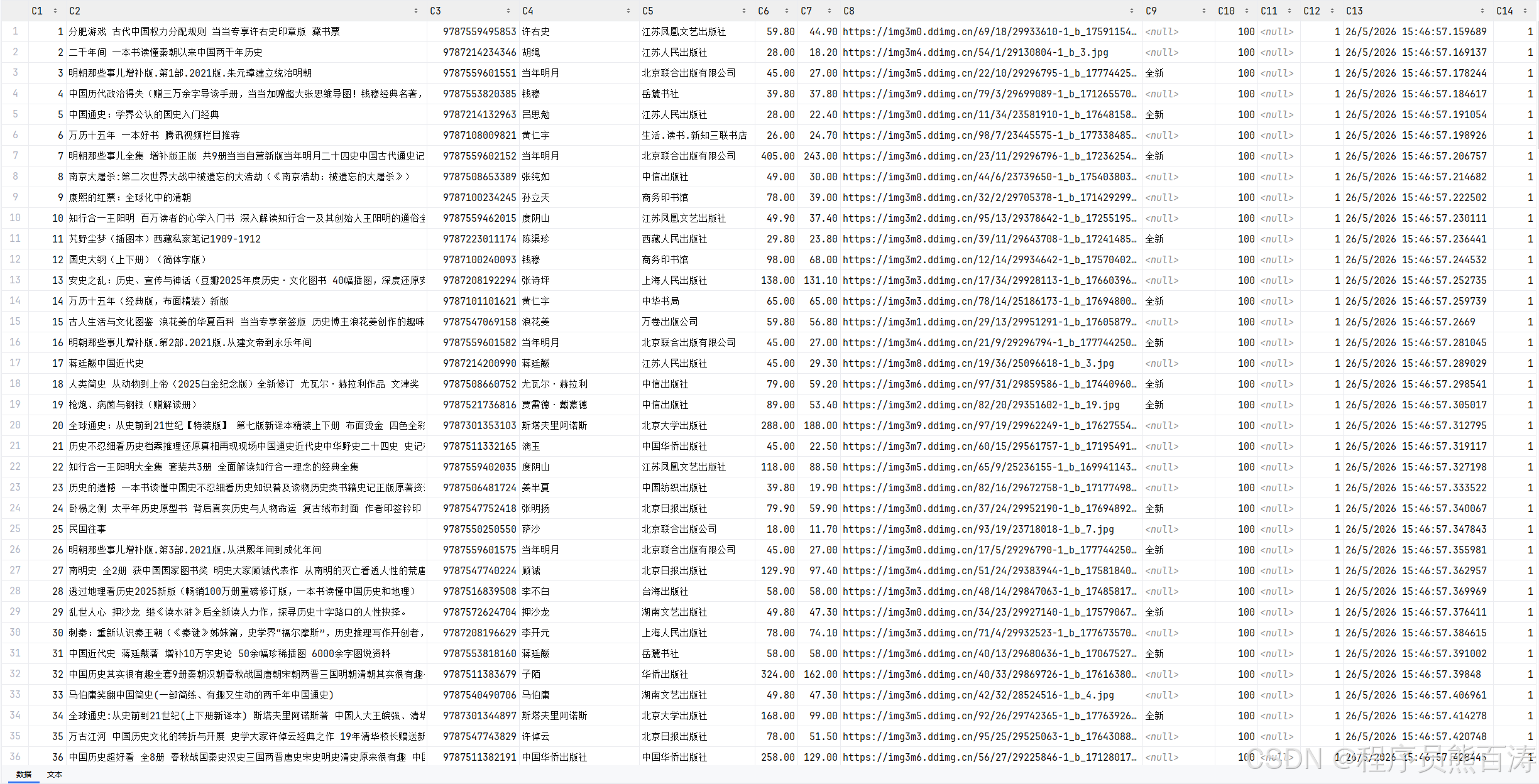
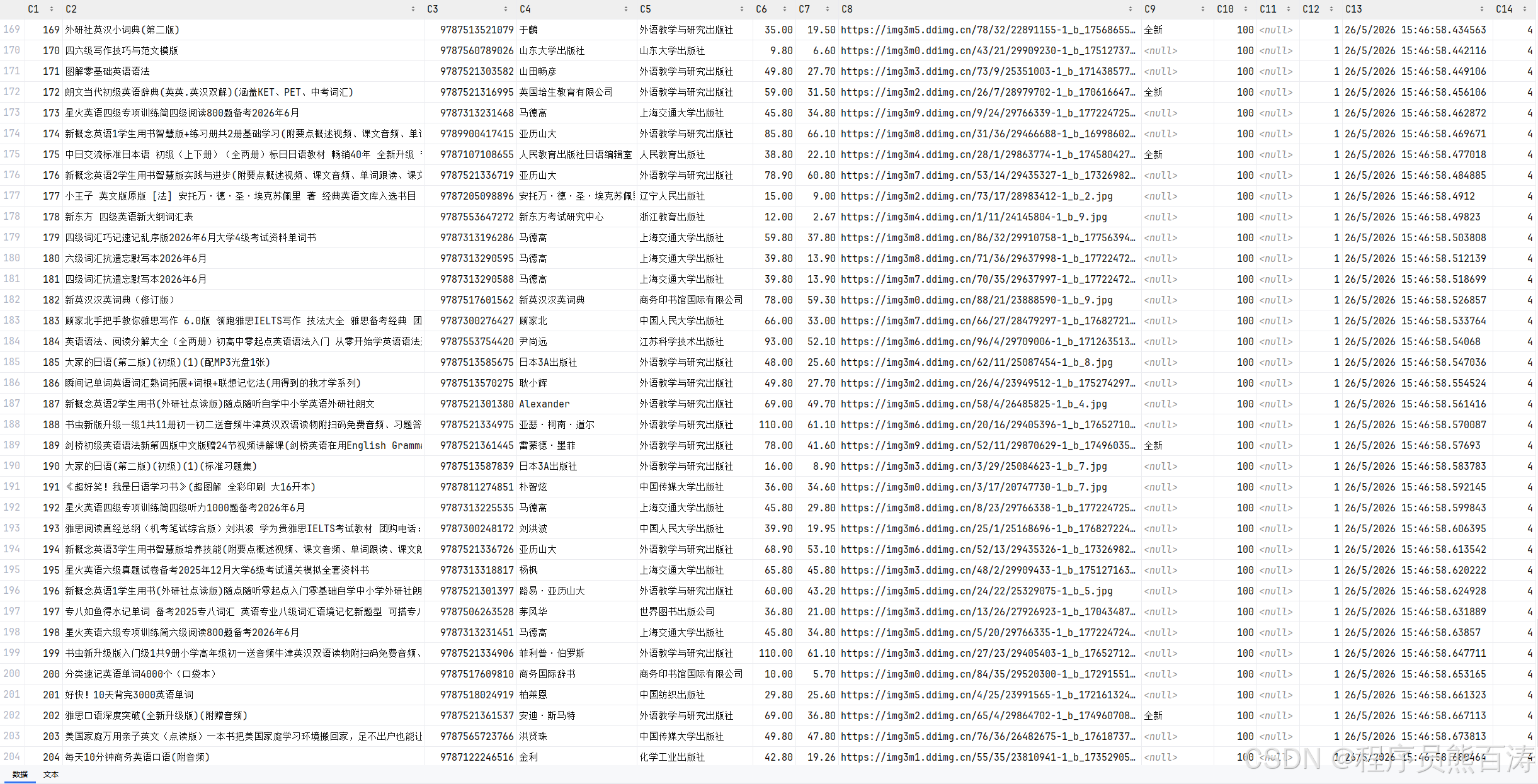
当当网二手图书爬虫技术详解
📖 一、项目概述
本项目是一个基于 Python 的当当网二手图书爬虫,专门用于抓取当当网分类页面中的二手图书信息。
1.1 目标功能
| 输出字段 | 说明 |
|---|---|
isbn |
图书 ISBN 号 |
title |
图书标题 |
author |
作者 |
publisher |
出版社 |
original_price |
原价 |
secondhand_price |
二手价 |
cover_image_url |
封面图片 URL |
condition |
图书品相(五成新、七成新等) |
category |
所属分类 |
🏗️ 二、技术架构
2.1 核心依赖
python
import requests # HTTP 请求库
from bs4 import BeautifulSoup # HTML 解析库
import re # 正则表达式
import json # JSON 序列化
import logging # 日志记录
import argparse # 命令行参数解析
from dataclasses import dataclass # 数据类
from urllib.parse import * # URL 处理工具2.2 整体架构图
┌─────────────────────────────────────────────────────────────┐
│ DangdangSpider │
├─────────────────────────────────────────────────────────────┤
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────────────┐ │
│ │ crawl() │ │ fetch() │ │ parse_category_ │ │
│ │ 主编排程 │ │ 页面请求 │ │ page() 列表解析 │ │
│ └─────────────┘ └─────────────┘ └─────────────────────┘ │
│ │
│ ┌─────────────────────┐ ┌───────────────────────────────┐ │
│ │ parse_book_card() │ │ merge_detail() │ │
│ │ 列表页数据提取 │ │ 详情页数据合并 │ │
│ └─────────────────────┘ └───────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────┐
│ DangdangBook │
│ 数据模型 │
└─────────────────┘📊 三、核心数据模型
3.1 DangdangBook 数据类
python
@dataclass
class DangdangBook:
category: str = "" # 图书分类
isbn: str = "" # ISBN 号
title: str = "" # 书名
author: str = "" # 作者
publisher: str = "" # 出版社
original_price: float | None = None # 原价
secondhand_price: float | None = None # 二手价
cover_image_url: str = "" # 封面图
condition: str = "" # 品相使用 @dataclass 装饰器,提供了自动生成的 __init__、__repr__、__eq__ 等方法,代码更简洁。
🔧 四、关键技术实现
4.1 正则表达式设计
项目定义了多组正则表达式用于精确提取图书信息:
python
# 价格提取:匹配 ¥ 符号开头的价格
PRICE_RE = re.compile(r"¥\s*([0-9]+(?:\.[0-9]{1,2})?)")
# ISBN 提取:支持多种格式
ISBN_RE = re.compile(r"(?:ISBN(?:-13)?|书号)[::]?\s*([0-9Xx-]{10,20})")
# 作者提取
AUTHOR_RE = re.compile(r"(?:作者|著者|编者)[::]?\s*([^\n\r<>]{1,80})")
# 出版社提取
PUBLISHER_RE = re.compile(r"(?:出版社|Publisher)[::]?\s*([^\n\r<>]{1,80})")4.2 多级解析策略
爬虫采用多级容错解析策略,确保在网页结构变化时仍能提取数据:
python
# 多选择器依次尝试,失败则回退到下一个
candidate_selectors = [
"ul.bigimg li", # 优先:大图列表
"ul.list li", # 次选:小图列表
"div.book_list li",
"div.search_list li",
"div#search_list li",
"div[class*='list'] li",
"div[class*='item']", # 兜底:任何包含 list/item 的 div
"li", # 最后:任何 li 元素
]4.3 详情页增量补全
列表页信息不完整时,自动抓取详情页补全数据:
python
def crawl(self) -> list[DangdangBook]:
# ... 省略部分代码 ...
# 判断是否为详情页链接
if self._looks_like_book_detail(href):
detail_html = self.fetch(href)
item = self.merge_detail(item, detail_html, href)4.4 URL 构建与参数处理
python
def build_page_url(self, page: int, start_url: str | None = None) -> str:
"""构建分页 URL"""
if page <= 1:
return start_url
# 解析现有 URL,追加或更新 page_index 参数
parsed = urlparse(start_url)
query = dict(parse_qsl(parsed.query, keep_blank_values=True))
query["page_index"] = str(page)
new_query = urlencode(query, doseq=True)
return urlunparse(parsed._replace(query=new_query))4.5 请求间隔控制
为避免被封禁,爬虫实现了智能延迟机制:
python
time.sleep(self.delay + random.uniform(0, self.delay / 2 if self.delay > 0 else 0))
# delay * 1.0 ~ delay * 1.5 之间的随机延迟🎯 五、核心类方法详解
5.1 类初始化
python
class DangdangSpider:
def __init__(
self,
start_url: str = DEFAULT_CATEGORY_URL, # 起始 URL
categories: dict[str, str] | None = None, # 分类映射
pages: int = 1, # 抓取页数
delay: float = 1.0, # 请求延迟(秒)
timeout: int = 20, # 请求超时(秒)
) -> None:
self.session = requests.Session()
self.session.headers.update(DEFAULT_HEADERS) # 复用会话5.2 默认分类配置
python
DEFAULT_CATEGORIES = {
"历史": "https://category.dangdang.com/cp01.36.00.00.00.00.html",
"艺术": "https://category.dangdang.com/cp01.07.00.00.00.00.html",
"心理学": "https://category.dangdang.com/cp01.31.00.00.00.00.html",
"外语": "https://category.dangdang.com/cp01.45.00.00.00.00.html",
}5.3 数据去重机制
python
seen_keys: set[str] = set()
key = item.isbn or f"{item.title}|{item.author}|{item.secondhand_price}"
if key in seen_keys:
continue
seen_keys.add(key)
results.append(item)💻 六、命令行接口
6.1 参数说明
| 参数 | 说明 | 默认值 |
|---|---|---|
--url |
单个分类页入口地址 | - |
--category-name |
分类名称 | "自定义分类" |
--categories |
指定分类(历史/艺术/心理学/外语) | 全部 |
--pages |
抓取页数 | 1 |
--delay |
请求间隔(秒) | 1.0 |
--output |
输出文件路径 | dangdang_books.json |
6.2 使用示例
bash
# 抓取默认分类(第1页)
python dangdang_spider.py
# 抓取历史分类5页,延迟2秒
python dangdang_spider.py --categories 历史 --pages 5 --delay 2.0
# 自定义URL抓取
python dangdang_spider.py --url "https://category.dangdang.com/cp01.36.00.00.00.00.html" --category-name "历史新书"📝 七、辅助函数
7.1 文本规范化
python
def normalize_text(text: str) -> str:
"""合并多个空白字符为单个空格"""
return re.sub(r"\s+", " ", text or "").strip()
def safe_float(value: str | None) -> float | None:
"""安全转换为浮点数,失败返回 None"""
if not value:
return None
try:
return round(float(value), 2)
except ValueError:
return None
def first_match(pattern: re.Pattern[str], text: str) -> str:
"""正则匹配首个结果"""
match = pattern.search(text or "")
return normalize_text(match.group(1)) if match else ""7.2 品相识别
python
CONDITION_KEYWORDS = [
"全新", "九成新", "八成新", "七成新", "六成新", "五成新",
"有笔记", "有划线", "轻微磨损", "品相",
]
def _guess_condition(self, text: str) -> str:
"""从文本中识别图书品相"""
for keyword in CONDITION_KEYWORDS:
if keyword in text:
return keyword
return ""🔒 八、反爬策略与容错
8.1 请求头伪装
python
DEFAULT_HEADERS = {
"User-Agent": (
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0 Safari/537.36"
),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,...",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Connection": "keep-alive",
}8.2 异常捕获
python
try:
item = self.parse_book_card(card, href, page_url)
# ...
except Exception as exc: # noqa: BLE001
logger.exception("解析失败: %s -> %s", href, exc)
finally:
if self.delay:
time.sleep(self.delay + random.uniform(...))8.3 出版社名称清洗
python
BAD_PUBLISHER_WORDS = ("加入购物车", "收藏", "购买", "我要买", "缺货", "抢购", "评论")
def _clean_publisher(self, value: str) -> str:
"""清除出版社字段中的无关词汇"""
for word in BAD_PUBLISHER_WORDS:
if word in value:
value = value.split(word, 1)[0].strip()
# ...
if len(value) > 40: # 异常长度的出版社名过滤
return ""
return value📄 九、数据输出
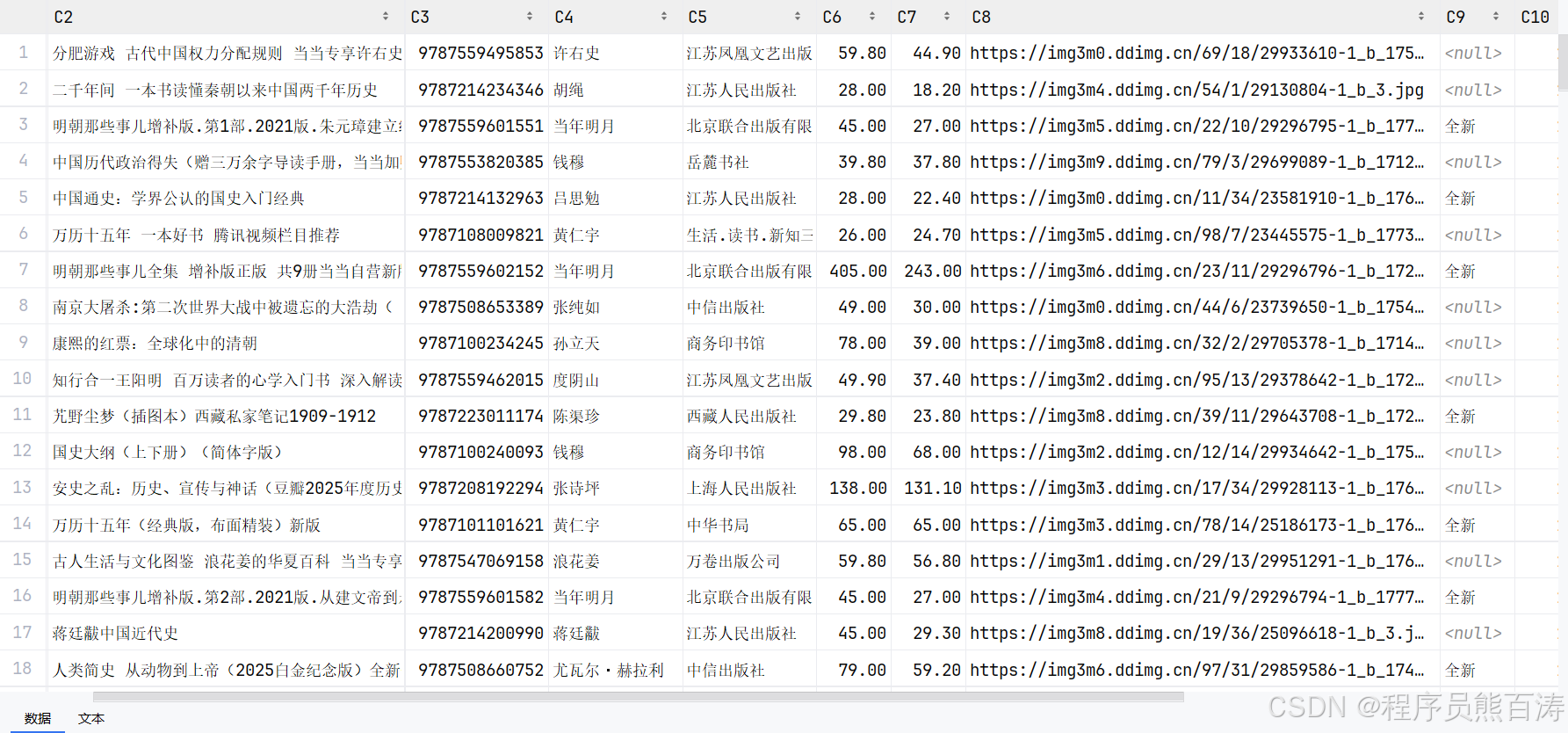
9.1 JSON 保存
python
def save_json(items: Iterable[DangdangBook], output: Path) -> None:
"""保存为格式化的 JSON 文件"""
output.parent.mkdir(parents=True, exist_ok=True)
data = [asdict(item) for item in items]
output.write_text(json.dumps(data, ensure_ascii=False, indent=2), encoding="utf-8")9.2 输出示例
json
[
{
"category": "历史",
"isbn": "9787108055543",
"title": "万历十五年",
"author": "黄仁宇",
"publisher": "中华书局",
"original_price": 45.0,
"secondhand_price": 25.0,
"cover_image_url": "https://...",
"condition": "八成新"
}
]全部代码
python
from __future__ import annotations
import argparse
import json
import logging
import random
import re
import time
from dataclasses import asdict, dataclass
from pathlib import Path
from typing import Iterable
from urllib.parse import parse_qsl, quote, urlencode, urljoin, urlparse, urlunparse
import requests
from bs4 import BeautifulSoup
DEFAULT_CATEGORY_URL = "https://category.dangdang.com/cp01.36.00.00.00.00.html"
DEFAULT_CATEGORIES = {
"历史": "https://category.dangdang.com/cp01.36.00.00.00.00.html",
"艺术": "https://category.dangdang.com/cp01.07.00.00.00.00.html",
"心理学": "https://category.dangdang.com/cp01.31.00.00.00.00.html",
"外语": "https://category.dangdang.com/cp01.45.00.00.00.00.html",
}
logger = logging.getLogger("dangdang_spider")
DEFAULT_HEADERS = {
"User-Agent": (
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0 Safari/537.36"
),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Connection": "keep-alive",
}
PRICE_RE = re.compile(r"¥\s*([0-9]+(?:\.[0-9]{1,2})?)")
ISBN_RE = re.compile(r"(?:ISBN(?:-13)?|书号)[::]?\s*([0-9Xx-]{10,20})")
AUTHOR_RE = re.compile(r"(?:作者|著者|编者)[::]?\s*([^\n\r<>]{1,80})")
PUBLISHER_RE = re.compile(r"(?:出版社|Publisher)[::]?\s*([^\n\r<>]{1,80})")
BAD_PUBLISHER_WORDS = ("加入购物车", "收藏", "购买", "我要买", "缺货", "抢购", "评论")
CONDITION_KEYWORDS = [
"全新",
"九成新",
"八成新",
"七成新",
"六成新",
"五成新",
"有笔记",
"有划线",
"轻微磨损",
"品相",
]
@dataclass
class DangdangBook:
category: str = ""
isbn: str = ""
title: str = ""
author: str = ""
publisher: str = ""
original_price: float | None = None
secondhand_price: float | None = None
cover_image_url: str = ""
condition: str = ""
def normalize_text(text: str) -> str:
return re.sub(r"\s+", " ", text or "").strip()
def safe_float(value: str | None) -> float | None:
if not value:
return None
try:
return round(float(value), 2)
except ValueError:
return None
def first_match(pattern: re.Pattern[str], text: str) -> str:
match = pattern.search(text or "")
return normalize_text(match.group(1)) if match else ""
class DangdangSpider:
"""
当当网二手图书爬虫。
目标输出字段与 `爬虫.md` 里的 JSON 样例一致:
isbn、title、author、publisher、original_price、
secondhand_price、cover_image_url、condition
"""
def __init__(
self,
start_url: str = DEFAULT_CATEGORY_URL,
categories: dict[str, str] | None = None,
pages: int = 1,
delay: float = 1.0,
timeout: int = 20,
) -> None:
self.start_url = start_url
self.categories = categories
self.pages = max(1, pages)
self.delay = max(0.0, delay)
self.timeout = timeout
self.session = requests.Session()
self.session.headers.update(DEFAULT_HEADERS)
def build_page_url(self, page: int, start_url: str | None = None) -> str:
start_url = start_url or self.start_url
if page <= 1:
return start_url
parsed = urlparse(start_url)
query = dict(parse_qsl(parsed.query, keep_blank_values=True))
query["page_index"] = str(page)
new_query = urlencode(query, doseq=True)
return urlunparse(parsed._replace(query=new_query))
def fetch(self, url: str) -> str:
response = self.session.get(url, timeout=self.timeout)
response.raise_for_status()
response.encoding = response.apparent_encoding or response.encoding
return response.text
def crawl(self) -> list[DangdangBook]:
results: list[DangdangBook] = []
seen_keys: set[str] = set()
crawl_categories = self.categories or {"二手图书": self.start_url}
for category_name, start_url in crawl_categories.items():
logger.info("开始抓取分类[%s]: %s", category_name, start_url)
for page in range(1, self.pages + 1):
page_url = self.build_page_url(page, start_url)
logger.info("开始抓取分类[%s]第 %s 页: %s", category_name, page, page_url)
html = self.fetch(page_url)
cards = self.parse_category_page(html, page_url)
logger.info("分类[%s]第 %s 页解析到 %s 条候选记录", category_name, page, len(cards))
for idx, (href, card) in enumerate(cards, start=1):
try:
item = self.parse_book_card(card, href, page_url)
item.category = category_name
if not item.title:
logger.warning("分类[%s]第 %s 页第 %s 条标题为空,跳过: %s", category_name, page, idx, href)
continue
if self._looks_like_book_detail(href):
logger.info("抓取详情页: %s", href)
time.sleep(self.delay)
detail_html = self.fetch(href)
item = self.merge_detail(item, detail_html, href)
key = item.isbn or f"{item.title}|{item.author}|{item.secondhand_price}"
if key in seen_keys:
continue
seen_keys.add(key)
results.append(item)
logger.info(
"已抓取: category=%s title=%s isbn=%s price=%s publisher=%s",
item.category,
item.title,
item.isbn or "-",
item.secondhand_price if item.secondhand_price is not None else "-",
item.publisher or "-",
)
except Exception as exc: # noqa: BLE001 - 爬虫容错
logger.exception("解析失败: %s -> %s", href, exc)
finally:
if self.delay:
time.sleep(self.delay + random.uniform(0, self.delay / 2 if self.delay > 0 else 0))
logger.info("抓取完成,共 %s 条", len(results))
return results
def parse_category_page(self, html: str, page_url: str) -> list[tuple[str, BeautifulSoup]]:
soup = BeautifulSoup(html, "html.parser")
seen: set[str] = set()
items: list[tuple[str, BeautifulSoup]] = []
candidate_selectors = [
"ul.bigimg li",
"ul.list li",
"div.book_list li",
"div.search_list li",
"div#search_list li",
"div[class*='list'] li",
"div[class*='item']",
"li",
]
for selector in candidate_selectors:
for card in soup.select(selector):
anchor = card.select_one("a[href]")
if not anchor:
continue
href = anchor.get("href", "").strip()
if not self._looks_like_book_link(href):
continue
full_url = urljoin(page_url, href)
if full_url in seen:
continue
seen.add(full_url)
items.append((full_url, card))
if items:
break
if not items:
for anchor in soup.select("a[href]"):
href = anchor.get("href", "").strip()
if not self._looks_like_book_link(href):
continue
full_url = urljoin(page_url, href)
if full_url in seen:
continue
seen.add(full_url)
container = anchor.find_parent(["li", "div", "dd", "tr"]) or anchor.parent
if container is not None:
items.append((full_url, container))
return items
def parse_book_card(self, card: BeautifulSoup, href: str, page_url: str) -> DangdangBook:
text = normalize_text(card.get_text(" ", strip=True))
anchor = card if getattr(card, "name", None) == "a" else card.select_one("a[href]")
title = ""
if anchor:
title = normalize_text(anchor.get("title") or anchor.get_text(" ", strip=True))
if not title:
title = self._extract_title_from_card(card, text)
image = ""
img = card.find("img")
if img:
image = img.get("data-original") or img.get("src") or img.get("data-src") or ""
image = urljoin(page_url, image) if image else ""
prices = [safe_float(p) for p in PRICE_RE.findall(text)]
prices = [p for p in prices if p is not None]
secondhand_price = prices[0] if prices else None
original_price = prices[1] if len(prices) > 1 else None
author = self._extract_author_from_card(card, text)
publisher = self._extract_publisher_from_card(card, text)
condition = self._guess_condition(text)
return DangdangBook(
title=title,
author=author,
publisher=publisher,
original_price=original_price,
secondhand_price=secondhand_price,
cover_image_url=image,
condition=condition,
)
def merge_detail(self, item: DangdangBook, detail_html: str, detail_url: str) -> DangdangBook:
soup = BeautifulSoup(detail_html, "html.parser")
text = normalize_text(soup.get_text(" ", strip=True))
if not item.title:
title = self._extract_title_from_detail(soup)
if title:
item.title = title
isbn = first_match(ISBN_RE, text)
if isbn:
item.isbn = isbn.replace("-", "")
if not item.author:
item.author = first_match(AUTHOR_RE, text)
if not item.publisher:
item.publisher = self._clean_publisher(first_match(PUBLISHER_RE, text))
if item.secondhand_price is None:
prices = [safe_float(p) for p in PRICE_RE.findall(text)]
prices = [p for p in prices if p is not None]
if prices:
item.secondhand_price = prices[0]
if len(prices) > 1 and item.original_price is None:
item.original_price = prices[1]
if not item.cover_image_url:
img = soup.find("img")
if img:
src = img.get("data-original") or img.get("src") or img.get("data-src") or ""
item.cover_image_url = urljoin(detail_url, src) if src else ""
if not item.condition:
item.condition = self._guess_condition(text)
return item
def _looks_like_book_link(self, href: str) -> bool:
if not href:
return False
lowered = href.lower()
return any(
token in lowered
for token in (
"product.dangdang.com",
"product.aspx",
"/product/",
"book.dangdang.com",
)
)
def _looks_like_book_detail(self, href: str) -> bool:
return self._looks_like_book_link(href)
def _extract_title_from_card(self, card: BeautifulSoup, text: str) -> str:
title_candidates = []
for selector in [
"a[title]",
".name a",
"p.name a",
"h3 a",
"h2 a",
".title a",
]:
node = card.select_one(selector)
if node:
value = normalize_text(node.get("title") or node.get_text(" ", strip=True))
if value:
title_candidates.append(value)
if title_candidates:
return title_candidates[0]
patterns = [
r"二手图书\s*([^\s¥]{2,80})",
r"〖.*?〗\s*([^\s¥]{2,80})",
r"《([^》]{2,80})》",
]
for pattern in patterns:
match = re.search(pattern, text)
if match:
return normalize_text(match.group(1))
return text[:80]
def _extract_author_from_card(self, card: BeautifulSoup, text: str) -> str:
for selector in [".author a", "p.author a", ".search_book_author a", ".author", "p.author"]:
node = card.select_one(selector)
if node:
value = normalize_text(node.get_text(" ", strip=True))
if value:
return value.replace("作者:", "").replace("著者:", "")
return first_match(AUTHOR_RE, text)
def _extract_publisher_from_card(self, card: BeautifulSoup, text: str) -> str:
search_book_author = card.select_one(".search_book_author")
if search_book_author:
value = normalize_text(search_book_author.get_text(" ", strip=True))
if value:
publisher = value.split("/")[-1].strip() if "/" in value else value
cleaned = self._clean_publisher(publisher)
if cleaned:
return cleaned
for selector in [
".publisher a",
"p.publisher a",
".search_book_publish a",
".publisher",
"p.publisher",
]:
node = card.select_one(selector)
if node:
value = normalize_text(node.get_text(" ", strip=True))
if value:
cleaned = self._clean_publisher(value.replace("出版社:", "").replace("出版社:", ""))
if cleaned:
return cleaned
return self._clean_publisher(first_match(PUBLISHER_RE, text))
def _clean_publisher(self, value: str) -> str:
value = normalize_text(value)
if not value:
return ""
for word in BAD_PUBLISHER_WORDS:
if word in value:
value = value.split(word, 1)[0].strip()
value = re.sub(r"(?:加入购物车|收藏).*$", "", value).strip(" ::,,;/|")
if not value or any(word == value for word in BAD_PUBLISHER_WORDS):
return ""
if len(value) > 40:
return ""
return value
def _guess_condition(self, text: str) -> str:
for keyword in CONDITION_KEYWORDS:
if keyword in text:
return keyword
return ""
def _extract_title_from_detail(self, soup: BeautifulSoup) -> str:
title = ""
if soup.title and soup.title.string:
title = normalize_text(soup.title.string)
if not title:
candidates = soup.select("h1, .name_info, .product_info h1, #product_info h1")
for node in candidates:
value = normalize_text(node.get_text(" ", strip=True))
if value:
return value
return title
def save_json(items: Iterable[DangdangBook], output: Path) -> None:
output.parent.mkdir(parents=True, exist_ok=True)
data = [asdict(item) for item in items]
output.write_text(json.dumps(data, ensure_ascii=False, indent=2), encoding="utf-8")
def build_arg_parser() -> argparse.ArgumentParser:
parser = argparse.ArgumentParser(description="当当网图书分类爬虫")
parser.add_argument("--url", default=None, help="单个分类页入口地址;不传则抓取默认多个分类")
parser.add_argument("--category-name", default="自定义分类", help="配合 --url 使用的分类名称")
parser.add_argument(
"--categories",
nargs="*",
choices=list(DEFAULT_CATEGORIES.keys()),
help="指定要抓取的默认分类;不传则抓取历史、艺术、心理学、外语",
)
parser.add_argument("--pages", type=int, default=1, help="抓取页数")
parser.add_argument("--delay", type=float, default=1.0, help="请求间隔秒数")
parser.add_argument("--output", default="dangdang_books.json", help="输出 JSON 文件")
return parser
def main() -> None:
args = build_arg_parser().parse_args()
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s [%(levelname)s] %(name)s: %(message)s",
)
spider = DangdangSpider(
start_url=args.url or DEFAULT_CATEGORY_URL,
categories={args.category_name: args.url} if args.url else {
name: DEFAULT_CATEGORIES[name] for name in (args.categories or DEFAULT_CATEGORIES.keys())
},
pages=args.pages,
delay=args.delay,
)
items = spider.crawl()
save_json(items, Path(args.output))
print(f"已保存 {len(items)} 条记录到 {args.output}")
if __name__ == "__main__":
main()✅ 十、总结 & 截图
本项目是一个结构清晰、容错性强、易于扩展的爬虫项目,主要技术亮点包括:
| 亮点 | 说明 |
|---|---|
| 🎯 多选择器容错 | 多种 CSS 选择器依次尝试,确保解析成功率 |
| 🔄 详情页补全 | 列表页信息不足时自动抓取详情页 |
| ⏱️ 智能延迟 | 随机延迟区间,降低被封风险 |
| 🛡️ 异常隔离 | 单条记录解析失败不影响整体流程 |
| 📦 数据去重 | 基于 ISBN 或标题+作者+价格去重 |
| 🖥️ CLI 接口 | 丰富的命令行参数支持 |
| 📊 类型提示 | 完整的类型注解,提高代码可维护性 |