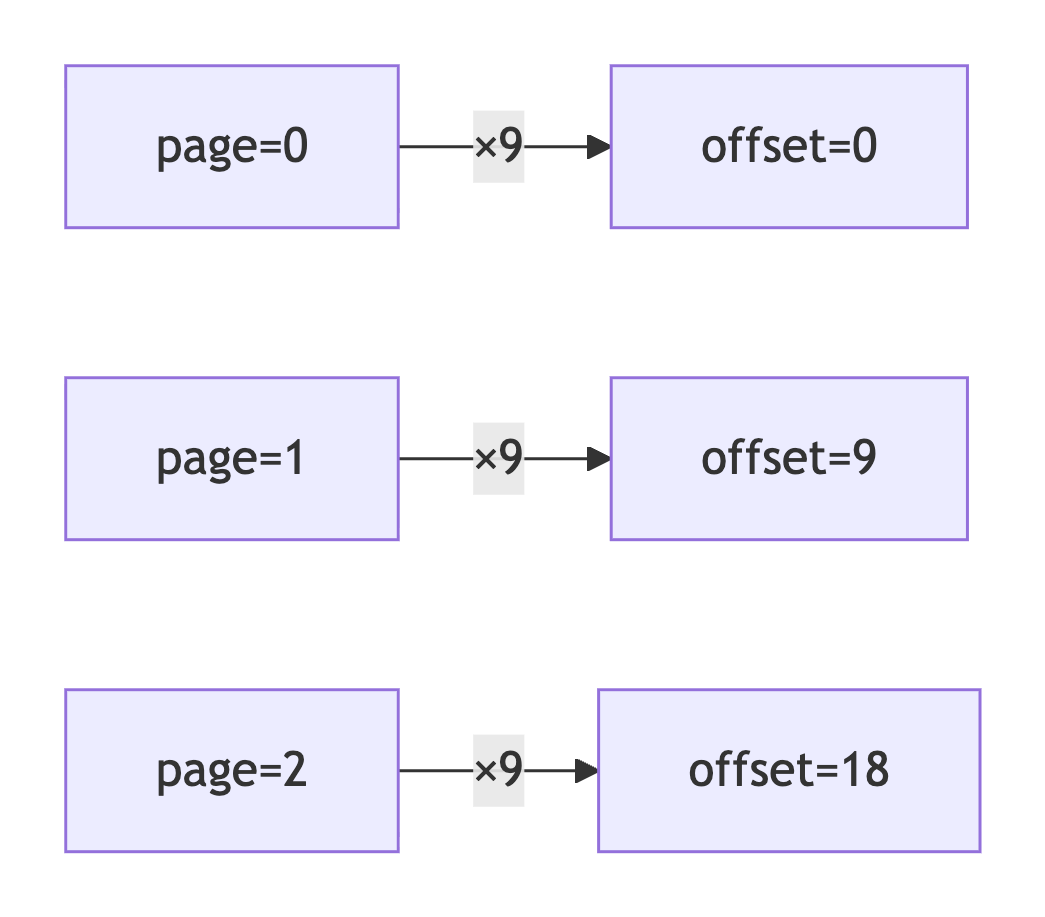
分页参数对照表:
| 请求次数 | page变量 | offset计算 | URL中的offset | 说明 |
|---|---|---|---|---|
| 第1次 | null | - | 不请求 | 初始化 |
| 第2次 | 0 | 0×9=0 | offset=0 | 第一页 |
| 第3次 | 1 | 1×9=9 | offset=9 | 触发page<=0条件,停止 |
难点二:双路条件分支容错机制
问题描述:
该网站的详情页结构不稳定,release_date字段可能出现在两个不同的位置:有时在.article-meta>span:nth-child(2),有时在.article-meta>span:nth-child(1)。如果只使用一个选择器,会导致数据丢失。
解决方案:
设计 "主备双路条件分支" 容错机制:
javascript
// 主路径:正常提取
{
"variable-name": ["title", "news_author", "release_date", "content"],
"variable-value": [
"${extract.selector(resp.html, '.article-header__title')}",
"${extract.selector(resp.html, '.article-meta>span:nth-child(1)>a')}",
"${extract.selector(resp.html, '.article-meta>span:nth-child(2)')}", // 主时间字段
"${extract.selector(resp.html, '.main-content')}"
]
}
// 条件分支:如果主时间字段为空
"condition": "${release_date==null}" // 蓝色连线
// 备用路径:从其他位置提取
{
"variable-name": ["release_date", "news_author"],
"variable-value": [
"${extract.selector(resp.html, '.article-meta>span:nth-child(1)')}", // 备用时间字段
"${null}" // 作者置空(因为此时时间占了作者位置)
]
}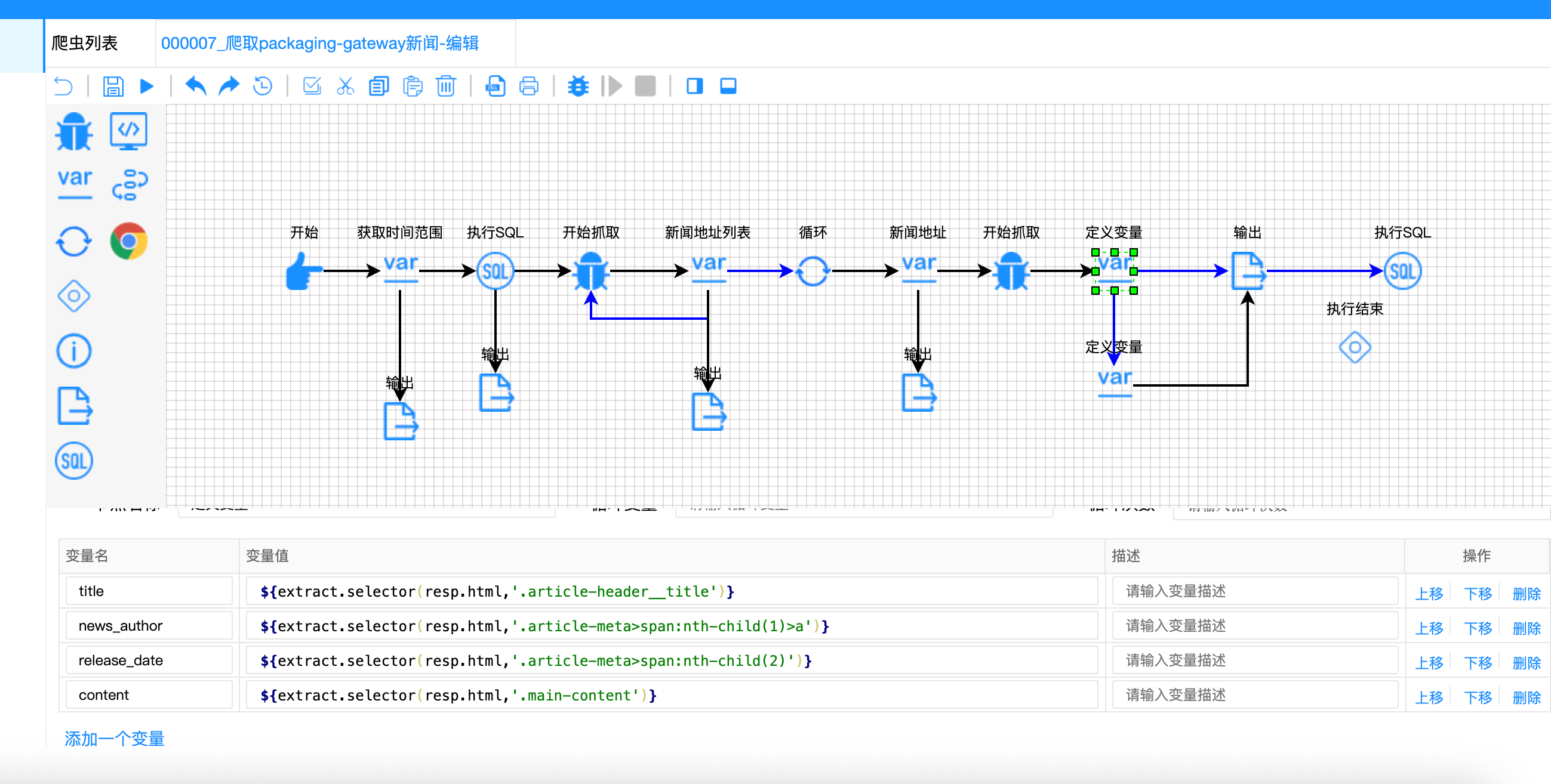
双路容错原理图:
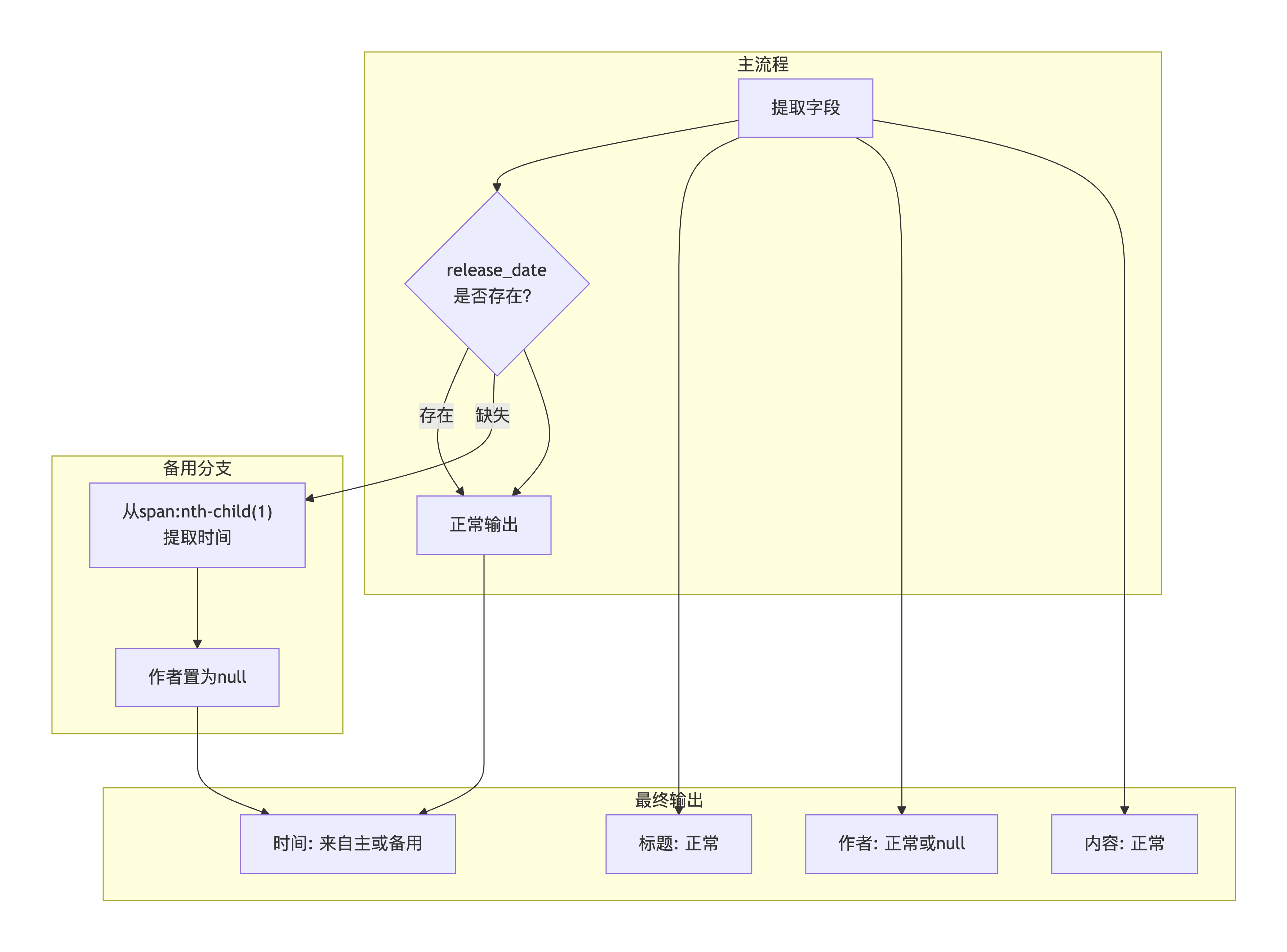
两种页面结构对比:
html
<!-- 结构A:时间在span:nth-child(2) -->
<div class="article-meta">
<span><a href="/author/john">John Doe</a></span> <!-- 作者 -->
<span>2024-01-15</span> <!-- 时间 -->
</div>
<!-- 结构B:时间在span:nth-child(1) -->
<div class="article-meta">
<span>2024-01-15</span> <!-- 时间 -->
<!-- 没有作者信息 -->
</div>难点三:JSON嵌套HTML的双层解析
问题描述:
接口返回的是JSON数据,但真正的列表HTML被包裹在$.content字段中。需要先解析JSON获取HTML字符串,然后再从HTML中提取URL。
解决方案:
采用 "JSONPath + CSS选择器" 双层解析策略:
javascript
// 双层解析
"${extract.selectors(
extract.jsonpath(resp.json, '$.content'), // 先取JSON中的HTML
'h3>a', // 再从HTML中取链接
'attr',
'href'
)}"双层解析示意图:
JSONPath
$.content
CSS选择器
h3>a
JSON响应
HTML字符串
URL列表
难点四:无ID字段的URL去重
问题描述:
该网站没有独立的新闻ID字段,只能直接使用URL作为唯一标识。
解决方案:
直接使用URL构造Map对象进行去重:
javascript
// 新闻地址节点
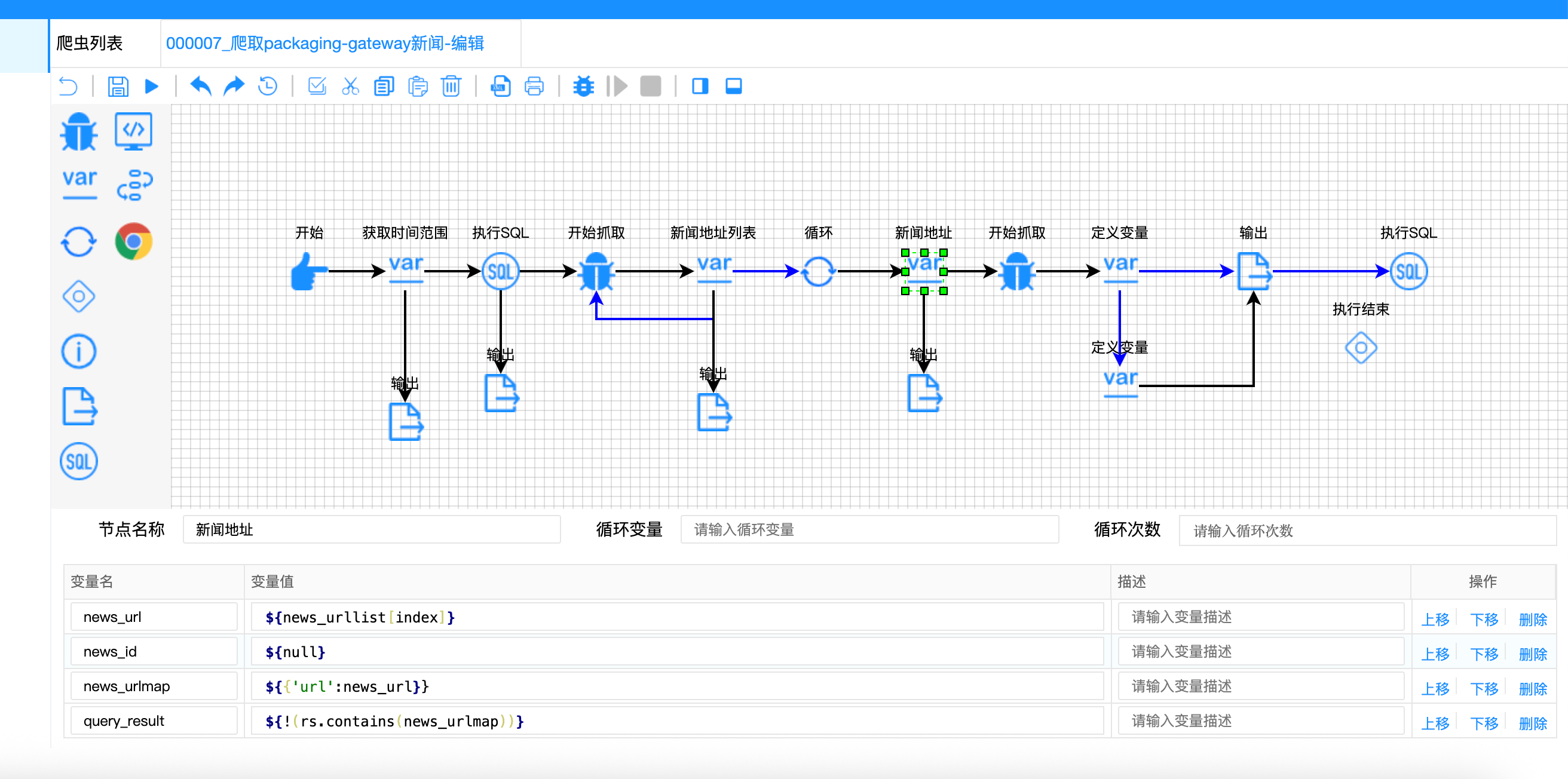
{
"variable-name": ["news_url", "news_id", "news_urlmap", "query_result"],
"variable-value": [
"${news_urllist[index]}", // 直接使用URL
"${null}", // ID字段置空
"${{'url': news_url}}", // 构造Map用于去重
"${!(rs.contains(news_urlmap))}" // 去重判断
]
}
难点五:30天时间窗口
问题描述:
需要抓取最近30天的博客文章,反映该网站更新频率适中。
解决方案:
动态时间范围计算:
javascript
// 获取时间范围节点
{
"variable-name": ["start_date", "end_date"],
"variable-value": [
"${date.format(date.addDays(date.now(),-30),'yyyy-MM-dd')}", // 30天前
"${date.format(date.addDays(date.now(),1),'yyyy-MM-dd')}" // 明天
]
}四、核心代码实现解析
4.1 偏移量计算器
javascript
// 伪代码:偏移量计算器
class OffsetPaginationCalculator {
constructor(pageSize = 9) {
this.pageSize = pageSize;
this.currentPage = null;
}
getNextOffset() {
if (this.currentPage === null) {
return null; // 首次不请求
}
return this.currentPage * this.pageSize;
}
updatePage() {
if (this.currentPage === null) {
this.currentPage = 0; // 第一次请求后设为0
} else {
this.currentPage++;
}
}
shouldContinue() {
return this.currentPage <= 0; // 只抓一页
}
}
// 使用示例
const calculator = new OffsetPaginationCalculator(9);
// 第一次请求后
calculator.updatePage(); // currentPage = 0
const offset = calculator.getNextOffset(); // 04.2 双路容错处理器
javascript
// 伪代码:双路容错处理器
class FaultTolerantExtractor {
async extractWithFallback(html) {
// 主路径提取
const mainResult = this.extractMain(html);
// 检查关键字段是否缺失
if (this.isFieldMissing(mainResult.releaseDate)) {
// 使用备用路径
return this.extractFallback(html);
}
return mainResult;
}
extractMain(html) {
return {
title: this.extractText(html, '.article-header__title'),
author: this.extractText(html, '.article-meta>span:nth-child(1)>a'),
releaseDate: this.extractText(html, '.article-meta>span:nth-child(2)'),
content: this.extractText(html, '.main-content')
};
}
extractFallback(html) {
return {
title: this.extractText(html, '.article-header__title'),
author: null, // 备用路径没有作者
releaseDate: this.extractText(html, '.article-meta>span:nth-child(1)'),
content: this.extractText(html, '.main-content')
};
}
isFieldMissing(value) {
return value === null || value === undefined || value === '';
}
}4.3 双层解析器
javascript
// 伪代码:双层解析器
class NestedHtmlParser {
parseResponse(jsonResponse) {
// 第一层:JSONPath提取HTML
const html = this.extractHtmlFromJson(jsonResponse);
if (!html) return [];
// 第二层:从HTML中提取URL
return this.extractUrlsFromHtml(html);
}
extractHtmlFromJson(json) {
return json?.content || '';
}
extractUrlsFromHtml(html) {
// 使用正则模拟CSS选择器
const regex = /<h3><a[^>]+href="([^"]+)"[^>]*>/g;
const urls = [];
let match;
while ((match = regex.exec(html)) !== null) {
urls.push(match[1]);
}
return urls;
}
}五、与前六个案例的对比分析
5.1 核心差异点对比
| 维度 | packaging-gateway | 雅式橡塑网 | icis新闻 | polymerupdate博客 | polymerupdate新闻 | bioplasticsnews | chemanalyst |
|---|---|---|---|---|---|---|---|
| 加载方式 | POST动态加载 | GET静态分页 | GET静态分页 | POST静态分页 | POST静态分页 | GET静态分页 | GET静态分页 |
| 分页参数 | offset=page×9 | page | page | page | page | page | page |
| 分页起始 | page从0开始 | page从2开始 | page从1开始 | page从1开始 | page从1开始 | page从1开始 | page从1开始 |
| 容错机制 | 双路条件分支 | 无 | 无 | 无 | 无 | 无 | 无 |
| ID字段 | 无(null) | 纯数字 | 复杂正则 | 对象属性 | URL正则 | post-数字 | URL正则 |
| 数据源 | JSON嵌套HTML | HTML属性 | JSON嵌套HTML | 纯JSON | HTML | HTML | HTML |
| 时间窗口 | 30天 | 7天 | 90天 | 30天 | 7天 | 90天 | 7天 |
| 解析复杂度 | ⭐⭐⭐ | ⭐ | ⭐⭐⭐ | ⭐⭐ | ⭐ | ⭐⭐ | ⭐ |
5.2 差异化技术难点
packaging-gateway
POST动态加载
offset=page×9
双路条件分支容错
无ID字段
纯URL去重
前六个案例
静态分页
单一字段提取
有ID字段
5.3 分页方式演进
GET参数分页
?page=2
POST表单分页
Body: Page=2
路径参数分页
/page/2/
偏移量计算分页
offset=page×9
六、性能优化与最佳实践
6.1 偏移量计算优化
javascript
// 通用的偏移量计算
function calculateOffset(page, pageSize = 9) {
return page * pageSize;
}
// 页码转换
function pageToOffset(page) {
return {
offset: page * 9,
nextPage: page + 1
};
}6.2 容错策略优化
| 策略 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 单一路径 | 结构稳定 | 简单 | 容错性差 |
| 双路分支 | 两种结构 | 容错性好 | 代码复杂 |
| 多路选择 | 多种结构 | 最可靠 | 维护成本高 |
6.3 无ID字段去重优化
javascript
// URL标准化处理
function normalizeUrl(url) {
// 移除URL末尾的斜杠
url = url.replace(/\/$/, '');
// 移除UTM参数
url = url.replace(/\?utm_.*$/, '');
return url;
}
// 去重判断
const normalizedUrl = normalizeUrl(news_url);
const isDuplicate = existingUrls.has(normalizedUrl);七、总结与经验分享
7.1 核心收获
- 偏移量分页技术:处理非标准分页参数,将页码转换为偏移量
- 双路容错机制:应对页面结构不稳定的情况,确保数据完整性
- 无ID去重策略:直接使用URL作为唯一标识
- POST动态加载:处理"加载更多"类型的AJAX接口
7.2 可复用经验
- 分析加载方式:通过浏览器开发者工具识别是静态分页还是动态加载
- 计算偏移量:观察请求参数,找出页码与偏移量的转换关系
- 设计容错分支:分析页面结构变化,设计主备两条提取路径
- URL标准化:对URL进行标准化处理,提高去重准确性
7.3 适用场景
该爬虫设计模式适用于:
- 使用"加载更多"按钮的动态网站
- 页面结构不稳定的网站
- 没有独立ID字段的网站
- 需要高容错性的数据采集
八、附录:核心配置对照表
| 节点类型 | 核心作用 | 关键技术点 |
|---|---|---|
| 获取时间范围 | 动态计算30天窗口 | date.addDays(now,-30) |
| 执行SQL(查询) | 获取已抓取URL | like '%packaging-gateway.com%' |
| 开始抓取(列表) | POST动态加载 | offset = page×9 |
| 新闻地址列表 | 双层解析 | JSONPath + CSS选择器 |
| 新闻地址 | 无ID处理 | news_id = null |
| 开始抓取(详情) | 获取详情页 | 代理IP |
| 定义变量(主) | 主路径提取 | 标准选择器 |
| 定义变量(备) | 备用路径提取 | 不同选择器 |
| 输出 | 数据汇总 | 合并主备路径结果 |
| 执行SQL(插入) | 存储数据 | source='packaging-gateway' |
通过以上设计,该爬虫成功应对了POST动态加载和字段缺失容错的双重挑战,实现了对packaging-gateway.com博客网站的高效稳定采集。其中的偏移量计算技术、双路条件分支容错等思路,对于处理动态加载和不稳定页面结构的爬虫开发具有很高的参考价值。